DeepSpeed分布式训练框架深度学习指南
原创DeepSpeed分布式训练框架深度学习指南
原创
引言
随着深度学习模型规模的日益增大,训练这些模型所需的计算资源和时间成本也随之增加。传统的单机训练方式已难以应对大规模模型的训练需求。分布式训练作为一种有效的解决方案,通过将模型和数据分布到多个计算节点上,实现了并行计算,从而显著提高了训练速度。DeepSpeed是由微软开源的深度学习训练优化库,专为分布式训练场景设计,旨在提高大规模模型训练的效率和可扩展性。本文将深入探讨DeepSpeed的背景知识、业务场景、功能点、解决的技术难点,并通过分布式Python示例展示其实际应用。
一、背景知识
1.1 深度学习模型的规模挑战
近年来,深度学习模型在各个领域取得了显著的成果,但模型的规模和复杂度也在不断增加。从自然语言处理的大规模预训练模型到计算机视觉中的深层神经网络,训练这些模型需要巨大的计算和内存资源。然而,硬件发展的速度远不及模型规模增长的速度,导致训练过程变得异常缓慢且成本高昂。
1.2 分布式训练的基本原理
分布式训练通过将模型和数据分布到多个计算节点上,实现了并行计算。每个节点独立处理数据的一个子集,并在训练过程中进行参数同步,从而加速训练过程。分布式训练主要包括数据并行、模型并行和流水线并行三种方式。
- 数据并行:将数据集分割成小块,每个节点处理数据的一个子集,并在训练过程中进行参数同步。
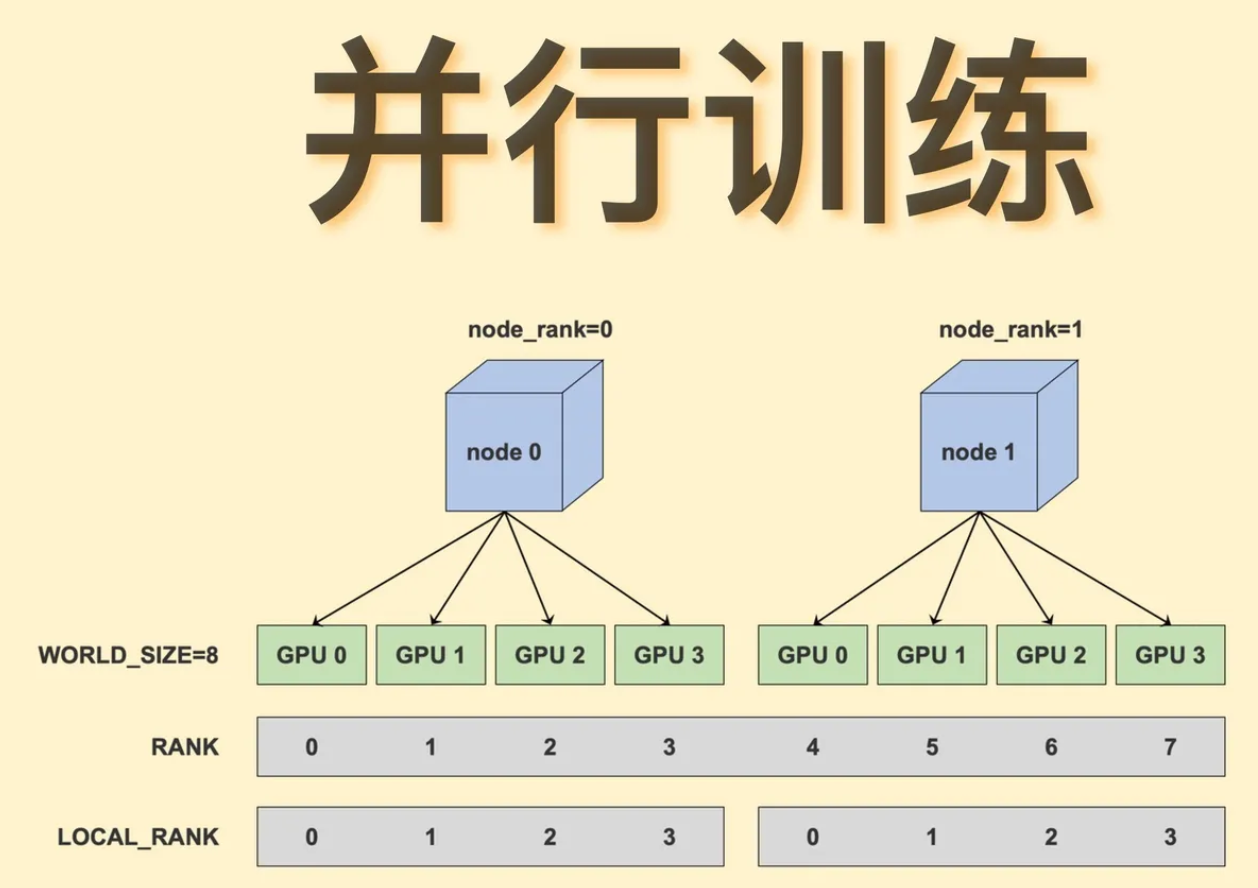
- 模型并行:将模型的不同部分分配到不同的节点上,每个节点负责模型的一部分计算。
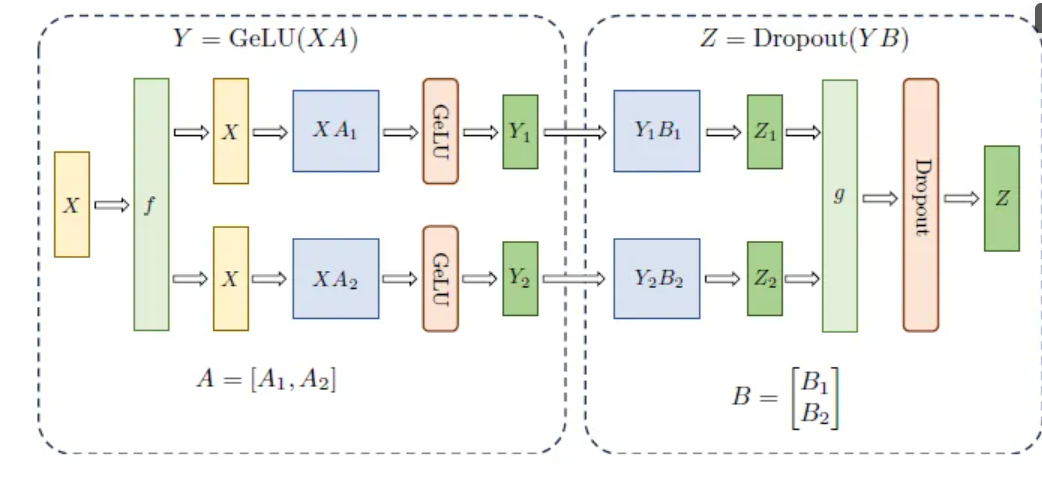
- 流水线并行:将模型的不同层分配到不同的节点上,形成流水线式的计算过程。
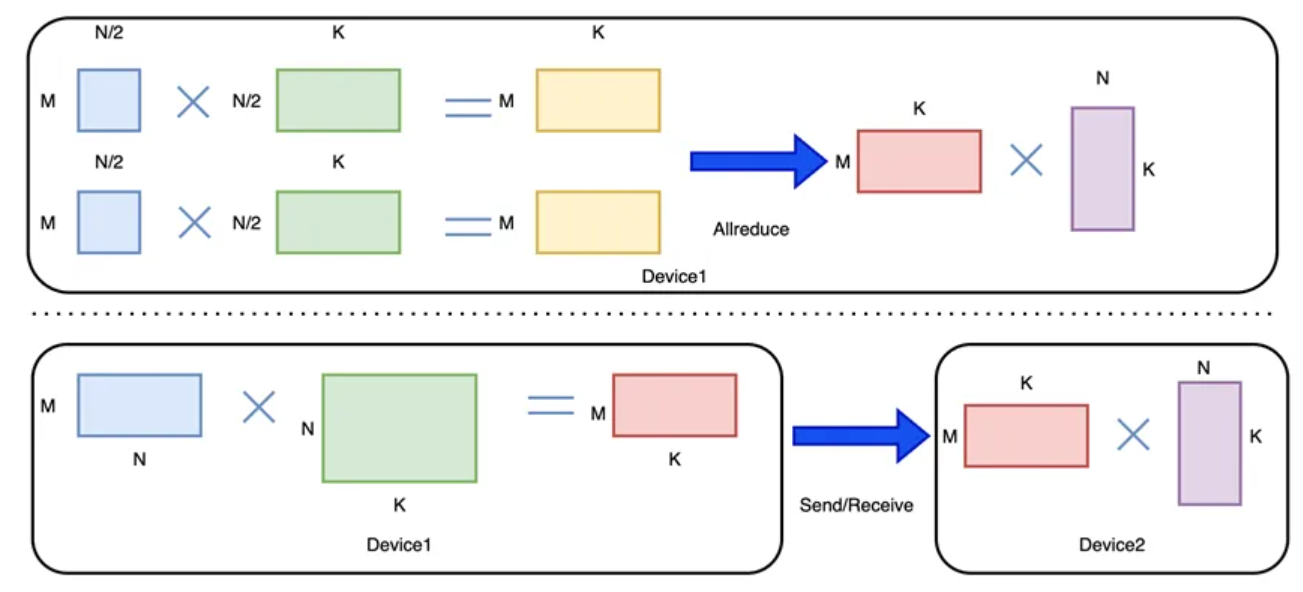
二、业务场景
DeepSpeed广泛应用于各种需要大规模模型训练的业务场景,包括但不限于:
- 自然语言处理:如训练BERT、GPT等大型语言模型。
- 计算机视觉:如训练ResNet、VGG等大型卷积神经网络。
- 推荐系统:如训练基于深度学习的推荐算法。
这些业务场景的共同特点是模型规模大、训练数据多、计算资源需求高。DeepSpeed通过其高效的分布式训练和优化技术,显著提高了这些场景下的训练速度和资源利用率。
三、功能点
DeepSpeed提供了丰富的功能点,以满足不同场景下的训练需求。以下是DeepSpeed的主要功能点:
3.1 Zero Redundancy Optimizer (ZeRO)
