Vitron:颜水成团队开源通用视觉多模态大模型、像素级智能、一统理解/生成/分割/编辑

Vitron:颜水成团队开源通用视觉多模态大模型、像素级智能、一统理解/生成/分割/编辑

AI进修生
发布于 2024-12-02 18:50:44
发布于 2024-12-02 18:50:44
Aitrainee | 公众号:AI进修生
🌟Vitron利用LLM作为核心,结合图像、视频和像素级区域编码器,采用文本为中心的策略,集成先进模块,支持从视觉理解到生成的各种任务。通过视觉语言对齐和区域感知调优,Vitron实现了精确的像素级感知。

Hi,这里是Aitrainee,欢迎阅读本期新文章。
当前的视觉大语言模型虽然已经取得了长足的进步,但仍面临一些难题:比如粗粒度实例级理解、缺乏对图像和视频的统一支持,以及在各种视觉任务中的覆盖范围不足。
今天我们来介绍Vitron——一个由颜水成教授带队,昆仑万维2050全球研究院、新加坡国立大学和新加坡南洋理工大学团队联合发布并开源的通用像素级视觉多模态大语言模型。
Vitron作为一个统一的像素级视觉多模态大语言模型,它能够全面处理从图像到视频,从理解到生成,再到编辑的所有任务。实现了从低层次到高层次的视觉任务的全面支持。同时,Vitron支持与用户的连续操作,实现了灵活的人机互动,展示了通向更统一的视觉多模态通用模型的巨大潜力。
我们先来看看Vitron的任务支持和主要功能:
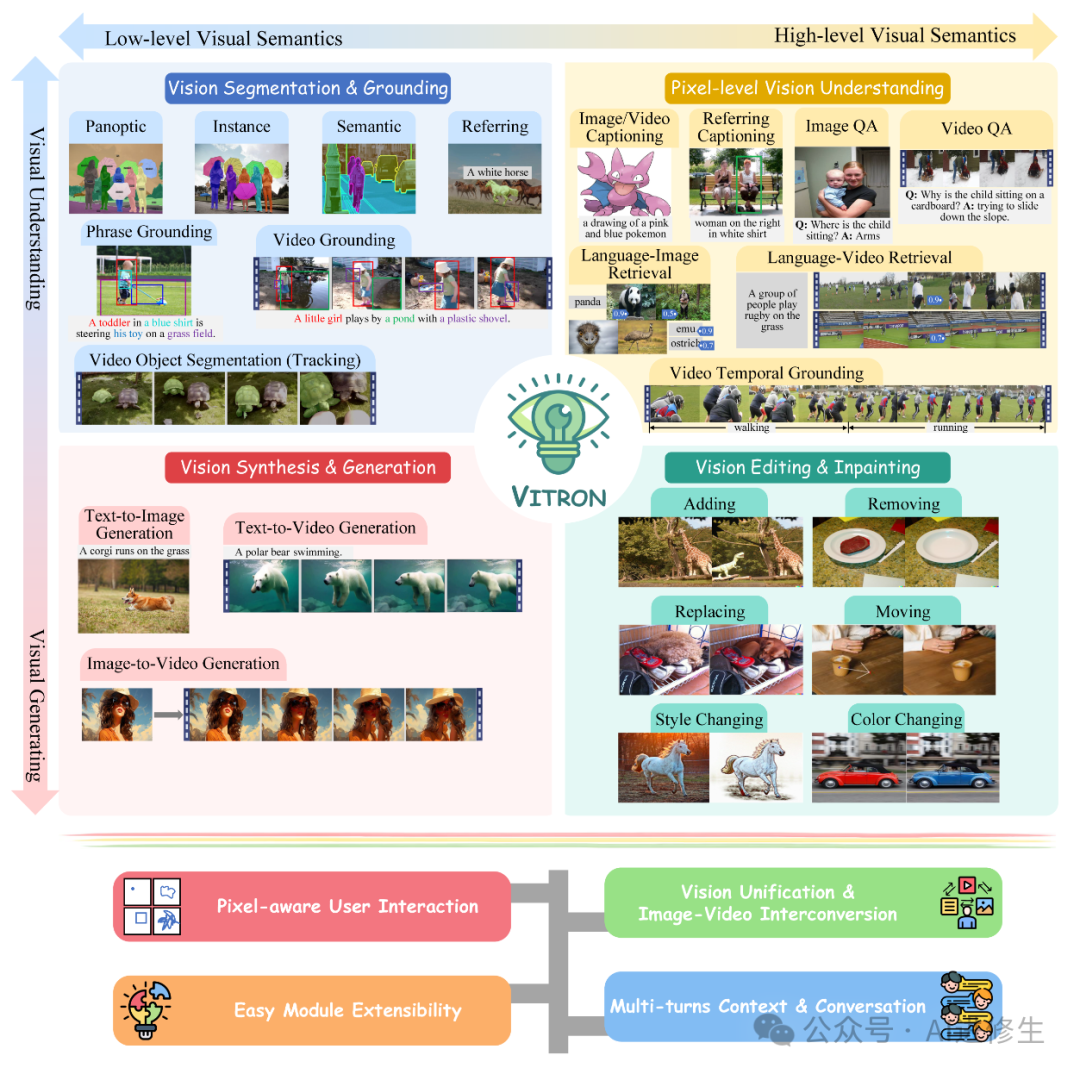
这张图展示了Vitron模型的功能和特点。让我详细解释每个部分的含义:
图的主要部分:
- 1. 低层视觉语义(Low-level Visual Semantics):图的左边区域,主要涉及视觉分割和定位。
