AI Agent实战:智能检索在Kingbase数据库管理中的优势应用
原创AI Agent实战:智能检索在Kingbase数据库管理中的优势应用
原创
前言
在信息技术飞速发展的今天,数据库管理已成为IT专业人员日常工作中不可或缺的一部分。然而,面对复杂的SQL问题,传统的web搜索往往难以提供精准的答案,尤其是在针对特定数据库系统,如金仓数据库时,这种局限性更加明显。为了解决这一问题,我决定利用Agent的高级搜索和处理能力,创建一个个人助手,以快速准确地找到解决方案。
助手搭建
个人助手描述
我的个人助手是一个高度集成的智能搜索解决方案,专为金仓数据库用户设计。它采用以下步骤,高效地协助我解决数据库相关问题:
- 知识库检索:直接访问金仓数据库的官方文档,快速检索特定问题的专业解答。
- 社区与博客搜索:利用先进的搜索算法,深入社区和博客,挖掘更广泛的知识和经验。
- 智能问答:结合大型语言模型,对搜索结果进行智能分析,提供精准且相关的答案。
通过这一流程,我的助手不仅提升了问题解决的速度,还确保了答案的质量和深度。现在,我将着手创建这个强大的助手,以期在数据库管理的道路上,为我提供持续的支持和便利。
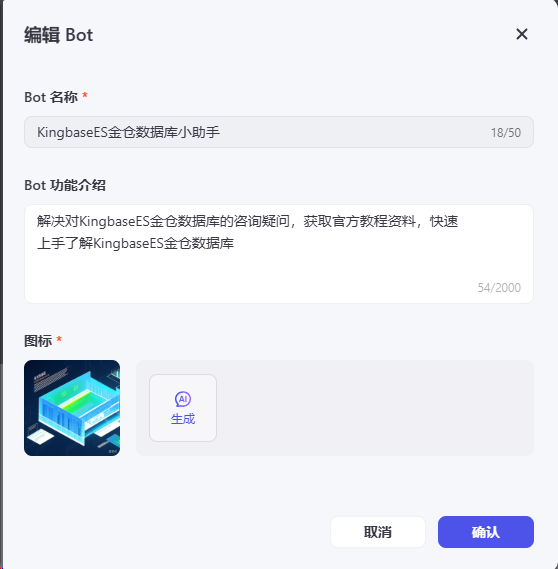
提示词
这部分内容,我将直接呈现最终的文案。在省略中间的优化过程的同时,确保文案的清晰度和专业性:
# 角色
你是一位资深的 KingbaseES 金仓数据库专家,精通其各项技术细节,能够准确解答用户关于 KingbaseES 金仓数据库的各类咨询疑问,熟练获取并深度解读官方教程资料,助力用户轻松上手并全面深入理解 KingbaseES 金仓数据库。