ZeRO是DeepSpeed的核心优化技术,旨在通过消除数据并行训练中的冗余内存开销来降低内存占用。ZeRO将模型的参数、梯度和优化器状态进行分片,并分布到多个计算节点上,从而实现内存的高效利用。ZeRO分为多个阶段,每个阶段都进一步减少内存占用和通信开销。
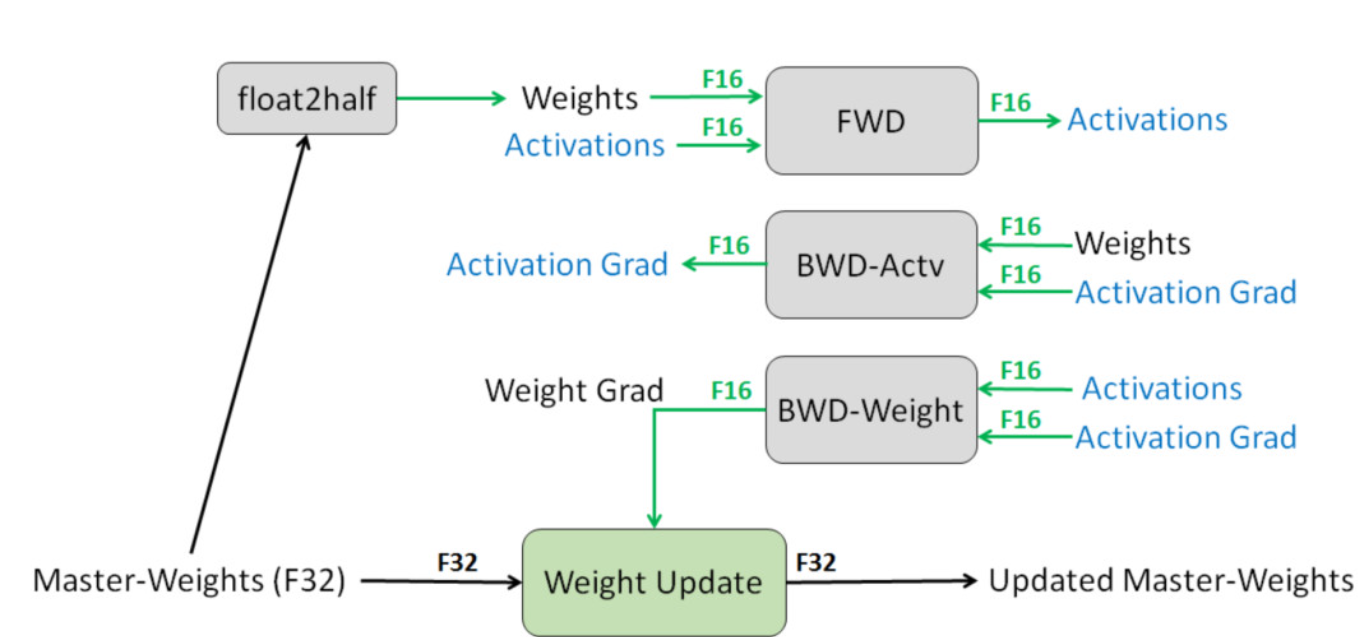
3.2 混合精度训练
DeepSpeed支持混合精度训练,即同时使用单精度和半精度浮点数进行训练。这种方法可以在保持模型性能的同时,减少内存占用和计算时间,降低能耗。
3.3 通信优化
DeepSpeed通过优化通信机制来减少节点间的数据传输量和延迟。它支持多种通信策略,如NCCL、Gloo等,并根据具体情况选择合适的通信库。此外,DeepSpeed还通过动态通信调度来进一步减少通信开销。
3.4 内存优化
除了ZeRO技术外,DeepSpeed还提供了其他内存优化技术,如激活检查点、梯度累积等。这些技术可以进一步减少内存占用,提高训练效率。
3.5 自定义优化器
DeepSpeed允许用户集成自定义的优化器,以满足特殊需求。用户可以根据自己的模型特点和训练目标来选择合适的优化器,并通过DeepSpeed进行高效的分布式训练。
四、解决的技术难点
DeepSpeed在分布式训练过程中解决了多个技术难点,包括内存瓶颈、通信开销、计算资源利用率低等。以下是DeepSpeed解决的主要技术难点:
4.1 内存瓶颈
在大规模模型训练过程中,内存瓶颈是一个常见问题。传统的数据并行方法会在每个节点上保存完整的模型参数、梯度和优化器状态,导致巨大的内存消耗。DeepSpeed通过ZeRO技术消除了这些冗余内存开销,将内存需求降低到单个节点可以承受的范围内。
4.2 通信开销
分布式训练过程中的通信开销也是一个重要问题。DeepSpeed通过优化通信机制、减少通信量和使用高效的通信库来降低通信开销。此外,DeepSpeed还通过动态通信调度来进一步减少通信延迟和开销。
4.3 计算资源利用率低
在分布式训练过程中,计算资源利用率低也是一个常见问题。DeepSpeed通过高效的并行计算和优化技术提高了计算资源利用率,使得更多的计算资源可以用于实际的训练过程。
五、DeepSpeed的功能点和使用方法
5.1DeepSpeed的功能点
DeepSpeed是一个由微软开发的深度学习优化库,旨在加速大规模模型的训练和推理。它提供了一系列强大的功能,以提高训练效率、减少内存占用和优化通信。以下是DeepSpeed的主要功能点:
5.2ZeRO(Zero Redundancy Optimizer)- ZeRO是DeepSpeed的核心技术,它通过消除数据并行训练中的冗余内存占用,显著降低了训练过程中的内存使用。
