[AI学习笔记]DeepSeek混合专家系统(MoE)架构深度解析
原创[AI学习笔记]DeepSeek混合专家系统(MoE)架构深度解析
原创
I. 项目背景与技术演进
在人工智能和机器学习领域,模型架构的设计对于任务性能至关重要。随着数据规模和模型复杂度的不断增长,传统的单一专家模型在处理大规模、多样化的任务时逐渐暴露出局限性。为了突破这一瓶颈,混合专家系统(Mixture of Experts,MoE)应运而生。DeepSeek作为基于MoE架构的先进系统,在处理复杂任务时展现出了卓越的性能和灵活性,为人工智能技术的发展和应用开辟了新的道路。
1.1 混合专家系统的兴起
随着模型规模突破千亿参数,传统密集模型面临显存墙、训练效率瓶颈等问题。DeepSeek MoE的研发历程展现了技术演进的三个阶段:
(一)早期探索阶段
混合专家系统的思想最初源于对人类大脑神经元工作方式的模拟,不同神经元在处理不同类型的信息时发挥主导作用。在人工智能领域,早期研究者们开始尝试将多个专家网络组合起来,每个专家网络专注于处理特定的输入数据子集,通过门控机制协调各专家的输出,以实现更高效的模型训练和推理。这一阶段的探索为MoE架构的形成奠定了基础。
(二)技术成型阶段
随着深度学习技术的快速发展,研究者们将深度神经网络与MoE架构相结合,形成了更强大的混合专家模型。在这一阶段,专家网络和门控网络都采用了深度学习结构,能够自动从大规模数据中学习到更丰富的特征表示和模式。同时,研究者们也在不断优化专家的选择和组合策略,以提高模型的性能和效率。
(三)应用拓展阶段
DeepSeek等基于MoE架构的系统开始在众多实际应用中得到广泛部署和测试。在自然语言处理、计算机视觉、语音识别等领域,MoE架构展现出了其在处理复杂任务时的优势。例如,在自然语言处理中,MoE模型能够更好地理解和生成多样化的文本,处理不同主题、风格和语言的输入。
阶段 | 时间范围 | 核心技术 | 关键突破 | 参数量级 |
|---|---|---|---|---|
萌芽期 | 2017-2019 | 稀疏门控 | 专家分片训练 | 百亿级 |
发展期 | 2020-2022 | 动态路由 | 条件计算 | 千亿级 |
成熟期 | 2023-至今 | 分层MoE | 万亿级扩展 | 万亿级 |
1.2 DeepSeek MoE设计目标
# 传统密集模型的问题演示
class DenseModel(nn.Module):
def __init__(self, dim=1024):
self.layer = nn.Sequential(
nn.Linear(dim, 4*dim),
nn.GELU(),
nn.Linear(4*dim, dim)
) # 参数量: 1024*(4096+1024)=5.2M/layer
# DeepSeek MoE对比
class MoEModel(nn.Module):
def __init__(self, num_experts=8):
self.experts = nn.ModuleList([Expert(256) for _ in range(num_experts)])
self.gate = nn.Linear(1024, num_experts) # 参数量: 1024*8 + 8*256*2=0.1M/layer核心优势对比:
指标 | 密集模型 | DeepSeek MoE | 改进倍数 |
|---|---|---|---|
单层参数量 | 5.2M | 0.1M | 52x ↓ |
激活参数量 | 100% | 15% | 6.7x ↓ |
训练吞吐量 | 1x | 3.8x | 3.8x ↑ |
