『学习笔记』如何监控 WebLogic 的运行状态与性能
原创
『学习笔记』如何监控 WebLogic 的运行状态与性能
原创
🎈今日推荐——https://cloud.tencent.com/developer/article/2467394
从零开始学机器学习——入门NLP——这篇文章介绍了自然语言处理(NLP)的基础知识和应用,包括构建基础聊天机器人和情感分析版聊天机器人的步骤。文章强调了Python在NLP中的重要性,并使用TextBlob库进行情感分析和名词短语提取,以提高机器人的交互性和智能性。
WebLogic 是一款功能强大的 Java 应用服务器,广泛应用于企业级应用的部署与管理中。其高效的性能与运行稳定性使其成为开发者和运维人员的首选。然而,为了确保 WebLogic 的高效运行和快速故障排除,实时监控其运行状态和性能至关重要。
随着应用程序的规模和复杂性增加,WebLogic 的运行负载也随之增加,常见的运维挑战包括:
- 性能瓶颈:高并发访问可能导致响应变慢或请求超时。
- 资源监控:CPU、内存、线程池和数据源的使用情况对系统健康至关重要。
- 快速故障排查:需要在故障发生时快速识别和解决问题。
为了应对这些挑战,WebLogic 提供了丰富的监控工具,包括 WebLogic 控制台、JMX(Java Management Extensions)、WLST 脚本等。
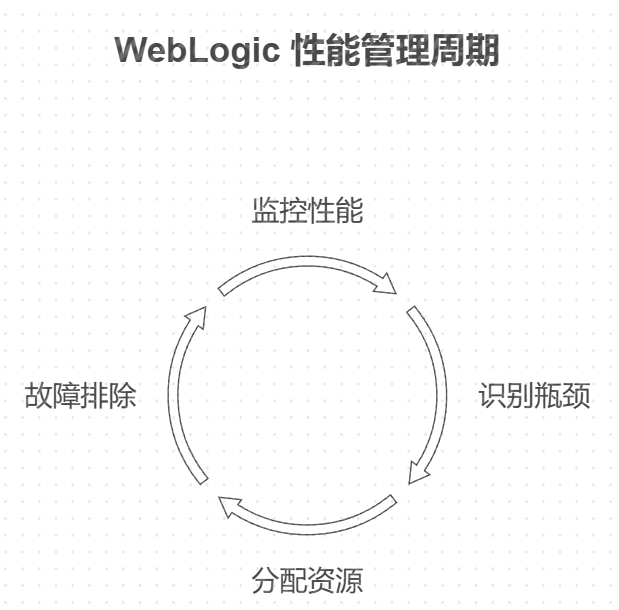
- WebLogic 监控的核心目标
目标 | 描述 |
|---|---|
实时运行状态监控 | 实时查看服务器的健康状态和性能指标 |
提前预警 | 在系统资源耗尽或出现异常之前发出预警 |
故障诊断与优化 | 收集数据以分析问题根因并持续优化性能 |
WebLogic 监控方法概览
WebLogic 提供了多种监控运行状态与性能的方式,以下是主要手段的对比:
方法 | 描述 | 使用场景 |
|---|---|---|
WebLogic 控制台 | 图形界面查看 WebLogic 运行状态与资源使用 | 小规模环境的手动实时监控 |
WLST | 脚本工具,获取监控数据并自动化任务 | 自动化性能分析与报表生成 |
JMX | 通过 Java 接口访问监控指标 | 与第三方监控工具集成 |
SNMP | 简单网络管理协议,发送告警到监控系统 | 集中式告警与网络性能监控 |

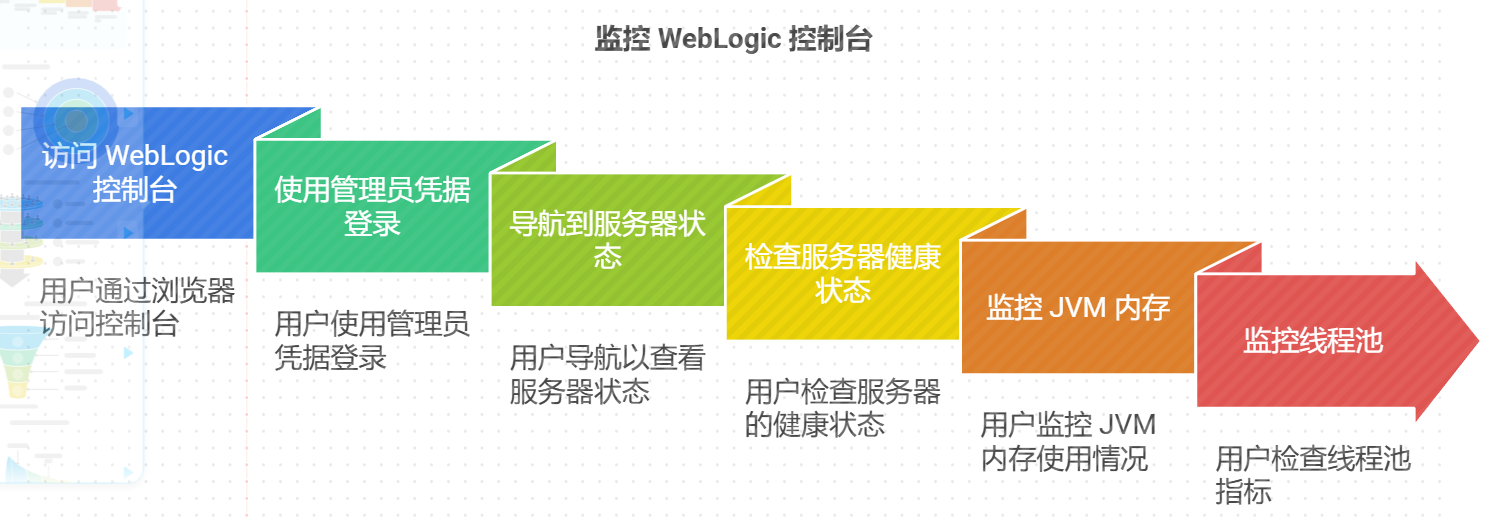
使用 WebLogic 控制台进行监控
- 控制台简介
WebLogic 提供一个直观的 Web 控制台,运维人员可以通过浏览器访问,执行以下任务:
1 查看服务器状态
2 监控线程池、JVM 内存使用情况
3 检查数据源与部署的应用状态
访问路径:
http://<hostname>:<port>/console
- 实例演示
- 登录控制台undefined通过管理员账号登录 WebLogic 控制台。
- 查看服务器运行状态
- 导航到