- ZeRO分为多个阶段(Stage 0-3),每个阶段都进一步优化了内存使用和通信效率。例如,ZeRO-3将模型参数、梯度和优化器状态分片到每个GPU上,实现了极高的内存节省。
5.3混合精度训练- DeepSpeed支持FP16和FP32混合精度训练,以减少内存占用和加速计算,同时保持模型的精度。
- 混合精度训练通过自动混合精度(AMP)技术实现,该技术能够动态地选择最佳的数值精度以平衡精度和性能。
5.4梯度累积- 梯度累积允许在多个小批量数据上累积梯度,然后进行一次优化器更新,这有助于在内存受限的情况下训练更大的模型。
5.5内存优化- DeepSpeed提供了多种内存优化技术,如激活检查点、梯度累积和参数分片,以减少内存占用并提高训练效率。
5.6通信优化- DeepSpeed通过优化通信机制来减少节点间的数据传输量和延迟,从而提高训练速度。
- 它支持多种通信策略,如All-Reduce、Reduce-Scatter等,并根据具体情况选择合适的通信库(如NCCL)。
5.7自定义优化器- DeepSpeed允许用户集成自定义的优化器,以满足特定模型或训练任务的需求。
5.8模型并行和流水线并行- 除了数据并行外,DeepSpeed还支持模型并行和流水线并行,以适应不同类型的模型和训练需求。
5.9I/O优化- DeepSpeed通过缓存和分布式文件系统等技术优化数据加载和存储速度,减少数据传输时间和网络带宽占用。
5.10推理优化- DeepSpeed还提供了推理优化技术,如模型并行和定制化的推理内核,以降低延迟并提高吞吐量。
5.11集成与兼容性- DeepSpeed支持多个深度学习框架,如PyTorch、TensorFlow和Horovod,便于与现有系统集成。
- 它与Hugging Face Transformers库等主流模型库紧密集成,提供了开箱即用的优化体验。
六、DeepSpeed的使用方法
要使用DeepSpeed进行分布式训练,你需要按照以下步骤进行操作:
6.1安装DeepSpeed- 你可以通过pip安装DeepSpeed:
bash复制代码
pip install deepspeedbash复制代码
git clone https://github.com/microsoft/DeepSpeed.git
cd DeepSpeed
pip install -r requirements.txt6.2准备数据集- 使用PyTorch数据加载器或自定义数据加载器来加载你的数据集。
6.3编写训练脚本- 在你的训练脚本中,使用DeepSpeed提供的分布式训练API。
