图解SQL查询处理的各个阶段

通知:《SQL每日一题》系列不再更新,有需要刷题的小伙伴可以查看历史文章。
大家好,我是李岳。
今天给大家介绍一下SQL查询处理的各个阶段,便于大家理解SQL的执行过程。
执行顺序
我们先用数字+关键字的方式标注一下每个关键字的处理步骤。
(5)SELECT (5-2) DISTINCT (5-3) TOP(<top-specification>) (5-1) <select_list>
(1) FROM (1-J)<left_table><join_type> JOIN <right_table> ON <on_predicate>
|(1-A)<left_table><apply_type> APPLY <right_table_expression> AS <alias>
|(1-P)<left_table> PIVOT (<pivot_specification>) AS <alias>
|(1-U)<left_table> UNPIVOT (<unpivot_specification>) AS <alias>
(2) WHERE <where_predicate>
(3) GROUP BY <group_by_specification>
(4) HAVING <having_predicate>
(6) ORDER BY (order_by_list);(提示:可左右滑动代码)
其中数字代表后面的关键字的执行顺序。
SQL与其它编程语言不同的最明显特征就是代码的执行顺序,在大多数编程语言中,代码是按照编写顺序来执行的,但在SQL中,第一个要执行的子句是FROM子句,尽管SELECT 语句第一个出现,但是几乎总是放在最后执行。
上述的执行序号每一个都会生成一个虚表,生成的虚表会作为下一步的输入来使用。这些生成的虚表对SQL发起者(客户端应用程序或者外部查询)是不可用的,只有最后一步生成的虚表才会返回给SQL发起者。如果在查询中没有指定某一个子句,就会跳过相应的步骤。
为方便大家理解,我们将每步的执行过程以图形的方式呈现给大家。
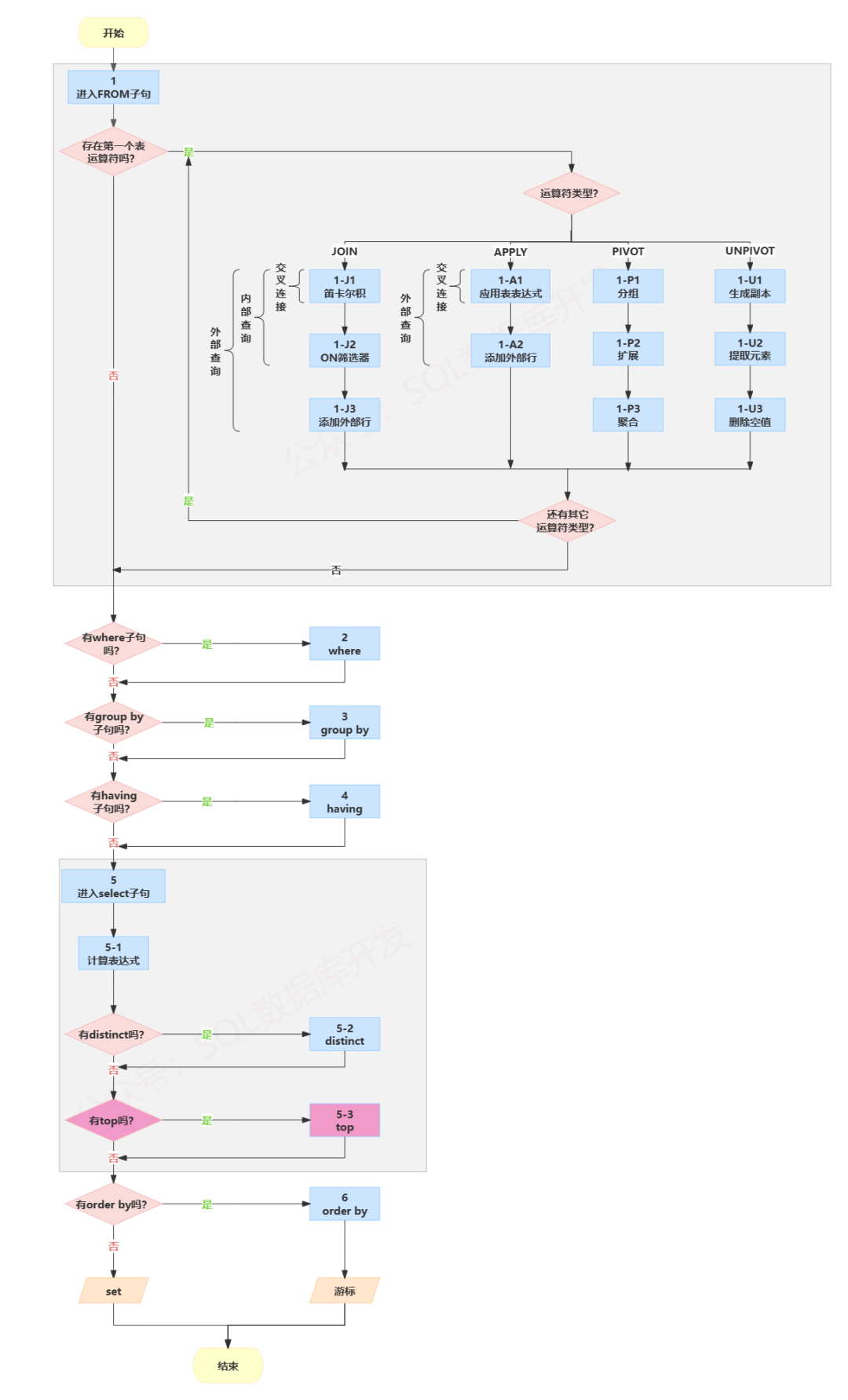
(提示:点击图片可以查看高清大图)
执行顺序解释
相信大部分人对这些步骤不太理解,我们按顺序对上面的步骤做个解读。
(1)FROM
FROM 阶段主要标明查询语句的来源表,如果是单表就表示不存在表运算符会直接跳转到WHERE子句;
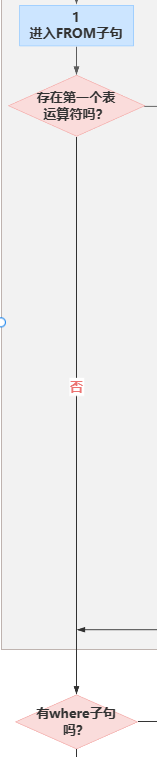
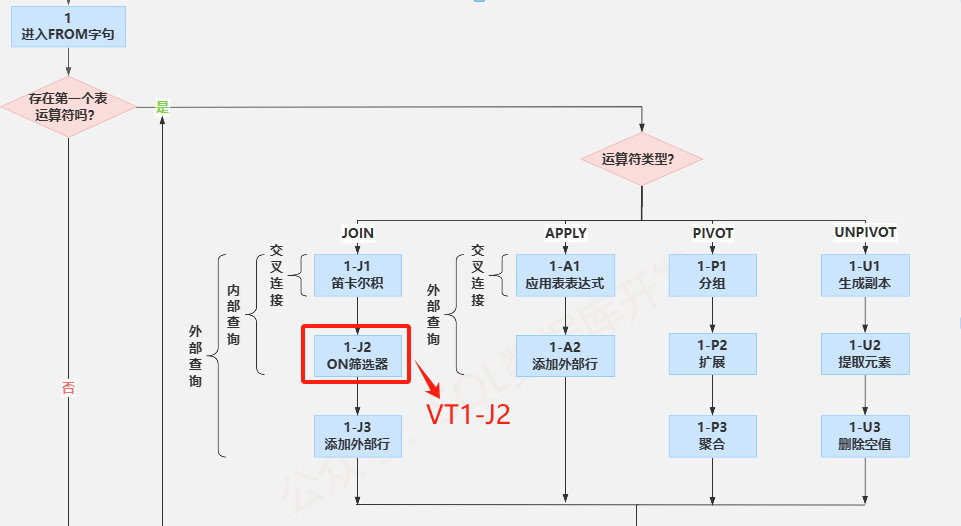
