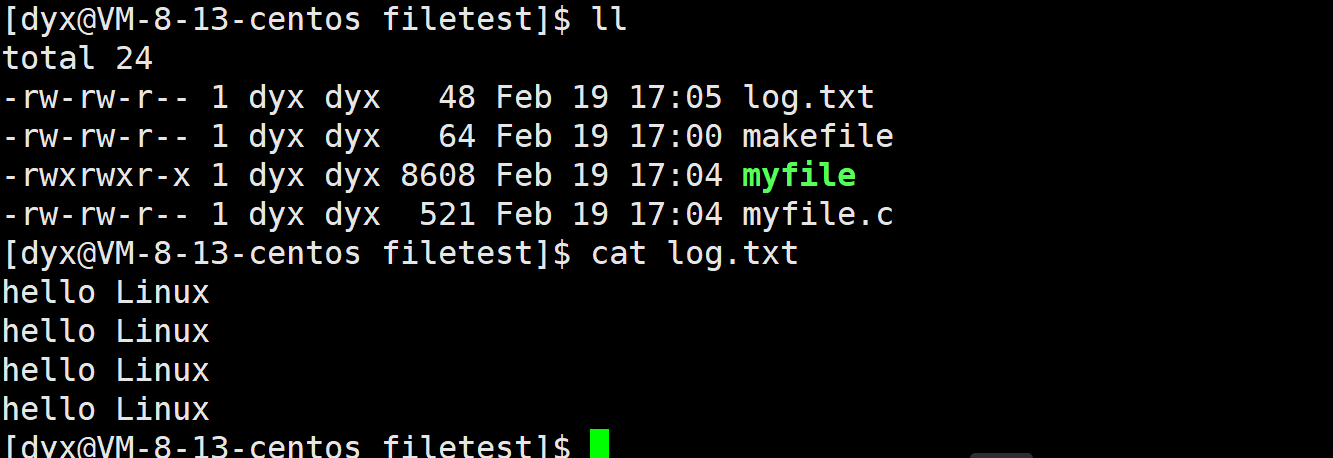
【Linux】重定向与缓冲区


01.文件属性获取
#include<stdio.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
const char * filename="log.txt";
int main()
{
int fd= open(filename,O_CREAT|O_WRONLY|O_TRUNC,0666);
if(fd<0)
{
perror("open");
return 1;
}
const char*message="hello Linux\n";
write(fd,message,strlen(message));
write(fd,message,strlen(message));
write(fd,message,strlen(message));
write(fd,message,strlen(message));
close(fd);
return 0;
}我们创建一个新文件并写入四行句子
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int stat(const char *path, struct stat *buf);
int fstat(int fd, struct stat *buf);
int lstat(const char *path, struct stat *buf);这三个函数 stat、fstat 和 lstat 都是 C 语言中用于获取文件的状态信息(如文件大小、权限、修改时间等)的系统调用。它们用于查询文件或目录的元数据,返回一个 struct stat 结构,结构中包含了该文件的详细信息。
这三个函数的区别在于它们如何访问文件,特别是在涉及符号链接(symlinks)时的行为。
stat 函数用于获取指定路径(path)所指向文件或目录的状态信息。它通常用于普通文件、目录或其他类型的文件。
-
path:指向一个字符串,表示文件或目录的路径。 -
buf:指向一个struct stat结构体,该结构体将被填充上文件的状态信息。 - 成功:返回
0,并将文件的状态信息存储到buf中。 - 失败:返回
-1,并设置errno来指示错误。
用法:
#include<stdio.h>
#include<sys/stat.h>
int main()
{
struct stat file_info;
if(stat("log.txt",&file_info)==-1)
{
perror("stat");
return 1;
}
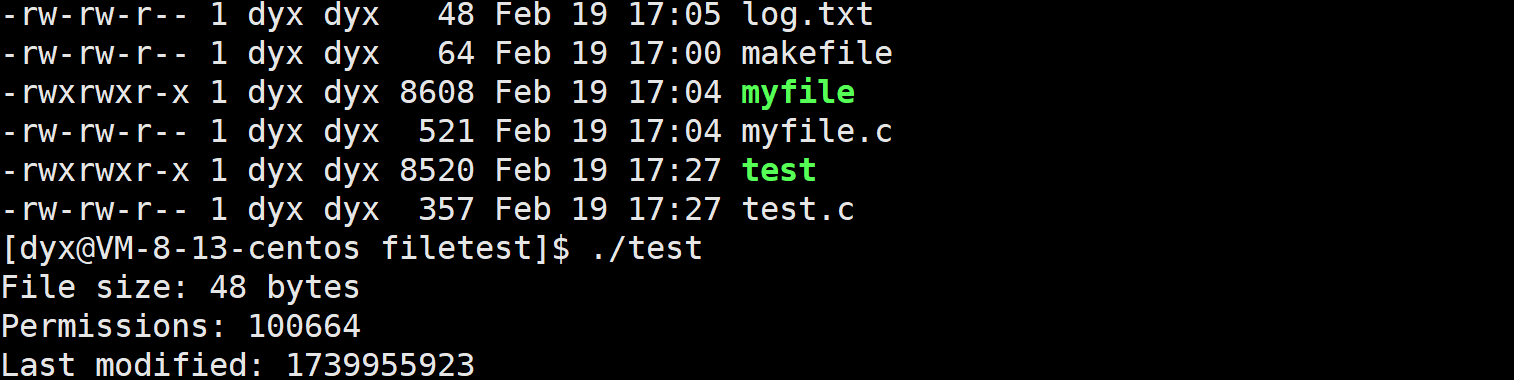
printf("File size: %ld bytes\n", file_info.st_size);
