解读 Optimizing Queries Using Materialized Views: A Practical, Scalable Solution
原创解读 Optimizing Queries Using Materialized Views: A Practical, Scalable Solution
原创
1. 概述
原文链接:Optimizing Queries Using Materialized Views:A Practical, Scalable Solution
该论文提出SPJG查询改写,高效实现基于selection, project, join, group-by算子匹配的视图改写方案,是当前很多计算引擎的物化视图查询改写的理论基础,例如:Calcite、Doris、StarRocks都基于优化器的SPJG结构改写进行扩展实现。
该论文主要贡献,提出:
- 一种高效的SPJG视图匹配算法,并给出详细的匹配步骤和需满足的条件说明;
- 一种新颖的索引结构,用于维护待匹配的视图,快速缩小搜索范围,仅对一小部分候选视图应用视图匹配。
备注:以下查询与逻辑计划子树一致
2. 问题定义
SQL Server 2000支持物化视图,由于视图可通过不同组合的索引实现,也称为索引视图。为确保视图支持增量更新,SQL Server要求物化视图必须包含唯一键(unique key),本文中聚合函数仅考虑sum 和count 算子。
--创建物化视图示例
create view v1 with schemabinding as
select p_partkey, p_name, p_retailprice,
count_big(*) as cnt,
sum(l_extendedprice*l_quantity) as gross_revenue
from dbo.lineitem, dbo.part
where p_partkey < 1000
and p_name like '%steel%'
and p_partkey = l_partkey
group by p_partkey, p_name, p_retailprice;
-- 在视图上创建唯一聚集索引,可支持视图增量更新
create unique clustered index v1_cidx on v1(p_partkey);
-- 创建辅助索引
create index v1_sidx on v1( gross_revenue, p_name);基于查询优化器实现计划树等价转换,是通过递归方式对逻辑计划子树遍历应用查询改写规则。视图匹配是对SPJG算子组成的子树应用改写规则。对于每个计划子树,希望能尽可能找到可等价改写的物化视图,最后通过CBO代价选择出最优的等价计划树。
单视图替代的视图匹配(View Matching with Single-View Substitutes):本文讨论范围,在计划子树应用规则时,仅考虑单个视图改写替代。由于优化器会对满足的SPJG计划子树递归应用改写规则,因此该限制并不会影响改写的灵活性。
3. 改写算法
介绍如何判断计划子树能否基于物化视图计算得到,如果为真,则说明如何通过视图构建对应的等价计划子树。本文先介绍相同基表下的SPJ结构的改写,后单独介绍视图具备额外基表、Aggregate聚合算子的改写场景。当视图基表少于计划子树查询基表,则无需考虑查询改写,此时视图表数据无法完全覆盖计划子树的数据,即仅考虑 T_q ⪯ T_v 场景,其中T_q 是计划子树的基表集合,T_v 是视图的基表集合。
本文仅考虑四种约束条件:(1).not-null: 字段非空非空约束;(2).primary key: 字段主键唯一性约束; (3). uniqueness con- straints: 显式/隐式的唯一性约束;(4).foreign key: 外键约束。假设SQL中的选择谓词都可转换为CNF(合取范式,conjunctive normal form),可由多个子句和逻辑与(AND)操作连接而成。
3.1. 相同基表SPJ改写
针对SPJ计划子树改写,视图需满足以下条件:
- The view contains all rows needed by the query expression:由于仅考虑单视图替代匹配,因此视图包含查询表达式所需的所有行