如果存在表运算符,则会根据每个表运算符执行一些列的子阶段,例如,在连接运算汇总涉及的阶段有(1-J1)笛卡尔积、(1-J2) ON 筛选器和(1-J3) 添加外部行。这个阶段FROM会生成虚表VT1。
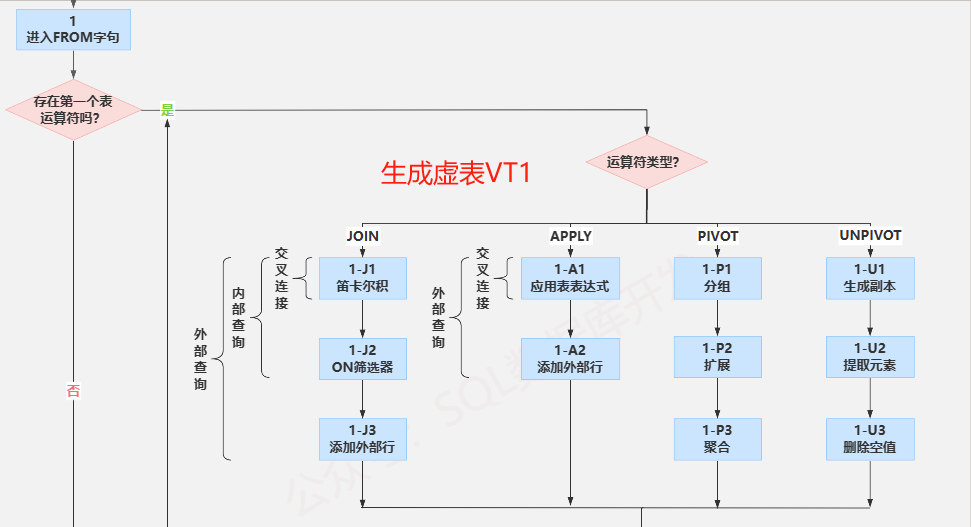
(1-J1)笛卡尔积
这个阶段对表运算符涉及的两个表执行笛卡尔积(cross join),会生成虚表VT1-J1。
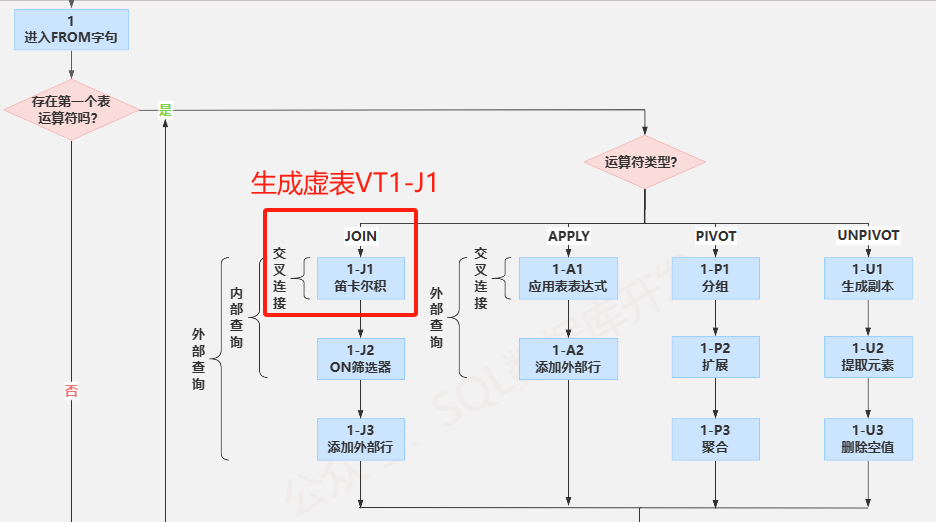
(1-J2)ON 筛选器
这个阶段会对VT1-J1中生成的数据行根据ON字句(<on_predicate>)中出现的条件进行筛选,只有当满足这些筛选条件的数据行,才会插入VT1-J2中。
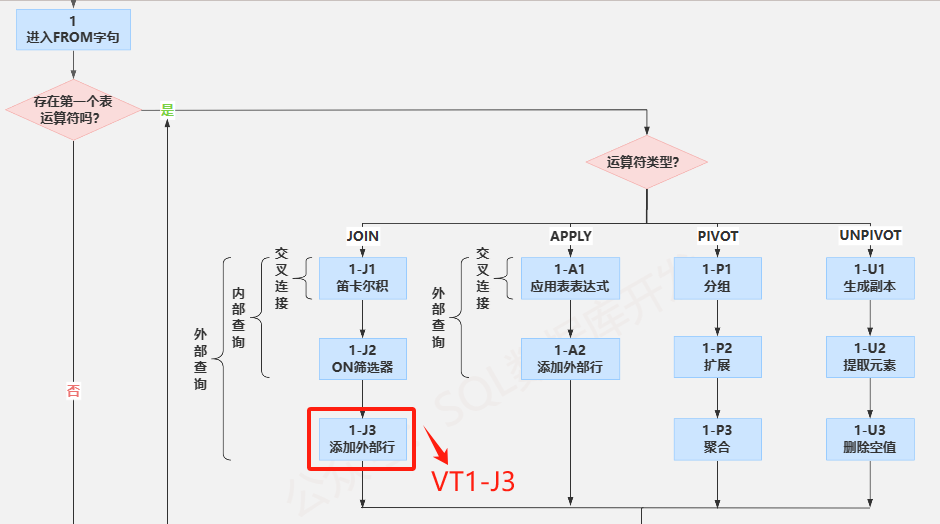
(1-J3)添加外部行
如果指定了OUTER JOIN(通常指LEFT JOIN 和RIGHT JOIN),则会将主表(如果是LEFT JOIN主表就是左表,如果是RIGHT JOIN主表就是右表)中没有匹配上的行,作为外部行添加到VT1-J2中,生成VT1-J3。
注:这一部分我会在后续的章节中给大家详细讲解外部行的添加过程
其它的运算符APPLY,PIVOT和UNPIVOT的处理过程与JOIN类似,我们就不再一一演示
通过上述各个子阶段的执行,最终生成虚表VT1.
