[AI学习笔记]预训练范式演进:DeepSeek多阶段预训练技巧解密
原创[AI学习笔记]预训练范式演进:DeepSeek多阶段预训练技巧解密
原创
I. 项目背景与技术演进
在人工智能与深度学习蓬勃发展的当下,预训练模型成为了推动自然语言处理、计算机视觉等众多领域取得突破性进展的关键力量。从最初的无监督预训练到如今复杂的多阶段预训练范式,每一次演进都为模型性能的提升和应用场景的拓展提供了新的可能。DeepSeek等先进系统通过创新的多阶段预训练技巧,在大规模数据上学习到丰富的特征表示,并在下游任务中展现出卓越的性能。
1.1 大模型预训练发展历程
- (一)早期无监督预训练 在深度学习初期,无监督预训练主要通过自编码器等模型,在未标记数据上学习数据的特征表示。这种方法能够在缺乏大量标记数据的情况下,对模型进行有效的初始化,为后续的有监督训练提供良好的起点。
- (二)语言模型预训练的兴起 随着自然语言处理领域的发展,基于语言模型的预训练方法(如Word2Vec、GloVe)开始流行。这些方法通过在大规模文本数据上训练,学习到单词的分布式表示,能够捕捉单词之间的语义和语法关系,为后续的文本处理任务提供了强大的语言特征。
- (三)Transformer架构的预训练 2018年,BERT模型的提出标志着Transformer架构在预训练领域的重大突破。BERT通过Masked Language Model(MLM)等任务,在大规模无监督文本上进行预训练,学习到了丰富的语言知识。随后,GPT系列等基于Transformer的预训练模型不断涌现,通过自回归语言模型等方式,在众多自然语言处理任务中取得了卓越的性能。
- (四)多模态预训练的发展 近年来,多模态预训练逐渐成为研究热点。通过将文本、图像、音频等多种模态数据结合起来进行预训练,模型能够学习到跨模态的特征表示和关联信息,为多模态下游任务(如图像描述生成、视觉问答等)提供了强大的支持。
- (五)DeepSeek的多阶段预训练创新 DeepSeek等系统进一步推动了预训练范式的发展,通过多阶段预训练策略,逐步提升模型的性能和泛化能力。在不同的预训练阶段,采用不同的训练任务和数据,使模型能够学习到更全面、更深入的特征表示,为在复杂多样的下游任务中取得优异表现奠定了基础。
DeepSeek预训练框架的演进反映了大模型训练范式的三次革命:
阶段 | 时间范围 | 核心技术 | 训练数据量 | 典型模型 | 关键突破 |
|---|---|---|---|---|---|
启蒙期 | 2018-2020 | 标准Transformer | 10-100GB | BERT/GPT-2 | 掩码语言建模 |
扩展期 | 2021-2022 | 混合专家(MoE) | 1-5TB | Switch-Transformer | 条件计算 |
专业期 | 2023-至今 | 多阶段课程学习 | 50TB+ | DeepSeek-67B | 动态数据调度 |
1.2 DeepSeek预训练挑战
在训练67B参数模型时面临的核心问题:
# 传统单阶段训练的问题演示
def train(model, dataset):
optimizer = AdamW(model.parameters(), lr=5e-4)
for epoch in range(100):
for batch in dataset:
loss = model(batch)
loss.backward()
optimizer.step() # 持续的高学习率导致后期不稳定
optimizer.zero_grad()问题分析:
- 数据利用率低:简单随机采样导致重要样本被稀释
- 优化不均衡:固定学习率无法适应不同训练阶段
- 知识固化:后期微调难以改变早期学习模式
II. 多阶段预训练核心技术
2.1 三阶段训练架构
DeepSeek提出"渐进式知识注入"的三阶段范式:
DeepSeek采用分阶段的训练策略,每个阶段专注于特定的训练任务和目标,逐步提升模型的能力。
- 第一阶段:基础语言模型预训练 在第一阶段,使用大规模的文本数据对模型进行基础语言模型的预训练。通过自回归或Masked Language Model等任务,让模型学习到语言的基本规律和词汇之间的关系。这一阶段的目标是为模型打下坚实的语言基础,使其具备良好的语言理解与生成能力。
- 第二阶段:任务特定预训练 在第二阶段,针对特定的任务类型或领域,进行进一步的预训练。例如,在自然语言处理领域,可以对模型进行命名实体识别、句子关系判断等任务的预训练;在计算机视觉领域,可以对模型进行图像分类、目标检测等任务的预训练。这一阶段的目的是让模型适应特定任务的需求,学习到与任务相关的特征和知识。
- 第三阶段:多模态融合预训练 在第三阶段,将不同模态的数据结合起来,进行多模态融合预训练。通过设计跨模态的训练任务,让模型学习到图像、文本等不同模态之间的关联和交互信息。例如,训练模型根据图像生成描述文本,或者根据文本描述识别图像中的内容。这一阶段使模型具备了处理多模态数据的能力,能够更好地应对现实世界中的复杂应用场景。2.1.1 各阶段配置对比
阶段 | 训练目标 | 数据构成 | Batch Size | 学习率 | 持续时长 |
|---|---|---|---|---|---|
筑基 | 语言建模 | 通用文本80%+代码20% | 4096 | 3e-4 | 30天 |
