从Berkeley DB,认识没有服务进程的内嵌式数据库
原创从Berkeley DB,认识没有服务进程的内嵌式数据库
原创
前言
说起数据库,很多人第一时间想到的是MySQL、oracle这样的关系型数据库,亦或者是redis这种KV结构的内存数据库。这些数据库在我们的生产环境中都是随处可见的。
后来我在学习python的爬虫框架Scrapy的时候,其中scrapy-deltafetch插件,解决了每次启动无法从上次结束位置接着爬取的问题。在深入学习的过程中了解到,scrapy-deltafetch这一功能是由嵌入式数据库Berkeley DB实现的。
嵌入式数据库
平时我们使用的 MySQL、redis 等,都需要在服务器上首先部署独立的软件服务,然后每个服务监听一个端口(例如MySQL的3306、redis的6376)。然后我们在编程开发中,通过客户端或者SDK连接这些服务。
这也意味着如果想获取MySQL、redis中的数据,用户程序要和就要和它们进行通讯,且出现网络波动、网络中断都会影响正常的数据库连接和请求。
那什么是嵌入式数据库呢?顾名思义,嵌入式数据就是将数据库嵌入到了应用程序进程中,同应用程序在相同的地址空间中运行,所以程序和嵌入式数据库不需要进程间(程序与服务)的通讯。
其次,嵌入数据库是一种具备了基本数据库特性的数据文件,提供了一套API去访问、管理一个数据库文件,采用程序方式直接驱动,而非引擎响应方式驱动。
常见的内嵌式数据库
在我的大数据开发生涯中,我遇到过三种内嵌式数据库:
- SQLite:SQLite是一个关系型的SQL数据库引擎。
- Berkeley DB:Berkeley DB是一个高性能的嵌入式数据库,支持键值存储模式。我在scrapy-deltafetch插件中第一次了解。
- RocksDB:从LevelDB派生出来的一个键值数据库引擎,我在学习flink开发的时候,RocksDB用作存储状态后端。
Berkeley DB安装
为了进一步更好地理解在嵌入式数据库章节中提到的理论,这里就用BerkeleyDB来做一个对于内嵌式数据库的操作。
我在这里选择python,python提供了berkeleydb和bsddb3两个库来操作BerkeleyDB。操作系统使用的Linux和macos(这两个系统的操作都一样),之所以没有选择windows,是因为windows安装bsddb3模块,确实比较麻烦,后面会讲。
