详解C语言的数据类型和变量(下)


1. signed和unsigned
1.1 序言
书接上回,在详解C语言的数据类型和变量(上)中,我给大家展示过一个数据类型的样式。
//怕大家忘了,写多一遍。加深大家对数据类型种类的了解。
//[]里面的内容可以在你编程时省略不写
//字符型
char
[signed] char //有符号的
unsigned char //无符号的
//短整型
short [int]
[signed] short [int] //有符号的
unsigned short [int] //无符号的
//整型
int
[signed] int //有符号的
unsigned int //无符号的
//长整型
long [int]
[signed] long [int] //有符号的
unsigned long [int] //无符号的
//更长的整型(在C99版本被引入,C99之前是没有这个数据类型的)
long long [int]
[signed] long long [int] //无符号的
unsigned long long [int] //有符号的
//浮点数类型
float //单精度浮点型
double //双精度浮点型
long double //更长的双精度浮点型
//布尔类型(记得使用时引入头文件<stdbool.h>)
_Bool里面的signed和unsigned到底是什么?它们有什么用?这个就是我接下来给大家讲的东西。
解决这个问题之前,先跟大家聊一些日常生活的问题。
- 假设我们买了一框的苹果,为了不被水果商贩上一课,我们把苹果都数了一遍,从1开始数,一直到到数完。在这个数苹果的过程中,我们不知不觉地用到了被unsigned修饰过的数据类型了。(1、2、…)
- 假设一个我们看好的股票在一定的时期内股值出现了波动(假设波动只呈现出整数变化),我们肯定希望股值呈现出红色,可它却库库地呈现出一片绿色,看到这里的我们心已经碎了一地。但是在悲伤之余,我们冷静地思考的一下,突然有一种脑袋被苹果砸到感觉,想到了这种波动不就是用了被signed修饰过的数据类型啊!
读完上面的例子,相信大家已经对signed和unsigned有一点点感觉了。那么,让我们开始正片内容!
1.2 详解signed和unsigned
C语言中使用signed和unsigned关键字修饰字符型和整型。 signed关键字,表示它所修饰的数据类型(字符型、整型)带有正负号。就如上面股票的例子。 unsigned关键字,表示该类型不带正负号,只能表示0和正整数。就如上面数苹果的例子。