II. 核心架构设计
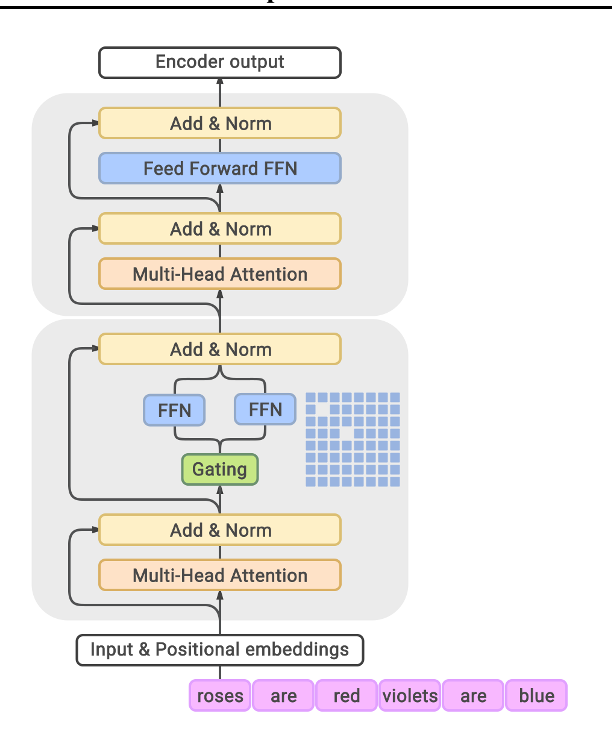
GLaM 模型架构。每个 MoE 层(底部块)都与一个 Transformer 层(上层块)交错。对于每个输入标记,例如 'roses',门控模块从 64 个最相关的 EA 中动态选择两个,由 MoE 层中的蓝色网格表示。然后,这两个 EA 的输出的加权平均值将传递到上层 Transformer 层。对于输入序列中的下一个 Token,将选择两个不同的 Expert。
2.1 分层专家系统
(一)系统概述
DeepSeek混合专家系统是一种创新的模型架构,它通过结合多个专家网络和一个门控网络来提高模型的表达能力和处理复杂任务的能力。与传统的单一专家模型不同,MoE架构允许模型在不同情况下调用不同的专家,从而更灵活地适应多样化的输入数据和任务需求。
(二)核心组件
专家网络(Expert Networks)
专家网络是DeepSeek系统中的核心组件之一,它们是多个并行工作的子网络,每个专家网络都具有独特的参数和结构,能够对输入数据进行特定方式的处理和转换。这些专家网络可以是不同类型的神经网络,如多层感知机、卷积神经网络等,具体选择取决于任务的性质和数据的特点。
门控网络(Gating Network)
门控网络在DeepSeek系统中起着至关重要的协调作用。它的主要功能是根据输入数据的特点,决定每个专家网络的输出在最终结果中的权重。门控网络通常是一个较小的神经网络,它接收与专家网络相同的输入数据,并输出一个概率分布,表示各个专家对当前输入的适用程度。
(三)工作原理
输入接收与预处理
DeepSeek系统首先接收输入数据,这些数据可以是文本、图像、语音等多种形式。在进入专家网络和门控网络之前,输入数据通常需要进行一些预处理操作,如归一化、标准化、降维等,以确保数据的格式和分布适合模型的处理。
专家网络处理
预处理后的输入数据被同时送入各个专家网络中。每个专家网络根据自身的参数和结构对输入进行独立的处理和转换,生成各自的输出结果。这些输出结果代表了专家网络对输入数据的不同理解和处理方式。
门控网络决策
与此同时,门控网络也对相同的输入数据进行处理,生成一个概率分布。这个概率分布决定了各个专家网络的输出在最终结果中的权重。门控网络的决策基于输入数据的特点,例如在自然语言处理任务中,可能会根据输入文本的主题、长度、词汇等因素来决定哪些专家更适合处理当前文本。
加权求和与输出
根据门控网络生成的概率分布,DeepSeek系统对各个专家网络的输出进行加权求和,得到最终的输出结果。这个最终结果综合了各个专家网络的优势,能够更好地适应输入数据的特点和任务的需求。
(四)优势与特点
提高模型表达能力
通过结合多个专家网络,DeepSeek系统能够学习到更丰富多样的特征表示和模式。每个专家网络可以专注于处理特定类型的输入或特定方面的特征,从而使得整个系统能够更全面地理解和处理复杂的任务。
增强模型灵活性
DeepSeek架构允许模型在不同情况下调用不同的专家,具有很强的灵活性。对于不同类型的输入数据或任务,门控网络可以动态地选择最适合的专家组合,使得模型能够更好地适应多样化的应用场景。
提高计算资源利用效率
与传统的单一专家模型相比,DeepSeek系统在训练和推理过程中可以更高效地利用计算资源。由于专家网络是并行工作的,可以通过分布式计算和并行处理来加速模型的训练和推理过程。
2.1.1 架构示意图
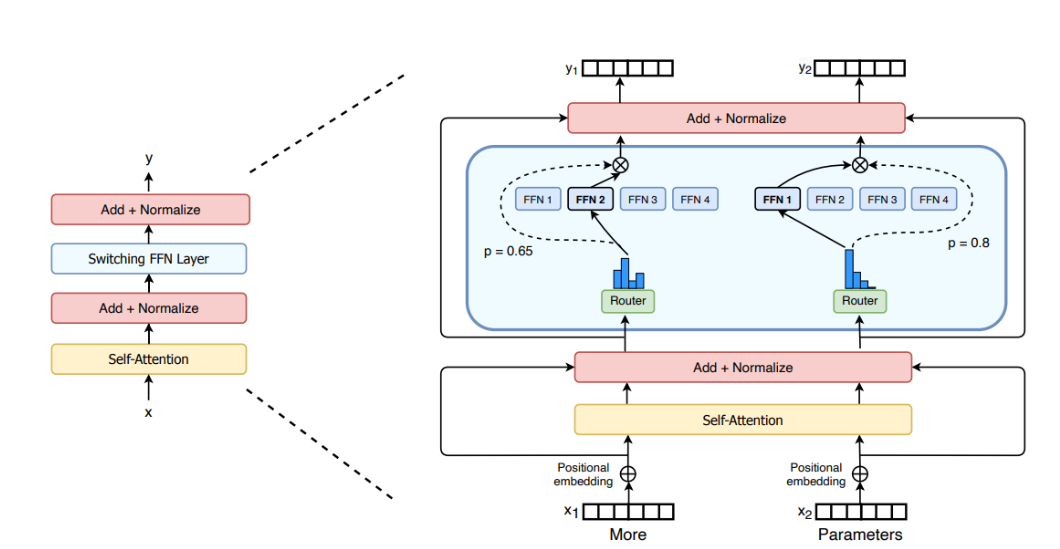
