首个超越GPT-4o的开源模型:LLAMA3.1开源了
原创
今年4月份的时候,META发布了自己的第三代开源模型LLAMA3,并且在那次就说了LLAMA3目前还在训练当中。
到现在不到3个月,META的LLAMA3.1在今天已经正式发布

有意思的是,在今天发布的稍早时候,模型已经在Reddit上被泄露出来了,并且连模型的效果对比图都整出来。(这不知道是多少次META的模型被泄露了!)

开源模型的几个亮点
从官方放出的LLAMA3.1来看,有以下几个关键要点:
- 模型上下文长度扩展:目前LLAMA3.1已经把模型上下文长度扩充到128K,对比于LLAMA2只有4k~8k,其提升幅度还是比较大
- 模型开源版本覆盖8B、70B和405B
- 模型效果更强:在多个测试集上效果都要优于GPT-4o模型
- 训练数据大小:模型训练的数据集来自于公开的15T数据
- 微调数据集:微调数据仅用了公开可用的指令微调数据集,同时也加上了自己合成的1500万个样本
- 模型目前支持多语言:包括法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语(但好像还是暂时不支持)
从对比图上看,LLAMA3.1 405B模型在多个测试集上的效果都已经超越了OpenAI的GPT-4o模型。
从下面图片中可以看到,LLAMA3.1在boolq、gsm8k、hellaswag等多项测试中优于GPT-4o,仅有HumanEval、MMLU-social sciences、truthfulqa_mc1这三项测试中低于GPT-4o。
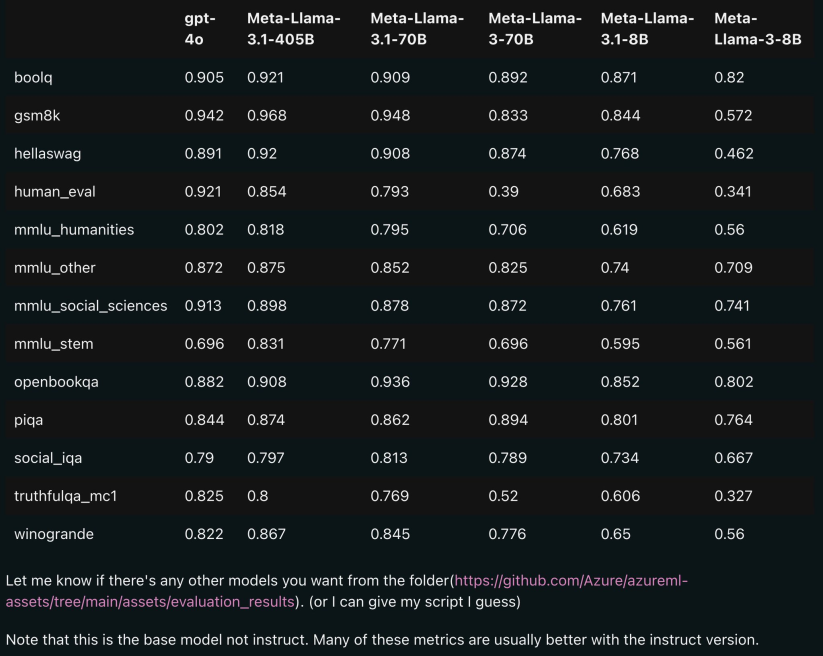
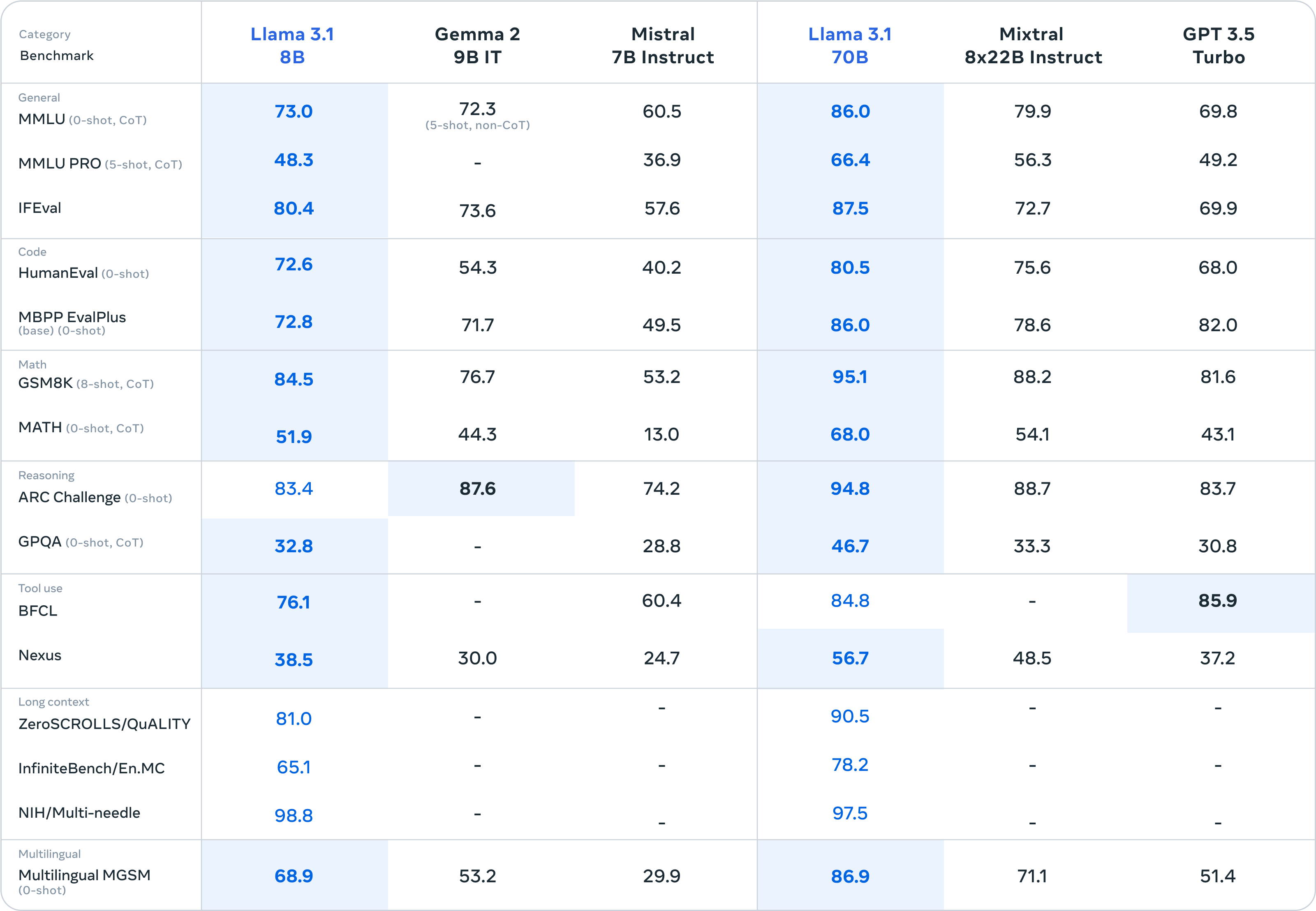
同时LLAMA3.1模型还有开源的70B、8B,并且这较小模型与具有相似参数数量的其他模型对比来看,在多个测试集上效果也更强:
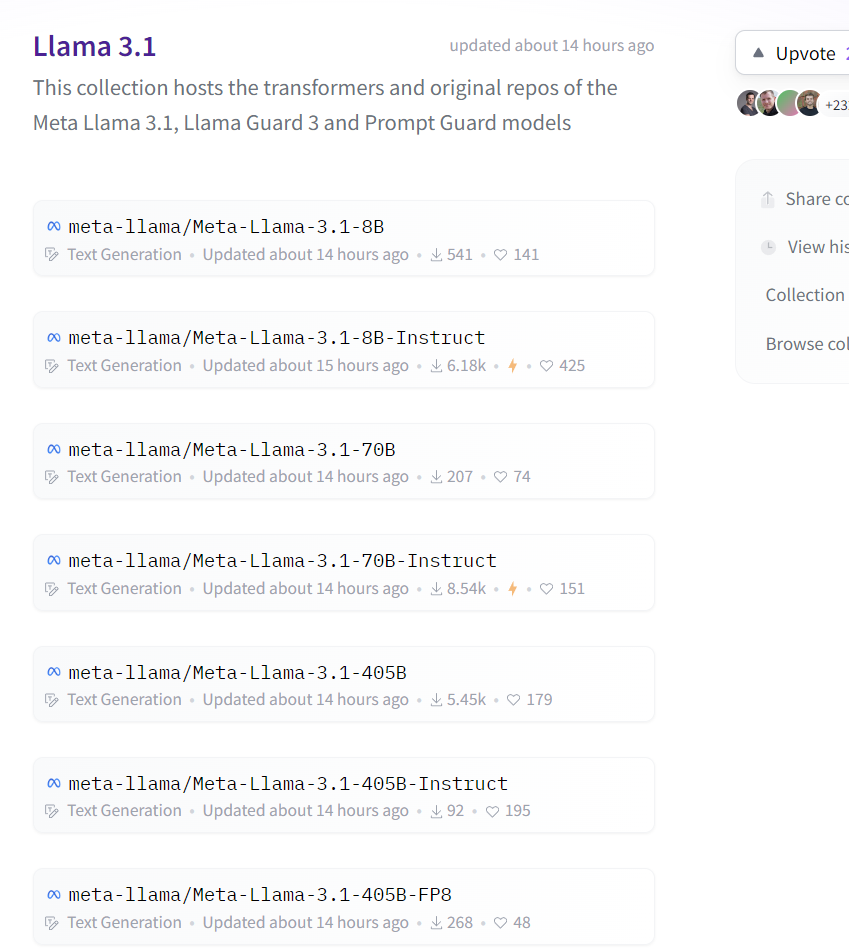
