向 AI Search 迈进,腾讯云 ES 自研 v-pack 向量增强插件揭秘!
原创向 AI Search 迈进,腾讯云 ES 自研 v-pack 向量增强插件揭秘!
原创
向 AI Search 迈进,腾讯云 ES 自研 v-pack 向量增强插件揭秘!
2025 年 1 月,腾讯云 ES 团队上线了 Elasticsearch 8.16.1 AI 搜索增强版,此发布版本重点提升了向量搜索、混合搜索的能力,为 RAG 类的 AI Search 场景保驾护航。除了紧跟 ES 官方在向量搜索上的大幅优化动作外,腾讯云 ES 还在此版本上默认内置了一个全新的插件 —— v-pack 插件。v-pack 名字里的"v"是 vector 的意思,旨在提供更加丰富、强大的向量、混合搜索能力。本文将对该版本 v-pack 插件所包含的功能做大体的介绍。
一、存储优化:突破向量搜索的存储瓶颈
1.1 行存裁剪:无损瘦身节省 70% 存储
技术原理
传统 Elasticsearch 默认将向量数据同时存储在行存_source(.fdt)和列存doc_value(.dvd/.vec)中,造成冗余。利用腾讯云 ES 贡献给社区的向量列存读取能力(PR #114484),在安装了 v-pack 插件的集群上,默认无损排除_source中的向量(dense_vector)字段,实现存储空间的高效利用。
技术亮点
- 动态开关:通过集群级参数
vpack.auto_exclude_dense_vector控制(默认开启) - 无损兼容:通过
docvalue_fields语法仍可获取原始向量值(用于业务开发调试、reindex 等操作)
实测效果
场景 | 原始存储 | 优化后存储 | 节省比例 |
|---|---|---|---|
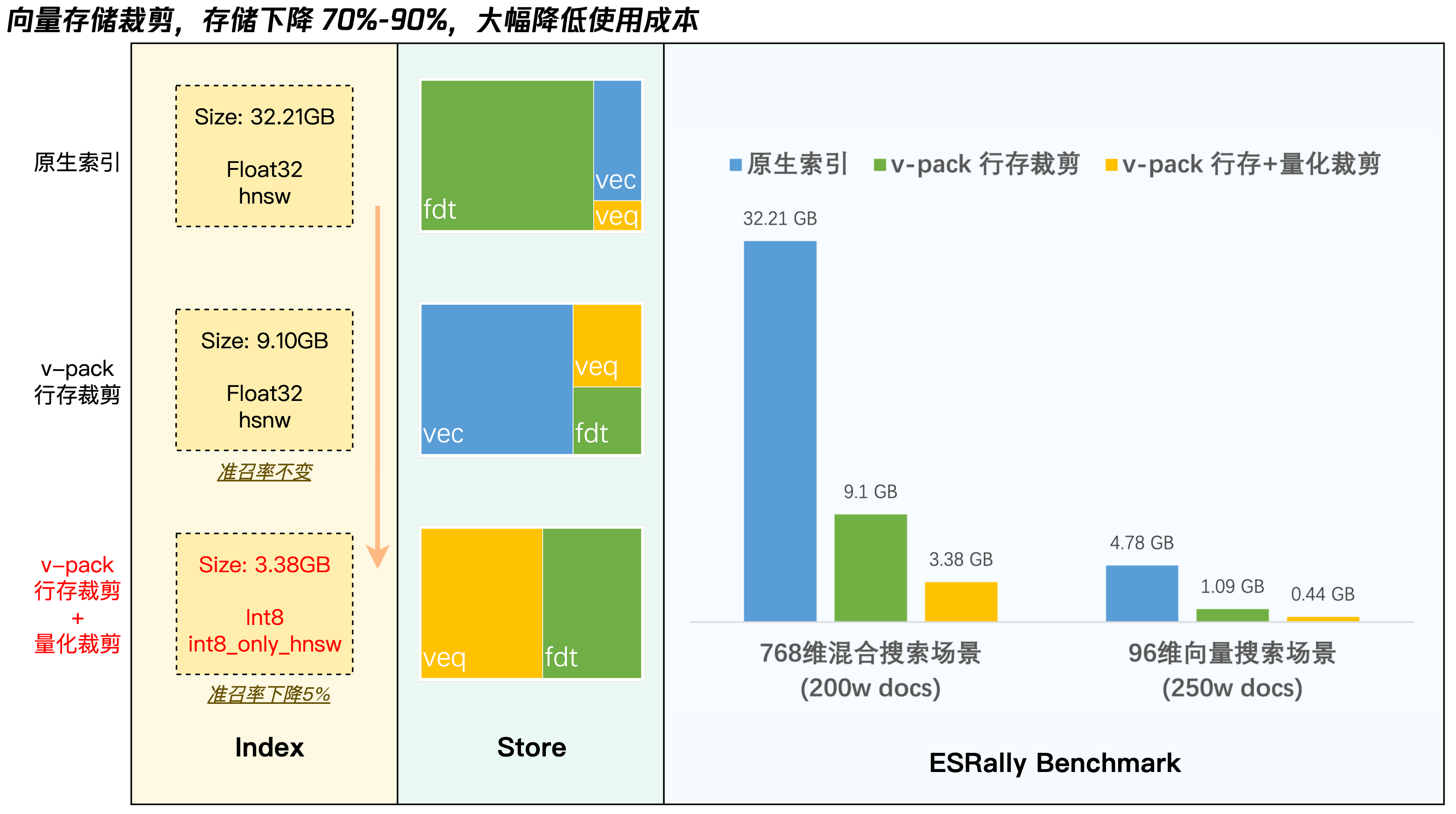
纯向量场景(250w条) | 4.78GB | 1.09GB | 77% |
混合场景(200w条) | 32.21GB | 9.10GB | 72% |
使用方法
无需手动启用,安装了 v-pack 插件的集群即生效。v-pack 会在创建新索引时,自动在索引 settings 中扩增 index.mapping.source.auto_exclude_types 参数来裁剪向量字段。
如需关闭,可关闭集群维度的供台开关,此后新创建的索引则不会做裁剪。
PUT _cluster/settings
{
"persistent": {
"vpack.auto_exclude_dense_vector": false
}
}场景建议
所有生产场景
1.2 量化裁剪:极致瘦身节省 90% 存储
技术原理
