从数据到行动:如何利用智能体模型进行自动化决策
原创从数据到行动:如何利用智能体模型进行自动化决策
原创
从数据到行动:如何利用智能体模型进行自动化决策
在现代人工智能(AI)的应用中,智能体模型(Agent-based Model, ABM)作为一种重要的工具,已广泛应用于各个领域,如自动化决策、智能推荐、金融分析等。智能体模型的核心思想是模拟具有自主决策能力的智能体(agent),通过与环境的交互来完成特定任务,从而实现自动化决策。在本文中,我们将深入探讨智能体模型如何从数据中获取信息,并将其转化为可执行的行动。
什么是智能体模型?
1.1 智能体模型的定义
智能体模型(ABM)是一个仿真框架,其中“智能体”指的是能够感知其环境并在此基础上做出决策的实体。智能体根据自身的状态、目标、以及对环境的感知信息进行推理、规划,并最终做出决策,从而影响环境并实现其目标。智能体可以是物理实体(如机器人),也可以是虚拟实体(如软件代理)。
1.2 智能体模型的基本构成
智能体模型的基本构成包括以下几个元素:
- 感知:智能体获取环境信息。
- 决策:基于感知到的信息,智能体评估可能的行动,并选择最优策略。
- 执行:智能体采取行动,影响环境或与其他智能体交互。
- 反馈:智能体根据执行的结果调整其决策策略,形成闭环。
智能体模型在自动化决策中的应用
2.1 自动化决策的核心问题
自动化决策系统的目标是通过算法和模型,替代或辅助人类进行决策,尤其是在复杂且动态的环境中。决策系统通常涉及以下问题:
- 数据采集:获取环境状态以及智能体自身的状态。
- 模型训练:基于历史数据和反馈调整智能体的决策模型。
- 实时决策:根据当前环境状态,选择最优决策。
2.2 智能体模型的决策过程
智能体模型的决策过程可以分为几个关键步骤:
- 感知环境:智能体感知当前环境的信息。
- 评估行动:根据感知的信息评估可能的行动。
- 选择策略:选择最优策略进行执行。
- 执行和反馈:执行决策并根据反馈调整策略。
通过不断与环境互动,智能体逐渐学习到最佳的决策策略,实现自动化决策。

代码实现:基于Q-learning的自动化决策
在本节中,我们将通过一个基于Q-learning(强化学习)算法的智能体模型来演示如何实现自动化决策。Q-learning是一个无模型的强化学习算法,广泛应用于强化学习任务中。其核心思想是通过与环境的交互,不断更新Q值(状态-动作价值函数),从而找到最优的决策策略。
3.1 环境设定
我们将创建一个简单的环境,其中智能体需要在一个网格世界中找到目标点。智能体可以在四个方向上移动:上、下、左、右。每个动作会带来不同的奖励,智能体的目标是最大化累积奖励。
import numpy as np
import random
# 定义网格世界环境
class GridWorld:
def __init__(self, size=(5, 5), goal=(4, 4)):
self.size = size # 环境大小
self.goal = goal # 目标位置
self.agent_pos = (0, 0) # 智能体初始位置
def reset(self):
"""重置环境,智能体回到起始位置"""
self.agent_pos = (0, 0)
return self.agent_pos
def step(self, action):
"""执行一个动作,并返回新的状态、奖励和是否完成"""
x, y = self.agent_pos
if action == 0: # 上
x = max(0, x - 1)
elif action == 1: # 下
x = min(self.size[0] - 1, x + 1)
elif action == 2: # 左
y = max(0, y - 1)
elif action == 3: # 右
y = min(self.size[1] - 1, y + 1)
self.agent_pos = (x, y)
# 判断是否到达目标
if self.agent_pos == self.goal:
return self.agent_pos, 100, True # 到达目标,奖励100
else:
return self.agent_pos, -1, False # 每步惩罚-1
def get_state(self):
return self.agent_pos
def get_possible_actions(self):