- 2. 高层视觉语义(High-level Visual Semantics):图的右边区域,主要涉及像素级的视觉理解。
详细说明:
1. 视觉分割和定位(Vision Segmentation & Grounding)
- • Panoptic、Instance、Semantic、Referring:分别指全景分割、实例分割、语义分割和指代分割,这些都是对图像中物体进行不同粒度的分割。
- • Phrase Grounding:根据短语定位图像中的对应部分。
- • Video Grounding:在视频中定位和识别特定对象。
- • Video Object Segmentation (Tracking):在视频中分割和跟踪目标对象。
2. 像素级视觉理解(Pixel-level Vision Understanding)
- • Image/Video Captioning:为图像或视频生成描述性文本。
- • Referring Captioning:生成指代性描述。
- • Image QA & Video QA:图像和视频问答。
- • Language-Image/Video Retrieval:语言和图像/视频检索。
- • Video Temporal Grounding:在视频中定位特定时间段的事件。
3. 视觉合成和生成(Vision Synthesis & Generation)
- • Text-to-Image/Video Generation:根据文本生成图像或视频。
- • Image-to-Video Generation:根据图像生成视频。
4. 视觉编辑和修复(Vision Editing & Inpainting)
- • Adding/Removing:在图像中添加或移除对象。
- • Replacing/Moving:替换或移动对象。
- • Style Changing/Color Changing:改变图像风格或颜色。
支持功能:
- • Pixel-aware User Interaction:支持像素级别的用户交互。
- • Easy Module Extensibility:模块化扩展的方便性。
- • Vision Unification & Image-Video Interconversion:统一的视觉处理以及图像和视频的互转换。
- • Multi-turns Context & Conversation:多轮对话和上下文理解。
通俗解释
Vitron就像一个超级智能的视觉助手,不仅能识别和理解图像和视频中的所有细节,还能根据你的需求生成和编辑内容。想象一下,Vitron就像一个视觉魔术师,你只需描述你的需求,它就能立刻帮你实现。
对比说明
- • 传统模型:处理图像和视频时,像是用不同的工具完成不同的任务,效率低下且容易出错。
- • Vitron:Vitron就像一把瑞士军刀,一个工具就能完成所有任务,既高效又精准。
小结一下
Vitron不仅填补了当前视觉大语言模型的多项短板,还实现了视觉任务的全面覆盖。从低层次的视觉语义理解到高层次的视觉内容生成,Vitron都能应对自如。无论是理解、生成、分割还是编辑,Vitron都为未来的视觉技术发展开辟了新的道路。
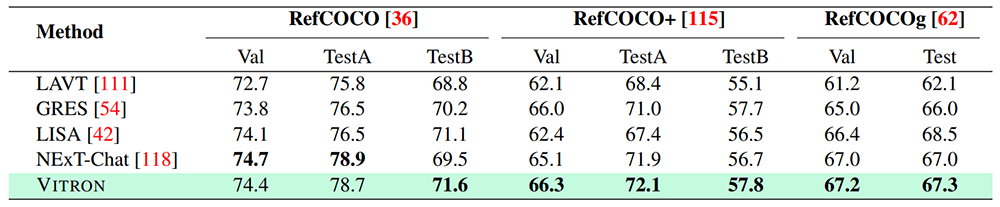
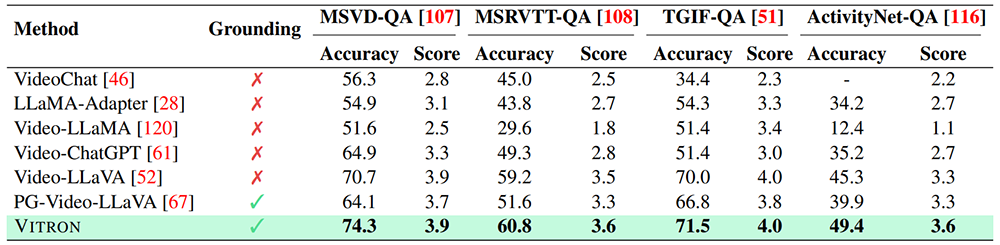
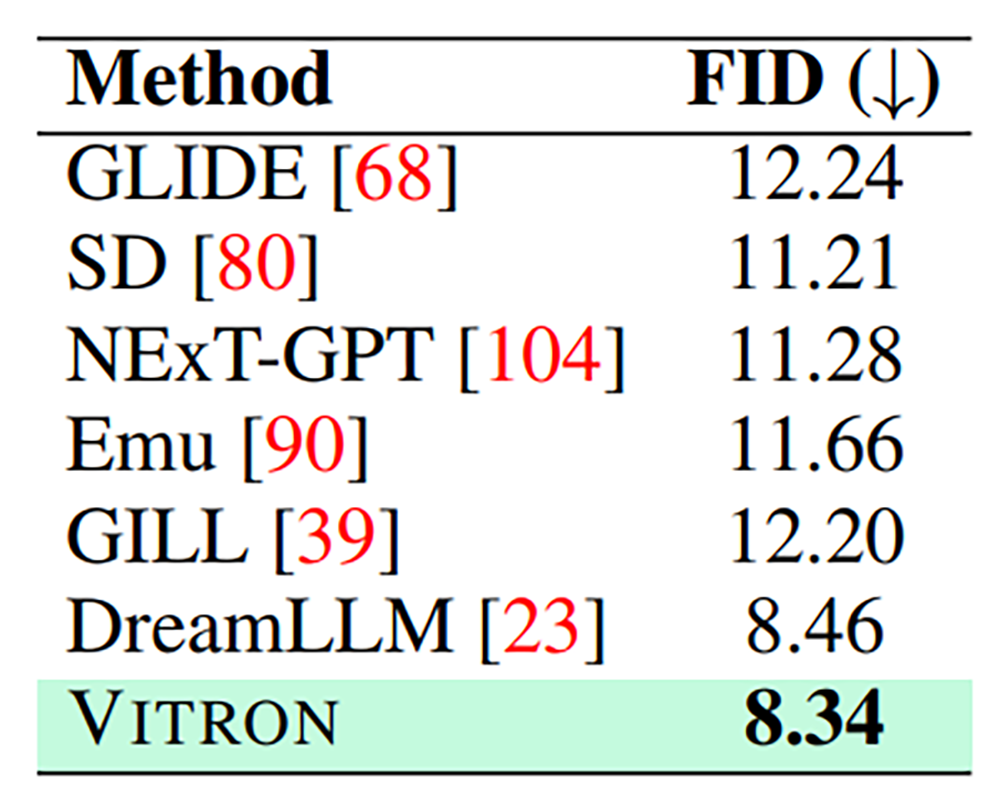
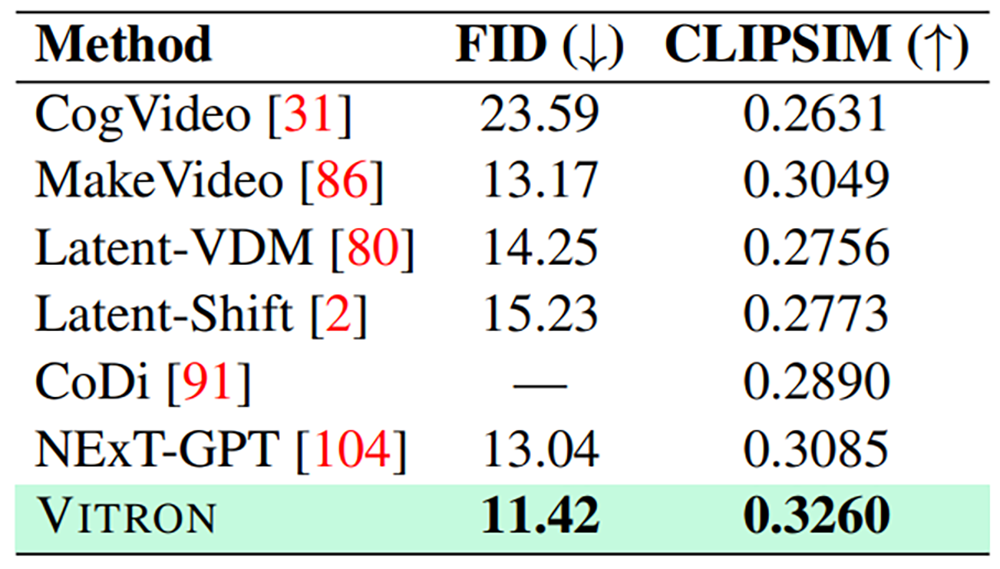