(2)WHERE
在WHERE这个阶段,会对VT1中的数据行进行条件筛选,同样是只有满足WHERE子句的数据行,才会被插入到虚表VT2中。

(3)GROUP BY
在GROUP BY阶段,按照GROUP BY子句中指定的列名,将VT2中的行进行分组,生成VT3,最终每个分组只有几个结果行。

(4)HAVING
在HAVING阶段,根据HAVING子句中出现的条件(通常是聚合函数条件,如果sum(),count(),min(),max()等)对VT3中的分组进行筛选,只有满足HAVING子句的条件的数据行,才会被插入到VT4中。

(5)SELECT
处理SELECT子句中的元素,产生VT5,如果SELECT后面没有DISTINCT或TOP则直接跳转到ORDER BY子句
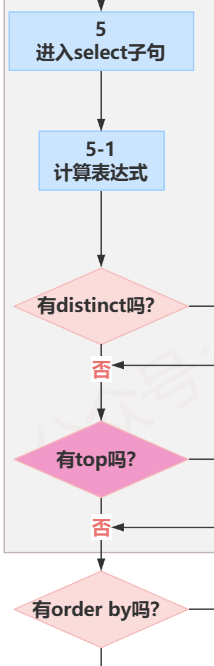
如果有DISTINCT或TOP子句则与FROM类似,需要执行一系列的子阶段
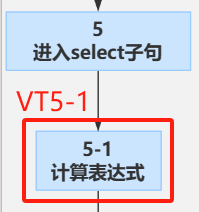
(5-1)计算表达式
计算SELECT列表中的表达式,通常是做一些列运算,如列之间简单的加减乘除或列拼接等(聚合函数运算也属于列的加减乘除),这阶段会生成虚表VT5-1
(5-2)DISTINCT
这个子阶段会删除VT5-1中的重复行,生成虚表VT5-2

(5-3)TOP
这里需要注意,TOP执行阶段会根据ORDER BY子句定义的逻辑顺序,从VT5-2中选择前面指定数量或百分比的数据行,生成VT5-3。

换言之实际上是有一个排序ORDER BY的过程在TOP前面,但是这个排序的过程我们通常是指发生在子查询中阶段。例如
SELECT * FROM
(
SELECT TOP 10 userid,username
FROM tablename
ORDER BY userid
) t
ORDER BY t.username这里的子查询t表里的TOP 1是在对userid先排序后再取前10条记录,而如果没有这个子查询,TOP直接在最外层,那么首先执行的应该是ORDER BY,而不是TOP,这里大家需要特别注意。
SELECT TOP 10 userid,username
FROM tablename
ORDER BY userid(6) ORDER BY
根据ORDER BY子句中指定的列名,对VT5(VT5-3)中的行进行排序,生成游标VT6
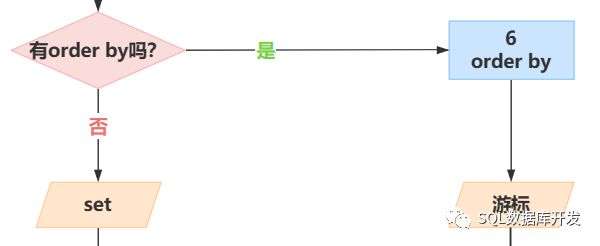
至此,整个SQL查询过程执行结束,最终返回VT6的结果给SQL发起者。