工作效率:通过pdfkit包实现网页导出为pdf

工作效率:通过pdfkit包实现网页导出为pdf

Freedom123
发布于 2024-03-29 14:59:40
发布于 2024-03-29 14:59:40
简介
遇到禁止复制该怎么办?幸好我会Pytho,相信大家都有遇到这种情况(无法复制):

或者是这种情况

以上这种情况都是网页无法复制文本的情况。不过这些对于Python来说都不是问题。今天辰哥就叫你们用Python去解决。
思路:利用pdfkit库将html网页保存为pdf
一、pdfkit
pdfkit,把HTML+CSS格式的文件转换成PDF格式文档的一种工具。它就是html转成pdf工具包wkhtmltopdf的Python封装。所以,必须手动安装wkhtmltopdf。
1.安装
首先需要安装 pdfkit 库,使用 pip install pdfkit 命令就好了。 还需要安装 wkhtmltopdf 工具,本质就是利用这个工具来进行转换,pdfkit 库就是作为接口来调用该工具。 python版本 3.x,在命令行输入:
pip install pdfkit工具下载地址:wkhtmltopdf 官网:https://wkhtmltopdf.org/downloads.html
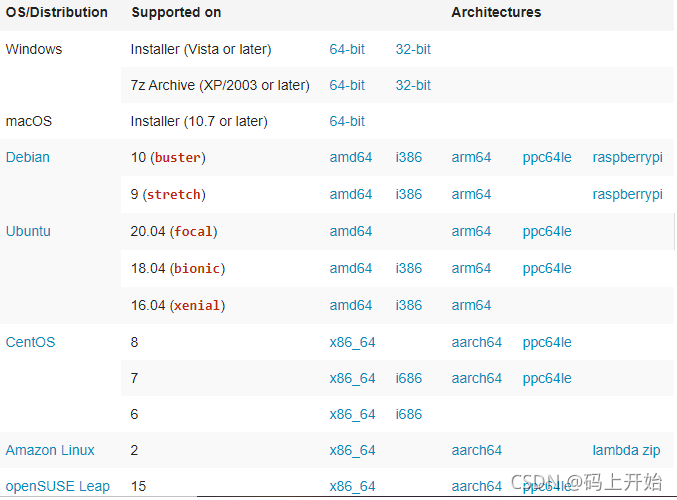
选择对于的版本下载并安装(记住自己的安装目录)
CentOS系统可以直接使用以下命令安装:
$sudo yum intsall wkhtmltopdf2.使用
2.1将url生成pdf文件
不指定wkhtmltopdf,会从系统的默认执行路径下找 wkhtmltopdf
import pdfkit
'''将url生成pdf文件'''
def url_to_pdf(url, to_file):
pdfkit.from_url(url, to_file,verbose=True)
url_to_pdf('http://www.baidu.com','out_3.pdf')指定 wkhtmltopdf 的位置:
import pdfkit
'''将url生成pdf文件'''
def url_to_pdf(url, to_file):
config = pdfkit.configuration(wkhtmltopdf='/usr/local/bin/wkhtmltopdf')
pdfkit.from_url(url, to_file,configuration=config,verbose=True)
url_to_pdf('http://www.baidu.com','out_3.pdf')3.执行
这样将内容保存为pdf就可以直接进行复制了。感兴趣的小伙伴,可以尝试其他的网页(你懂得)
二、小结
本文的讲解就到这里,内容主要是将网页保存为pdf,对于其他禁止复制的网页、长网页等都可以保存为pdf。大家下去可以去自己尝试。
1.参考
(2条消息) python包-pdfkit(wkhtmltopdf) 将HTML转换为PDF_python pdfkit_西京刀客的博客-CSDN博客
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-04-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号