printf("Permissions: %o\n", file_info.st_mode);
printf("Last modified: %ld\n", file_info.st_mtime);
return 0;
}stat 函数用于获取文件 log.txt 的状态信息,并打印文件的大小、权限和最后修改时间。
fstat 与 stat 很相似,不同之处在于它是通过文件描述符来获取文件的状态,而不是通过路径。它适用于文件已经被打开并且拥有文件描述符的情况。
lstat 函数与 stat 函数非常相似,但它用于获取符号链接本身的状态,而不是符号链接所指向的目标文件的状态。对于普通文件或目录,lstat 的行为与 stat 相同。
用法:
#include <stdio.h>
#include <sys/stat.h>
int main() {
struct stat file_info;
if (lstat("symlink.txt", &file_info) == -1) {
perror("lstat");
return 1;
}
if (S_ISLNK(file_info.st_mode)) {
printf("It's a symbolic link!\n");
} else {
printf("It's not a symbolic link.\n");
}
return 0;
}在这个例子中,lstat 用于获取符号链接 symlink.txt 的状态信息。与 stat 不同,lstat 会返回符号链接本身的元数据,而不是符号链接指向的文件的元数据。如果目标文件是符号链接,stat 会返回链接目标的状态,而 lstat 返回的是符号链接本身的信息。
stat、fstat 和 lstat 的主要区别
函数 | 访问方式 | 适用场景 | 重要差异 |
|---|---|---|---|
stat | 路径(文件名) | 获取指定路径文件的状态 | 适用于普通文件、目录等,符号链接会返回目标文件的状态 |
fstat | 文件描述符 | 获取已打开文件的状态 | 适用于已经通过 open 打开的文件 |
lstat | 路径(文件名) | 获取符号链接本身的状态 | 对于符号链接,返回的是符号链接本身的状态,而非目标文件 |
struct stat 结构体
这三个函数都将文件的状态信息存储到 struct stat 结构体中。该结构体包含了关于文件的各种元数据,例如文件的大小、权限、修改时间等。常见的字段如下:
struct stat {
dev_t st_dev; // 设备ID
ino_t st_ino; // inode号
mode_t st_mode; // 文件类型和权限
nlink_t st_nlink; // 硬链接数
