『Python工具篇』requests 发起请求

本文简介
点赞 + 关注 + 收藏 = 学会了
在 《『Python爬虫』极简入门》 里介绍了写一个爬虫程序的基础原理:
- 爬取数据
- 解析数据
- 存储数据
而在爬取数据时使用的是 requests 这个库,当时只是简单的使用了一下这个库。本文打算更详细的介绍这个库的常用功能。
requests 可以帮助我们向服务器发送请求,获取资源信息(比如网页内容、文本、图片等)。而且不需要我们去关心网络请求底层的一些通讯协议和原理,它都给我们封装好了。
对于前端来说,向服务器发起网络请求通常是用 Ajax 或者 fetch ,而市面上也有很多成熟的网络请求工具,比如 axios。这类工具是在 Ajax 的基础上封装了很多简单易用的方法给前端开发者使用。
requests 和 axios 有点像,都是提供了很多方便快捷的方法给开发者使用。
对网络请求有点了解之后就开始了解一下 requests 的使用方法吧。
本文使用的编辑器是 Jupyter Notebook,这个编辑器对于学习 Python 来说非常好用,有兴趣的工友可以了解一下 《Python编辑器:Jupyter Notebook》。
安装和引入
在使用 requests 之前需要先安装并引入它。
安装
pip install requests引入
import requests基础用法
requests 支持常见的 get 、post、put、patch 和 delete 请求方法。它们在 requests 里的使用方式都差不多,本文挑最常用的 get 和 post 来讲解。
发起请求
先试试 get 请求。我们访问的网址是 http://books.toscrape.com
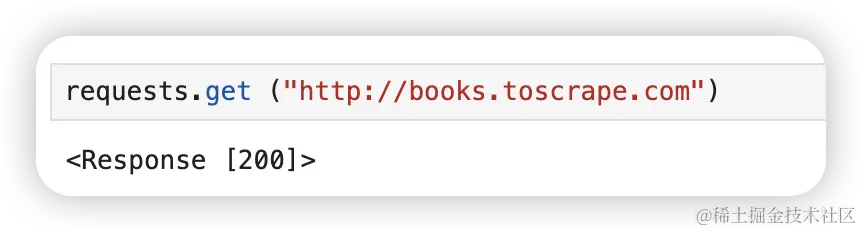