目前可以在huggingface网站上下载LLAMA3.1,META提供了多个不同的版本,也包括经过指令微调过后的模型版本
https://huggingface.co/collections/meta-llama/llama-31-669fc079a0c406a149a5738f
模型架构
META在模型训练的时候,用到了15万亿的token,同时在16000涨H100的GPU上进行训练。
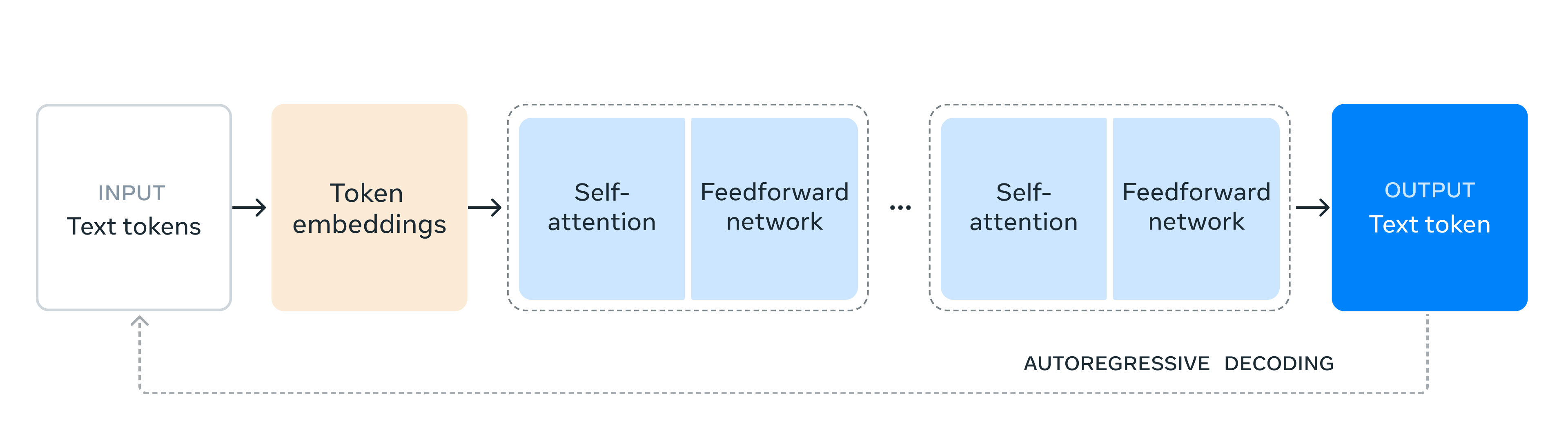
由于模型高达405B的参数量级,META做出了两个关键点:
- 没有使用MOE架构(混合专家模型),而是只使用decoder-only transformer进行训练,这是因为MOE架构的模型往往在训练的时候不稳定且难以收敛
- 使用后训练技术(post-training),每次迭代都利用有监督的微调和偏好优化。这样可以在每次迭代的过程中使用高质量的合成数据提升模型在下游中的性能
模型实测效果
拿最近比较火的数学问题问LLAMA3.1,发现它还是回答错误
9.9和9.11哪个大?

