基于聆思开发套件实现读取图片中的信息
原创
1. 开发环境介绍
- 聆思开发套件
- Miniconda
- Python:3.11
- Django
- Docker
- 智谱AI大模型
- PyCharm
- Git
- 云服务器
2. 后端开发环境搭建
我们这里使用Django来作为web服务,主要是为了后期功能扩展做准备
1.创建虚拟环境
conda create -n LS_AI python=3.11 -y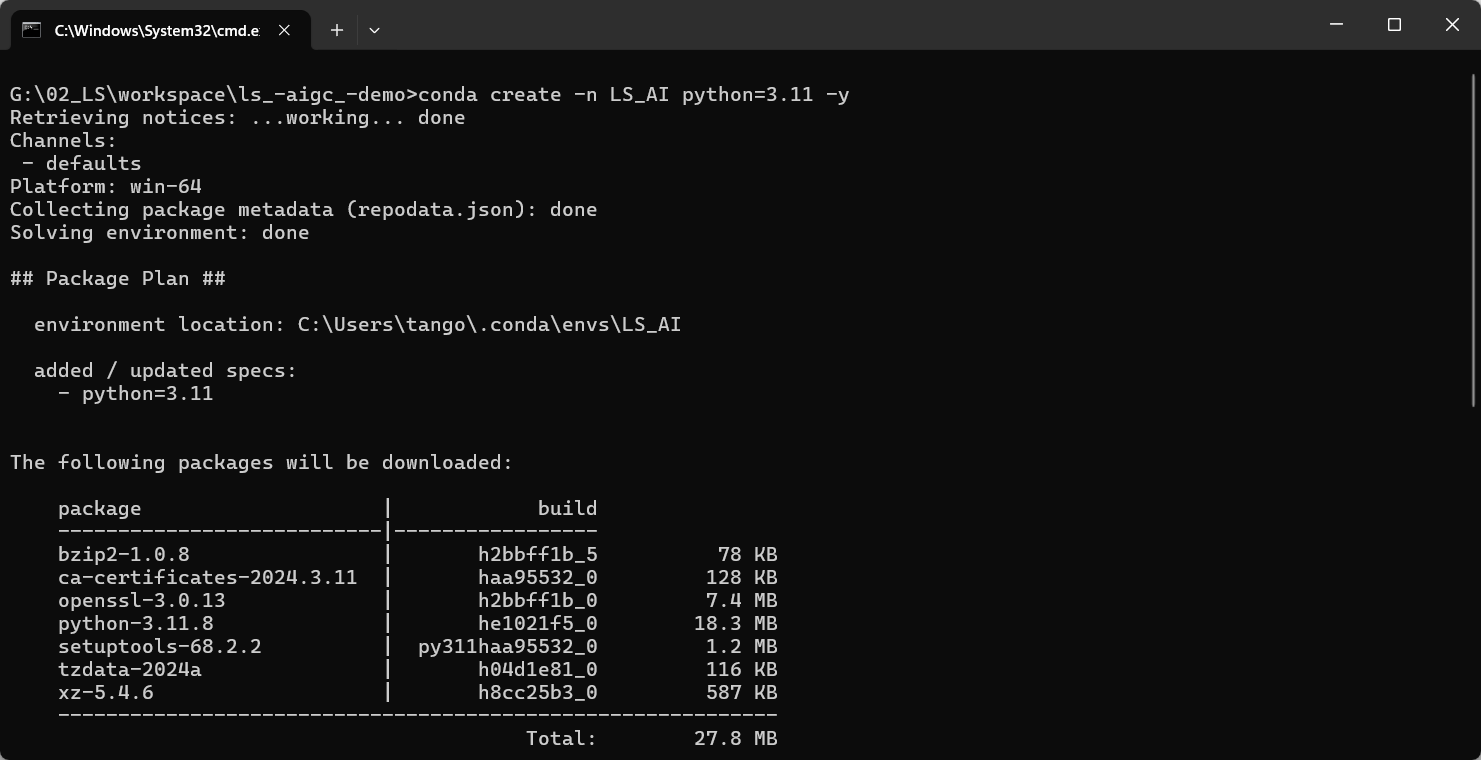
激活虚拟环境
activate LS_AI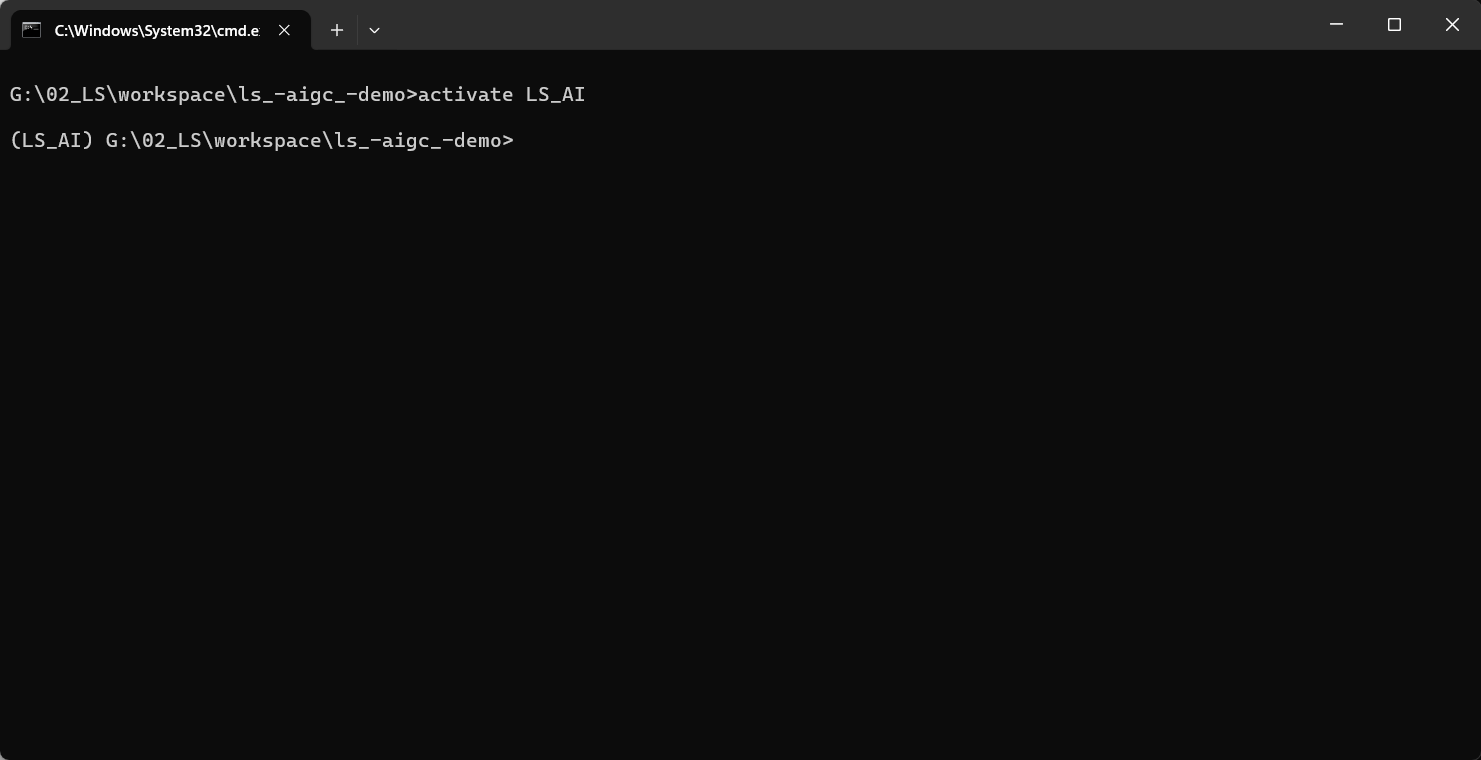
2. 配置Django
pip install django -i https://mirrors.aliyun.com/pypi/simple/创建Django项目
django-admin startproject config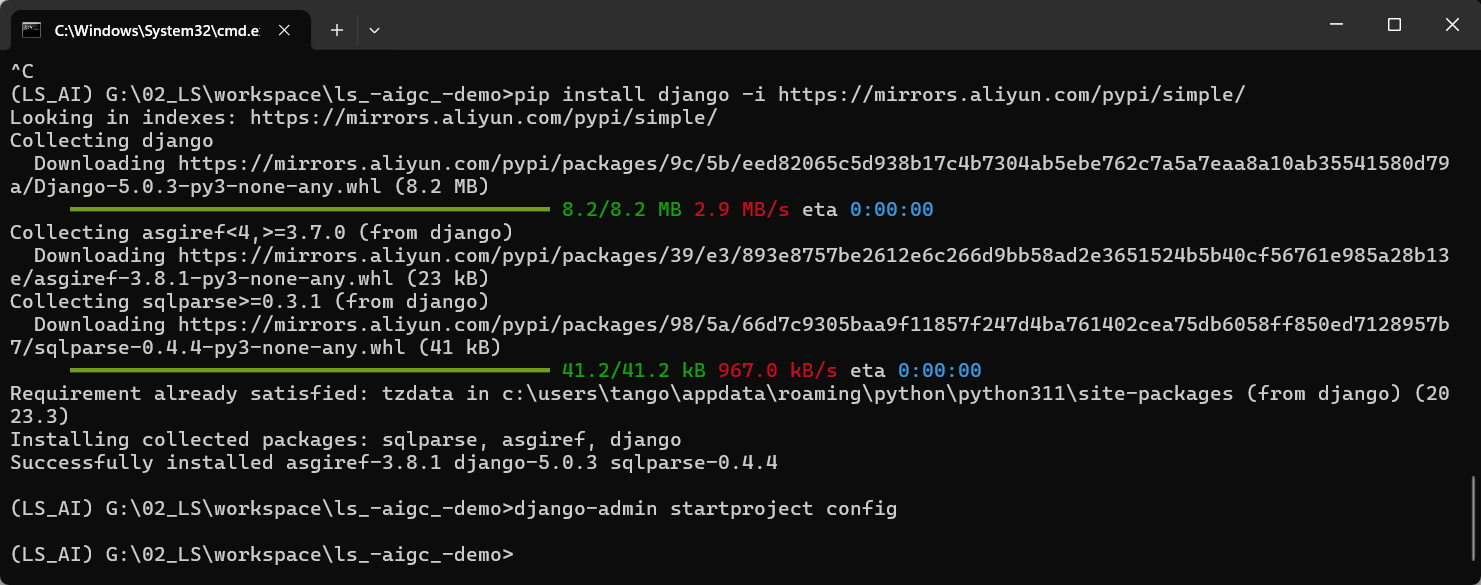
创建APP
cd config
python manage.py startapp LS_AI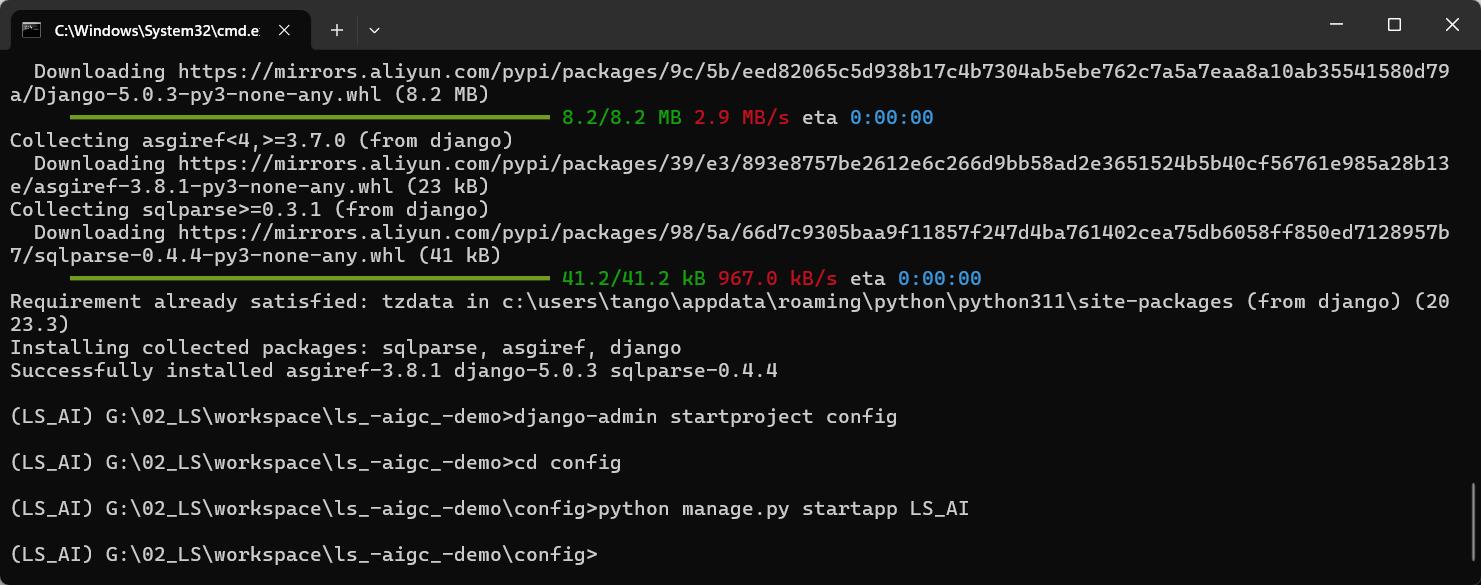
3. 后端获取图片接口开发
我们这里使用PyCharm打开上面创建好的项目
这里的项目名称暂时叫config,等我们全部完成时再修改即可。
修改Django的配置文件
ALLOWED_HOSTS = ["*"]
pass
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'LS_AI'
]
1. 业务逻辑介绍
- 我们在后台通过URL的形式,保存一些网上的图片,可以时自己图床中的,也可以是网上的。
