解析时间复杂度和空间复杂度


1.算法效率
1.1 如何衡量一个算法的好坏
算法的好坏有很多点,效率高,运行时间短就是其中的一点。
long long Fib(int n)
{
if(n<3)
return 1;
return Fib(n-1)+Fib(n-2);
}这是一个求斐波那契数的递归函数,看起来很简洁,但效率其实非常低。
1.2 算法的复杂度
算法再编写成可执行程序后,运行时需要耗费的时间和空间(内存)资源。因此衡量一个算法的好坏,一般是从时间和空间两个维度来衡量的,即时间复杂度和空间复杂度。
时间复杂度主要衡量一个算法的运行快慢,而空间复杂度主要衡量一个算法运行所需要的额外空间。在计算机发展的早期,计算机的存储容量很小。而对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。所以我们如今已经不早特别需要关注一个程序的空间复杂度。
2.时间复杂度
2.1 时间复杂度的概念
时间复杂度的定义:在计算机科学中,算法的时间复杂度是一个函数,它定量的描述了该算法的运行时间。一个算法执行所花费的时间,从理论上说,是不能算出来的,只有你把你的程序放在程序机器上跑起来,才能知道。但是我们需要每个算法都上机测试是不现实的。所以才有了时间复杂度这个分析方式。一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。
即:找到某条基本语句与问题规模n之间的数学表达式,就是算出了算法的时间复杂度。
//计算Func1中的++count被执行了多少次
void Func1(int n)
{
int count = 0;
for(int i = 0;i<n;++i)
{
for(int j = 0;j<n;++j)
{
++count;
}
}
for(int k = 0;k<2*n;++k)
{
++count;
}
int m = 10;
while(m--)
{
++count;
}
}通过计算可以得知 ++count被执行的次数有:n^2+2*n+10 设f(n)为++count被执行次数的函数 f(n) = n^2+2*n+10.
- n = 10 f(n) = 130
- n = 100 f(n) = 10210
- n = 1000 f(n) = 1002010 时间上我们在计算时间复杂度时,不需要计算这么精确的数值,只需要知道大概执行的次数就可以了。于是就出现了我们现在使用的大O的渐近表示法
2.2 大O的渐近表示法
大O符号(Big O notation)是用来描述函数渐近的数学符号。 推导大O阶方法:
1.用常数1取代时间中的所有加法常数 2.在修改后的运动次数函数中,只保留最高阶项 3.如果最高阶项存在且不是1,则去除这个项目相乘的常数。得到的结果就是大O阶。
使用大O的渐近表示法,Func1的时间复杂度为O(N^2)
- n = 10 f(n) = 100
- n = 100 f(n) = 10000
- n = 1000 f(n) = 1000000 通过上面我们会发现大O的渐近表示法1去掉了那些结果影响不大的项,简洁明了的表示出了执行次数。 另外有些算法的时间复杂度存在最好、平均和最坏的情况: 最坏情况:任意输入规程的最大次数运行次数(上届) 平均情况:任何输入规模的期望运行次数 最好情况:任意输入规模的最小运行次数(下届) 例如:在一个长度为N数组中搜索一个数据x 最好情况:一次找到 最坏情况:N次找到 平均情况:N/2次找到 在实际中一般情况关注的是算法的最坏情况,所以数组中搜索数据时间复杂度为O(N)
2.3 常见时间复杂度计算练习
练习1
void func2(int n)
{
int count = 0;
for(int k = 0;k<2*n;++k)
{
++count;
}
int M = 10;
while(M--)
{
++count;
}
}f(n) = 2*n+10 时间复杂度O(N).时间复杂度会忽略系数和加减的常数项。
练习2
void func3(int n,int m)
{
int count = 0;
for(int k = 0;k<m;++k)
{
++count;
}
for(int k = 0;k<n;++k)
{
++count;
}
}时间复杂度:O(M+N)
练习3
void func4(int n)
{
int count = 0;
for(int k = 0;k<100;++k)
{
++count;
}
}时间复杂度:O(1),当运行次数为常数次时,用1来代替具体的次数。
练习4
//计算strchr的时间复杂度
const char* strchr(const char* str,int character);该函数的功能,是在一个字符串中寻找一个字符 时间复杂度:O(N),最坏情况下可能遍历整个字符串都找不到。
练习5