量化实际是将原始高位向量压缩成低位向量的一种算法,如果把量化比作“脱水”,那这类算法函数的逆运算,就可以实现反向“复水”得到原来的向量。当然由于低位不能完全表示高位,在精度上会有一定损失,但它带来的是磁盘存储的进一步下降,对于存储有强烈需求的客户仍然具有很高的实际意义。在上文行存裁剪的基础上,进一步节省存储到 90%。
技术亮点
在社区标量量化技术int8_hnsw基础上,首创int8_only_hnsw索引类型:
- “脱水”存储:仅保留量化后的 int8 向量(
.veq文件) - 动态“复水”:merge 时通过量化参数还原近似原始向量
实测效果
场景 | 原始存储 | 优化后存储 | 节省比例 |
|---|---|---|---|
纯向量场景(250w条) | 4.78GB | 0.44GB | 90% |
混合场景(200w条) | 32.21GB | 1.09GB | 91% |
技术对比
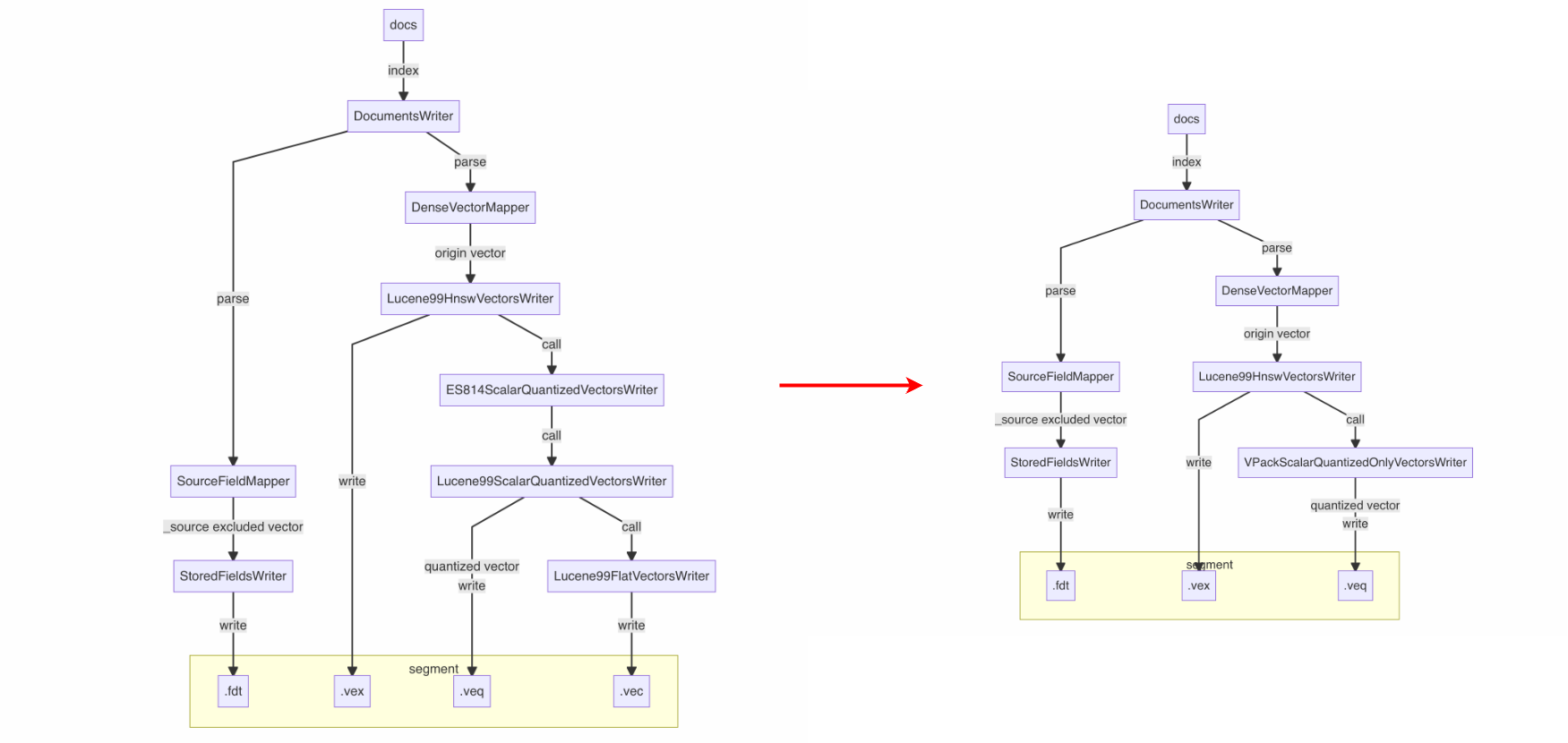
使用方法
在安装了 v-pack 插件的集群,创建索引时,将index_options.type设置为int8_only_hnsw索引类型
PUT product_vector_index
{
"mappings": {
"properties": {
"embedding": {
"type": "dense_vector",
"dims": 768,
"index_options": {
"type": "int8_only_hnsw",
"m": 32,
"ef_construction": 100
}
}
}
}
}场景建议
- 搜推系统:对存储敏感的场景
- RAG 应用:海量的知识库数据
1.3 小结
下图展示了 v-pack 的两种向量存储裁剪的效果。详细的技术方案解析详见:《ES8向量功能窥探系列(二):向量数据的存储与优化》
二、排序优化:多策略融合的灵活组合
2.1 权重可调 RRF 融合:
算法演进
在标准 RRF(Reciprocal Rank Fusion)公式中引入权重因子:
加权得分 = Σ( weight_i / (k + rank_i) )突破传统多路召回等权融合的限制,支持业务自定义权重策略。
混合排序示例
GET news/_search
{
"retriever": {
"rank_fusion": {
"retrievers": [
{
"standard": {
"query": {"match": {"title": "人工智能"}}
}
},
{
"knn": {
"field": "vector",
"query_vector": [...],
"k": 50
}
}
],
"weights": [2, 1],
"rank_constant": 20
}
}
}适用场景
- 电商搜索:提升关键词权重(权重比 3:1 或更大)
- 内容推荐:增强语义相关性(权重比 1:2 或更大)
- 知识库检索:平衡语义与关键词(权重比 1:1 微调)