- 我们希望通过语音交互,拿到最新的一个图片,并通过智谱的能力识别出图片中的内容
- 让聆思套件告诉我们结果
2. 功能开发
我们创建一张表表,只需要保存url,创建日期即可
from django.db import models
# Create your models here.
class ImageInfo(models.Model):
image_url = models.URLField(max_length=200, verbose_name='图片地址')
create_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
class Meta:
verbose_name = '图片信息'
verbose_name_plural = verbose_name
def __str__(self):
return self.image_url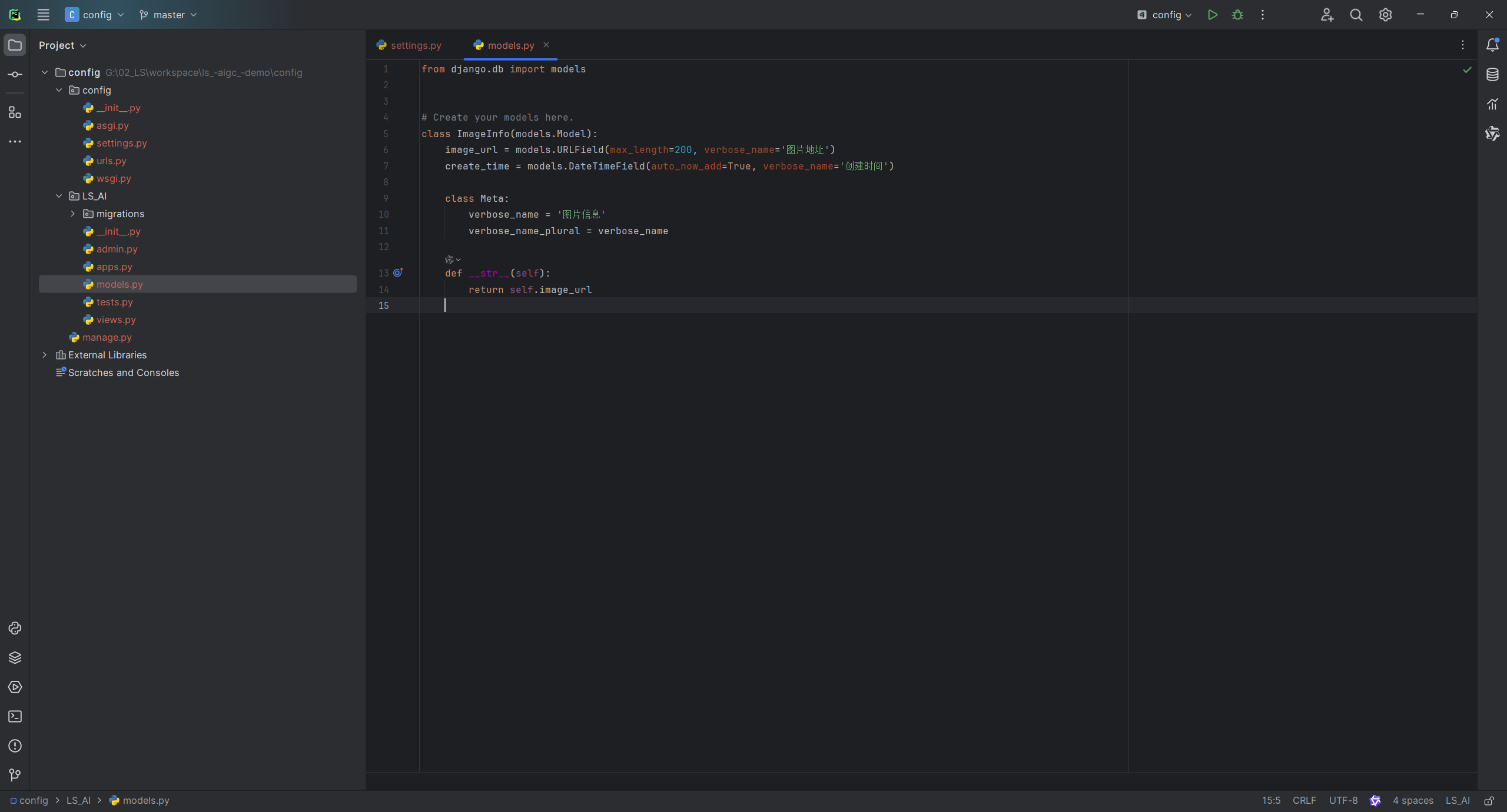
接下来我们需要一个方法来查找最新的图片地址
import json
from django.http import HttpResponse
from .models import ImageInfo
# Create your views here.
def get_latest_image(request):
# 获取最新的图片
image_list = ImageInfo.objects.all().order_by('-id')
info = {
"img_url": image_list[0].image_url
}
return HttpResponse(json.dumps(info), content_type='application/json')业务写好后,我们配置一下路由
