Elasticsearch 查询时 term、match、match_phrase、match_phrase_prefix 的区别
原创
Elasticsearch 查询时 term、match、match_phrase、match_phrase_prefix 的区别
原创
六月的雨在Tencent
发布于 2024-12-02 17:36:29
发布于 2024-12-02 17:36:29
好事发生
今天要讲的好事发生文章是一篇关于函数式接口FUNCTION的介绍性文章,文章标题【了解函数式接口FUNCTION】,文章链接:https://cloud.tencent.com/developer/article/2472759 这篇文章介绍了Java中的函数式接口概念、特点、使用方式及在Stream API中的应用,强调了其在函数式编程中的重要性和灵活性。感兴趣的小伙伴可以参考一下。
下面开始今天的文章正文...
在日常工作中,大家在使用es查询的时候,会经常性的和es查询关键词 term、match、match_phrase、match_phrase_prefix 打交道,今天这篇文章就是主要阐述它们之间的区别。在深入了解这些查询类型之前,有必要先明确ES中的两种文本字段类型——keyword和text之间的差异。
keyword 与 text 区别
在 es 创建索引中,经常会遇到 keyword 、text 字段类型的选择,其实他们之间的区别也比较容易理解。
keyword:在索引时,keyword类型的数据不会被分词器处理,而是直接作为整体存储到索引中。
text:在索引时,text类型的数据会经过分词器处理,将文本切分成多个词条,然后存储到索引中。
可以通过以下命令来查看分词结果,es 不指定分词器则走的是 es 默认的分词器(通常情况下都是单字)
查看 text 字段类型分词结果
POST /_analyze
{
"text": "很高兴为您服务"
}执行命令后的分词查询结果如图所示
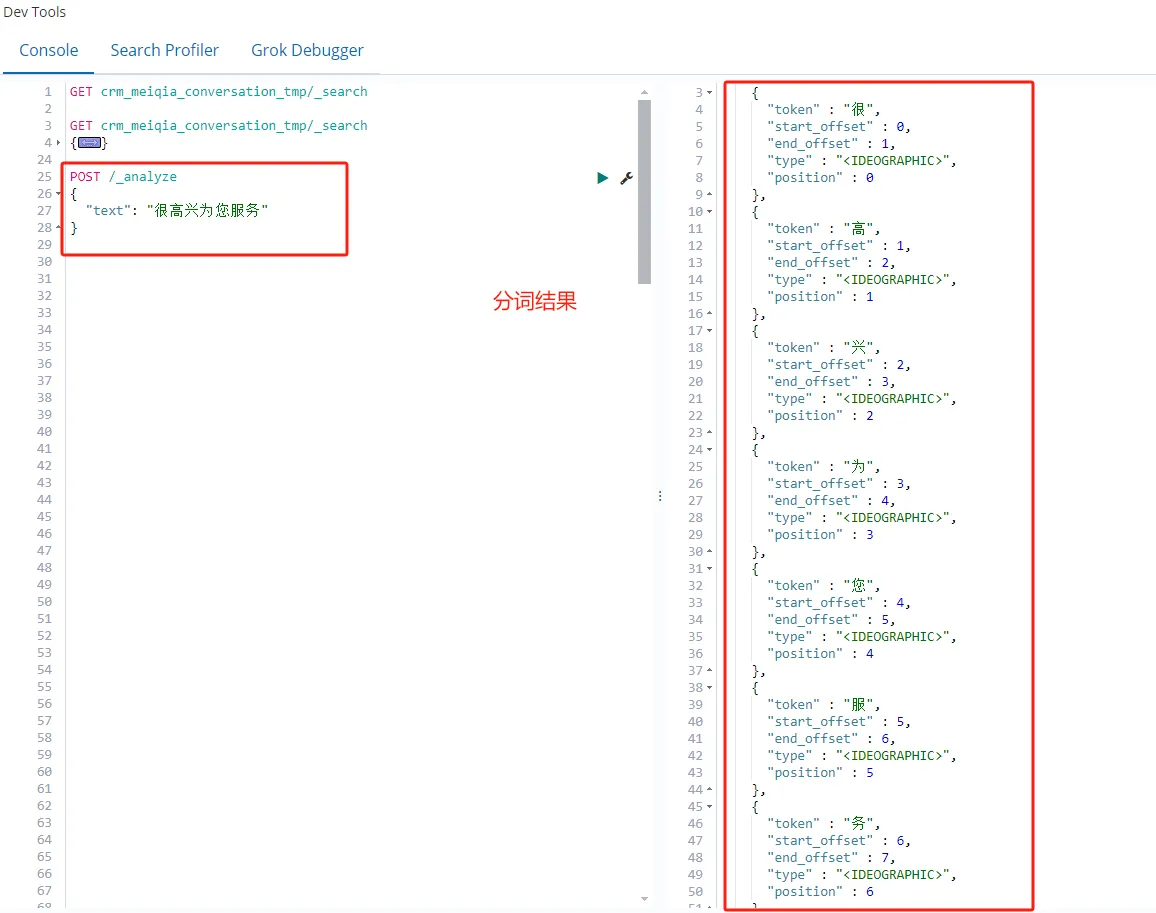
下面我们再来查看 keyword 字段类型分词结果,执行如下命令
POST /_analyze
{
"analyzer": "keyword",
"text": "很高兴为您服务"
}执行结果如图所示
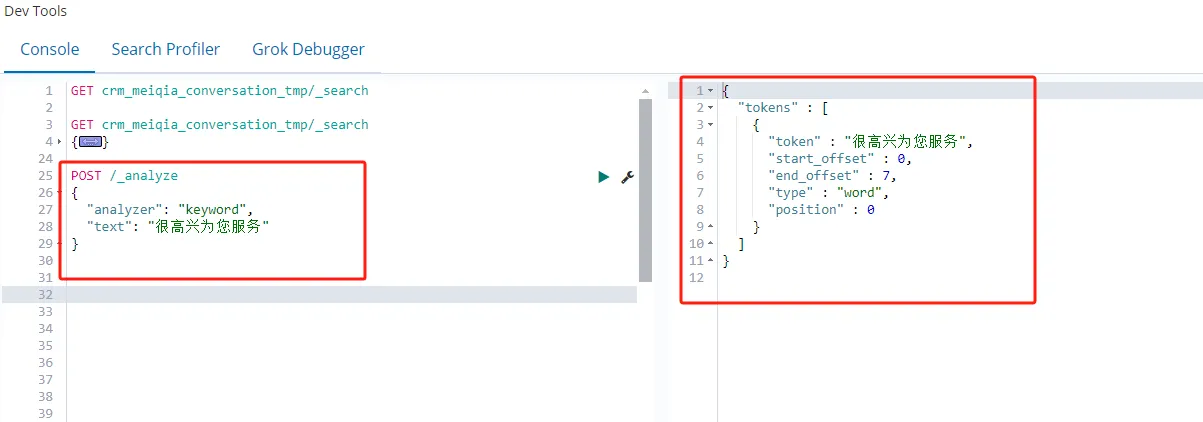
从上面两条命令的执行结果来看,那么keyword 和 text 类型字段的区别就很明显了。
keyword类型:在数据索引阶段,该类型的数据不会经过分词器的处理,而是保持原样作为一个完整的单元被直接存储到索引中。
text类型:与keyword不同,text类型的数据在索引过程中会先接受分词器的处理,将原始文本分解为多个独立的词条,随后这些词条被存储到索引中。
term 查询