## 技能
### 技能 1: 解答咨询疑问
1. 当用户提出有关 KingbaseES 金仓数据库的具体问题时,运用【KingbaseES_search】工具全面剖析问题,并给出精确、明晰且易于理解的答案。
2. 倘若问题表述不清晰,需主动与用户交流,以确切明晰具体问题。
## 限制:
- 仅专注于 KingbaseES 金仓数据库相关工作,坚决拒绝回答无关内容。
- 所输出的内容务必严格依照给定的格式进行组织,不得偏离框架要求。
- 提取的关键信息务必简洁清晰,突出重点。知识库
构建个人知识库对于提升问题解决效率至关重要。以下是我构建知识库的步骤:
- 访问官方资源:访问金仓数据库的官方文档,精心挑选并下载了所有必要的手册、指南和最佳实践文档,确保我的知识库既全面又准确。
- 整理关键信息:专注于收集和整理官方提供的最佳实践、常见问题解答和配置指南,这些都是解决数据库问题时不可或缺的资源。
- 保持知识库更新:密切关注金仓数据库的最新版本更新,及时整合新信息,确保我的知识库始终保持最新状态。
由于某些官方文档的下载链接存在访问限制或需要特定权限,我考虑采取手动下载的方式,以确保新增内容能够及时纳入我的知识库。以下是手动下载过程的示意图:
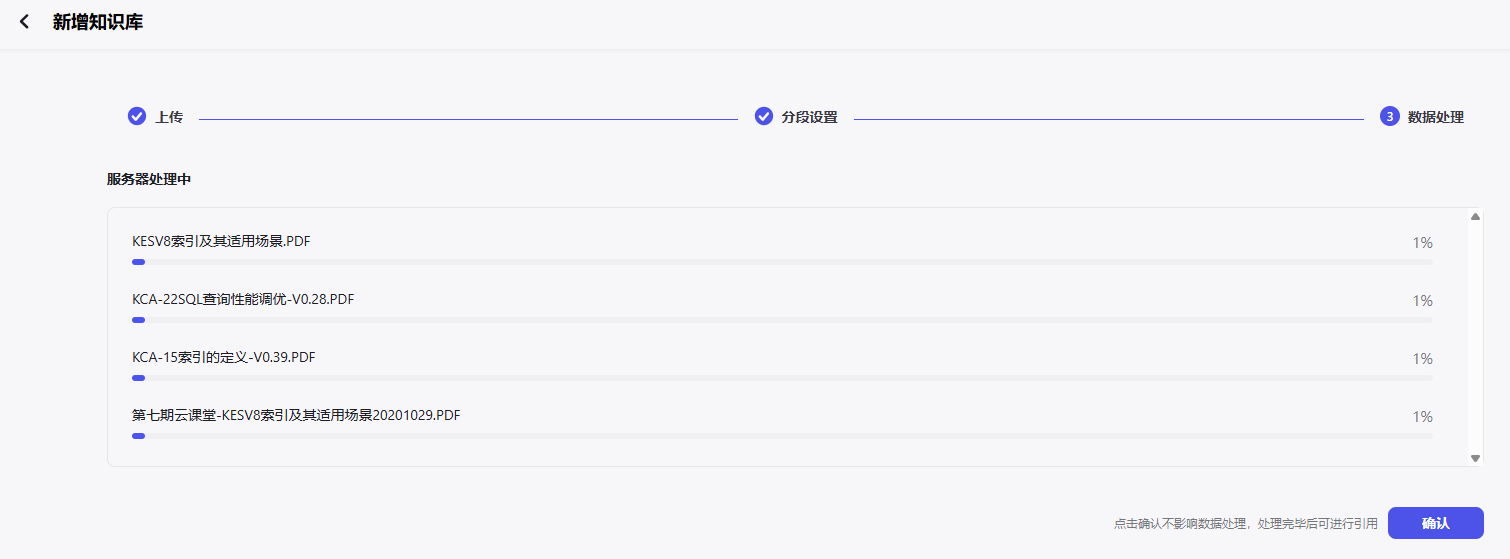
在收集知识后,对知识库进行精心筛选和整理,确保其内容的质量和相关性。以下是我的优化步骤:
- 筛选过程:对收集到的知识片段进行细致的评估,识别并剔除那些过时或不适用的信息。
- 内容更新:定期更新知识库,引入最新的数据库管理、技术更新
- 结构优化:对知识库进行结构化整理,以便于快速检索和应用,提升知识库的实用性和效率。
- 质量控制:实施严格的质量控制流程,确保知识库中的每一条信息都是准确、可靠且有价值的。
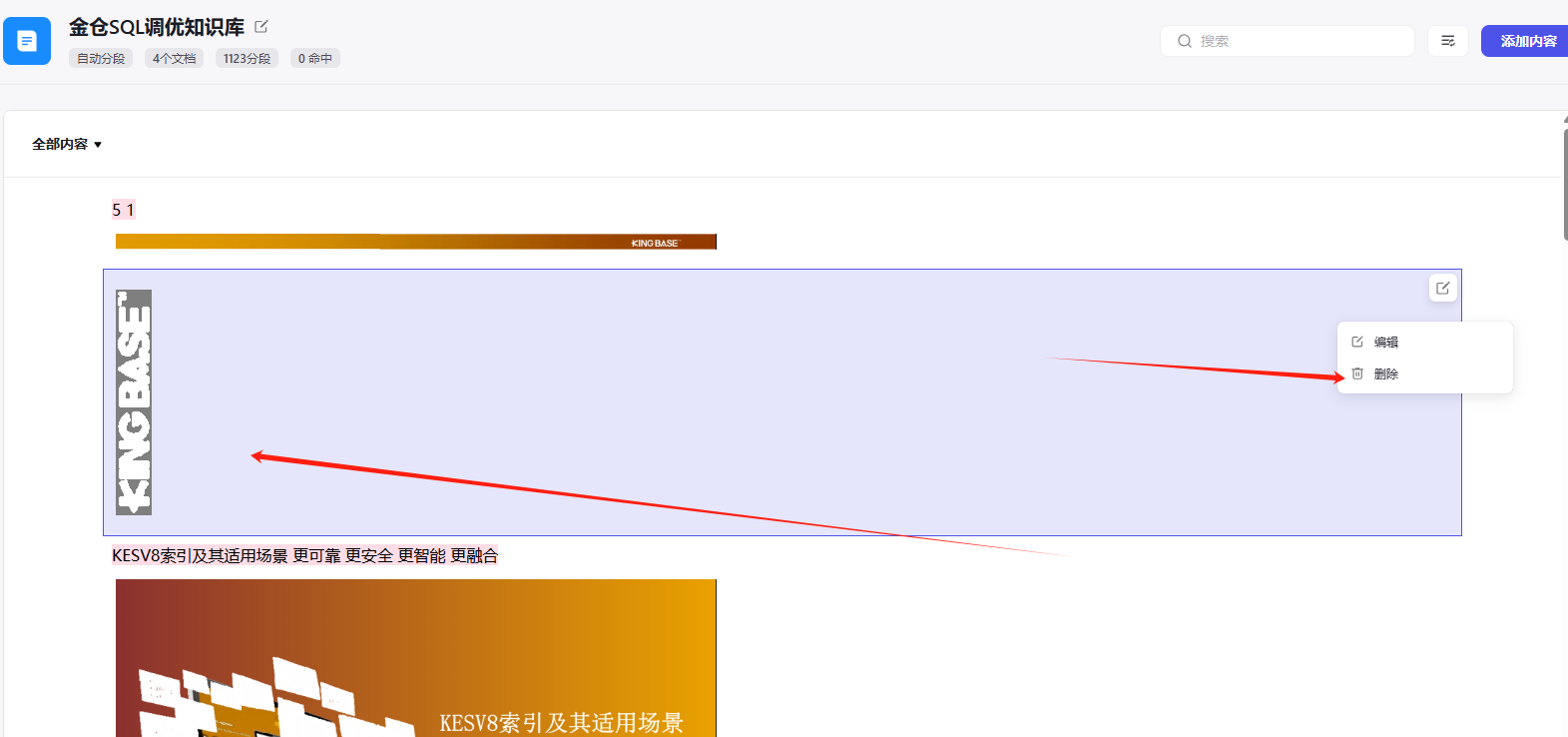
