RDMA-Linux-infiniband-RDMA子系统-源码分析-IB架构-IB设备初始化和注册-内核uverbs接口注册-GID缓存机制
原创
RDMA-Linux-infiniband-RDMA子系统-源码分析-IB架构-IB设备初始化和注册-内核uverbs接口注册-GID缓存机制
原创
术语
- RDMA netlink类型有4种:
enum {
RDMA_NL_IWCM = 2,
RDMA_NL_RSVD,
RDMA_NL_LS, /* RDMA Local Services */
RDMA_NL_NLDEV, /* RDMA device interface */
RDMA_NL_NUM_CLIENTS
};- 子网SA/子网管理器SM: InfiniBand 子网管理 (SA) 服务是由子网管理器 (SM) 提供的预定义通用服务代理 (GSA)。 在 InfiniBand 结构上,设备应通过联系 SA 查询正确的路由来解析到其他主机的路由
简介
IB软件架构
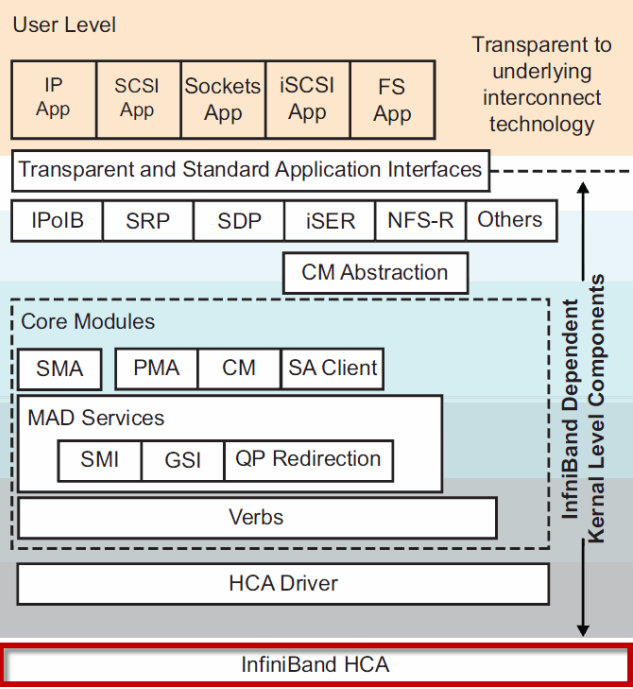
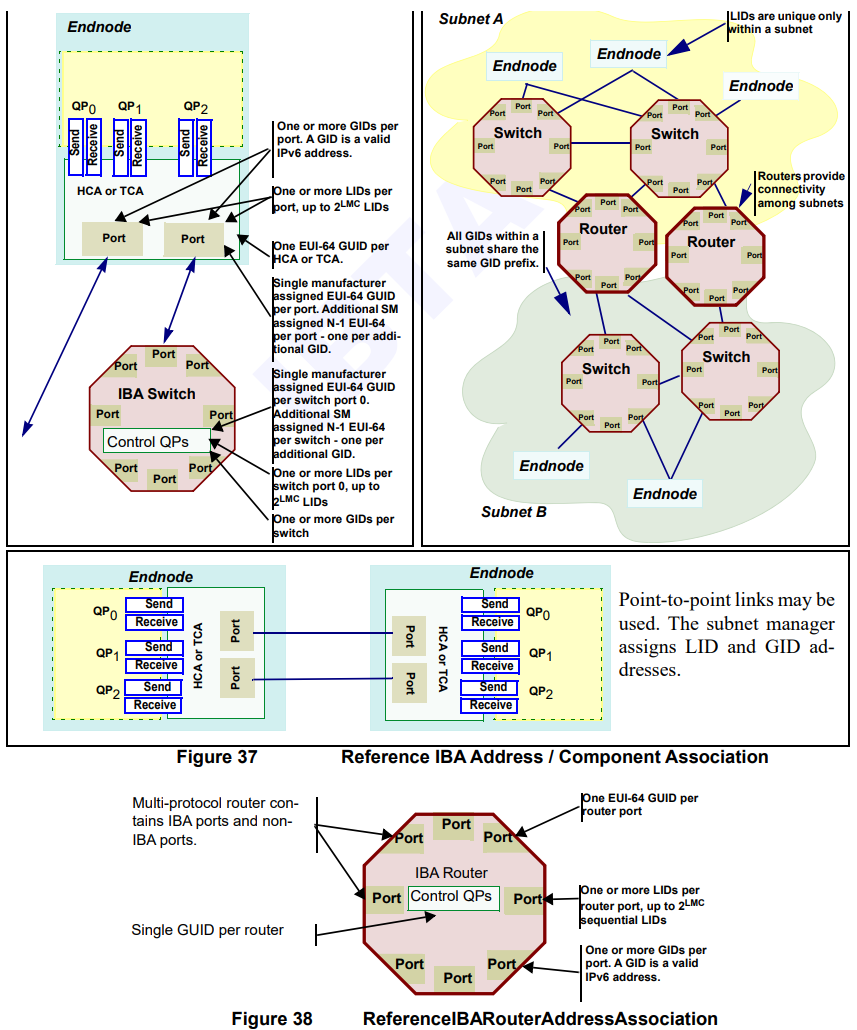
寻址/子网
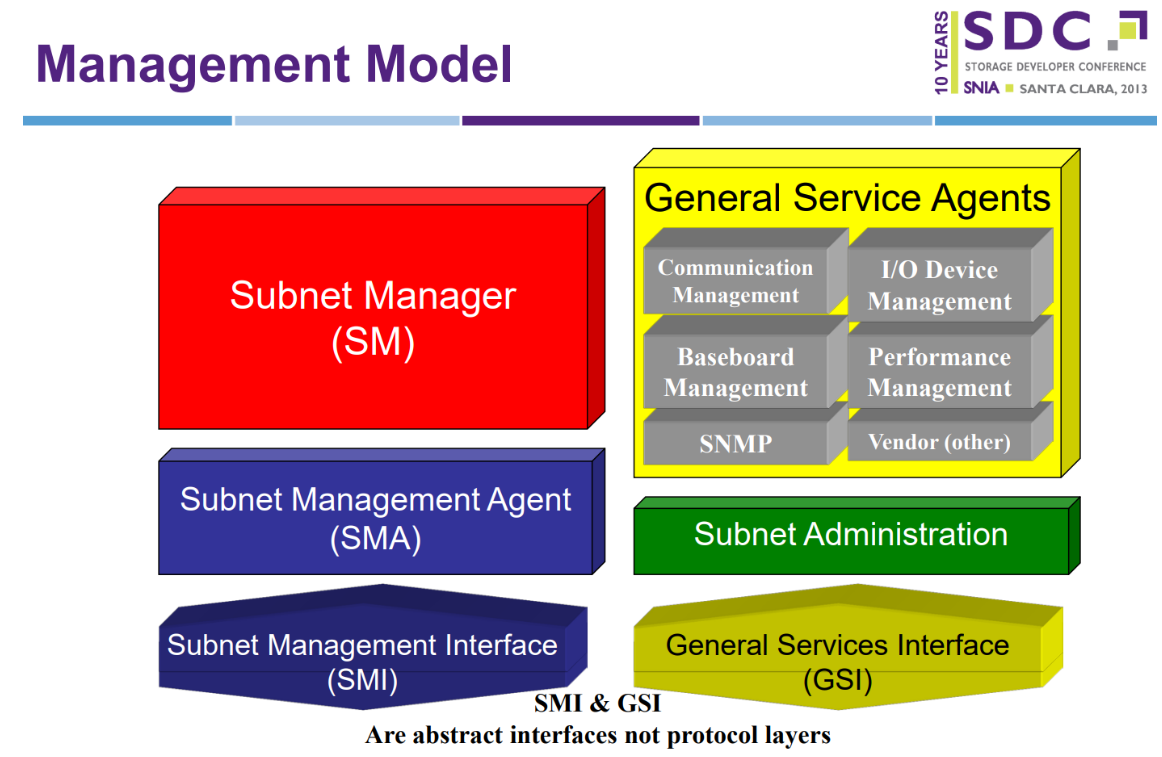
管理模型
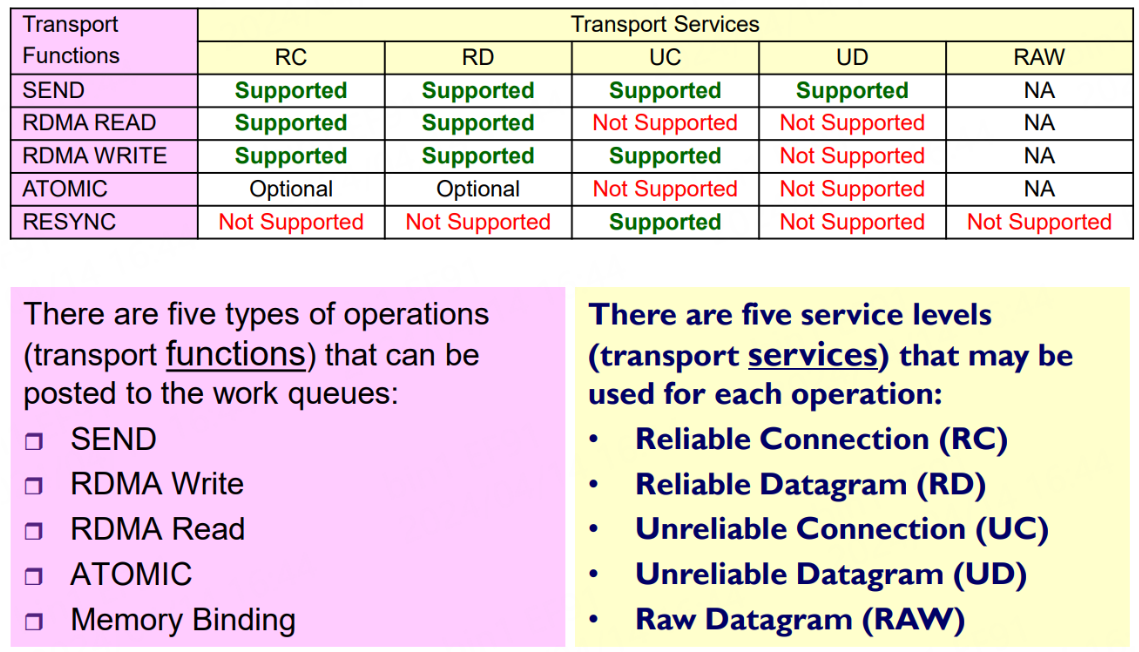
IB五种传输类型和服务
RXE简介:
该驱动程序通过 Linux 网络堆栈实现 InfiniBand RDMA 传输。 它使具有标准以太网适配器的系统能够与 RoCE 适配器或运行 RXE 驱动程序的另一个系统进行互操作。 有关 InfiniBand 和 RoCE 的文档可以从 www.infinibandta.org 和 www.openfabrics.org 下载。 (另请参见 siw,它是 iWARP 的类似软件驱动程序。)该驱动程序分为两层,一层与 Linux RDMA 堆栈接口,并实现内核或用户空间动词 API。 用户空间动词 API 需要一个名为 librxe 的支持库,该支持库由通用用户空间动词 API libibverbs 加载。 另一层与第 3 层的 Linux 网络堆栈接口。要配置和使用 soft-RoCE 驱动程序,请使用“配置 Soft-RoCE (RXE)”部分下的以下 wiki 页面:https://github.com/linux-rdma/rdma-core/blob/master/Documentation/rxe.md
中间软件层/CM/SA/SMA/PMA/GSI/MAD/QP0_1/SMI

管理能力标记位
/* Management 0x00000FFF */
#define RDMA_CORE_CAP_IB_MAD 0x00000001
#define RDMA_CORE_CAP_IB_SMI 0x00000002
#define RDMA_CORE_CAP_IB_CM 0x00000004
#define RDMA_CORE_CAP_IW_CM 0x00000008
#define RDMA_CORE_CAP_IB_SA 0x00000010
#define RDMA_CORE_CAP_OPA_MAD 0x00000020模块依赖关系
rdma_rxe.ko依赖ib_core.ko, ib_uverbs.ko及其他网络模块, 详见:
drivers/infiniband/Kconfig
# SPDX-License-Identifier: GPL-2.0-only
config RDMA_RXE
tristate "Software RDMA over Ethernet (RoCE) driver"
depends on INET && PCI && INFINIBAND -> 依赖RDMA相关模块
depends on INFINIBAND_VIRT_DMA
rdma模块定义如下:
drivers/infiniband/Kconfig
# SPDX-License-Identifier: GPL-2.0-only
menuconfig INFINIBAND
tristate "InfiniBand support"
depends on HAS_IOMEM && HAS_DMA
depends on NET
depends on INET
depends on m || IPV6 != m
depends on !ALPHA
select IRQ_POLL
select DIMLIB
help
Core support for InfiniBand (IB). Make sure to also select
any protocols you wish to use as well as drivers for your
InfiniBand hardware.