增强 | 多任务学习 | 领域文本50%+知识图谱30%+数学20% | 2048 | 1e-4 | 20天 |
精调 | 指令跟随 | 人工标注30%+合成数据70% | 1024 | 5e-5 | 10天 |
2.2 动态数据调度算法
DeepSeek在预训练过程中,精心选择和动态更新训练数据,以提高模型的性能和泛化能力。
- 多样化数据来源 从多个领域和来源收集数据,包括书籍、网页、学术文献、图像数据集等,确保训练数据的多样性和丰富性。这样可以使模型学习到不同领域和风格的知识,提高其在各种下游任务中的适应性。
- 数据质量控制 对收集到的数据进行严格的质量控制,去除低质量、噪声较多或存在偏见的数据。通过数据清洗和筛选,保证训练数据的准确性和可靠性,有助于模型更好地学习到有效的特征表示。
- 动态数据更新 随着训练的进行,不断引入新的数据和任务,保持模型的学习活力。通过动态更新数据,模型能够持续接触到新的知识和信息,避免过拟合到固定的训练数据上,提高其泛化能力和对新任务的适应性。2.2.1 课程学习策略 p_t^{(i)} = \frac{\exp(\alpha \cdot s_i^{(t)})}{\sum_j \exp(\alpha \cdot s_j^{(t)})}
class CurriculumSampler:
def __init__(self, dataset, alpha=0.5):
self.scores = compute_difficulty(dataset) # 预计算样本难度
self.alpha = alpha # 课程进度系数
def sample(self, current_step):
# 动态调整采样概率
temp = 1.0 + self.alpha * current_step
probs = F.softmax(self.scores / temp, dim=0)
return torch.multinomial(probs, batch_size)难度评分维度:
- 词汇复杂度 (词频逆文档频率)
- 句法嵌套深度
- 语义抽象级别
2.2.2 混合数据训练
def hybrid_loss(batch):
text_loss = model(batch['text']) # 语言建模损失
kg_loss = model(batch['triples']) # 知识图谱三元组损失
math_loss = model(batch['equations']) # 数学公式推导损失
return 0.6*text_loss + 0.3*kg_loss + 0.1*math_lossIII. 核心训练技巧实现
3.1 渐进式优化策略
3.1.1 学习率动态调整
class DeepSeekScheduler:
def get_lr(self, step):
if step < warmup_steps: # 初始阶段
return base_lr * step / warmup_steps
elif step < transition_step: # 平稳阶段
return base_lr
else: # 衰减阶段
return base_lr * 0.5 ** ((step - transition_step) // decay_interval)各阶段学习率曲线:
训练阶段 | 初始学习率 | 衰减策略 | 最终学习率 |
|---|---|---|---|
筑基 | 3e-4 | 线性预热 | 3e-4 |
增强 | 1e-4 | 余弦衰减 | 5e-5 |
精调 | 5e-5 | 阶梯衰减 | 1e-5 |
3.1.2 参数冻结策略
def freeze_layers(model, current_stage):
# 筑基阶段:仅训练顶层
if current_stage == 1:
for param in model.base_layers.parameters():
param.requires_grad = False
# 增强阶段:解冻中间层
elif current_stage == 2:
for param in model.mid_layers.parameters():
param.requires_grad = True
# 精调阶段:全参数训练
else:
for param in model.parameters():
param.requires_grad = True3.2 正则化技术演进
技术 | 筑基阶段 | 增强阶段 | 精调阶段 |
|---|---|---|---|
Dropout率 | 0.1 | 0.3 | 0.5 |
权重衰减 | 0.01 | 0.05 | 0.1 |
梯度裁剪 | 1.0 | 2.0 | 5.0 |
标签平滑 | 0.05 | 0.1 | 0.2 |
IV. 分布式训练实现
DeepSeek对模型架构进行了一系列优化,以适应多阶段预训练的需求。
- 深度Transformer架构 采用深度Transformer架构,增加模型的层数和参数规模,提高模型的表达能力和对复杂特征的学习能力。通过堆叠多个Transformer编码器和解码器层,模型能够在不同的抽象层次上捕捉数据的特征和模式。