void bubblesort(int* a,int n)
{
assert(a);
for(int i = 0;i<n-1;++i)
{
int flag = 0;
for(int j = 0;j<n-i-1;++j)
{
if(a[j-1]>a[j])
{
swap(&a[j-1],&a[j]);
flag = 1;
}
}
if(flag == 0)
break;
}
}时间复杂度:O(N^2),计算时间复杂度要从算法的原理计算,冒泡排序的本质是什么 冒泡排序:两两比较,第一趟会比较n-1次,第二趟会比较n-2次,直到最后一次只比较一次。次数相加就为1+2+3+…+n-1。这是一个等差数列,运用等差数列求和公式,得到(1+n-1)*n/2得时间复杂度为n^2。
练习6
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n-1;
// [begin, end]:begin和end是左闭右闭区间,因此有=号
while (begin <= end)
{
int mid = begin + ((end-begin)>>1);
if (a[mid] < x)
begin = mid+1;
else if (a[mid] > x)
end = mid-1;
else
return mid;
}
return -1;
}时间复杂度:O(logN) 二分查找:二分查找的特点就是每次的选择将会去除一半的错误答案。每次选择都去除一半的情况下,最后一个数就是所需要的数。 设去除的次数为x,1*2的x次方等于n,两边同时取对数,就可以得到x=log2n。 时间复杂度就是O(logN) 提问:为什么省略底数2 回答:因为在计算时间复杂度时就是这么规定的,当底数为2时可以省略。
练习7
long long Fac(size_t N)
{
if(0 == N)
return 1;
return Fac(N-1)*N;
}时间复杂度为O(N)

阶乘
每次只会调用一层函数
练习8
long long Fib(int n)
{
if(n<3)
return 1;
return Fib(n-1)+Fib(n-2);
}时间复杂度为O(2^N)
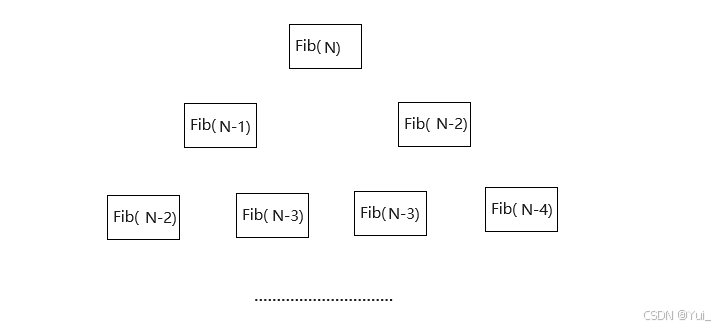
斐波那契数列
每次的调用都是上一次的两倍。如图也可以看出该计算斐波那契数的方法存在大量的重复计算。
3.空间复杂度
空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度。 空间复杂度不是程序占用了多少Bytes的字节,因为计算这个没什么意义,所以空间复杂度算的变量个数。空间复杂度的计算规则和时间复杂度类型,也使用大O的渐近表示法。 注意 函数运行需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译阶段就已经确定好了,因此空间复杂度主要通过在运行是显示申请的额外空间来确定。
练习1
void bubblesort(int* a,int n)
{
assert(a);
for(int i = 0;i<n-1;++i)
{
int flag = 0;
for(int j = 0;j<n-i-1;++j)
{
if(a[j-1]>a[j])
{
swap(&a[j-1],&a[j]);
flag = 1;
}
}
if(flag == 0)
break;
}
}空间复杂度为O(1),无额外开辟的空间。
练习2
long long* Fibonacci(size_t n)
{
if(n==0)
return NULL;
long long * fibArray = (long long *)malloc((n+1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n ; ++i)
{
fibArray[i] = fibArray[i - 1] + fibArray [i - 2];
}
return fibArray;
}空间复杂度:O(N),动态开辟了N+1个空间
练习3
long long Fac(size_t N)
{
if(0 == N)
return 1;
return Fac(N-1)*N;
}空间复杂度度:O(N) 递归调用了N个堆栈,每个堆栈使用了常数个的空间
4.常见复杂度对比
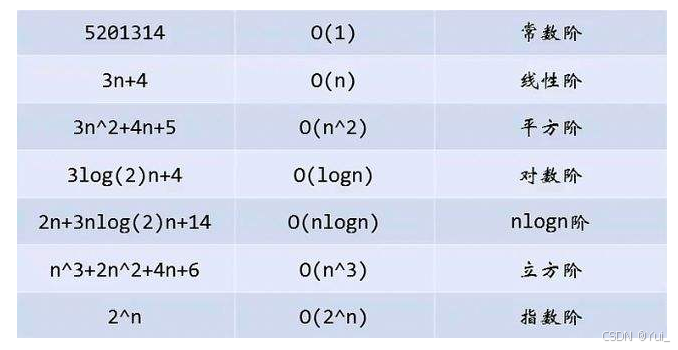
对比图
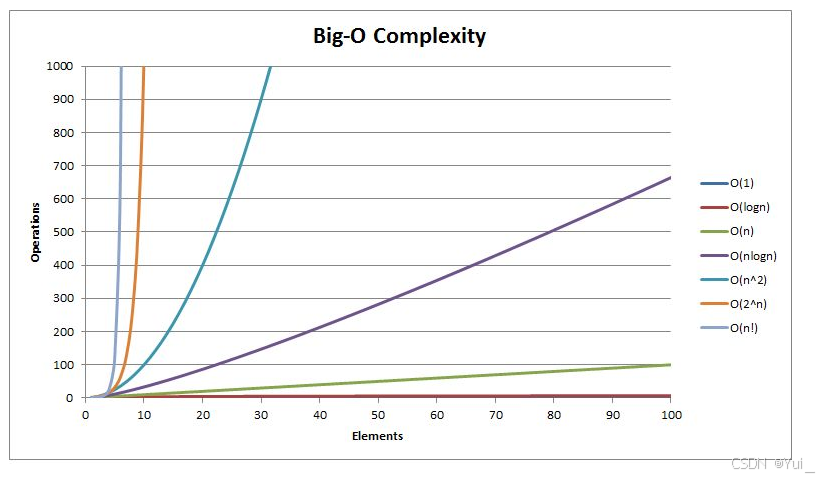
对比图
完
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-07-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号