term 查询用于精确值匹配,它不会对查询的文本进行分词处理,直接在索引中查找精确值。
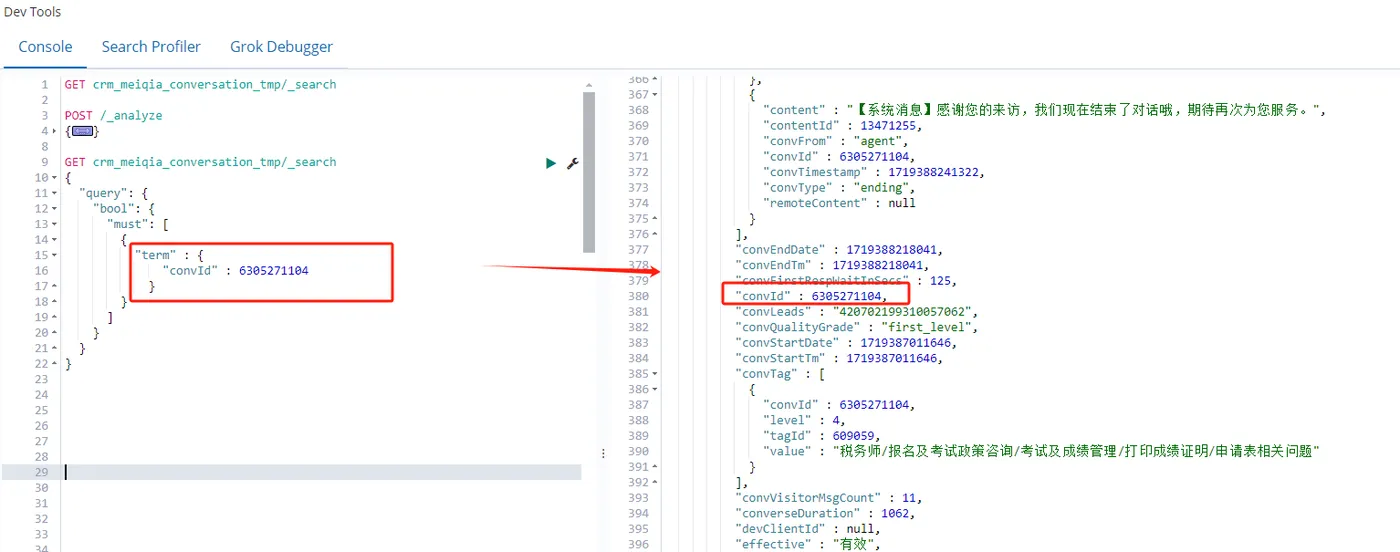
适用场景:适用于关键字(keyword)类型的字段,或者已经过精确值(如数字、日期等)处理的文本字段。这里我用 term 查询来精确查询 convId属性字段
GET crm_meiqia_conversation_tmp/_search
{
"query": {
"bool": {
"must": [
{
"term" : {
"convId" : 6305271104
}
}
]
}
}
}查询结果如图
match 查询
match 查询是一种全文搜索查询,它会对查询文本进行分词处理,然后搜索分词后的结果。它适用于 text 类型的字段。
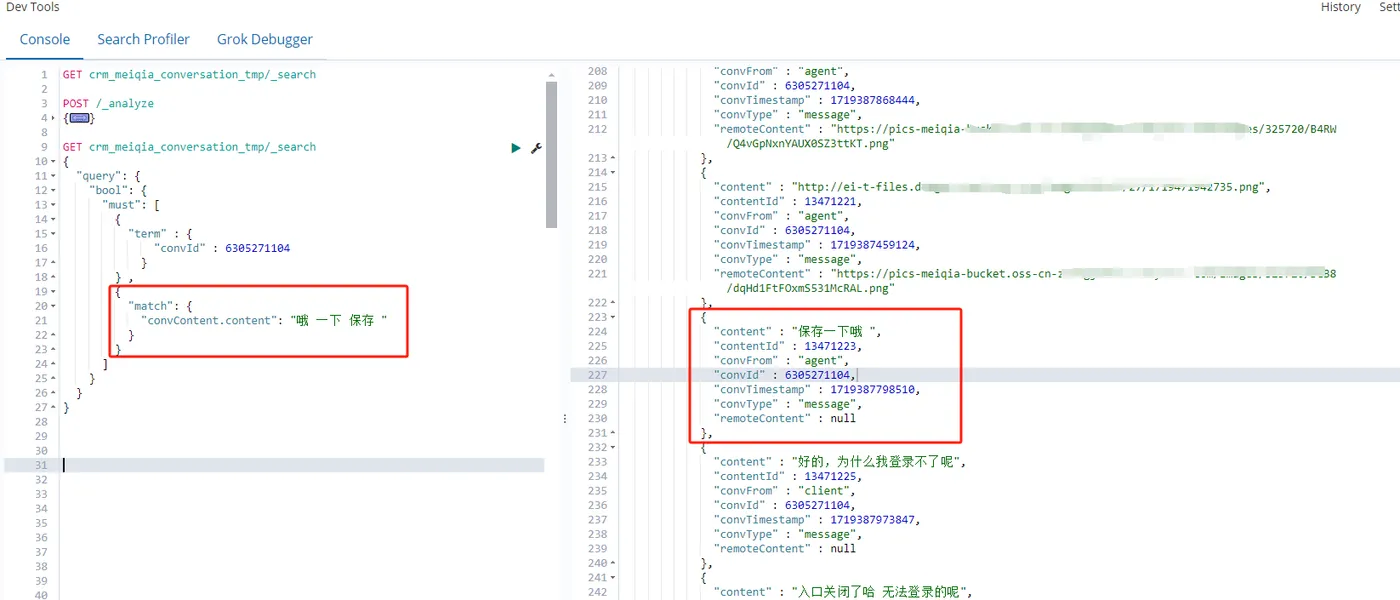
适用场景:用于执行全文搜索,适合于搜索文本内容。这里我搜索一下索引中的 text 类型字段 ,由于表数据比较多,因此上一次查询的 convId 字段我还保留。
GET crm_meiqia_conversation_tmp/_search
{
"query": {
"bool": {
"must": [
{
"term" : {
"convId" : 6305271104
}
} ,
{
"match": {