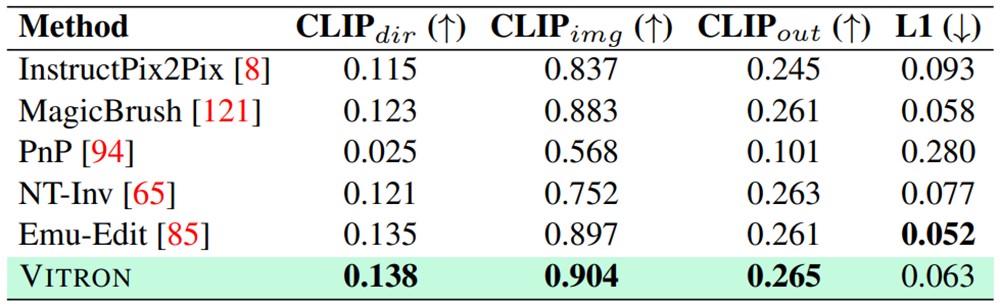
四个主要视觉任务类别中均表现优异
研究团队在22个常见基准数据集和12种图像/视频视觉任务上,对Vitron进行了全面的实验评估。结果表明,Vitron在四个主要视觉任务类别(包括分割、理解、内容生成和编辑)中均表现优异。此外,Vitron还展现了强大且灵活的用户交互能力。以下是一些具有代表性的定性比较结果:
以下代表性地展示了一些定性比较结果:
视觉分割:
▲图像指代图像分割结果
细粒度视觉理解:

▲图像目标指代理解结果
▲视频QA结果
视频生成:
▲文生图
▲文生视频

▲图生视频
视觉编辑:
▲图像编辑结果
具体更多详细实验内容和细节参见论文。
架构
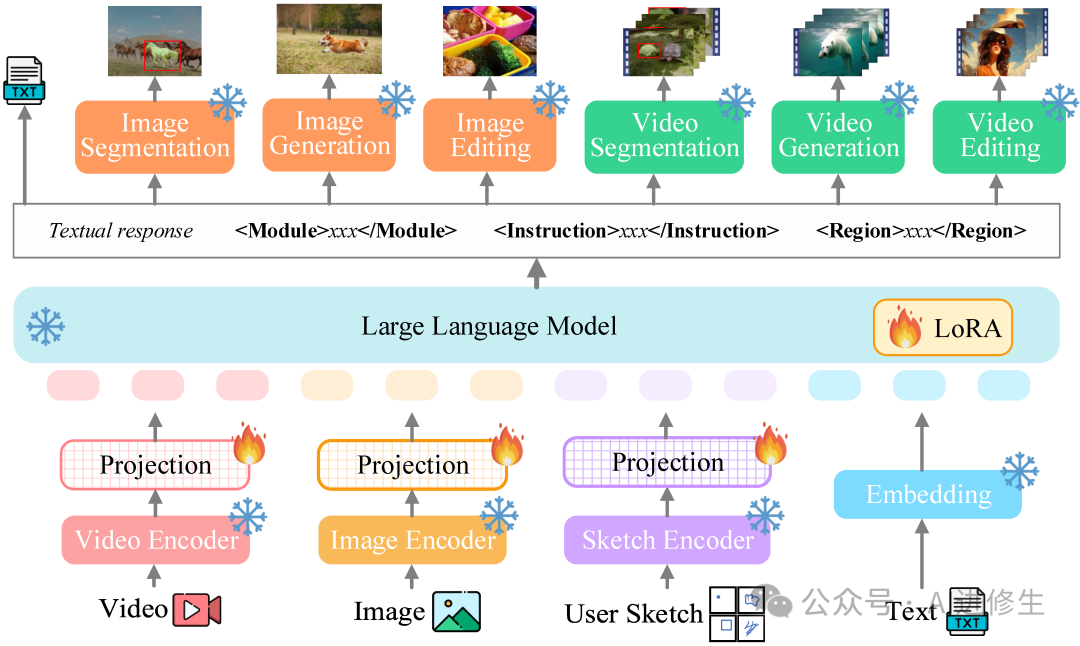
Vitron框架包括多个模块,每个模块都负责处理特定类型的视觉任务。让我们通过图表和表格详细了解Vitron的结构和功能。
图表解释
- 1. 前端模块:视觉语言编码
- • 图像编码器:将图像输入转换为特征向量。
- • 视频编码器:将视频输入转换为特征向量。
- • 区域草图编码器:将用户的草图输入转换为特征向量。
- 2. 中心区块:核心大模型(LLM)
- • Vitron采用了Vicuna(7B,版本1.5)作为核心语言模型,用于处理和生成文本指令,并协调各模块的工作。
- 3. 后端块:用户响应和模块调用
- • Vitron采用以文本为中心的调用策略,集成了各种现成的SoTA(State of the Art)模块,以支持从低级到高级的一系列视觉任务,涵盖视觉理解到视觉生成。
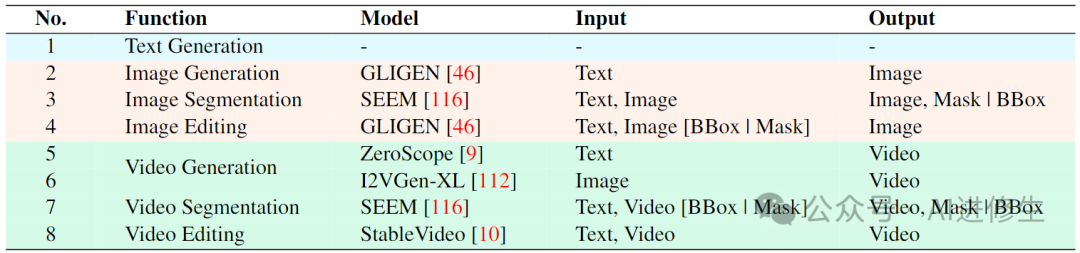
▲ 表 1:Vitron 中的后端模块摘要。
