知识图谱嵌入与多跳推理技术的应用
原创

知识图谱嵌入(Knowledge Graph Embedding, KGE)已经成为了从海量数据中提取潜在信息、辅助问答、推荐系统等领域的核心技术。通过将实体和关系嵌入到低维向量空间中,知识图谱嵌入可以将符号化的知识结构转换为可计算的形式。然而,单一的三元组推理往往无法满足复杂问答的需求,特别是涉及到多个关联实体和关系的场景。为此,多跳推理技术(Multi-hop Reasoning)被引入,能够在知识图谱上通过多次跳跃连接不同的实体,以获取更为复杂的推理路径和答案。
随着深度学习的发展,知识图谱嵌入技术经历了多个模型的发展阶段。早期的经典模型如TransE、TransH、DistMult等,主要处理实体与单一关系的嵌入表示。随着应用需求的增加,这些模型逐渐融入了多跳推理技术。例如,基于路径的推理方法(如Path-RNN)、强化学习(如MINERVA)等,为解决复杂关系推理提供了更好的解法。
多跳推理允许模型在图谱中探索更长的路径,找到与查询相关的多级关系。例如,在医疗知识图谱中,问题"糖尿病的副作用是什么?"可以通过多跳推理找到相关副作用和潜在的治疗方法。该技术通过逐步探索不同的关系路径,可以给出更加复杂的答案。
知识图谱嵌入的基本原理
知识图谱嵌入是一种将图谱中的实体和关系映射到低维向量空间的技术,方便通过向量计算进行复杂的推理操作。常见的知识图谱嵌入模型包括:
模型名称 | 描述 | 特点 |
|---|---|---|
TransE | 将实体与关系嵌入到同一空间中,假设实体和关系之间的线性关系可以用向量加减表示 | 简单高效 |
TransH | 通过在不同关系上引入超平面,克服了TransE模型无法处理一对多、多对一等复杂关系的不足 | 能处理复杂关系 |
DistMult | 基于张量分解,使用双线性模型表示关系嵌入 | 强调关系的对称性 |
在这些嵌入模型的帮助下,实体和关系可以被表示为向量,并且通过简单的向量操作就可以进行推理。
知识图谱嵌入示例代码
以下代码展示了如何使用TransE模型对知识图谱进行嵌入:
from openke.config import Trainer, Tester
from openke.module.model import TransE
from openke.module.loss import MarginLoss
from openke.data import TrainDataLoader, TestDataLoader
# 数据加载
train_dataloader = TrainDataLoader(
in_path = "./benchmarks/FB15K/",
nbatches = 100,
threads = 8,
sampling_mode = "normal",
bern_flag = 0,
filter_flag = 1,
neg_ent = 25,
neg_rel = 0
)
# 模型定义
transe = TransE(
ent_tot = train_dataloader.get_ent_tot(),
rel_tot = train_dataloader.get_rel_tot(),
dim = 100,
p_norm = 1,
norm_flag = True
)
# 定义训练器
trainer = Trainer(
model = transe,
data_loader = train_dataloader,
train_times = 1000,
alpha = 0.5,
use_gpu = True
)
trainer.run()
transe.save_checkpoint('./checkpoint/transe.ckpt')多跳推理技术的原理与应用