2.2 归一化 Score 融合
算法原理
通过动态归一化将不同评分体系统一到 0,1 区间:
- BM25 归一化:
(score - min_score)/(max_score - min_score) - 向量相似度归一化:
cosine_similarity + 1 / 2
混合排序示例
{
"retriever": {
"score_fusion": {
"retrievers": [...],
"weights": [1.5, 1]
}
}
}适用场景
- 结果可解释性强
- 多维度加权评分的精排搜索
2.3 基于模型的 Rerank 融合
算法原理
借助腾讯云智能搜索的原子能力,腾讯云 ES 8.16.1 搜索增强版,已支持调用第三方 rerank 模型对混合搜索的结果进行重排。当前已支持内置下列重排序模型,这些模型都部署在GPU上,性能有极大提升。
原子服务 | token限制 | 维度 | 语言 | 备注 |
|---|---|---|---|---|
bge-reranker-large | 514 | 1024 | 中文、英文 | bge经典模型 |
bge-reranker-v2-m3 | 8194 | 1024 | 多语言 | bge经典模型 |
bge-reranker-v2-minicpm-layerwise | 2048 | 2304 | 多语言 | 在英语和中文水平上均表现良好,可以自由选择输出层,有助于加速推理 |
使用示例
PUT _inference/rerank/tencentcloudapi_bge-reranker-large
{
"service": "tencent_cloud_ai_search",
"service_settings": {
"secret_id": "xxx",
"secret_key": "xxx",
"url": "https://aisearch.internal.tencentcloudapi.com",
"model_id": "bge-reranker-large",
"region": "ap-beijing",
"language": "zh-CN",
"version": "2024-09-24"
}
}POST _inference/rerank/tencentcloudapi_bge-reranker-large
{
"query": "中国",
"input": [
"美国",
"中国",
"英国"
]
}{
"rerank": [
{
"index": 1,
"relevance_score": 0.99990976,
"text": "中国"
},
{
"index": 0,
"relevance_score": 0.013636836,
"text": "美国"
},
{
"index": 2,
"relevance_score": 0.00941259,
