容器干扰检测与治理(上篇)

容器干扰检测与治理(上篇)

zouyee
发布于 2024-07-25 18:34:56
发布于 2024-07-25 18:34:56
编辑|zouyee
该系列涵盖了不同的使用场景,从runc到containerd,从K8s到Istio等微服务架构,全面展示了Kubernetes在实际应用中的最佳实践。通过这些案例,读者可以掌握如何应对复杂的技术难题,并提升Kubernetes集群的性能和稳定性。
1. Containerd CVE-2020–15257细节说明
2. OpenAI关于Kubernetes集群近万节点的生产实践
3. 一条K8s命令行引发的血案
4. 揭开K8s适配CgroupV2内存虚高的迷局
5. 探索Kubernetes 1.28调度器OOM的根源
6. 解读Kubernetes常见错误码
7. RLIMIT_NOFILE设置陷阱:容器应用高频异常的隐形元凶
从资源分配视图来看,集群分配相对平衡的,但从实际负载情况来看,已经出现较多的热点,此时容易发生应用间竞争共享资源, 导致核心业务出现性能干扰,应用的响应时间往往会出现长尾现象,导致应用服务质量下降,且会增加其故障的可能性,这种应用间的资源竞争及性能干扰(如noisy neighbor现象)使得应用调度与资源管理变得十分复杂,因此考虑如何降低应用间的性能干扰, 以保障业务的稳定性。
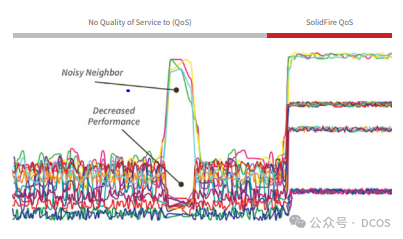
“noisy neighbor”问题是云基础设施中的一种常见现象,指的是当应用程序所需的资源被同一计算节点中的其他应用程序大量占用时,导致应用程序性能降低,如延迟时间增加。这对业务敏感型应用来说,尤其棘手,但通常难以识别。
问题的根源在于资源共享时缺乏严格的隔离策略。从资源层面来看,包括CPU、内存(L1/L2/L3缓存)、网络和块I/O等。从硬件拓扑层面来看,则涉及到CPU缓存、内存带宽等。CPU核心紧密连接着其他可共享资源,如最后一级缓存(LLC)和内存带宽。在分配共享资源时,如果没有有效的隔离策略,问题就会出现。例如,同级超线程共享相同的物理CPU核心,不同物理CPU核心上的工作负载共享相同的最后一级缓存、内存控制器和I/O总线带宽,甚至不同物理CPU插槽上的工作负载也共享CPU互连带宽、相同的存储设备或I/O总线。在这种情况下,”noisy neighbor”往往需要更多的资源,并且需要消耗更多时间才能完成同一任务。这会导致核心应用无法获得所需资源,导致性能下降和stall情况的出现。
Kubernetes提供了CPU管理器和设备插件管理器,用于硬件资源分配,例如CPU和设备(SR-IOV、GPU)。目前,Kubernetes还提供了拓扑管理器,以实现NUMA拓扑感知,协调资源并保证关键工作负载的最佳性能。然而,这些功能并未直接解决”noisy neighbor”问题。
要解决这个问题,可以考虑以下优化策略:
1. 资源请求和限制:在Kubernetes中为每个Pod设置合理的资源请求和限制,以确保应用程序在资源竞争时能获得足够的资源。
2. 亲和性和反亲和性规则:使用Kubernetes的亲和性和反亲和性规则,将关键应用与其他高资源消耗的应用分开部署,减少资源竞争。
3. 隔离策略:利用Kubernetes的CPU隔离策略,确保关键应用独占特定的CPU核心,减少共享资源的争夺。
4. 优先级和抢占:设置应用程序的优先级,确保关键应用可以优先获得资源,并在必要时抢占低优先级应用的资源。
5. NUMA感知调度:通过Kubernetes的拓扑管理器,确保关键应用在NUMA节点内分配资源,最大化本地资源的使用效率,减少跨节点资源访问的延迟。
6. 使用专用硬件:对于需要高性能的应用,考虑使用专用硬件(如GPU、FPGA)或独立的物理节点,避免与其他应用共享资源。
7. 监控和调整:持续监控应用程序的资源使用情况和性能表现,及时调整资源分配策略,确保关键应用的稳定运行。
通过实施这些优化策略,可以在很大程度上缓解”noisy neighbor”问题,保障关键应用程序的性能和稳定性,其中隔离策略、优先级和抢占以及numa感知调度都是针对应用场景的资源QoS优化策略,那么我们如何衡量性能干扰?
