Java内存模型(JMM)解析:为何并发编程如此重要?
原创
Java内存模型(JMM)解析:为何并发编程如此重要?
原创
努力的小雨
发布于 2024-08-15 09:29:09
发布于 2024-08-15 09:29:09
计算机
现代计算机的架构,尤其是冯·诺依曼模型,为我们提供了一个理解计算机如何工作的框架。在这一模型中,CPU与主内存之间的交互是至关重要的。我们不必过多关注输入输出设备,而是将焦点放在计算器和存储器之间的数据流动上。IO总线作为数据流通的桥梁,不仅连接了CPU和磁盘,还承载着来自显示器、键盘和鼠标等外围设备的数据流。然而,CPU的GHz级计算速度与内存的MB级数据传输速度之间的巨大差异,催生了多级缓存技术,从L1到L3,它们在缓解IO瓶颈的同时,也带来了缓存一致性的挑战。
首先,我们需要详细讲解计算机的模型:现代计算机模型是基于冯·诺依曼计算机模型,这一模型不仅仅是计算机科学的基石,更是我们理解和设计计算机系统的重要框架。
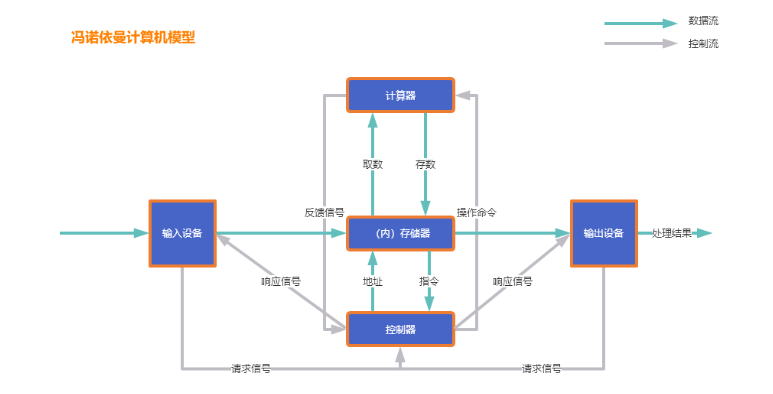
在计算机系统中,我们无需过多关注输入输出设备,因为最关键的是中央处理器(CPU)与主内存之间的数据交互过程,即CPU从主内存中取数并进行计算、再将结果存回主内存的动态过程。
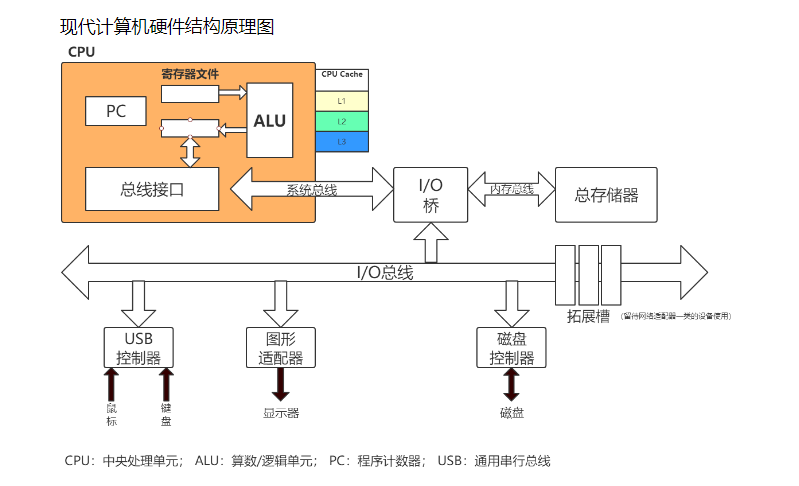
当我们观察计算机系统时,可以看到一个重要的IO总线负责数据的传输。因此,CPU与磁盘之间的交互也必须经过IO总线。然而,IO总线上还有其他设备的数据流动,比如显示器、鼠标和键盘等。当前的CPU计算速度通常达到GHz级别,而内存的输出却通常以MB为单位,这给CPU带来了显著的影响。因为每次取数都必须通过IO总线,这不可避免地会影响IO性能。为了缓解这一问题,CPU引入了三级缓存(L1、L2、L3),这些缓存存储了常用的指令集和数据,如下图所示:
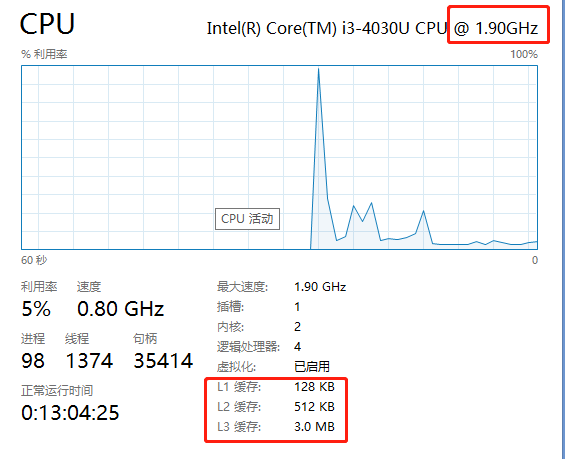
在CPU读取存储器数据的过程中,各级缓存的影响可以描述如下:
当CPU需要获取寄存器XX的值时,操作仅需一步:直接读取即可。
若CPU需获取L1缓存中的某个值,则可能需要1-3步甚至更多:首先要锁定特定的缓存行,获取数据,然后解锁。如果未能成功锁定缓存行,则读取速度可能会受到影响。
访问L2缓存的数据则更为复杂,因为必须先从L1缓存中寻找数据。若在L1中未找到,CPU则需将数据从L2复制到L1,这可能涉及到多个步骤的加锁和解锁过程。
同样,访问L3缓存的过程类似,需要先从L3复制到L2,然后再从L2复制到L1,最终再传输到CPU。
而当CPU需要访问主内存时,过程最为复杂:首先需要通知内存控制器占用总线带宽,然后请求内存加锁,发出内存读取请求并等待响应。响应数据将被保存到L3缓存(或者L2缓存,如果L3中未找到),然后再从L3或者L2复制到L1,最终传输到CPU,完成后再解除总线锁定。
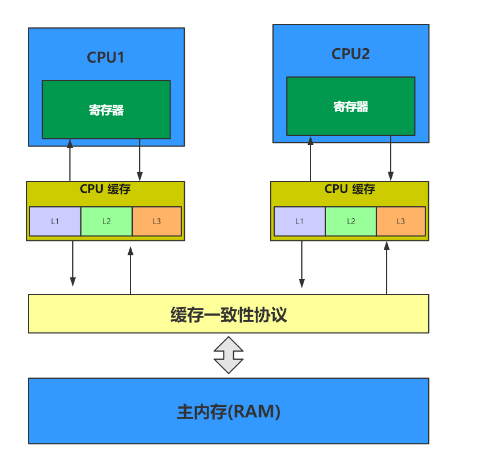
在多处理器环境下,为了保证数据一致性,必须遵循一些协议如MESI(修改、独占、共享、无效),以确保各个CPU之间的数据同步问题得到有效管理,最终确定以哪个缓存中的数据为最终结果。
什么是线程
在现代操作系统中,当启动一个程序(比如Java程序)时,操作系统会为其创建一个进程。这个进程是操作系统进行资源分配和调度的基本单位。进程可以被视为一个独立的运行环境,它包含了程序的代码、数据以及程序运行时所需的各种资源。
在一个进程内部,可以创建多个线程。线程是操作系统调度的最小执行单位,也被称为轻量级进程(Light Weight Process)。每个线程都有自己的计数器、堆栈、局部变量等属性,并且可以访问共享的内存变量,这使得线程之间可以进行有效的信息共享和协作。
处理器能够在这些线程之间高速切换,从而使得用户感觉到这些线程在同时执行。这种并发执行的感觉是通过操作系统和处理器的调度和管理来实现的。
线程的实现可以分为两大类:用户级线程、内核线程
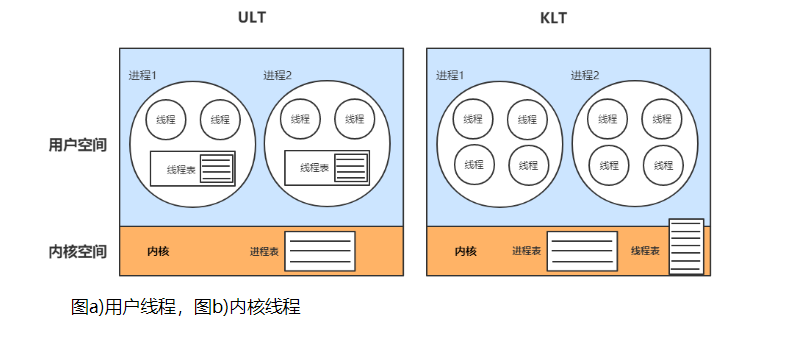
用户线程