from django.contrib import admin
from django.urls import path
from LS_AI.views import get_latest_image
urlpatterns = [
path('admin/', admin.site.urls),
path('get_latest_image/', get_latest_image),
]将我们的model添加到后台界面
from django.contrib import admin
# Register your models here.
from .models import ImageInfo
@admin.register(ImageInfo)
class ImageInfoAdmin(admin.ModelAdmin):
list_display = ('id', 'image_url', 'create_time')
list_display_links = ('id', 'image_url')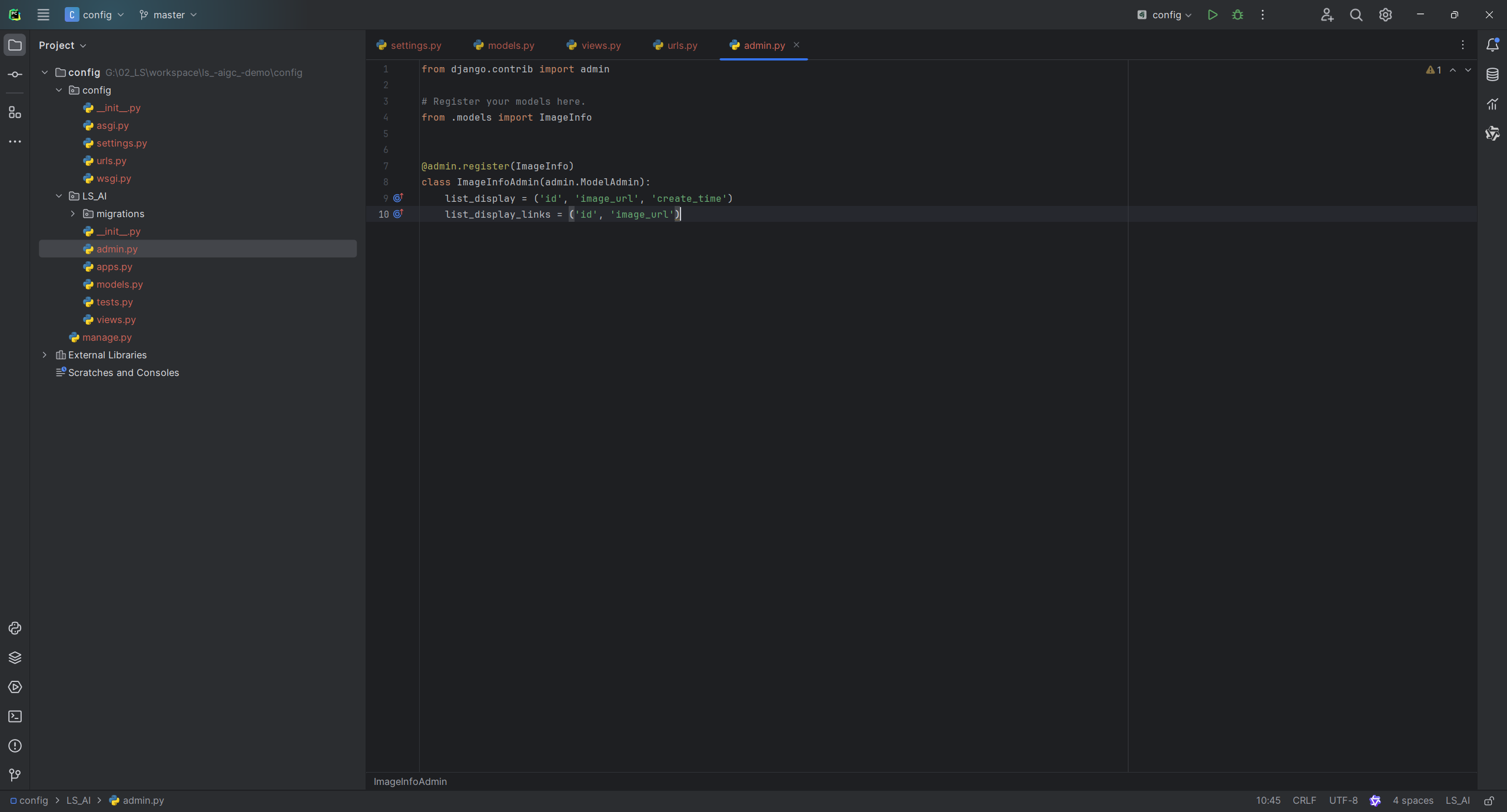
同步数据
python manage.py makemigrations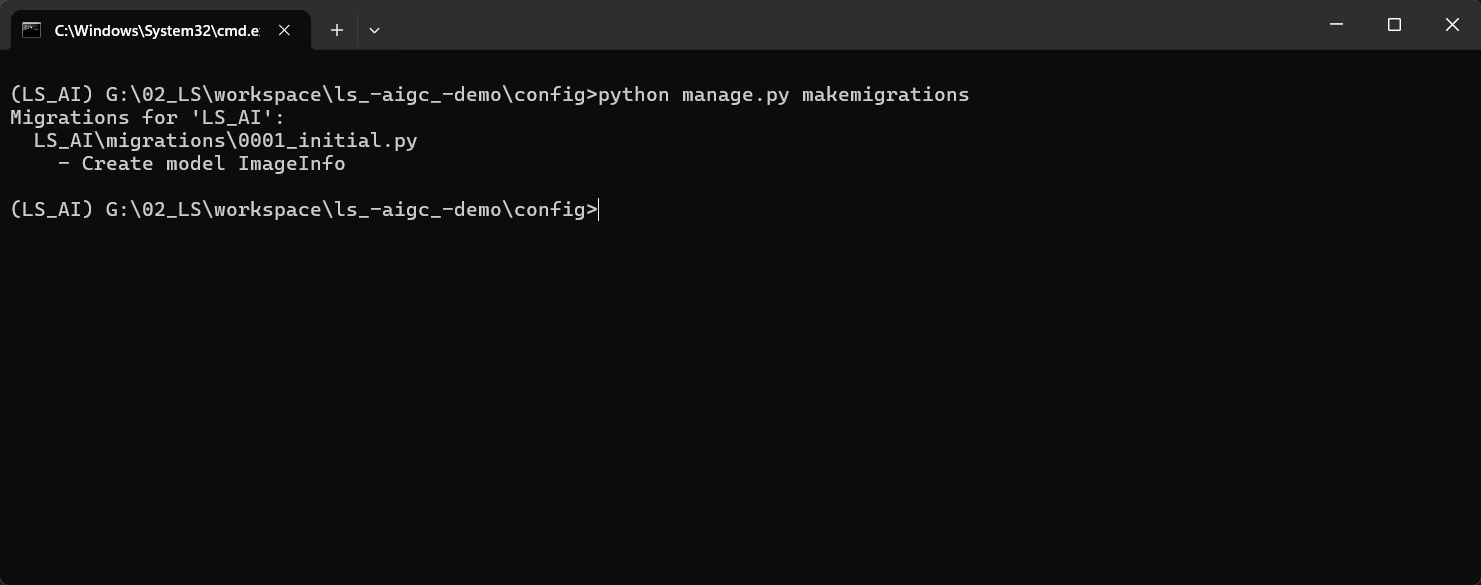
python manage.py migrate创建超级管理员并启动项目进行测试
python manage.py createsuperuser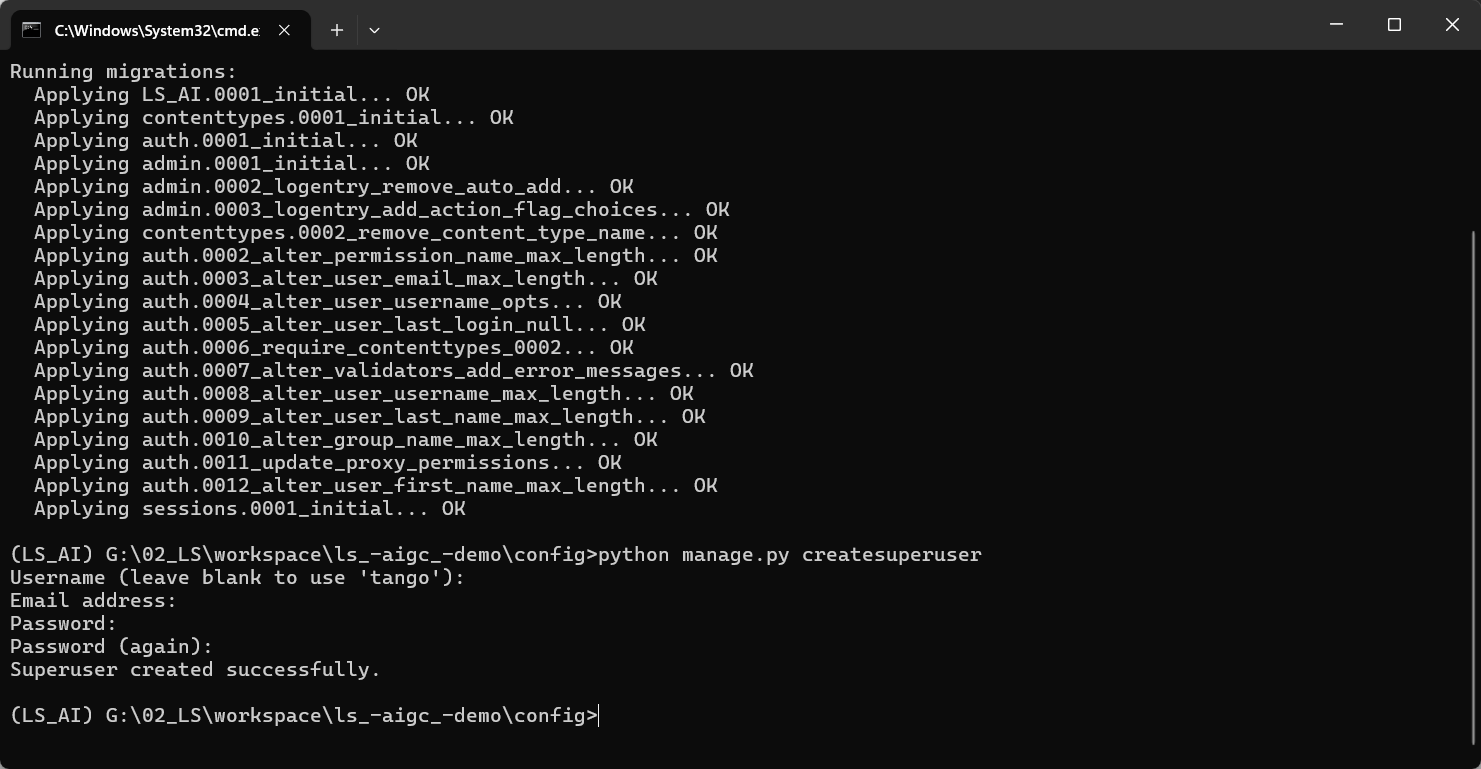
python manage.py runserver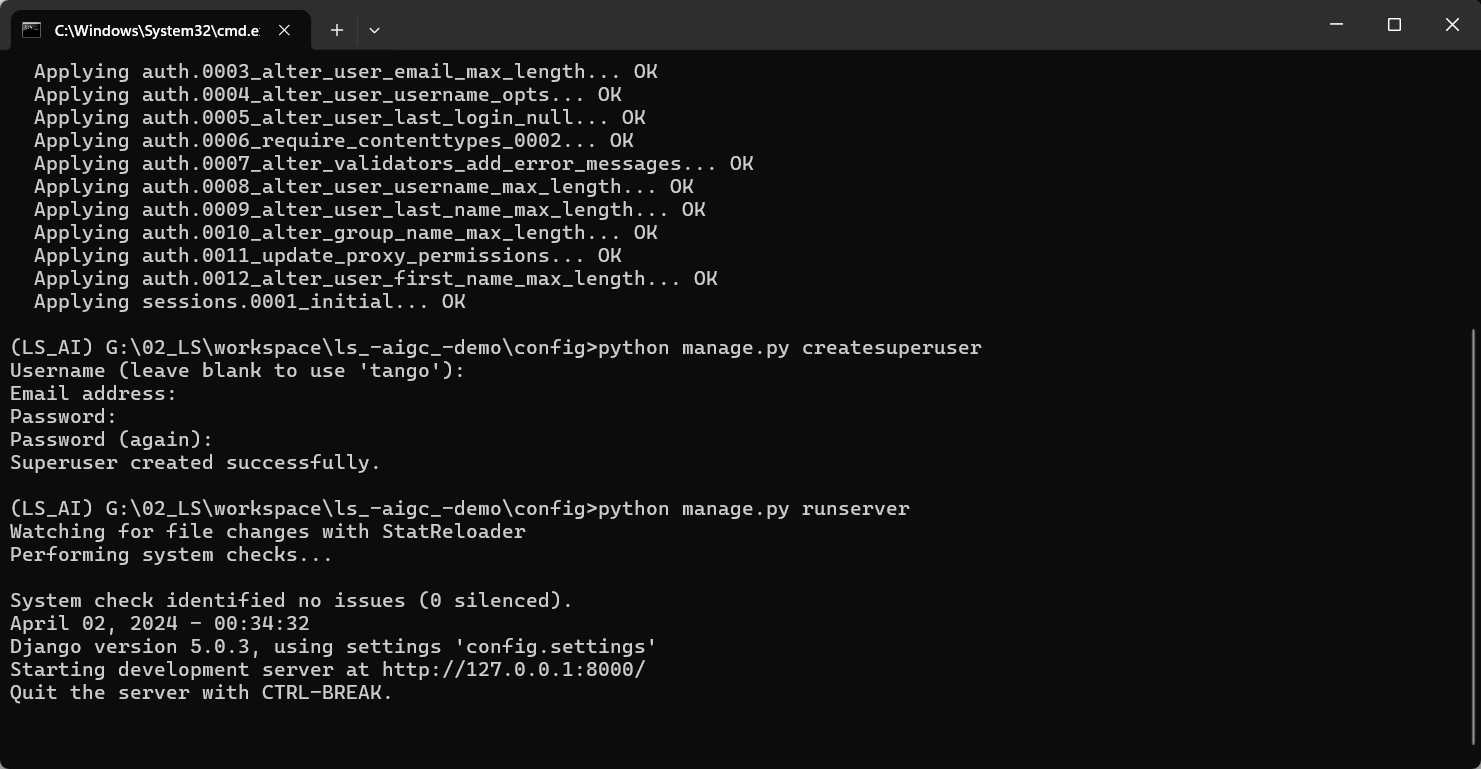