if INFINIBAND
config INFINIBAND_USER_MAD
tristate "InfiniBand userspace MAD support"
depends on INFINIBAND子网管理
3.7.5.1 子网管理 子网管理实际上分为子网管理器 (SM) 应用程序和子网管理代理 (SMA)。 每个子网只需要一个子网管理器,它可以驻留在任何节点,包括交换机和路由器。 子网管理使用一类特殊的管理数据报 (MAD),称为子网管理数据包 (SMP),它被定向到特殊的队列对 (QP0)。 如图 30 所示,每个端口都有一个 QP0,每个节点都包含一个 SMA,用于: • 处理 QP0 上接收到的 Get() 和 Set() SMP • 将 GetResp() SMP 发送出 QP0 • 将 Trap() SMP 发送出 QP0 A 子网管理器: • 将SMP 从QP0 发送到任何端口的QP0 • 处理QP0 上收到的所有SMP(由该节点的SMA 处理的SMP 除外)
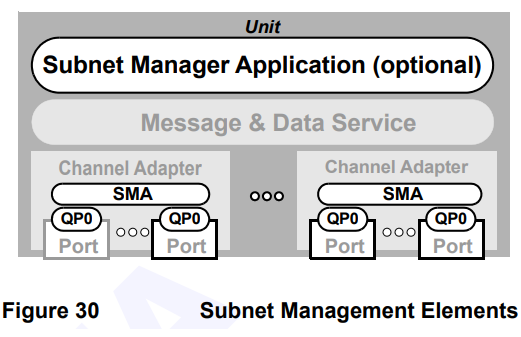
3.7.5.2 一般服务 一般服务代理(GSA*)实际上由许多管理服务代理组成,如图 31 所示。有些服务是可选的。 通用服务使用称为通用管理数据包 (GMP) 的消息格式,它是管理数据报 (MAD),通常定向到称为通用服务接口 (GSI) 的特殊队列对 (QP1)。 如图 31 所示,每个端口都有一个 QP1,QP1 上收到的所有 GMP 均由其中一个 GSA 处理。 GSA 实际上能够将其特定服务类别的 GMP 重定向到另一个队列对,从而允许每个 GSA 维护自己的通信接口

RoCEv2帧格式

虚拟化verbs
源码流程
uverbs注册流程
以rdma_rxe.ko为例, 执行modinfo查看其依赖ib_core和ib_uverbs
当用户态iproute2/rdma库执行rdma link add rxe_ens3 type rxe netdev ens3时
qemu_vm:
/root/project/rdma/iproute2/rdma
gdb --args ./rdma link add rxe_ens3 type rxe netdev ens3
main
filename = basename(argv[0]);
err = rd_init(&rd, filename);
rd_prepare_msg
err = rd_batch(&rd, batch_file, force)
rd_cmd(&rd, argc, argv)
rd_exec_cmd
rd_argv_match
c->func(rd) -> int cmd_link
rd_exec_cmd -> link_add
link_add -> link_add_type -> link_add_netdev
rd_prepare_msg(rd, RDMA_NLDEV_CMD_NEWLINK, &seq, -> to kernel 通过Netlink转到内核态
mnl_attr_put_strz(rd->nlh, RDMA_NLDEV_ATTR_DEV_NAME, rd->link_name);
...内核态动态加载rdma_rxe.ko模块, 并加载其依赖模块
kernel: RDMA_NLDEV_CMD_NEWLINK
static const struct rdma_nl_cbs nldev_cb_table[RDMA_NLDEV_NUM_OPS] = {
[RDMA_NLDEV_CMD_GET] = {
.doit = nldev_get_doit,
.dump = nldev_get_dumpit,
},
[RDMA_NLDEV_CMD_GET_CHARDEV] = {
.doit = nldev_get_chardev,
},
[RDMA_NLDEV_CMD_SET] = {
.doit = nldev_set_doit,
.flags = RDMA_NL_ADMIN_PERM,
},
[RDMA_NLDEV_CMD_NEWLINK] = {
.doit = nldev_newlink, -> 根据用户态发送的RDMA_NLDEV_CMD_NEWLINK命令, 执行此doit函数
.flags = RDMA_NL_ADMIN_PERM,
},加载模块及依赖模块: MODULE_ALIAS_RDMA_LINK("rxe");
nldev_newlink
nlmsg_parse_deprecated
dev_get_by_name
link_ops_get
CONFIG_MODULES
request_module("rdma-link-%s", type) <- #define MODULE_ALIAS_RDMA_LINK(type) MODULE_ALIAS("rdma-link-" type) -> MODULE_ALIAS_RDMA_LINK("rxe"); -> 动态加载
ops->newlink(ibdev_name, ndev)执行ib_core(ib_core_init)和ib_uverbs的初始化函数
drivers/infiniband/core/device.c
fs_initcall(ib_core_init); -> RDMA/core:将 sysfs 条目视图限制为 init_net,这是一个准备补丁,用于在网络命名空间中提供 rdma 设备的隔离。 第一步,使 rdma 设备仅在 init net 命名空间中可见。 后续补丁将使用 compat ib_core_device 设备/sysfs 树在多个网络命名空间中启用 rdma 设备可见性。 由于IB子系统依赖于net stack,因此需要在netdev之后初始化,并且由于它支持设备,因此需要在设备子系统之前初始化; 因此,将 initcall 顺序更改为 fs_initcall,以便在内核映像中编译 ib_core 时遵循正确的 init 顺序
static int __init ib_core_init(void)
ib_wq = alloc_workqueue("infiniband", 0, 0)
ib_comp_unbound_wq -> IB/core:向新的 CQ API 添加未绑定的 WQ 类型,下面引用的上游内核提交将新的 CQ API 中的工作队列修改为绑定到特定的 CPU(而不是未绑定)。 这导致新 CQ API 的所有用户都使用相同的绑定 WQ。 具体来说,当绑定到 WQ 的 CPU 忙于处理(更高优先级)中断时,MAD 处理会严重延迟。 这导致 MAD“心跳”响应处理延迟,从而导致端口被错误地分类为“关闭”。 要解决此问题,请向新的 CQ API 添加新的“未绑定”WQ 类型,以便用户可以选择绑定 WQ 或未绑定 WQ。 对于 MAD,选择新的“未绑定”WQ
class_register(&ib_class) -> int class_register(const struct class *cls)
pr_debug("device class '%s': registering\n", cls->name)
error = sysfs_create_groups(&cp->subsys.kobj, cls->class_groups)
rdma_nl_init -> IB/core:在 netlink 消息处理期间避免死锁,当未加载 rdmacm 模块时,以及当接收 netlink 消息以获取 char 设备信息时,由于使用以下调用序列对 rdma_nl_mutex 进行递归锁定,因此会导致死锁。 [..] rdma_nl_rcv() mutex_lock() [..] rdma_nl_rcv_msg() ib_get_client_nl_info() request_module() iw_cm_init() rdma_nl_register() mutex_lock(); <- 死锁,再次获取互斥体 由于上述调用序列,观察到以下调用跟踪和死锁。 内核:__mutex_lock+0x35e/0x860 内核:? __mutex_lock+0x129/0x860 内核:? rdma_nl_register+0x1a/0x90 [ib_core] 内核: rdma_nl_register+0x1a/0x90 [ib_core] 内核:? 0xffffffffc029b000 内核:iw_cm_init+0x34/0x1000 [iw_cm] 内核:do_one_initcall+0x67/0x2d4 内核:? kmem_cache_alloc_trace+0x1ec/0x2a0 内核:do_init_module+0x5a/0x223 内核:load_module+0x1998/0x1e10 内核:? __symbol_put+0x60/0x60 内核:__do_sys_finit_module+0x94/0xe0 内核:do_syscall_64+0x5a/0x270 内核:entry_SYSCALL_64_after_hwframe+0x49/0xbe 进程堆栈跟踪:[<0>] __request_module+0x1c9/0x460 [<0>] ib_get_client_nl _信息+0x5e/0xb0 [ib_core] [<0>] nldev_get_chardev+0x1ac/0x320 [ib_core] [<0>] rdma_nl_rcv_msg+0xeb/0x1d0 [ib_core] [<0>] rdma_nl_rcv+0xcd/0x120 [ib_core] [<0>] netlink_unicast+0x179 /0x220 [<0>] netlink_sendmsg+0x2f6/0x3f0 [<0>] sock_sendmsg+0x30/0x40 [<0>] ___sys_sendmsg+0x27a/0x290 [<0>] __sys_sendmsg+0x58/0xa0 [<0>] do_syscall_64+0x5a /0x270 [<0>]entry_SYSCALL_64_after_hwframe+0x49/0xbe 为了克服此死锁并允许多个 netlink 消息并行处理,实施了以下方案。 1. 将保护cb_table 的锁拆分为per-index 锁,并使其成为rwlock。 此锁用于确保取消注册返回后不会运行任何回调。 由于模块一旦已经运行回调就不会被注册,这避免了死锁。 2. 注册时使用smp_store_release()更新cb_table,这样就不需要锁了。 这避免了认为所有 rwsem 都是相同锁类的 lockdep 问题
init_rwsem(&rdma_nl_types[idx].sem)
addr_init -> IB/core:将IB地址解析模块集成到核心中,IB地址解析被声明为一个模块(ib_addr.ko),该模块在IB核心模块(ib_core.ko)之前加载自身。 这会导致由IB core初始化的IB netlink无法被ib_addr.ko使用的情况。 为了解决这个问题,我们将 ib_addr.ko 转换为 IB 核心模块的一部分
alloc_ordered_workqueue("ib_addr", 0)
register_netevent_notifier(&nb) -> netevent_callback
NETEVENT_NEIGH_UPDATE
set_timeout(req, jiffies)
ib_mad_init
INIT_LIST_HEAD(&ib_mad_port_list) <- ib_mad_port_open
list_add_tail(&port_priv->port_list, &ib_mad_port_list)
ib_register_client(&mad_client)
ib_sa_init -> 中间核心层:Mid-layer Core , 核心服务包括管理接口(MAD)、连接管理器(CM)接口和子网管理员(SA)接口。 该堆栈包括用于用户模式和内核应用程序的组件。 核心服务在内核中运行,并为动词、CM 和管理向用户模式公开接口 -> 第 5 章 配置 INFINIBAND 子网管理器, 所有 InfiniBand 网络都必须运行子网管理器才能正常工作。即使两台机器没有使用交换机直接进行连接, 也是如此。 有可能有一个以上的子网管理器。在那种情况下,当主子网管理器出现故障时,另外一个作为从网管理器 的系统会接管。 大多数 InfiniBand 交换机都包含一个嵌入式子网管理器。然而,如果您需要一个更新的子网管理器,或者 您需要更多控制,请使用 Red Hat Enterprise Linux 提供的 OpenSM 子网管理器
get_random_bytes(&tid, sizeof tid)
ib_register_client(&sa_client)
mcast_init -> IB/sa:跟踪多播加入/离开请求,IB SA 以每个端口为基础跟踪多播加入/离开请求,并且不执行任何引用计数:如果同一端口的两个用户加入同一组,并且其中一个用户离开该组 ,那么 SA 将从组中删除该端口,即使有一个用户想要保留成员身份。 因此,为了支持来自同一端口的同一组播组的多个用户,我们需要在本地执行引用计数。 为此,向 ib_sa 添加一个多播子模块以执行多播加入/离开操作的引用计数。 修改ib_ipoib(多播的唯一内核用户)以使用新接口
ib_sa_register_client(&sa_client)
ib_register_client(&mcast_client) -> mcast_add_one -> InfiniBand 子网管理 (SA) 服务是由子网管理器 (SM) 提供的预定义通用服务代理 (GSA)。 在 InfiniBand 结构上,设备应通过联系 SA 查询正确的路由来解析到其他主机的路由
rdma_cap_ib_mcast -> rdma_cap_ib_mcast - 检查设备端口是否具有 Infiniband、组播功能。 @device:要检查的设备 @port_num:要检查的端口号 * InfiniBand 多播注册比普通 IPv4 或 IPv6 多播注册更复杂。 当每个主机通道适配器希望加入多播组时,必须向子网管理器注册。 无论它订阅该组有多少队列对,它都应该只执行一次。 只有在附加到该组的所有队列对都已分离后,它才应该离开该组。 * 返回:如果端口必须承担向 SM 注册/取消注册以及跟踪附加到多播组的队列对总数的额外管理开销,则返回 true
