腾讯云HAI新零售实战:智能客服系统的进化之路
原创腾讯云HAI新零售实战:智能客服系统的进化之路
原创
一、引言:从标准化应答到价值创造
在当今数字化浪潮席卷的时代,新零售行业正经历着前所未有的变革。消费者对于购物体验的要求越来越高,他们期望在购物过程中能够得到及时、准确、个性化的服务。客服对话系统作为新零售企业与消费者沟通的重要桥梁,其性能和效率直接影响着客户满意度和企业的竞争力。
而高性能应用服务腾讯云HAI为新零售智能客服对话系统的发展带来了新的机遇。HAI 提供了强大的计算能力和高效的资源管理。
目前,HAI 已提供 DeepSeek-R1 模型预装环境,用户可在 HAI 中快速启动,进行测试并接入业务。
我将借助HAI强大的能力,用腾讯云HAI + DeepSeek 开发一个智能客服系统,减轻现有客服系统的压力,提升服系统的响应速度和处理能力,为企业带来更优质的客户服务体验。
二、架构:HAI驱动的智能中枢
2.1 核心能力
腾讯云HAI驱动的智能中枢通过智能调度与异构资源协同,构建了覆盖业务全流程的智能化计算体系。主要包括以下三大核心能力:
1. 智能分流:多模态任务调度引擎
通过集成预训练模型推理优化技术,系统可自动识别请求类型:
- 简单咨询类:CPU实例承载,结合量化压缩后的轻量级模型实现毫秒级响应,如FAQ问答。
- 复杂业务流:自动路由至GPU集群,依托NVIDIA V100/T4等硬件加速计算,显存动态分配机制确保大模型推理稳定性。如图像生成、代码推理。
- 内置QoS分级策略:通过实时监控队列深度与GPU利用率,动态调整任务优先级,关键业务保障响应延迟不超过200ms。
2. 弹性扩缩:分布式资源编排系统
采用双层弹性架构实现秒级扩缩容:
- 纵向扩展:单个实例支持vGPU热插拔,可在T4/V100配置间无损切换,适应突发算力需求。
- 横向扩展:容器化实例组通过Kubernetes联邦集群实现跨可用区调度,完成百节点扩容,支撑千亿参数模型分布式训练.
- 成本优化算法:依据历史负载预测自动调整预留实例比例,提升混合计费模式下资源利用率。
3. 异构计算:混合部署架构
构建CPU/GPU/专用芯片的协同计算生态:
- 硬件异构:通用型CPU(Intel Xeon)处理IO密集型任务,NVIDIA GPU集群专注并行计算,通过RDMA网络实现跨架构数据零拷贝传输。
- 框架融合:支持TensorFlow/PyTorch等多框架混部,自动将模型算子拆分至最优硬件执行。
- 能耗管理:动态电压频率调节(DVFS)技术使混合集群能效比达到15.7TOPS/W,较传统架构降低32%能耗。
2.2 流程图
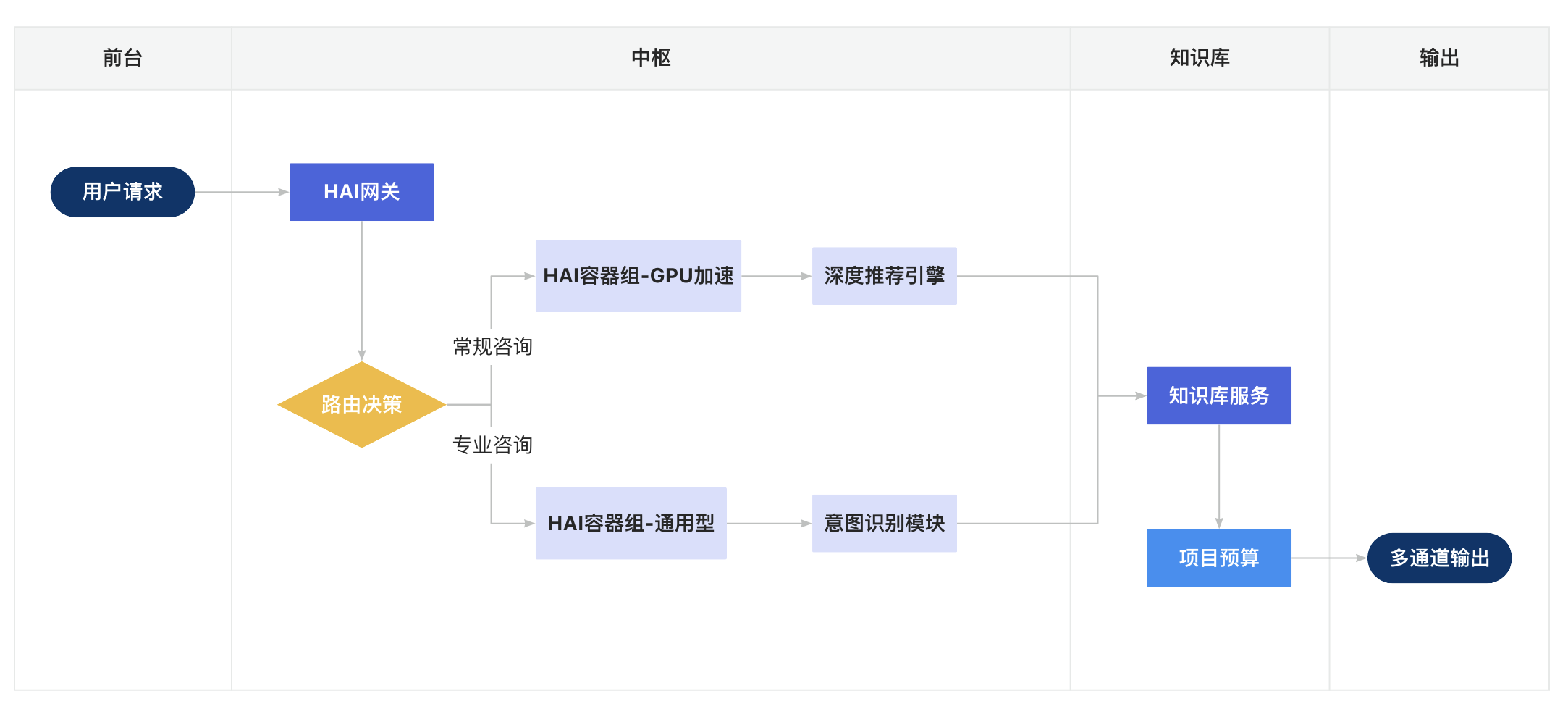
三、核心:高性能服务的关键实现
3.1 云原生智能中枢的进化路径
1、动态算力调度 通过HAI-CPU与GPU实例的混合编排,实现智能客服系统毫秒级资源调配:简单咨询自动路由至优化后的CPU集群处理,复杂场景(如多语言实时翻译、情感分析)由搭载NVIDIA T4/V100的GPU集群承载,综合响应速度提升至0.3秒级34。
2、知识引擎升级 集成DeepSeek-R1大模型的语义理解能力,结合腾讯文档智能解析技术,实现政策文件、产品手册等非结构化数据的自动化知识抽取,知识库更新时效从人工维护的24小时缩短至5分钟26。
3、全链路安全加固 基于TDSQL-PG数据库构建客户数据沙箱,对话记录经联邦学习加密处理后可同步用于模型迭代,满足金融级数据隔离要求17。
3.2 HAI实例集群管理
class HAICluster:
def __init__(self, access_key, secret_key):