- 创建一个DeepSpeed引擎实例,并将模型、优化器和数据加载器传递给它。
- 使用DeepSpeed引擎进行前向传播、反向传播和优化器更新。
6.4配置DeepSpeed- 通过JSON配置文件或直接在代码中配置DeepSpeed的参数,如ZeRO阶段、混合精度训练选项、通信策略等。
6.5启动训练- 使用mpirun或其他分布式启动工具来启动训练脚本,并指定所需的GPU数量和其他分布式训练参数。
以下是一个简单的DeepSpeed使用示例:
python复制代码
import torch
import torch.nn as nn
import torch.optim as optim
from deepspeed import DeepSpeedEngine, Hparams
# 定义模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
# 创建模型和优化器
model = SimpleModel()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 定义DeepSpeed配置
hparams = Hparams(
zero_optimization={
"stage": 3, # 使用ZeRO-3进行优化
},
fp16={
"enabled": True, # 启用混合精度训练
},
gradient_accumulation_steps=4 # 梯度累积步数
)
# 初始化DeepSpeed引擎
model_engine, optimizer, _, _ = DeepSpeedEngine(
model=model,
optimizer=optimizer,
config=hparams
)
# 模拟数据加载和训练循环
for epoch in range(10): # 训练10个epoch
for batch in range(100): # 假设有100个batch
# 生成模拟数据
inputs = torch.randn(32, 10) # 假设batch size为32,输入特征维度为10
labels = torch.randn(32, 1) # 假设输出维度为1
# 前向传播
outputs = model_engine(inputs)
loss = nn.MSELoss()(outputs, labels)
# 反向传播和优化
model_engine.backward(loss)
model_engine.step()