requests.get ("http://books.toscrape.com")可以看到请求后返回的结果是 <Response [200]>,可以看到返回了状态码 200,证明请求成功了。
再试试 post 请求。

requests.post ("https://jsonplaceholder.typicode.com/posts")再次成功。
从上面的规律可以看出requests 的不同请求方法的基础使用规则。
使用 get 方法的话就在 requests 后面拼上 .get,然后跟上一对括号,括号里面传入要请求的URL。post 等其他方法也同理。
响应状态码
前面看到,直接输出请求回来的内容会返回一个状态码。
我们可以先通过状态码判断响应结果,比如状态码为 200 表示响应成功,404 表示服务器无法找到所请求的资源。
想了解各个状态码分别表示什么意思,可以查阅这个网址:developer.mozilla.org/zh-CN/docs/…
状态码为 200 、201 这些其实都属于成功的状态,如果我们要将所有成功状态的状态码判断一遍就很累了。requests 提供了一个更方便的方法,可以通过 ok 来判断,如果 ok 为 True 就证明成功。
res = requests.get("https://www.baidu.com/")
if res.ok:
print("请求成功")
else:
print("失败了!")输出响应内容
请求成功后我们可以输出服务器响应回来的内容,看看里面长什么样子。此时需要输出结果的 text 里的内容。

如果你请求的是一个页面,通过 res.text 获取到的就是网页的 HTML 代码。

如果你请求的是一个接口,通过 res.text 获取到的就是接口返回的内容,通常会是对象格式(也有可能直接返回一些字符串之类的),内容是接口定义的。比如下面这个情况,内容又完全不同了。
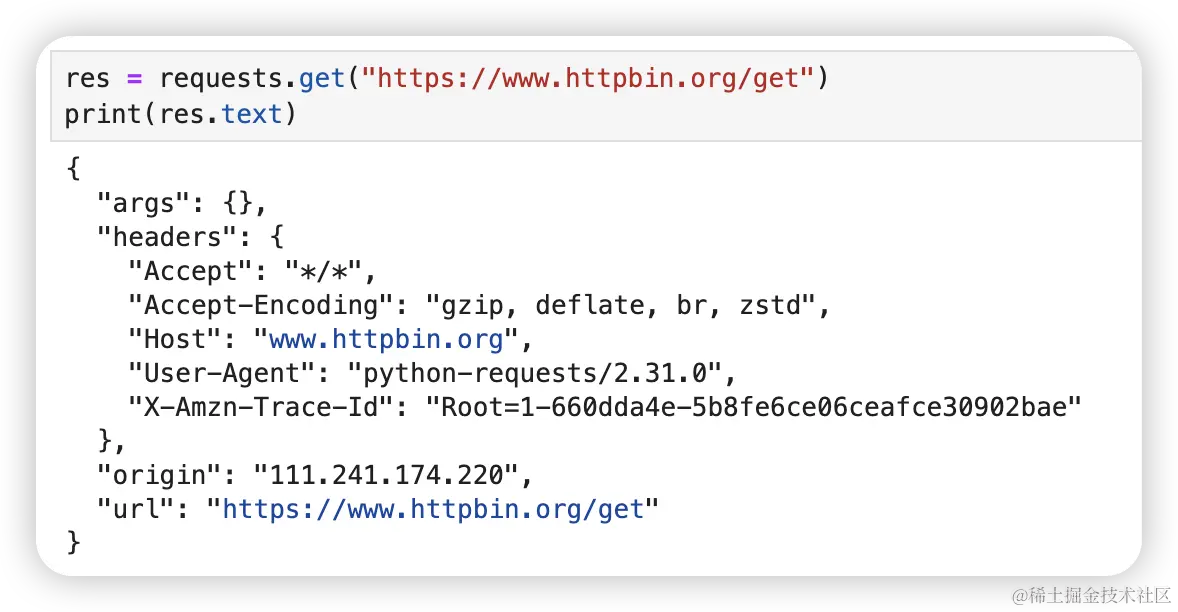
