【愚公系列】软考高级-架构设计师 059-反规范化、模式分解
原创【愚公系列】软考高级-架构设计师 059-反规范化、模式分解
原创
🏆 作者简介,愚公搬代码 🏆《头衔》:华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 🏆《近期荣誉》:2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主等。
🏆《博客内容》:.NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。
🏆🎉欢迎 👍点赞✍评论⭐收藏
🚀前言
反规范化(Denormalization)是数据库设计中的一种技术,它通过增加冗余数据以提高查询性能或简化数据模型,通常用于解决由规范化(Normalization)带来的性能问题。规范化旨在减少数据冗余并确保数据一致性,但在某些情况下,规范化会导致查询变得复杂且缓慢,特别是在涉及多个表连接的情况下。
反规范化通过将数据冗余存储在表中,减少表之间的连接,从而加快查询速度。这可能会导致数据冗余,但在某些情况下,牺牲一些冗余以换取性能提升是值得的。
模式分解(Decomposition)是数据库设计中的一个过程,旨在将一个关系模式分解成更小更简单的关系模式,以便更好地遵循数据库设计原则,如规范化。模式分解是为了消除数据冗余、确保数据完整性、简化数据操作等目的。
在模式分解过程中,一个复杂的关系模式可能会被拆分成多个简单的关系模式,每个关系模式包含少量属性,并且可以通过连接操作重新构建原始的关系模式。通过模式分解,数据库设计可以更好地组织数据,减少数据冗余,提高数据的一致性和完整性。
🚀一、反规范化、模式分解
🔎1.反规范化
反规范化技术是在规范化设计后,为了提高性能而有意放弃部分规范化的数据库设计方法。这种技术的使用可能会带来一些益处,但同时也可能引发一些问题。以下是反规范化技术的益处。
🦋1.1 益处
- 降低连接操作的需求:
- 减少表之间的连接操作,提高查询效率,特别是对于复杂查询而言。
- 降低外码和索引的数目:
- 减少了数据的索引和外键,降低了数据库的维护成本和存储开销。
- 可能减少表的数目:
- 通过重新组织数据,将原本分散的信息整合到一个表中,减少了表的数量,简化了数据库结构。
🦋1.2 可能带来的问题
- 数据的重复存储:
- 增加了数据的冗余,浪费了磁盘空间,可能导致数据一致性的问题。
- 可能出现数据的完整性问题:
- 由于数据的冗余和重复存储,增加了数据维护的复杂性,可能导致数据一致性的问题。
- 降低修改速度:
- 数据的冗余和重复存储增加了数据的维护成本,可能会降低数据的修改速度。
🦋1.3 具体方式
- 增加冗余列:
- 在多个表中保留相同的列,通过增加数据冗余减少或避免查询时的连接操作。
- 增加派生列:
- 在表中增加可以由本表或其他表中数据计算生成的列,减少查询时的连接操作并避免计算或使用集合函数。
