从零开始学机器学习——构建一个推荐web应用
原创
首先给大家介绍一个很好用的学习地址:https://cloudstudio.net/columns
今天,我们终于将分类器这一章节学习完活了,和回归一样,最后一章节用来构建web应用程序,我们会回顾之前所学的知识点,并新增一个web应用用来让模型和用户交互。所以今天的主题是美食推荐。
美食推荐 Web 应用程序
首先,请不要担心,本章节并不会涉及过多的前端知识点。我们此次的学习重点在于机器学习本身,因此我们的目标是将模型打包,使得前端用户能够与模型进行直接的界面交互,而不再依赖于后端输入的形式。
在前面的回归章节中,我们学习了如何使用第三方依赖包 pickle 来创建一个后台生成的 .pkl 后缀的模型文件,并通过 Flask 框架加载该模型,从而在后台暴露接口供调用和分析。今天,我们将探索一个新的知识点——ONNX Web,这将进一步拓宽我们在机器学习模型部署与应用方面的视野。
ONNX Web
ONNX Web 是一个用于在浏览器中运行 ONNX 模型的工具和库,主要用于深度学习模型的推理。ONNX(Open Neural Network Exchange)是一个开放的深度学习模型交换格式,它允许不同深度学习框架之间共享模型。ONNX Web 使得开发者可以将 ONNX 模型直接在网页上运行,通常用于机器学习和深度学习的前端应用。
开发步骤
- 准备 ONNX 模型:首先,需要一个经过训练并导出的 ONNX 模型。
- 引入 ONNX Web 库:在你的前端项目中引入 ONNX Web 的 JavaScript 库。可以通过 npm 安装或直接在 HTML 中使用 CDN。
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.9.09/dist/ort.min.js"></script> - 加载模型:使用 ONNX Web API 加载模型并进行推理。
const session = await ort.InferenceSession.create('./model.onnx');- 进行推理:准备输入数据,并使用加载的模型进行推理。
- 处理输出:根据模型的输出格式处理结果,并在应用中展示。
好的,经过对开发步骤的全面了解后,接下来让我们开始逐步构建一个功能齐全的 Web 应用程序。
构建模型
首先,我们将使用之前清洗后的菜品数据集来训练一个分类模型。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report
data = pd.read_csv('../data/cleaned_cuisines.csv')
X = data.iloc[:,2:]
y = data[['cuisine']]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
model = SVC(kernel='linear', C=10, probability=True,random_state=0)
model.fit(X_train,y_train.values.ravel())
y_pred = model.predict(X_test)
print(classification_report(y_test,y_pred))关于上述这段代码流程,大家可能已经对其有了一定的了解,因此我将不再进行单独的讲解。
运行结果如下所示:模型的精度表现相对令人满意,达到了一个不错的水平。
precision recall f1-score support
chinese 0.71 0.72 0.72 238
indian 0.90 0.86 0.88 259
japanese 0.76 0.75 0.75 248
korean 0.83 0.78 0.80 233
thai 0.73 0.82 0.77 221
accuracy 0.79 1199
macro avg 0.79 0.79 0.78 1199
weighted avg 0.79 0.79 0.79 1199模型转换到 Onnx
由于使用到了第三方依赖库,我们需要安装一下,命令如下:
! pip install skl2onnx
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [('float_input', FloatTensorType([None, 380]))]
options = {id(model): {'nocl': True, 'zipmap': False}}
onx = convert_sklearn(model, initial_types=initial_type, options=options)
with open("./model.onnx", "wb") as f:
f.write(onx.SerializeToString())这段代码的整体目的是准备将一个 Scikit-Learn 模型转换为 ONNX 格式的过程,定义了输入数据的结构以及转换时的一些配置选项。
initial_type是一个列表,定义了模型的输入特征及其数据类型。'float_input'是输入的名称,可以是任意字符串,用于标识输入。FloatTensorType([None, 380])指定输入数据的形状。这里的[None, 380]表示:- 第一个维度是
None,表示可以接受任意数量的样本(即批处理大小)。 - 第二个维度是
380,表示每个样本有 380 个特征。
- 第一个维度是
options是一个字典,用于指定转换过程中的一些选项。id(model)获取模型的唯一标识符(ID),用作字典的键。- 选项中:
'nocl': True表示在转换时不使用类别标签的映射(Class Label Mapping)。'zipmap': False表示在输出的 ONNX 模型中不使用 ZipMap 功能,这意味着输出将是一个多维数组,而不是一个字典结构。通常在处理分类问题时,ZipMap 可能会将类别标签转换为字典形式,但这里选择保持原始输出。
最后一步则是将模型写入文件即可。
可视化模型工具——Netron
Netron 是一个用于可视化和分析深度学习模型的开源工具,支持多种模型格式,包括 ONNX、TensorFlow、Keras、PyTorch 等。它提供了一个直观的图形界面,帮助用户理解和检查模型结构、层、参数等信息。
开源地址:https://github.com/lutzroeder/Netron?tab=readme-ov-file
其中包含了多种系统的安装版本,方便用户根据自己的需求进行选择和安装。此外,它还提供了在线Web应用,用户可以直接通过浏览器访问,无需额外安装任何软件。
在线Web应用地址如下:https://netron.app/

在我们将刚才训练好的模型上传后,可以清晰地查看模型的详细信息。
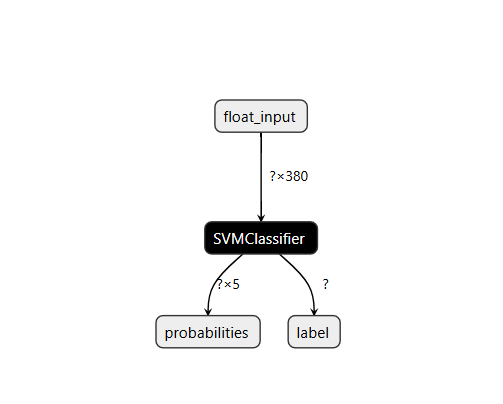
同样,你可以通过点击每一个框框来进一步探索模型的具体信息。例如,如果我们点击了“SVMClassifier”这一选项,屏幕上将会弹出一个详细的对话框,如下所示。
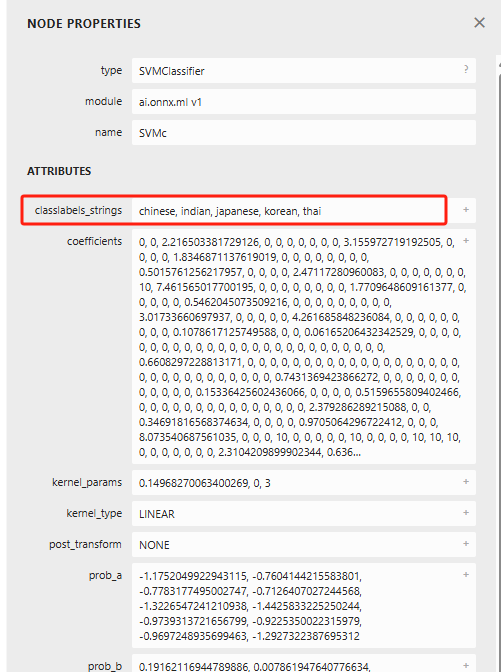
好的,以后如果你想查看模型的具体信息和性能表现,当然可以利用这个可视化工具作为参考。
Web 应用程序
这次,我们将不再使用Python后台来启动应用,而是完全依赖一个前端静态页面来实现所有功能。
<!DOCTYPE html>
<html>
<header>
<title>Cuisine Matcher</title>
</header>
<body>
<h1>Check your refrigerator. What can you create?</h1>
<div id="wrapper">
<div class="boxCont">
<input type="checkbox" value="4" class="checkbox">
<label>apple</label>
</div>
<div class="boxCont">
<input type="checkbox" value="247" class="checkbox">
<label>pear</label>
</div>
<div class="boxCont">
<input type="checkbox" value="77" class="checkbox">
<label>cherry</label>
</div>
<div class="boxCont">
<input type="checkbox" value="126" class="checkbox">
<label>fenugreek</label>
</div>
<div class="boxCont">
<input type="checkbox" value="302" class="checkbox">
<label>sake</label>
</div>
<div class="boxCont">
<input type="checkbox" value="327" class="checkbox">
<label>soy sauce</label>
</div>
<div class="boxCont">
<input type="checkbox" value="112" class="checkbox">
<label>cumin</label>
</div>
</div>
<div style="padding-top:10px">
<button onClick="startInference()">What kind of cuisine can you make?</button>
</div>
<!-- import ONNXRuntime Web from CDN -->
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.9.0/dist/ort.min.js"></script>
<script>
const ingredients = Array(380).fill(0);
const checks = [...document.querySelectorAll('.checkbox')];
checks.forEach(check => {
check.addEventListener('change', function() {
// toggle the state of the ingredient
// based on the checkbox's value (1 or 0)
ingredients[check.value] = check.checked ? 1 : 0;
});
});
function testCheckboxes() {
// validate if at least one checkbox is checked
return checks.some(check => check.checked);
}
async function startInference() {
let atLeastOneChecked = testCheckboxes()
if (!atLeastOneChecked) {
alert('Please select at least one ingredient.');
return;
}
try {
// create a new session and load the model.