signed在编写时可以省略,写了也不算错。而unsigned就不能省略了。
什么?你还没有理解?那就上代码!!! 例子:
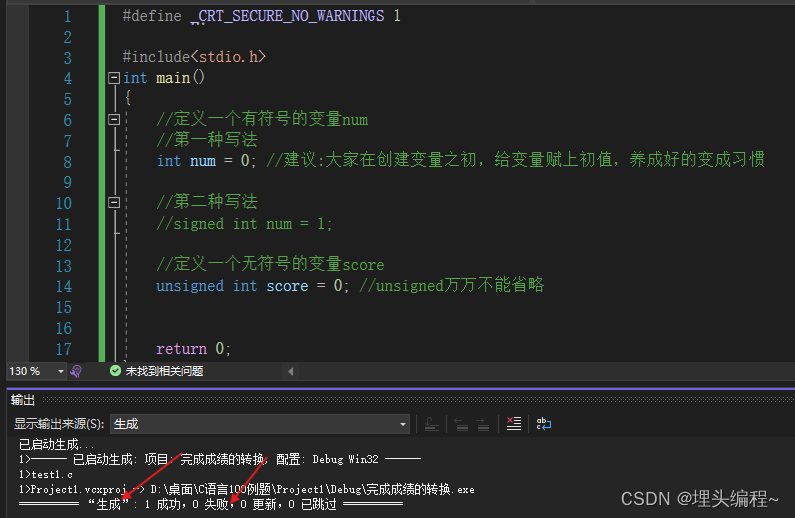
代码演示
可见编译器并没有报错。
那如果我们省略了unsigned时又会出现什么状况呢?在回答这个问题之前,担心有C语言零基础的 读者,特别在这说明一下,等会的例子,不需要你每一条的代码都理解。你只需要了解到unsigned这个关键字在修饰数据两位类型是不能省略这个道理就可以了
代码(省略unsigned的危害):
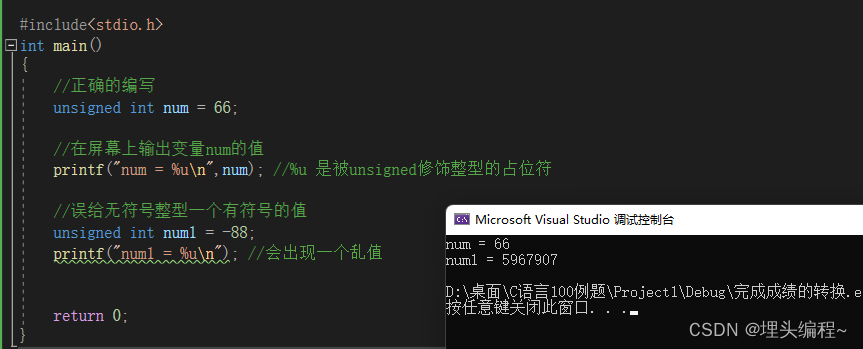
代码演示
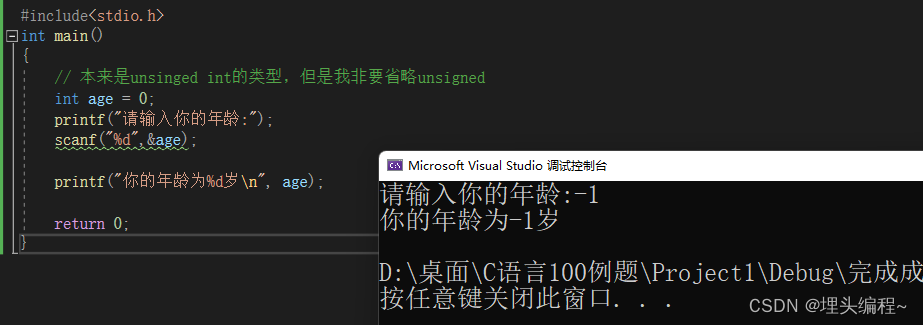
代码演示
你看到这里应该发现了,年龄怎么可能有-1岁这种的说法。这是与我们常识相违背的,还记得我在之前说过,计算机语言是为了解决我们在日常生活中的问题。那如果我们问题都描述错误了,得到的肯定也是错误答案。这个点希望读者们牢记心中,该在什么场景下就得使用对应的数据类型,可不敢z再乱用了!!!
1.2.1 signed和unsigned的数值取值范围
在说明这个问题之前,不妨先想一下。即然signed关键字所修饰的数据类型可以带正负号,而unsigned关键字只能修饰0和正整数,signed关键字所修饰的数据类型包含了unsigned关键字所修饰的数据类型,那我以后干脆,直接都用signed关键字得了呗。但事实真的是如此吗?
这个问题的回答:
- 我们要该在什么场景下就得使用对应的数据类型,可不敢乱用被signed和unsigned修饰过数据类型。
- 在正整数范围内,unsigned比signed所表示的范围更大。
为什么会出现这种情况呢? 之前我们讲过一个东西,变量在被创建之初编译就会根据变量的数据类型大小,分配对应的内存空间(整型对应4个字节的大小)。既然存储空间有限,那么由数据类型所修饰的变量肯定也存在一个所能表示的数值范围。至于为什么unsigned比signed所表示的范围更大,是因为在计算机底层对于无符号的整数和有符号整数的处理方式不一样所导致的。(限于篇幅的限制,如果想了解更深的知识,可自行查找,或在直接私信我)
2.数据类型的取值范围
希望读者读到这里,不要被signed和unsigned的数值取值范围这个知识点打乱思维了。数据类型的取值范围又是另外一回事了。
我们所学的数据类型有很多种,特别是整数类型,就有short、int、long、long long四种,那为什么会有那么多种类型呢?