uid_t st_uid; // 文件所有者的UID
gid_t st_gid; // 文件所属组的GID
dev_t st_rdev; // 设备类型(如果是设备文件)
off_t st_size; // 文件大小(字节)
blksize_t st_blksize; // 文件系统的块大小
blkcnt_t st_blocks; // 文件占用的块数
time_t st_atime; // 最后访问时间
time_t st_mtime; // 最后修改时间
time_t st_ctime; // 最后状态变化时间
};接着来完成读操作
NAME
read - read from a file descriptor
SYNOPSIS
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);-
fd:文件描述符,表示要读取的文件或设备。通常,0表示标准输入(stdin),其他数字表示打开的文件、设备或网络连接。 -
buf:一个指针,指向程序预先分配的缓冲区,数据会从文件中读取到这个缓冲区。 -
count:要读取的字节数,即最多读取count个字节。 - 成功:返回实际读取的字节数。如果实际读取的字节数小于请求的
count,表示文件已到达末尾或读取操作受到某些限制。 - 失败:返回
-1,并设置errno来指示错误类型。
#include<stdio.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
#include<stdlib.h>
const char * filename="log.txt";
int main()
{
struct stat st;
int n=stat(filename,&st);
if(n<0)return 1;
int fd= open(filename,O_RDONLY);
if(fd<0)
{
perror("open");
return 2;
}
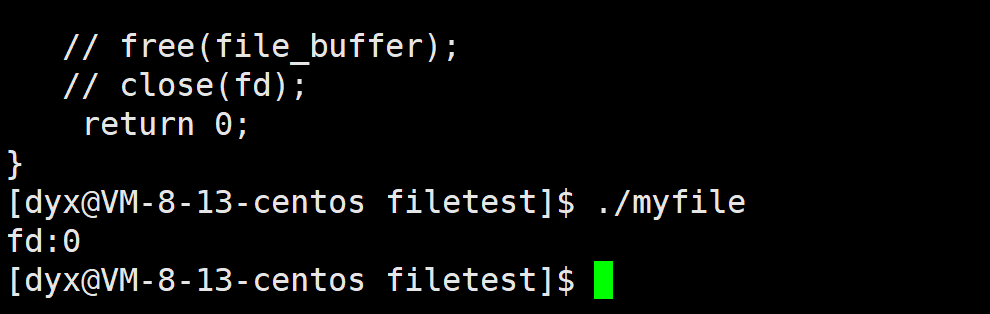
printf("fd:%d\n",fd);
char *file_buffer=(char*)malloc(st.st_size+1);
n=read(fd,file_buffer,st.st_size);
if(n>0)
{
file_buffer[n]='\0';
printf("%s\n",file_buffer);
}
free(file_buffer);
close(fd);
return 0;
}stat用来获取文件状态,存储在st结构体中,使用 open 系统调用以只读模式打开文件,read(fd, file_buffer, st.st_size):从文件中读取数据,read 会将最多 st.st_size 字节的数据从文件中读取到 file_buffer 中。返回的 n 表示实际读取的字节数。 如果 n > 0,表示成功读取了文件内容,程序会把文件内容输出到屏幕上。file_buffer[n] = ‘\0’; 将读取的数据末尾添加一个结束符,使其成为一个 C 字符串