return [0, 1, 2, 3] # 上、下、左、右3.2 Q-learning 算法实现
接下来,我们将实现Q-learning算法来训练智能体从数据中学习决策策略。
class QLearningAgent:
def __init__(self, environment, alpha=0.1, gamma=0.9, epsilon=0.2):
self.env = environment
self.alpha = alpha # 学习率
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # 探索率
self.q_table = {} # Q值表
def get_q_value(self, state, action):
"""获取Q值"""
if state not in self.q_table:
self.q_table[state] = np.zeros(4) # 初始化Q值为0
return self.q_table[state][action]
def update_q_value(self, state, action, reward, next_state):
"""更新Q值"""
future_q = np.max(self.q_table.get(next_state, np.zeros(4)))
current_q = self.get_q_value(state, action)
self.q_table[state][action] = current_q + self.alpha * (reward + self.gamma * future_q - current_q)
def choose_action(self, state):
"""选择一个动作(ε-贪婪策略)"""
if random.uniform(0, 1) < self.epsilon:
return random.choice(self.env.get_possible_actions()) # 随机探索
else:
return np.argmax(self.q_table.get(state, np.zeros(4))) # 利用已有知识
def train(self, episodes=1000):
for episode in range(episodes):
state = self.env.reset()
done = False
while not done:
action = self.choose_action(state)
next_state, reward, done = self.env.step(action)
self.update_q_value(state, action, reward, next_state)
state = next_state
# 创建环境和智能体
env = GridWorld()
agent = QLearningAgent(env)
# 训练智能体
agent.train()
# 打印最终的Q值表
print("训练后的Q值表:")
for state, q_values in agent.q_table.items():
print(f"状态 {state}: {q_values}")3.3 代码解析
- GridWorld 环境:我们设计了一个简单的5x5网格世界,其中智能体需要从起点(0, 0)移动到目标点(4, 4)。每移动一步,智能体会得到一个惩罚,直到到达目标为止。
- QLearningAgent 智能体:这个类实现了Q-learning算法,智能体通过与环境交互,不断更新Q值,并学习如何在每个状态下选择最优动作。
- 训练过程:在每一轮训练中,智能体会通过探索(随机选择)和利用(选择当前Q值最高的动作)来学习最优策略。
智能体模型的优势与挑战
4.1 优势
- 适应性强:智能体能够根据环境变化调整决策策略,实现高度灵活的自动化决策。
- 数据驱动:智能体通过与环境的交互,不断学习和优化策略,从而实现数据驱动的自动化决策。
- 可扩展性:智能体模型可以应用于多种不同的领域,如交通调度、金融分析、供应链管理等。
4.2 挑战
- 数据依赖:智能体的决策质量依赖于数据的质量和多样性。在数据不足或质量差的情况下,智能体的决策可能会受到影响。