表1:Vitron中的后端模块摘要
表1展示了Vitron所集成的各个模块的功能、模型名称、输入类型和输出类型:
通俗解释
Vitron就像一个多才多艺的视觉助手,能够理解文本指令,并根据指令生成或编辑图像和视频。例如,你可以给它一段文字描述,它就能生成相应的图像或视频,或者你提供一张图片和编辑指令,它就能按要求编辑图片。
对比说明
- • 传统方法:需要分别使用不同的工具来处理文本生成、图像生成、图像分割、图像编辑、视频生成、视频分割和视频编辑等任务,操作复杂且效率低下。
- • Vitron:整合了多个先进模型和模块,一个平台就能完成所有这些任务,操作简便且高效。
通过这种综合性的架构设计,Vitron能够为用户提供全面且高效的视觉处理解决方案。
下面展示一下Vitron功能实例演示:
图像分割
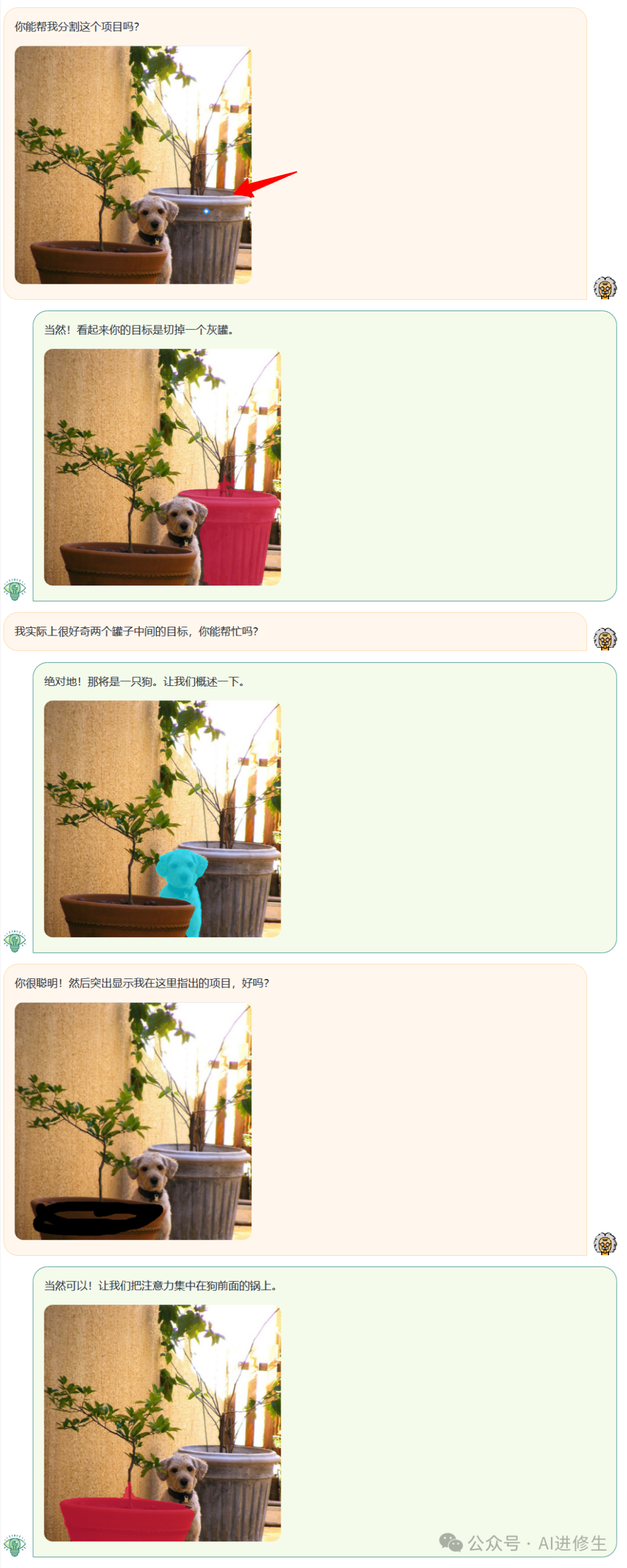
用户:你能帮我分割这个项目吗
tips:这里补充一下,可能有些读者不明白一些专业术语,就是说所谓的分割就是模型按照你的意思将你所需要的物体像素级区分开来,就比如下面图中用不同颜色框出来的物体区域,上面其实我们说过的有全景分割、实例分割、语义分割和指代分割,这里就是所谓的指代分割,而全景分割是实例分割加上语义分割(指代分割:用户可以通过简单的语言描述来与图像进行交互,这在图像编辑、标注和搜索等应用中非常有用。)。
视频跟踪
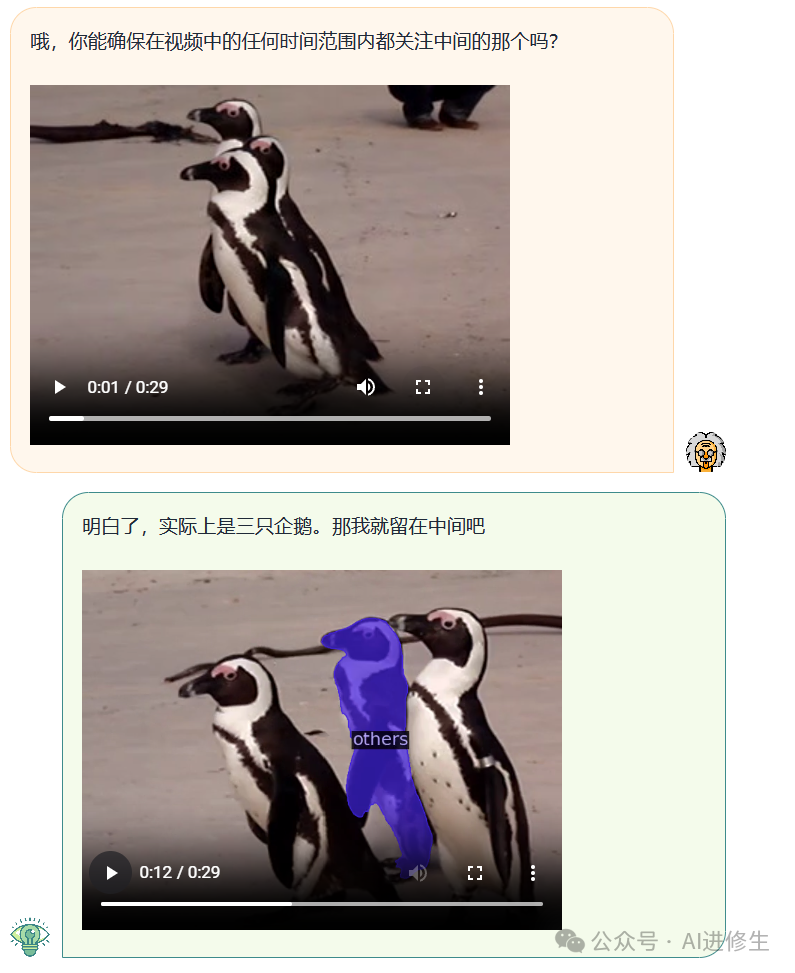
用户:你能为我勾勒出视频中那只灰母鸡的轮廓吗?

用户:哦,你能确保在视频中的任何时间范围内都关注中间的那个吗?
视频理解
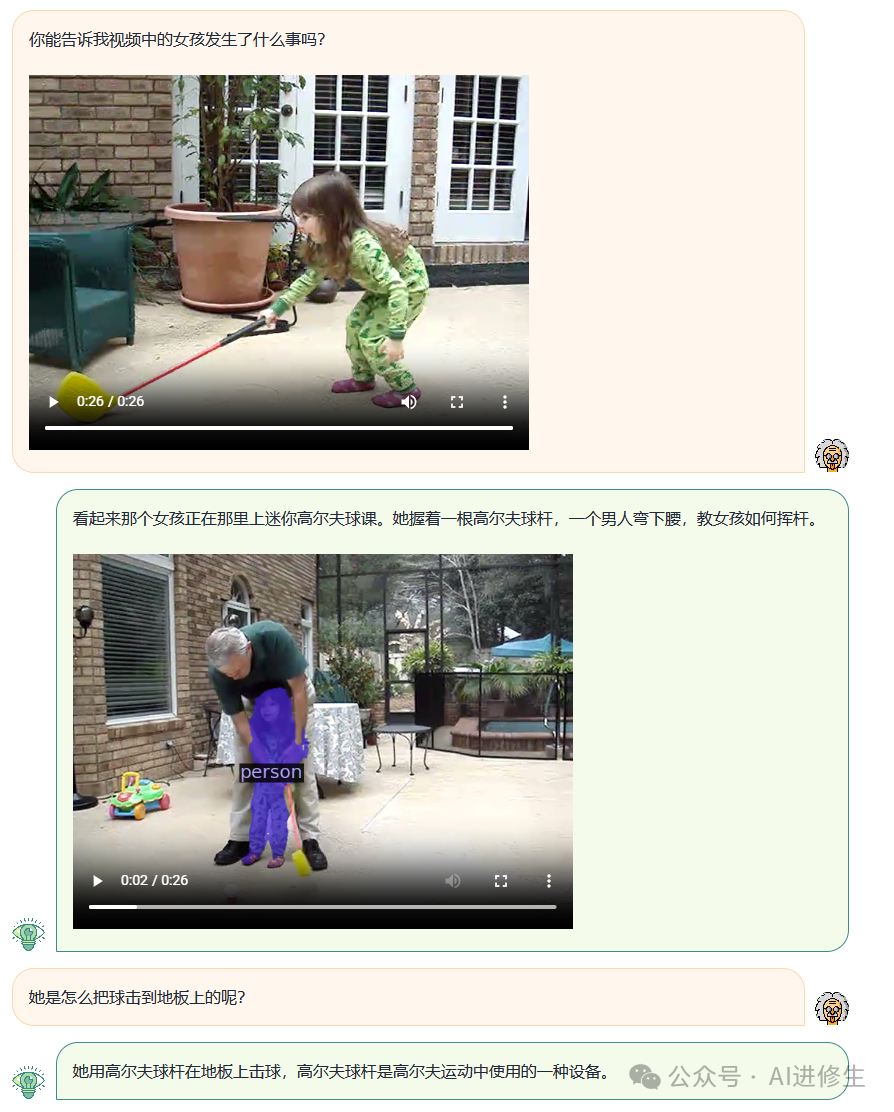
用户:你能告诉我视频中的女孩发生了什么事吗?