02.重定向
我们前面提到,文件描述符是从最小开始分配的,分配最小的没有被使用过的fd。
0 1 2是系统默认分配的,我们现在关闭一下观察一下现象
int main()
{
close(0);
int fd = open(filename,O_WRONLY|O_CREAT|O_TRUNC,0666);
if(fd<0)
{
perror("open");
return 1;
}
printf("fd:%d\n",fd);
close(fd);
return 0;
}这行代码关闭了标准输入(stdin,文件描述符 0)。 之后的 open() 调用会返回最小可用的文件描述符
我们现在关闭1:
int main()
{
close(1);
int fd = open(filename,O_WRONLY|O_CREAT|O_TRUNC,0666);
if(fd<0)
{
perror("open");
return 1;
}
printf("printf fd:%d\n",fd);
fprintf(stdout,"fprinf fd:%d\n",fd);
close(fd);
return 0;
}
我们发现这里显示器和文件中都没有打印出内容,这里就与重定向和缓冲区有关了
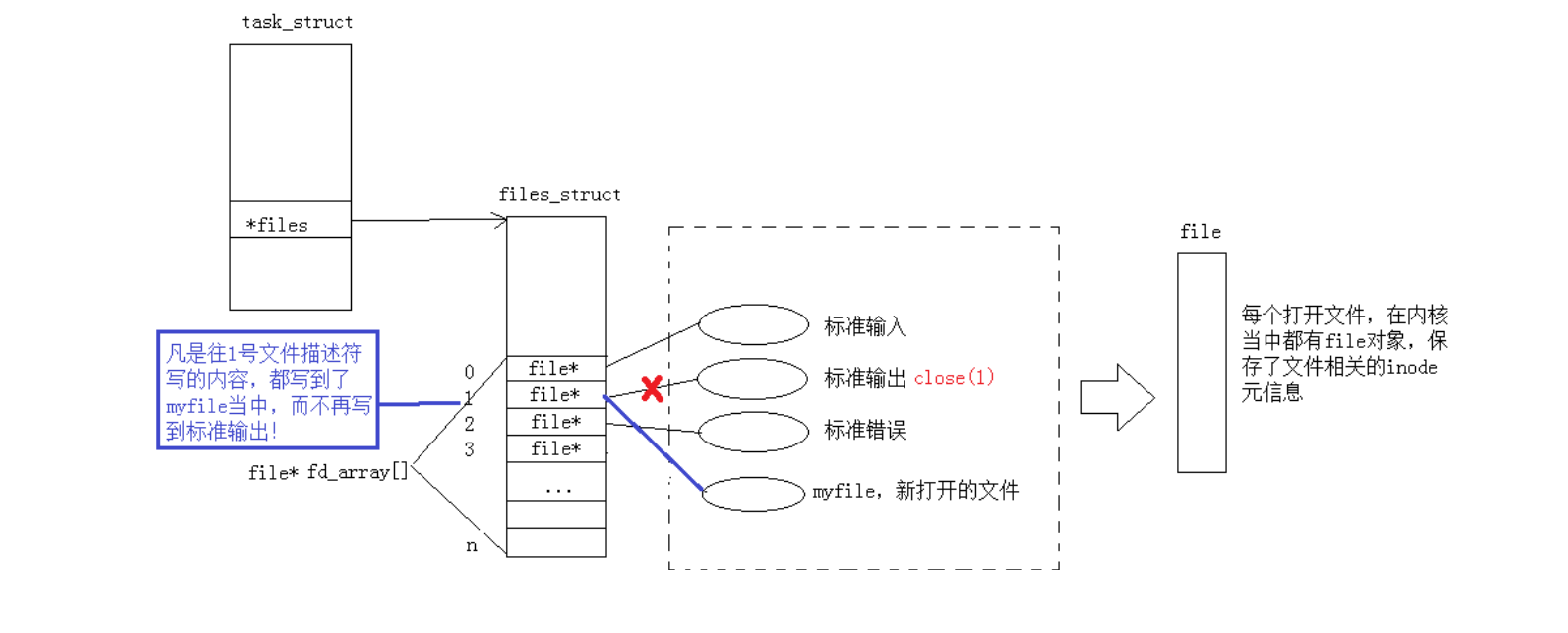
首先看第一部分,为什么显示器没有内容?
这是因为我们的close(1)关闭了文件标准输出的描述符(stdout,文件描述符 1)
因此,之后所有通过 printf()/fprinf() 输出的内容将不再显示在终端(显示器上),而是会被重定向到指定的文件中
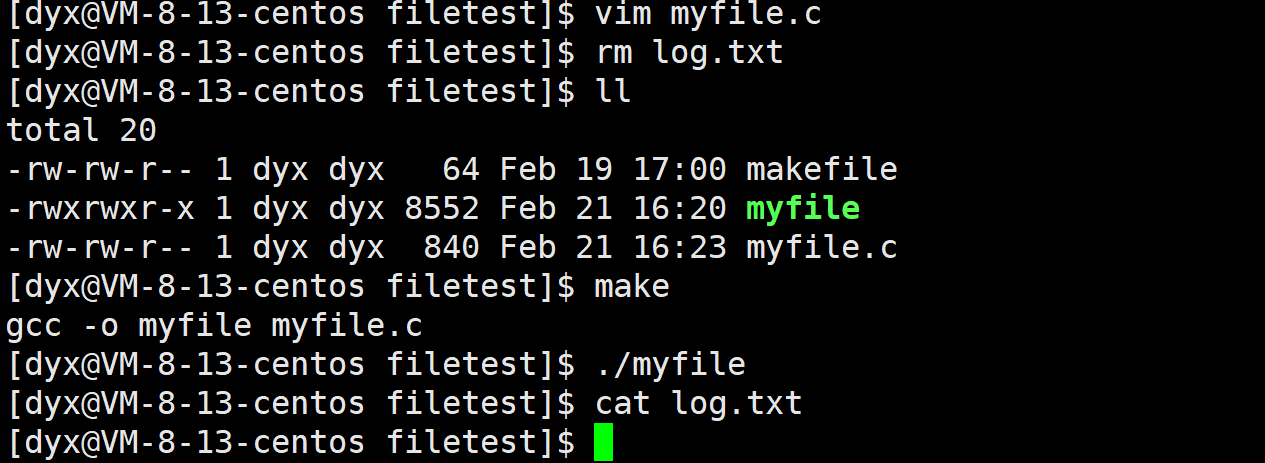
1号此时是我们log.txt的文件描述符,printf依旧向1里面打,所以此时打印的内容打入到了log.txt中,我们这里可以刷新查看:
int main()
{
close(1);
int fd = open(filename,O_WRONLY|O_CREAT|O_TRUNC,0666);
if(fd<0)
{
perror("open");
return 1;
}
printf("printf fd:%d\n",fd);
fprintf(stdout,"fprinf fd:%d\n",fd);
fflush(stdout);
close(fd);
return 0;
}
所以所谓的重定向本质就是在内核中改变文件描述符表,与上层无关
来看第二部分,为什么没有fflush(stdout)这一部分文件就显示不到内容呢?