ib_set_client_data(device, &mcast_client, dev)
INIT_IB_EVENT_HANDLER(&dev->event_handler, device, mcast_event_handler)
switch (event->event)
mcast_groups_event
rb_first
rb_next
rb_entry
ib_register_event_handler(&dev->event_handler)
alloc_ordered_workqueue("ib_nl_sa_wq", WQ_MEM_RECLAIM)
INIT_DELAYED_WORK(&ib_nl_timed_work, ib_nl_request_timeout) -> ib_nl_request_timeout
queue_delayed_work(ib_nl_wq, &ib_nl_timed_work, delay)
ib_sa_disable_local_svc
send_handler -> callback
register_blocking_lsm_notifier(&ibdev_lsm_nb) -> LSM:切换到阻止策略更新通知程序,原子策略更新程序不是很有用,因为它们通常无法自行执行策略更新。 由于似乎对原子性没有严格的要求,因此切换到阻塞变体。 执行此操作时,相应地重命名函数
blocking_notifier_chain_register
register_pernet_device(&rdma_dev_net_ops)
nldev_init()
rdma_nl_register(RDMA_NL_LS, ibnl_ls_cb_table) -> rdma_nl_register(RDMA_NL_NLDEV, nldev_cb_table)
down_write(&rdma_nl_types[index].sem)
rdma_nl_types[index].cb_table = NULL
roce_gid_mgmt_init -> IB/核心:添加 RoCE GID 表管理,RoCE GID 基于与 RDMA (RoCE) 设备端口相关的以太网网络设备上配置的 IP 地址。 目前,每个支持 RoCE(ocrdma、mlx4)的低级驱动程序都管理自己的 RoCE 端口 GID 表。 由于本质上没有任何特定于供应商的内容,因此我们对其进行概括,并增强 RDMA 核心 GID 缓存来完成这项工作。 为了填充 GID 表,我们监听事件: (a) netdev up/down/change_addr 事件 - 如果 netdev 构建在我们的 RoCE 设备上,我们需要添加/删除其 IP。 这涉及添加与此 ndev 相关的所有 GID、添加默认 GID 等。 (b) inet 事件 - 将新 GID(根据 IP 地址)添加到表中。 为了对端口 RoCE GID 表进行编程,提供商必须实现 add_gid 和 del_gid 回调。 RoCE GID 管理要求我们在 GID 旁边声明关联的 net_device。 为了管理 GID 表,此信息是必需的。 例如,当删除 net_device 时,其关联的 GID 也需要删除。 RoCE 要求根据相关网络设备的 IPv6 本地链路为每个端口生成默认 GID。 与基于常规 IPv6 链路本地的 GID(因为我们为每个 IP 地址生成 GID)相反,当网络设备关闭时,默认 GID 也可用(为了支持环回)。 锁定的完成方式如下:该补丁修改了 GID 表代码,适用于实现 add_gid/del_gid 回调的新 RoCE 驱动程序以及未实现 add_gid/del_gid 回调的当前 RoCE 和 IB 驱动程序。 更新表的流程不同,因此锁定要求也不同。 更新 RoCE GID 表时,通过 mutex_lock(&table->lock) 实现针对多个写入者的保护。 由于写入表需要我们在表中查找一个条目(可能是空闲条目)然后修改它,因此该互斥锁保护 find_gid 和 write_gid 确保操作的原子性。 GID 缓存中的每个条目均受 rwlock 保护。 在 RoCE 中,写入(通常来自 netdev 通知程序的结果)涉及调用供应商的 add_gid 和 del_gid 回调,这些回调可能会休眠。 因此,为每个条目添加无效标志。 RoCE 的更新是通过工作队列完成的,因此允许休眠。 在IB中,更新是在write_lock_irq(&device->cache.lock)中完成的,因此write_gid不允许休眠并且add_gid/del_gid不会被调用。 当将网络设备传入/传出 GID 缓存时,该设备始终被传递为保持 (dev_hold)。 该代码使用单个工作项来更新所有 RDMA 设备,遵循 netdev 或 inet 通知程序。 该补丁将缓存从客户端(这是不正确的,因为缓存是 IB 基础设施的一部分)转变为在设备注册/删除时显式初始化/释放, commit: https://github.com/ssbandjl/linux/commit/03db3a2d81e6e84f3ed3cb9e087cae17d762642b, drivers/infiniband/core/cache.c
gid_cache_wq = alloc_ordered_workqueue("gid-cache-wq", 0) -> 串行
register_inetaddr_notifier(&nb_inetaddr) -> 注册网络地址事件 -> blocking_notifier_chain_register -> 将通知程序添加到阻塞通知程序链 @nh:指向阻塞通知程序链头部的指针 @n:通知程序链中的新条目 将通知程序添加到阻塞通知程序链。 必须在进程上下文中调用。 成功时返回 0,错误时返回 %-EEXIST
notifier_chain_register(&nh->head, n, unique_priority)
trace_notifier_register((void *)n->notifier_call)
register_inet6addr_notifier(&nb_inet6addr)
register_netdevice_notifier(&nb_netdevice) -> 我们依靠 netdevice 通知程序来枚举系统中所有现有的设备。 最后注册到此通知程序以确保我们不会错过任何 IP 添加/删除回调
IPv4网络事件
static struct notifier_block nb_inetaddr = {
.notifier_call = inetaddr_event
};
static struct notifier_block nb_inet6addr = {
.notifier_call = inet6addr_event
};
IPv6网络事件
inetaddr_event
addr_event(struct notifier_block *this, unsigned long event, struct sockaddr *sa, struct net_device *ndev)
case NETDEV_UP:
gid_op = GID_ADD
case NETDEV_DOWN:
gid_op = GID_DEL
INIT_WORK(&work->work, update_gid_event_work_handler)
rdma_ip2gid(sa, &work->gid)
queue_work(gid_cache_wq, &work->work) -> 端口UP/Down时触发事件并更新GID
update_gid_event_work_handler
ib_enum_all_roce_netdevs(is_eth_port_of_netdev_filter, work->gid_attr.ndev, callback_for_addr_gid_device_scan, work) -> callback_for_addr_gid_device_scan
update_gid(parsed->gid_op, device, port, &parsed->gid, &parsed->gid_attr)执行ib_uverbs_init
uverbs
module_init(ib_uverbs_init) -> [PATCH] IB uverbs:核心实现,添加 InfiniBand 用户空间动词实现的核心,包括创建字符设备节点、从用户空间分派请求以及将事件通知传递回用户空间 -> commit: https://github.com/ssbandjl/linux/commit/bc38a6abdd5a50e007d0fcd9b9b6280132b79e62
drivers/infiniband/core/uverbs.h
drivers/infiniband/core/uverbs_cmd.c
drivers/infiniband/core/uverbs_main.c
register_chrdev_region(IB_UVERBS_BASE_DEV, infiniband_verbs
alloc_chrdev_region(&dynamic_uverbs_dev, 0,
class_register(&uverbs_class)
class_create_file(&uverbs_class, &class_attr_abi_version.attr);
ib_register_client(&uverbs_client) -> ib_register_client - 注册 IB 客户端,@client:Client 来注册 IB 驱动程序的上层用户可以使用 ib_register_client() 来注册 IB 设备添加和删除的回调。 当添加 IB 设备时,将调用每个已注册客户端的 add 方法(按照客户端注册的顺序),而当删除设备时,将调用每个客户端的 remove 方法(按照客户端注册的相反顺序)。 此外,当调用 ib_register_client() 时,客户端将收到所有已注册设备的添加回调
init_completion(&client->uses_zero)
assign_client_id(client)
xa_for_each_marked
add_client_context(device, client)
client->add(device) -> ib_uverbs_add_one执行ib_uverbs_add_one
ib_uverbs_add_one -> RDMA:允许 ib_client 在调用 add() 时失败,添加客户端时不允许失败,但所有客户端在其添加例程中都有各种失败路径。 这会产生一种非常边缘的情况:添加客户端后,在添加过程中失败并且未设置 client_data。 然后,核心代码仍然会使用 NULL client_data 调用其他以 client_data 为中心的操作,例如 remove()、rename()、get_nl_info() 和 get_net_dev_by_params() - 这是令人困惑和意外的。 如果 add() 回调失败,则不要再为设备调用任何客户端操作,甚至删除。 删除操作回调中现在对 NULL client_data 的所有冗余检查。 更新所有 add() 回调以正确返回错误代码。 EOPNOTSUPP 用于 ULP 不支持 ib_device 的情况 - 例如,因为它仅适用于 IB
参考: https://www.cnblogs.com/vlhn/p/8301427.html
device_initialize(&uverbs_dev->dev)
init_completion(&uverbs_dev->comp)
uverbs_dev->xrcd_tree = RB_ROOT
INIT_LIST_HEAD(&uverbs_dev->uverbs_file_list) <- list_add_tail(&file->list, &dev->uverbs_file_list) <- ib_uverbs_open
ib_uverbs_create_uapi
uverbs_alloc_api
uapi_merge_def(uapi, ibdev, uverbs_core_api, false)
uapi_merge_obj_tree
uapi_merge_method
case UAPI_DEF_WRITE:
rc = uapi_create_write(uapi, ibdev, def, cur_obj_key, &cur_method_key);
method_elm->handler = def->func_write -> 注册内核态uverbs接口
dev_set_name uverbs/xxx
cdev_init device->ops.mmap ? &uverbs_mmap_fops : &uverbs_fops);
cdev_device_add
ib_set_client_data
xa_store(&device->client_data, client->client_id, data,内核态uverbs接口定义参考如下:
定义内核态供用户态使用的verbs内核接口
drivers/infiniband/core/uverbs_uapi.c
static const struct uapi_definition uverbs_core_api[] = {
UAPI_DEF_CHAIN(uverbs_def_obj_counters),
UAPI_DEF_CHAIN(uverbs_def_obj_cq),
UAPI_DEF_CHAIN(uverbs_def_obj_device),
UAPI_DEF_CHAIN(uverbs_def_obj_dm),
UAPI_DEF_CHAIN(uverbs_def_obj_flow_action),
UAPI_DEF_CHAIN(uverbs_def_obj_intf),
UAPI_DEF_CHAIN(uverbs_def_obj_mr),
UAPI_DEF_CHAIN(uverbs_def_write_intf),
{},
};
rdma user/kernel api/abi:
const struct uapi_definition uverbs_def_write_intf[] = {
...