混部(混合部署),这里的“混”,本质上就是“区分优先级”。狭义上,可以简单的理解为“在线+离线”(在离线)混部,广义上,可以扩展到更广的应用范围:多优先级业务混合部署

技术背景
名称解释
a. CPI
CPI 即 Cycle Per Instruction 的缩写,它的含义就是每指令周期数。此外,在一些场合,也可以经常看到 IPC,即 Instruction Per Cycle,含义为每周期指令数。
CPI 值越小,表示计算机系统的指令执行效率越高。
CPI 和 IPC 的关系为: CPI = 1 / IPC
如果具体到单 CPU 的程序执行性能场景,实际上可以表示为:

由于受到硅材料和制造工艺的限制,处理器主频的提高已经面临瓶颈,因此,程序性能的提高,主要的变量在 Instruction Count 和 CPI 这两个方面
通常情况下,通过 CPI 的取值,我们可以大致判断一个计算密集型任务,到底是 CPU 密集型的还是 Memory 密集型的:
1. CPI 小于 1,程序通常是 CPU 密集型的;
2. CPI 大于 1,程序通常是 Memory 密集型的;
这只是一个大致的判断方法,不同的任务类型可能会有不同的CPI取值范围,因此需要结合实际情况进行判断。同时,还需要考虑到其它因素,比如内存大小、带宽、CPU的缓存等,才能更全面地判断任务类型。
判断一个计算密集型任务运行效率的重要依据就是看程序运行时的 CPU 利用率。很多人认为 CPU 利用率高就是程序的代码在疯狂运行。实际上,CPU 利用率高,也有可能是 CPU 正在忙等一些资源(非iowait),如访问内存遇到了瓶颈。
一些计算密集型任务,在正常情况下,CPI 很低,性能原本很好。CPU 利用率很高。但是随着系统负载的增加,其它任务对系统资源的争抢,导致这些计算任务的 CPI 大幅上升,性能下降。而此时,很可能 CPU 利用率上看,还是很高的,但是这种 CPU 利用率的高,实际上体现的是 CPU 的忙等,及流水线的停顿带来的效应。
Brendan Gregg 曾在 CPU Utilization is Wrong 这篇博客中指出,CPU 利用率指标需要结合 CPI/IPC 指标一起来分析。
通过perf record,生成CPI 火焰图,其可以展示了程序的 Call Stack 与 CPU 占用率的关联性,而且还揭示了这些 CPU 占用率里,哪些部分是真正的有效的运行时间,哪些部分实际上是 CPU 因某些停顿造成的忙等。
一般可以通过此工具发现系统存在的资源瓶颈,并且通过一些方式来缓解资源的瓶颈;例如,应用间的 Cache 颠簸干扰,可以通过将应用绑到不同的 CPU 上解决。
而应用开发者则可以通过优化相关函数,来提高程序的性能。例如,通过优化代码减少 Cache Miss,从而降低应用的 CPI 来减少处理器因访存停顿造成的性能问题。
b. LLC