const session = await ort.InferenceSession.create('./model.onnx');
const input = new ort.Tensor(new Float32Array(ingredients), [1, 380]);
const feeds = { float_input: input };
// feed inputs and run
const results = await session.run(feeds);
// read from results
alert('You can enjoy ' + results.label.data[0] + ' cuisine today!')
} catch (e) {
console.log(`failed to inference ONNX model`);
console.error(e);
}
}
</script>
</body>
</html>大致解释下js部分的代码:
- 创建一个长度为 380 的数组 ingredients,初始值为 0,用于表示选择的食材状态。
- 获取所有的复选框,并为每个复选框添加 change 事件监听器。当复选框状态变化时,根据复选框的 value 更新 ingredients 数组,选中为 1,未选中为 0。
- testCheckboxes 函数用于检查是否至少选中一个复选框。
- startInference 函数首先检查是否选中至少一个食材。如果没有,则弹出提示框。
- 如果有选中食材,异步加载 ONNX 模型 (model.onnx)。
- 创建一个张量 input,形状为 1, 380,用以存储食材信息。
- 调用模型的 run 方法进行推理,并获取结果。
- 结果中的 label 数据用于显示推荐的菜肴。
我们来运行一下,这里用到了http-server依赖:
npm install --global http-server
运行后,如图所示:
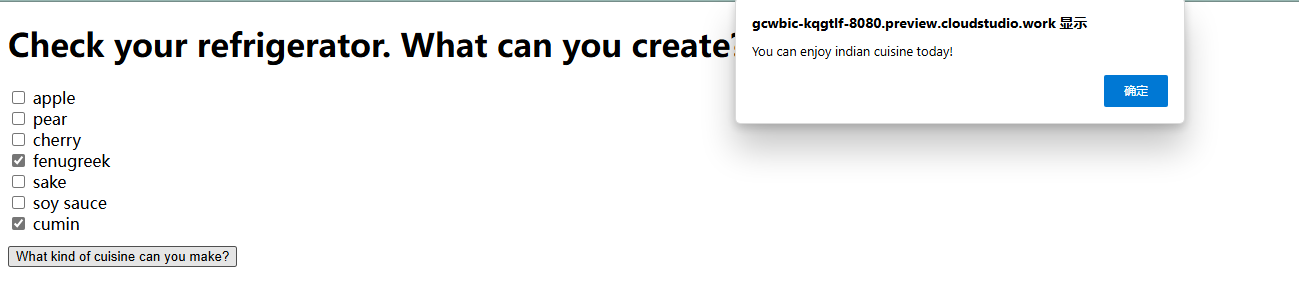
至此,我们已经完成了整个Web应用程序的构建过程。
总结
在这次学习旅程中,我们成功构建了一个美食推荐的Web应用程序,探索了机器学习和Web开发的交集。通过使用ONNX Web,我们能够将训练好的模型直接集成到浏览器中,让用户可以与模型进行互动,而无需依赖后端,这极大地提高了用户体验。结合Netron这一强大的可视化工具,我们不仅能够分析和理解模型的内部结构,还可以直观地展示模型的性能与特点。
至此,我们的分类章节圆满结束,感谢大家的认真学习和参与。在下一次的课程中,我们将深入探讨聚类技术,了解其在数据分析和机器学习中的重要应用。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