DECLARE_UVERBS_OBJECT(
UVERBS_OBJECT_PD,
DECLARE_UVERBS_WRITE(
IB_USER_VERBS_CMD_ALLOC_PD,
ib_uverbs_alloc_pd,
UAPI_DEF_WRITE_UDATA_IO(struct ib_uverbs_alloc_pd,
struct ib_uverbs_alloc_pd_resp),
UAPI_DEF_METHOD_NEEDS_FN(alloc_pd)),
DECLARE_UVERBS_WRITE(
IB_USER_VERBS_CMD_DEALLOC_PD,
ib_uverbs_dealloc_pd,
UAPI_DEF_WRITE_I(struct ib_uverbs_dealloc_pd),
UAPI_DEF_METHOD_NEEDS_FN(dealloc_pd))),
...
}
====>
{
.kind = UAPI_DEF_OBJECT_START,
.object_start = { .object_id = UVERBS_OBJECT_PD },
},
{
.kind = UAPI_DEF_WRITE,
.scope = UAPI_SCOPE_OBJECT,
.write = {
.is_ex = 0,
.command_num = IB_USER_VERBS_CMD_ALLOC_PD
},
.func_write = ib_uverbs_alloc_pd, <- method_elm->handler = def->func_write
.write.has_resp = 1 + (sizeof(struct { int:(-!!(offsetof(struct ib_uverbs_alloc_pd, response) != 0)); })) + (sizeof(struct { int:(-!!(sizeof(((struct ib_uverbs_alloc_pd *)0)->response) != sizeof(u64))); })),
.write.req_size = sizeof(struct ib_uverbs_alloc_pd), .write.resp_size = sizeof(struct ib_uverbs_alloc_pd_resp),
.write.has_udata = 1 + (sizeof(struct { int:(-!!(offsetof(struct ib_uverbs_alloc_pd, driver_data) != sizeof(struct ib_uverbs_alloc_pd))); })) + (sizeof(struct { int:(-!!(offsetof(struct ib_uverbs_alloc_pd_resp, driver_data) != sizeof(struct ib_uverbs_alloc_pd_resp))); })),
},
{
.kind = UAPI_DEF_IS_SUPPORTED_DEV_FN,
.scope = UAPI_SCOPE_METHOD,
.needs_fn_offset = offsetof(struct ib_device_ops, alloc_pd) + (sizeof(struct { int:(-!!(sizeof(((struct ib_device_ops *)0)->alloc_pd) != sizeof(void *))); })), },
{
.kind = UAPI_DEF_WRITE,
.scope = UAPI_SCOPE_OBJECT,
.write = {
.is_ex = 0,
.command_num = IB_USER_VERBS_CMD_DEALLOC_PD
},
.func_write = ib_uverbs_dealloc_pd,
.write.req_size = sizeof(struct ib_uverbs_dealloc_pd),
},
{
.kind = UAPI_DEF_IS_SUPPORTED_DEV_FN,
.scope = UAPI_SCOPE_METHOD,
.needs_fn_offset = offsetof(struct ib_device_ops, dealloc_pd) + (sizeof(struct { int:(-!!(sizeof(((struct ib_device_ops *)0)->dealloc_pd) != sizeof(void *))); })),
}继续执行新建连接ops->newlink(ibdev_name, ndev)
static struct rdma_link_ops rxe_link_ops = {
.type = "rxe",
.newlink = rxe_newlink,
};
...
rxe_newlink -> 添加对 RDMA_NLDEV_CMD_NEWLINK/DELLINK 消息的支持,允许动态添加新的 RXE 链接。 暂时弃用旧的模块选项
is_vlan_dev -> RDMA/rxe:防止在 vlan 接口之上创建 rxe,在 vlan 接口之上创建 rxe 设备将创建一个无功能的设备,该设备具有空的 gids 表,并且不能用于 rdma cm 通信。 这是由 enum_all_gids_of_dev_cb()/is_eth_port_of_netdev() 中的逻辑引起的,该逻辑仅考虑连接到已配置网络设备的“上层设备”的网络,导致 vlan 接口的 gid 集为空,并尝试通过此 rdma 连接 由于无法解析 gid,设备在 cm_init_av_for_response 中失败。 显然,实现此行为是为了适应为每个端口创建 RoCE 设备的 HW-RoCE 设备,因此 RXE 的行为必须与 HW-RoCE 设备相同,并且仅为每个真实设备创建 rxe 设备。 为了通过 vlan 接口进行通信,用户必须使用 vlan 地址的 gid 索引,而不是通过 vlan 创建 rxe
rxe_get_dev_from_net
rxe_net_add
ib_alloc_device
rxe_add
rxe_init -> RDMA/rxe:用xarray替换红黑树,当前rxe驱动程序使用红黑树向rxe对象池添加索引。 Linux xarrays 提供了一种更好的方法来实现索引的相同功能。 此补丁将池对象的红黑树替换为 xarray。 由于 xarray 已经有一个自旋锁,请使用它来代替池 rwlock。 确保 xarray(index) 和 kref(ref count) 中的所有更改均以原子方式发生
rxe_init_device_param
rxe->attr.vendor_id = RXE_VENDOR_ID
addrconf_addr_eui48((unsigned char *)&rxe->attr.sys_image_guid -> RDMA/rxe:将 sys_image_guid 设置为与 HW IB 设备对齐,RXE 驱动程序不设置 sys_image_guid,并且用户空间应用程序看到零。 这会导致 pyverbs 测试失败并出现以下回溯,因为 IBTA 规范要求具有有效的 sys_image_guid。 回溯(最近一次调用最后一次):文件“./tests/test_device.py”,第 51 行,在 test_query_device self.verify_device_attr(attr) 文件“./tests/test_device.py”,第 74 行,在 verify_device_attr 中断言 attr.sys_image_guid != 0 为了修复它,请将 sys_image_guid 设置为等于 node_guid
rxe_init_ports -> RDMA/rxe:删除 pkey 表,RoCE 规范要求 RoCE 设备仅支持默认 pkey。 然而,rxe 驱动程序维护一个 64 个实体的 pkey 表,并且仅使用第一个条目。 删除 pkey 表并使用默认 pkey 硬连接长度为 1 的表进行硬编码。 将 pkey_table 的所有检查替换为与 default_pkey 的比较
rxe_init_port_param
port->attr.state = IB_PORT_DOWN
...
rxe_init_pools
rxe_pool_init(rxe, &rxe->uc_pool, RXE_TYPE_UC)
pool->rxe = rxe
pool->elem_size = ALIGN(info->size, RXE_POOL_ALIGN)
xa_init_flags(&pool->xa, XA_FLAGS_ALLOC)
rxe->mcg_tree = RB_ROOT
rxe_set_mtu
eth_mtu_int_to_enum
mtu = mtu ? min_t(enum ib_mtu, mtu, IB_MTU_4096) : IB_MTU_256
rxe_register_device(rxe, ibdev_name)
dev->node_type = RDMA_NODE_IB_CA
ib_set_device_ops(dev, &rxe_dev_ops)
ib_device_set_netdev(&rxe->ib_dev, rxe->ndev, 1)
alloc_port_data
add_ndev_hash
hash_add_rcu(ndev_hash, &pdata->ndev_hash_link,
rxe_icrc_init
crypto_alloc_shash
ib_register_device -> 注册IB设备IB设备注册流程(ib_register_device)
drivers/infiniband/core/device.c -> ib_register_device - 向 IB 核心注册 IB 设备 @device:要注册的设备 @name:唯一的字符串设备名称。 这可能包括“%”,这将导致将唯一索引添加到传递的设备名称中。 @dma_device:指向支持 DMA 的设备的指针。 如果%NULL,则将使用IB 设备。 在这种情况下,调用者应该为 DMA 完全设置 ibdev。 这通常意味着使用 dma_virt_ops。 低级驱动程序使用 ib_register_device() 将其设备注册到 IB 内核。 所有注册的客户端都将收到添加的每个设备的回调。 @device 必须使用 ib_alloc_device() 进行分配。 如果驱动程序使用 ops.dealloc_driver 并异步调用任何 ib_unregister_device() ,则一旦该函数返回,设备指针可能会被释放
int ib_register_device(struct ib_device *device, const char *name, struct device *dma_device) -> roce和IB注册的flow: https://blog.csdn.net/tiantao2012/article/details/77746141
assign_name(device, name) -> DMA/devices:使用 xarray 来存储 client_data,现在我们为每个客户端都有了一个小 ID,我们可以使用 xarray 而不是线性搜索链表来获取客户端数据。 这将提供更快且可扩展的客户端数据查找,并使我们能够修改锁定方案。 由于xarray可以使用标记来存储'going_down',因此完全消除了struct ib_client_data并将client_data值直接存储在xarray中。 然而,这确实需要一个特殊的迭代器,因为我们仍然必须迭代任何 NULL client_data 值。 还消除了 client_data_lock 以支持内部 xarray 锁定
dev_set_name
err = kobject_set_name_vargs(&dev->kobj, fmt, vargs)
__ib_device_get_by_name <- static DEFINE_XARRAY_FLAGS(devices, XA_FLAGS_ALLOC);
xa_for_each (&devices, index, device)
setup_device(device) -> ib_register_device() 执行多个分配和初始化步骤。 将其拆分为更小、更易读的函数,以便于审查和维护 -> setup_device() 分配内存并设置需要调用设备操作的数据,这是在 ib_alloc_device 期间未完成这些操作的唯一原因。 它由 ib_dealloc_device() 撤消
ib_device_check_mandatory -> must option
IB_MANDATORY_FUNC
mandatory_table
IB_MANDATORY_FUNC(query_device),
...