旧式的 CPU 会有两级内存(L1 和 L2),新的CPU会有三级内存(L1,L2,L3 ),如下图所示:
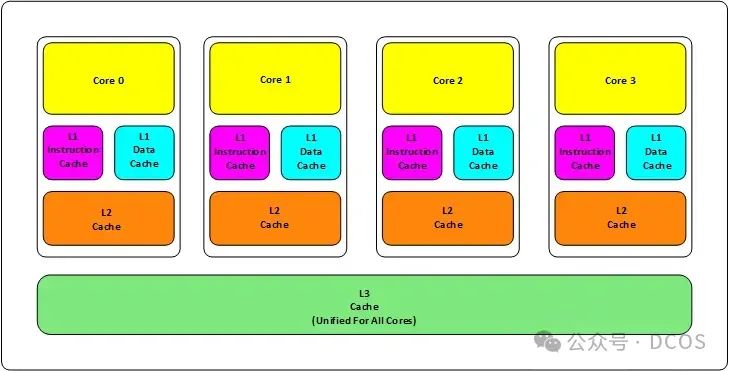
其中:
1. L1 缓存分成两种,一种是指令缓存,一种是数据缓存。L2 缓存和 L3 缓存不分指令和数据。
2. L1 和 L2 缓存在每一个 CPU 核中,L3 则是所有 CPU 核心共享的内存。
3. L1、L2、L3 的越离CPU近就越小,速度也越快,越离 CPU 远,速度也越慢。
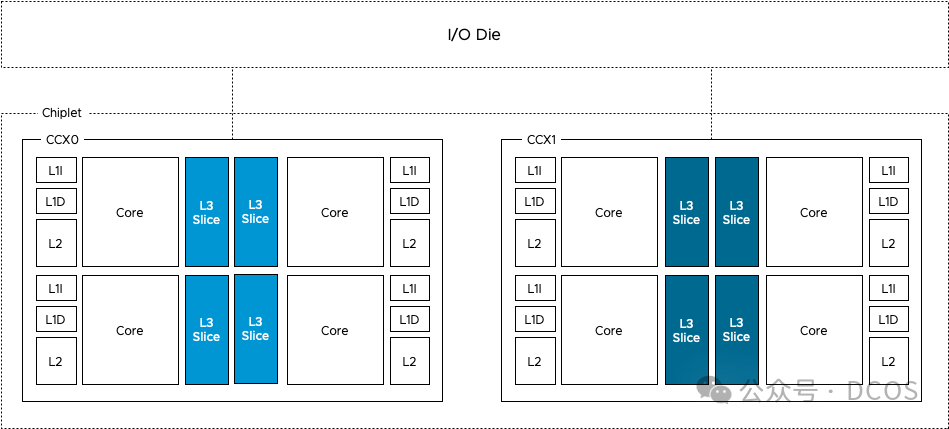
LLC(last level cache)缓存资源作为影响作业性能的重要资源, 其上的干扰同样不可忽略.多个应用在共享缓存时可能出现相互替换的现象, LLC失效时原本访存指令的执行时间将从15ns上升至70ns, 假设CPU主频为3Ghz, 则一条访存指令需要多消耗200多个周期才能完成,消除此类干扰的方法是使用资源划分技术, 在物理上划分多个作业对共享资源的使用,上图所示为经典的多核体系结构, 多个CPU共享了LLC, 运行于不同CPU上的作业会在LLC上发生竞争, Intel Cascade Lake微架构与amd的Rome chiplet, 通过为每个核设置独立的LLC以减少核间对于LLC的资源竞争; 但是, 同一CPU上的多个应用在混部运行时仍然会出现缓存相互替换问题, 因此需要应用级别的缓存划分技术.为了实现应用级别的缓存划分, Intel提出了RDT技术,其中, CAT(cache allocation technology)可为进程或者CGroup分配私有的缓存空间, 避免缓存相互替换;
LLC 缓存的命中率和缺失率的计算方式通常如下:
- LLC 缓存命中率 = L3_CACHE_HITS / L3_CACHE_REFERENCES
- LLC 缓存缺失率 = L3_CACHE_MISSES / L3_CACHE_REFERENCES
其中,L3_CACHE_REFERENCES 表示所有访问 LLC 缓存的事件计数器,L3_CACHE_HITS 表示 LLC 缓存的命中事件计数器,L3_CACHE_MISSES 表示 LLC 缓存的缺失事件计数器。
需要注意的是,这里的事件计数器并不是简单的累加计数器,而是需要进行一定的处理和归一化,才能得到准确的结果。具体处理方法可以参考 pcm-exporter 的文档或者其他类似的文档。
在container环境下,一个运行在container里面的streaming应用不停的读写数据导致大量的LLC占用,会导致同机器上另外一个container里运行的LS需要的数据被evict出LLC,从而导致LS应用性能下降。
指标采集
几种实现路径:
通过cgroup perf_event获取主机所以的应用的CPI指标
unix.IoctlSetInt(p.fd, unix.PERF_EVENT_IOC_ENABLE, 0)