1. Berkeley DB安装
在oracle的官网下载BerkeleyDB的安装包,然后解压,编译、安装。
cd build_unix
../dist/configure --prefix=/usr/local/BerkeleyDB
make & make install 2. 模块安装
这样,在我们的Linux系统上就安装成功了BerkeleyDB。然后就安装berkeleydb和bsddb3模块。
export BERKELEYDB_DIR=/usr/local/BerkeleyDB
export YES_I_HAVE_THE_RIGHT_TO_USE_THIS_BERKELEY_DB_VERSION=yes
pip3 install bsddb3
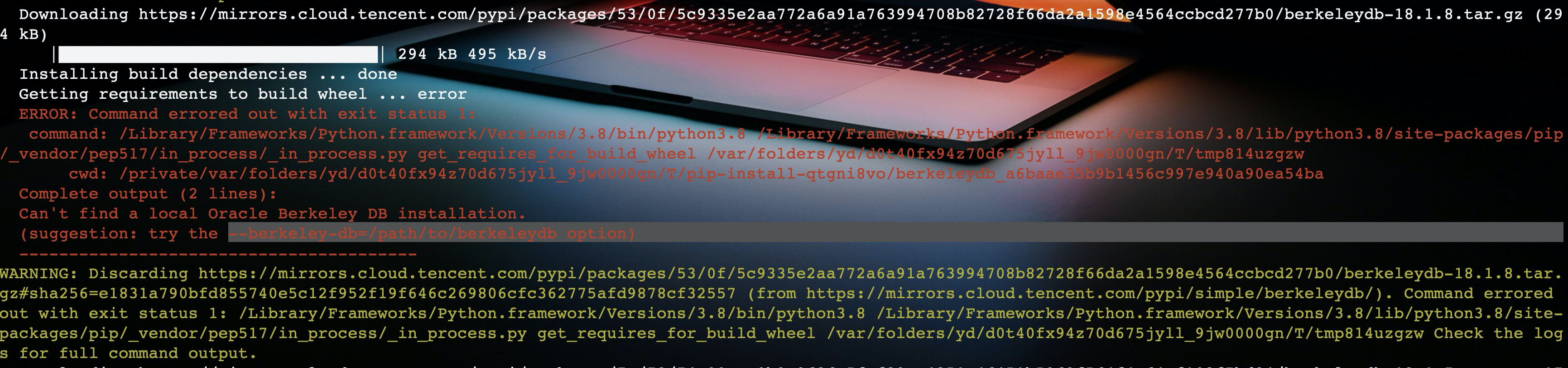
pip3 install berkeleydb如果我们不设置变量BERKELEYDB_DIR的话,在使用pip安装模块时,就会提示让你指定BerkeleyDB的安装目录,这样才能将“将数据库嵌入到了应用程序进程中”。