其实每一种数据类型都有自己的取值范围,也就是所存储的数据的最大值和最小值的区间,有了丰富的数据类型,我们就可以在特定的场合中选择合适的类型去使用。
那我们该怎么知道这些数据类型的取值范围呢? 如果我们要在自己的IDE上查看不同类型的最大值和最小值:
- 在limit.h文件中说明了整数类型的取值范围。
- 在float.h文件中说明了浮点型类型的取值范围。
这里由我来展示给大家看(下来,自己也可以在自己的编译器上试试) 第一步:
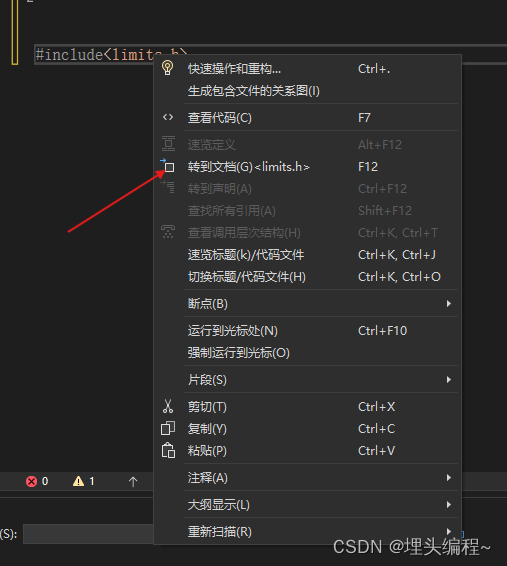
第一步
第二步:

limits.h里面的内容
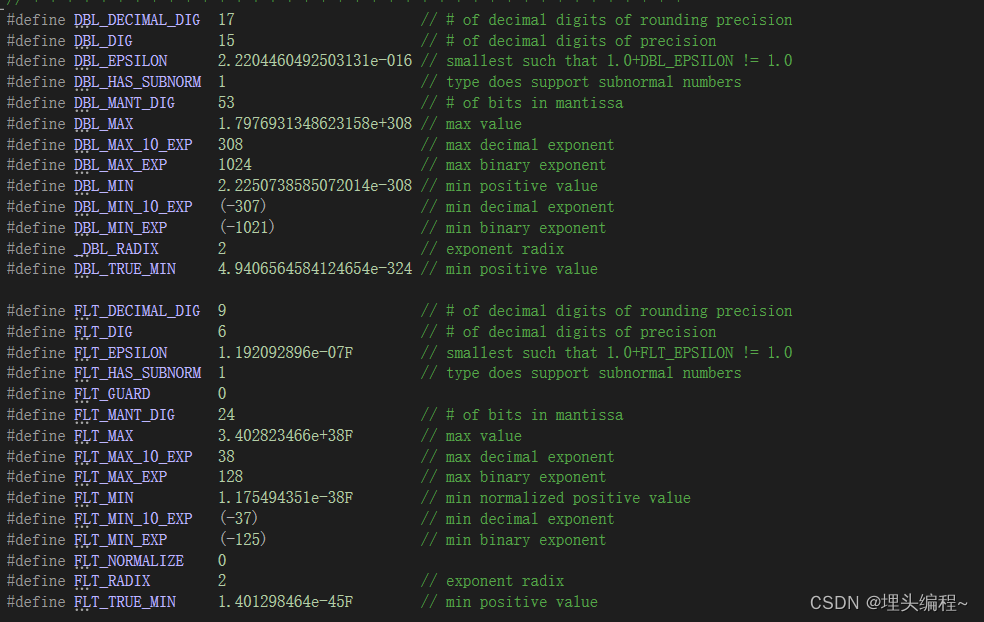
float.h里面的内容
查看浮点数类型取值范围的方法跟查看整数范围的方法一样。
3. 变量
3.1 变量的创建
在之前我们用了大量的篇幅介绍了数据类型,我们说数据类型给予了我们解决实际问题的方向,如果要将实际问题的某些个体进行具象化告诉给计算机时,就得用到变量. 换句话说,我们在计算机使用类型做什么?类型是用来创建变量的
那什么是变量呢?在C语言中,把经常变化的值就称作为变量,不变的值称为常量。
变量创建的语法形式是这样的(其实在之前的例子中,就给大家展示过了):
data_type name; //data_type 就是指你要为这个变量给它一个怎样的数据类型,name 就是变量名
| |
| |
数据类型 变量名int age; //整型变量
char ch; //字符变量
double weight; //浮点型变量我们在创建变量之初,给变量一个初始值的操作,叫做初始化。(这是一个编程的好习惯)
//代码演示
int age = 18; //永远18岁!!!