"text": "英国"
}
]
}混合排序示例
{
"retriever": {
"tencent_cloud_ai_reranker": {
"retrievers": [...],
"model_id": "tencentcloudapi_bge-reranker-large",
"rank_field": "content",
"rank_text": "nice day",
"rank_window_size": 10,
"min_score": 0.6
}
}
}适用场景
- 对语义相关性有更高需求的场景
- 对准召率有更高需求的场景
2.4 小结
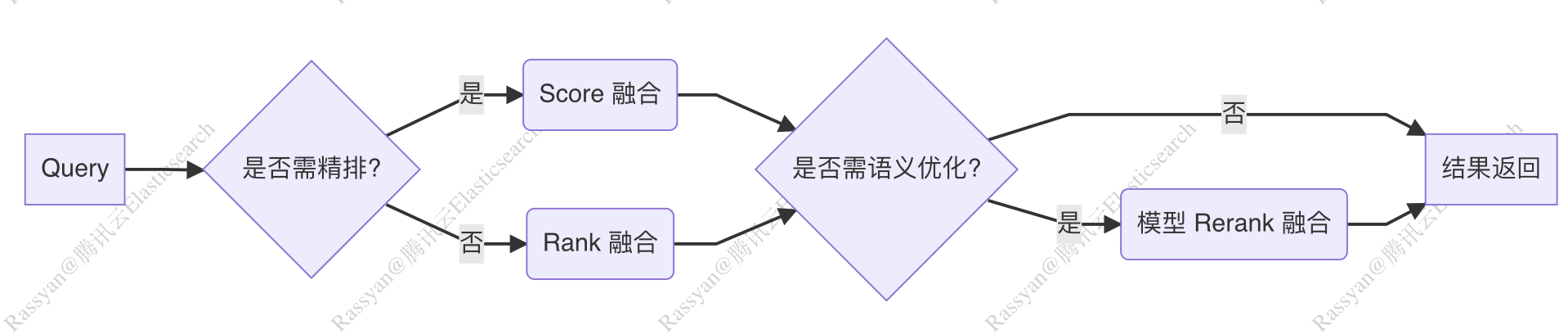
下图展示了 v-pack 提供的多种融合排序算法,所带来的更丰富的准召率提升手段。

v-pack 提供的融合算法,支持自定义的灵活组合,可以参考如下的做法来组合使用。
三、推理飞跃:无缝连接最强模型
3.1 对话推理:一键接入满血 Deepseek 大模型
借助腾讯云智能搜索的 LLM 生成服务,腾讯云 ES 8.16.1 搜索增强版亦可以一键接入 DeepSeek 以及混元系列大模型进行推理。
模型类型 | 模型名称(model) | Tokens | 特性 |
|---|---|---|---|
deepseek-r1 | 最大输入128k | 最大输出8k | 擅长复杂需求拆解、技术方案直译,提供精准结构化分析及可落地方案,实现了与GPT-4o和Claude Sonnet 3.5等顶尖模型相媲美的性能 |
deepseek-v3 | 最大输入128k | 最大输出8k | 通用型AI模型,拥有庞大参数规模及强大多任务泛化能力,擅长开放域对话、知识问答、创意生成等多样化需求 |
deepseek-r1-distill-qwen-32b | 最大输入128k | 最大输出8k | r1-36b参数蒸馏版,效果没有r1好,但响应速度更快,资源成本更低 |
hunyuan-turbo | 最大输入28k | 最大输出4k | 腾讯新一代旗舰大模型,混元Turbo模型,在语言理解、文本创作、数学、推理和代码等领域都有较大提升,具备强大的知识问答能力 |
... |
使用示例
PUT _inference/completion/deepseek
{
"service": "tencent_cloud_ai_search",
"service_settings": {
"secret_id": "xxx",
"secret_key": "xxx",
"url": "https://aisearch.internal.tencentcloudapi.com",
"model_id": "deepseek-v3",
"region": "ap-beijing",
"language": "zh-CN",