- All required rows can be selected from the view:应用谓词条件,可实现所有行从视图中提取
- All output expressions can be computed from the output of the view: 所有输出表达式都能从视图输出中计算得出
- All output rows occur with the correct duplication factor: 所有输出行的重复因子正确,任何重复行出现的次数必须完全相同,适用distinct计算。
3.1.1. 列等价类
列之间的等价关系在匹配验证中起着重要作用,设W=P_1\land P_2\land...\land P_n 为CNF格式的SPJ查询的选择谓词。通过合适的合取项整合,将谓词重写为W=PE \land PNE ,其中PE 包含列相等谓词T_i.C_p = T_j.C_q,PNE 包含其余列非相等谓词,T_i 和T_j 分为基表,C_p 和C_q 是列引用。
基于PE 中的列等价谓词也可以应用在PNE 中,在PNE 谓词和输出列中,部分列是可互换的。基于列等价类实现的列引用重新路由是视图改写的重要能力。
列等价类是一组相互之间值相等的列集合,通过PE 计算列等价类,能够清晰的获取列之间的等价关系。如果有三列A、B、C,在特定谓词条件下,A=B 且B=C,那么A、B、C属于同一个列等价类。初始化表的所有列,遍历PE所有选择谓词T_i.C_p = T_j.C_q ,分别查找包含T_i.C_p 和T_j.C_q 的列集合,如果属于不同集合,则合并这两个列集合。例如,发现C_p在集合\{C_p\}中,C_q在集合\{C_q\}中,两个集合不相等,则合并集合为\{C_p, C_q\} 。遍历完PE 后,得到的列集合是最终的列等价类,其中没有与其他列合并,仅包含单个列的集合是平凡列,在\{C_p, C_q\} 、\{C_a\} 集合中,\{C_a\} 是平凡列。
3.1.2. 条件一: 视图包含查询的所有行数据
假设查询和视图引用表为T_1,T_2,...,T_m ,其中查询的选择谓词设置为W_q ,视图的选择谓词为W_v , 判断视图是否包含查询的所有行,则只需证明select * from ~ T_1,T_2,…,T_m ~ where ~ W_q 的输出是select * from ~ T_1,T_2,…,T_m ~ where ~ W_v 的子集,即W_q ⇒ W_v ,其中 ⇒ 表示逻辑蕴含。
为判断W_q ⇒ W_v 为真,将选择谓词分别表示为CNF格式,W_q=P_{q,1}\land P_{q,2}\land...\land P_{q,m} 和W_v=P_{v,1}\land P_{v,2}\land...\land P_{v,n} ,一种简单包含算法是检查W_v 中每个合取项P_{v,i} 是否与W_q 中的某个合取项P_{q,j} 匹配。判断合取项是否匹配有多种方法,例如纯粹的语法匹配,判断查询与视图的SQL字符串是否一致,该方法限制严苛,例如A>B 和B<A 两个谓词条件是字符串语法不匹配的。为提升匹配的命中率,需要进行谓词解释并利用表达式间的等价关系。例如,交换律是一个重要的等价关系,可适用于比较、加法、乘法和OR运算。可根据谓词条件函数中可适用的等价关系来设计不同复杂程度的匹配算法。例如:简单谓词条件函数识别(A+B)=(B+A) ,复杂函数识别(A/2+B/5)*10 = A*5 + B*2 。
本论文设计的匹配算法利用了列等价类和列范围理论,将W_q 和W_v 分解为三部分,蕴含关系如下:
其中 PE_q 由查询中所有列等价谓词(column equality predicates)组成,PR_q 由范围谓词(range predicates)组成,PU_q 是W_q 其他所有合取项组成的剩余谓词(residual predicate)。列等价类谓词形式 (T_i.C_p = T_j.C_q) ,范围谓词形式 T_i.C_p ~op ~c ,其中op 是比较运算符,包括 <,\leq, =,\geq,> 。由于合取蕴含关系的特性,蕴含校验可拆分为三个独立的校验:
通过减少合取项会使验证条件更严格,(A⇒C)⇒(AB⇒C) 对任意谓词A、B、C 成立,通过减少合取项B 的验证条件(A⇒C)更严苛,因此可整理更严苛的三个校验如下:
在实践中,大部分列等价谓词来自等值连接(equijoins),而PE 的蕴含校验是十分关键的,可用于后续列等价类的重新路由。由于减少合取项,以上校验比原始校验更严格,会导致部分匹配校验遗漏。例如,由于忽略(PR_q ⇒ PE_v),导致(A=2)\land(B=2) 无法匹配 (A=B) ;由于忽略(PR_q ⇒ PU_v) ,导致(A=3)\land(B=2) 无法匹配(A+B=5) 。这涉及视图匹配效率与完整性之间的权衡,视图匹配完整性越高,需考虑的场景越多,匹配效率越低。
约束条件校验可融入以上校验中。关键在于,新增约束条件不会改变查询结果,因此将约束校验纳入W_q ⇒ W_v 考虑。
3.1.2.1:等值连接蕴含校验
三步骤:1.识别查询和视图的列等价类;2. 校验视图非平凡等价类为查询的子集;3.视图等值连接补偿
等值连接蕴含校验 要求视图中所有相等列在查询中必须存在,反之则无需成立,改写时查询额外的等值条件可补偿到视图中。首先分别计算查询和视图的列等价类,判断视图中非平凡的列等价类是否是查询的子集。基于传递性,相比谓词判断,判断列等价类是更简单的校验。例如 视图等价谓词为A=B ~ and ~ B=C ,查询等价谓词为A=C ~ and ~ C=B ,两者谓词条件不相等,但逻辑上是等价的A=B=C,对应的列等价类相等。
如果通过等值连接蕴含校验,则视图不包含任何与查询冲突的列相等约束,并且可计算出对视图补偿的列相等约束。当视图等价类E_1,E_2,...,En都映射到同一个查询等价类E时,需要在E_i 中的任意列与E_{i+1} 中的任意列之间创建列相等谓词,其中i=1,2,...n-1 。
3.1.2.2:范围蕴含校验
三步骤:1. 识别查询和视图等价类的上下界范围;2. 校验视图范围包含查询范围;3. 视图上下界范围补偿
当不涉及OR条件时,可使用一个简单的校验算法。分别为查询和视图中的每个等价类关联一个范围,该范围指定等价类中各列的上下界。最开始,列的两个边界都是未初始化的,默认为空。然后,逐个考虑范围谓词PR,找到包含被引用列的等价类,并根据谓词条件调整范围。例如
- (T_i.C_p \leq c),则设置最新上界为 min(当前上界,C) ;
- (T_i.C_p \geq c) ,则设置最新下界为max(当前下界,C) ;
- (T_i.C_p < c) ,则视为(T_i.C_p \leq c-\Delta) ,其中c-\Delta 表示T_i.C_p 定义域中小于c的最新上界;
- (T_i.C_p > c) , 则视为(T_i.C_p \geq c+\Delta) ,其中c+\Delta 表示T_i.C_p 定义域中大于c 的最新下界;
- (T_i.C_p = c),则视为(T_i.C_p \leq c) \land (T_i.C_p \geq c) 。
如果视图的范围约束条件比查询的更严格,则视图无法生成查询所需的全部数据行。为实现范围蕴含校验,考虑所有任一边界确定的视图等价类,在计划子树查询中找到与之匹配的等价类,然后检查查询等价类的范围是否包含在视图等价类的范围内,即校验查询等价类范围小于视图等价类范围。
通过以上过程,可以确定视图的范围补偿谓词,如果查询范围与视图范围一致,则无需补偿,如果查询范围小于视图范围,若视图无范围限制为(-\infty, +\infty),则需要对该视图等价类应用范围补偿。
- 上界不完全匹配:则针对视图补偿 (T.C≤ub) ,ub 是查询范围的上界;
- 下界不完全匹配:则针对视图补偿 (T.C \geq lb) ,其中 T.C 是查询对应的视图等价类,lb 是查询范围的下界。
除此之外,以上的范围校验可扩展到OR条件判断。
3.1.2.3:剩余蕴含校验
两步骤:1. 逐个匹配视图剩余谓词的合取项;2. 视图剩余谓词补偿
对于剩余谓词,仅能通过列等价关系校验,判断视图剩余谓词的每一个合取项是否与查询剩余谓词中的某个合取项匹配。遍历视图合取项并获取提取列,获取查询中列等价类,校验谓词条件是否一致匹配,若匹配失败则拒绝改写。针对两个合取项是否匹配,设计了一种浅匹配算法,除列等价类关系外,表达式必须完全相同。一个表达式可由一个文本字符串和一个列引用列表表示,为比较两个表达式,首先比较字符串,若字符串相同,则遍历比较列引用,如果所有列引用匹配,则表达式匹配。
通过以上过程,可确定视图的剩余补偿谓词,所有查询中额外的剩余谓词都必须应用在视图中。
3.1.2.4:校验示例