setup_port_data -> RDMA/device:将 ib_device per_port 数据合并到一个位置,没有理由对每个端口数据进行 3 次分配。 将它们组合在一起并使所有每端口数据的生命周期与 struct ib_device 匹配。 后续补丁将需要更多特定于端口的数据,现在有一个好地方可以放置它
alloc_port_data
rdma_end_port
rdma_for_each_port
INIT_LIST_HEAD(&pdata->pkey_list)
INIT_HLIST_NODE(&pdata->ndev_hash_link)
rdma_for_each_port
get_port_immutable -> .get_port_immutable = irdma_roce_port_immutable -> 获取端口信息并固化
ib_query_port -> 校验端口有效性, 是否iwarp -> __ib_query_port
return device->ops.query_port(device, port_num, port_attr) -> or xtrdma_qeury_port
static int irdma_query_port(struct ib_device *ibdev, u32 port,
props->max_mtu = IB_MTU_4096
props->lid = 1;
props->lmc = 0;
props->sm_lid = 0;
props->sm_sl = 0;
props->state = IB_PORT_ACTIVE;
ib_get_eth_speed(ibdev, port, &props->active_speed,
rdma_port_get_link_layer -> IB_LINK_LAYER_ETHERNET
ib_device_get_netdev -> RDMA/device:添加 ib_device_set_netdev() 作为 get_netdev 的替代方案,关联的 netdev 实际上不应该非常动态,因此对于大多数驱动程序来说,没有理由进行这样的回调。 提供一个 API 来通知核心代码有关网络开发从属关系,并使用核心维护的数据结构。 这使得核心代码能够更加了解 ndev 关系,从而允许一些基于此的新 API。 这也使用了某种意义上的锁定,许多驱动程序都有令人困惑的 RCU 锁定,或者缺少不正确的锁定
pdata = &ib_dev->port_data[port]
ib_dev->ops.get_netdev(ib_dev, port) -> mlx5_ib_get_netdev -> IB/mlx5:支持 IB 设备的回调以获取其 netdev,仅适用于 Eth 端口:在 mlx5_ib_device 中维护网络设备指针,如果网络设备和 IB 设备具有相同的 PCI 父设备,则在 NETDEV_REGISTER 和 NETDEV_UNREGISTER 事件时更新它。 实现 get_netdev 回调以返回该网络设备
mdev = mlx5_ib_get_native_port_mdev(ibdev, port_num, NULL)
mlx5_ib_port_link_layer
mlx5_core_mp_enabled
ndev = mlx5_lag_get_roce_netdev(mdev) -> net/mlx5:获取 RoCE netdev,当 LAG 处于活动状态时,IB 驱动程序使用它来确定 IB 绑定设备的 netdev。 如果模式不是主动备份,则返回 PF0 的 netdev;如果模式是主动备份,则返回主动从机的 PF netdev
ldev = mlx5_lag_dev(dev) -> net/mlx5:更改lag的所有权模型,Lag用于将同一HCA的两个PCI功能组合成单个逻辑单元。 这是核心功能,因此应由核心驱动程序管理。 目前情况并非如此。 当我们将滞后软件结构存储在较低设备内时,其生命周期(创建/销毁)由 mlx5e 部分决定。 更改所有权模型,使延迟与较低级别驱动程序的生命周期相关,而不是与 mlx5e 部分相关
ldev && __mlx5_lag_is_roce(ldev)
mlx5_ib_put_native_port_mdev(ibdev, port_num)
mlx5_core_mp_enabled
mpi = ibdev->port[port_num - 1].mp.mpi
rcu_dereference_protected -> rcu_dereference_protected() - 当更新被阻止时获取 RCU 指针 @p:在解除引用之前要读取的指针 @c:发生解除引用的条件 返回指定 RCU 保护指针的值,但省略 READ_ONCE() 。 这在更新端锁阻止指针值更改的情况下很有用。 请注意,此原语不会阻止编译器重复此引用或将其与其他引用组合,因此不应在没有适当锁保护的情况下使用它。 该功能仅供更新端使用。 仅受 rcu_read_lock() 保护时使用此函数将导致罕见但非常难看的失败
__rcu_dereference_protected
如果我们开始通过防止传播取消注册的 netdev 来加快取消注册的速度
__ethtool_get_link_ksettings -> net: ethtool: 添加新的 ETHTOOL_xLINKSETTINGS API,此补丁定义了新的 ETHTOOL_GLINKSETTINGS/SLINKSETTINGS API,由新的 get_link_ksettings/set_link_ksettings 回调处理。 此 API 提供对大多数旧版 ethtool_cmd 字段的支持,添加对更大链接模式掩码(最多 4064 位,可变长度)的支持,并删除 ethtool_cmd 已弃用的字段(transceiver/maxrxpkt/maxtxpkt)。 此 API 弃用了旧版 ETHTOOL_GSET/SSET API,并提供以下向后兼容性属性: - 带有旧版驱动程序的旧版 ethtool:没有变化,仍然使用 get_settings/set_settings 回调。 - 具有新 get/set_link_ksettings 驱动程序的旧版 ethtool:使用新的驱动程序回调,数据在内部转换为旧版 ethtool_cmd。 ETHTOOL_GSET 将仅返回每个链接模式掩码的第一个 32b。 如果用户尝试将 ethtool_cmd 弃用字段设置为非 0(收发器/maxrxpkt/maxtxpkt),ETHTOOL_SSET 将失败。 如果驱动程序设置较高位,则会记录内核警告。 - 未来的 ethtool 与遗留驱动程序:没有变化,仍然使用 get_settings/set_settings 回调,内部转换为新的数据结构。 不推荐使用的字段(transceiver/maxrxpkt/maxtxpkt)将被忽略,并在用户空间中被视为 0。 请注意,“未来”的 ethtool 工具将不允许更改这些已弃用的字段。 - 未来的 ethtool 具有新的驱动程序:直接调用新的回调。 “未来”ethtool 的含义是: - 查询:首先尝试 ETHTOOL_GLINKSETTINGS,如果失败则恢复到 ETHTOOL_GSET - 设置:首先查询并记住 ETHTOOL_GLINKSETTINGS 或 ETHTOOL_GSET 中哪一个成功了 + 如果 ETHTOOL_GLINKSETTINGS 成功,则使用 ETHTOOL_SLINKSETTINGS 更改配置。 失败是最终的(不要尝试 ETHTOOL_SSET)。 + 否则 ETHTOOL_GSET 成功,使用 ETHTOOL_SSET 更改配置。 失败是最终的(不要尝试 ETHTOOL_SLINKSETTINGS)。 通过新 API 的交互用户/内核首先需要进行一次小的 ETHTOOL_GLINKSETTINGS 握手,以就链接模式位图的长度达成一致。 如果内核不同意用户的要求,它将返回用户期望的位图长度作为负长度(并且 cmd 字段为 0)。 当内核和用户同意时,内核返回所有字段中的有效信息(即链接模式长度> 0且cmd为ETHTOOL_GLINKSETTINGS)。 跨越用户/内核边界的数据结构与 32/64 位无关。 在内部转换为合法的内核位图。 当第一个“link_settings”驱动程序开始出现时,内部 __ethtool_get_settings 内核帮助程序将逐渐被 __ethtool_get_link_ksettings 取代。 所以这个补丁并没有改变它,在需要改变之前它就会被删除
dev->ethtool_ops->get_link_ksettings(dev, link_ksettings)
cmd->base.duplex = DUPLEX_FULL;
ib_get_width_and_speed -> 获取/计算RDMA网卡位宽和速度 -> RDMA/core:从netdev获取IB宽度和速度,以前无法查询网卡的通道数(lanes ),因此相同的netdev_speed会得到固定的位宽和速度。 随着网卡规格越来越多样化,这种固定模式已经不再适用,因此需要一种方法来根据通道数获取正确的宽度和速度。 该补丁从 net_device 检索 netdev 通道和速度,并将其转换为 IB 位宽和速度
props->gid_tbl_len = 32;
props->pkey_tbl_len = IRDMA_PKEY_TBL_SZ -> 1
props->max_msg_sz = iwdev->rf->sc_dev.hw_attrs.max_hw_outbound_msg_size
ib_get_cached_subnet_prefix -> IB/core:通过缓存读取ib_query_port中的subnet_prefix。 ib_query_port() 调用 device->ops.query_port() 来获取端口属性。 查询方法是特定于设备驱动程序的。 相同的函数调用device->ops.query_gid()来获取GID并提取subnet_prefix (gid_prefix)。 GID 和subnet_prefix 存储在缓存中。 但如果设备是 Infiniband 设备,则不会从缓存中读取它们。 以下更改利用了缓存的subnet_prefix。 RDBMS 测试表明,此更改使性能有了显着提高
*sn_pfx = device->port_data[port_num].cache.subnet_prefix;
immutable->max_mad_size = IB_MGMT_MAD_SIZE
verify_immutable -> 校验固化的端口数据
rdma_cap_ib_mad -> rdma_cap_ib_mad - 检查设备的端口是否支持 Infiniband 管理数据报。 @device:要检查的设备 @port_num:要检查的端口号 管理数据报 (MAD) 是 InfiniBand 规范的必需部分,并且受所有 InfiniBand 设备支持。 OPA 接口还支持稍微扩展的版本。 返回:如果端口支持发送/接收MAD数据包,则返回true
device->port_data[port_num].immutable.core_cap_flags & RDMA_CORE_CAP_IB_MAD
rdma_max_mad_size -> 返回此 RDMA 端口所需的最大 MAD 大小。 @device:设备 @port_num:端口号 该 MAD 大小包括 MAD 标头和 MAD 负载。 不包含其他标头。 返回端口所需的最大 MAD 大小。 如果端口不支持 MAD,则返回 0
device->port_data[port_num].immutable.max_mad_size
device->ops.query_device(device, &device->attrs, &uhw) -> irdma_query_device
ib_cache_setup_one(device) -> 设置IB(GID)缓存 -> IB/核心:添加 RoCE GID 表管理,RoCE GID 基于与 RDMA (RoCE) 设备端口相关的以太网网络设备上配置的 IP 地址。 目前,每个支持 RoCE(ocrdma、mlx4)的低级驱动程序都管理自己的 RoCE 端口 GID 表。 由于本质上没有任何特定于供应商的内容,因此我们对其进行概括,并增强 RDMA 核心 GID 缓存来完成这项工作。 为了填充 GID 表,我们监听事件: (a) netdev up/down/change_addr 事件 - 如果 netdev 构建在我们的 RoCE 设备上,我们需要添加/删除其 IP。 这涉及添加与此 ndev 相关的所有 GID、添加默认 GID 等。 (b) inet 事件 - 将新 GID(根据 IP 地址)添加到表中。 为了对端口 RoCE GID 表进行编程,提供商必须实现 add_gid 和 del_gid 回调。 RoCE GID 管理要求我们在 GID 旁边声明关联的 net_device。 为了管理 GID 表,此信息是必需的。 例如,当删除 net_device 时,其关联的 GID 也需要删除。 RoCE 要求根据相关网络设备的 IPv6 本地链路为每个端口生成默认 GID。 与基于常规 IPv6 链路本地的 GID(因为我们为每个 IP 地址生成 GID)相反,当网络设备关闭时,默认 GID 也可用(为了支持环回)。 锁定的完成方式如下:该补丁修改了 GID 表代码,适用于实现 add_gid/del_gid 回调的新 RoCE 驱动程序以及未实现 add_gid/del_gid 回调的当前 RoCE 和 IB 驱动程序。 更新表的流程不同,因此锁定要求也不同。 更新 RoCE GID 表时,通过 mutex_lock(&table->lock) 实现针对多个写入者的保护。 由于写入表需要我们在表中查找一个条目(可能是空闲条目)然后修改它,因此该互斥锁保护 find_gid 和 write_gid 确保操作的原子性。 GID 缓存中的每个条目均受 rwlock 保护。 在 RoCE 中,写入(通常来自 netdev 通知程序的结果)涉及调用供应商的 add_gid 和 del_gid 回调,这些回调可能会休眠。 因此,为每个条目添加无效标志。 RoCE 的更新是通过工作队列完成的,因此允许休眠。 在IB中,更新是在write_lock_irq(&device->cache.lock)中完成的,因此write_gid不允许休眠并且add_gid/del_gid不会被调用。 当将网络设备传入/传出 GID 缓存时,该设备始终被传递为保持 (dev_hold)。 该代码使用单个工作项来更新所有 RDMA 设备,遵循 netdev 或 inet 通知程序。 该补丁将缓存从客户端(这是不正确的,因为缓存是 IB 基础设施的一部分)转变为在设备注册/删除时显式初始化/释放