浏览器输入地址:http://127.0.0.1:8000/admin
添加几条测试数据
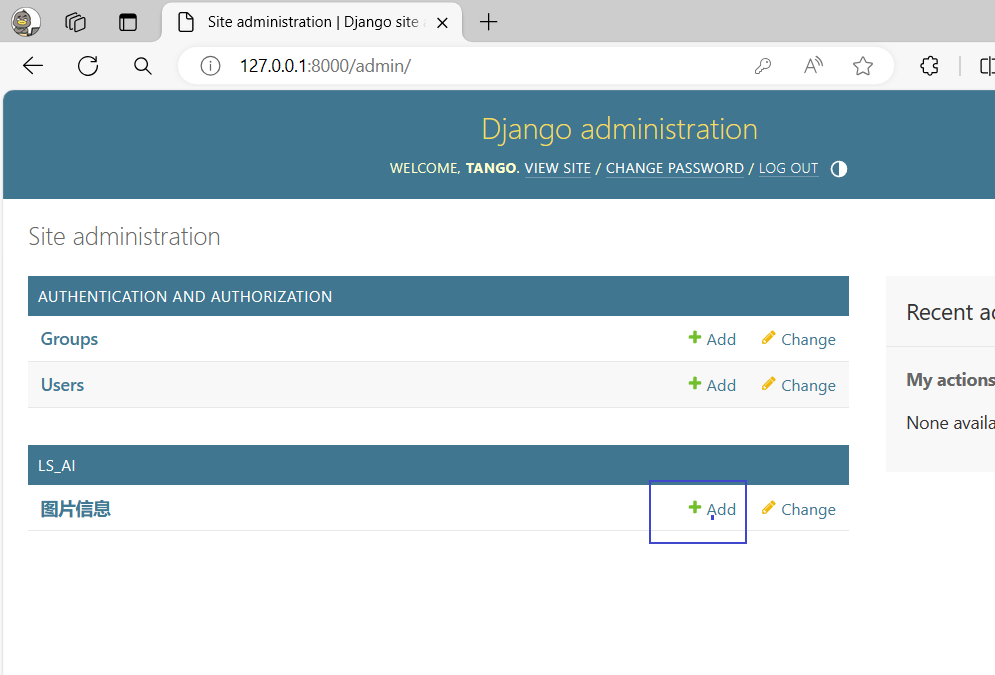
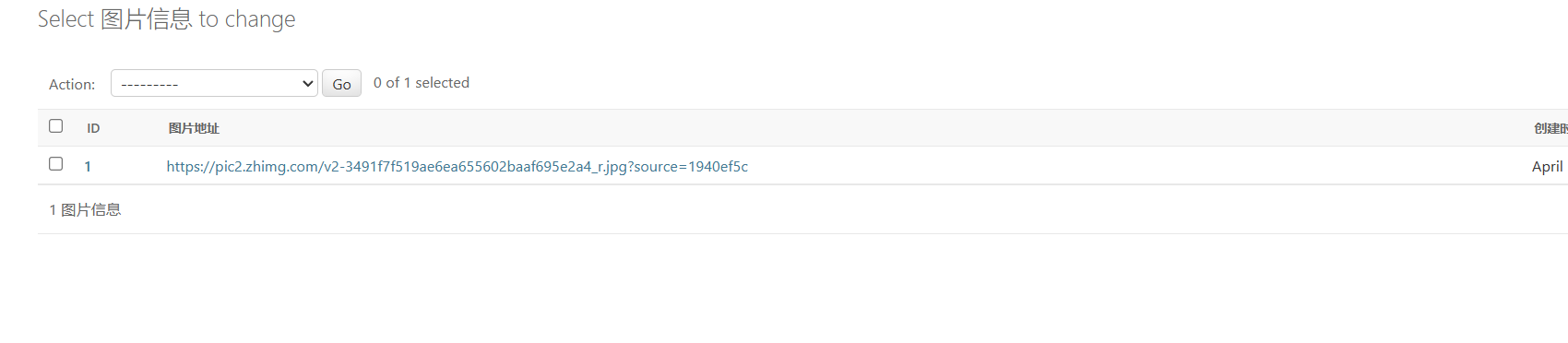
测试获取数据的接口
目前我们获取图片地址的功能已经完成。
4. 图片识别功能开发
我们这里使用的是智谱的SDK进行开发
1. 安装智谱的SDK
pip install --upgrade zhipuai -i https://mirrors.aliyun.com/pypi/simple/2. 功能实现
def get_img_info(request):
client = ZhipuAI(api_key="157cca7daacc280aaa48cdd503986951.389ak8CMFgYTo4R6") # 填写您自己的APIKey
response = client.chat.completions.create(
model="glm-4v", # 填写需要调用的模型名称
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "图里有什么"
},
{
"type": "image_url",
"image_url": {
"url": "https://img1.baidu.com/it/u=1369931113,3388870256&fm=253&app=138&size=w931&n=0&f=JPEG&fmt=auto?sec=1703696400&t=f3028c7a1dca43a080aeb8239f09cc2f"
}
}
]
}
]
)