汇总以上三个蕴含校验步骤为:都基于视图检查并进行视图谓词补偿
- 计算查询和视图的类等价类
- 校验视图的每个非平凡等价类是否为查询等类的子集,如果不是,则拒绝该视图
- 计算查询和视图的上下界区间范围
- 校验视图每个范围是否包含对应的查询范围,如果不是,则拒绝该视图
- 检查视图剩余谓词中的每个合取项是否与查询剩余谓词中的某个合取项匹配。如果不匹配,则拒绝该视图。
View:视图定义
Create view V2 with schemabinding as
Select l_orderkey, o_custkey, l_partkey,
l_shipdate, o_orderdate,
l_quantity*l_extendedprice as gross_revenue
From dbo.lineitem, dbo.orders, dbo.part
Where l_orderkey = o_orderkey
And l_partkey = p_partkey
And p_partkey >= 150
And o_custkey >= 50 and o_custkey <= 500
And p_name like ‘%abc%’
Query:查询
Select l_orderkey, o_custkey, l_partkey,
l_quantity*l_extendedprice
From lineitem, orders, part
Where l_orderkey = o_orderkey
And l_partkey = p_partkey
And l_partkey >= 150 and l_partkey <= 160
And o_custkey = 123
And o_orderdate = l_shipdate
And p_name like ‘%abc%’
And l_quantity*l_extendedprice > 100步骤1:计算列等价类
- 视图列等价类:{l_orderkey, o_orderkey},{l_partkey, p_partkey},{o_orderdate},{l_shipdate}
- 查询列等价类:{l_orderkey, o_orderkey},{l_partkey, p_partkey},{o_orderdate, l_shipdate}
步骤2:校验视图列等价类包含关系
判断视图所有非平凡列等价类是查询列等价类的子集,其中{o_orderdate} 和 {l_shipdate} 都映射到相同的查询等价类,则视图的等值连接补偿谓词:(o_orderdate = l_shipdate)。
步骤3:计算范围
- 视图范围:{l_partkey, p_partkey} ∈ (150, +∞), {o_custkey} ∈ (50, 500)
- 查询范围:{l_partkey, p_partkey} ∈ (150, 160), {o_custkey} ∈ (123, 123)
步骤4:检查视图范围包含关系
视图范围包含查询范围{l_partkey, p_partkey} ∈ (150, 160),上界不匹配,则视图的范围补偿谓词 ({l_partkey, p_partkey} <= 160)。 视图范围包含查询范围 {o_custkey} ∈ (123, 123),上下界不匹配,则视图的范围补偿谓词 (o_custkey >= 123) and (o_custkey <= 123),并简化为 (o_custkey = 123)。
步骤5:检查视图剩余谓词匹配
- 视图剩余谓词:p_name like ‘% abc%’
- 查询剩余谓词:p_name like ‘% abc%’, l_quantity * l_extendedprice > 100
视图仅有一个剩余谓词 p_name like ‘% abc%’,在查询中完全匹配,并视图的剩余补偿谓词(l_quantity * l_extendedprice > 100)。
3.1.3. 条件二:补偿谓词在视图中可正确计算
通过条件一校验,可得到如下三种视图补偿谓词:
- 等值连接补偿谓词:如示例中 (o_orderdate = l_shipdate)
- 范围补偿谓词:如示例中 ({l_partkey, p_partkey} <= 160) 和 (o_custkey = 123)
