pandas
原创
使用pandas过程中出现的问题
TOC
1.pandas无法读取excel文件:xlrd.biffh.XLRDError: Excel xlsx file; not supported
应该是xlrd版本太高
解决方法,使用openpyxl打开xlsx文件
df = pd.read_excel('鄱阳湖水文资料.xlsx',engine='openpyxl') 2、pandas索引问题
在Python pandas中,从0开始行列索引
3.pandas 时间序列之pd.date_range()
pd.date_range(python
start=None,#开始时间
end=None,#截止时间
periods=None,#总长度
freq=None,#时间间隔
tz=None,#时区
normalize=False,#是否标准化到midnight
name=None,#date名称
closed=None,#首尾是否在内
**kwargs,
) 生成的日期为年月日时分秒
1961/1/8 0:00:00
4.pandas中series与DataFrame区别
Series是带索引的一维数组
Series对象的两个重要属性是:index(索引)和value(数据值)
DataFrame的任意一行或者一列就是一个Series对象
创建Series对象:pd.Series(data,index=index)
其中data可以是很多类型:
一个列表---------->pd.Series([1,2,3])
一个ndarray------->pd.Series(np.random.randint(2),index=['a','b'])
一个python字典---->pd.Series({"a":2,"b":0})
一个标量值-------->pd.Series(3,index=[1,2,3])
创建DataFrame对象:pd.DataFrame(data,index,columns)
与Series不同的是,DataFrame包括索引index和表头columns:
其中data可以是很多类型:
包含列表、字典或者Series的字典
二维数组
一个Series对象
另一个DataFrame对象
5.dataframe保存进excel中多个sheet(需要注意一下,如果是在for循环中,就要考虑writer代码的位置了)
# 将日流量写入‘逐日流量’,将位置写入‘格网中的经纬度’
writer = pd.ExcelWriter()
df.to_excel(writer, sheet_name='逐日流量')
df2.to_excel(writer, sheet_name='格网中的经纬度')
writer.save() # 后面可能有writer.close(),但实际不需要,save完后会自动关闭,加close反而会有警告提示。
print(file + " over")更新后出现的警告
`FutureWarning: save is not part of the public API, usage can give unexpected results and will be removed in a future version`或者\`AttributeError: 'XlsxWriter' object has no attribute 'save'. Did you mean: '\_save'?原因:
writer.save()接口已经私有化,close()里面有save()会自动调用,将writer.save()替换为writer.close()即可
更细致的操作:
可以添加更多的参数,比如:
dataframe.to_excel("文件.xlsx", index=False, header=None)
index=False,代表不会导出index,就是最左侧的那一列
header=None,代表不会导出第一行,也就是列头
读写文件注意
df.to_excel(writer, sheet_name='逐日流量', index=False) # header = 0 不要最顶上一行
pandas生成日期去掉时分秒
import pandas as pd
import numpy as np
df = pd.DataFrame({
"date":pd.date_range("20100102",periods=6),
"age":np.arange(6)})
print(df)
df["date"] = df["date"].dt.date #将date列中的日期转换为没有时分秒的日期
df.to_excel("dates.xlsx")向pandas中插入数据
如果想忽略行索引插入,又不想缺失数据与添加NaN值,建议使用
df['column_name'].values得出的是ndarray类型的值,后面的操作就不会限制于索引了
# waterlevel_data_trainx.values是一维数组
new_df['新列名'] = waterlevel_data_trainx.valuesA value is trying to be set on a copy of a slice from a DataFrame.Try using .loc[row_indexer,col_indexer] = value instead
问题:当向列表中增加一列时,需要先将变量复制一份,再添加才可以
a=a.copy()
a['column01']= columnpandas添加索引列名称
baidu.index.name = "列名称"
pandas删除数据
用drop()或者del(),drop()可以不会对原数据产生影响(可以调);del()会删除原始数据
drop()
一次删除多行或多列,比较灵活
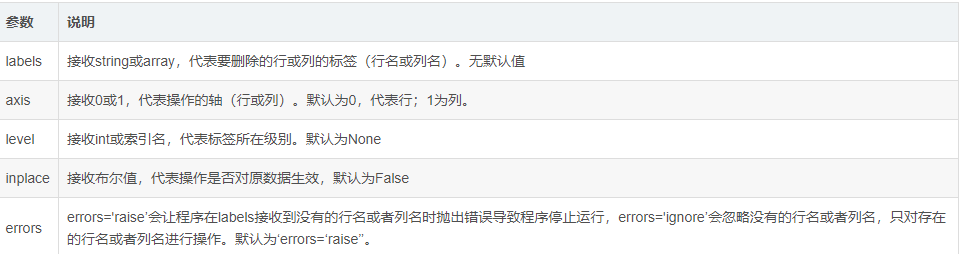
DataFrame.drop(labels,axis=0,level=None,inplace=False,errors=’raise’)
删除特定的多列
# Import pandas package
import pandas as pd
# create a dictionary with five fields each
data = {
'A': ['A1', 'A2', 'A3', 'A4', 'A5'],
'B': ['B1', 'B2', 'B3', 'B4', 'B5'],
'C': ['C1', 'C2', 'C3', 'C4', 'C5'],
'D': ['D1', 'D2', 'D3', 'D4', 'D5'],
'E': ['E1', 'E2', 'E3', 'E4', 'E5']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# Remove two columns name is 'C' and 'D'
df.drop(['C', 'D'], axis=1)
# df.drop(columns =['C', 'D'])根据列索引删除列
# Import pandas package
import pandas as pd
# create a dictionary with five fields each
data = {
'A': ['A1', 'A2', 'A3', 'A4', 'A5'],
'B': ['B1', 'B2', 'B3', 'B4', 'B5'],
'C': ['C1', 'C2', 'C3', 'C4', 'C5'],
'D': ['D1', 'D2', 'D3', 'D4', 'D5'],
'E': ['E1', 'E2', 'E3', 'E4', 'E5']}
python
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# Remove three columns as index base
df.drop(df.columns[[0, 4, 2]], axis=1, inplace=True) # 删除0 2 4三列
dfdel()
一次只能删除一列
read_excel()
data = pd.read_excel(r"Result_Model.xlsx", sheet_name="prediction", engine='openpyxl', skiprows=1) # 先用都昌运行前的数据测试一下,跳过第一行也可以设置成跳过多行,跳过其他行等
参考博客
'DataFrame' object has no attribute 'append'. Did you mean: '_append'?
在我们使用append合并时,可能会弹出这个错误,这个问题就是pandas版本问题,高版本的pandas将append换成了-append
results = results.append(temp, ignore_index=True)
换成
results = results._append(temp, ignore_index=True)
pandas数据转置
与矩阵相同,在 Pandas 中,我们可以使用 .transpose() 方法或 .T 属性来转置 我们的DataFrame数据表。通常情况下, 因为.T的简便性, 更常使用.T属性来进行转置
注意
转置不会影响原来的数据,所以如果想保存转置后的数据,请将值赋给一个变量再保存。如下所示:
import pandas as pd
from faker import Faker
# 你的一维列表数据
data = []
fk = Faker(locale='zh_CN')
for i in range(10):
result = fk.name_female()
data.append(result)
# 创建一个 DataFrame 对象,将列表作为一列数据
df = pd.DataFrame(data, columns=['姓名'])
df_transposed = df.T # 保存为行
# 将 DataFrame 写入 Excel 文件
df_transposed.to_excel('output2.xlsx', index=False)原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