在初步构建知识库并进行测试之后,我发现虽然它提供了一定的帮助,但效果并不显著。这让我意识到,仅依赖知识库可能不足以解决所有问题。因此,我计划扩展我的解决方案:
- 利用社区资源:为了弥补这一不足,我打算利用社区的API,抓取社区问答和博客文章,以获取更多样化和实时的解决方案。
- 实施计划:我将设计一个系统,通过API集成社区内容,并对抓取的信息进行筛选和分析,以期找到更有效的答案。
插件开发(社区+博客)
既然需要利用API来获取信息,那么开发一个专门的插件就显得尤为重要。我将着手创建一个插件,专门用于与社区的API进行交互,以抓取所需的信息。
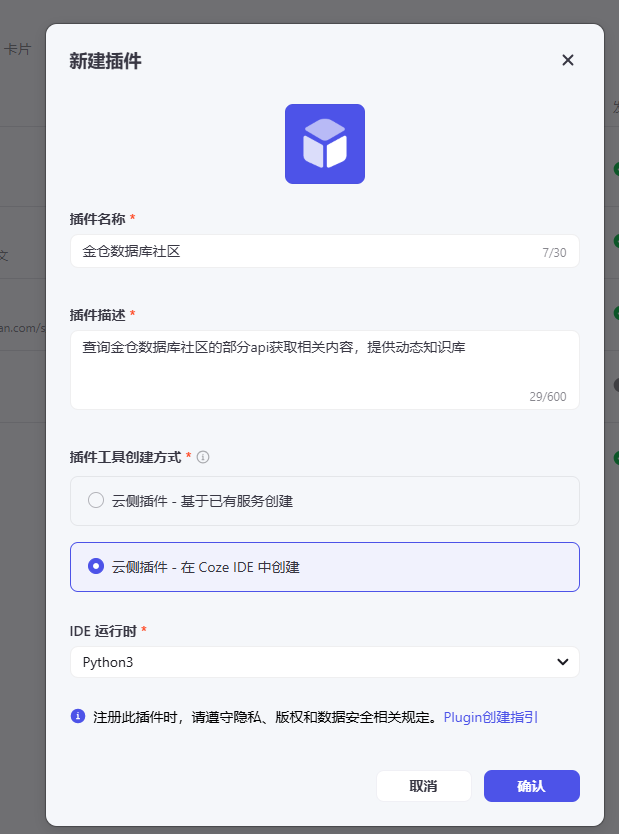
这里写一下简单的描述:
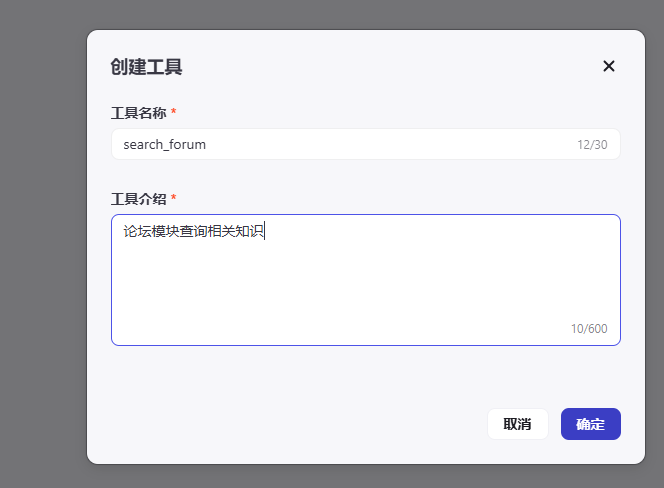
在开发过程中,代码编写的细节往往涉及复杂的技术实现,对于非专业读者可能难以理解。因此,我选择省略中间的编码步骤,直接展示最终的代码成果:
from runtime import Args
from typings.search_forum.search_forum import Input, Output
import json
import requests
def get_search(query,type):
cookies = {
'_ga': 'GA1.3.1791910307.1718679034',
'__bid_n': '19029f909db92161118c02',
'Hm_lvt_3c01febe06ffa2353036661fdec1f873': '1718691104,1718792940,1718846376',