gid_table_setup_one
_gid_table_setup_one
struct ib_gid_table *table
rdma_for_each_port (ib_dev, rdma_port)
table = alloc_gid_table(ib_dev->port_data[rdma_port].immutable.gid_tbl_len)
gid_table_reserve_default(ib_dev, rdma_port, table)
roce_gid_type_mask = roce_gid_type_mask_support(ib_dev, port)
num_default_gids = hweight_long(roce_gid_type_mask) -> 计算1的个数
table->default_gid_indices |= BIT(i)
ib_dev->port_data[rdma_port].cache.gid = table -> init gid table
rdma_roce_rescan_device -> 重新扫描系统中的所有网络设备,并根据需要将其 gid 添加到相关 RoCE 设备 -> {net, IB}/mlx5:管理多端口 RoCE 的端口关联,调用 mlx5_ib_add 时确定要添加的 mlx5 核心设备是否能够进行双端口 RoCE 操作。 如果是,请使用 num_vhca_ports 和affiliate_nic_vport_criteria 功能确定它是主设备还是从设备。 如果该设备是从属设备,请尝试找到与其关联的主设备。 可以关联的设备将共享系统映像 GUID。 如果没有找到,请将其放入非关联端口列表中。 如果找到主设备,则通过在 NIC vport 上下文中配置端口从属关系将端口绑定到它。 同样,当调用 mlx5_ib_remove 时确定端口类型。 如果它是从端口,则将其与主设备取消关联,否则只需将其从非关联端口列表中删除即可。 即使第二个端口不可用于关联,IB 设备也会注册为多端口设备。 当第二个端口稍后附属时,必须刷新 GID 缓存才能获取缓存中第二个端口的默认 GID。 导出roce_rescan_device以提供在绑定新端口后刷新缓存的机制。 在多端口配置中,所有 IB 对象(QP、MR、PD 等)相关命令应流经主站 mlx5_core_dev,其他命令必须发送到从端口 mlx5_core_mdev,提供一个接口来获取非 IB 对象命令的正确 mdev
ib_enum_roce_netdev pass_all_filter enum_all_gids_of_dev_cb
rdma_for_each_port
ib_cache_update -> IB/核心:仅在相应事件上更新 PKEY 和 GID 缓存,HCA 中的 PKEY 和 GID 表都可以保存数百个条目。 阅读它们是昂贵的。 部分原因是用于检索它们的 API 一次仅返回一个条目。 此外,在某些实现上,例如 CX-3,VF 在这方面是半虚拟化的,并且必须依赖 PF 驱动程序来执行读取。 这再次需要 VF 到 PF 的通信。 IB Core 的缓存会根据所有事件进行刷新。 因此,根据收到的事件分别为 IB_EVENT_PKEY_CHANGE 和 IB_EVENT_GID_CHANGE 来过滤 PKEY 和 GID 缓存的刷新
rdma_is_port_valid
ib_query_port(device, port, tprops)
rdma_protocol_roce
config_non_roce_gid_cache(device, port, tprops) -> IB/核心:重构RoCE的GID修改代码,代码被重构为RoCE准备单独的函数,可以执行与引用计数相关的更复杂的操作,同时仍然保持代码的可读性。 这包括 (a) 简化为不执行 IB 链路层的网络设备检查和修改。 (b) 不要添加具有 NULL 网络设备的 RoCE GID 条目; 相反,返回一个错误。 (c) 如果 GID 添加在提供者级别 add_gid() 失败,则不要在缓存中添加该条目并保持该条目标记为 INVALID。 (d) 简化并重用 ib_cache_gid_add()/del() 例程,以便它们甚至可以用于修改默认 GID。 这避免了修改默认 GID 时的一些代码重复。 (e) find_gid() 例程引用数据条目标志来将 GID 限定为有效或无效 GID,而不是依赖于 GID 内容的属性和零。 (f) gid_table_reserve_default() 在设置 GID 表时一开始就设置 GID 默认属性。 无需在 write_gid()、add_gid()、del_gid() 等低级函数中使用 default_gid 标志,因为它们在 GID 表更新期间永远不需要更新 GID 条目的 DEFAULT 属性。 作为此重构的结果,保留的 GID 0:0:0:0:0:0:0:0 不再可搜索,如下所述。 根据 IB 规范版本 1.3 第 4.1.1 节第 (6) 点,单播 GID 条目 0:0:0:0:0:0:0:0 是保留 GID,其片段如下。 “单播 GID 地址 0:0:0:0:0:0:0:0 是保留的 - 称为保留 GID。它不得分配给任何终端端口。它不得用作目标地址或 全局路由标头(GRH)。” GID 表缓存现在仅存储有效的 GID 条目。 在此补丁之前,可以使用 ib_find_cached_gid_by_port() 和其他类似的查找例程在 GID 表中搜索保留 GID 0:0:0:0:0:0:0:0。 零 GID 不再可搜索,因为它不应出现在 GRH 或路径记录条目中,如 IB 规范版本 1.3 第 4.1.1 节第 (6) 点、第 12.7.10 节和第 12.7.20 节中所述。 ib_cache_update() 被简化为检查链路层一次,对所有链路层使用统一的锁定方案,删除临时 gid 表分配/释放逻辑。 此外,(a) 扩展 ib_gid_attr 以存储端口和索引,以便 GID 查询例程可以从属性结构中获取端口和索引信息。 (b) 扩展 ib_gid_attr 来存储设备,以便在将来的代码中,当完成 GID 引用计数时,设备用于返回到 GID 表条目
device->ops.query_gid(device, port, i, &gid_attr.gid)
rdma_protocol_iwarp(device, port)
add_modify_gid(table, &gid_attr)
ib_query_pkey -> Get P_Key table entry
device->ops.query_pkey(device, port_num, index, pkey) -> irdma_query_pkey -> #define IRDMA_DEFAULT_PKEY 0xFFFF
ib_security_cache_change -> IB/核心:在 QP 上强制执行 PKey 安全性,添加新的 LSM 挂钩以分配和释放安全上下文,并检查访问 PKey 的权限。 创建和销毁 QP 时分配和释放安全上下文。 此上下文用于控制对 PKey 的访问。 当请求修改 QP 来更改端口、PKey 索引或备用路径时,请检查 QP 是否具有对该端口子网前缀上的 PKey 表索引中的 PKey 的权限。 如果 QP 是共享的,请确保 QP 的所有句柄也具有访问权限。 存储 QP 正在使用的端口和 PKey 索引。 重置到初始化转换后,用户可以独立修改端口、PKey 索引和备用路径。 因此,端口和 PKey 设置更改可以是先前设置和新设置的合并。 为了在 PKey 表或子网前缀更改时维持访问控制,请保留每个端口上使用每个 PKey 索引的所有 QP 的列表。 如果发生更改,则使用该设备和端口的所有 QP 都必须强制执行新缓存设置的访问权限。 这些更改将事务添加到 QP 修改过程中。 如果修改失败,则必须保持与旧端口和 PKey 索引的关联;如果修改成功,则必须将其删除。 必须在修改之前建立与新端口和 PKey 索引的关联,如果修改失败则将其删除。 1. 当 QP 被修改为特定端口时,PKey 索引或备用路径将该 QP 插入到适当的列表中。 2. 检查访问新设置的权限。 3. 如果步骤 2 授予访问权限,则尝试修改 QP。 4a. 如果步骤 2 和 3 成功,则删除任何先前的关联。 4b. 如果以太失败,请删除新的设置关联。 如果 PKey 表或子网前缀发生更改,则遍历 QP 列表并检查它们是否具有权限。 如果没有,则将 QP 发送到错误状态并引发致命错误事件。 如果它是共享 QP,请确保共享 real_qp 的所有 QP 也具有权限。 如果拥有安全结构的 QP 被拒绝访问,则安全结构将被标记为此类,并且 QP 将被添加到 error_list 中。 一旦将 QP 移至错误完成,安全结构标记就会被清除。 正确维护列表会将 QP 销毁转变为事务。 设备的硬件驱动程序释放 ib_qp 结构,因此当销毁正在进行时,ib_qp_security 结构中的 ib_qp 指针未定义。 当销毁过程开始时,ib_qp_security 结构被标记为正在销毁。 这可以防止对 QP 指针采取任何操作。 QP 成功销毁后,它仍然可以列在 error_list 上,等待该流处理它,然后再清理结构。 如果销毁失败,则 QP 端口和 PKey 设置将重新插入到适当的列表中,销毁标志将被清除,并强制执行访问控制,以防在销毁流程期间发生任何缓存更改。 为了保持安全更改隔离,使用新文件来保存与安全相关的功能
list_for_each_entry (pkey, &device->port_data[port_num].pkey_list,
check_pkey_qps(pkey, device, port_num, subnet_prefix)
ib_get_cached_pkey
enforce_qp_pkey_security
security_ib_pkey_access -> Check if access to an IB pkey is allowed
return call_int_hook(ib_pkey_access, 0, sec, subnet_prefix, pkey) -> selinux_ib_pkey_access
sel_ib_pkey_sid(subnet_prefix, pkey_val, &sid)
avc_has_perm(sec->sid, sid,
qp_to_error(pp->sec)
.qp_state = IB_QPS_ERR
.event = IB_EVENT_QP_FATAL
ib_modify_qp(sec->qp,
sec->qp->event_handler(&event,
list_del(&pp->to_error_list)
complete(&pp->sec->error_complete)
device->groups[0] = &ib_dev_attr_group; -> RDMA/core:通过普通组机制创建设备 hw_counters,而不是调用 device_add_groups() 将组添加到通过 device_add() 管理的现有组数组中。 这需要在 device_add() 之前设置 hw_counters,以便它从已经分割的端口 sysfs 流中分割出来 -> 第一组用于设备属性,第二组用于驱动程序提供的属性(可选)。 第三组是 hw_stats 它是一个以 NULL 结尾的数组
device->groups[1] = device->ops.device_group;
ib_setup_device_attrs
data = alloc_hw_stats_device(ibdev)
ibdev->ops.get_hw_stats
sysfs_attr_init(&attr->attr.attr)
attr->attr.show = hw_stat_device_show
attr->show = show_hw_stats
attr->show = show_stats_lifespan;