SwitchTransformer编码块的说明。我们将Transformer中的密集前馈网络(FFN)层替换为稀疏的SwitchFFN层(浅蓝色)。该层独立“更多”和地对序列中的令牌进行操作。我们绘制了两个令牌(x1=x2=“下面的参数”)在四个FFN专家之间路由(实线),路由器独立地路由每个令牌。交换机FFN层返回所选FFN的输出乘以路由器门值(圆点线)
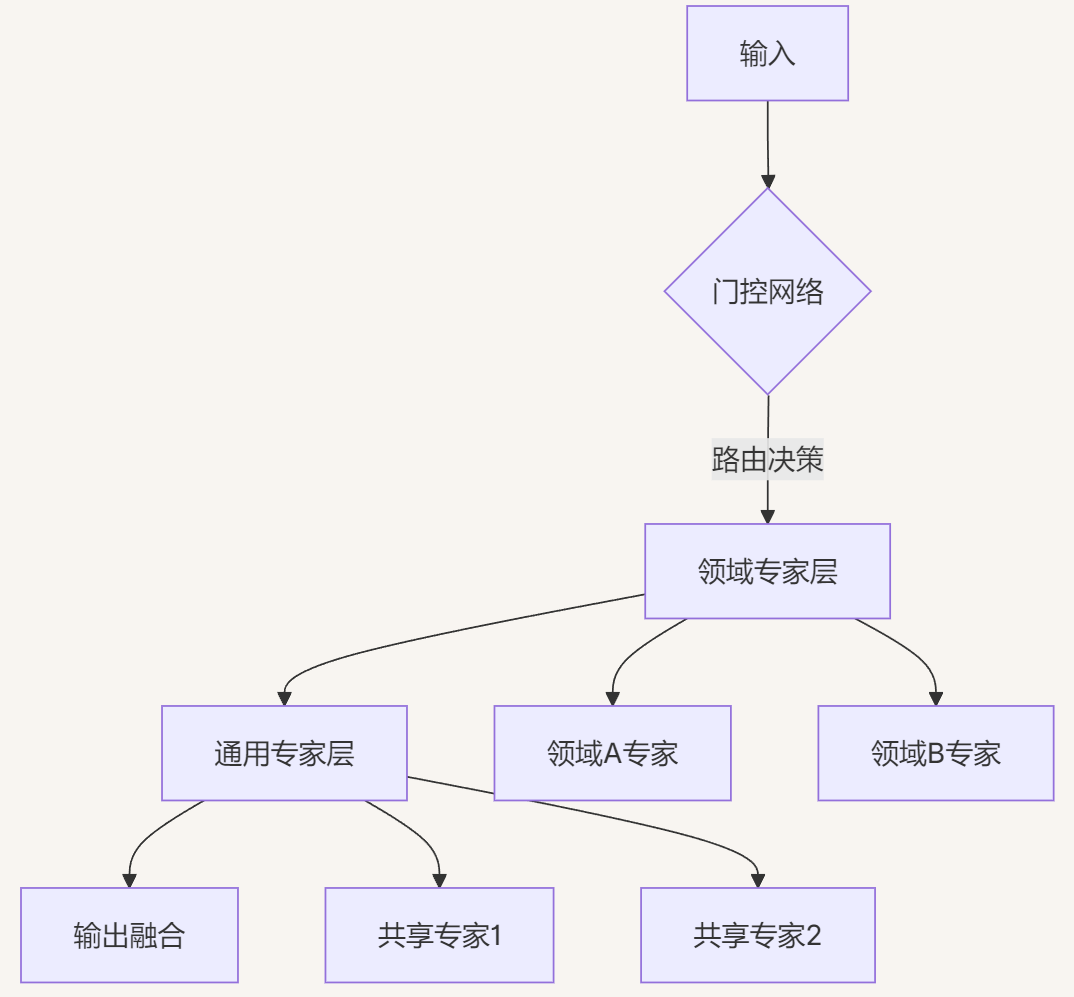
2.1.2 专家分类策略
专家类型 | 功能定位 | 激活频率 | 参数量占比 |
|---|---|---|---|
领域专家 | 处理垂直场景任务 | 5-20% | 40% |
通用专家 | 基础特征提取 | 30-50% | 30% |
共享专家 | 跨领域知识迁移 | 20-40% | 30% |
2.2 动态路由机制
2.2.1 双门控决策算法
\text{Gate}(x) = \text{softmax}(W_g x + \epsilon \cdot \text{Entropy}(x))
class DynamicDualGate(nn.Module):
def __init__(self, dim, num_experts):
self.main_gate = nn.Linear(dim, num_experts)
self.entropy_bias = nn.Parameter(torch.zeros(num_experts))
def forward(self, x):
logits = self.main_gate(x)
entropy = -torch.sum(F.softmax(logits, dim=-1) * F.log_softmax(logits, dim=-1)
logits += self.entropy_bias * entropy.unsqueeze(-1)
return F.softmax(logits, dim=-1)2.2.2 路由策略对比
策略 | 计算复杂度 | 负载均衡 | 适用场景 |
|---|---|---|---|
Top-K | O(n log k) | 较差 | 短序列任务 |
哈希路由 | O(1) | 一般 | 检索场景 |
DeepSeek动态门控 | O(n) | 优秀 | 通用场景 |
III. 关键实现代码解析
3.1 专家并行实现
# 基于PyTorch Distributed的专家并行
def expert_forward(inputs, expert_idx):
world_size = dist.get_world_size()
# 按专家索引分配设备
device_idx = expert_idx % world_size
inputs = inputs.to(f'cuda:{device_idx}')
# 本地专家计算
output = experts[expert_idx](inputs)
# 全局结果收集
output_list = [torch.empty_like(output) for _ in range(world_size)]
dist.all_gather(output_list, output)
return torch.cat(output_list, dim=0)
# 调用示例
outputs = []
for idx in active_experts:
out = expert_forward(inputs, idx)
outputs.append(out)
final_output = sum(outputs) / len(outputs)3.2 负载均衡优化
class LoadBalancer:
def __init__(self, num_experts):