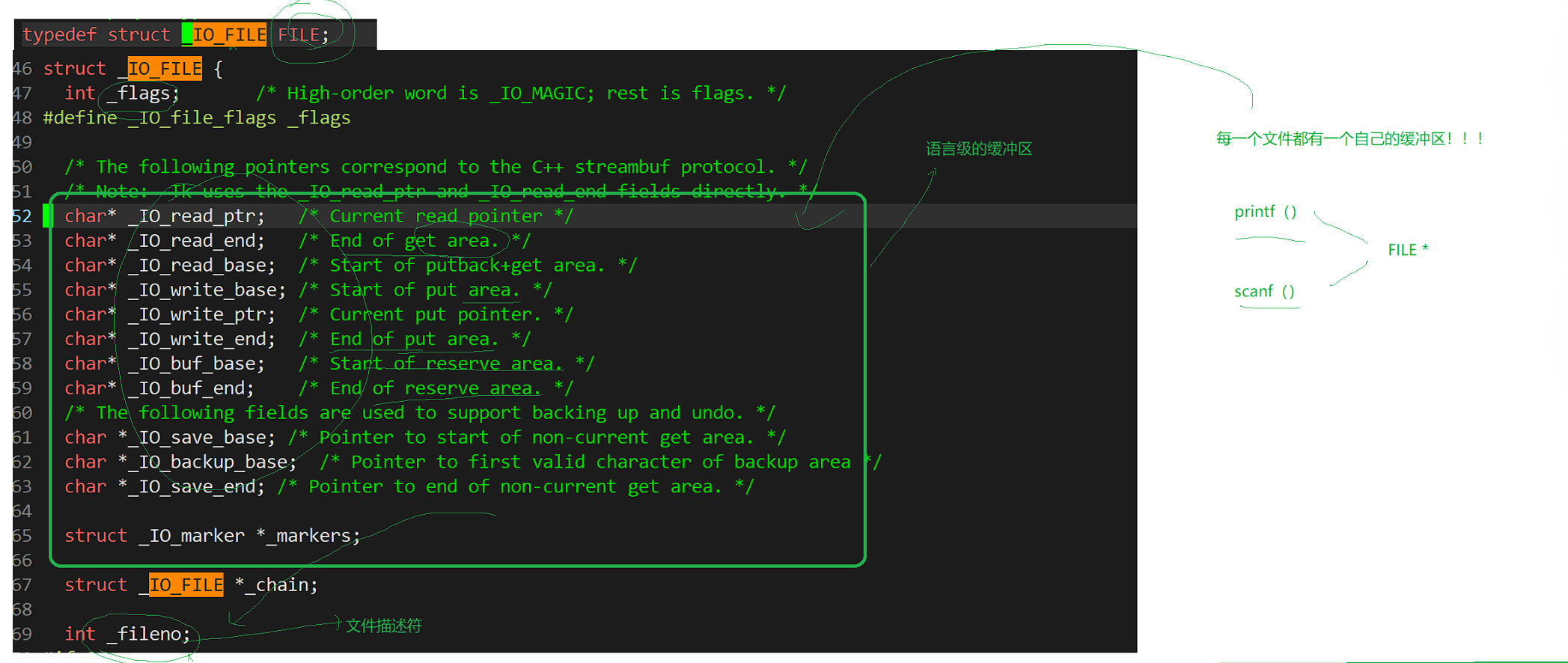
我们上层往log.txt文件中写的时候,最终是写到了内核文件的缓冲区里面,c语言中,stdin,stdout,stdin这三个本质都是struct FILE*的结构体,这三个对应的底层的文件描述符为0 1 2 ,它们有语言级别的缓冲区,
printf/fprintf并不是直接写入操作系统的,它们都是写入到stdout语言级别的缓冲区里,后面stdout通过1号文件描述符刷新到操作系统的文件缓冲区里,此时外设才能看到缓冲区的内容
所以fflush传参stdout本质不是把底层内核文件缓冲区刷到外设上,而是把语言级别的缓冲区,通过文件描述符,写到内核当中
我们代码最后直接close(fd),这里fd是我们打开的设备,所以我们正准备return之前刷新的时候,直接把文件描述符关了,将来刷新是根本没有办法通过1写入文件中,所以最终我们看见log.txt中没有任何内容
所以这里fflush在文件关之前刷新到了文件中
dup2 系统调用
dup2 是 Linux/Unix 下的一个 系统调用,用于将一个文件描述符(fd_old)复制到 另一个文件描述符(fd_new)。如果 fd_new 已经被打开,dup2 会先关闭它,然后让 fd_new 指向 fd_old 指向的文件。本质是文件描述符下标所对应内容的拷贝
#include <unistd.h>
int dup2(int fd_old, int fd_new);fd_old:要复制的文件描述符(源)。fd_new:目标文件描述符(目的地)。- 返回值:
- 成功返回
fd_new。 - 失败返回
-1,并设置errno。
- 成功返回
特点:
fd_new会被强制指向fd_old所指的文件。- 如果
fd_new已经打开,dup2会先关闭fd_new,然后再进行复制。 fd_new和fd_old共享同一个文件表项(即共享偏移量、文件状态等),但它们是独立的文件描述符。
让标准输出重定向到文件
dup2 最常见的用途之一是 重定向标准输入 (stdin)、标准输出 (stdout) 或标准错误 (stderr),通常用于日志文件、命令行工具或守护进程。
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 1;
}
dup2(fd, 1); // 把标准输出 (fd=1) 重定向到 log.txt
close(fd); // 关闭 fd,标准输出仍然有效
printf("This will be written to log.txt\n");
return 0;
}解释:
- 打开
log.txt,获取文件描述符fd(比如fd = 3)。 dup2(fd, 1);让stdout(fd = 1)指向fd = 3的文件。- 关闭
fd = 3,但stdout仍然指向log.txt。 printf()现在不会输出到终端,而是写入log.txt。
让标准错误 (stderr) 也写入文件
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd = open("error.log", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 1;
}
dup2(fd, 2); // 把标准错误 (fd=2) 重定向到 error.log
close(fd);
fprintf(stderr, "This is an error message!\n");
return 0;
}效果:
- 所有
fprintf(stderr, "...");输出都会进入error.log,而不会显示在终端。
创建子进程并修改输入/输出
在 进程创建后,子进程继承了父进程的文件描述符。如果我们希望子进程的 stdin 或 stdout 进行重定向,可以使用 dup2。