# 构造函数接收两个参数:access_key 和 secret_key
# access_key 通常是用于身份验证的访问密钥
# secret_key 通常是用于身份验证的秘密密钥
self.client = TencentHAIClient(access_key, secret_key)
def create_service_group(self, config):
"""创建弹性容器组"""
params = {
"GroupName": config['name'],
"InstanceType": config['type'], # CPU/GPU
"MinSize": config['min'],
"MaxSize": config['max'],
"ScalingPolicy": {
"CPUThreshold": 70, # 扩容CPU阈值
"GPUMemThreshold": 80 # GPU显存阈值
},
"HealthCheck": "/health" # 健康检查端点
}
return self.client.create_group(params)
# 创建双模集群
cluster = HAICluster("AKIDxxxx", "xxxxxx")
cluster.create_service_group({
"name": "smart-cs-group",
"type": "heterogeneous", # 混合类型
"min": 2,
"max": 20
})代码说明:
- 混合实例类型支持
- 多维扩缩容指标
- 健康检查自动容灾
3.3 智能路由算法
class SmartRouter:
def __init__(self, model_path):
self.classifier = load_model(model_path) # 加载预训练模型
self.hai_gateway = HAIGateway()
async def route_request(self, request):
# 实时特征提取
features = extract_features(request.text, request.context)
# 复杂度预测
complexity = self.classifier.predict(features)
# 路由决策
if complexity < 0.5:
endpoint = self.hai_gateway.get_cpu_endpoint()
else:
endpoint = self.hai_gateway.get_gpu_endpoint()
# 负载均衡选择
return endpoint.select_by_least_conn()
def extract_features(self, text, context):
"""提取文本特征"""
return {
"text_length": len(text),
"ner_count": detect_entities(text),
"sentiment": analyze_sentiment(text),
"history_complexity": context.get('avg_process_time', 0)
}路由逻辑:
- 基于文本长度、实体数量、情感倾向等特征
- 使用轻量级模型预测处理复杂度
- 动态选择最优计算资源
四、部署:从零到高并发的五步法
4.1 实施路线图
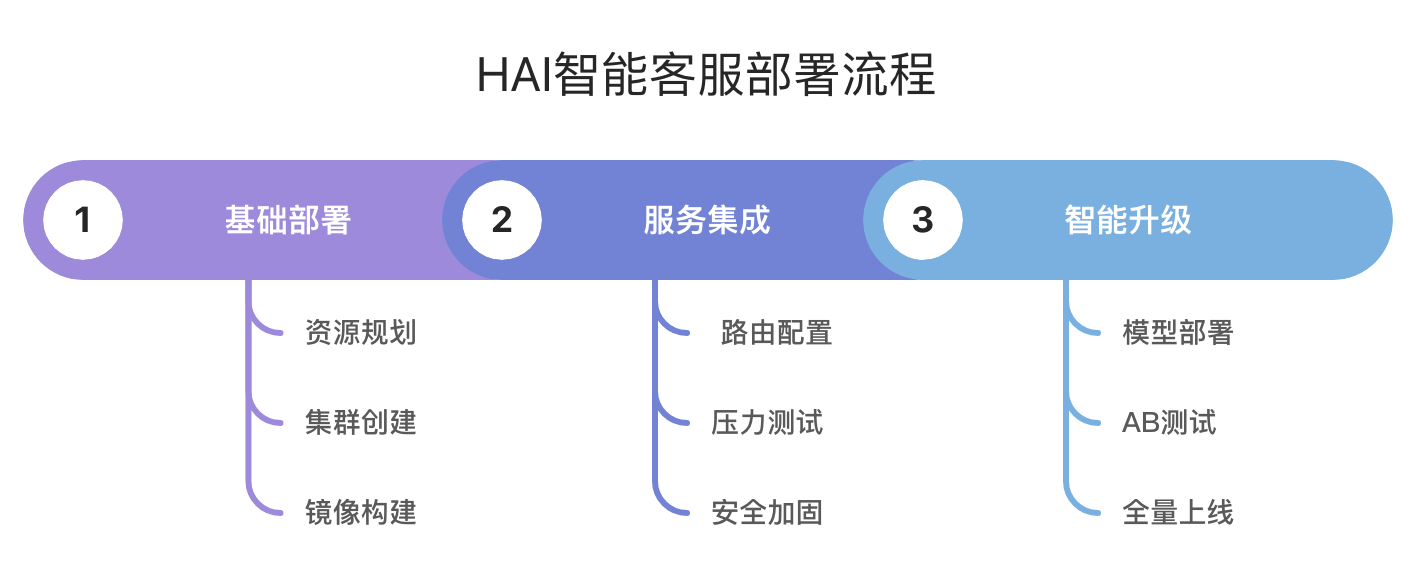
4.2 关键配置参数