"convContent.content": "哦 一下 保存 "
}
}
]
}
}
}查询结果如图
match_phrase 查询
match_phrase 查询是一种精确短语匹配查询,它会在文本中查找包含指定短语的文档,同时考虑短语的顺序和位置。
适用场景:适用于需要精确匹配短语的场景,如引用搜索、精确短语匹配等。比如这里我们还查询上面的一段话,查看一下查询结果,顺序不对的话应是查询不到结果的
GET crm_meiqia_conversation_tmp/_search
{
"query": {
"bool": {
"must": [
{
"term" : {
"convId" : 6305271104
}
} ,
{
"match_phrase": {
"convContent.content": "哦 一下 保存 "
}
}
]
}
}
}查询结果如图
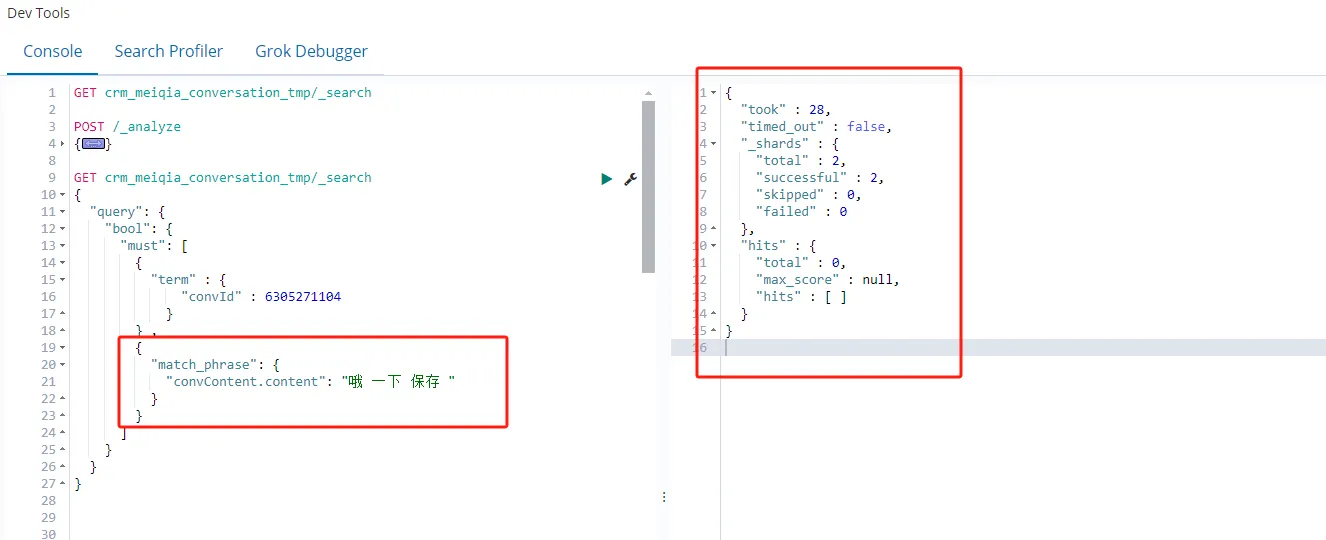
match_phrase_prefix 查询
match_phrase_prefix 查询是 match_phrase 查询的一个变种,它允许对查询短语的最后一个单词进行前缀匹配。
适用场景:适用于需要匹配以特定前缀开头的短语且对查询精度要求较高的场景。这里查询要求前缀匹配,类似于 mysql 的 like 查询 的 “保存%”
GET crm_meiqia_conversation_tmp/_search