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd = open("output.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 1;
}
pid_t pid = fork();
if (pid < 0) {
perror("fork");
return 1;
}
if (pid == 0) { // 子进程
dup2(fd, 1); // 重定向 stdout 到 output.txt
close(fd);
execlp("ls", "ls", "-l", NULL); // `ls -l` 输出将写入 output.txt
perror("execlp");
exit(1);
}
close(fd);
wait(NULL); // 等待子进程结束
return 0;
}执行流程:
- 父进程创建
output.txt并获取文件描述符fd。 fork()生成子进程,子进程继承fd。- 在子进程中:
dup2(fd, 1);让stdout指向output.txt。execlp("ls", "ls", "-l", NULL);执行ls -l命令,输出写入output.txt。
- 结果: 终端不会有
ls -l的输出,而output.txt里会有ls -l的结果。
使用 dup2 进行进程间通信
如果两个进程使用 pipe() 创建管道,dup2 可以让子进程的 stdin/stdout 连接到管道。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
int pipefd[2];
pipe(pipefd);
pid_t pid = fork();
if (pid == 0) { // 子进程
close(pipefd[0]); // 关闭管道读取端
dup2(pipefd[1], 1); // 让 stdout 指向管道写入端
close(pipefd[1]);
execlp("ls", "ls", "-l", NULL); // `ls -l` 输出进入管道
perror("execlp");
exit(1);
}
close(pipefd[1]); // 关闭管道写入端
char buffer[1024];
read(pipefd[0], buffer, sizeof(buffer)); // 读取子进程的输出
printf("Output from child process:\n%s\n", buffer);
close(pipefd[0]);
return 0;
}作用:
- 子进程 执行
ls -l,但stdout被dup2重定向到管道。 - 父进程 从管道
read()读取子进程的ls -l结果,并打印到终端。
特性 | dup(fd) | dup2(fd_old, fd_new) |
|---|---|---|
作用 | 复制 fd 到一个新的最小可用 fd | 强制将 fd_new 指向 fd_old |
fd_new | 自动分配新 fd | fd_new 由用户指定 |
关闭 fd_new | 否 | 是(会关闭 fd_new,然后再复制) |
返回值 | 新的 fd | fd_new |
示例:
int new_fd = dup(fd); // 自动分配新的文件描述符
dup2(fd, 4); // 让 4 指向 fd✅ dup2(fd_old, fd_new) 让 fd_new 指向 fd_old
✅ 应用场景:
- 标准输入/输出/错误重定向(日志记录、后台进程)
- 子进程
exec前修改 I/O - 进程间通信(
pipe()+dup2) - 文件描述符管理
缓冲区的理解
缓冲区(Buffer) 本质上是一个临时存储数据的内存区域,用于提高 I/O 处理的效率,减少系统调用的次数。