attr->attr.store = hw_stat_device_store;
attr->store = set_stats_lifespan;
ib_device_register_rdmacg
rdma_counter_init
dev_set_uevent_suppress
ib_setup_port_attrs
enable_device_and_get
add_client_context
client->add(device) -> .add = ib_uverbs_add_one,
add_compat_devs(device) -> RDMA/core:在net命名空间中实现compat device/sysfs树,实现ib_core的兼容层sysfs条目,以便非init_net net命名空间也可以发现rdma设备。 每个非 init_net 网络命名空间都在其中创建了 ib_core_device。 这样的 ib_core_device sysfs 树类似于 init_net 命名空间中找到的 rdma 设备。 这允许通过 sysfs 条目在多个非 init_net 网络命名空间中发现 rdma 设备,并且对 rdma-core 用户空间很有帮助
add_one_compat_dev
dev_set_uevent_suppress
kobject_uevent(&device->dev.kobj, KOBJ_ADD)
ib_device_put通过扫描设备的回调枚举设备所有的GIDs(根据IP计算GID,并缓存GID)(enum_all_gids_of_dev_cb)
通过扫描设备的回调枚举设备所有的GIDs(根据IP计算GID,并缓存GID)
static void enum_all_gids_of_dev_cb(struct ib_device *ib_dev, u32 port, struct net_device *rdma_ndev,void *cookie)
for_each_net(net) -> 两层for循环
for_each_netdev(net, ndev)
当不处于绑定模式时,过滤并添加主网络设备的默认 GID,或者当处于绑定模式时,添加绑定主设备的默认 GID
is_ndev_for_default_gid_filter
add_default_gids(ib_dev, port, rdma_ndev, ndev) -> ib_cache_gid_set_default_gid
mask = GID_ATTR_FIND_MASK_GID_TYPE | -> IB/core:修复了更改 mac 地址时删除默认 GID 的问题,在 [1] 之前,当网络设备的 MAC 地址更改时,默认 GID 应该被删除并添加回来,这会按以下顺序影响节点和/或端口 GUID。 netdevice_event() -> NETDEV_CHANGEADDR default_del_cmd() del_netdev_default_ips() bond_delete_netdev_default_gids() ib_cache_gid_set_default_gid() ib_cache_gid_del() add_cmd() [..] 但是,在非绑定场景中不会调用 ib_cache_gid_del(),因为 event_ndev 和 rdma_ndev 相同。 因此,修复这种情况,当事件 ndev 和 rdma_dev 相同时忽略检查上层设备; 类似于 bond_set_netdev_default_gids()。 此修复 ib_cache_gid_del() 被正确调用; 但是 ib_cache_gid_del() 找不到要删除的默认 GID,因为 find_gid() 被赋予 default_gid = false 并设置了 GID_ATTR_FIND_MASK_DEFAULT。 但后来它被 ib_cache_gid_set_default_gid() 覆盖,作为 add_cmd() 的一部分。 因此,mac 地址更改通常适用于默认 GID。 通过重构系列 [1],可以检测到这种不正确的行为。 因此,删除默认GID时,请设置default_gid并设置MASK标志。 当删除基于IP的GID时,清除default_gid并设置MASK标志。 [1] https://patchwork.kernel.org/patch/10319151/
for (gid_type = 0; gid_type < IB_GID_TYPE_SIZE; ++gid_type) -> 遍历3种GID类型
if (1UL << gid_type & ~gid_type_mask)
make_default_gid(ndev, &gid)
gid->global.subnet_prefix = cpu_to_be64(0xfe80000000000000LL)
addrconf_ifid_eui48(&gid->raw[8], dev) -> 函数ipv6_generate_eui64最终调用addrconf_ifid_eui48生成地址。将设备的MAC地址dev_addr的前三个字节拷贝到IPv6地址的后半段(s6_addr+8)开始处;在接下来的第4和第5个字节处添加0xFF和0xFE值;拷贝MAC地址的后三个字节到接下来的IPv6地址的第6个字节开始处
__ib_cache_gid_add(ib_dev, port, &gid, &gid_attr, mask, true)
rdma_is_zero_gid(gid) -> IB/core:减少使用 zgid 的地方,而不是开放编码 memcmp() 来检查给定的 GID 是否为零,而是使用辅助函数来执行此操作,并用 memset 替换 memcpy(z,&zgid) 的实例
find_gid(table, gid, attr, default_gid, mask, &empty) -> find gid from cache
add_modify_gid(table, attr)
entry = alloc_gid_entry(attr)
add_roce_gid(entry)
rdma_cap_roce_gid_table
attr->device->ops.add_gid(attr, &entry->context) -> mlx5_ib_add_gid
store_gid_entry(table, entry)
table->data_vec[entry->attr.index] = entry; -> store gid
dispatch_gid_change_event(ib_dev, port)
event.event = IB_EVENT_GID_CHANGE
ib_dispatch_event_clients(&event) -> IB/核心:让 IB 核心分发缓存更新事件 目前,当低级驱动程序通知 Pkey、GID 和端口更改事件时,它们会按照注册的顺序通知给已注册的处理程序。 IB 核心和其他 ULP(例如 IPoIB)对 GID、LID、Pkey 更改事件感兴趣。 由于 ULP 完成的所有 GID 查询均由 IB 核心提供服务,并且 IB 核心将缓存更新推迟到工作队列,因此其他客户端在处理自己的事件时可能会看到过时的缓存数据。 例如,下面的调用树显示了 ipoib 如何在更新 WQ 中的缓存的同时调用 rdma_query_gid()。 mlx5_ib_handle_event() ib_dispatch_event() ib_cache_event()queue_work() -> 缓存更新速度较慢 [..] ipoib_event()queue_work() [..] 工作处理程序 ipoib_ib_dev_flush_light() __ipoib_ib_dev_flush() ipoib_dev_addr_changed_valid() rdma_query_gid() <- 返回旧 GID ,缓存未更新。 将所有事件分派移至工作队列,以便始终在通知任何客户端之前完成缓存更新
list_for_each_entry(handler, &event->device->event_handler_list, list)
handler->handler(handler, event)
is_eth_port_of_netdev_filter
real_dev = rdma_vlan_dev_real_dev(cookie) -> IB/core:删除从 void 到 net_device 的指针转换,此补丁避免了从 void 到 net_device 的不必要的类型转换 -> IB/核心:为 IBoE 添加 VLAN 支持,为 IBoE 添加 802.1q VLAN 支持。 VLAN 标记按以下方式编码在从链路本地地址派生的 GID 中: 当 GID 包含 VLAN 时,GID[11] GID[12] 包含 VLAN ID。 数据包的 3 位用户优先级字段与 SL 的 3 位相同。 对于 rdma_cm 应用程序,TOS 字段用于通过右移 5 位来生成 SL 字段,从而有效地占用 TOS 字段的 3 MS 位 -> commit: https://github.com/ssbandjl/linux/commit/af7bd463761c6abd8ca8d831f9cc0ac19f3b7d4b
is_vlan_dev(dev) ? vlan_dev_real_dev(dev) : NULL
net_device *ret = vlan_dev_priv(dev)->real_dev -> while (is_vlan_dev(ret)) -> 递归拿到vlan设备对应的真实设备
rdma_is_upper_dev_rcu -> IB/core:将 rdma_is_upper_dev_rcu 移至头文件,为了验证路由,我们需要一种简单的方法来检查网络设备是否属于我们的 RDMA 设备。 将此辅助函数移至头文件以使检查更容易
netdev_has_upper_dev_all_rcu -> Check if device is linked to an upper device
netdev_walk_all_upper_dev_rcu(dev, ____netdev_has_upper_dev,
is_eth_active_slave_of_bonding_rcu -> IB/核心:添加RoCE表绑定(bond)支持,处理绑定和其他设备需要我们所有网络设备的GID,这些网络设备是RoCE端口相关网络设备的上层设备。 活动备份配置带来了更多挑战,因为默认 GID 只能在活动设备上设置(这是必要的,否则相同的 MAC 可以用于多个从设备,因此多个从设备将具有相同的 GID)。 管理这些配置是通过监听来完成的: (a) NETDEV_CHANGEUPPER 事件 (1) 如果链接了相关的网络设备,则删除所有不活动的从设备默认 GID 并添加上层设备 GID。 (2) 如果相关网络设备未链接,则删除所有上层GID,并添加默认GID。 (b) NETDEV_BONDING_FAILOVER: (1) 从非活动从站删除绑定 GID (2) 删除非活动从站的默认 GID (3) 将绑定 GID 添加到活动从站 -> struct bonding
netif_is_bond_master(upper)
bond_option_active_slave_get_rcu
rcu_dereference_rtnl(bond->curr_active_slave)
bond_uses_primary(bond)
_add_netdev_ips(ib_dev, port, ndev)
enum_netdev_ipv4_ips(ib_dev, port, ndev) -> 枚举IPv4设备的IP地址
__in_dev_get_rcu
list_add_tail(&entry->list, &sin_list)
update_gid_ip(GID_ADD, ib_dev, port, ndev, (struct sockaddr *)&sin_iter->ip);
rdma_ip2gid(addr, &gid) -> IP地址到GID的转换算法 -> IB/core:verbs/cm 结构中的以太网 L2 属性,此补丁添加了对 verbs/cm/cma 结构中的以太网 L2 属性的支持。 在处理 L2 以太网时,我们应该以与使用 IB L2(和 L4 PKEY)属性类似的方式使用 smac、dmac、vlan ID 和优先级。 因此,这些属性被添加到以下结构中: * ib_ah_attr - 添加了 dmac * ib_qp_attr - 添加了 smac 和 vlan_id,(sl 保留 vlan 优先级) * ib_wc - 添加了 smac、vlan_id * ib_sa_path_rec - 添加了 smac、dmac、vlan_id * cm_av - 添加了 smac 和 vlan_id 对于路径记录结构,在将其打包为有线格式时特别注意避免新字段,因此我们不会破坏 IB CM 和 SA 有线协议。 在主动侧,CM 被填充。 其内部结构来自 ULP 提供的路径。 我们添加了 ETH L2 属性并将它们放入 CM 地址句柄(struct cm_av)中。 在被动侧,CM 从与 REQ 消息关联的 WC 中填充其内部结构。 我们添加了从 WC 获取 ETH L2 属性的内容。 当硬件驱动程序在 WC 中提供所需的 ETH L2 属性时,它们会设置 IB_WC_WITH_SMAC 和 IB_WC_WITH_VLAN 标志。 IB 核心代码检查这些标志是否存在,如果没有,则从 ib_init_ah_from_wc() 辅助函数进行地址解析。 ib_modify_qp_is_ok 也被更新以考虑链路层。 有些参数对于以太网链路层是必需的,而对于IB来说则无关。 修改供应商驱动程序以支持新的函数签名