- 交叉模态注意力机制 在多模态预训练中,引入交叉模态注意力机制,让模型能够有效地融合和交互不同模态的信息。通过在图像和文本等模态之间建立注意力连接,模型可以关注到不同模态中的关键信息,并学习它们之间的关联。
- 动态路由与模块化设计 采用动态路由和模块化设计,使模型能够根据输入数据的特点和任务需求,灵活地选择和组合不同的模块进行计算。这种设计不仅提高了模型的计算效率,还增强了其对多样化任务的适应性。
4.1 混合并行策略
4.1.1 张量并行实现
# 基于Megatron-LM的层内并行
from megatron.core import tensor_parallel
class ParallelMLP(nn.Module):
def __init__(self, hidden_size):
self.dense_h_to_4h = tensor_parallel.ColumnParallelLinear(
hidden_size, 4*hidden_size
)
self.dense_4h_to_h = tensor_parallel.RowParallelLinear(
4*hidden_size, hidden_size
)
def forward(self, x):
x = self.dense_h_to_4h(x)
x = gelu(x)
return self.dense_4h_to_h(x)并行配置对比:
并行维度 | 筑基阶段 | 增强阶段 | 精调阶段 |
|---|---|---|---|
数据并行 | 1024卡 | 512卡 | 256卡 |
流水并行 | 8 stages | 4 stages | 2 stages |
专家并行 | 32 experts | 64 experts | 128 experts |
4.2 性能优化技巧
4.2.1 显存优化
def activation_checkpoint(module):
# 使用选择性激活检查点
from torch.utils.checkpoint import checkpoint_sequential
def forward(*inputs):
def custom_forward(*tensors):
return module(*tensors)
return checkpoint_sequential(
[custom_forward],
chunks=4,
input=inputs
)
return forward显存节省效果:
优化技术 | 67B模型显存占用 | 节省比例 |
|---|---|---|
基础配置 | 320GB | - |
+梯度检查点 | 245GB | 23% |
+CPU卸载 | 182GB | 43% |
+混合精度 | 97GB | 70% |
V. 部署与推理优化
5.1 模型压缩技术
5.1.1 动态量化实现
# 使用Torch Quantization
model_fp32 = load_pretrained_model()
model_fp32.eval()
# 量化配置
qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
model_fp32.qconfig = qconfig
# 准备量化
model_int8 = torch.quantization.prepare_qat(model_fp32)
# 校准
for data in calibration_data:
model_int8(data)
# 转换
model_final = torch.quantization.convert(model_int8)量化效果对比:
精度 | 模型大小 | 推理延迟 | 准确率 |
|---|---|---|---|
FP32 | 260GB | 350ms | 82.3% |
FP16 | 130GB | 210ms | 82.1% |
INT8 | 65GB | 150ms | 81.7% |
5.2 推理服务部署
# 使用Triton推理服务器配置
name: "deepseek_67b"
platform: "pytorch_libtorch"
max_batch_size: 16
input [
{ name: "input_ids", data_type: TYPE_INT64, dims: [ 2048 ] }
]
output [
{ name: "logits", data_type: TYPE_FP32, dims: [ 50257 ] }
]
instance_group [
{ count: 4, kind: KIND_GPU }
]
optimization {
cuda {
graphs: true
busy_wait_events: true
}
}部署性能指标:
硬件配置 | 吞吐量(query/s) | P99延迟 | 服务成本($/M tokens) |
|---|---|---|---|
4×A100 | 1240 | 210ms | 1.27 |
8×T4 | 680 | 450ms | 2.15 |
16×TPUv4 | 3840 | 95ms | 0.89 |
VI. 实例分析:多模态情感分析任务
假设我们要在DeepSeek的多阶段预训练框架下,完成一个跨模态的情感分析任务,即根据图像和对应的文本描述,判断其中蕴含的情感倾向。