通过node perf获取各cpu的CPI指标,这里使用的go的实现,需要LockOS,然后使用perf_event_open
cadvisor使用libpfm工具,这里要cgo,其中libpfm底层用的perf_event_open
a. node exporter
目前node exporter只支持cpu级别的metrics,具体实现
b. cgroup perf_event
期望支持cgroup级别的metrics,即可以监测属于某个特定的 group 的所有线程以及运行在特定 CPU 上的线程,LWN.net],其中cadvisor支持cgroup perf_event,具体实现
c. 其他指标采集方式
https://github.com/intel/pcm
Intel RDT
以往解决方法是通过控制虚拟机逻辑资源(cgroup)但是调整粒度太粗,并且无法控制处理器缓存这样敏感而且稀缺的资源。为此Intel推出了RDT技术, 相关介绍
RDT技术,全称为Resource Director Technology,提供了两种能力:监控和分配。该技术旨在通过一系列的CPU指令从而允许用户直接对每个CPU核心(附加了HT技术后为每个逻辑核心)的L2缓存、L3缓存(LLC)以及内存带宽进行监控和分配。
Linux Kernel 4.10引入了Intel RDT实现架构,基于 resctrl 文件系统提供了 L3 CAT (Cache Allocation Technology),L3 CDP(Code and Data Prioritization),以及L2 CAT。并且Linux Kernel 4.12进一步实现支持了MBA(Memory Bandwidth Allocation)内存带宽分配技术。
Intel RDT提供了一系列分配(资源控制)能力,包括缓存分配技术(Cache Allocation Technology, CAT),代码和数据优先级(Code and Data Prioritization, CDP) 以及 内存带宽分配(Memory Bandwidth Allocation, MBA)。
Intel至强处理器 E5-xxxx v4系列(即Broadwell)提供了L3缓存的配置以及CAT机制,其中部分通讯相关功能在 E5-xxxx v3系列(即Haswell)引入。一些Intel处理器系列(例如Intel Atom处理器系列)可能支持对L2缓存的控制。此外,MBA共功能提供了相应的处理器核心级别的内存带宽管理。
为了能够在Linux中使用资源分配技术,需要在内核和用户空间引入 resctl 接口。从Linux Kernel 4.10开始,可以使用 L3 CAT, L3 CDP 和 L2 CAT 以及 resctrl 架构。从Linux Kernel 4.12开始,开始引入并正在开发MBA技术, 内核使用说明参见内核文档