视觉生成
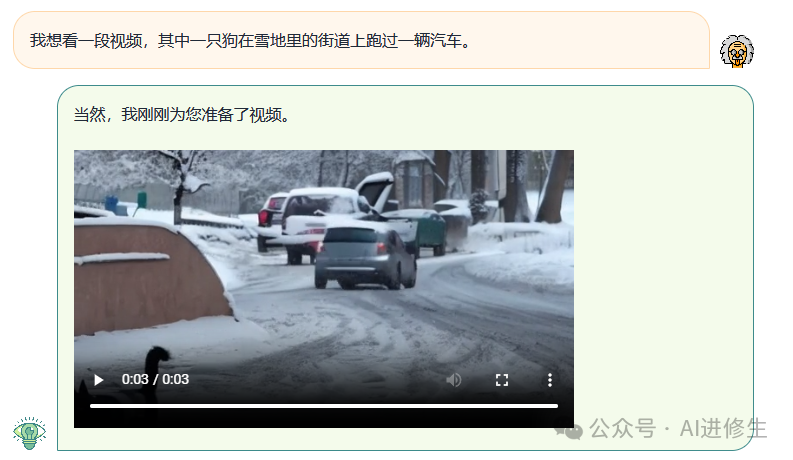
用户:我想看一段视频,其中一只狗在雪地里的街道上跑过一辆汽车
用户:嗯,很酷,但不完全是我想要的xxx...
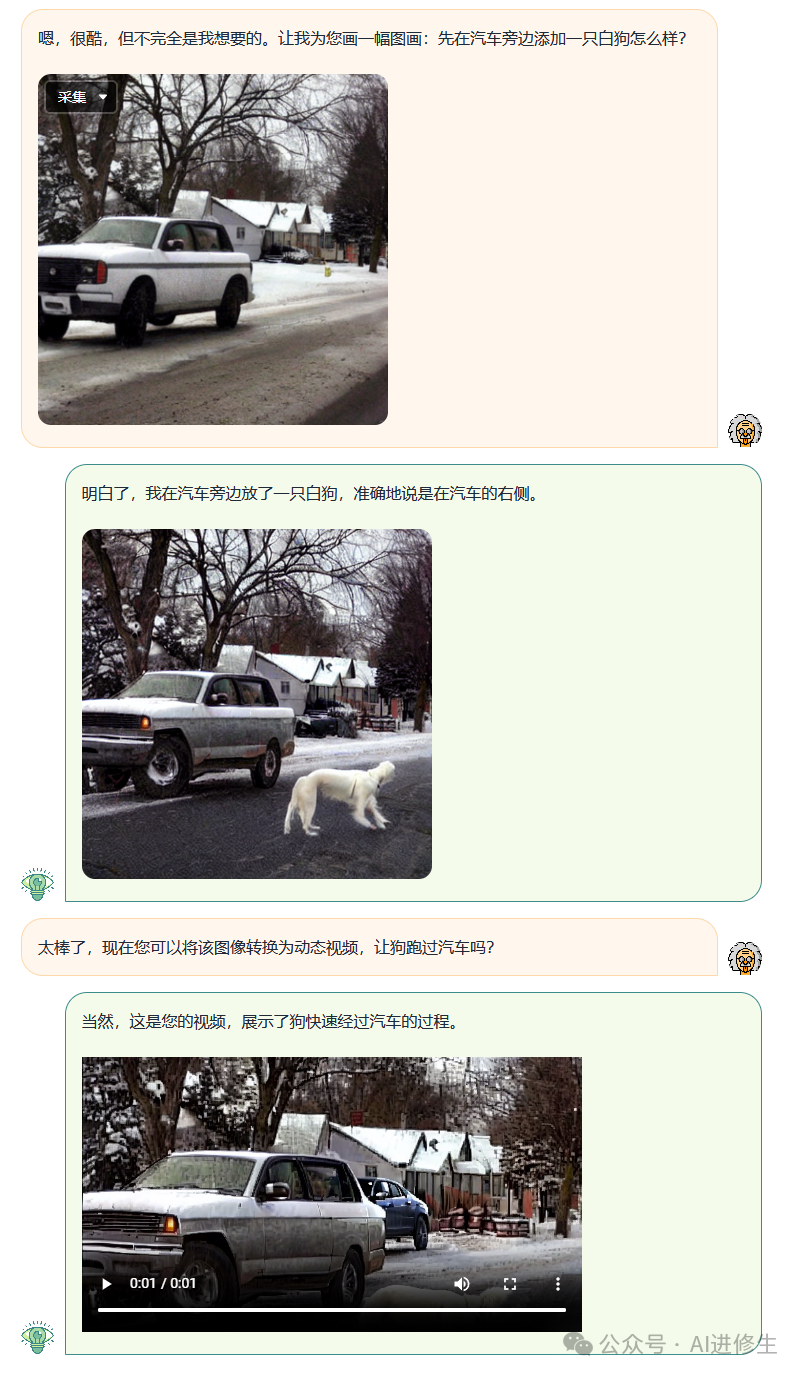