但这里有个问题啊,看上去返回的是字典,其实并不是,它只是字典格式的字符串。所以我们还需要将它转换成真正的字典类型才能方便获取里面的值。
通过 json() 方法可以将 requests 请求回来的内容转换成字典类型。
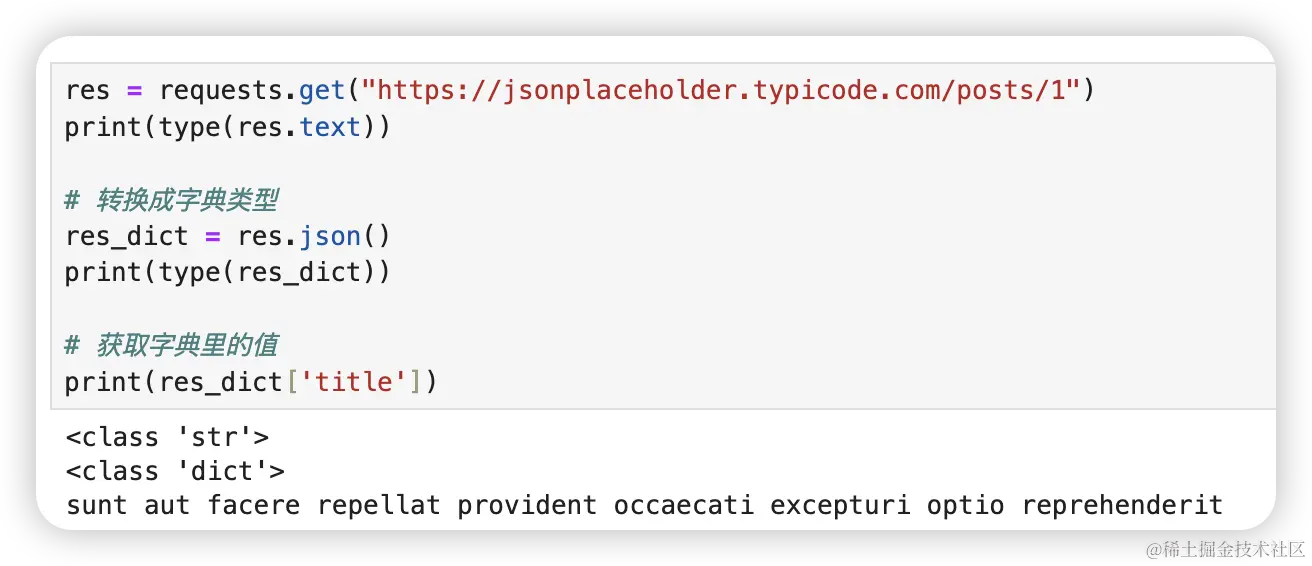
res = requests.get("https://jsonplaceholder.typicode.com/posts/1")
print(type(res.text))
# 转换成字典类型
res_dict = res.json()
print(type(res_dict))
# 获取字典里的值
print(res_dict['title'])注意,并不是所有响应内容都是 json 格式,比如你请求一个网页源码就不能用 json() 方法将其转换成字典,这种情况会抛出 json.decoder.JSONDecoderError 这个错误,需要自行判断。
获取资源文件
如果想要获取资源文件,比如图片、视频等文件,就不能使用前面讲到的方式直接获取了。
比如我想获取 jsonplaceholder 这个网站标签上的图标。
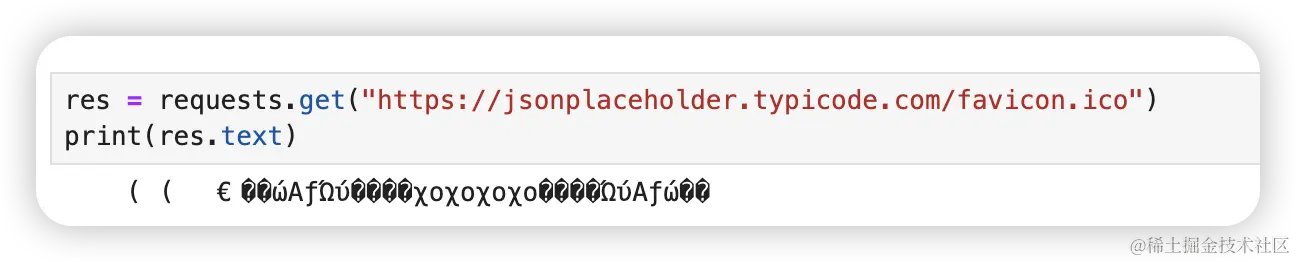
res = requests.get("https://jsonplaceholder.typicode.com/favicon.ico")
print(res.text)输出了一坨乱码,原因是我们把图片文件转成字符串了。
这类资源其实是有二进制编码组成的,我们可以通过 content 查看它的组成结构。
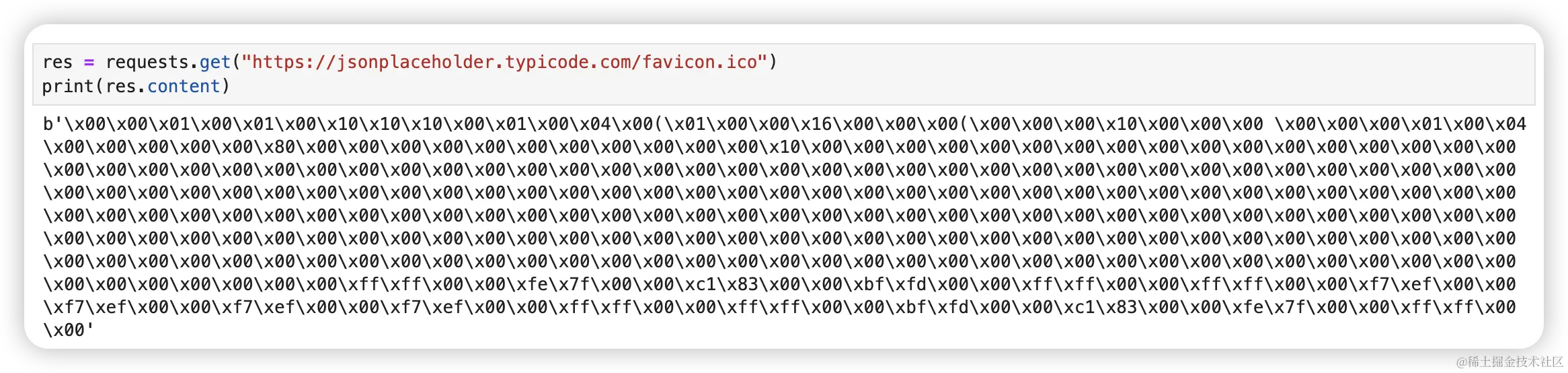
res = requests.get("https://jsonplaceholder.typicode.com/favicon.ico")