多跳推理指的是从一个实体出发,通过多个中间实体和关系,找到答案。与单跳推理不同,多跳推理通过探索多个关系路径,能够从复杂的图谱结构中提取深层次的知识。
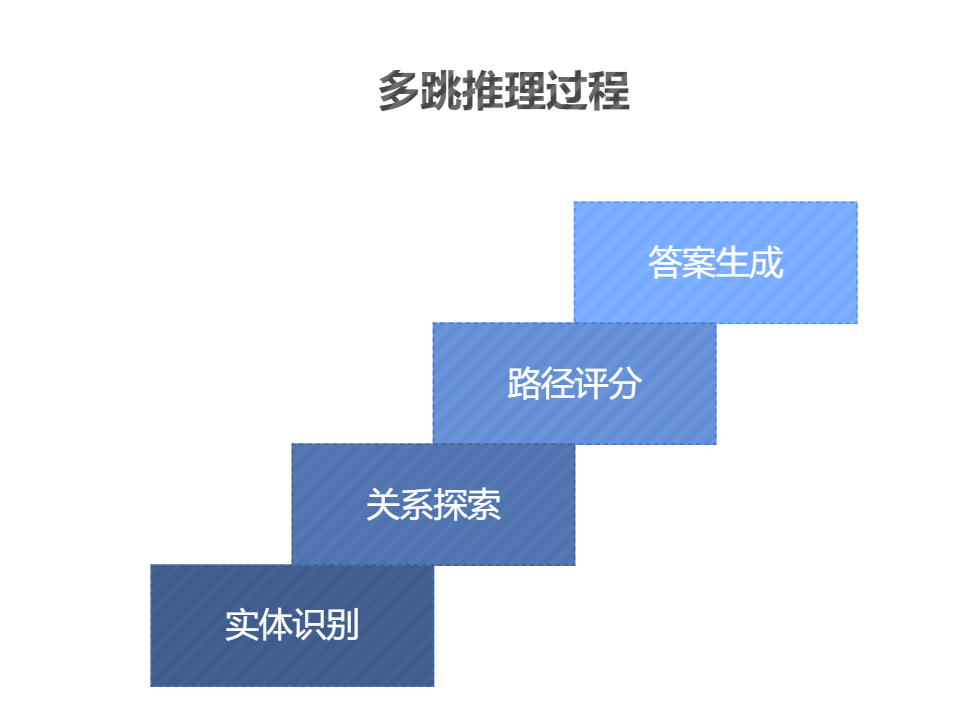
1 基本原理
多跳推理通常通过以下几步完成:
- 初始实体定位:确定问题中的初始实体。
- 关系链探索:逐步在图谱中沿着不同的关系探索多个实体。
- 路径得分计算:根据各个跳跃路径的相关性,为每条路径计算得分。
- 答案生成:选择得分最高的路径,生成最终答案。
例如,对于问题“哪些药物可以治疗糖尿病的并发症?”,通过多跳推理可以从“糖尿病”出发,先找到与之相关的并发症,再通过进一步跳跃,找到可能治疗这些并发症的药物。
2 路径强化学习
在多跳推理中,强化学习技术经常被用来引导模型选择最优的推理路径。例如,MINERVA(Multi-hop Reasoning with Reinforcement Learning)模型使用了基于策略梯度的强化学习方法,来逐步探索知识图谱中的路径。
MINERVA 示例代码
在知识图谱的多跳推理中,强化学习可以通过策略网络来引导模型在知识图谱中选择下一步的跳跃关系。每次选择一个动作(即选择关系进行跳跃),通过多次迭代,最终达到一个目标实体。下面的代码是一个简单的策略网络的实现,该网络用于选择在知识图谱中的下一跳。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个策略网络类,输入为实体的嵌入,输出为可能的动作(关系)的概率分布
class PolicyNetwork(nn.Module):
def __init__(self, input_dim, output_dim):
# 调用父类的构造函数,初始化模型结构
super(PolicyNetwork, self).__init__()
# 定义一个全连接层,输入为实体的嵌入向量,输出为可选的动作(关系)的数量
self.fc = nn.Linear(input_dim, output_dim)
# 定义前向传播函数,用于计算给定输入的输出(即下一跳关系的概率分布)
def forward(self, x):
# 使用Softmax激活函数将全连接层的输出转化为概率分布,表示下一跳关系的选择概率
return torch.softmax(self.fc(x), dim=-1)
# 创建策略网络的实例
# 假设嵌入空间维度为100(实体的嵌入),输出为50(可能的关系数量)
policy_net = PolicyNetwork(input_dim=100, output_dim=50)
# 定义优化器,这里我们使用Adam优化器,它常用于训练深度学习模型
# 它会对策略网络的参数进行更新,学习如何选择最优的跳跃关系
optimizer = optim.Adam(policy_net.parameters(), lr=0.01)
# 初始化实体的嵌入向量,这里我们假设有一个实体嵌入向量
# 通过torch.rand函数生成一个大小为(1, 100)的随机张量,表示初始实体的嵌入
initial_entity_embedding = torch.rand(1, 100)
# 将实体嵌入输入到策略网络中,得到每个动作(关系)的概率分布
# 这个概率分布表示了每个关系作为下一步跳跃动作的可能性
action_probs = policy_net(initial_entity_embedding)
# 根据生成的概率分布,随机选择一个动作(即选择下一跳的关系)
# torch.multinomial根据给定的概率分布,随机选择一个值
action = torch.multinomial(action_probs, 1)