图像理解
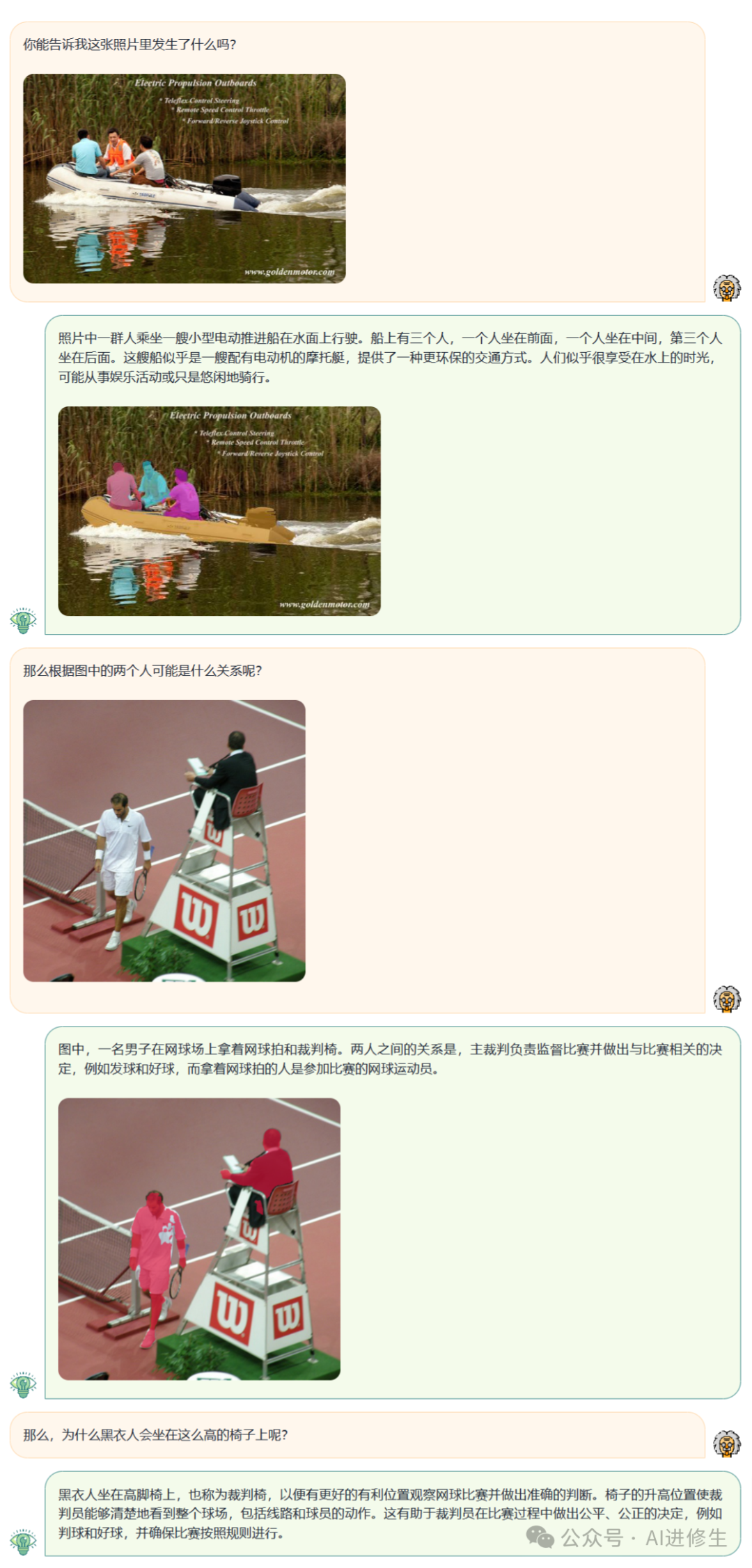
用户:你能告诉我这张图片里发生什么吗
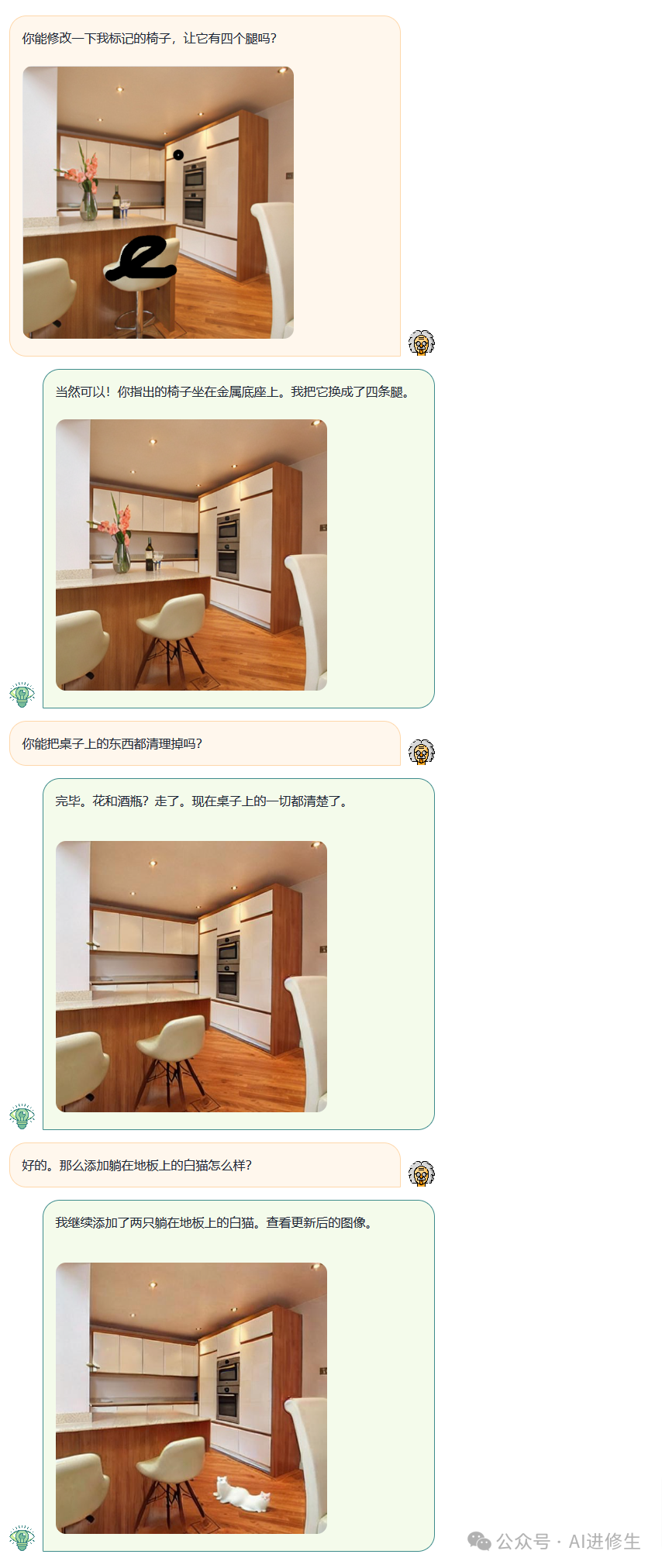
图像编辑
用户:什么吗你能修改一下我标记的椅子,让他有4个腿吗?