info = {
"desc": response.choices[0].message.content
}
print(info)
return HttpResponse(json.dumps(info), content_type='application/json')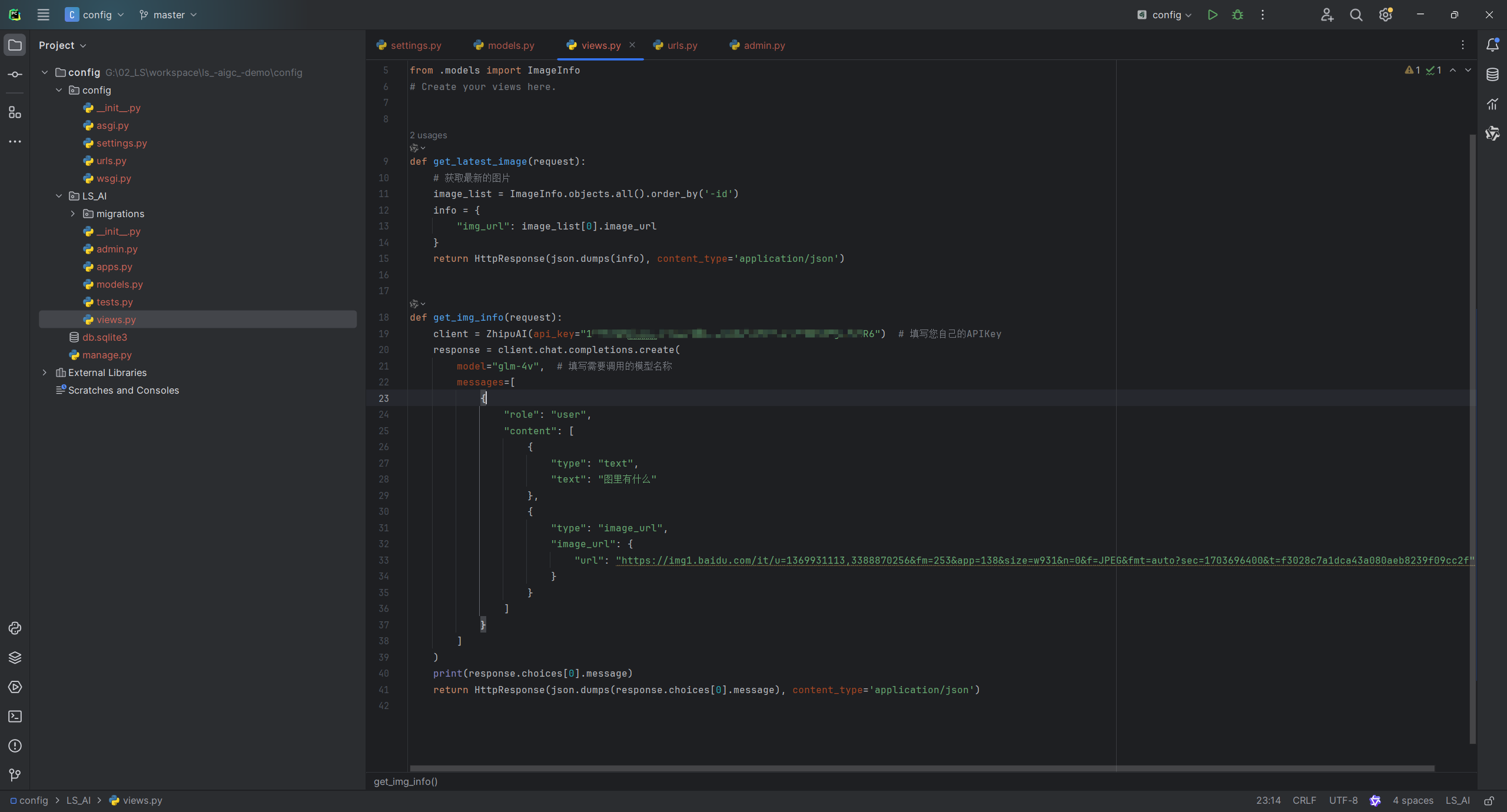
上面的代码运行后可以看到我们返回。
5. 项目重构
核心功能实现后我们需要重新将后端编排一下。
- 用户语音输入
- 识别语音中需要的图片的索引
- 根据索引获取到指定图片
- 分析图片中的内容返回给AI套件
2~4我们可以通过一个方法来实现,修改后的代码
import json
from django.conf import settings
from django.http import HttpResponse
from zhipuai import ZhipuAI
from .models import ImageInfo
# Create your views here.
def get_img_info(request):
# 判断POST
if request.method == 'POST':
# 获取POST参数
content = request.POST.get('content') # 获取用户输入
client = ZhipuAI(api_key=settings.API_KEY) # 填写您自己的APIKey
tools = [
{
"type": "function",
"function": {
"name": "image_info",
"description": "根据用户提供的信息,返回要查询的数字",