为什么需要缓冲区
在计算机系统中,数据的读写速度通常是不均衡的:
- CPU 的处理速度 远快于 磁盘 I/O 和 网络 I/O。
- 内存访问速度 远快于 硬盘读写速度。
- 硬盘 I/O 远快于 网络通信(如 TCP 传输)。
如果每次读写数据都直接操作外部设备(比如磁盘或网络),CPU 可能会因为等待 I/O 而浪费大量时间。因此,缓冲区的作用是让数据的读写更高效,减少直接访问外部设备的次数。
缓冲区的分类
缓冲区可以按作用场景分为多种类型:
缓冲区类型 | 作用 |
|---|---|
用户态(应用层)缓冲区 | C 标准库 stdio 缓冲区(如 stdout、stdin),减少 write() 调用,提高性能 |
内核态缓冲区(操作系统层) | page cache(磁盘缓存)、socket buffer(网络缓冲) |
设备缓冲区 | 硬盘、网卡、打印机等设备内部的缓冲 |
环形缓冲区(Ring Buffer) | 常见于音视频处理、网络通信 |
C 语言 stdio 的缓冲区
(1)C 语言的 stdout 其实有缓冲
在 C 语言中,printf() 并不会立即把数据写入屏幕或文件,而是先存入 stdout 语言级别的缓冲区,然后由 fflush(stdout) 或 \n 触发输出。
示例
#include <stdio.h>
int main() {
printf("Hello, World!"); // 没有 `\n`,可能不会立刻显示
while (1); // 进入死循环,不调用 `fflush(stdout)`
}可能的现象:
- 终端上看不到
Hello, World!,因为stdout还没有刷新。 - 解决方法:
- 手动刷新缓冲区
fflush(stdout); - 使用换行符
\n,行缓冲模式会自动刷新 - 关闭缓冲模式
setbuf(stdout, NULL);
- 手动刷新缓冲区
(2)stdout 的 3 种缓冲模式
C 语言的 stdio(stdout, stdin, stderr)在不同情况下有不同的缓冲模式:
缓冲模式 | 触发时机 | 应用场景 |
|---|---|---|
全缓冲(Fully Buffered) | 缓冲区满了时 或 fflush(stdout); | 文件 I/O |
行缓冲(Line Buffered) | 遇到 \n 时自动刷新 | 终端交互(如 stdout) |
无缓冲(Unbuffered) | 每次 printf() 都直接写入 | stderr(标准错误) |
修改 stdout 缓冲模式
#include <stdio.h>
int main() {
setbuf(stdout, NULL); // 禁用缓冲区(无缓冲)
printf("Hello, World!"); // 立刻输出
}write() vs. printf()
函数 | 是否经过 C 语言缓冲区 | 是否直接写入内核 |
|---|---|---|
printf() | ✅ 是 | ❌ 否(写入 stdio 缓冲区) |
fprintf(stdout, ...) | ✅ 是 | ❌ 否(写入 stdout 缓冲区) |
fflush(stdout) | ✅ 是 | ✅ 是(写入内核 write()) |
write(fd, buf, size) | ❌ 否 | ✅ 是(直接进入内核缓冲区) |
内核缓冲区(Page Cache)
即使 printf() 经过 fflush(stdout);,或者 write(fd, buf, size);,数据仍然不会立即写入磁盘,而是进入内核的 Page Cache,等待操作系统调度落盘。
(1)Page Cache 的作用
- 加速磁盘读写,避免频繁访问硬盘。
- 合并小的写入请求,减少
I/O操作次数。
(2)如何强制数据写入磁盘?