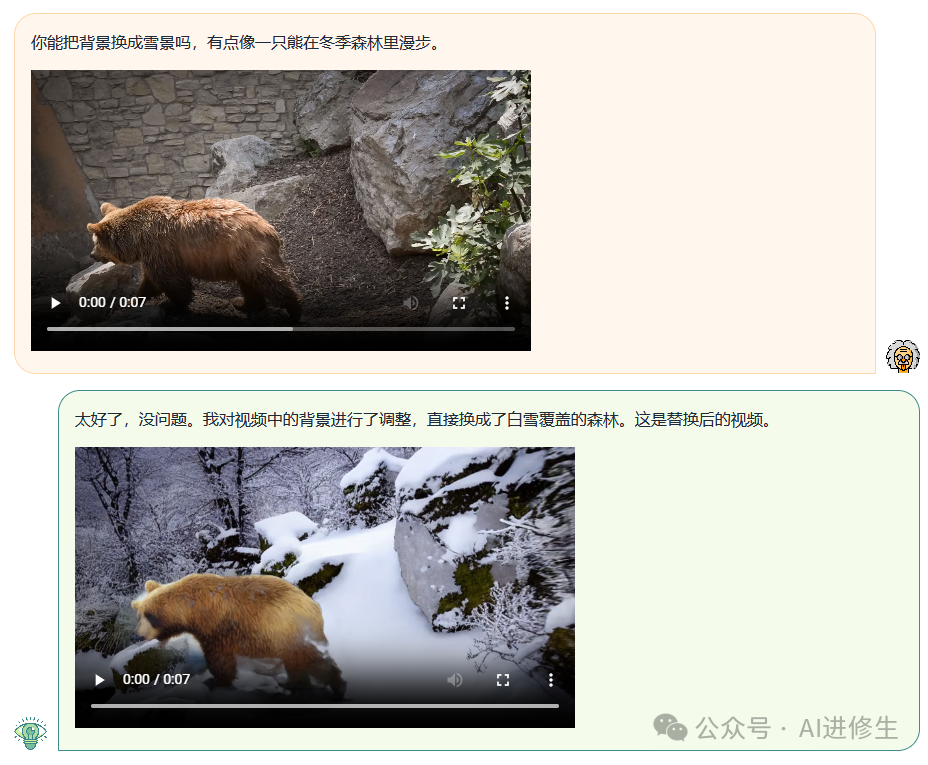
视频编辑
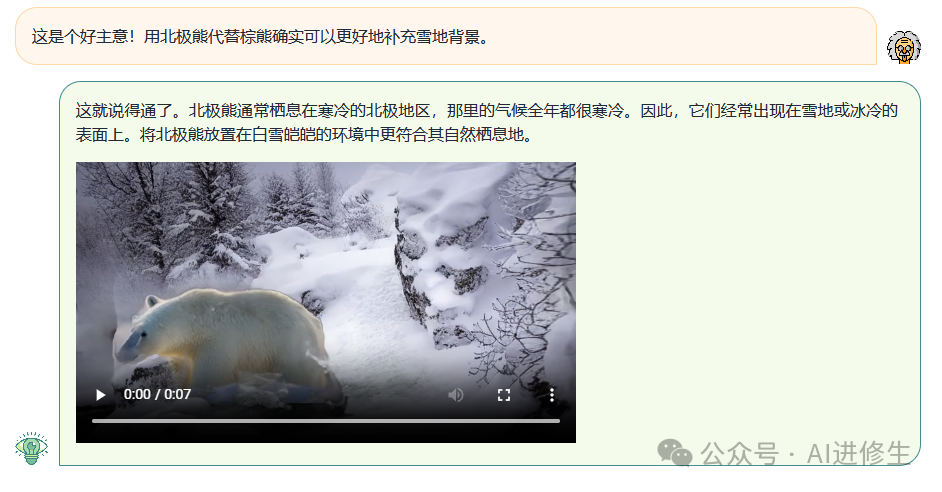
用户:你能把背景换成雪景吗有一只熊在冬天森林里漫步
下面提供官方的文档介绍、相关资源、部署教程等,进一步支撑你的行动,以提升本文的帮助力。
📰 新闻
- • [2024.04.04] 👀👀👀 我们的 Vitron 现在可用了!欢迎 关注 👀 此库以获取最新更新。
😮 亮点
现有的视觉语言模型(LLM)可能会遇到实例级理解浅薄、缺乏对图像和视频的统一支持以及各种视觉任务覆盖不足的问题。为了弥补这些不足,我们提出了 Vitron,一个通用的像素级视觉语言模型,旨在对静态图像和动态视频内容进行全面的理解(感知和推理)、生成、分割(定位和跟踪)、编辑(修复)。
🛠️ 要求和安装
- • Python >= 3.8
- • Pytorch == 2.1.0
- • CUDA 版本 >= 11.8
- • 安装所需软件包:
git clone https://github.com/SkyworkAI/Vitron
cd Vitron
conda create -n vitron python=3.10 -y
conda activate vitron
pip install --upgrade pip
pip install -e .
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
pip install decord opencv-python git+https://github.com/facebookresearch/pytorchvideo.git@28fe037d212663c6a24f373b94cc5d478c8c1a1d🔥🔥🔥 安装或运行失败?🔥🔥🔥
1. 运行 ffmpeg 时遇到 Unknown encoder 'x264' 错误:
conda uninstall ffmpeg
conda install -c conda-forge ffmpeg # `-c conda-forge` 参数不能省略- • 尝试重新安装 ffmpeg:
2. 安装 detectron2 失败,尝试以下命令:
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'或参考这个网站。
3. gradio 出错。由于 gradio>=4.0.0 版本有重大更新,请确保安装 requirements.txt 中相同版本的 gradio。
4. deepspeed 出错。如果在微调模型时出现以下错误:
FAILED: cpu_adam.so
/usr/bin/ld: cannot find -lcurand这个错误是由于安装 deepspeed 时软链接错误引起的。请尝试以下命令解决该错误:
cd ~/miniconda3/envs/vitron/lib
ls -al libcurand* # 检查链接
rm libcurand.so # 删除错误的链接
ln -s libcurand.so.10.3.5.119 libcurand.so # 建立新的链接再次检查:
python
from deepspeed.ops.op_builder import CPUAdamBuilder
ds_opt_adam = CPUAdamBuilder().load() # 如果加载成功,说明 deepspeed 已成功安装。👍 部署 Gradio 演示
- • 首先,您需要准备检查点,然后可以通过以下命令在本地运行演示:
python app.py附加
什么是粗粒度实例级理解、缺乏对图像和视频的统一支持?

论文
http://haofei.vip/downloads/papers/Skywork_Vitron_2024.pdf
Github
https://github.com/SkyworkAI/Vitron
参考链接: [1]https://www.youtube.com/watch?v=wiGMJzoQVu4&t=104s [2]https://mp.weixin.qq.com/s/A61WU7SyUrupYcC3LOp6kg
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号