用户线程,也称为用户级线程,是指在用户程序中实现的线程,不依赖于操作系统核心的支持。应用进程通过线程库提供的函数来创建、同步、调度和管理这些用户线程。与内核线程相比,用户线程不需要进行用户态和核心态之间的切换,因此其执行速度相对较快。
在用户线程的实现中,操作系统内核并不知道线程的存在,它只知道进程的存在。因此,如果一个用户线程被阻塞,整个进程(包括其所有线程)都会被阻塞。这是因为操作系统将处理器时间片的分配以进程为基本单位进行,而不是以线程为基本单位。
用户线程的优点在于其快速的创建和上下文切换,这使得它们适合于对并发性能有高要求的应用。然而,由于无法利用操作系统的多核调度功能,用户线程在利用多核处理器时可能会出现效率不高的情况。
内核线程
内核线程是由操作系统内核来管理和调度的线程形式。所有关于线程的创建、调度以及状态管理等操作都由操作系统内核完成。每个内核线程都有其自己的状态和上下文信息,这些信息由内核负责保存和维护。
当一个内核线程执行了可能引起阻塞的系统调用时,操作系统内核可以智能地调度同一进程中的其他线程来继续执行,从而最大程度地利用系统资源,特别是在多处理器系统中,可以同时将属于同一进程的多个线程分配到多个处理器上运行,以提高进程执行的并行度和整体性能。
相较于用户级线程,内核线程的管理操作速度要慢得多,因为它们涉及到操作系统内核的介入和复杂的调度算法。然而,与整个进程的创建和管理相比,内核线程的创建和管理操作仍然更加高效和快速。
几乎所有主流的操作系统,例如Windows、Linux等,都广泛支持内核级线程的实现和管理,这使得开发者可以根据具体应用的需求选择合适的线程模型,以达到最优的性能和效率。
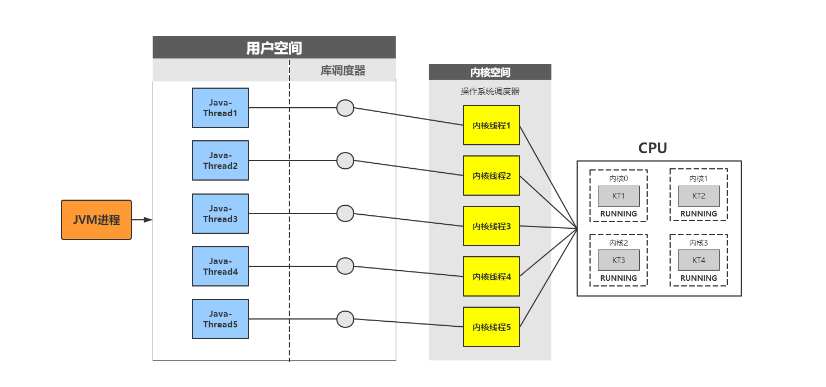
当我们在Java虚拟机(JVM)中创建一个线程时,实际上是在操作系统的内核空间中创建了一个对应的线程。这种做法确保了操作系统不需要知道Java虚拟机内部的线程存在,而只需知道整个JVM进程的存在。因此,如果JVM中的任何一个线程被阻塞,操作系统不会对CPU进行上下文切换,从而可能导致整个JVM进程的阻塞。
为什么用到并发?