Environment > Servers。 - 选择目标服务器,查看健康状态(如 RUNNING、FAILED 等)。
- 导航到
- 监控 JVM 使用情况
- 导航到
Environment > Servers > <ServerName>。 - 点击
Monitoring标签,查看 JVM 的堆内存使用率。
- 导航到
- 线程池监控
- 同样在
Monitoring标签中选择Threads选项。 - 查看当前执行线程数量、空闲线程数量等。
- 同样在
指标名称 | 描述 |
|---|---|
堆内存使用率 | JVM 分配的堆内存使用情况 |
当前线程数 | 当前活动线程数量 |
数据源连接状态 | 数据库连接池中可用连接的数量 |
使用 WLST 自动化监控
WLST 是 WebLogic 提供的脚本工具,适用于自动化监控与任务处理。
- 环境准备
- 安装 WebLogicundefined确保 WebLogic 安装完成并运行。
- 配置脚本工作目录
mkdir /opt/weblogic-monitoring
cd /opt/weblogic-monitoring- WLST 监控脚本开发
以下脚本定期监控 JVM 内存使用情况和线程池状态,并将结果输出到日志文件。
WLST 监控脚本示例
文件名:monitorWebLogic.py
from datetime import datetime
import os
# WebLogic 管理服务器信息
admin_url = 't3://localhost:7001'
admin_user = 'weblogic'
admin_password = 'weblogic123'
# 日志文件路径
log_file = '/opt/weblogic-monitoring/monitor.log'
# 连接到 WebLogic 管理服务器
connect(admin_user, admin_password, admin_url)
# 获取服务器列表
servers = cmo.getServers()
# 日志记录函数
def log_message(message):
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
with open(log_file, 'a') as f:
f.write(f'[{timestamp}] {message}\n')
# 监控每个服务器的状态
for server in servers:
server_name = server.getName()
cd(f'/ServerRuntimes/{server_name}')
# 获取 JVM 堆内存使用情况
heap_current = cmo.getHeapFreeCurrent()
heap_max = cmo.getHeapSizeMax()
heap_usage = ((heap_max - heap_current) / heap_max) * 100
# 获取线程池状态
thread_pool = cmo.getThreadPoolRuntime()