BerkeleyDB 从版本 6.x 开始使用了GPL(GNU Affero General Public License) 许可证。这意味着,如果你使用该版本的BerkeleyDB,并将其集成到你的软件中,那么根据 AGPL 许可证的规定,你的整个软件也必须开源,除非你有一个与Oracle公司签订的商业许可协议。
为了确保开发者在使用 Berkeley DB 版本 6.x 或更高版本时理解并接受这些许可证条款,Berkeley DB的源代码中包含了一段代码,要求开发者明确设置 YES_I_HAVE_THE_RIGHT_TO_USE_THIS_BERKELEY_DB_VERSION 这个宏。在编译代码时,你需要显式定义这个宏来确认你有权使用当前版本的 Berkeley DB。
如果不指定的话,在安装的时候就会失败,并给出响应的提示。

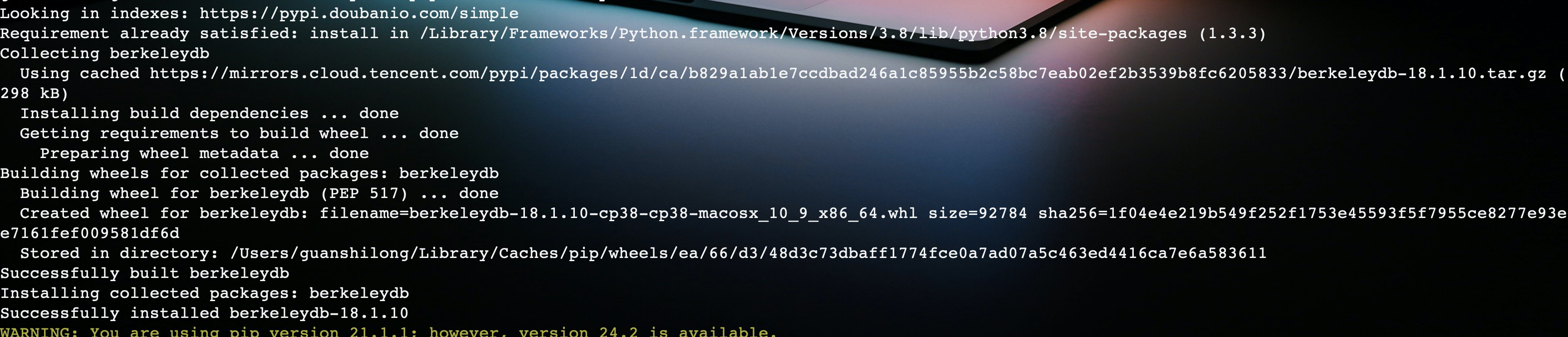
最后,成功安装berkeleydb模块。
数据库操作