使用 fsync(fd);
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
write(fd, "Hello, World!", 13);
fsync(fd); // 强制写入磁盘
close(fd);
return 0;
}fsync(fd); 强制把 page cache 数据写入磁盘。
fflush(stdout); vs. fsync(fd);
函数 | 作用 | 刷新的范围 |
|---|---|---|
fflush(stdout); | 刷新 C 语言 stdio 缓冲区 | 从 stdout 到 write(fd, buf, size); |
fsync(fd); | 刷新内核 Page Cache | 从 Page Cache 到 磁盘 |
进程间通信中的缓冲区
进程通信(IPC)中也大量使用缓冲区:
- 管道(Pipe):在
pipe()读写时,数据先写入 内核管道缓冲区,再由read()读取。 - Socket 缓冲区:数据在 TCP 发送时,先进入 Socket Send Buffer,然后由操作系统调度到网卡发送。
- 共享内存(SHM):多个进程可以映射到同一个缓冲区,避免多次拷贝。
✅ 缓冲区的作用
- 提高 I/O 效率,减少系统调用次数。
- 避免 CPU 频繁等待慢速设备(磁盘、网络)。
- 减少小数据块写入,提高吞吐量。
✅ 缓冲区的层次
层次 | 缓冲区类型 |
|---|---|
C 语言缓冲区 | stdout, stderr, stdin |
内核缓冲区 | page cache, socket buffer |
设备缓冲区 | 硬盘、网卡、打印机 |
✅ 如何控制缓冲区刷新
fflush(stdout);把stdio数据写入write()fsync(fd);把write()发送的数据刷入磁盘O_SYNC/O_DIRECT直接绕过Page Cache
✅ write() vs. printf()
write(fd, buf, size);直接进入内核,不会受fflush()影响。printf()先写入 C 语言缓冲区,需要fflush(stdout);才能写入write()。
🌟 重点:
C 语言的 stdout 缓冲区和 Linux Page Cache 是两层不同的缓冲区,fflush(stdout); 只能刷新 stdout,但不会保证数据写入磁盘,需要 fsync(fd);。 🚀
#include<stdio.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
#include<unistd.h>
#include<string.h>
#include<stdlib.h>
int main()
{
printf("hello printf\n");
fprintf(stdout,"hello fprintf\n");
const char *msg ="hello write\n";
write(1,msg,strlen(msg));
fork();
return 0;
}我们运行结果和重定向到log.txt打印结果不同
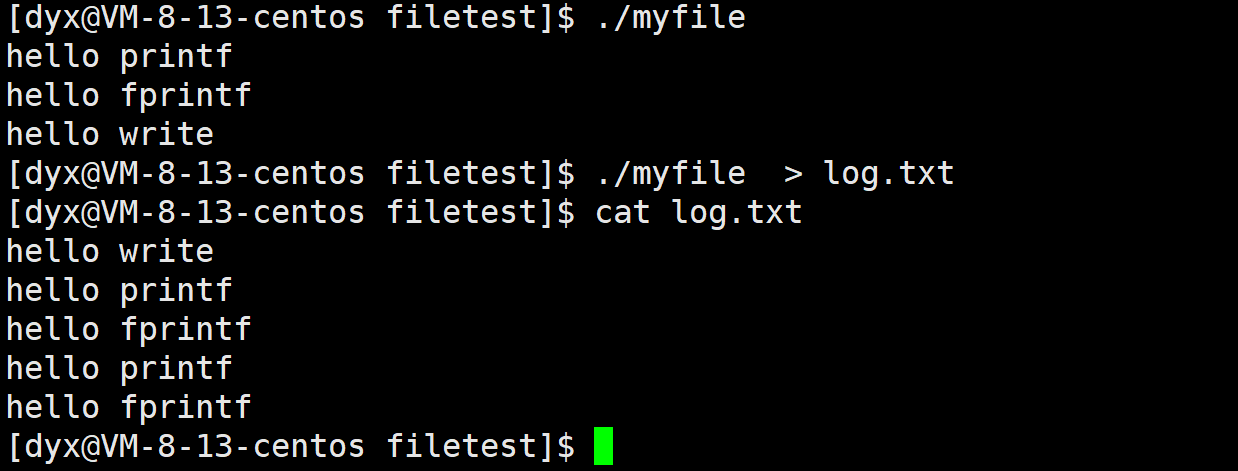
log.txt打印两次肯定与fork()有关,./myfile默认是向显示器打印的,显示器的刷新策略是行刷新,重定向的本质是向普通文件进行写入,这里的刷新策略发生变化,普通文件采用的是全缓冲
如果是向显示器打印,还没走到fork,上面打印数据已经写到了操作系统内部,文件缓冲区里数据已经存在了,这里的fork没什么意义了
但是重定向到文件中,它是全缓冲,文件的缓冲区并没有被写满,文件的缓冲区会将写入的数据暂时的保存起来,但是write系统调用直接写到了内核里,后面在fork时,write已经写到了操作系统内部,但是printf和fprintf依旧在语言级别的stdout的缓冲区中,所以fork时候数据还在缓冲区中,因为缓冲区没写满,所以fork这里出现父子进程,退出的时候父子进程各自刷新一次缓冲区,所以printf和fprintf打印两次
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-02-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号