char ch = 's';
double weight = 66.0;
unsigned int height = 180; //一米8,大高个3.2 变量的分类
按种类分类(觉得掌握的话,可以在框里打个勾,激励自己):
- 字符型
- 整型
- 浮点型
- 布尔型
(只讨论内置类型的情况)
按作用域分类
- 全局变量
- 局部变量
此时,有的读者会发出疑问,什么是作用域? 其实,作用域,顾名思义就是变量能够生效的范围。超过这个范围就失去作用了。
那可能又有的读者继续提问,那我们该如何确定这个范围? 以对应大括号之间范围,为一个作用域。
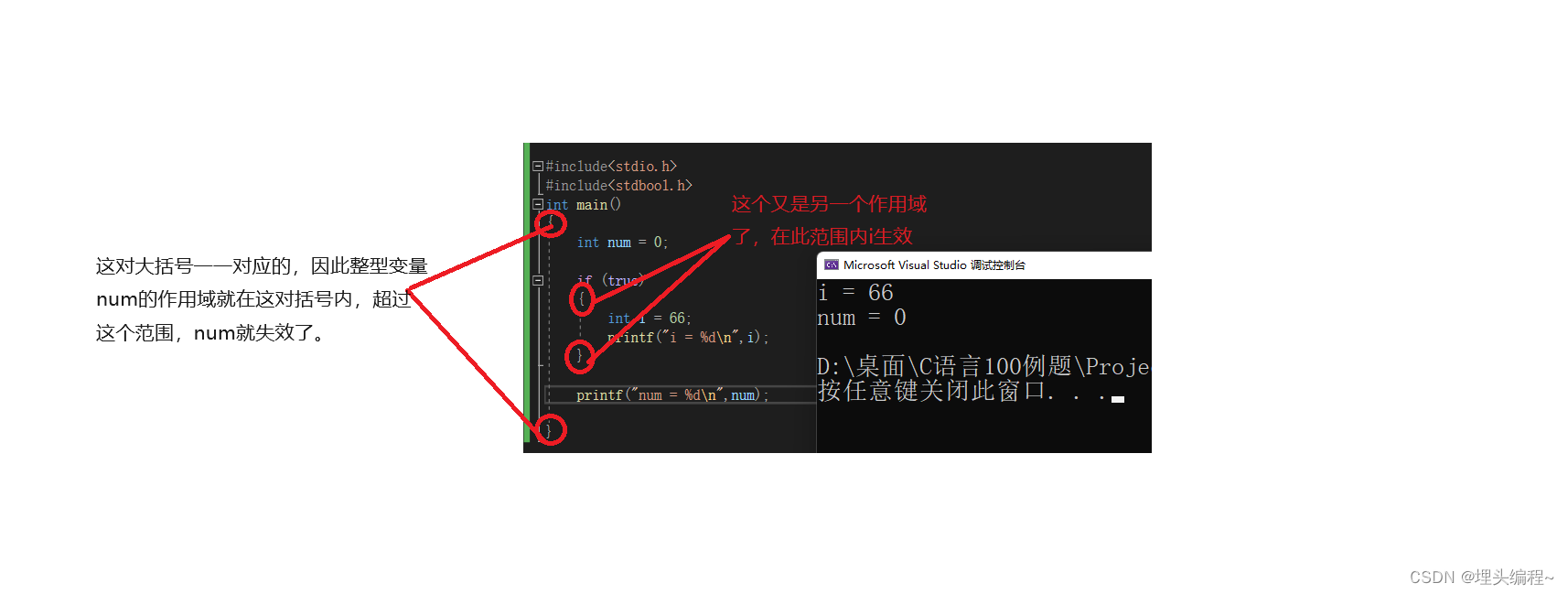
作用域的简单演示
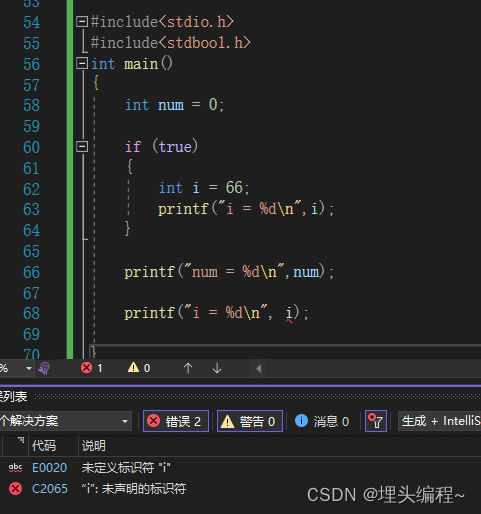
作用域的演示
我相信上面这个代码更能凸显出作用于的重要性。
我们说过变量 i 是在 if 语句这个大括号里面的,超过这个范围变量 i 就失效了。 我们再看一下编译器给我们的报错信息,它说 “i”是未定义的标识符。可能在上面没有看懂的读者就会发出疑惑,我不是定义了过了 i ,为什么说我没定义? 其实是作用域在作祟!!!(希望大家通过上面的例子,能够感知到变量作用域的存在)