要想使用MySQL,我们首先要create database,然后create table,这样我们就可以通过MySQL的客户端和SDK,对表数据做增删改查。

MySQL
MySQL有自己的数据库管理系统,在创建数据库会默认在/var/lib/mysql下创建一个同名目录,然后表数据都会存放在这个目录下。
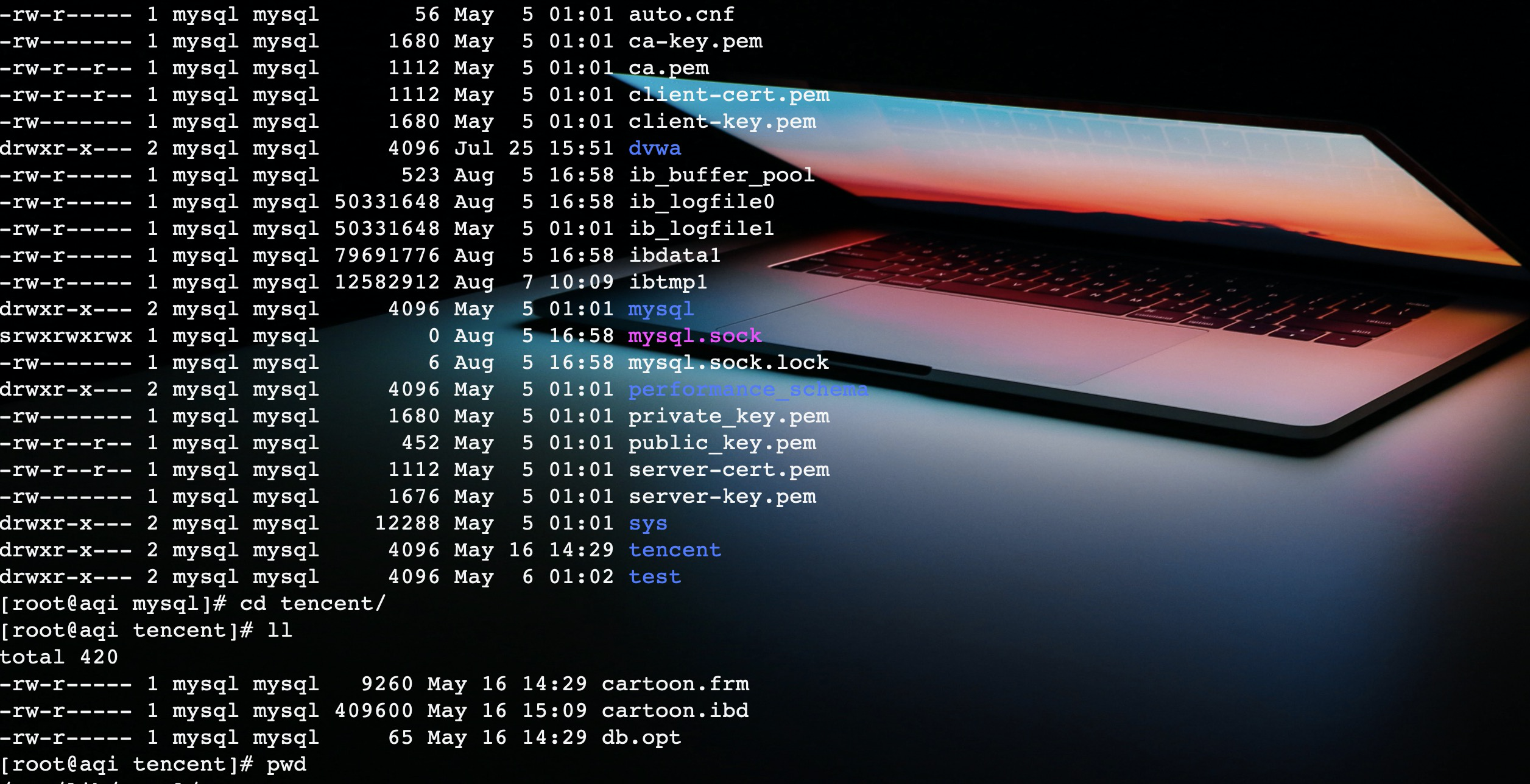
如图,我在tencent数据库下有一个cartoon表,在MySQL的文件系统中的tencent目录下,就有对应的cartoon.idb,其中 .ibd 文件包含表的数据和索引。
redis
而对于redis来说,数据是放在内存中的,当机器宕机或者redis服务故障重启的时候,内存中的数据就会丢失。为了解决这个问题,redis使用RDB(Redis DataBase)和AOF(Append Only File)来持久化数据,当重启时可以从持久化文件中加载数据。
从上面的信息可以看出,MySQL和redis都有自己的文件系统,且数据文件都存放在服务所在的服务器上。
Berkeley DB