# 输出选择的下一步关系
print(f"选择的下一步关系是: {action}")策略网络定义 (PolicyNetwork 类)
class PolicyNetwork(nn.Module):
def __init__(self, input_dim, output_dim):
super(PolicyNetwork, self).__init__()
self.fc = nn.Linear(input_dim, output_dim)
def forward(self, x):
return torch.softmax(self.fc(x), dim=-1)PolicyNetwork是一个简单的前馈神经网络,用于表示强化学习中的策略函数。输入为实体的嵌入向量,输出为可选的关系动作的概率分布。self.fc = nn.Linear(input_dim, output_dim):这是一个全连接层,负责将输入的实体嵌入映射到输出空间(即关系空间)。torch.softmax(self.fc(x), dim=-1):Softmax函数将全连接层的输出转化为概率分布,每个可能的动作(关系)都有一个对应的选择概率。
初始化策略网络和优化器
policy_net = PolicyNetwork(input_dim=100, output_dim=50)
optimizer = optim.Adam(policy_net.parameters(), lr=0.01)policy_net = PolicyNetwork(input_dim=100, output_dim=50):我们实例化策略网络,输入维度为100(实体嵌入维度),输出维度为50(代表可能的关系数量)。optimizer = optim.Adam(policy_net.parameters(), lr=0.01):使用Adam优化器更新策略网络的参数,学习最优的动作选择策略。Adam是一种广泛应用的优化算法,能够自适应调整学习率,从而加速训练。
输入初始实体的嵌入
initial_entity_embedding = torch.rand(1, 100)initial_entity_embedding是初始实体的嵌入向量。这里我们通过torch.rand(1, 100)生成一个随机向量,表示一个实体在100维嵌入空间中的位置。实际应用中,这个嵌入通常是从预训练模型或知识图谱中获得的。
通过策略网络选择下一步动作
action_probs = policy_net(initial_entity_embedding)
action = torch.multinomial(action_probs, 1)action_probs = policy_net(initial_entity_embedding):我们将实体的嵌入输入到策略网络中,策略网络根据输入生成每个可能关系的选择概率。action = torch.multinomial(action_probs, 1):根据生成的概率分布,我们使用torch.multinomial函数从中选择一个动作(关系)。multinomial函数会根据给定的概率,随机选择一个动作,这里选择的动作代表下一跳选择的关系。
输出选择的关系
print(f"选择的下一步关系是: {action}")action是策略网络基于实体嵌入向量选择的下一步关系动作。最终输出的结果是策略网络推荐的跳跃方向。
实例分析:医疗领域的多跳推理
我们以医疗领域的知识图谱为例,演示多跳推理的实际应用。假设我们有一个关于药物、疾病和副作用的知识图谱,问题是“什么药物可以治疗糖尿病的并发症?”