第二道题主要是判断模型能不能识别用户的文字情绪。从结论上来看,对于句子中的情绪符号识别都比较准确。
Q2:请判断这些句子中表达的情绪:我的猫好可爱♥♥

第三题是逻辑推理
逻辑推理:赵三的父母结婚的时候,为什么没有邀请自己参加
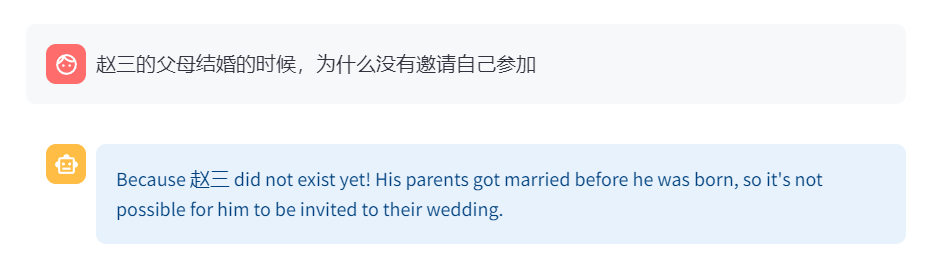
在伦理逻辑上,模型知道了“赵三”是他们的孩子,所以不可能参加他们的婚礼
开源的LLMAM3.1能够超越GPT-4吗?
虽然这个405B的大模型在一定程度上已经超越了GPT-4o,但是超越了目前的4o模型,并不代表能够超越OpenAI的GPT-4模型,要知道4o是在GPT-4的基础上优化了两个版本(GPT-4 TURBO - GPT 4O)而得来的。
同时由于这个模型参数量过大,已经有网友觉得性价比不高,普通人想要在自己电脑上跑起来肯定是不现实:
要运行一个这么大的模型,本质上已经和调用OpenAI的API没有什么区别,普通人一样是玩不转的。
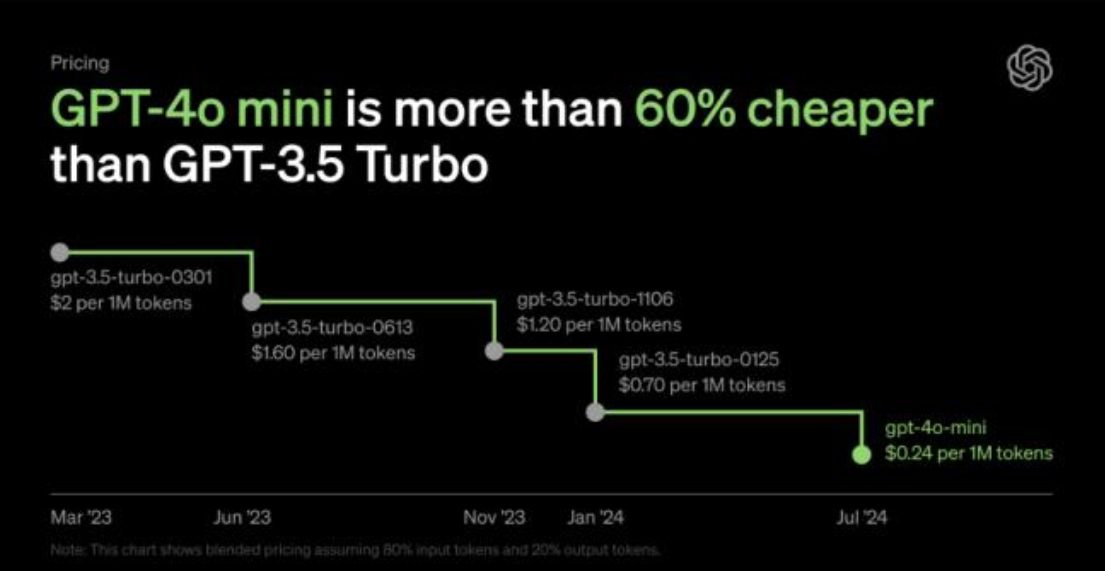