"parameters": {
"type": "object",
"properties": {
"img_index": {
"type": "integer",
"description": "图片编号",
},
},
"required": ["img_index"],
},
}
}
]
messages = [
{
"role": "user",
"content": content
}
]
response = client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=messages,
tools=tools,
tool_choice="auto",
)
try:
info = eval(response.choices[0].message.tool_calls[0].function.arguments)
img_index = info["img_index"]
image_list = ImageInfo.objects.all().order_by('-id')
image_url = image_list[img_index].image_url
response = client.chat.completions.create(
model="glm-4v", # 填写需要调用的模型名称
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "图里有什么"
},
{
"type": "image_url",
"image_url": {
"url": image_url
}
}
]
}
]
)
info = {
"desc": response.choices[0].message.content
}
return HttpResponse(json.dumps(info), content_type='application/json')
except:
info = {
"desc": "似乎发生错误了"
}
return HttpResponse(json.dumps(info), content_type='application/json')修改后的路由
from django.contrib import admin
from django.urls import path
from LS_AI.views import get_img_info
urlpatterns = [
path('admin/', admin.site.urls),
path('get_img_info/', get_img_info)
]6. 后端部署
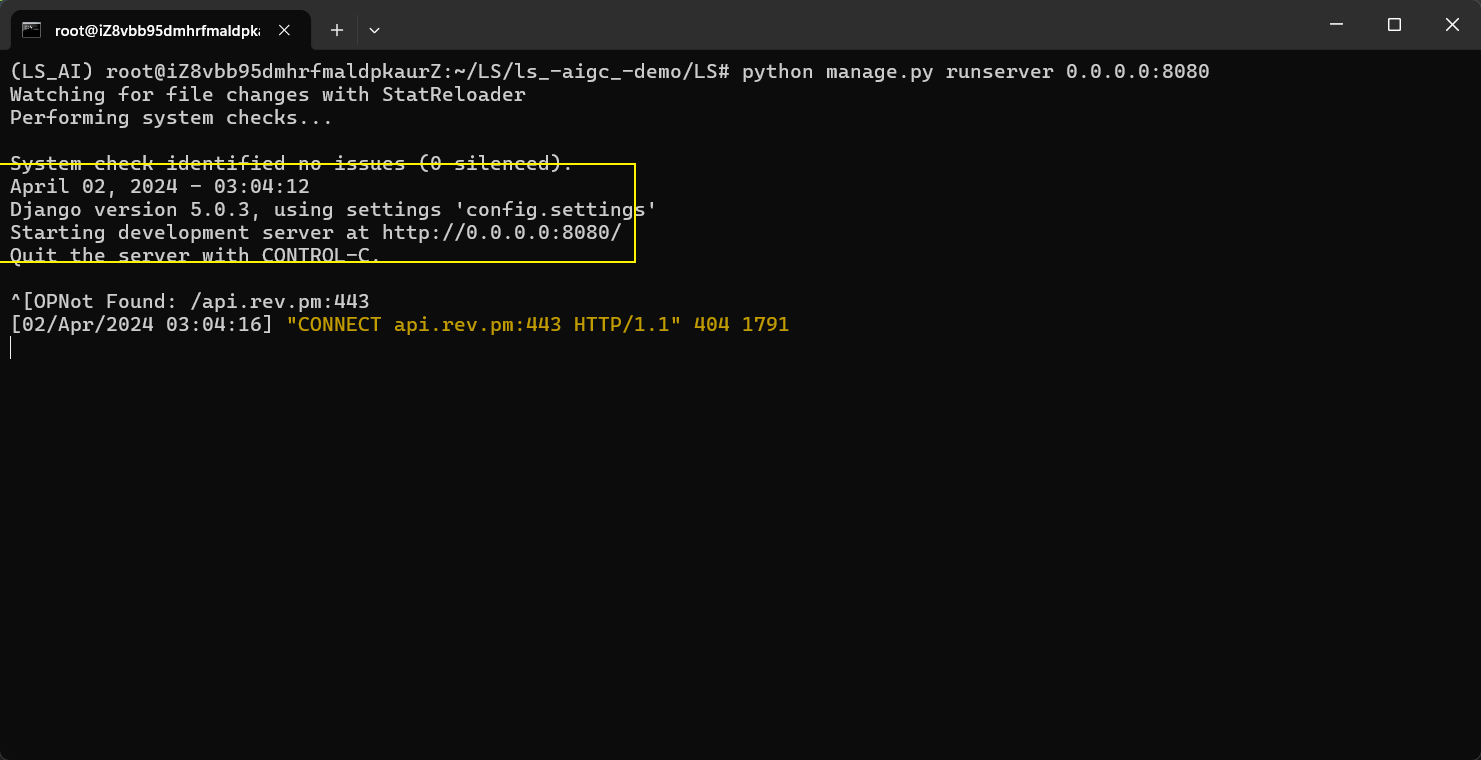
我这里使用的是阿里云的Ubuntu镜像,git和miniconda已经安装好了,由于只是演示这里并没有真正的部署到80端口,只是通过调试模式用8080端口进行验证。
7. 项目编排
我们进入到项目后点击右上角可以创建一个应用
点击创建好的项目可以进入编排
我们可以从左侧选择一些我们需要的节点进行编排
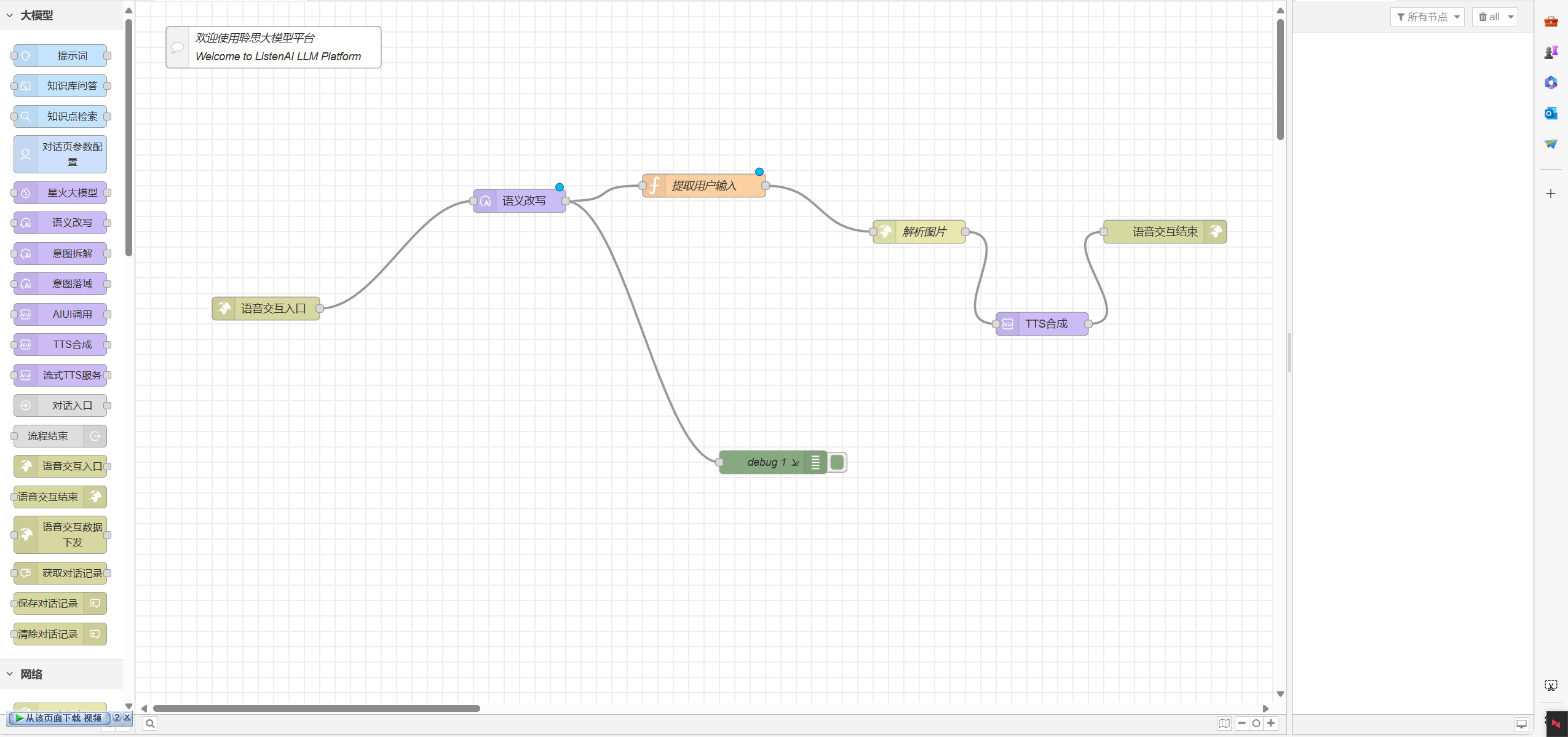
前期编写时可以灵活的使用debug节点。
编排完成后我们可以点击右上角的部署按钮。
如果要想和套件进行联调,我们还需要创建产品,并绑定设备
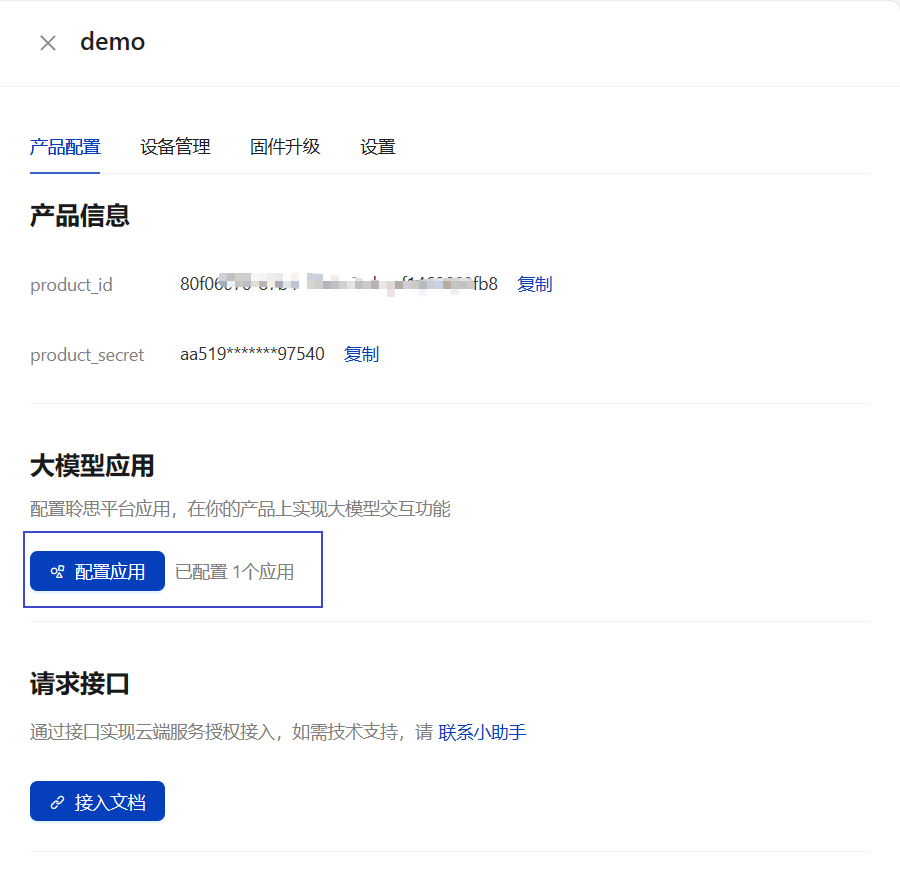