在Berkeley DB内嵌数据库中,它也有自己的文件系统,但是因为内嵌式数据库是与程序一起运行的,所以数据文件是放在程序目录(客户端)中的。
而且因为内嵌式数据库没有自己的服务,我们就无法通过类似MySQL、redis这种终端命令去创建数据库,以及对数据的增删改查。只能在程序中通过API来操作数据库。例如,我使用berkeleydb模块来来创建一个数据库。
import berkeleydb
db = berkeleydb.hashopen('aqi.db', 'c')
db[b'aqi'] = b'qi'
print(db[b'aqi'])其中,'c' 表示创建数据库,如果不存在的话;如果已存在,则打开数据库。因为Berkeley DB是一个KV数据库,所以将字符串'aqi'作为key存放到数据库中。运行程序:
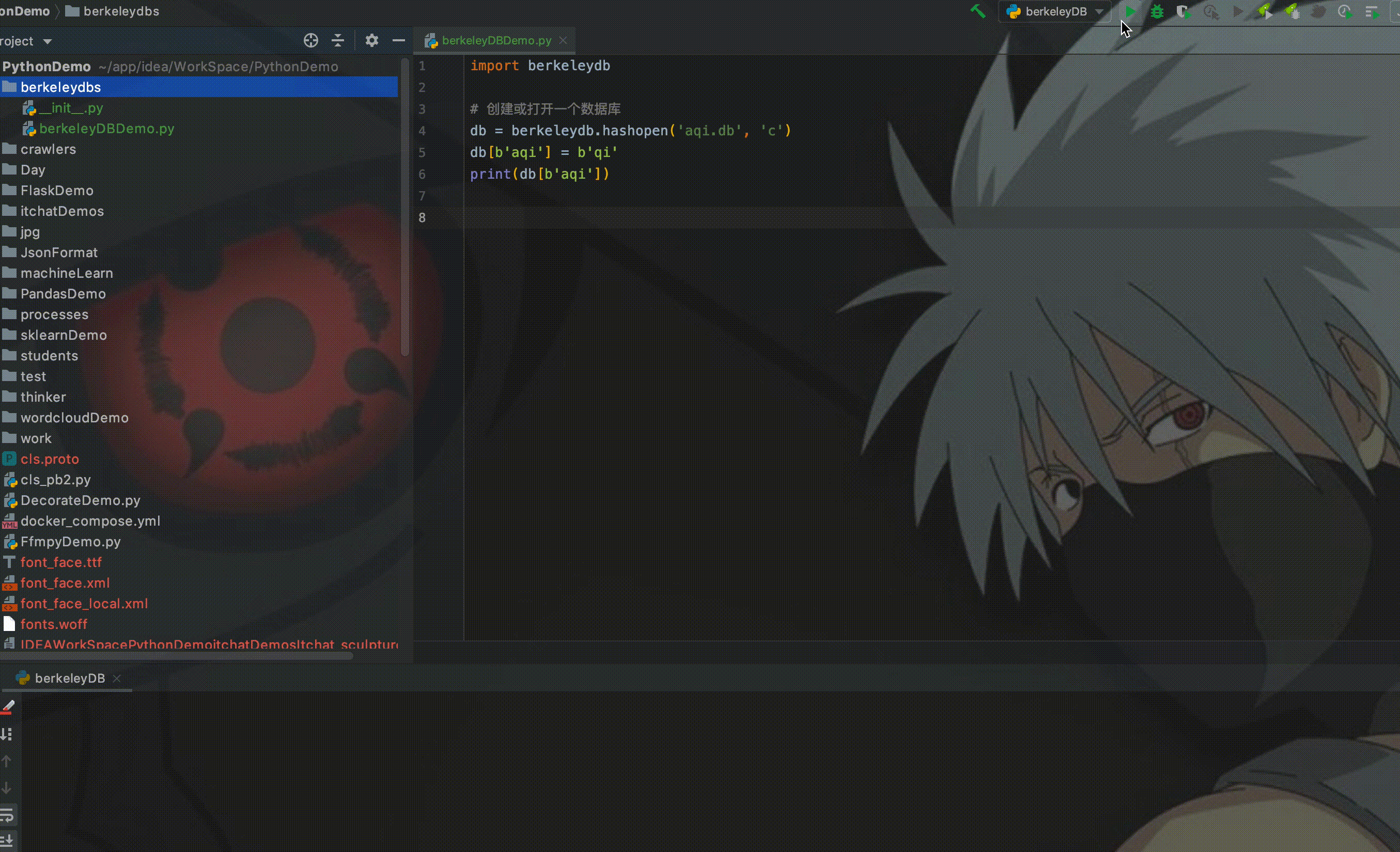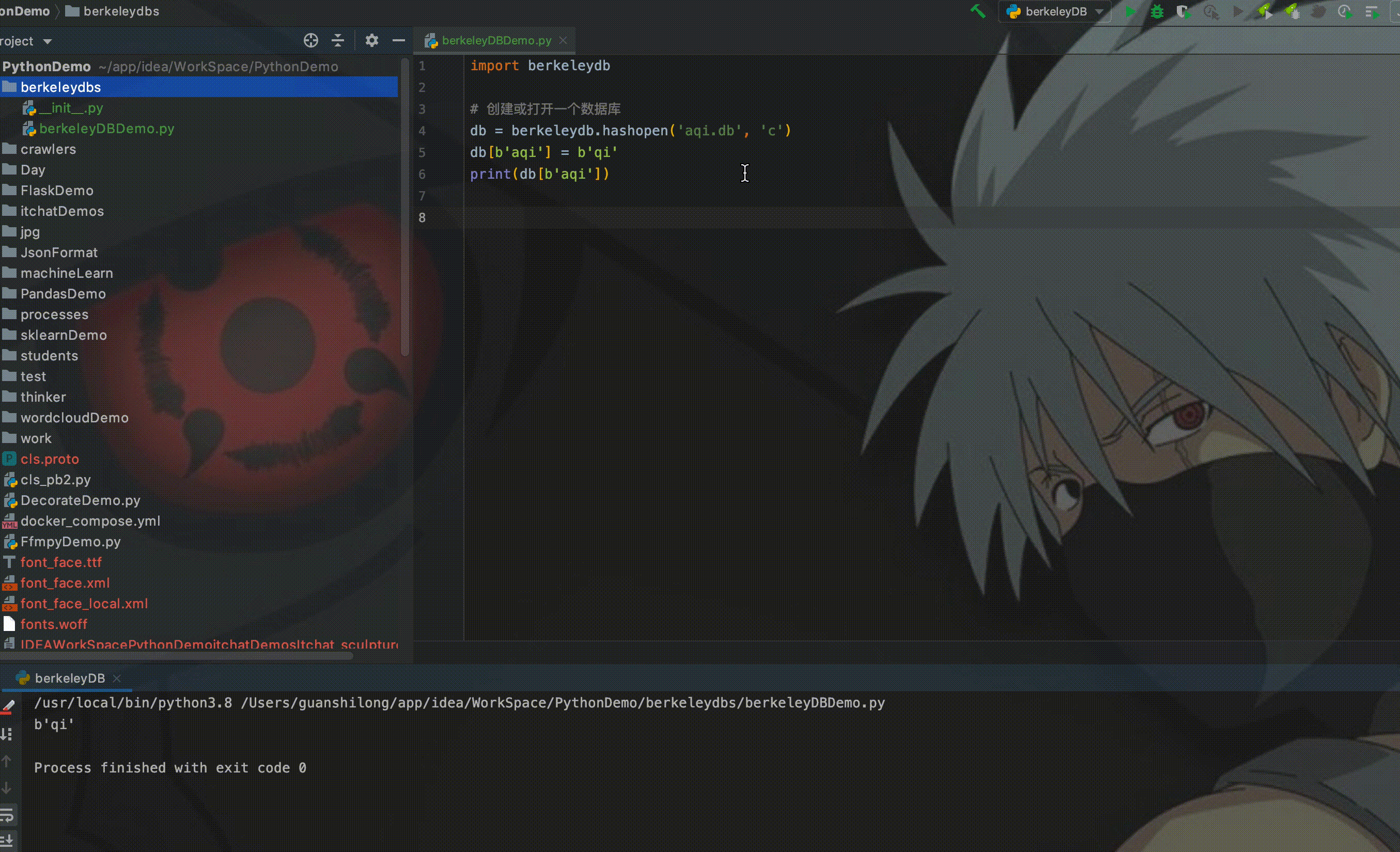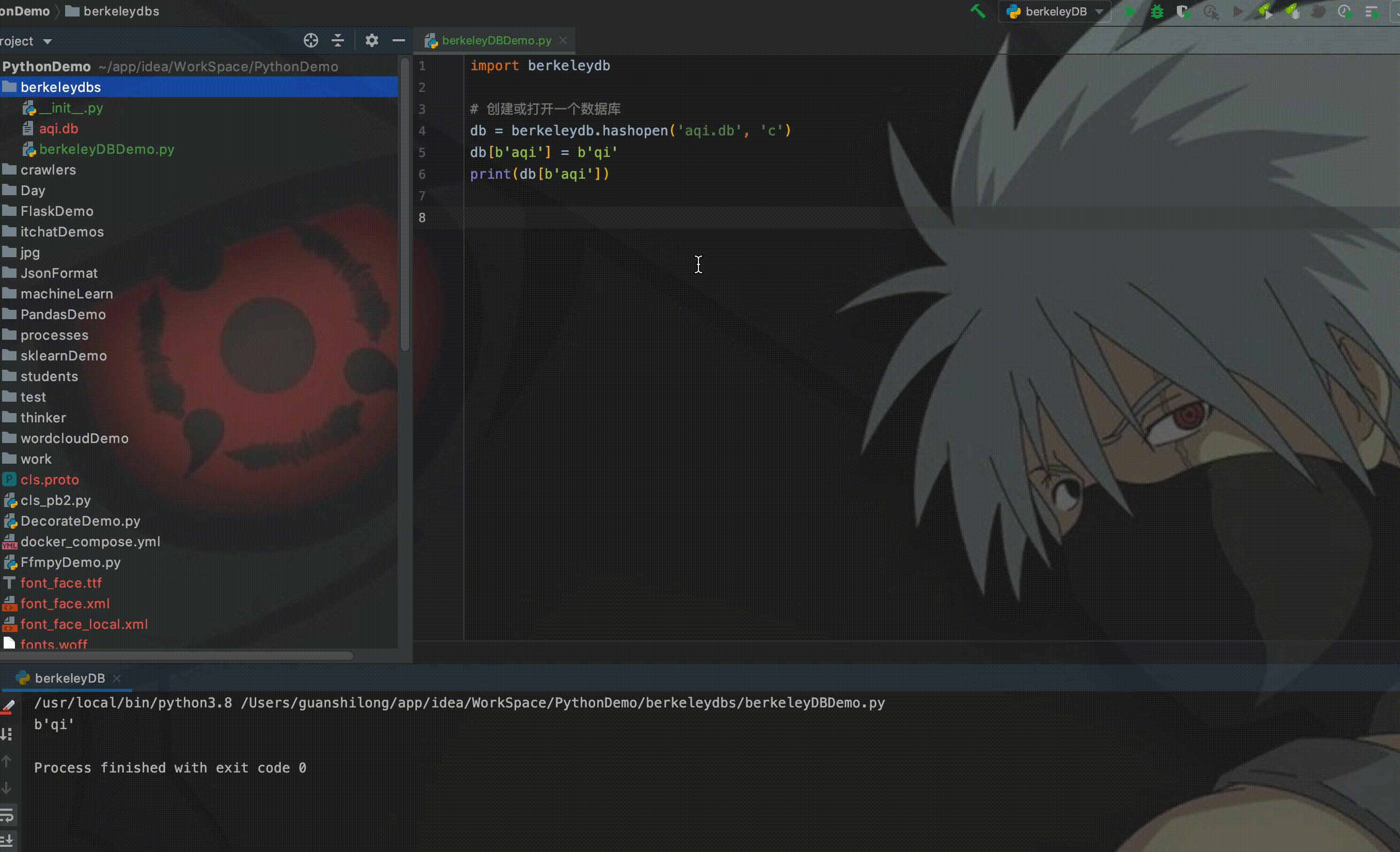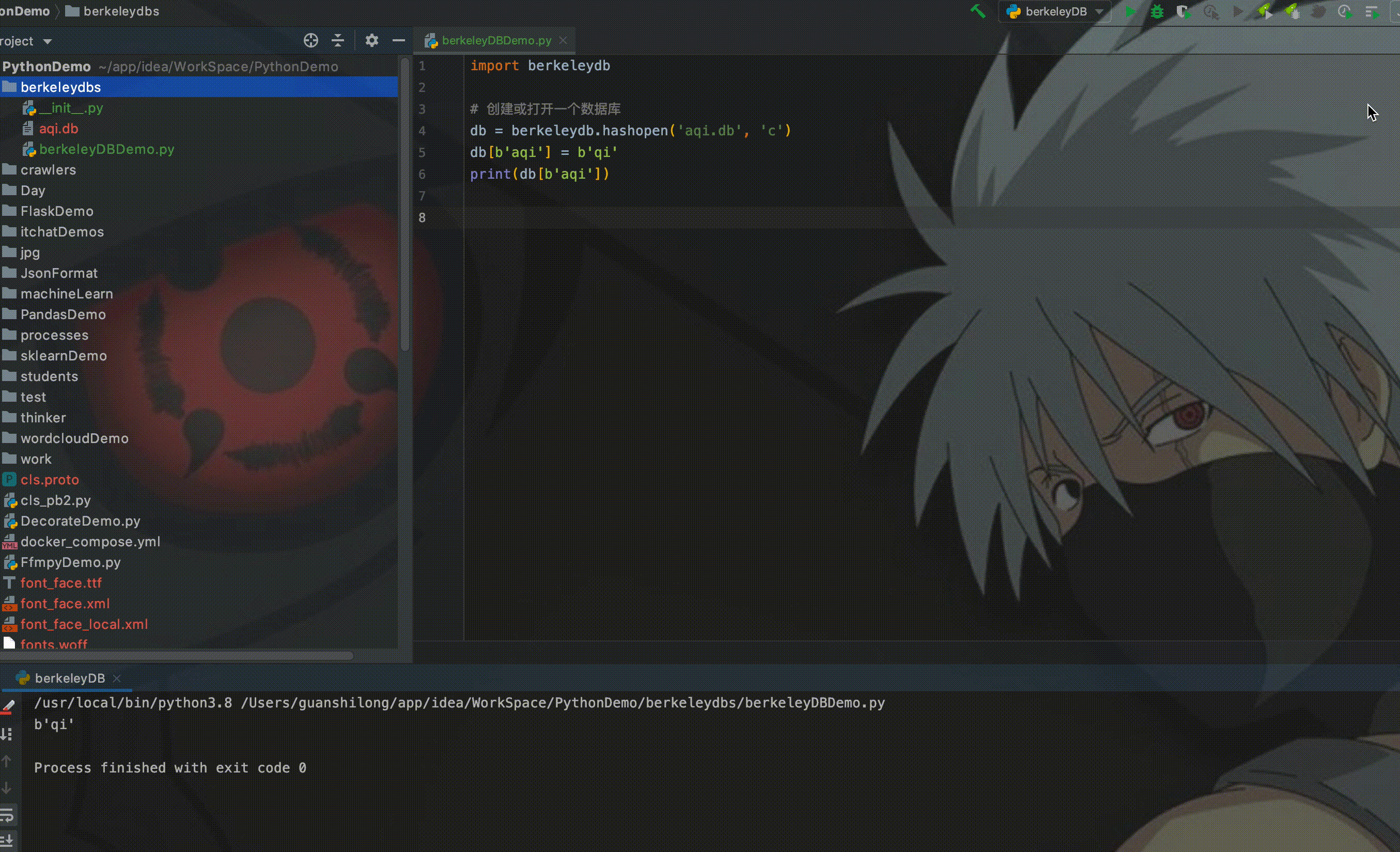