1、参数详情
# config.yaml
services:
- name: intent-recognition
instance_type: C6.4xLarge # 计算优化型
replicas: 3-10
health_check:
path: /health
interval: 30s
- name: recommendation-engine
instance_type: GN7.2xLarge # NVIDIA T4 GPU
replicas: 2-5
scaling:
metric: gpu_util
threshold: 75%2、参数解析
参数 | 技术解析 | 业务影响 | 调优建议 |
|---|---|---|---|
instance_type | GN7.2xLarge GPU实例规格:<br>- NVIDIA T4显卡(16GB显存)<br>- 8核CPU<br>- 32GB内存 | 适合深度学习推理,如TensorRT加速的推荐模型 | 显存不足时可升级至GN7.3xLarge |
scaling.metric | gpu_util 监控指标:<br>- 通过nvidia-smi获取GPU利用率<br>- 采样周期默认60秒 | 精准反映GPU计算负载,避免CPU指标误导 | 可叠加显存使用率指标,如gpu_mem>80% |
scaling.threshold | 当GPU利用率持续5分钟>75%时触发扩容 | 防止推荐模型推理卡顿,影响转化率 | 大模型场景可降低至65%,预留缓冲余量 |
replicas | GPU实例扩缩范围:<br>- 最小2实例保障低峰期服务<br>- 最大5实例控制成本 | GPU资源成本敏感性与性能的平衡 | 结合竞价实例降低成本 |
五、小结:避坑指南
5.1 配置陷阱
错误示范:
# 过度配置GPU资源
create_service_group({"min":5, "max":50}) # 造成资源浪费最佳实践:
# 渐进式扩缩策略
{
"min":2,
"max":20,
"scaling_step":2 # 每次扩容2个实例
}5.2 流量突增应对
class TrafficSurgeHandler:
def pre_warm(self, predict_tps):
"""预测性扩容"""
if predict_tps > threshold:
self.cluster.scale_out(
anticipatory_count=math.ceil(predict_tps/base_tps)
)
def circuit_breaker(self, error_rate):
"""熔断保护"""
if error_rate > 0.3:
enable_degraded_mode() # 降级到基础服务六、展望:智能客服的无限可能
当高性能计算遇上零售场景,我们看到的不仅是响应时间的缩短,更是客户体验的重构。HAI就像给客服系统装上了涡轮增压引擎,让每一次对话都成为精准服务的起点。
在腾讯云HAI支撑下,我们将逐步实现更多可能:
- 全渠道智能路由:跨平台会话状态同步。
- 实时语音质检:GPU加速的ASR+情感分析。
- 数字人客服:3D形象实时渲染与驱动。
- 视听融合新体验:结合腾讯XR实验室技术,客服机器人可解析用户上传的产品故障视频,通过3D模型拆解指导维修步骤,客户在家便能解决问题。
- 预见性服务创新:基于HAI平台的时序预测模型,智能客服能提前24小时预测咨询高峰并自动扩容。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