RDT技术架构
缓存分配技术CAT(Cache Allocation Technology)的核心目标是基于服务级别(Class of Service, COS 或 CLOS)来实现资源分配。应用程序或者独立线程可以按照处理器提供的一系列服务级别来标记。这样就会按照应用程序和线程的服务分类来限制和分配其使用的缓存。每个CLOS可以使用能力掩码(capacity bitmasks, CBMs)来标志并在服务分类中指定覆盖(overlap)或隔离(isolation)的程度。
对于每个逻辑处理器,都有一个寄存器(被称为 IA32_PQR_ASSOC MSR或PQR)来允许操作系统(OS)或虚拟机管理器(VMM)在应用程序、线程、虚拟机(VM)调度(scheduled)的时候指定它的CLOS。
RDT分为5个功能模块:
1. Cache Monitoring Technology (CMT) 缓存检测技术
2. Cache Allocation Technology (CAT) 缓存分配技术
3. Memory Bandwidth Monitoring (MBM) 内存带宽监测
4. Memory Bandwidth Allocation (MBA) 内存带宽分配
5. Code and Data Prioritization (CDP) 代码和数据优先级
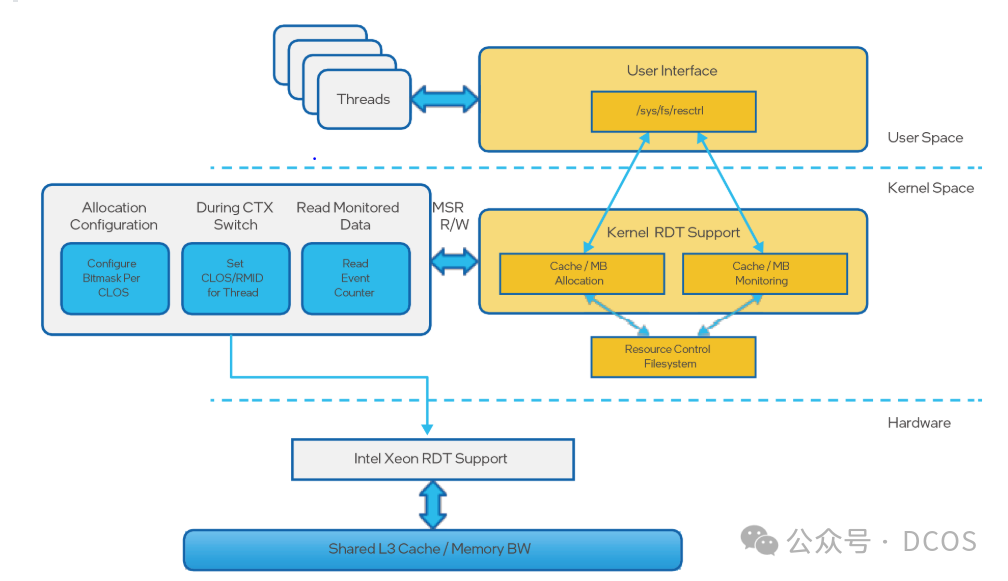
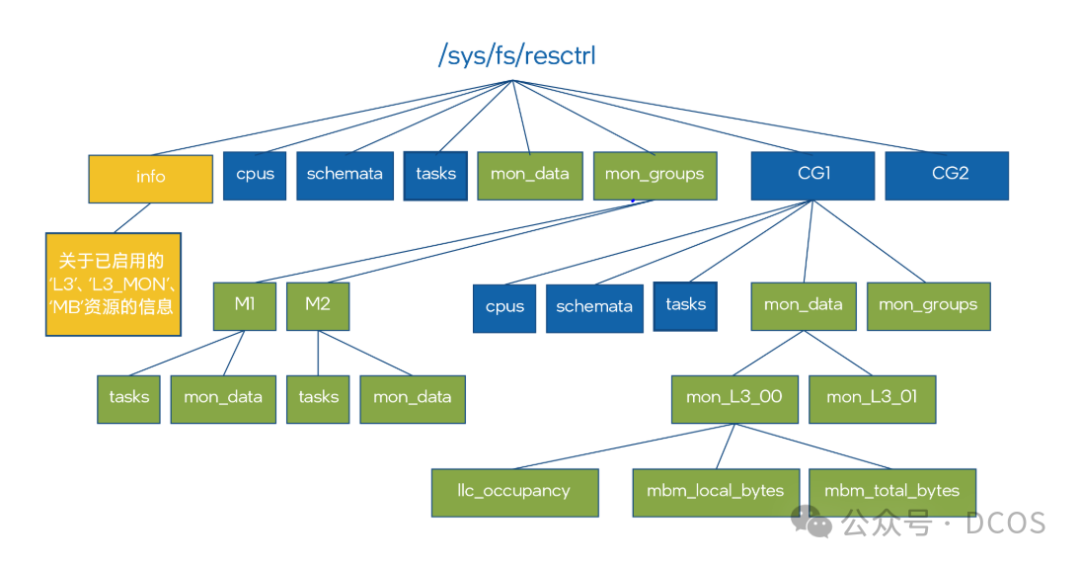
启用 RDT 控制后,可在根目录中创建用户目录(“CG1” 和 “CG2”,见图 4:英特尔® RDT 在 resctrl 文件系统中的分层结构),为每个共享资源指定不同的控制力度。RDT 控制组包含以下文件:“tasks”:读取该文件会显示该群组所有任务的列表。将任务 ID 写入文件会添加任务到群组。“cpus”:读取该文件会显示该群组拥有的逻辑 CPU 的位掩码。将掩码写入文件会添加 CPU 到群组或从群组中移除 CPU。“schemata”:该群组可访问的所有资源的列表。
启用 RDT 监控功能后,根目录和其他顶层目录会包含 “mon_groups” 目录,在此目录中可以创建用户目录(“M1” 和 “M2”,见图 4:英特尔® RDT 在 resctrl 文件系统中的分层结构),以监控任务群组。“Mon_data” 目录包含一组按照资源域和 RDT 事件组织的文件。这些目录中,每个目录针对每个事件都有一个文件(“llc_occupancy”、“mbm_ total_bytes” 和 “mbm_local_bytes”)。这些文件为群组中的所有任务提供了事件当前值的计数器。

理论基础
CPI2 : CPU performance isolation for shared compute clusters