#include<stdio.h>
int global = 2024; //全局变量
int main()
{
int local = 2018; //局部变量
printf("%d\n",local);
printf("%d\n",global);
return 0;
}- 全局变量可以简单地理解为,变量被定义在main函数之外,其作用域是整个程序。
- 局部变量可以简单地理解为,是被定义在一对对大括号内,其作用于是在对应的大括号内。
可能有些读者的脑洞比较大,它会想,如果局部变量名与全局变量名一致时,请问阁下又该如何应对?这个就是我们接下来要讨论的问题,局部变量与全局变量同名时的情况。
废话不多说,直接上代码:
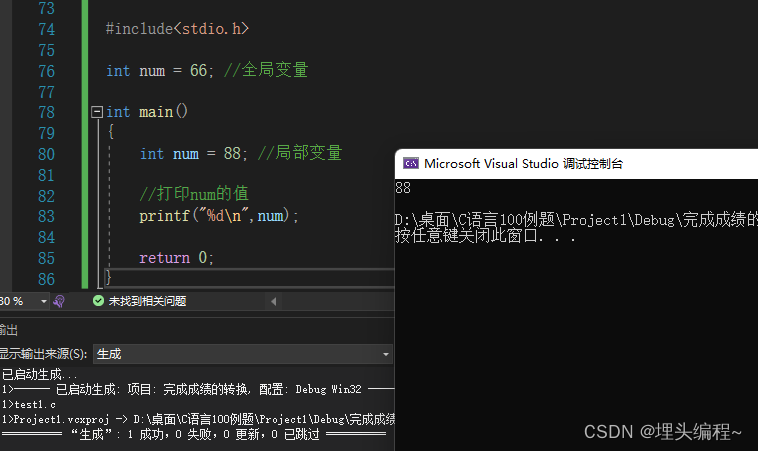
代码演示
看到这里,你会惊奇的发现,编译器不仅没有报错,还给我们输出了一个值。再仔细地一看输出的值,这…不就是那个局部变量num的值麻。看到这里,我相信很多读者内心已经有答案了,