- 重新组表:
- 将需要经常连接的表重新组合成一个表,减少连接操作而提高性能。
- 水平分割表:
- 根据一列或多列数据的值,将数据放到多个独立的表中,主要用于表数据规模很大、表中数据相对独立或数据需要存放到多个介质上时使用。
- 垂直分割表:
- 将表按照列的关系进行分割,将主键与部分列放到一个表中,主键与其它列放到另一个表中,在查询时减少I/O次数。
通过反规范化技术,数据库设计者可以根据具体的业务需求和性能要求,灵活地调整数据库结构,以达到更好的性能和效率。然而,需要在益处和可能带来的问题之间进行权衡,确保数据库的可靠性和稳定性。
🔎2.模式分解
🦋2.1 具体方式
模式分解是关系数据库规范化设计中的一个重要过程,旨在消除关系模式中的混合组合依赖,将其分解为更小的模式。一般来说,模式分解可分为以下两种类型:
☀️2.1.1 是否保持函数依赖分解
在这种分解中,关系模式R经过分解后,多个关系模式的依赖集保持不变,同时要消除冗余依赖,如传递依赖。
特点:
- 分解后的每个关系模式仍然保持了原来的函数依赖。
- 消除了冗余依赖,确保了分解后的关系模式的简洁性和一致性。
☀️2.1.2 有损无损分解
这种分解是根据分解后的关系模式是否能够还原出原始的关系模式来分类的。
- 无损分解:分解后的关系模式能够完全还原出原始的关系模式。
- 有损分解:分解后的关系模式无法完全还原出原始的关系模式。
特点:
- 无损分解保留了原始的所有信息,保证了数据的完整性和一致性。
- 有损分解可能会丢失某些信息,但在某些情况下也是可接受的,例如为了优化性能或简化数据结构。
模式分解是规范化设计中的关键步骤,它有助于优化数据库结构,提高数据的组织和管理效率。在进行模式分解时,需要综合考虑数据的复杂性、业务需求和性能优化等因素,以确保最终的数据库设计能够满足实际应用的要求。
🦋2.2 是否保持函数依赖案例
设原关系模式R(A,B,C),依赖集F(A->B,B->C,A->C),将其分解为两个关系模式R1 (A,B)和R2(B,C),此时R1 中保持依赖A->B,R2保持依赖B->C,说明分解后的R1 和R2是保持函数依赖的分解,因为A->C这个函数依赖实际是一个冗余依赖,可以由前两个依赖传递得到,因此不需要管。
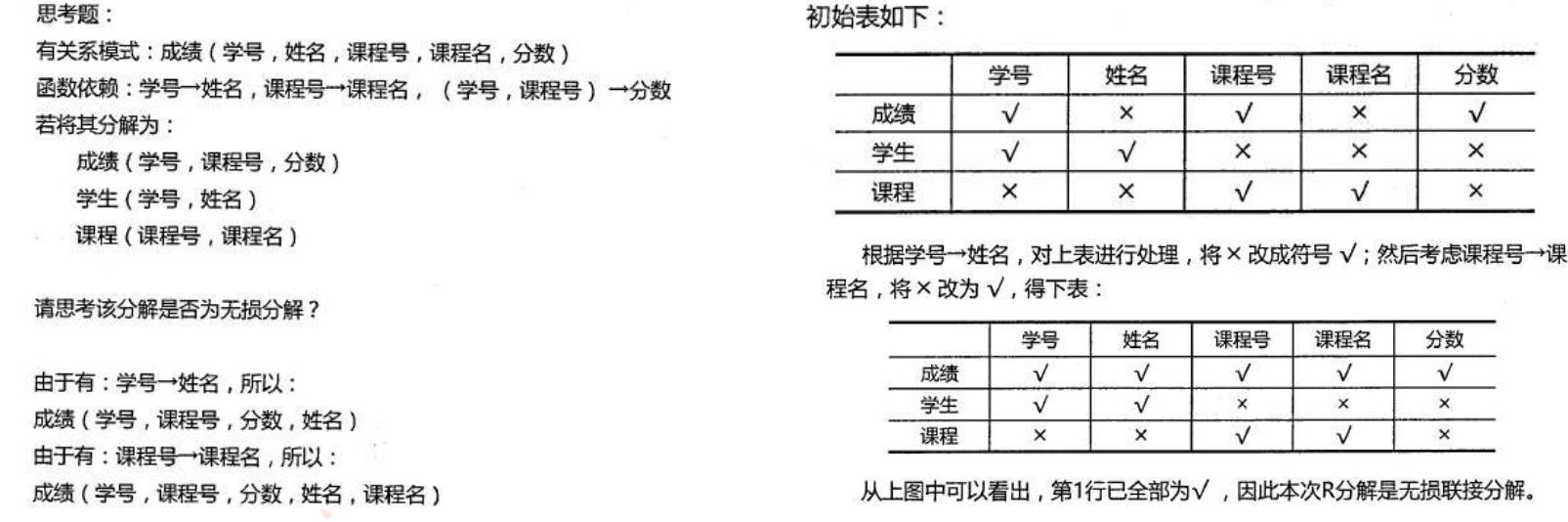
当分解为两个关系模式,可以通过以下定理判断是否无损分解:
- 定理:如果R的分解为p={R1 ,R2},F为R所满足的函数依赖集合,分解p具有无损连接性的充分必要条件是R1 ∩R2->(R1 -R2)或者R1 ∩R2->(R2-R1 )。
- 当分解为三个及以上关系模式时,可以通过表格法求解,如下:
 在这里插入图片描述
在这里插入图片描述
🔎3.练习

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