print(res.content)可以看到,输出结果是 b 开头,代表它是 bytes 类型的数据。
但我们还是看不懂这些内容,因为它需要用专用的解析工具来查看,比如各种图片查看工具。所以我们需要将这些内容保存到本地。
res = requests.get("https://jsonplaceholder.typicode.com/favicon.ico")
with open('favicon.ico', 'wb') as f:
f.write(res.content)此时我们打开项目目录就能看到这个图标了。
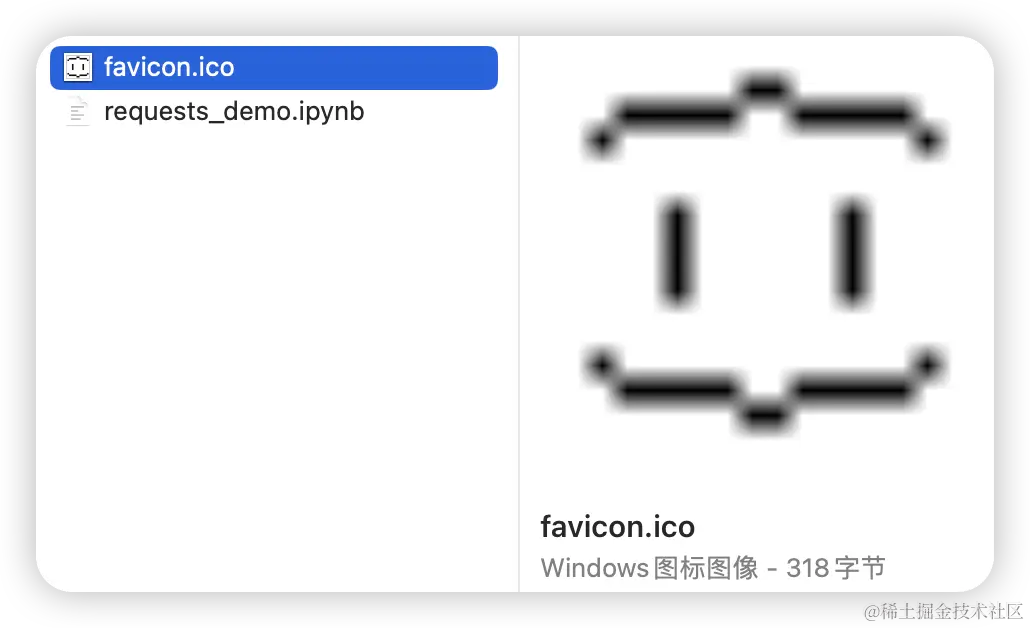
这个例子中使用到 python 对文件的“写”操作,关于文件的“读/写”操作之后我会写一篇文章专门讲解。
其他响应参数
前面我们了解到如何获取响应数据中的内容(text 和 content),如何获取状态码。
除了这些数据之外,我们还可以获取响应数据中的响应头、Cookie 等数据。
res = requests.get("https://www.baidu.com")
# 获取响应头
print(res.headers)
# 获取cookie
print(res.cookies)
# 获取当前请求的url
print(res.url)
# 获取历史请求
print(res.history)拼接参数
使用 get 请求时,有时候需要带上一些额外的信息,此时通常会将参数拼接到 URL 里,比如这样:
https://jsonplaceholder.typicode.com/comments?postId=1这里我拼接了一个参数 postId=1,这样写是没问题的,但如果参数有八九十个点时候,这样写就不好维护了,看到眼都花了。这种情况一般可以这样写:

params = {
"postId": "11"
}