特别是上周OpenAI发布了自己的小模型GPT-4o mini,它在性能超越GPT-3.5的同时,价格还更加便宜:其价格比GPT-3.5 Turbo便宜超过60%,定价为每100万个输入token才15美分和每100万个输出token则为60美分(大约相当于一本标准书的2500页)。
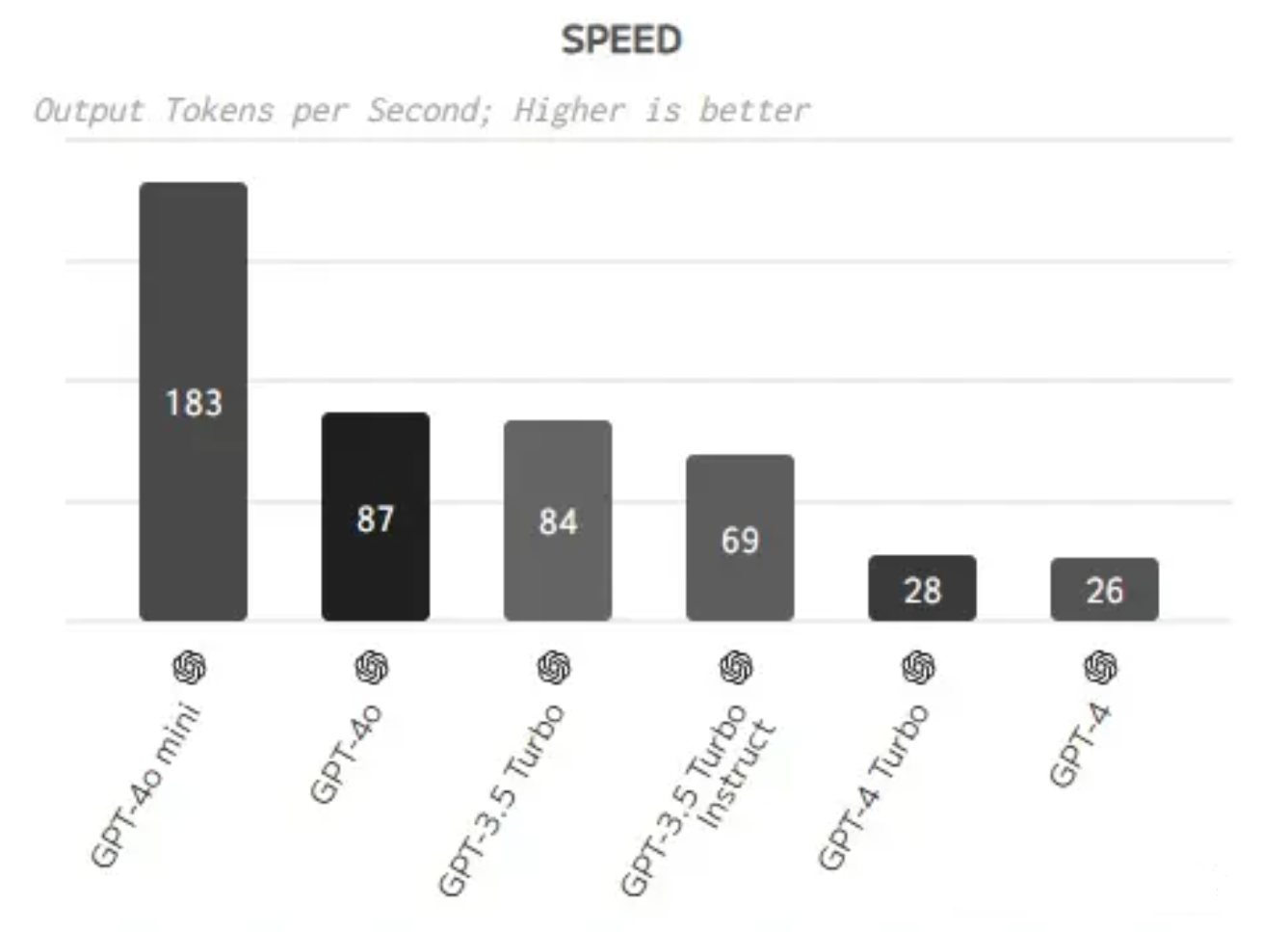
从相应速度来看,GPT-4o mini明显比OpenAI其他模型推理速度要快得多。应该是因为其参数量不大,所以速度提升明显。
而LLAAM3.1从网友反馈来看,就算对Llama3.1-405B就算进行大幅度优化,其推理速度很慢,对硬件要求很高。这在硬件层面上就吓退了很多开发者了。
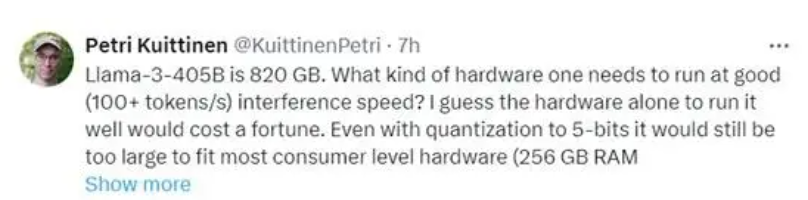
OpenAI目前都在开始卷小模型市场,GPT-4o mini或许能够成为最具性价比的大模型。因此一直走开源路线的LLAMA3.1还需要不断继续优化,成为普通人都能用到的一个性价比更好的大模型才是关键。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