性能指标
CPI
核心方法
Google的方法,完全基于历史数据做统计分析,不需要单独做压测,方法简单。Google基于历史数据,对CPI与RT的相关性做论证,得出对于链路处于叶子,且主要为CPU型的应用,相关性有0.97;其他一些服务,如部分IO型,中间节点服务,仍然0.7+的相关性。所以确定CPI可以作为性能的proxy。在线作业通常为常驻作业,这类作业在同一CPU型号的CPI数据走向通常呈现一定规律,是可预测的。所以用传统的滑动窗口预测方法,对下一周期的CPI进行预测。
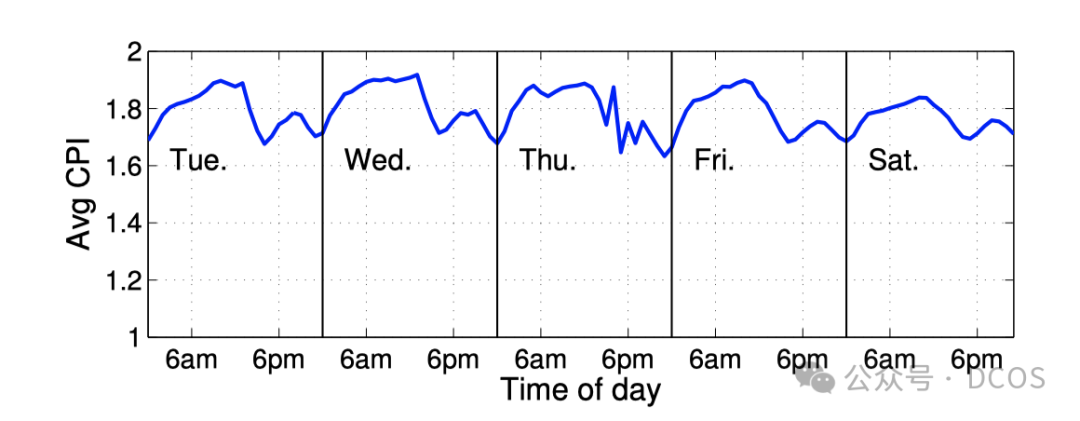
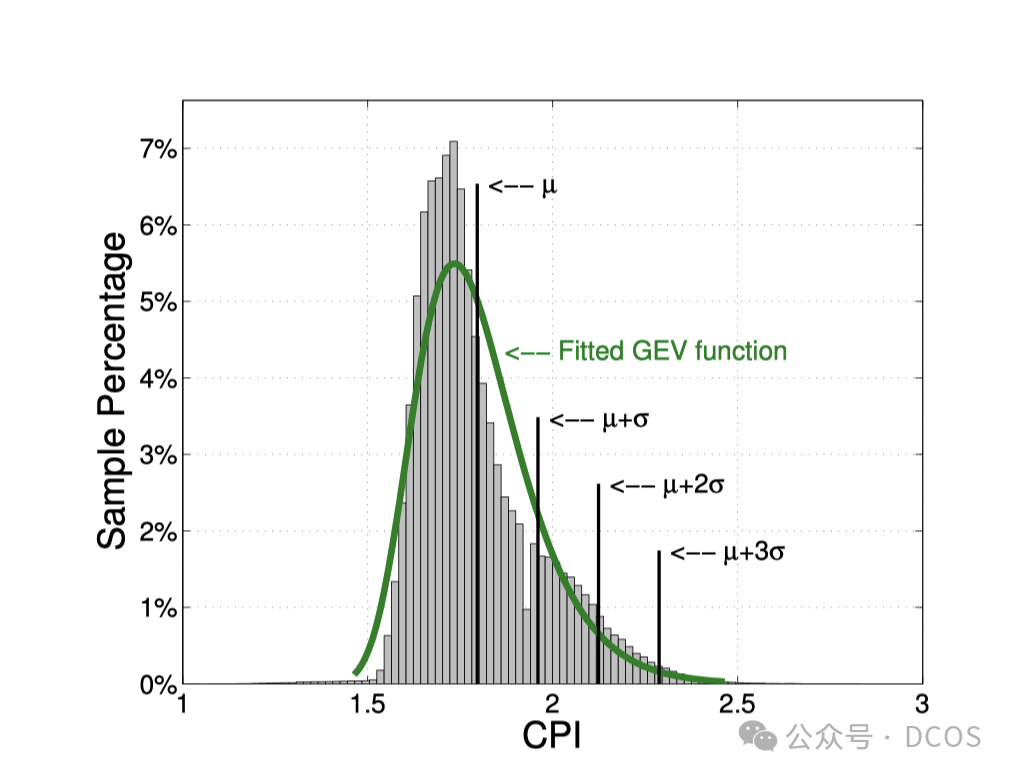
并且每天CPI的数据分布都相差不大,所以可以直接用统计的方法,算前一天CPI的平均值CPIavg,及标准差stddev,设置 CPIavg + 2 * stddev为阈值,超过该值,认定QoS受到影响。同时,为了避免误判,规则为5min中内发现3次超过,才确定QoS受到影响。
结论
实验数据表明,CPI与干扰相关性线性系数为0.97
LIBRA: Clearing the Cloud Through Dynamic Memory Bandwidth Management
性能指标
CPI
核心方法
阿里这篇文章的主要贡献在于如何更细粒度的调整LLC;Intel RDT提供了CAT和MBA两种技术(用法与cgroups相似,由于推入container runtime太慢了,intel专门开源了intel-resource-manager支持他家的黑科技),前者是对LLC size的隔离,后者是对L2-L3内存带宽的隔离;由于两个维度单独调整的粒度都是10%,粒度太粗;阿里通过CAT和MBA结合,实现更细粒度的调整。其中用CPI做干扰检测,但是阿里是用压测的方式计算出;RT与CPI的相关性,构建RT=k*CPI+l like线性方程;从而用实时的CPI,计算出大致的RT值,判断应用QoS是否超过SLA。
结论
CPI与干扰线性相关,根据CPI计算RT,据此调整LLC、MBA等资源隔离
PARTIES: QoS-Aware Resource Partitioning for Multiple Interactive Services
指标
Latency(ms)
核心方法
压测得出单应用最合适的Latency-targetQoS(加压直至Latency与压力曲线出现拐点),资源维度为<cpu core, cache way, cpu frequency, mem space, disk bandwidth>,对应的调整粒度为<1 core, 1 way, 100MHz, 1GB, 1GB/s>* 500ms检测一次QoS,如果发现与targetQoS偏离过大,则开始调整资源,对每个应用每轮尝试不同的资源up/down(等于猜受干扰资源),直至保证了机器所有应用的QoS。文章提供了很好的思路,资源是可交换的,即发现干扰时,不用统一扩容或缩容资源,文章的背景是所有在线应用部署在一个集群里,一台机器各维度资源有限,那就通过交换,比如把io密集型应用的cpu让给cpu密集型的。从而保证每个应用具有合适的资源。