- 第一阶段:基础语言模型与图像特征预训练 使用大规模的文本语料和图像数据集,分别对语言模型和图像特征提取模型进行预训练。在语言模型预训练中,采用Masked Language Model任务,让模型学习到文本中的词汇和语法知识;在图像特征预训练中,使用图像分类任务,让模型学习到图像的基本视觉特征。
- 第二阶段:跨模态关联预训练 将图像和文本数据结合起来,进行跨模态的关联预训练。设计任务让模型学习图像和文本之间的情感关联,例如,训练模型根据图像预测对应的文本情感描述,或者根据文本描述判断图像中的情感场景。
- 第三阶段:多模态情感分析微调 在完成多阶段预训练后,将模型在具体的情感分析数据集上进行微调。通过在包含图像和文本以及对应情感标签的数据集上进行有监督训练,进一步优化模型的参数,使其能够准确地完成多模态情感分析任务。代码部署过程
(一)环境准备
在进行多阶段预训练之前,需要准备相应的计算环境和数据资源。
- 硬件与软件环境搭建 确保有足够的计算资源,如多块高性能GPU,并安装好深度学习框架(如PyTorch)及相关依赖库。同时,配置分布式训练环境,以便在多GPU或多个机器上进行并行训练。
- 数据收集与预处理 收集大规模的文本和图像数据,并进行相应的预处理。对于文本数据,进行分词、去除噪声等操作;对于图像数据,进行归一化、裁剪等处理。将处理好的数据存储为模型能够读取的格式,方便在训练过程中加载和使用。
(二)模型构建
使用PyTorch框架构建DeepSeek的多模态预训练模型。
import torch
import torch.nn as nn
from transformers import BertConfig, BertModel
from torchvision.models import resnet50
# 图像特征提取模块
class ImageFeatureExtractor(nn.Module):
def __init__(self):
super(ImageFeatureExtractor, self).__init__()
self.resnet = resnet50(pretrained=True)
self.features = nn.Sequential(*list(self.resnet.children())[:-1]) # 去掉最后一层全连接层
def forward(self, x):
x = self.features(x)
x = x.squeeze(-1).squeeze(-1) # 将二维特征图转换为一维特征向量
return x
# 文本特征提取模块
class TextFeatureExtractor(nn.Module):
def __init__(self, bert_model_name='bert-base-uncased'):
super(TextFeatureExtractor, self).__init__()
self.config = BertConfig.from_pretrained(bert_model_name)
self.bert = BertModel.from_pretrained(bert_model_name, config=self.config)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
return outputs.last_hidden_state
# 多模态融合模块
class MultimodalFusion(nn.Module):
def __init__(self, image_feature_dim, text_feature_dim, fusion_dim):
super(MultimodalFusion, self).__init__()
self.image_fc = nn.Linear(image_feature_dim, fusion_dim)
self.text_fc = nn.Linear(text_feature_dim, fusion_dim)
self.activation = nn.ReLU()
def forward(self, image_features, text_features):
image_features = self.image_fc(image_features)
text_features = self.text_fc(text_features)
fused_features = image_features + text_features # 简单的加法融合,也可以尝试其他融合方式
fused_features = self.activation(fused_features)
return fused_features
# 完整的多模态预训练模型
class DeepSeekMultimodalModel(nn.Module):
def __init__(self, bert_model_name='bert-base-uncased'):
super(DeepSeekMultimodalModel, self).__init__()
self.image_extractor = ImageFeatureExtractor()