res = requests.get("https://jsonplaceholder.typicode.com/comments", params=params)
print(res)通过维护 params 这个参数,写法就优雅很多了。
post 请求如果不把参数拼接到 URL 上,就需要用到 data 这个参数了。
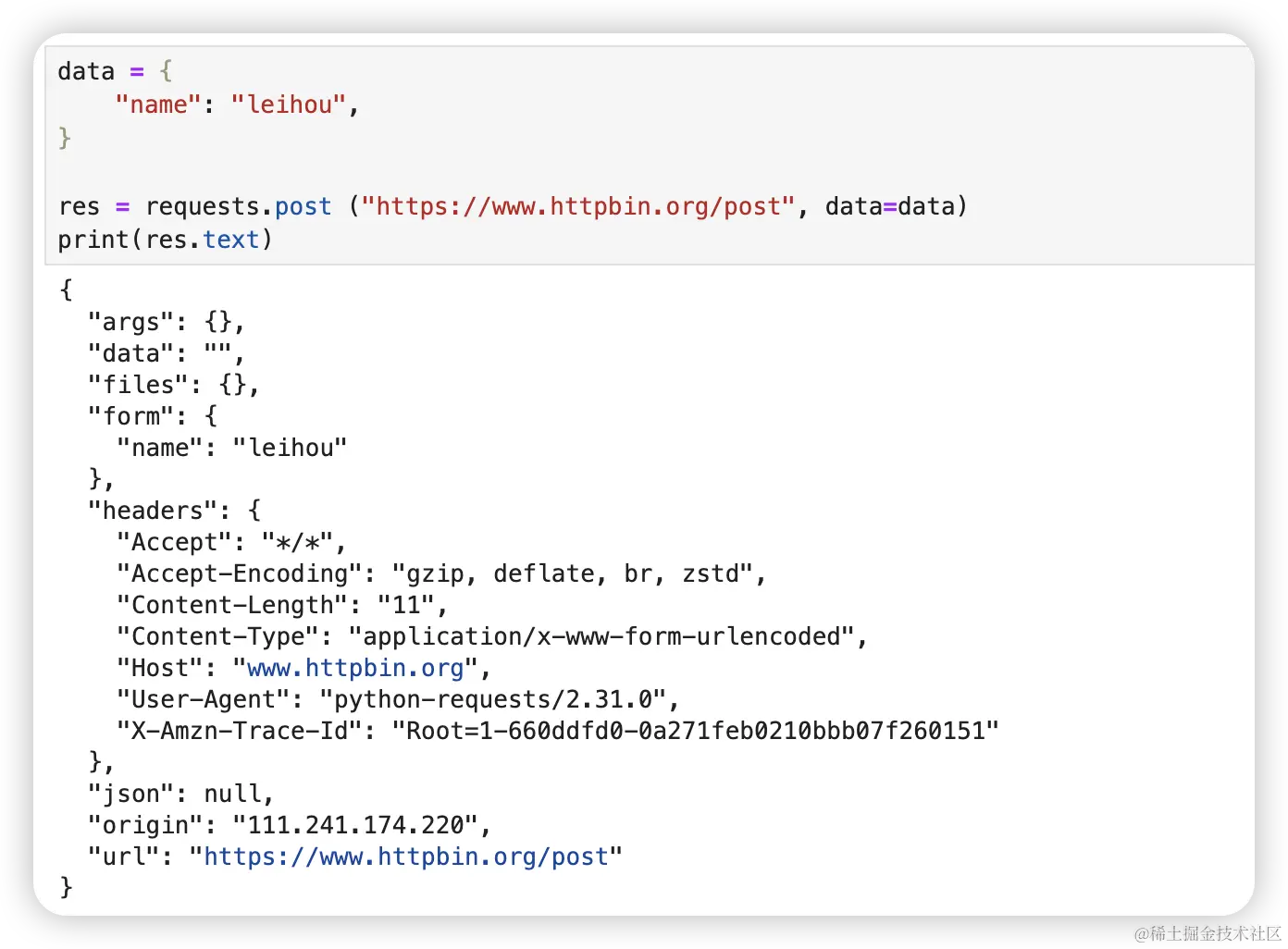
data = {
"name": "leihou",
}
res = requests.post ("https://www.httpbin.org/post", data=data)
print(res.text)请求头
在发送请求时,除了将 params 和 data 的数据发送出去之外,还会将请求头的数据也一起发送出去。
有些网站是限制爬虫直接爬取数据的,比如豆瓣。
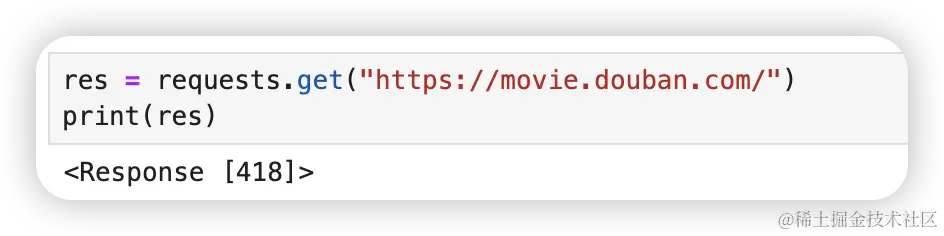
res = requests.get("https://movie.douban.com/")
print(res)状态码 418 表示服务器拒绝冲泡咖啡,因为它是个茶壶。该错误是超文本咖啡壶控制协议的参考,和 1998 年愚人节的玩笑。
翻译成人话就是服务器不想理你。
此时我们就要将爬虫代码伪装成是通过浏览器发起的请求,我们就可以将请求头里的 User-Agent 设置成浏览器。

headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
res = requests.get("https://movie.douban.com/", headers=headers)
print(res)headers 还可以放各种自定义内容,这个要看请求的网站需要你提供哪些内容。
获取和设置cookie