- 剩余补偿谓词:如示例中 (l_quantity * l_extendedprice > 100)
所有补偿谓词都必须在视图上可应用,保证视图改写执行的结果与原查询结果一致。基于列等价关系,每个列引用指向对应的列等价类,而非该列本身,因此可重定向到其列等价类内的任意列。
上述第 1 类和第 2 类补偿谓词仅包含简单的列引用。只需检查被引用等价类中的列是否至少包含一个是视图的输出列,然后将引用指向该视图列。第 3 类补偿谓词可能涉及更复杂的表达式,在这种情况下,即便表达式中引用的某些列无法映射到视图的输出列,该表达式仍有可能被求值。“l_quantity * l_extendedprice” 作为视图的一个输出列,即便没有 “l_quantity” 和 “l_extendedprice” 这两列,依然能够对谓词 “(l_quantity * l_extendedprice > 100)” 进行求值。 但该设计忽略了这种可能性,要求补偿谓词中引用的所有列都必须映射到视图的(简单)输出列。
综上,可通过以下步骤校验条件二,能否能从视图中正确选出查询所需的所有行。
- 等值连接补偿谓词:基于视图列等价类,尝试将每个列引用映射到一个视图输出列;无法映射则拒绝该视图;
- 范围补偿谓词:基于视图列等价类,尝试将每个列引用映射到一个视图输出列;无法映射则拒绝该视图;
- 剩余补偿谓词:提取剩余谓词中所有引用列,尝试将每个列引用映射到一个视图输出列;无法映射则拒绝该视图。
3.1.4. 条件三:输出表达式在视图中可正确执行
该判断与条件二判断补偿谓词能否在视图正确计算类似。
- 常量表达式:只需将该常量复制到输出结果中;
- 简单列引用:基于视图列等价类,检查能否映射到视图的某个输出列上;
- 其他表达式:校验表达式能否从视图输出列计算得到。首先判断视图输出中是否包含完全相同的表达式,如果存在,则直接替换为视图列引用;如果不存在,则检查引用列是否能完全映射到视图的输出列。
3.1.5. 条件四:输出行的重复因子正确
当查询和视图引用的表完全相同时,如果视图通过了前面的条件判断,该条件自然就满足。更值得关注的情况是视图引用了额外的表,下一节将具体讨论这种情况。
综上,整体基于列等价类理论,视图与查询源表一致时,SPJ需要满足四个条件:
条件 | 解释 |
|---|---|
1.行覆盖性 | CNF谓词拆分+蕴含校验:等值连接蕴含校验 + 范围蕴含校验 + 剩余蕴含校验 |
2.补偿谓词可用性 | 补偿谓词校验:等值连接补偿谓词、范围补偿谓词、剩余补偿谓词 |
3.输出表达式可计算性 | 输出表达式:常量表达式、简单列引用、其他表达式 |
4.行重复因子正确性 | 约束条件:非空约束、主键唯一键约束、显式/隐式的唯一性约束、外键约束 |
3.2. 视图额外基表改写
针对SPJ查询引用表T_1,T_2,...T_n ,而视图额外引用一张表S,即T_1,T_2,...T_n, S。为判断视图改写,基于保持基数连接(cardinality preserving join)判断,表T中每一行都恰好与表S中一行连接,即与S 表JOIN前后的输出结果行数不变。若保持基数连接成立,则可将S 简单视为T 的列扩展。 示例,T 的非空外键与S 的唯一键进行等值连接,可满足保持基数连接的特性。外键约束能够保证:于表T中的每一行t,在表S中至少存在一行s 等值。
考虑视图多个额外表的场景,视图引用m 个额外表 T_1,T_2,...T_n, T_{n+1},T_{n+2},...,T_{n+m} ,为判断T_{n+1},T_{n+2},...,T_{n+m} 能否通过一系列保持基数连接与表T_1,T_2,...T_n 相连,构建一个称为外键连接图(foreign-key join graph)的有向图。有向图的各顶点分别代表基表T_1,T_2,...T_n, T_{n+1},T_{n+2},...,T_{n+m} ;当视图直接或间接指定 T_i 与T_j 之间存在连接,且连接满足所有五个条件(等值连接、涉及所有列、列值非空、外键约束、唯一键约束)时,则表T_i 与T_j 之间存在边。
为保证等值连接可正确传递,在有向图中添加边时必须考虑类等价类。例如从T_i 向T_j 添加一条边,存在外键约束,从表T_i 的列F_1,F_2,...,F_n 指向表T_j 的列C_1,C_2,...,C_n ,对于每一列C_i 找到对应的列等价类,并判断相应的外键列F_i 是否属于同一个等价类,如果每个列都通过验证,则添加边T_i → T_j ,其中T_i 外键,T_j 主键。