self.text_extractor = TextFeatureExtractor(bert_model_name)
self.fusion = MultimodalFusion(image_feature_dim=2048, text_feature_dim=768, fusion_dim=768)
self.classifier = nn.Linear(768, 2) # 假设为二分类任务
def forward(self, images, input_ids, attention_mask):
image_features = self.image_extractor(images)
text_features = self.text_extractor(input_ids, attention_mask)
text_features = text_features[:, 0, :] # 取[CLS] token的特征作为文本的整体特征
fused_features = self.fusion(image_features, text_features)
logits = self.classifier(fused_features)
return logits(三)预训练阶段实现
第一阶段:基础特征预训练
# 图像特征预训练(以图像分类为例)
model = ImageFeatureExtractor()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 假设已经加载好图像数据和对应的分类标签
for epoch in range(num_epochs):
for images, labels in image_dataloader:
images = images.to(device)
labels = labels.to(device)
features = model(images)
logits = classifier(features) # classifier是一个简单的全连接分类层
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 文本特征预训练(以Masked Language Model为例)
model = TextFeatureExtractor()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 假设已经加载好文本数据,并进行了Mask处理
for epoch in range(num_epochs):
for batch in text_dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()- 第二阶段:跨模态关联预训练
# 跨模态关联预训练(以图像-文本匹配为例)
model = DeepSeekMultimodalModel()
criterion = nn.CosineEmbeddingLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 假设已经加载好图像和对应的文本数据,并生成了匹配和不匹配的样本对
for epoch in range(num_epochs):
for images, pos_texts, neg_texts in multimodal_dataloader:
images = images.to(device)
pos_input_ids = pos_texts['input_ids'].to(device)
pos_attention_mask = pos_texts['attention_mask'].to(device)
neg_input_ids = neg_texts['input_ids'].to(device)
neg_attention_mask = neg_texts['attention_mask'].to(device)
# 计算匹配对的特征
pos_text_features = model.text_extractor(pos_input_ids, pos_attention_mask)
pos_text_features = pos_text_features[:, 0, :]
image_features = model.image_extractor(images)
pos_similarity = torch.cosine_similarity(image_features, pos_text_features)
# 计算不匹配对的特征
neg_text_features = model.text_extractor(neg_input_ids, neg_attention_mask)
neg_text_features = neg_text_features[:, 0, :]
neg_similarity = torch.cosine_similarity(image_features, neg_text_features)
# 定义目标,匹配对的相似度应大于不匹配对
targets = torch.ones(images.size(0), dtype=torch.long).to(device)