数据准备
我们需要一个包含疾病、药物和副作用等信息的知识图谱。这个知识图谱中的三元组形式如 (糖尿病, 并发症, 肾病) 和 (肾病, 治疗药物, 肾上腺素)。
问题解析
问题“什么药物可以治疗糖尿病的并发症?”可以解析为以下几步推理:
- 从糖尿病找到并发症实体。
- 从并发症找到相关的治疗药物。
多跳推理实现
通过上面的MINERVA模型,我们可以使用强化学习在知识图谱中逐步找到答案。每一步跳跃后,模型会评估下一步的潜在动作,并选择最优路径。
# 定义初始问题
initial_entity = "糖尿病"
current_embedding = get_entity_embedding(initial_entity)
# 第一步:找到糖尿病的并发症
action_probs = policy_net(current_embedding)
action = torch.multinomial(action_probs, 1)
next_entity = get_next_entity(action) # 假设get_next_entity可以返回下一个实体
print(f"糖尿病的并发症是: {next_entity}")深度融合
随着自然语言处理(NLP)领域的飞速发展,预训练语言模型(如BERT、GPT等)展现出了极强的语义理解和生成能力。然而,这些语言模型通常依赖于大规模文本数据,而不具备对符号化知识(如知识图谱)的直接理解能力。通过将知识图谱嵌入技术与预训练语言模型深度融合,我们可以增强系统的推理能力,使其既能够从结构化知识中获取准确信息,又能从非结构化文本中提取语义信息。这种融合的一个典型场景是在问答系统中。BERT等预训练模型能够通过自然语言理解技术解析问题的意图,而知识图谱嵌入则可以提供精确的实体关系推理。例如,问题“糖尿病的并发症有哪些?”不仅需要基于文本理解问题的意思,还需要通过知识图谱找到相关的并发症列表。通过融合语言模型的强大文本处理能力和知识图谱的符号推理能力,可以为复杂的医疗问答提供更加准确和全面的答案。同时,预训练模型的上下文感知能力也可以帮助改进知识图谱嵌入的推理路径。例如,当面对模糊问题时,预训练模型可以通过上下文给出合理的猜测,从而为知识图谱提供初始推理线索。这种跨模型的深度结合正在被越来越多的研究者和工业界关注,尤其在大规模多领域问答和推荐系统中,已经开始展现出巨大的潜力。
适应大规模图谱