有向图构建完成后,尝试通过删除操作移除额外表的顶点T_{n+1},T_{n+2},...,T_{n+m} ,迭代删除没有出边且仅有一条入边的顶点,如果可以成功移除额外表顶点T_{n+1},T_{n+2},...,T_{n+m} ,则可通过保持基数连接消除额外表。
除此之外,视图还需满足上一节的验证条件。为满足初始假定查询与视图的表引用相同,从概念上将额外表T_{n+1},T_{n+2},...,T_{n+m} 追加到查询中,并使用视图消除额外表时相同的外键连接方式,将额外表与查询原始表进行连接。由于保存基数连接的特性,因此新增连接不会改变查询结果。
在实际操作中,仅通过更新查询的列等价类模拟添加额外表,首先为额外表T_{n+1},T_{n+2},...,T_{n+m} 的每个列添加对应的平凡列等价类。其次,扫描上述消除过程中所有被删除外键边的连接条件,识别列等价类,将额外表与查询的列等价类合并。理论上,更新后的查询引用表与视图相同,可进行上一节的条件验证。
视图额外表示例:
--视图定义
Create view v3 with schemabinding as
Select c_custkey, c_name, l_orderkey,
l_partkey, l_quantity
From dbo.lineitem, dbo.orders, dbo.customer
Where l_orderkey = o_orderkey
And o_custkey = c_custkey
And o_orderkey >= 500
--查询
Select l_orderkey, l_partkey, l_quantity
From lineitem
Where l_orderkey between 1000 and 1500
And l_shipdate = l_commitdate可得到以下列等价类和范围谓词:
- 视图:等价类 {l_orderkey, o_orderkey}, {o_custkey, c_custkey},范围 {l_orderkey, o_orderkey}∈(500, +∞)
- 查询:等价类 {l_shipdate, l_commitdate},范围 {l_orderkey}∈(1000, 1500)
该视图的外键连接图 有三个顶点(lineitem、orders、customer)组成,其中边为:lineitem → orders,orders → customer。由于customer 没有出边且只有一条入边,该顶点可移除。继续迭代,由于orders没有出边,也可移除。满足额外表可被移除的条件。
然后,从概念上将orders、customer 表添加到查询中,lineitem → orders 边的连接谓词为(l_orderkey = o_orderkey),因此可生成等价类{l_orderkey, o_orderkey},orders → customer 边的连接谓词为(o_custkey = c_custkey),可生成等价类{o_custkey, c_custkey} ,更新查询等价类如下:
- 查询:等价类 {l_shipdate, l_commitdate},{l_orderkey, o_orderkey},{o_custkey, c_custkey},范围 { l_orderkey, o_orderkey}∈(1000, 1500)
通过验证蕴含条件,视图添加范围补偿谓词(l_orderkey >= 1000 and l_orderkey <= 1500)。
基于保持基数连接,以上校验确保能够直接或间接地将视图中每个额外表与查询某个输入表 T进行 “预连接”,且得到更宽的表包含与T完全相同的行。这是安全的,但也有一定的局限性,在实际中,仅要求保证查询中实际使用的行满足这一点即可,而无需所有行。 示例,假设视图由表T 和表S 通过T.F=S.C 连接而成,其中F 为C 外键,C 为S 主键。考虑查询的谓词为T.F > 50,如果 T.F 没有声明为非空的,则会判断拒绝该视图。但由于查询中已限定T.F>50 ,因此T.F 为空的行都会忽略,在该场景下判断视图必须声明T.F 必须非空具有局限性。
3.3. 聚合算子改写