并发编程的本质是利用多线程技术,特别是在现代多核CPU的背景下,这种技术趋势愈发显著。通过并发编程,可以充分利用多核CPU的计算能力,从而极大地提升系统的性能。此外,面对复杂的业务模型,使用并行程序比串行程序更能够适应业务需求,因为并发编程更符合这种业务模型的需求拆分。
即使在单核处理器上,也能够支持多线程执行代码。CPU通过分配给每个线程时间片来实现这一机制。时间片是CPU分配给各个线程的一段时间,在这段时间内,线程可以执行其任务。由于时间片非常短暂,通常只有几十毫秒(ms),因此CPU通过快速切换线程的执行顺序,让我们感觉多个线程在同时执行。
并发与并行并非同一概念:并发指的是多个任务交替进行,而并行则是指在同一时刻真正地同时进行。在实际应用中,即使系统只有一个CPU,在使用多线程时,任务仍然是通过时间片轮转的方式交替执行,这被称为并发执行。真正的并行执行只能在拥有多个CPU的系统中实现。
并发的优点包括:
- 充分利用多核CPU的计算能力,提高系统整体的处理效率。
- 方便进行业务拆分,通过将任务分解成多个并发执行的部分,可以提升应用的响应速度和性能。
然而,并发也会带来一些问题:
- 在高并发场景下,会导致频繁的上下文切换,因为CPU需要在不同的线程之间快速切换执行。
- 存在临界区线程安全问题,例如竞争条件和死锁,这些问题可能会导致系统功能不可用。
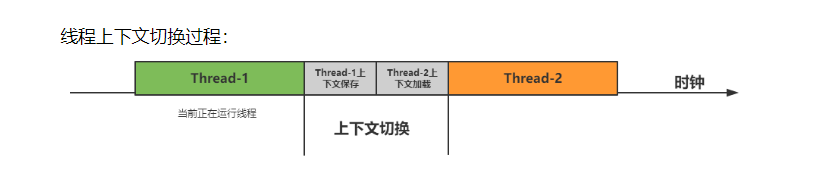
CPU在执行任务时通过分配时间片来实现每个线程的轮流执行。每次切换到下一个任务时,CPU会保存当前任务的状态,以便在需要切换回来时能够恢复执行。因此,任务从保存到再加载的过程称为一次上下文切换。
什么是JMM模型
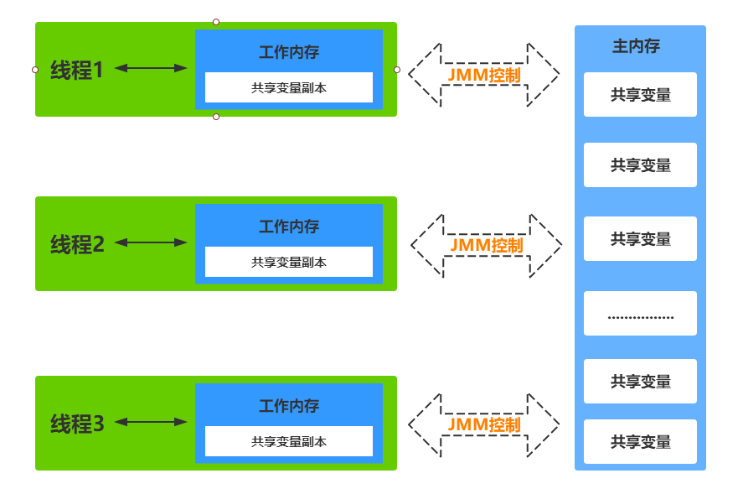
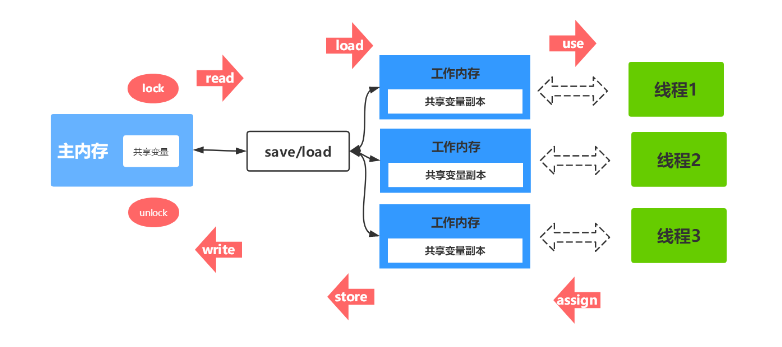
Java内存模型(JMM)并非实际存在的物理结构,而是一种规范,用于定义程序中各个变量的访问方式。在JVM中,程序的执行实体是线程,每个线程在创建时都会有一个私有的工作内存(有时称为栈空间),用于存储线程私有的数据。根据Java内存模型的规定,所有变量都存储在主内存中,主内存是所有线程共享的内存区域,所有线程都可以访问。
然而,线程对变量的操作(如读取、赋值等)必须在自己的工作内存中进行。具体来说,当线程需要操作某个变量时,首先会将该变量从主内存中拷贝到自己的工作内存空间,然后进行操作。操作完成后,再将变量的最新值写回主内存。重要的是,线程不能直接操作主内存中的变量,而是操作工作内存中的变量副本。
由于每个线程都有自己的工作内存,因此不同线程之间无法直接访问对方的工作内存。线程之间的通信(传递值)必须通过主内存来完成,即一个线程修改了变量后,其他线程需要通过主内存来获取最新的值。
JMM主要围绕着三个概念展开:
- 原子性(Atomicity):指一个操作是不可中断的。即使在多个线程同时执行的情况下,一个操作的执行过程中不会被其他线程干扰。
- 有序性(Ordering):指程序执行的顺序按照代码的先后顺序来执行。在JMM中,程序的执行可能会进行指令重排序,但JMM通过一些规则来保证最终执行的结果与代码顺序一致。
- 可见性(Visibility):指一个线程修改了共享变量的值,其他线程能够立即看到修改后的值。为了保证可见性,通常需要使用同步机制(如锁、volatile变量等)来确保数据的同步更新。
Java内存模型(JMM)中的八种同步操作可以详细解释如下:
- lock(锁定):作用于主内存的变量,将一个变量标记为线程独占状态,确保后续的操作对该变量的访问是排他的。
- unlock(解锁):作用于主内存的变量,释放一个处于锁定状态的变量,使其可以被其他线程锁定并修改。
- read(读取):作用于主内存的变量,将一个变量的值从主内存复制到线程的工作内存中,以便后续的load操作使用。
- load(载入):作用于工作内存的变量,将read操作从主内存中获取的变量值放入工作内存的变量副本中,供线程使用。
- use(使用):作用于工作内存的变量,将工作内存中的一个变量值传递给执行引擎,用于执行计算或其他操作。
- assign(赋值):作用于工作内存的变量,将执行引擎接收到的值赋给工作内存中的变量,更新其值。
- store(存储):作用于工作内存的变量,将工作内存中的一个变量的值传送到主内存中,以便随后的write操作使用。
- write(写入):作用于工作内存的变量,将store操作从工作内存中的一个变量的值传送到主内存中的变量,更新主内存中的值。
在Java内存模型中,为了保证多线程程序的正确性,读取和写入操作必须按照一定的顺序执行,以确保数据的可见性和一致性。尽管JMM要求这些操作按顺序执行,但并没有强制要求它们必须连续执行,这允许了一定的优化空间,比如指令重排序等,只要最终的执行结果与顺序执行的结果一致即可。
总结
在本文中,我们深入探讨了计算机科学的核心概念,包括现代计算机的冯·诺依曼模型、CPU与内存的交互、以及多级缓存技术对性能的影响。文章还阐释线程的工作原理,区分用户级线程与内核级线程,并讨论并发编程的优势与挑战。特别地,我们剖析了Java内存模型(JMM),它规定了线程如何安全地访问和修改共享变量,以及如何通过同步机制维护数据的一致性。通过这些内容,读者可以对计算机架构、操作系统调度、并发编程和内存管理的全面理解。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位掘金优秀作者、腾讯云内容共创官、阿里云专家博主、华为云云享专家。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号