active_threads = thread_pool.getExecuteThreadCurrentCount()
hogging_threads = thread_pool.getHoggingThreadCount()
# 输出日志
log_message(f'Server: {server_name}')
log_message(f' JVM Heap Usage: {heap_usage:.2f}%')
log_message(f' Active Threads: {active_threads}')
log_message(f' Hogging Threads: {hogging_threads}')
# 断开连接
disconnect()调度脚本执行
使用 cron 定时执行脚本:
crontab -e添加以下内容,每 5 分钟执行一次:
*/5 * * * * java weblogic.WLST /opt/weblogic-monitoring/monitorWebLogic.py- 集成 ELK 堆栈进行高级日志分析
配置 Logstash
将 WebLogic 日志通过 Logstash 收集到 Elasticsearch:
input {
file {
path => "/path/to/weblogic/logs/*.log"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "weblogic-logs"
}
}在 Kibana 中创建可视化
- 创建 Dashboard:
- 展示错误日志数量、日志级别分布等指标。
- 设置告警规则:
- 当错误数量超过阈值时触发告警。
性能优化建议
在实际运维中,为了保证 WebLogic 系统的高效运行,对日志进行优化并与监控工具集成是关键的一环。以下内容将详细阐述日志优化与监控预警的具体实施方法和注意事项。
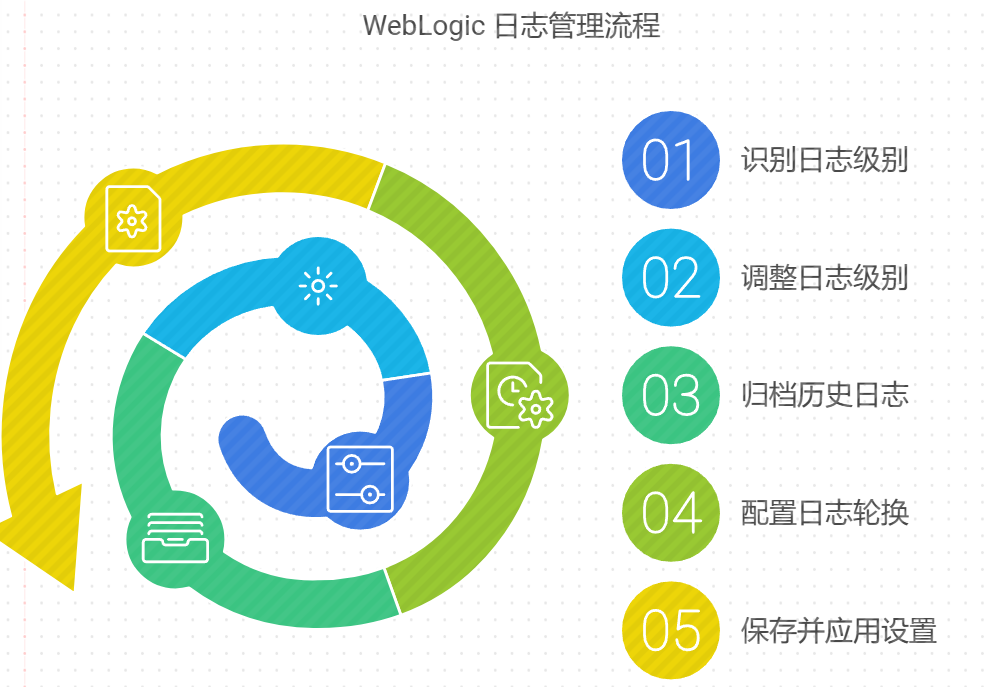
- 1 日志优化
日志是问题排查的重要依据,但过量的日志记录可能影响系统性能。通过合理调整日志级别与归档策略,可以减少系统开销,同时确保必要的信息被完整记录。
调整日志级别
WebLogic 日志记录的详细程度可以通过日志级别进行控制,常见的日志级别包括 INFO、WARNING、ERROR 等。
在生产环境中,不建议启用 DEBUG 或 INFO 级别的日志记录,以减少性能开销。
级别 | 描述 | 适用场景 |
|---|---|---|
| 记录系统的详细运行状态,用于调试应用程序或分析细节问题。 | 仅用于开发或测试环境,不适合生产环境。 |
| 记录系统的正常运行信息,如启动、停止等事件。 | 用于开发或测试环境,生产环境应避免使用。 |
| 记录潜在问题或非严重错误,例如资源接近极限或配置问题。 | 适合生产环境,可监控潜在风险。 |
| 记录严重问题,例如系统错误或服务不可用。 | 强烈推荐在生产环境中设置为最低日志级别。 |
| 记录系统不可恢复的关键错误,通常需要立即处理。 | 适用于生产环境的报警通知。 |