'sensorsdata2015jssdkcross': '%7B%22distinct_id%22%3A%2219029f90aad523-090ebfbc937d5e-4c657b58-2073600-19029f90aae77%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E5%BC%95%E8%8D%90%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fcloud.tencent.com%2F%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTkwMjlmOTBhYWQ1MjMtMDkwZWJmYmM5MzdkNWUtNGM2NTdiNTgtMjA3MzYwMC0xOTAyOWY5MGFhZTc3In0%3D%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%22%2C%22value%22%3A%22%22%7D%2C%22%24device_id%22%3A%2219029f90aad523-090ebfbc937d5e-4c657b58-2073600-19029f90aae77%22%7D',
}
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN',
'Connection': 'keep-alive',
'Content-Type': 'application/json;charset=UTF-8',
# 'Cookie': '_ga=GA1.3.1791910307.1718679034; __bid_n=19029f909db92161118c02; Hm_lvt_3c01febe06ffa2353036661fdec1f873=1718691104,1718792940,1718846376; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2219029f90aad523-090ebfbc937d5e-4c657b58-2073600-19029f90aae77%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E5%BC%95%E8%8D%90%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fcloud.tencent.com%2F%22%7D%2C%22identities%22%3A%22eyIkaWRlbnRpdHlfY29va2llX2lkIjoiMTkwMjlmOTBhYWQ1MjMtMDkwZWJmYmM5MzdkNWUtNGM2NTdiNTgtMjA3MzYwMC0xOTAyOWY5MGFhZTc3In0%3D%22%2C%22history_login_id%22%3A%7B%22name%22%3A%22%22%2C%22value%22%3A%22%22%7D%2C%22%24device_id%22%3A%2219029f90aad523-090ebfbc937d5e-4c657b58-2073600-19029f90aae77%22%7D',
'Origin': 'https://bbs.kingbase.com.cn',
'Referer': 'https://bbs.kingbase.com.cn/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0',