- 计算复杂性:智能体需要不断与环境互动,这会导致计算成本的增加。特别是在高维环境中,Q-learning等算法的训练时间和资源需求可能很大。
智能体模型的优势与挑战
4.1 优势
- 适应性强:智能体模型的最大优势之一在于其适应性。智能体能够根据环境的变化自动调整其决策策略,适应不同的任务和环境。无论是在面对动态变化的市场环境,还是在多变的生产调度问题中,智能体模型都能够通过实时反馈进行自我优化。这种特性使得智能体在自动化决策领域中,尤其是实时决策和应急响应场景中,表现出色。
- 数据驱动决策:智能体的决策完全基于与环境的交互数据。通过大规模的数据输入,智能体不仅能有效识别环境中的模式,还能对未来的情境做出准确预测。因此,智能体可以在大量数据的驱动下,做出精确的决策,并逐步提高其决策的质量和效率。
- 可扩展性与灵活性:智能体模型在理论上能够应用于任何环境和任务,并且可以在多种应用场景中进行调整和扩展。通过适当的设计,智能体模型可以非常容易地适应不同规模、不同复杂度的系统,处理更大范围的问题,如智能交通管理、智能家居系统、机器人控制等。
- 增强自主性:智能体的决策过程不依赖于外部的指令或干预,而是自主地根据当前的环境状态做出行动决策。这种自主性使得智能体在自动化场景中,能够高效执行任务,减少人工干预,提高工作效率。
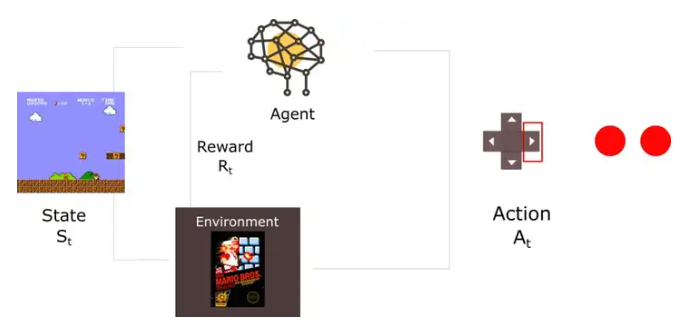
4.2 挑战
- 数据依赖性:智能体模型的决策能力依赖于高质量和高多样性的训练数据。如果数据存在噪声、不完整或偏差,智能体的决策质量将大打折扣。尤其在复杂的、动态变化的环境中,如何保证数据的准确性和全面性,成为智能体系统应用的一大挑战。
- 探索与利用的平衡:Q-learning等强化学习算法的核心是“探索”与“利用”的平衡。探索意味着智能体要尝试不同的行动,发现潜在的最优策略;而利用则是选择已知的最优行动。这一平衡的选择对决策过程至关重要。在初期,智能体可能会花费较多的时间来探索新的策略,导致决策效率低下。而在后期,过于依赖已知策略也可能导致智能体错过潜在的更优决策。
- 计算复杂性:在复杂的环境中,智能体的状态空间和动作空间通常非常庞大,导致Q-learning等强化学习算法的计算需求极高。尤其是当环境的维度增加时,状态-动作对的数量呈指数级增长,训练过程中所需的时间和计算资源也大幅度增加。因此,在高维环境中,如何提高计算效率、降低资源消耗,是智能体应用中的一大挑战。
- 长期策略的优化:对于大多数自动化决策任务,智能体不仅需要在当前状态下做出合理的决策,还需要优化长期回报。传统的强化学习算法,如Q-learning,依赖于历史经验来调整策略,但在某些复杂的决策任务中,智能体可能需要面对大量的历史信息和长时间的决策过程。这就要求智能体能够从长远的角度做出优化决策,而不是仅仅关注短期奖励。
智能体模型的实际应用
智能体模型在多个领域中已成功应用,并且随着技术的发展,其应用场景还在不断扩展。
5.1 自动驾驶与智能交通
在自动驾驶领域,智能体模型可以帮助汽车在不同的交通状况下做出实时决策。例如,智能体可以根据交通信号、周围车辆的行为、道路状况等信息,自动决策是否加速、刹车或变道,从而实现安全的自动驾驶。
# 自动驾驶环境简化版示例
class DrivingEnvironment:
def __init__(self):
self.state = 'idle' # 当前状态
self.traffic_signal = 'green' # 交通信号
self.other_vehicles = {'left': 'stop', 'right': 'go'} # 其他车辆的状态
def get_state(self):
return self.state, self.traffic_signal, self.other_vehicles
def step(self, action):
"""自动驾驶智能体根据动作选择驾驶行为"""
if action == 'accelerate':
self.state = 'moving'
elif action == 'brake':
self.state = 'stopped'
return self.state, self.evaluate_action(action)
def evaluate_action(self, action):
"""根据智能体的动作评估其合理性"""
if self.state == 'moving' and self.traffic_signal == 'red':