{
"query": {
"bool": {
"must": [
{
"term" : {
"convId" : 6305271104
}
} ,
{
"match_phrase_prefix": {
"convContent.content": "保存 一下 "
}
}
]
}
}
}查询结果如图
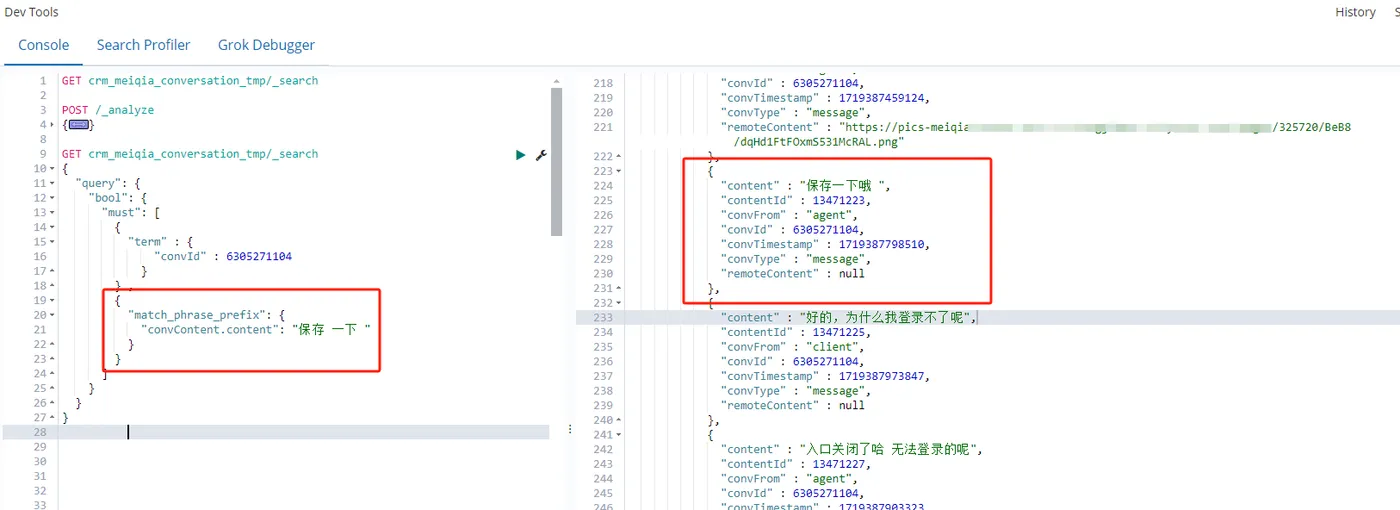
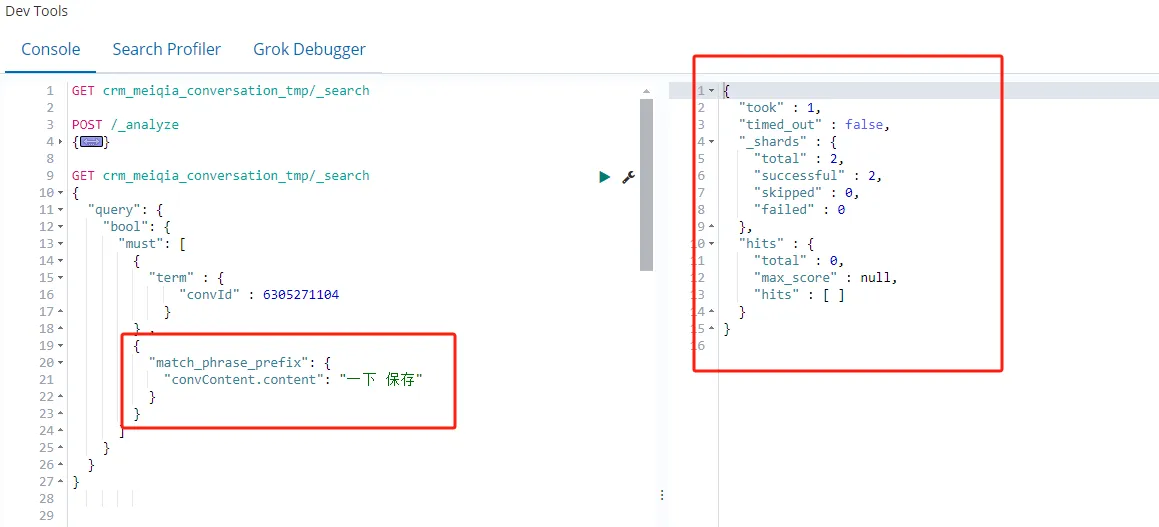
更换一下顺序,就无法通过前缀匹配到内容了,比如
GET crm_meiqia_conversation_tmp/_search
{
"query": {
"bool": {
"must": [
{
"term" : {
"convId" : 6305271104
}
} ,
{
"match_phrase_prefix": {
"convContent.content": "一下 保存"
}
}
]
}
}
}查询结果如图
写在最后
在Elasticsearch查询中,对于上面讲述的四种不同的查询方式,有他们各自的适用场景和使用方法。在使用时可以根据具体的业务需求来采用不同的查询方式,帮助大家更好的使用Elasticsearch查询语句。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号