操作步骤:调整日志级别
- 登录 WebLogic 控制台。
- 导航至
Domain Structure > Environment > Servers。 - 选择目标服务器,进入
Logging > General配置页面。 - 将
Log Level设置为WARNING或ERROR。 - 保存配置并重启服务器。
归档历史日志
随着系统运行时间增长,日志文件的大小会不断增大,这可能导致磁盘空间不足或文件操作变慢。因此,需要定期归档历史日志并清理旧日志。
归档策略 | 描述 |
|---|---|
时间归档 | 按时间间隔(如每天、每周)自动归档旧日志。 |
大小归档 | 当日志文件达到指定大小时自动归档(例如 10MB)。 |
多级存储 | 将历史日志存储在低成本的存储设备(如云存储)上,以节省本地存储空间。 |
归档压缩 | 将归档的日志文件压缩为 |
操作步骤:配置日志归档
- 登录 WebLogic 控制台。
- 导航到目标服务器的
Logging > File页面。 - 启用
Rotate Log Files,选择合适的归档方式:- By Size:根据文件大小归档(推荐)。
- By Time:根据时间间隔归档。
- 配置
Number of Files Limited,指定最大保留的归档文件数量。 - 保存并应用设置。
- 2 监控与预警
为保证系统能够在问题发生前或刚发生时迅速响应,需要结合监控工具与预警机制对 WebLogic 的性能和运行状态进行持续监控。
使用 SNMP 或 JMX 进行监控
SNMP 和 JMX 是 WebLogic 提供的两种常用监控接口,它们允许管理员采集关键运行数据并集成至第三方监控系统(如 Zabbix、Nagios)。
工具 | 描述 | 适用场景 |
|---|---|---|
SNMP | 简单网络管理协议,可监控系统性能指标并设置告警规则。 | 适合基础监控,适用于大部分生产环境。 |
JMX | Java 管理扩展,允许通过 MBeans 获取详细的性能指标和运行数据。 | 适合高级监控和定制化需求,如监控线程或 JDBC。 |
操作步骤:启用 SNMP 监控
- 登录 WebLogic 控制台。
- 导航至
Domain Structure > Environment > Servers > Monitoring. - 配置 SNMP Trap Server 的地址及端口。
- 启用 SNMP Trap,设置告警规则,例如 CPU 超过 80% 时发送 Trap 消息。
操作步骤:通过 JMX 监控性能
- 在 Java 程序中连接 WebLogic 的 JMX 服务端口。
- 使用
javax.management包编写脚本获取性能指标。 示例代码:
import javax.management.*;
import javax.management.remote.*;
public class WebLogicJMXMonitor {
public static void main(String[] args) throws Exception {