print(f'Epoch {epoch+1} complete')在上面的示例中,我们创建了一个简单的线性回归模型,并使用DeepSpeed引擎进行训练。我们通过配置ZeRO-3和混合精度训练来优化内存使用和计算速度。然后,我们模拟了一个训练循环,其中包括数据加载、前向传播、反向传播和优化器更新。
请注意,这只是一个非常简单的示例。在实际应用中,你可能需要根据你的模型和训练需求进行更复杂的配置和优化。建议查阅DeepSpeed的官方文档,以获取更详细的信息和高级用法。
下面是一个使用DeepSpeed进行分布式训练的Python示例。该示例展示了如何在多个计算节点上并行训练一个简单的深度学习模型。
python复制代码
import torch
import torch.nn as nn
import torch.optim as optim
from deepspeed import DeepSpeedEngine, Hparams
# 定义简单的神经网络模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
# 定义损失函数和优化器
model = SimpleModel()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 定义DeepSpeed的配置参数
hparams = Hparams(
zero_optimization={
"stage": 3,
"offload_optimizer": {
"device": "cpu"
},
"overlap_comm": True,
"contiguous_gradients": True,
"reduce_scatter": True,
"reduce_bucket_size": 5e8,
"allgather_bucket_size": 5e8,
"partition_activations": True,
"cpu_offload": True,
"min_num_size": 1e8,
"load_from_fp32_weights": True,
"stage3_gather_fp16_weights_on_model_save": True,
"stage3_prefetch_bucket_size": 5e8,
"stage3_param_persistence_threshold": 1e8,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_fp16_weights_during_training": True,
"offload_param": True,
"pin_memory": True,