在SQL Server物化视图中,所有分组表达式必须包含在输出列表中,以确保每行都有唯一的键。此外,输出列表必须包含一个count_big(*)列,便于视图增量更新。
将聚合查询当做SPJ查询+分组操作组成,视图改写需满足以下条件:
- 视图SPJ部分与查询SPJ部分的输出数据行,具有正确的重复因子;
- 补偿谓词所需的所有列在视图中都可计算;
- 视图不包含聚合操作,或者聚合程度低于查询,即查询的聚合分组可通过视图输出的分组进一步聚合计算;
- 进一步聚合分组的所有列在视图中都可计算;
- 输出表达式的所有列在视图中都可计算。
前两个条件与SPJ条件相同。查询的分组列表是视图分组列表的子集,则第三个条件满足。如果查询分组列表与视图分组列表相同,则无需进一步聚合,第四个条件满足。若查询分组为视图分组的真子集,则需在视图上添加分组补偿谓词。第四个条件与SPJ判断类似,但需注意聚合表达式处理,如果输出包含SUM(E) ,其中E是某个标量表达式,要求视图包含一个完全匹配的输出列;AVG(E)会转为SUM(E)/count(*)计算。
聚合算子示例:
--视图定义
Create view v4 with schemabinding as
Select o_custkey, count_big(*) as cnt
sum(l_quantity*l_extendedprice)as revenue
From dbo.lineitem, dbo.orders
Where l_orderkey = o_orderkey
Group by o_custkey
--查询
Select c_nationkey,
sum(l_quantity*l_extendedprice)
From lineitem, orders, customer
Where l_orderkey = o_orderkey
And o_custkey = c_custkey
Group by c_nationkey直观的看,该视图并不满足上述列出的任何条件,但SQL Server优化器支持预聚合,考虑eager/lazy聚合策略,可生成如下查询表达式:
Select c_nationkey, sum(rev)
From customer,
(select o_custkey,
sum(l_quantity*l_extendedprice) as rev
From lineitem, orders
Where l_orderkey = o_orderkey
Group by o_custkey) as iq
Where c_custkey = o_custkey
Group by c_nationkey将关联的聚合下推到lineitem和orders连接,其中iq子查询可满足SPJG条件,基于视图改写可得到:
Select c_nationkey, sum(revenue)
From customer, v4
Where c_custkey = o_custkey
Group by c_nationkey4. 视图筛选
如果视图数量过大,每次调用视图匹配规则时,对所有视图应用以上验证条件的速度会很慢。提出一种内存索引: 过滤树(filter tree),加速视图筛选,高效剪枝无效视图。
过滤树是一种多路搜索树,其所有叶子节点都处于同一层级,一个节点包含一组(键,指针),一个键由一组值构成,而非单个值。内部节点中的指针指向下一层的节点,而叶节点中的指针指向视图描述列表,过滤树基于层级结构将视图集合不断细分。
在过滤树中进行搜索可能会遍历多条路径,当搜索到达一个节点时,会沿着该节点的某些外向指针继续进行。是否沿某个指针继续搜索,取决于对与该指针关联的键应用搜索条件的结果。搜索条件为是否属于同一类型,即如果一个键是给定搜索键的子集(超集)或与之相等,则该键符合条件,其中搜索键也是一个集合。针对大量搜索键,基于线性扫描并判断每个键会导致效率较低,因此将键组织成格状结构,能够快速找到对应子集(超集),该结构也称为lattice index(格索引)。
4.1. 格索引(lattice index)
元素+偏序关系可构成Lattice,格索引将键组织在一个Lattice结构中,并包含两类指针集合:超集指针和子集指针。节点V的超集指针指向V的最小超集,节点V的子集指针指向V的最大子集。没有子集的节点称为root根节点,没有超集的节点称为Tops顶节点。
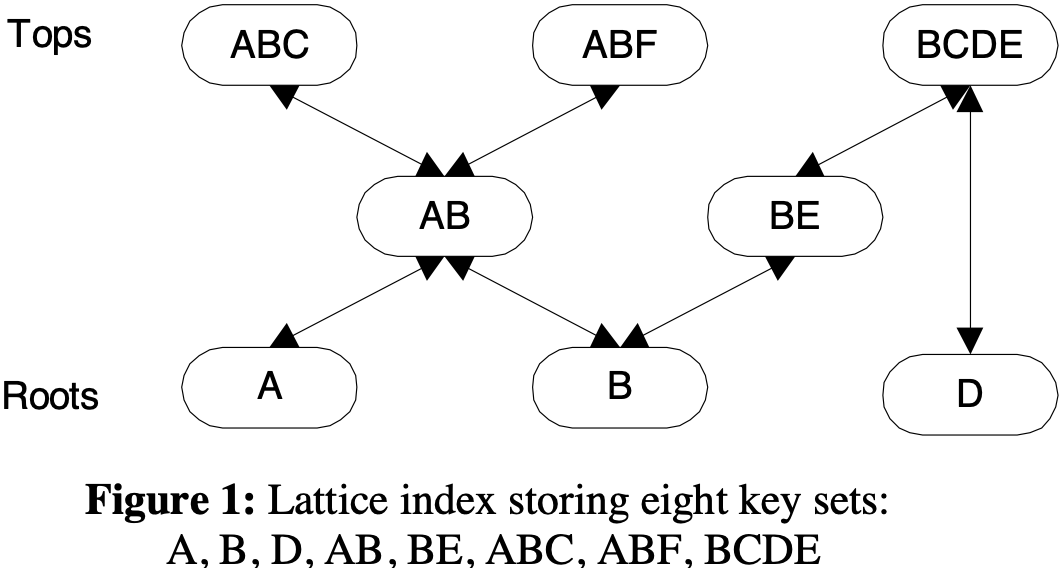