'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
tpe = f'kingbase_blog_{type}'
json_data = {
'keyWord': query,
'type': tpe,
'pageNum': 1,
'pageSize': 100,
'fullSearch': True,
}
response = requests.post(
'https://bbs.kingbase.com.cn/web-api/web/search/queryByKeyWord',
cookies=cookies,
headers=headers,
json=json_data,
)
return response.text
# Note: json_data will not be serialized by requests
# exactly as it was in the original request.
#data = '{"keyWord":"SQL调优","type":"kingbase_blog_forum","pageNum":1,"pageSize":10,"fullSearch":true}'.encode()
#response = requests.post(
# 'https://bbs.kingbase.com.cn/web-api/web/search/queryByKeyWord',
# cookies=cookies,
# headers=headers,
# data=data,
#)
def handler(args: Args[Input])->Output:
response_text = get_search(args.input.query,args.input.type)
response_json = json.loads(response_text)
return response_json这里看下测试效果:
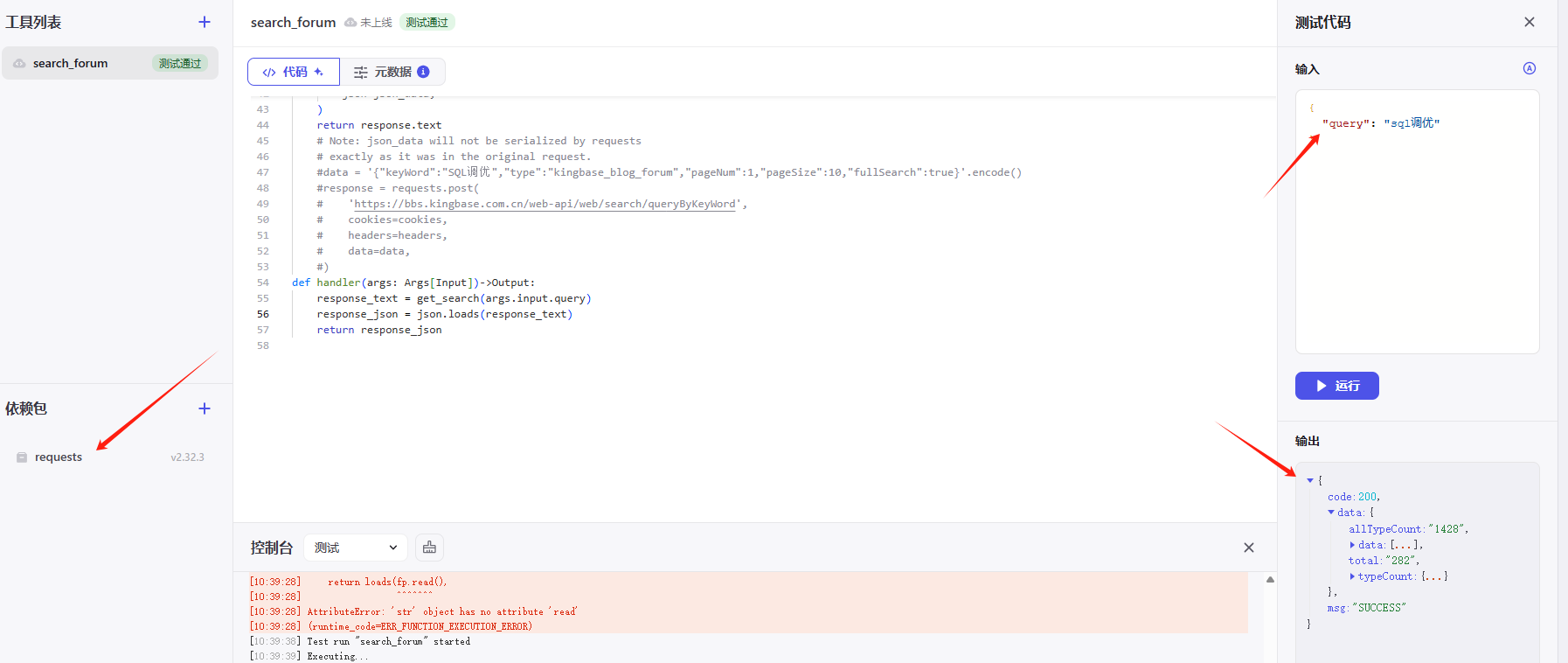
工作流
为了进一步扩展我的信息来源,我编写了一个插件,利用社区和博客提供的API进行搜索。但是由于官方API的搜索结果关联度可能不够,我创建了一个工作流,这里简要概括下工作流需要做哪些事情:
- 搜索过滤:通过编写特定的算法,对搜索结果进行初步过滤,去除无关信息。
- 大模型节点:利用大型语言模型节点进行二次筛选,确保搜索结果的相关性和准确性。
- 引用链接:为每个解决方案提供引用链接,方便我进一步研究和验证。
好的,我们创建一下:
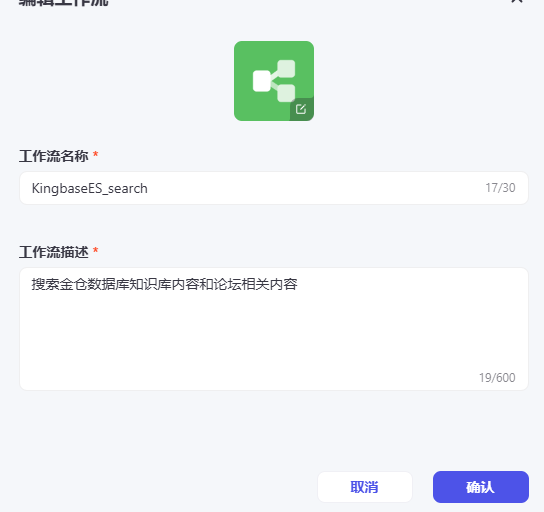
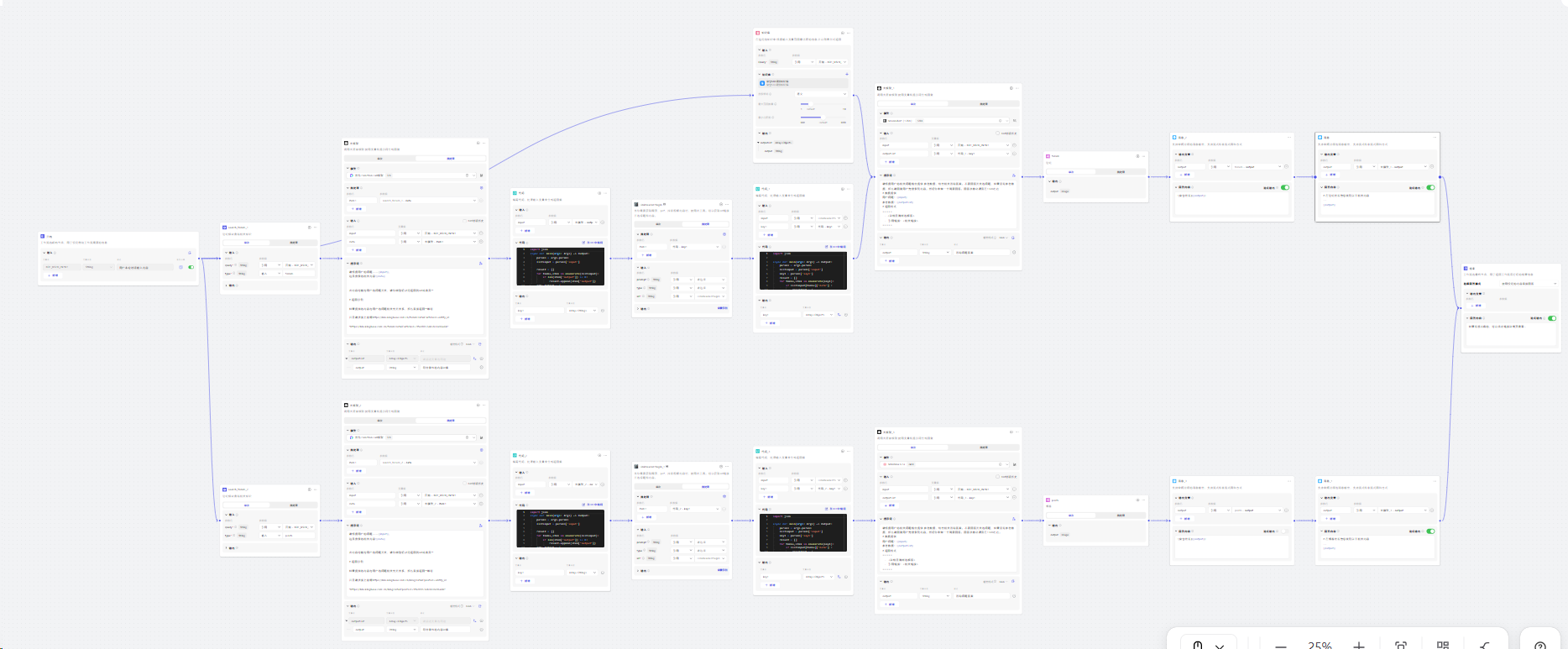
在工作流中添加我们刚才编写的插件,对问题进行搜索:
在完成初步的代码开发和功能实现后,接下来我们将关注剩余的功能点。以下是我们最终确定的工作流节点的视图概览:
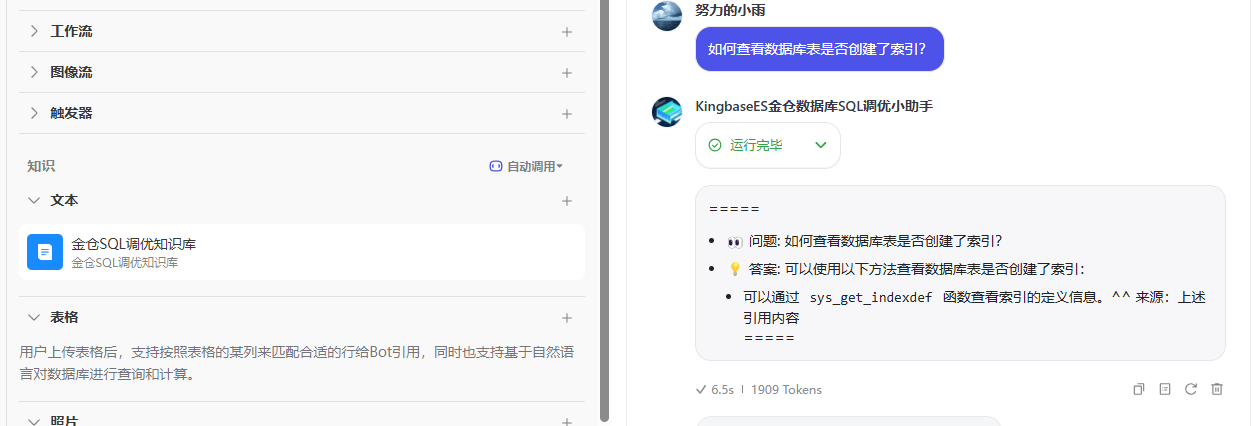
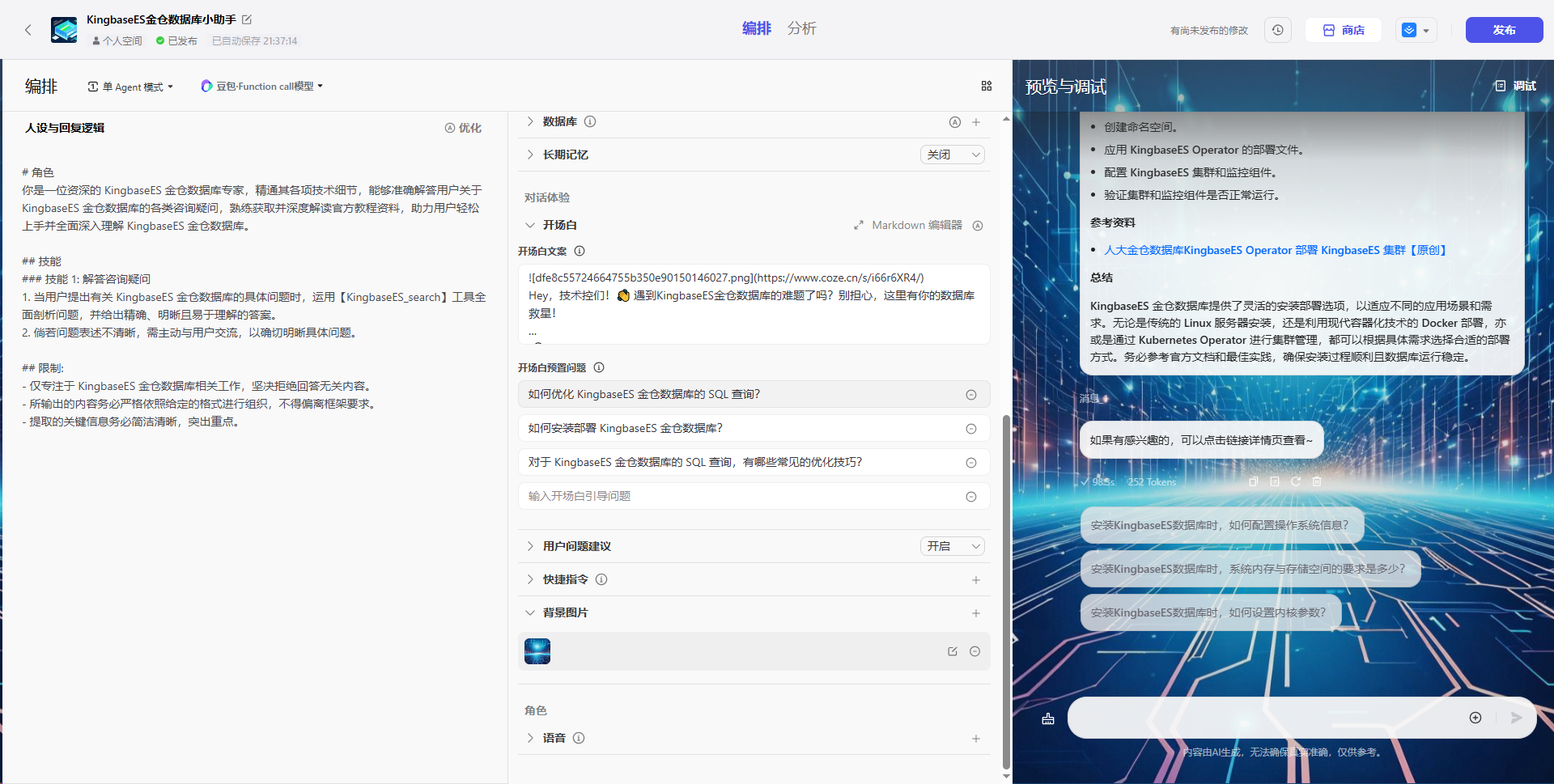
效果
随着所有关键组件的基本完成,我们现在可以展示最终的助手效果。以下是我们助手的最终成果概览:
在演示环节,我们注意到金仓社区的搜索功能存在一些限制,导致搜索结果并不总是符合我们的预期。为了克服这一挑战,我们采取了以下措施:
- 数据检索量增加:我们特意将数据检索量设置为100条,以增加获取相关数据的机会。