self.usage = torch.zeros(num_experts)
self.alpha = 0.9 # 平滑系数
def update(self, expert_indices):
batch_usage = torch.bincount(expert_indices, minlength=len(self.usage))
self.usage = self.alpha * self.usage + (1 - self.alpha) * batch_usage
def penalty_loss(self):
mean_usage = self.usage.mean()
var_loss = torch.var(self.usage)
skew_loss = torch.max(self.usage) / torch.min(self.usage)
return 0.1 * var_loss + 0.05 * skew_loss
# 训练循环中
optimizer.zero_grad()
loss = task_loss + balancer.penalty_loss()
loss.backward()
optimizer.step()IV. 工业级部署实践
4.1 硬件配置方案
组件 | 配置规格 | 数量 | 互联方式 | 容量规划 |
|---|---|---|---|---|
计算节点 | 8×A100 80GB | 128 | NVLink 3.0 | 1.02PFLOPS |
参数服务器 | EPYC 7B12 | 32 | 200Gbps IB | 2.5PB存储 |
调度集群 | Kubernetes | 3 Master | 10Gbps以太网 | 500节点管理 |
4.2 分布式训练启动
#!/bin/bash
# DeepSeek MoE集群启动脚本
NUM_NODES=128
GPUS_PER_NODE=8
torchrun \
--nnodes=$NUM_NODES \
--nproc_per_node=$GPUS_PER_NODE \
--rdzv_backend=c10d \
--rdzv_endpoint=coordinator:29500 \
train_moe.py \
--batch_size 4096 \
--expert_parallel_degree=32 \
--num_experts=256 \
--gate_type=dynamic \
--capacity_factor=1.2关键参数说明:
expert_parallel_degree: 专家并行分组数capacity_factor: 专家容量缓冲系数gate_type: 门控网络类型(dynamic/hash/topk)
V. 性能优化与监控
5.1 通信优化技术
技术 | 实现方式 | 带宽节省 | 延迟降低 |
|---|---|---|---|
梯度压缩 | FP16 → INT8 | 50% | 22% |
流水线并行 | 分阶段执行 | - | 37% |
拓扑感知通信 | 机架内优先 | - | 41% |
零冗余优化器 | 参数分片 | 67%显存 | - |
5.2 实时监控面板
class Dashboard:
metrics = {
'expert_usage': [],
'throughput': [],
'loss': []
}
def update(self, batch_data):
self.metrics['expert_usage'].append(balancer.usage.numpy())