case AF_INET: -> ipv4
ipv6_addr_set_v4mapped(((struct sockaddr_in *)addr)->sin_addr.s_addr, (struct in6_addr *)gid)
ipv6_addr_set(v4mapped, 0, 0, htonl(0x0000FFFF), addr)
__ipv6_addr_set_half(&addr->s6_addr32[0], w1, w2)
__ipv6_addr_set_half(&addr->s6_addr32[2], w3, w4)
case AF_INET6:
*(struct in6_addr *)&gid->raw = ((struct sockaddr_in6 *)addr)->sin6_addr
update_gid(gid_op, ib_dev, port, &gid, &gid_attr)
unsigned long gid_type_mask = roce_gid_type_mask_support(ib_dev, port) -> IB/core:将gid_type添加到gid属性中,为了支持多种GID类型,我们需要存储每个GID的gid_type。 这也与 RoCE v2 附件“RoCEv2 端口 GID 表条目应具有表示 L3 地址类型的“GID 类型”属性”保持一致。 当前支持的 GID 是 IB_GID_TYPE_IB,这也是 RoCE v1 GID 类型。 这意味着 gid_type 应添加到 roce_gid_table 元数据中
ib_cache_gid_add(ib_dev, port, gid, gid_attr) -> .is_supported = &mlx5_rdma_supported,
__ib_cache_gid_add
or ib_cache_gid_del(ib_dev, port, gid, gid_attr) -> _ib_cache_gid_del
find_gid
del_gid(ib_dev, port, table, ix) -> del_gid
mlx5r_del_gid_macsec_operations -> del flow
dispatch_gid_change_event(ib_dev, port)
enum_netdev_ipv6_ips(ib_dev, port, ndev)
in6_dev = in6_dev_get(ndev)
list_add_tail(&entry->list, &sin6_list)
rdma_ip2gid((struct sockaddr *)&sin6_iter->sin6, &gid)
update_gid(GID_ADD, ib_dev, port, &gid, &gid_attr)
ucma_copy_iboe_route struct rdma_route -> RDMA/cma:多路径记录支持 netlink 通道,支持通过 RDMA netlink 通道从用户空间服务接收入站和出站 IB 路径记录(以及 GMP PathRecord)。 这3个PR中的LID可以这样使用: 1. GMP PR:用作标准本地/远程LID; 2、出站PR的DLID:用作出站流量的“dlid”字段; 3.入站PR的DLID:用作响应方出站流量的“dlid”字段。 这样做的目的是支持自适应路由。 使用当前的 IB 路由解决方案,当数据包发出时,每个目标都会被分配一个固定的 DLID,这意味着将使用固定的路由器。 入站/出站路径记录中的 LID 可用于识别允许与另一个子网实体进行通信的路由器组。 通过它们,来自子网间连接的数据包可以通过该组中的任何路由器到达目标。 正如 Jason 所确认的,当发送 netlink 请求时,内核使用 LS_RESOLVE_PATH_USE_ALL 以便服务知道内核支持多个 PR
IB:地址转换以将 IP 映射到 IB 地址 (GID),添加地址转换服务,使用 IPoIB 将 IP 地址映射到 InfiniBand GID 地址
/**
* struct rdma_dev_addr - Contains resolved RDMA hardware addresses
* @src_dev_addr: Source MAC address.
* @dst_dev_addr: Destination MAC address.
* @broadcast: Broadcast address of the device.
* @dev_type: The interface hardware type of the device.
* @bound_dev_if: An optional device interface index.
* @transport: The transport type used.
* @net: Network namespace containing the bound_dev_if net_dev.
* @sgid_attr: GID attribute to use for identified SGID
*/
struct rdma_dev_addr {
unsigned char src_dev_addr[MAX_ADDR_LEN]; -> 源MAC(SMAC)
unsigned char dst_dev_addr[MAX_ADDR_LEN]; -> 目的MAC(DMAC)
unsigned char broadcast[MAX_ADDR_LEN];
unsigned short dev_type;
int bound_dev_if;
enum rdma_transport_type transport;
struct net *net;
const struct ib_gid_attr *sgid_attr;
enum rdma_network_type network;
int hoplimit;
};地址解析(addr_resolve)
addr_resolve
rdma_set_src_addr_rcu
...
rdma_translate_ip -> Translate a local IP address to an RDMA hardware
dev = dev_get_by_index(dev_addr->net, dev_addr->bound_dev_if) -> IB/addr:将网络命名空间作为参数传递,为ib_addr模块添加网络命名空间支持。 为此,所有地址解析和匹配都应该使用适当的命名空间而不是 init_net 来完成。 这是通过以下方式实现的: 1. 将显式网络命名空间参数添加到需要命名空间的导出函数。 2. 将命名空间保存在 rdma_addr_client 结构中。 3. 调用网络功能时使用。 为了保留调用模块的行为,&init_net 在其他模块的调用中作为参数传递。 随着在更多级别上添加命名空间支持,此内容已被修改 -> Deprecated for new users, call netdev_get_by_index() instead -> netdev_get_by_index() - 通过 ifindex 查找设备, @net:适用的网络命名空间 @ifindex:设备索引 @tracker:获取引用的跟踪对象 @gfp:跟踪器的分配标志 按索引搜索接口。 如果未找到设备或指向设备的指针,则返回 NULL。 返回的设备已添加了引用,并且指针是安全的,直到用户调用 netdev_put() 表明他们已完成使用它
dev_get_by_index_rcu(net, ifindex)
hlist_for_each_entry_rcu(dev, head, index_hlist)
rdma_copy_src_l2_addr(dev_addr, dev)
memcpy(dev_addr->broadcast, dev->broadcast, MAX_ADDR_LEN)
dev = rdma_find_ndev_for_src_ip_rcu(dev_addr->net, addr)
switch (src_in->sa_family)
case AF_INET:
__ip_dev_find
ifa = inet_lookup_ifaddr_rcu(net, addr)
u32 hash = inet_addr_hash(net, addr)
net_eq(dev_net(ifa->ifa_dev->dev), net)
local = fib_get_table(net, RT_TABLE_LOCAL)
fib_table_lookup
trace_fib_table_lookup
case AF_INET6:
ipv6_chk_addr -> ipv6_chk_addr_and_flags -> VRF 设备与 ip 规则相结合,提供了在 Linux 网络堆栈中创建虚拟路由和转发域(又名 VRF,具体为 VRF-lite)的能力。 一种用例是多租户问题,其中每个租户都有自己独特的路由表,并且至少需要不同的默认网关。 通过将套接字绑定到 VRF 设备,进程可以“感知 VRF”。 然后,通过套接字的数据包使用与 VRF 设备关联的路由表。 VRF 设备实现的一个重要特征是它仅影响第 3 层及以上层,因此 L2 工具(例如 LLDP)不受影响(即它们不需要在每个 VRF 中运行)。 该设计还允许使用更高优先级的 IP 规则(基于策略的路由,PBR),以优先于根据需要引导特定流量的 VRF 设备规则。 此外,VRF 设备允许 VRF 嵌套在命名空间内。 例如,网络命名空间提供设备层网络接口的分离,命名空间内接口上的 VLAN 提供 L2 分离,然后 VRF 设备提供 L3 分离。 设计 VRF 设备是通过关联的路由表创建的。 然后网络接口被从属于 VRF 设备:-> net/ipv6:更改地址检查以始终采用设备参数,ipv6_chk_addr_and_flags 确定地址是否是本地地址,以及(可选)是否是特定设备上的地址。 例如,由 ip6_route_info_create 调用它来确定给定的网关地址是否是本地地址。 地址检查当前不考虑 L3 域,因此如果下一跳指向第二个 VRF 中的地址,则不允许在一个 VRF 中添加路由。 例如,$ ip route add 2001:db8:1::/64 vrf r2 via 2001:db8:102::23 错误:网关地址无效。 其中 2001:db8:102::23 是 vrf r1 中接口上的地址。 ipv6_chk_addr_and_flags 需要允许调用者始终传入带有单独参数的设备,以免将地址限制为特定设备。 该设备用于确定感兴趣的 L3 域。 为此,添加一个参数以跳过设备检查并更新调用者以始终在可能的情况下传递设备,并使用新参数来表示域中的任何地址。 使用 NULL dev 参数更新 ipv6_chk_addr 的少数用户。 此补丁处理对这些调用者的更改,而无需添加域检查。 ip6_validate_gw 需要处理 2 种情况 - 一种是设备作为下一跳规范的一部分给出,另一种是设备被解析。 至少有 1 种 VRF 情况,将检查推迟到仅在路由查找解决之后,设备会失败并出现不直观的错误“RTNETLINK 答案:没有到主机的路由”,而不是首选的“错误:网关不能是本地地址” ”。 “没有到主机的路由”错误是由于回退到完整查找而导致的。 检查两次以避免此错误
inet6_addr_hash
l3mdev_master_dev_rcu
ipv6_addr_equal参考
iproute2: https://github.com/ssbandjl/iproute2.git, https://github.com/ssbandjl/MLNX_OFED_SRC-5.9-0.5.6.0/tree/main/SOURCES/mlnx-iproute2-6.0.0
Linux符号表/加载模块/驱动的符号表: https://sysprogs.com/VisualKernel/documentation/kernelsymbols/
加载Linux模块/模块加载流程: https://www.cnblogs.com/sky-heaven/p/13280255.html, https://www.cnblogs.com/aspirs/p/15522142.html
晓兵(ssbandjl)
博客: https://cloud.tencent.com/developer/user/5060293/articles | https://logread.cn | https://blog.csdn.net/ssbandjl | https://www.zhihu.com/people/ssbandjl/posts
DPU专栏
https://cloud.tencent.com/developer/column/101987
技术会友: 欢迎对DPU/智能网卡/卸载/网络,存储加速/安全隔离等技术感兴趣的朋友加入DPU技术交流群
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