格索引搜索是递归过程,假设查询AB节点的超集,从顶节点出发判断是否为AB的超集,若满足则递归沿着子集指针查找判断是否为AB的超集,如果不满足则停止该路搜索,最终搜索返回ABC、ABF、AB。
4.2. 分区条件
过滤树以递归方式将视图集细分为越来越小的不重叠分区,每一层会应用不同分区条件,本节介绍视图搜索过滤条件,也可理解为不同层的分区条件。
4.2.1. 源表条件
忽略源表少于查询源表的视图,要求视图源表集合是查询源表集合的超集。以视图源表集合作为键构建格索引,以查询源表集合作为搜索键,查找搜索键的超集。
4.2.2. Hub条件
基于3.2节的视图额外表消除,将剩余集合称为视图核心(hub),并忽略非查询源表子集的视图。以视图核心(hub)作为键构建格索引,以查询源表集合作为搜索键,查找搜索键的子集。
4.2.3. 输出列条件
假设查询和视图的输出列表都是简单的列引用,要求查询的所有输出表达式都能从视图计算得出。由于列等价类关系,该要求并不意味查询的输出列必须与视图的输出列完全匹配。
假设查询输出A、B、C三列,基于列相等谓词,得到列等价类{A, D, E}、{B, F}、{C}。视图的列等价类 {A, D, G}、{E}、{B} 和 {C, H},第一个查询列A,在视图中存在A, D, E 任意一列即可满足;第二个查询列B,在视图中存在B, F任意一列即可满足;第三个查询列C,在视图中存在C即可满足。因此查询输出列可基于视图输出列获取。
输出列条件:视图的列等价类至少包含每个查询输出列等价类的任意一列。以视图的列等价类为键构建格索引,给定查询,从顶节点递归搜索,如果一个节点的满足条件,则顺序子集指针搜索,若不满足,则退出搜索。
4.2.4. 分组列条件
要求查询分组列是视图分组列的子集,视图的分组列等价类至少包含每个查询分组列等价类的任意一列。以视图分组列为键构建格索引,以查询分组列为搜索键,查询搜索键的超集。
4.2.5. 范围约束列条件
要求视图范围约束列是查询约束列的子集,查询的约束列等价类至少包含每个视图约束列等价类的任意一列;而视图约束范围是查询约束范围的超集。以视图约束列为键构建格索引,以查询约束列为搜索键,查找搜索键的子集。
4.2.6. 剩余谓词条件
要求视图剩余谓词列是查询剩余谓词列的子集,以视图剩余谓词列为键构建格索引,以查询剩余谓词列为搜索键,查找搜索键的子集。
4.2.4. 输出表达式条件
要求查询输出表达式是视图输出表达式的子集,以视图输出表达式为键构建格索引,以查询输出表达式为搜索键,查询搜索键的超集。
4.2.4. 分组表达式条件
要求查询分组表达式是视图分组表达式的子集,以视图分组表达式为键构建格索引,以查询分组表达式为搜索键,查询搜索键的超集。
上述每个条件都可以作为格索引细分视图集合的基础。这些条件相互独立,可以按任意顺序组合以创建一个过滤树。整理如下,可以看出规律:
- 都以视图元素作为键构建格索引(Lattice Index);
- 都以查询元素作为搜索键;
- 搜索指针与蕴含条件相关,如果查询元素⇒视图元素,则使用超集指针,若视图元素 ⇒查询元素,则使用子集指针。
分区条件 | 格索引构建 | 搜索键 | 搜索指针 |
|---|---|---|---|
源表条件 | 视图源表集合为键 | 查询源表 | 超集 |
Hub条件 | 视图核心(Hub)为键 | 查询源表 | 子集 |
输出列条件 | 视图输出列等价类为键 | 查询输出列等价类 | 超集 |
分组列条件 | 视图分组列等价类为键 | 查询分组列等价类 | 超集 |
范围约束条件 | 视图约束列等价类为键 | 查询约束列等价类 | 子集 |
剩余谓词条件 | 视图剩余谓词列等价类为键 | 查询剩余谓词列等价类 | 子集 |
输出表达式条件 | 视图输出表达式为键 | 查询输出表达式 | 超集 |
分组表达式条件 | 视图分组表达式为键 | 查询分组表达式 | 超集 |
5. 局限性
可考虑以下方向扩展:
- UNION联合:当单个视图无法提供查询所需的全部行时,可从多个视图收集行数据。
- 基表回连(base table backjoins):当视图包含查询所需的所有表和行,但缺少部分列时可适用。将这个视图与基表进行连接操作,从查询基表中把缺失的列补充到结果中。
附录
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