当你在浏览网页时,有时会看到一些网站问你是否同意使用 cookie。那么什么是 cookie 呢?它可不是我们生活中的小饼干。
想象一下你去了一家咖啡馆,服务员问你想要什么,你说你想要一杯咖啡。这时服务员会给你一张小票,上面写着你点了一杯咖啡。等咖啡做好之后,你拿着这张小票给服务员,服务员就知道哪杯咖啡是你的了。
在网站上,cookie 就像这张小票一样。当你访问一个网站时,它会给你的浏览器发送一个小文件,里面包含一些信息,比如你之前在网站上做过什么,比如你在购物网站里放了什么商品到购物车里。这样,当你再次访问这个网站时,网站就能识别你,知道你之前做过什么,从而提供更好的个性化服务。所以,cookie就是一种让网站记住你并提供更好服务的方式。
前面提到,可以使用 res.cookies 的方式获取服务器返回的 cookie 信息。
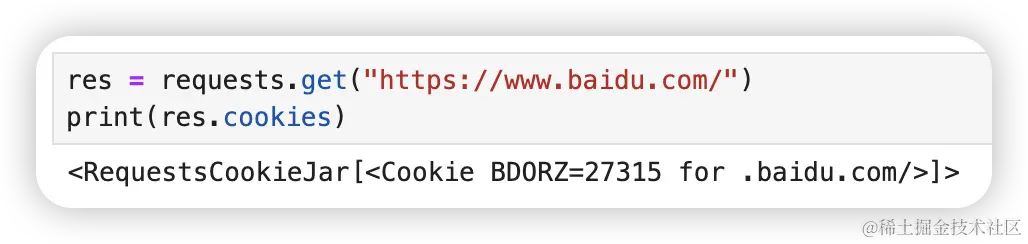
res = requests.get("https://www.baidu.com/")
print(res.cookies)我们可以使用 items() 方法将 cookie 里的数据遍历出来。

res = requests.get("https://www.baidu.com/")
for key, value in res.cookies.items():
print(key + " - " + value)获取 cookie 就这么简单。
设置 cookie 也同样简单。
我举个不太正规的例子哈,有一个网站在你登录后,你打开“我的”页面能看到你的用户名,这个用户名是你之前设置好的。
在这个场景中,服务器会在你登录后,在你的浏览器的 cookie 里放一个 userID,等你打开“我的”页面时,浏览器会向服务器发起一个“获取用户信息”的请求,服务器这时会读取这个请求里的 cookie 信息,发现 cookie 里有 userID 这个字段,就会拿着 userID 去数据库里查对应的用户信息返回给浏览器。