return -10 # 红灯时加速会被惩罚
elif self.state == 'stopped' and self.traffic_signal == 'green':
return 10 # 绿灯时停车加速是奖励
return 0 # 其他情况下无奖励或惩罚5.2 金融市场预测
在金融市场中,智能体可以通过不断分析市场数据,做出买入、卖出或持有的决策。金融智能体不仅可以在短期内响应市场波动,还能基于历史数据预测长期趋势,为投资者提供决策支持。
class FinancialAgent:
def __init__(self):
self.balance = 10000 # 初始资金
self.stock_price = 100 # 初始股价
self.action_history = [] # 动作历史
def get_state(self):
return self.balance, self.stock_price
def step(self, action):
"""模拟股票交易"""
if action == 'buy':
self.balance -= self.stock_price # 买入股票
elif action == 'sell':
self.balance += self.stock_price # 卖出股票
self.action_history.append(action)
reward = self.balance - 10000 # 简化的奖励函数,基于余额的变化
return self.get_state(), reward5.3 智能制造与供应链管理
在智能制造领域,智能体模型可用于自动化生产调度和供应链管理。智能体通过对生产线、库存、运输等多方面信息的感知,优化生产流程和资源分配,减少成本和时间浪费。
class SupplyChainAgent:
def __init__(self, initial_stock=100):
self.stock = initial_stock # 初始库存
self.demand = 50 # 需求量
self.production_rate = 10 # 每单位时间生产量
def get_state(self):
return self.stock, self.demand
def step(self, action):
"""根据生产决策调整库存"""
if action == 'produce':
self.stock += self.production_rate
elif action == 'sell':
self.stock -= self.demand
reward = max(0, self.stock - self.demand) # 库存越高,奖励越大
return self.get_state(), reward未来发展方向
6.1 强化学习与深度学习的结合
近年来,深度学习在许多领域取得了显著的成果,尤其在图像识别和自然语言处理领域。将深度学习与强化学习相结合,可以增强智能体的感知和决策能力。例如,深度Q网络(DQN)算法将深度神经网络应用于Q-learning,可以处理更复杂、更高维的环境。
6.2 多智能体协作
在复杂的环境中,多个智能体可能需要协同工作来完成任务。例如,在智能制造中,不同的生产线或机器人可能需要合作以最大化产量。通过多智能体系统(MAS),不同智能体之间可以通过通信和协调,优化整体的决策过程。
6.3 智能体的解释性与透明性
随着智能体在关键领域(如医疗、金融)的应用越来越广泛,其决策过程的透明性和可解释性变得尤为重要。未来的研究将致力于提高智能体模型的可解释性,使其决策过程对人类用户更加清晰,以便于监控和控制。
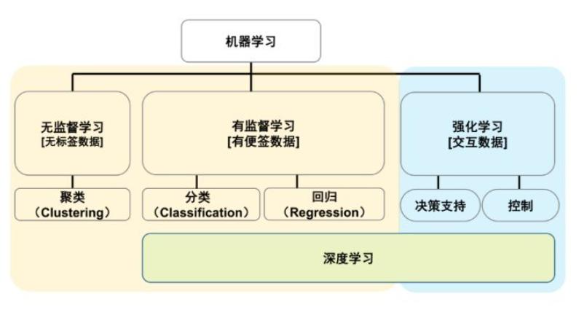
总结
智能体模型通过模拟环境中的互动,帮助实现自动化决策,广泛应用于自动驾驶、金融预测、智能制造等领域。其主要优势包括高度适应性、数据驱动决策、可扩展性以及增强的自主性。然而,智能体在实际应用中也面临着数据依赖性、探索与利用的平衡、计算复杂性和长期策略优化等挑战。随着深度学习与强化学习的结合、多智能体协作以及解释性增强技术的进展,智能体的应用前景将更加广泛,未来将进一步推动自动化决策的智能化与高效化。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