由于笔者时间、视野、认知有限,本文难免出现错误、疏漏等问题,期待各位读者朋友、业界专家指正交流,上述排障信息已修改为社区内容。
参考文献
1.Caelus—全场景在离线混部解决方案
2.Google Borg 2015:https://research.google/pubs/pub43438/
3. Google Borg 2019:https://dl.acm.org/doi/pdf/10.1145/3342195.3387517
4. Google Autopilot:https://dl.acm.org/doi/pdf/10.1145/3342195.3387524
5.百度千寻:百度大规模战略性混部系统演进
6.阿里伏羲:https://yq.aliyun.com/articles/651202
7.阿里k8s混部:https://static.sched.com/hosted_files/kccncosschn19chi/70/ColocationOnK8s.pdf
8.CPI论文: https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/40737.pdf
9.Heracles论文:https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/43792.pdf
10.Bubble-up论文:https://ieeexplore.ieee.org/document/7851476
11.Linux kernel perf architecture (terenceli.github.io)
12. resolving noisy neighbors (intel.com)
13. Maximizing Resource Utilization with cgroup2
14. 字节跳动:混布环境下集群的性能评估与优化
15. 混部之殇-论云原生资源隔离技术之CPU隔离(一)
16. CN106776005A - 一种面向容器化应用的资源管理系统及方法
17. hodgesds/perf-utils
18. 用CPI火焰图分析Linux性能问题
19. 在离线混部作业调度与资源管理技术研究综述
20. 从混部到统一调度
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-07-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号