loss = criterion(pos_similarity, neg_similarity, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()- 第三阶段:多模态情感分析微调
# 多模态情感分析微调
model = DeepSeekMultimodalModel()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
# 假设已经加载好包含图像、文本和情感标签的数据
for epoch in range(num_epochs):
for images, input_ids, attention_mask, labels in sentiment_dataloader:
images = images.to(device)
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
labels = labels.to(device)
logits = model(images, input_ids, attention_mask)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()(四)模型评估与应用
在完成多阶段预训练和微调后,对模型进行评估和实际应用。
- 模型评估
# 在测试集上评估模型性能
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, input_ids, attention_mask, labels in test_dataloader:
images = images.to(device)
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
labels = labels.to(device)
logits = model(images, input_ids, attention_mask)
_, predicted = torch.max(logits, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
print(f'Test Accuracy: {accuracy:.4f}')- 实际应用 将训练好的模型部署到实际的应用场景中,如社交媒体情感分析、广告效果评估等。当用户输入图像和文本时,平台调用DeepSeek多模态模型,对内容进行情感分析,并返回分析结果。
# 保存模型
torch.save(model.state_dict(), 'deepseek_multimodal_sentiment_analysis.pth')
# 加载模型
model = DeepSeekMultimodalModel()
model.load_state_dict(torch.load('deepseek_multimodal_sentiment_analysis.pth'))
model.eval()
# 应用示例
def analyze_multimodal_sentiment(image_path, text):
# 加载和预处理图像
image = load_and_preprocess_image(image_path)
image_tensor = torch.tensor(image, dtype=torch.float32).unsqueeze(0).to(device)
# 预处理文本
text_inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
input_ids = text_inputs['input_ids'].to(device)
attention_mask = text_inputs['attention_mask'].to(device)
# 情感分析
logits = model(image_tensor, input_ids, attention_mask)
probabilities = torch.softmax(logits, dim=1)
predicted_class = torch.argmax(probabilities).item()
return predicted_class, probabilities.cpu().numpy()[0]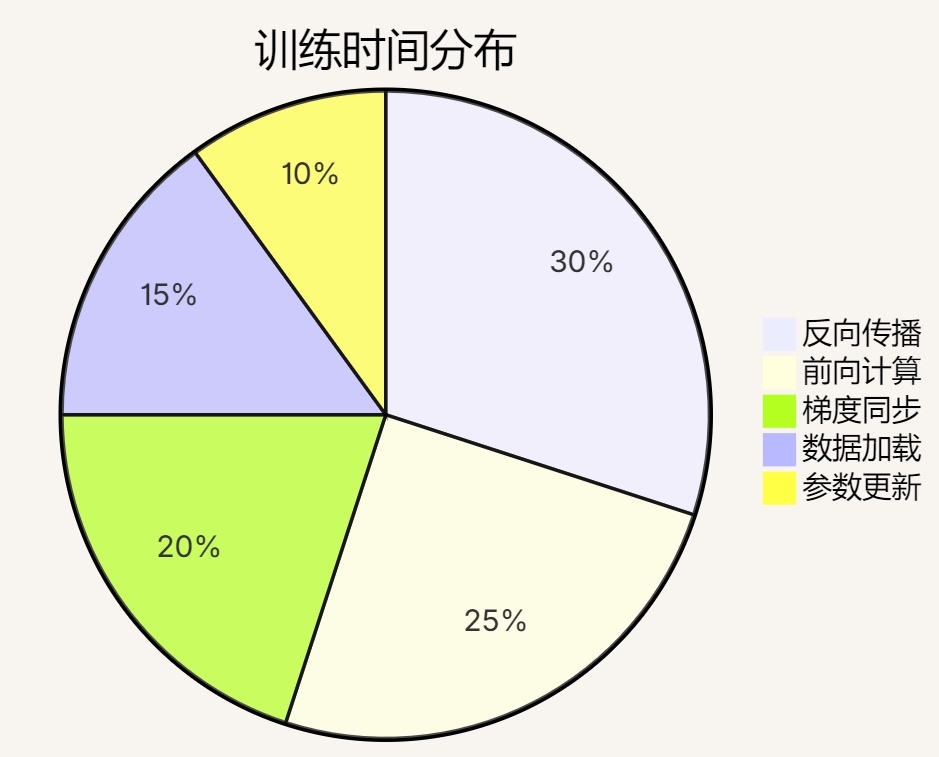
Ⅶ.结论
预训练范式从早期的无监督预训练到如今的多阶段预训练,经历了多次重要的演进。DeepSeek等系统通过分阶段训练策略、数据选择与动态更新、自监督与对比学习结合、模型架构优化等多方面的创新技巧,实现了在多模态等复杂任务中的卓越性能。
参考文章:
1 Liu Y, Ott M, Goyal N, et al. Roberta: A robustly optimized bert pretraining approachJ. arXiv preprint arXiv:1907.11692, 2019.
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