JMXServiceURL url = new JMXServiceURL("service:jmx:rmi:///jndi/rmi://<HOST>:<PORT>/jmxrmi");
JMXConnector connector = JMXConnectorFactory.connect(url, null);
MBeanServerConnection connection = connector.getMBeanServerConnection();
ObjectName runtimeName = new ObjectName("com.bea:Name=RuntimeService,Type=weblogic.management.mbeanservers.runtime.RuntimeServiceMBean");
String serverName = (String) connection.getAttribute(runtimeName, "Name");
System.out.println("Server Runtime Name: " + serverName);
connector.close();
}
}定期分析性能指标
为了避免性能问题累积,应定期分析以下关键指标:
- 线程池使用率:识别线程瓶颈。
- JDBC 数据源活动连接:检测数据库连接池问题。
- JMS 队列大小:发现消息队列堆积问题。
- 系统资源:CPU、内存、磁盘 IO 等。
指标 | 描述 | 建议值 |
|---|---|---|
线程池利用率 | 线程池中正在使用的线程比例。 | 不超过 80%,高于 90% 时需优化应用或扩容。 |
数据库连接池活动连接数 | 当前正在使用的数据库连接数。 | 应小于最大连接池大小,避免超过 90%。 |
JMS 队列积压消息数量 | 队列中未被消费的消息数。 | 应尽量为 0,积压严重时需检查消费者性能。 |
Heap 使用率 | JVM 堆内存的利用率。 | 小于 85%,超出时需增加堆内存或排查泄漏。 |
操作步骤:分析指标
- 定期从 WebLogic 管理控制台导出性能数据。
- 使用图表工具(如 Grafana)可视化关键指标。
- 设置预警规则,当指标超出阈值时触发告警。

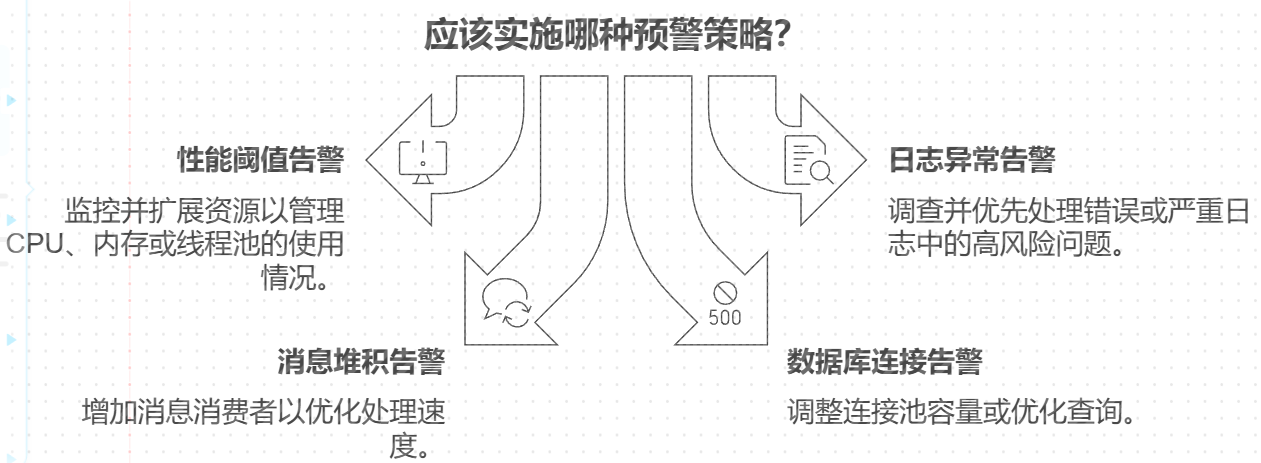
- 3 预警策略
在监控的基础上,制定合理的预警策略,以便在系统异常或接近阈值时采取主动措施:
预警类型 | 描述 | 响应措施 |
|---|---|---|
性能阈值告警 | CPU、内存或线程池利用率超出阈值。 | 检查应用负载,扩展资源。 |
日志异常告警 | 日志中出现大量 | 排查问题根因,优先处理高危问题。 |
消息堆积告警 | JMS 队列中消息积压数量超过警戒线。 | 增加消息消费者,优化处理速度。 |
数据库连接告警 | 活跃连接数接近或超过连接池最大值。 | 增加连接池容量或优化查询性能。 |
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