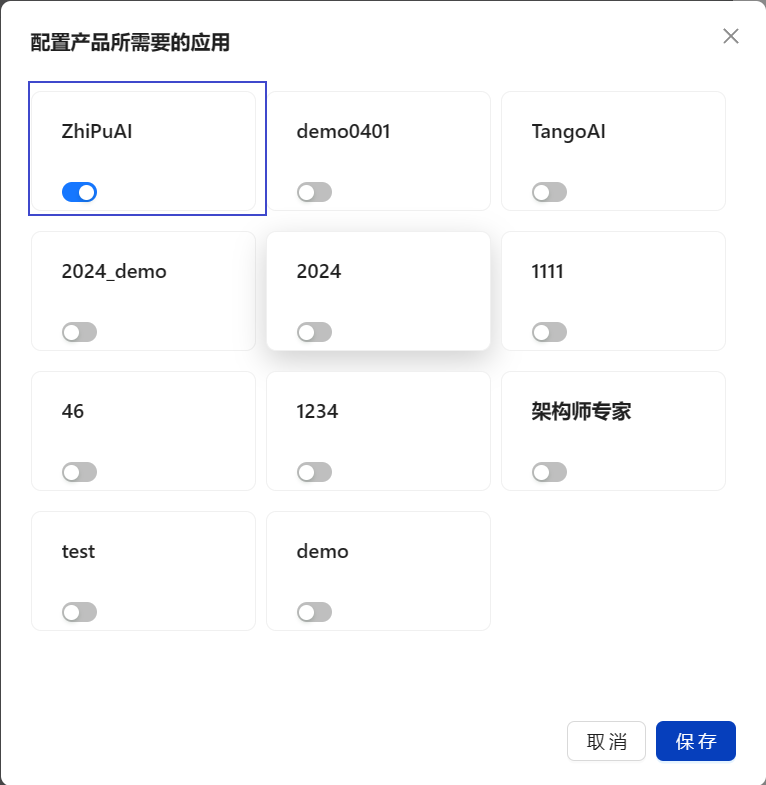
将我们的应用配置上
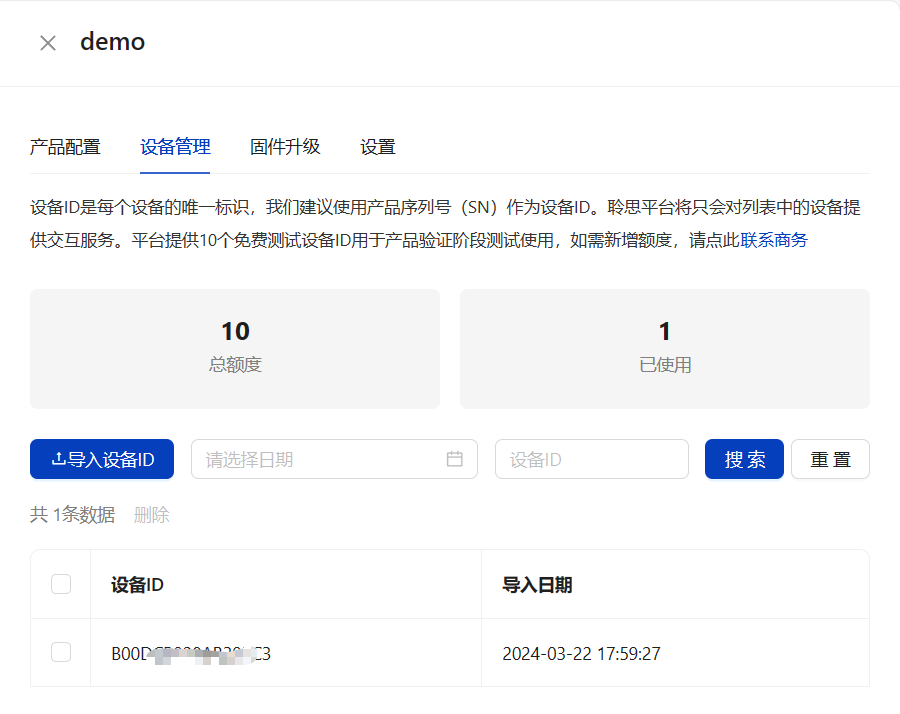
设备ID可以通过以下命令获取: lisa zep exec cskburn -s \\.\COMxx -C 6 -b 748800 --chip-id
将设备联网后,我们说小聆,小聆,帮我找第一张图片会看到如下输出
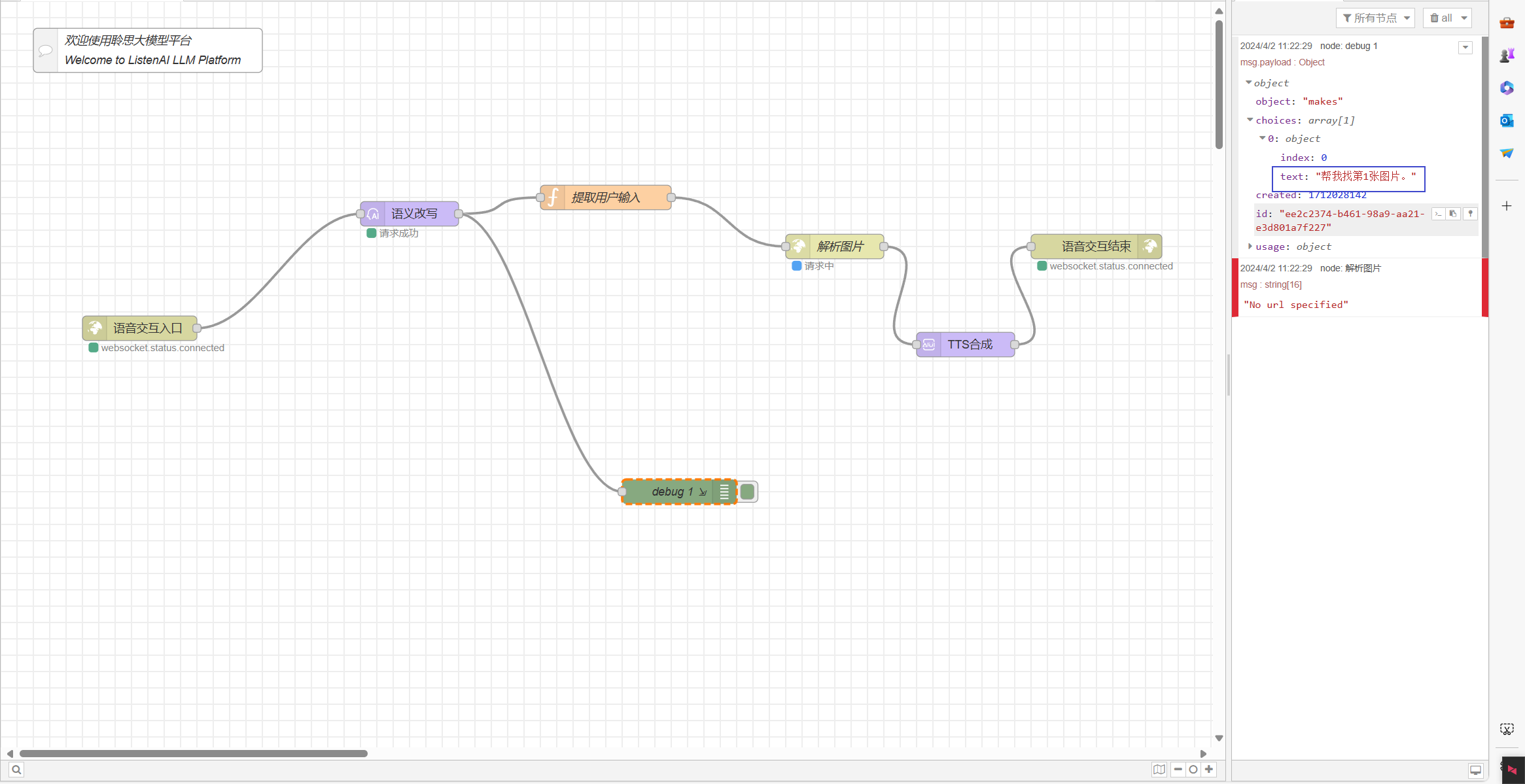
由于我们的后端只需要介绍文本内容,不需要其他信息,因此需要一个函数将用户输入提取出来
函数如下
let content = msg.payload.choices[0] || '';
msg.payload = {
"content": msg.payload.choices[0].text
}
return msg;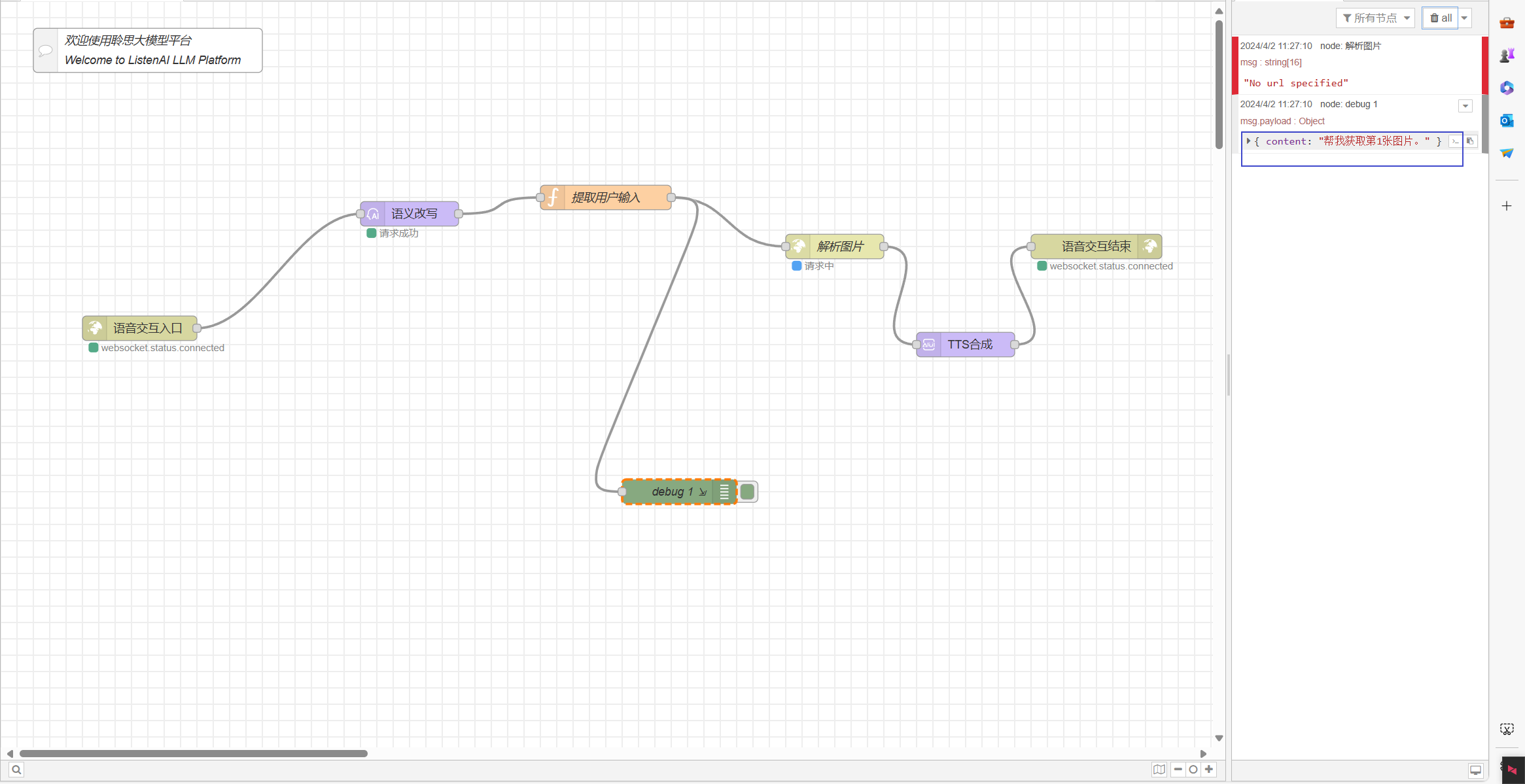
整合好输入数据格式后,就可以通过POST的形式将数据发送给我们的后端进行处理了
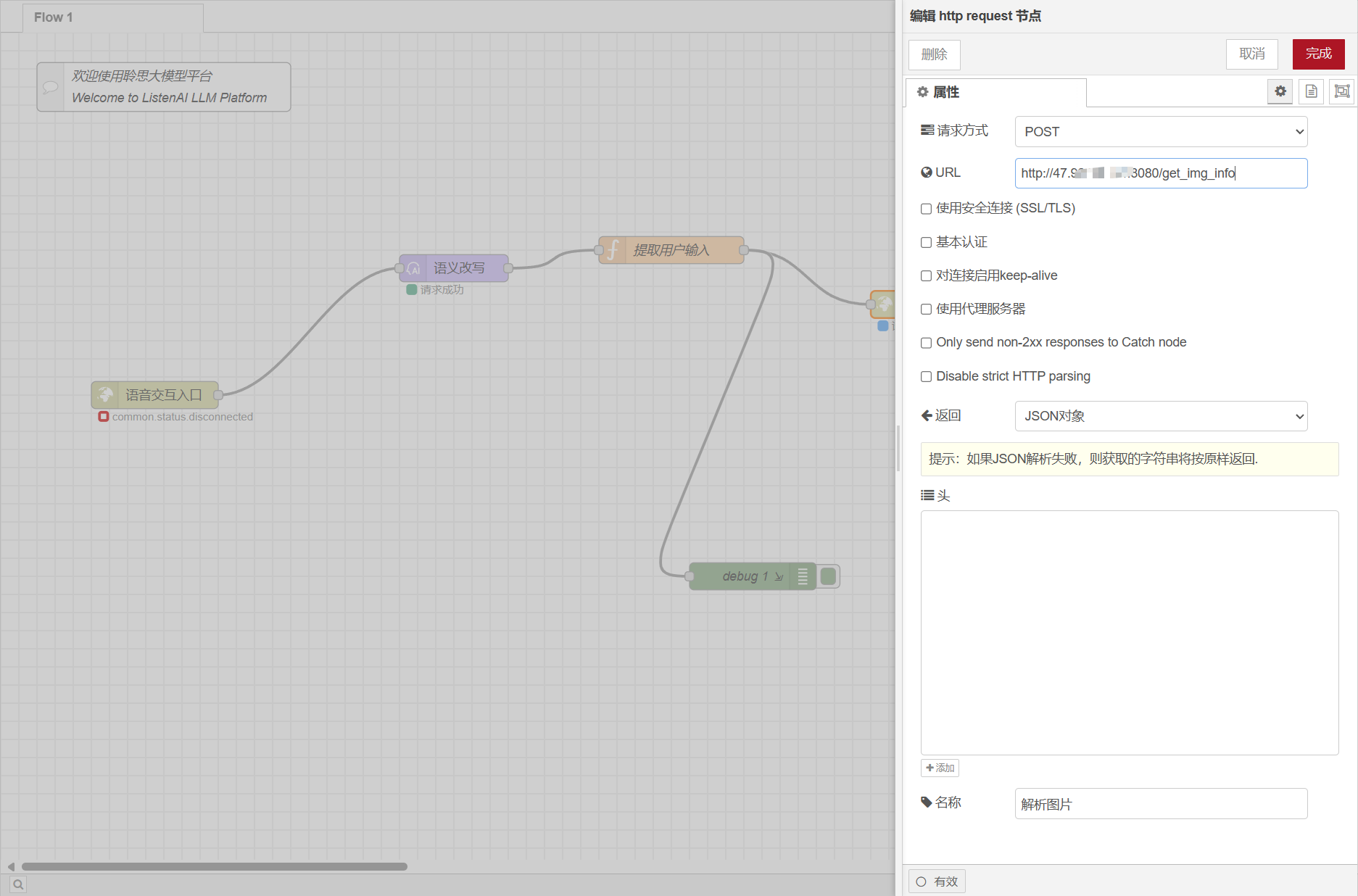
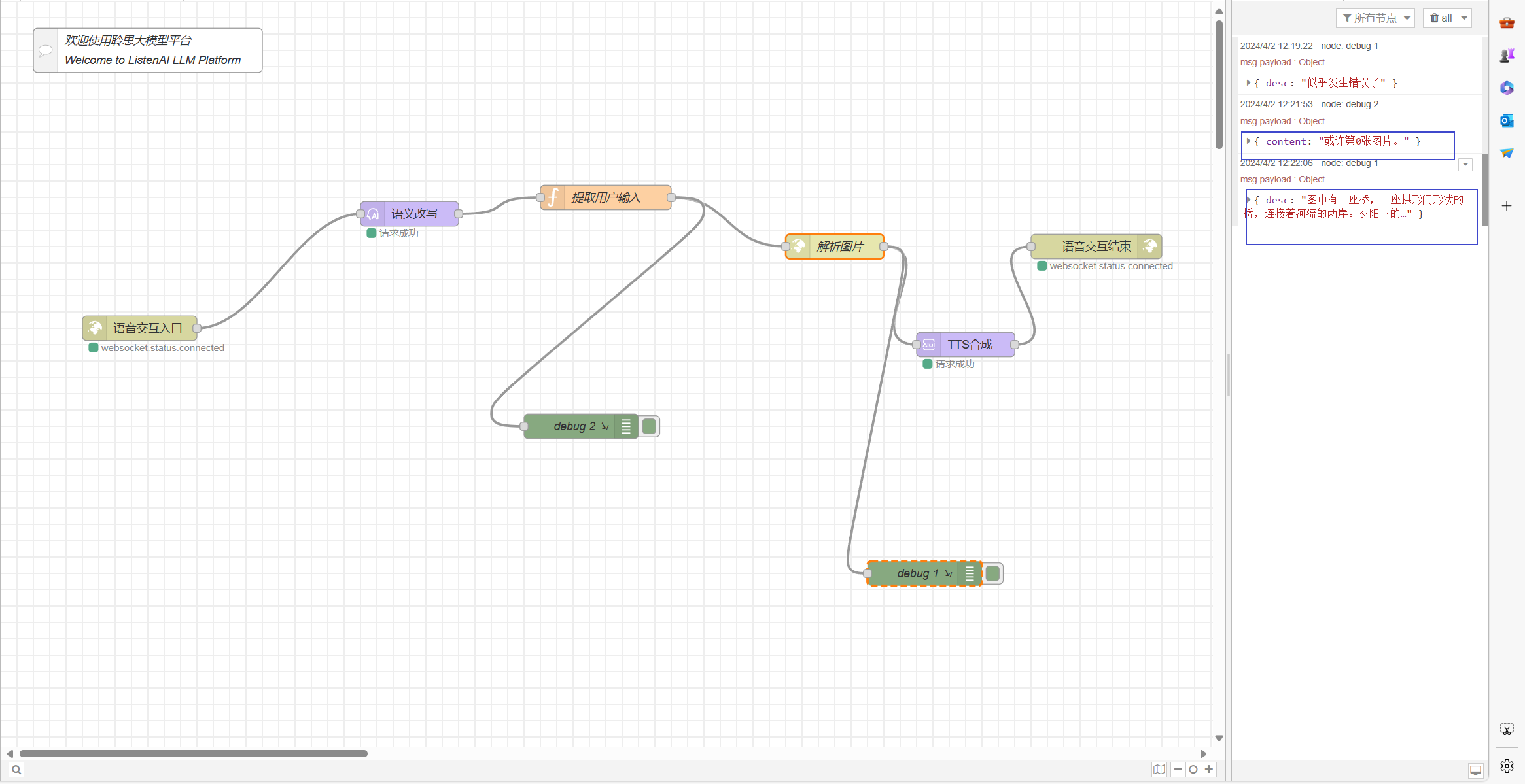

可以看到已经获得到结果了,接下来需要让AI套件帮我们将内容朗读出来。
完成后的节点
总结
整个使用过程中,前期需要一些学习,但是上手很快,在线编排的学习成本很低,非常建议大家上手体验一下。
我是Tango,今天的内容就是这些,我们下期见
---
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