随着信息量的激增,知识图谱的规模正在迅速扩大。例如,医疗、金融、法律等领域的知识图谱不仅包含了海量的实体和关系,还包括大量复杂的上下游关联。处理这些大规模知识图谱是一个巨大的挑战,尤其是在推理任务中,多跳推理需要通过多层次的关系链进行推断。为了应对大规模知识图谱推理带来的计算负载,分布式训练与推理技术显得尤为重要。分布式计算环境下,图神经网络(Graph Neural Networks, GNN)成为了处理大规模知识图谱的核心技术之一。GNN通过将图结构的局部信息整合到节点表示中,能够在不丢失图结构信息的情况下进行并行化处理。通过分布式框架如TensorFlow、PyTorch等,我们可以将大规模知识图谱拆分成多个子图,并行计算推理路径。这种方式极大地提升了处理大规模图谱的效率,尤其在多跳推理任务中,可以显著减少训练和推理的时间。此外,研究者们也在探索更加高效的知识图谱压缩与索引技术,例如通过生成规则和模式来压缩图谱,使得在图谱中的检索更加快速。同时,基于分布式存储和图数据库(如Neo4j)的优化方案,也为大规模知识图谱的推理带来了更高的存储和访问效率。随着图计算技术和硬件支持的不断提升,知识图谱嵌入与多跳推理将能够处理更大、更复杂的数据集,进一步扩展其应用场景。
应用场景扩展
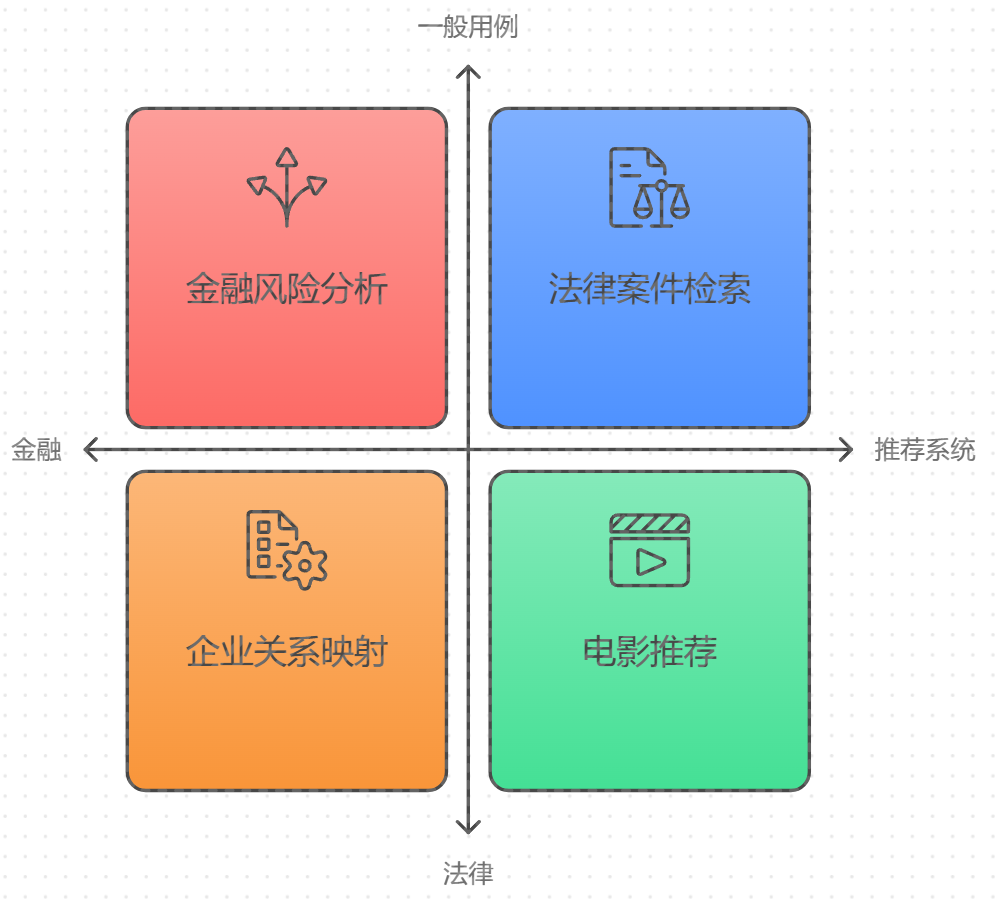
知识图谱嵌入与多跳推理技术不仅在医疗领域大放异彩,它们还在多个领域展现了广泛的应用前景。例如,在金融领域,多跳推理技术可以帮助分析企业之间的关联、追踪金融交易的链条,并识别潜在的风险。例如,通过多跳推理可以分析企业的股权结构、找出隐秘的关联交易,进而评估一个企业的潜在财务风险。在法律领域,通过构建法律知识图谱,可以实现复杂的法律推理和判例检索。用户输入某个法律问题后,系统可以通过多跳推理找到相关法律条文、判例及解释文档,生成具有参考价值的法律建议。这种技术还可以帮助法律工作者快速定位相似案件,辅助他们进行更为准确的法律推理和判决分析。此外,在推荐系统中,知识图谱嵌入与多跳推理的结合也起到了至关重要的作用。例如,电影推荐系统可以通过多跳推理分析用户的观影记录,找到用户喜欢的演员、导演、类型,进而推荐用户可能感兴趣的电影。这种基于知识图谱的推荐不仅限于用户的行为数据,还可以结合更为复杂的关联信息,如影片之间的评分、评论等,实现更加智能化和个性化的推荐。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号