- 结论:
- 首先,当局部变量与全局变量同名时,编译器是允许这种写法存在的;
- 其次,局部变量会优先使用。
拓展: 一般我们在学习C/C++语言的时候,我们会关注内存中的三个区域:栈区、堆区、静态区
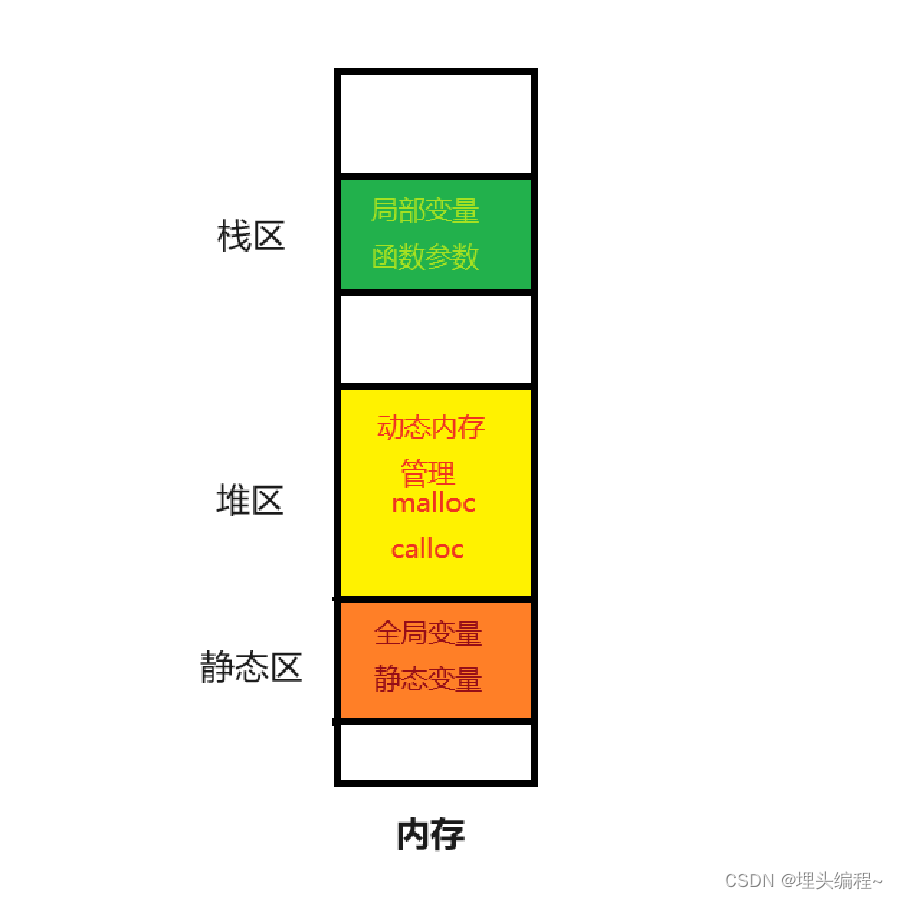
内存
- 局部变量是存放在内存中的栈区
- 全局变量是存放在内存中的静态区
- 堆区是用来动态内存管理的(后面我会介绍的)
4.小结
在这节我们讲了signed和unsigned诸多细节,并要求大家在编程时,什么样的场景就使用什么样的数据类型。数据类型的取值范围,以及变量的诸多细节。 希望下来,读者们能够静下心来,慢慢研究C语言。
最后的最后,送给广大读者一句话:学习很难,但坚持一定很酷。所以努力学习吧,少年们!!!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-04-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号