如图所示,从右侧可能看到创建了一个aqi.db的数据文件,在控制台也打印出来从Berkeley DB中获取的数据。这时候如果我们删除存放数据的代码,直接获取数据库中的数据,运行程序:
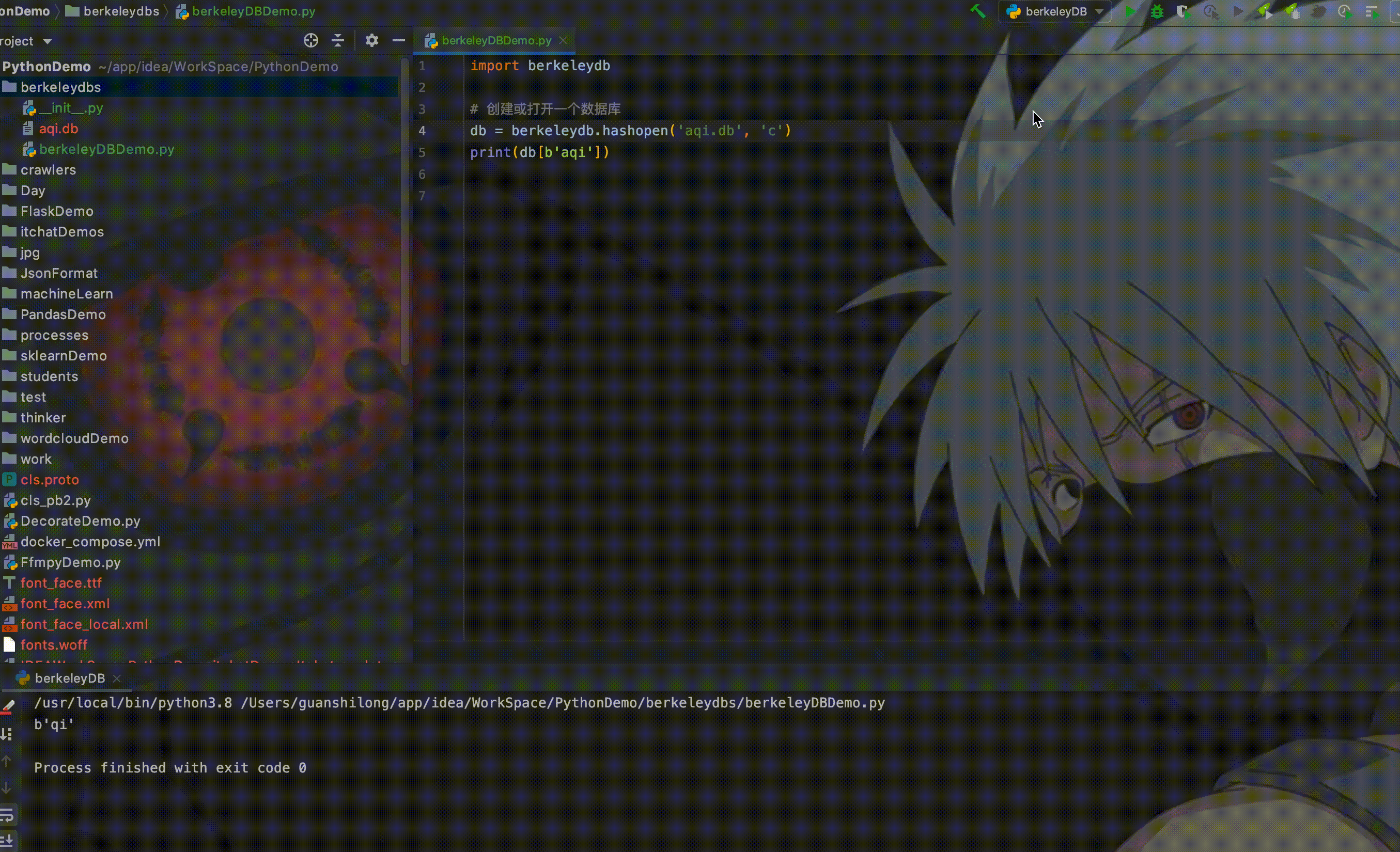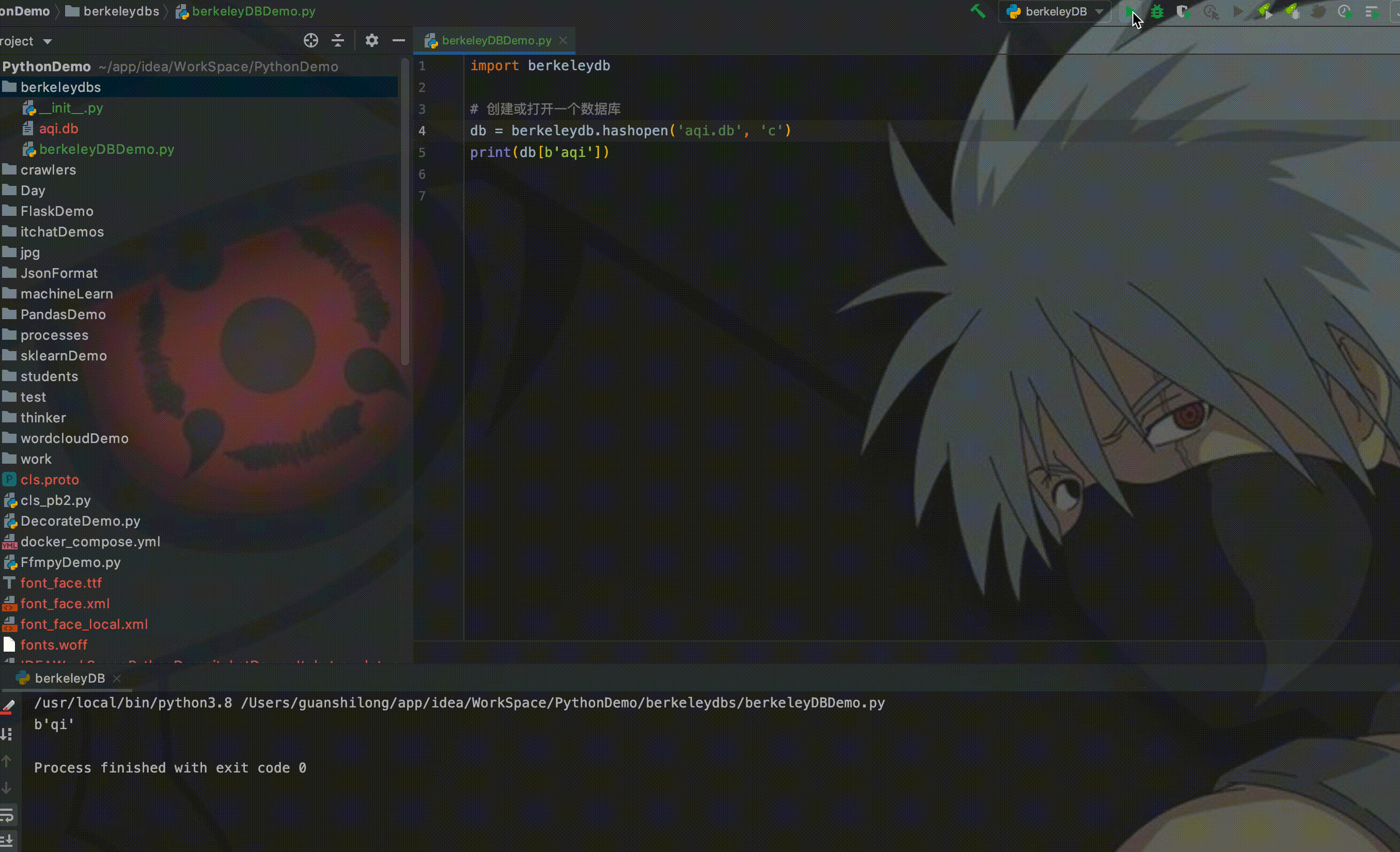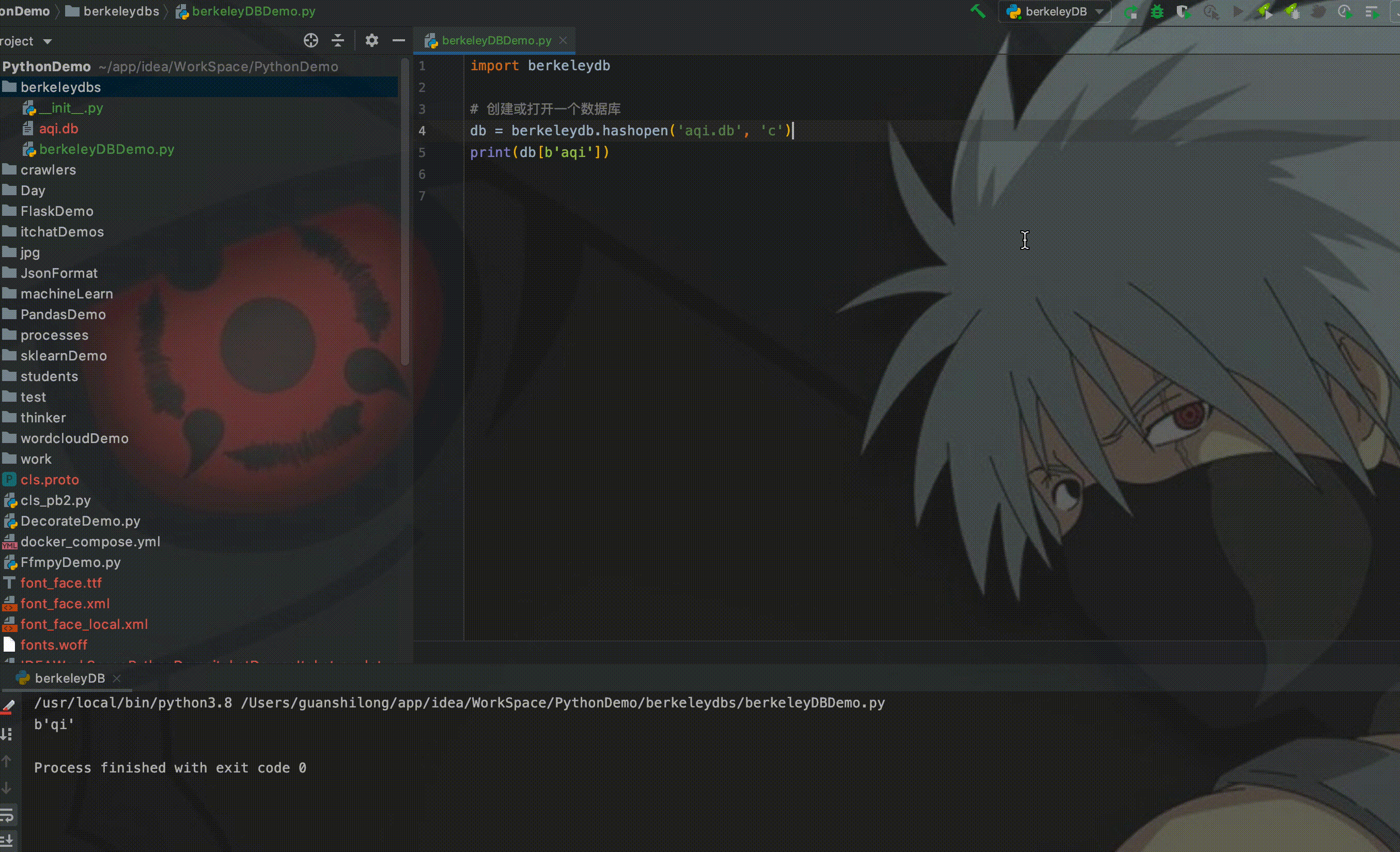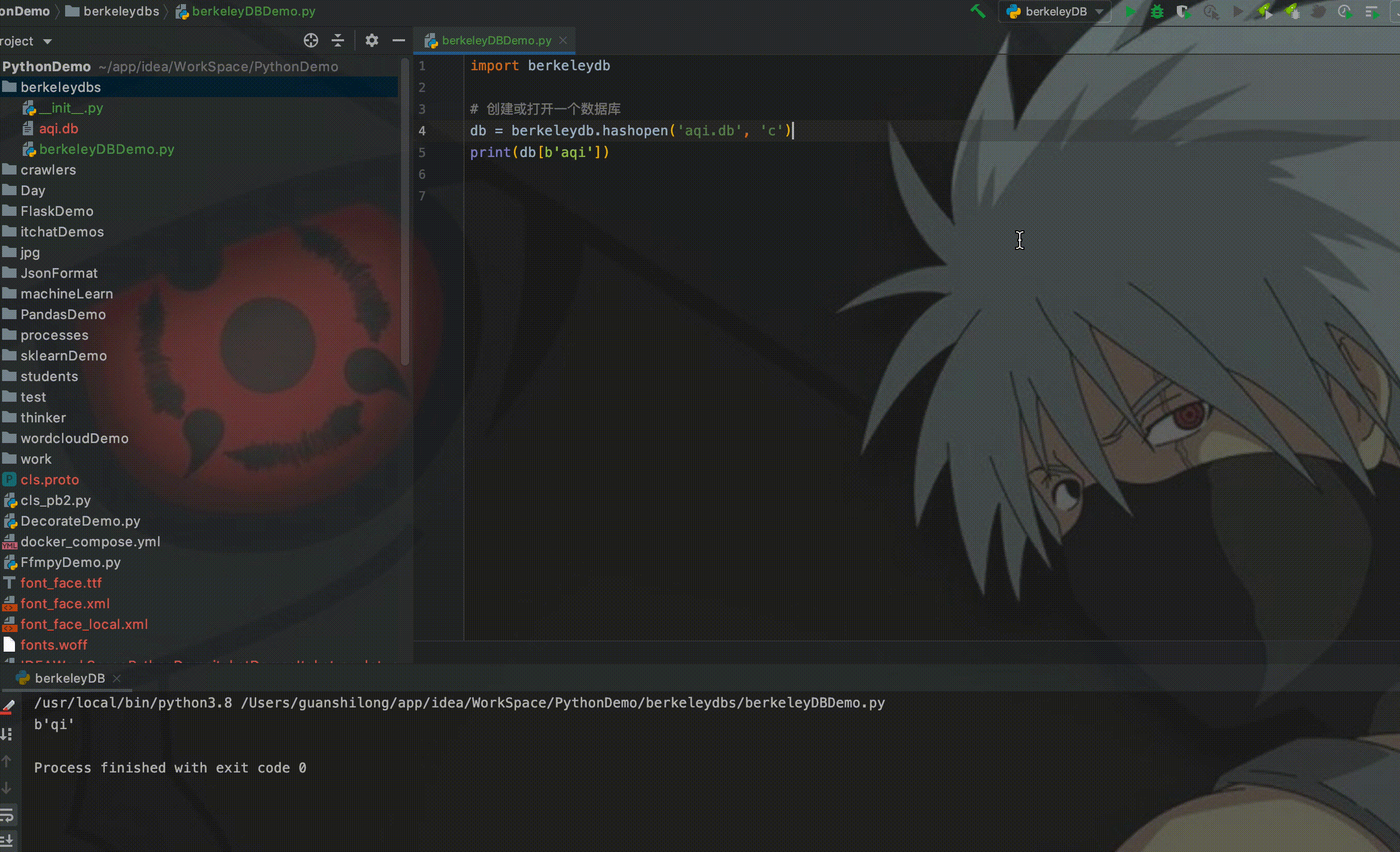
从控制台可以看出,也获取到了之前存放的数据。所以,在程序内部就实现了类似于MySQL的文件系统。
通过上面代码,你会发现在python中对于Berkeley DB的操作,和python对于map的操作是一模一样的。但区别就是一旦程序重启,map中的数据(在内存中)就会丢失,而Berkeley DB中的数据就能持久化下来生成db文件。
而且多个线程、多个程序乃至多个开发者之间都可以共享数据库文件。我用bsddb3模块来读取berkeleydb生成的aqi.db数据文件,代码如下:
from bsddb3 import db
bsddb = db.DB()
bsddb.open("aqi.db")
value = bsddb.get(b'aqi')
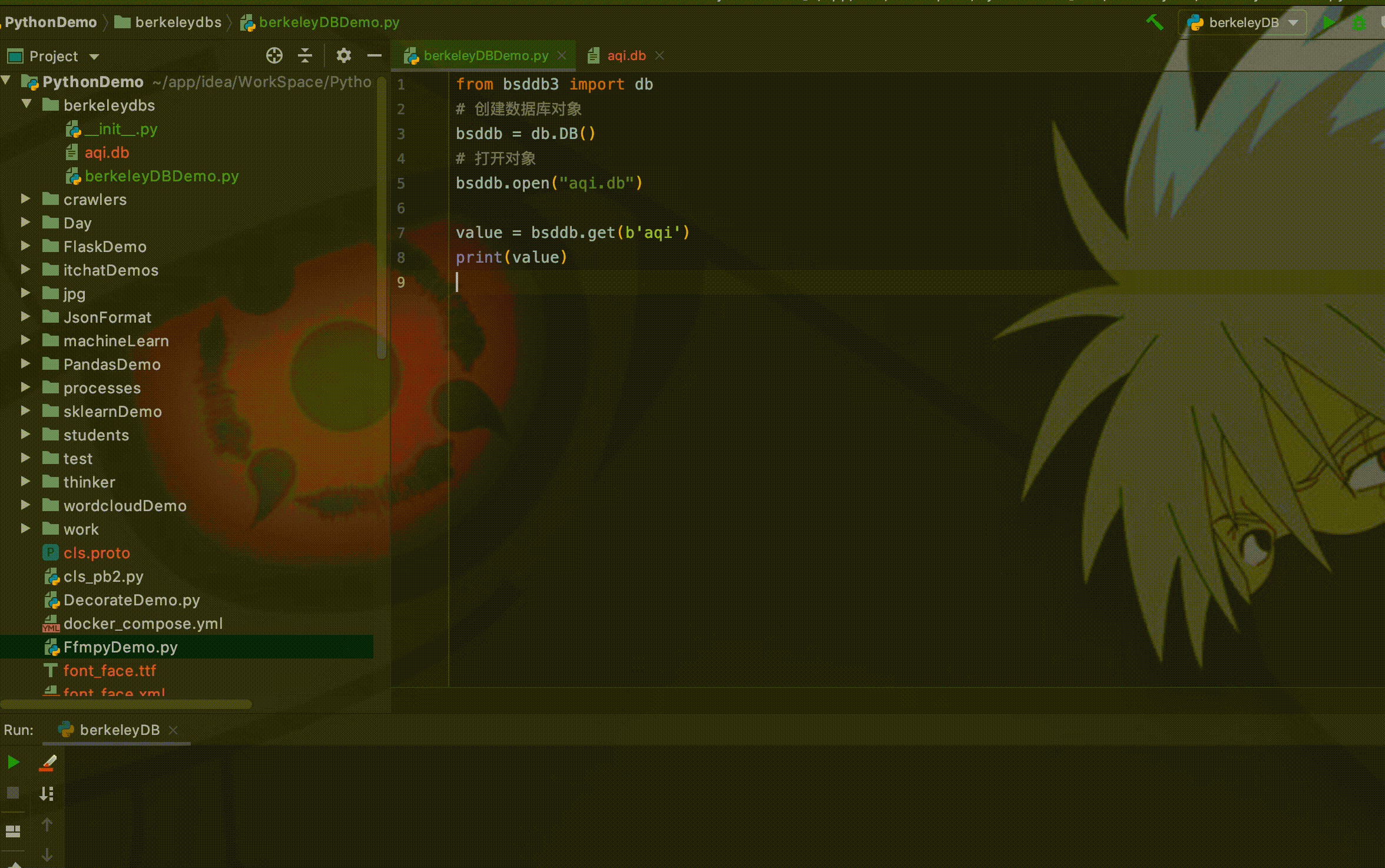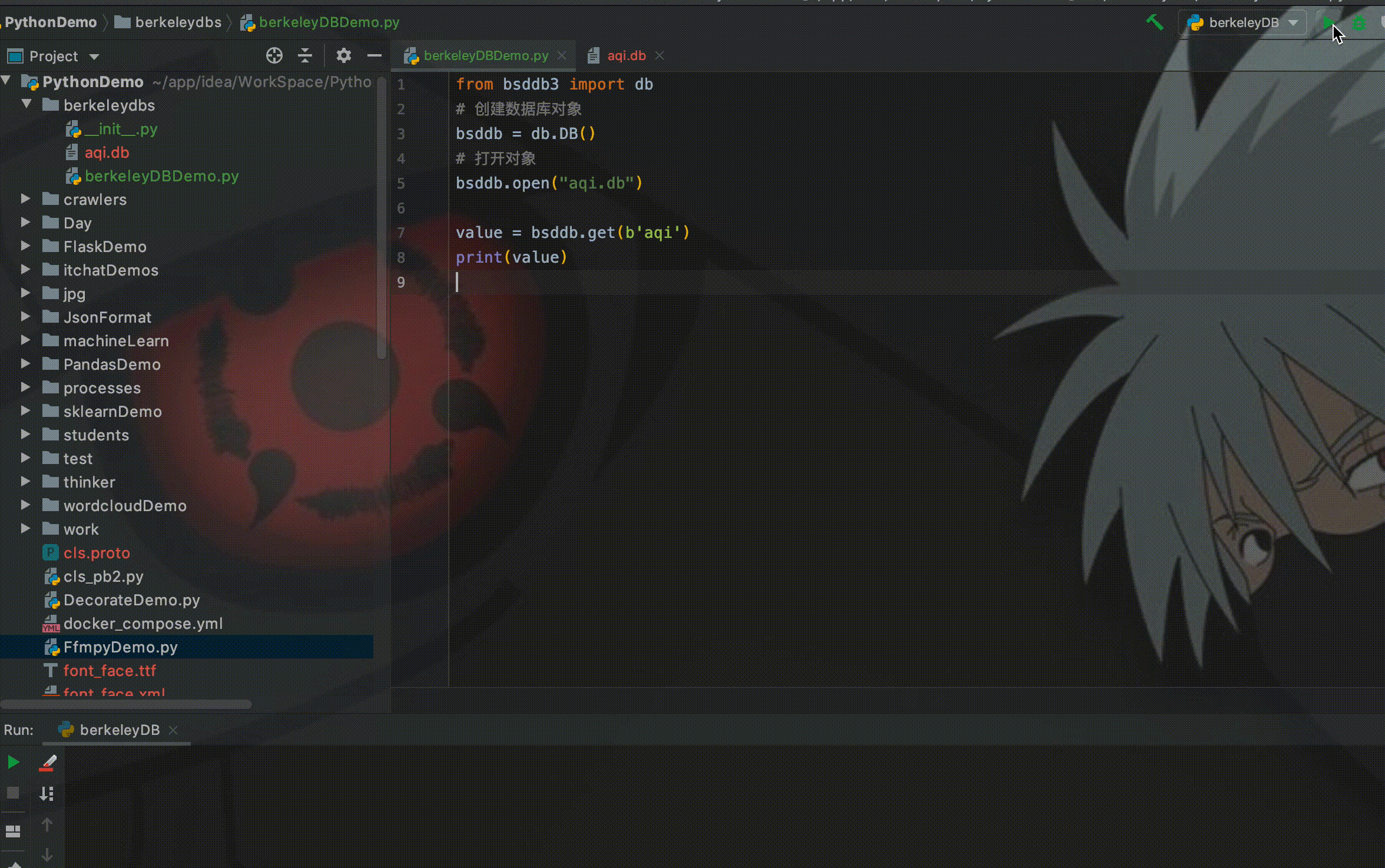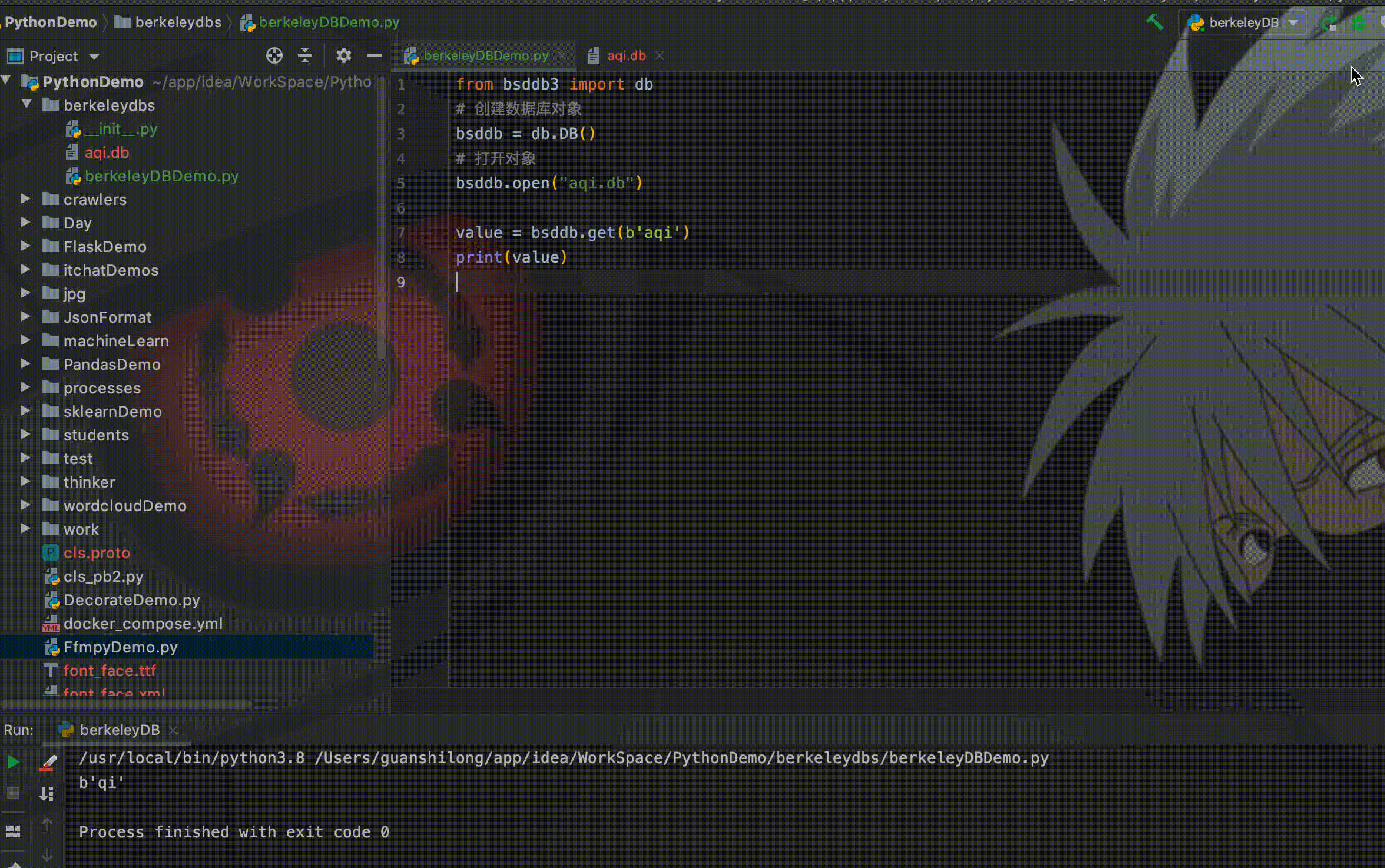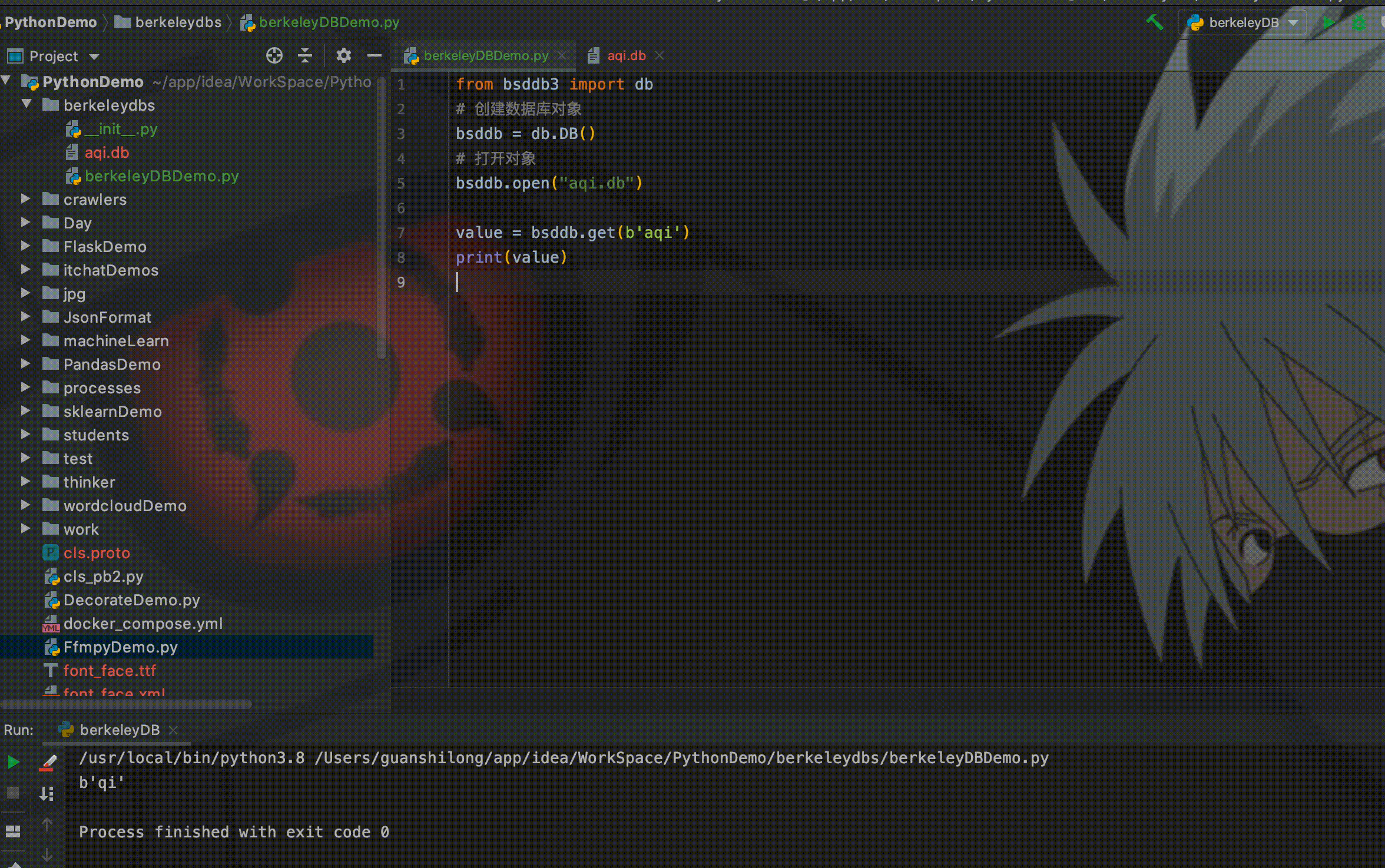
print(value)运行程序,从控制台可以看到成功从aqi.db中读到了数据。
结语
本篇文章主要从Berkeley DB角度,讲述了内嵌数据库的理论和使用,内嵌数据库没有自己的服务进程,所以对于它的操作看起来更像是一个“规则化的本地化文件读写”。
在python中,为Berkeley DB提供了简单易操作的接口,我们可以从很多场景去使用Berkeley DB,例如记录去重等,跟多的使用技巧值得去探索。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