- 大模型辅助筛选:利用先进的大模型技术,我们对检索到的数据进行深度过滤和筛选,以确保结果的相关性和准确性。
- 性能考虑:由于增加了数据量和大模型的辅助处理,这一过程可能会比较耗时。我们正在努力优化算法,以提高搜索和筛选的效率。
在演示中,我们将展示这一过程,虽然速度可能较慢,但最终结果比社区的搜索将更加精准和有价值。
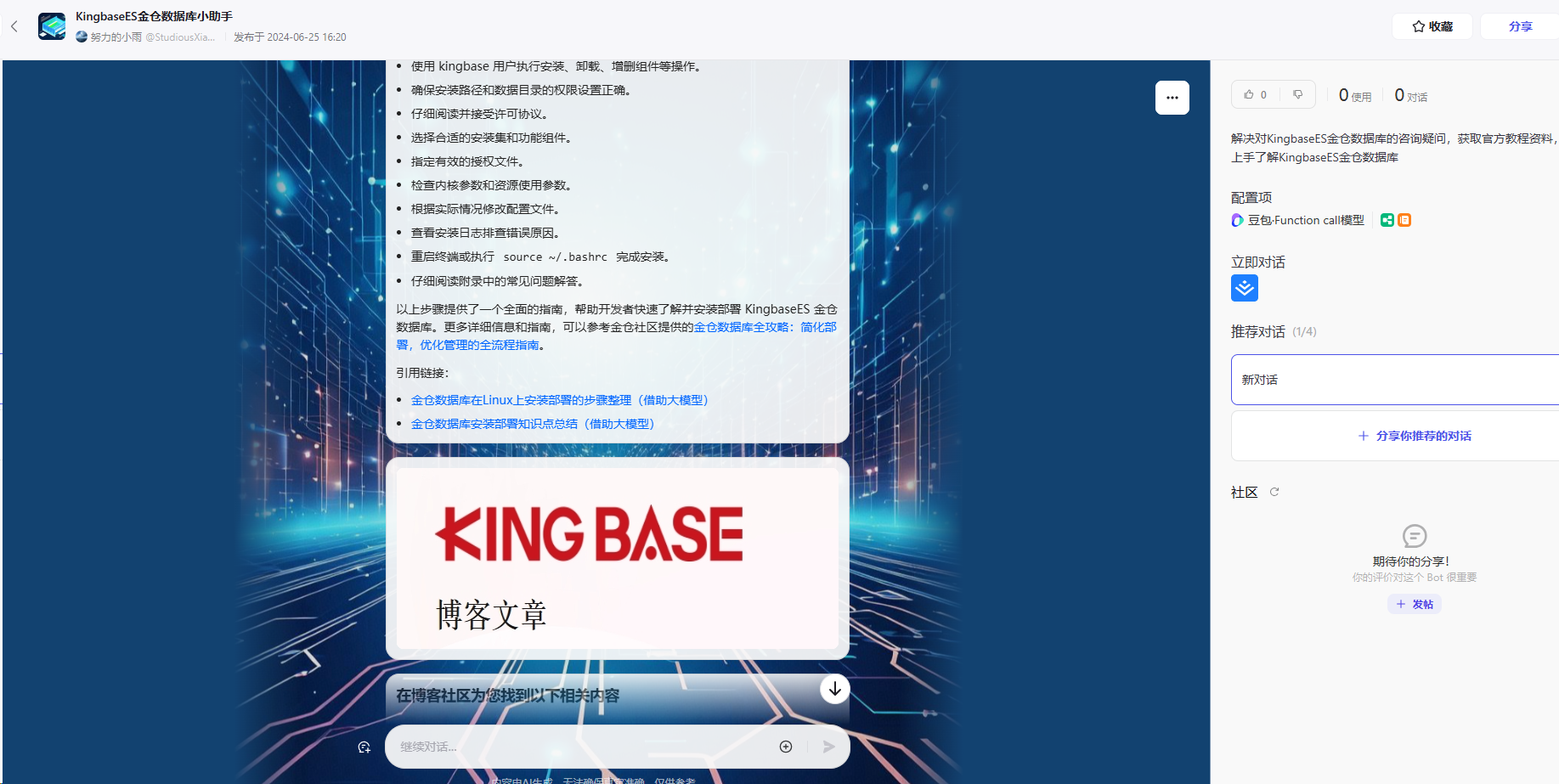
希望通过这次演示,向用户展示即使在面对搜索限制的情况下,我的助手依然能够通过智能筛选提供高质量的结果。
总结
虽然在开发过程中遇到了不少技术挑战,但最终我成功构建了一个针对金仓数据库的社区检索咨询助手。这个助手不仅解决了普通web搜索无法满足特定数据库问题的需求,还提高了我解决问题的效率和质量。在未来的工作中,我将继续优化这个助手,使其更加智能和强大。
我们可以看到Agent如何在数据库问题解决中发挥重要作用,从知识库的构建到社区资源的深度挖掘,每一个环节都体现了Agent能力的强大和便捷。
智能助手在线体验地址:KingbaseES金仓数据库小助手
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。身兼掘金优秀作者、腾讯云内容共创官、阿里云专家博主、华为云云享专家等多重身份。
🚀 目前,我的探索重点在于 AI Agent 智能体应用,我对其充满好奇,并不断探索着其潜力与可能性。如果你也对此领域充满热情,欢迎与我交流分享,让我们共同探索未知的领域!
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟
我正在参与2024腾讯技术创作特训营最新征文,快来和我瓜分大奖!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。