"fast_init": True,
"sync_bn_in_backward": True,
"reduce_bucket_size": 5e8,
"allgather_bucket_size": 5e8,
"reduce_scatter": True,
"contiguous_gradients": True,
"overlap_comm": True
},
fp16={
"enabled": True,
"loss_scale": 0,
"initial_scale_power": 16,
"scale_window": 1000
},
gradient_clipping={
"enabled": True,
"clip_value": 1.0
},
train_batch_size=32,
gradient_accumulation_steps=4,
steps_per_print=10
)
# 初始化DeepSpeed引擎
model_engine, optimizer, dataloader, _ = DeepSpeedEngine(
model=model,
optimizer=optimizer,
config=hparams,
dataloader=..., # 这里需要传入你的数据加载器
)
# 定义训练循环
for epoch in range(num_epochs):
for batch in dataloader:
inputs, labels = batch
# 前向传播
outputs = model_engine(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
model_engine.backward(loss)
model_engine.step()
print(f'Epoch {epoch+1} complete')
# 保存模型
model_engine.save_checkpoint('model_checkpoint.pt')总结
DeepSpeed是一个高效的分布式训练框架,它通过一系列优化技术和特性显著提高了大规模模型训练的效率和可扩展性。DeepSpeed广泛应用于自然语言处理、计算机视觉、推荐系统等业务场景,为研究人员和工程师提供了强大的训练工具。通过本文的学习,你可以深入了解DeepSpeed的背景知识、业务场景、功能点、解决的技术难点,并通过分布式Python示例掌握其实际应用。希望这篇文章能对你学习和使用DeepSpeed有所帮助。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