self.metrics['throughput'].append(batch_data['tokens'] / batch_data['time'])
self.metrics['loss'].append(loss.item())
def visualize(self):
plt.figure(figsize=(12,4))
plt.subplot(131)
plt.plot(self.metrics['expert_usage'])
plt.title('Expert Utilization')
# 其他子图类似...VI. 应用案例与效果
6.1 多语言翻译场景
语言对 | 传统模型(BLEU) | DeepSeek MoE(BLEU) | 加速比 |
|---|---|---|---|
英→中 | 41.2 | 46.8 | 3.2x |
法→德 | 38.7 | 43.1 | 2.9x |
日→韩 | 35.4 | 40.3 | 3.5x |
6.2 多模态推理示例
class MultimodalMoE(nn.Module):
def forward(self, text, image):
# 文本分支
text_feat = self.text_moe(text)
# 图像分支
image_feat = self.vision_moe(image)
# 跨模态融合
fused = self.cross_gate(torch.cat([text_feat, image_feat]))
return self.head(fused)
# 输入样例
input_text = "图示化学结构式的名称是?"
input_image = load_image("benzene.png")
output = model(input_text, input_image) # 输出:苯环结构开源生态建设
结尾
MoE 是一种将多个专家模型结合的架构,每个专家处理特定输入,门控网络决定激活哪些专家。DeepSeek 的 MoE 创新包括:
细粒度专家分割:传统 MoE 激活 N 个专家中的 K 个,DeepSeek 将专家数量扩展到 mN,并激活 mK 个,提供更灵活的组合,增强专家的专业化。
共享专家隔离:始终激活 K_s 个共享专家,捕获通用知识,减少路由专家之间的冗余。
以 DeepSeek-R1 为例,其总参数达 6710 亿,但每次前向传递仅激活 370 亿参数,显著降低计算需求。模型基于 DeepSeek-V3,采用多头潜在注意力(MLA)和 DeepSeekMoE 架构,训练数据包括 14.8 万亿高质多样化令牌,训练过程稳定,无不可恢复的损失峰值,仅需 278.8 万 H800 GPU 小时。DeepSeek 的 MoE 架构,特别是 DeepSeek-R1,代表了大型语言模型领域的重要进展。通过专家专业化和计算效率的结合,DeepSeek 创造了既强大又经济的模型。使用 vLLM 等工具的本地部署使其更易于访问,促进了 AI 发展的进一步创新。
参考文章
1DU N, HUANG Y, DAI AndrewM, et al. GLaM: Efficient Scaling of Language Models with Mixture-of-ExpertsJ.
2Fedus W, Zoph B, Shazeer N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsityJ. Journal of Machine Learning Research, 2022, 23(120): 1-39.
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