而我们使用爬虫脚本,想获取自己存放在这个网站的用户信息时,首先需要知道自己的 userID 是什么(这很简单,我们打开浏览器登录一次,打开控制台查找一下就知道了)。拿到 userID 后再把它放在爬虫脚本的 cookie 里再发起请求即可。
操作如下:
headers = {
"Cookie": "userID=123456"
}
res = requests.get("https://www.baidu.com", headers=headers)当然,cookie 通常不值1个数据,不同数据之间用 ; 分隔。
举个例子
headers = {
"Cookie": "params1=123; params2=456; params3=789"
}
requests.get("https://www.baidu.com", headers=headers)还有另一种写法,通过 RequestCookieJar 对象的 set 方法设置好 cookie 的每一个值。
cookies = "params1=123; params2=456; params3=789"
jar = requests.cookies.RequestsCookieJar()
for cookie in cookies.split(";"):
key, value = cookie.split("=", 1)
jar.set(key, value)
requests.get("https://www.baidu.com", cookies=jar)维持 Session
requests 不同的请求使用的不是同一个 session 。 requests 早已想到这种情况,只需在前面讲到的所有案例的基础上稍作改造即可。
req_s = requests.Session()
req_s.get("https://www.httpbin.org/cookies/set/name/leihou")
res = req_s.get("https://www.httpbin.org/cookies")
print(res.text)SSL证书
使用HTTPS协议的网站需要设置好证书,但有些网站偏偏没设置好,所以访问时浏览器会出现提示信息。
使用 requests 访问时也会报错。
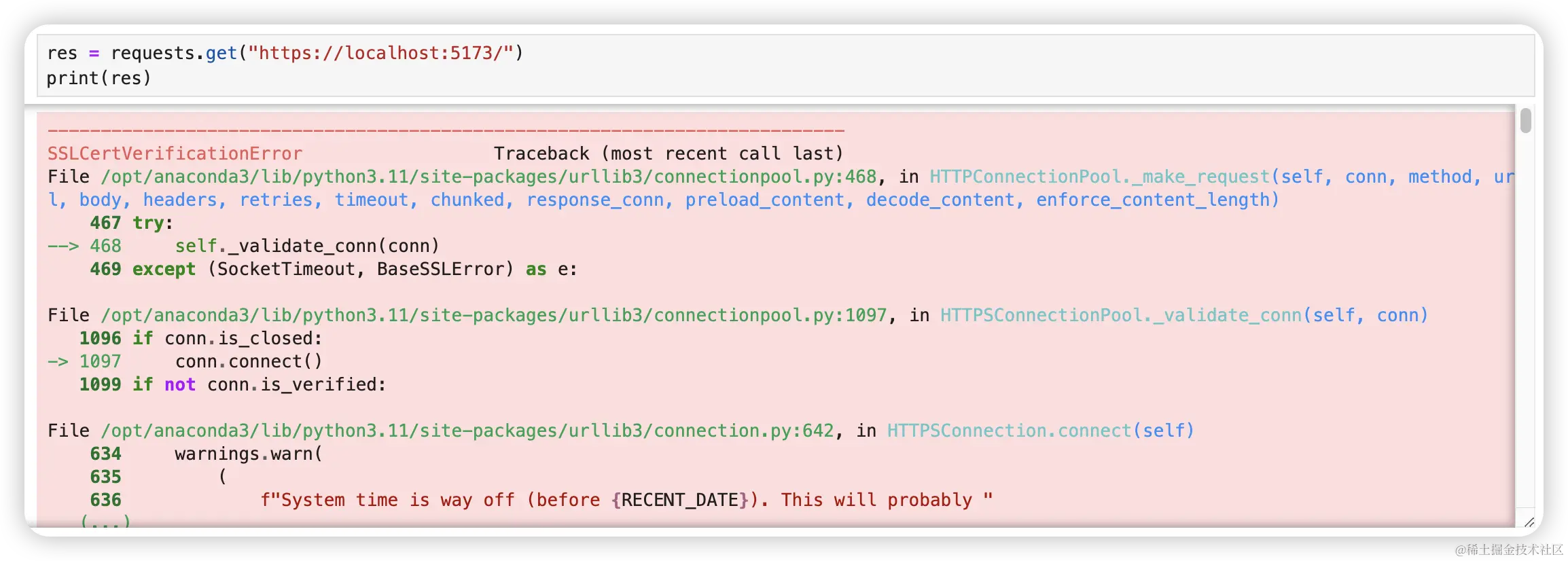
res = requests.get("https://localhost:5173/")
print(res)怎么办怎么办?
其实我们只要告诉 requests 不去检测安全证书就行了,在请求时加多一个 verify 参数,将它设置为 False 。

res = requests.get("https://localhost:5173/", verify=False)
print(res)状态码返回200了,但它还是很啰嗦,还是要提醒你。
如果不想看这些警告可以这么做
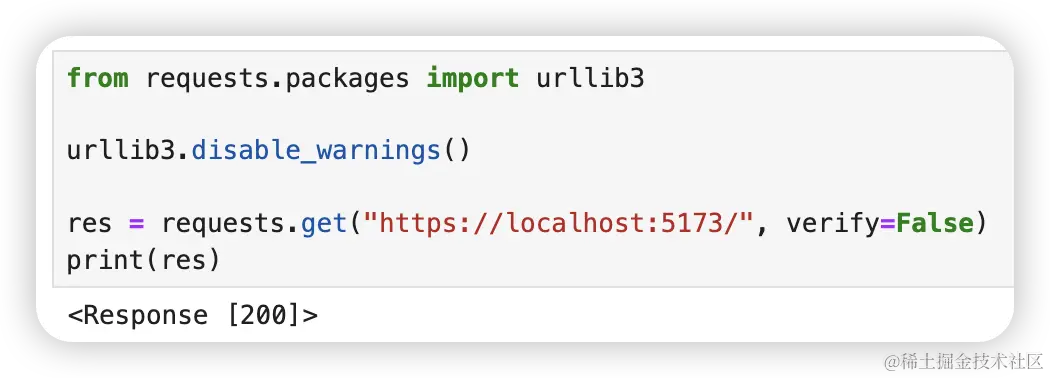
from requests.packages import urllib3
urllib3.disable_warnings()
res = requests.get("https://localhost:5173/", verify=False)
print(res)设置超时
当你发起请求时,服务器迟迟不给答复你,你可以设置一个时间,如果超过这个时间就算了。
这个时间可以自己定,这么设置:

res = requests.get("https://www.baidu.com", timeout=0.001)
print(res)timeout 接收一个描述,1表示1秒,0.001表示0.001秒。
点赞 + 关注 + 收藏 = 学会了