"version": "2024-09-24"
}
}POST _inference/completion/deepseek
{
"input": "你是谁?"
}{
"completion": [
{
"result": "我是DeepSeek Chat,一个由深度求索公司开发的智能助手,旨在通过自然语言处理和机器学习技术来提供信息查询、对话交流和解答问题等服务。"
}
]
}我们可以借助该能力,使用 Deepseek 代替 OpenAI 实现官方最佳实践中的相关功能:https://www.elastic.co/search-labs/blog/elasticsearch-openai-completion-support
3.2 嵌入推理:接入 GPU embedding 消除推理高延迟
借助腾讯云智能搜索的 LLM 生成服务,腾讯云 ES 8.16.1 搜索增强版支持内网无缝推理,目前支持以下主流的 embedding 模型。
原子服务 | token限制 | 维度 | 语言 | 备注 |
|---|---|---|---|---|
bge-base-zh-v1.5 | 512 | 768 | 中文 | bge经典模型 |
bge-m3 | 8194 | 1024 | 多语言 | bge经典模型 |
conan-embedding-v1 | 512 | 1792 | 中文 | 腾讯自研,在MTEB榜单一度综合排第一 |
使用示例
PUT _inference/text_embedding/tencentcloudapi_bge_base_zh-v1.5
{
"service": "tencent_cloud_ai_search",
"service_settings": {
"secret_id": "xxx",
"secret_key": "xxx",
"url": "https://aisearch.internal.tencentcloudapi.com",
"model_id": "bge-base-zh-v1.5",
"region": "ap-beijing",
"language": "zh-CN",
"version": "2024-09-24"
}
}PUT semantic_text_index
{
"mappings": {
"properties": {
"content": {
"type": "semantic_text",
"inference_id": "tencentcloudapi_bge_base_zh-v1.5"
}
}
}
}3.3 小结
借助腾讯云智能搜索的原子服务,腾讯云 ES 允许用户将 ES 作为 AI Search 的服务中枢,成为向量、文本、模型的统一引擎,all in one 一站式地完成整套 RAG 场景的搜索和推理需求。
四、持续进化:社区贡献与自研特性齐头并进
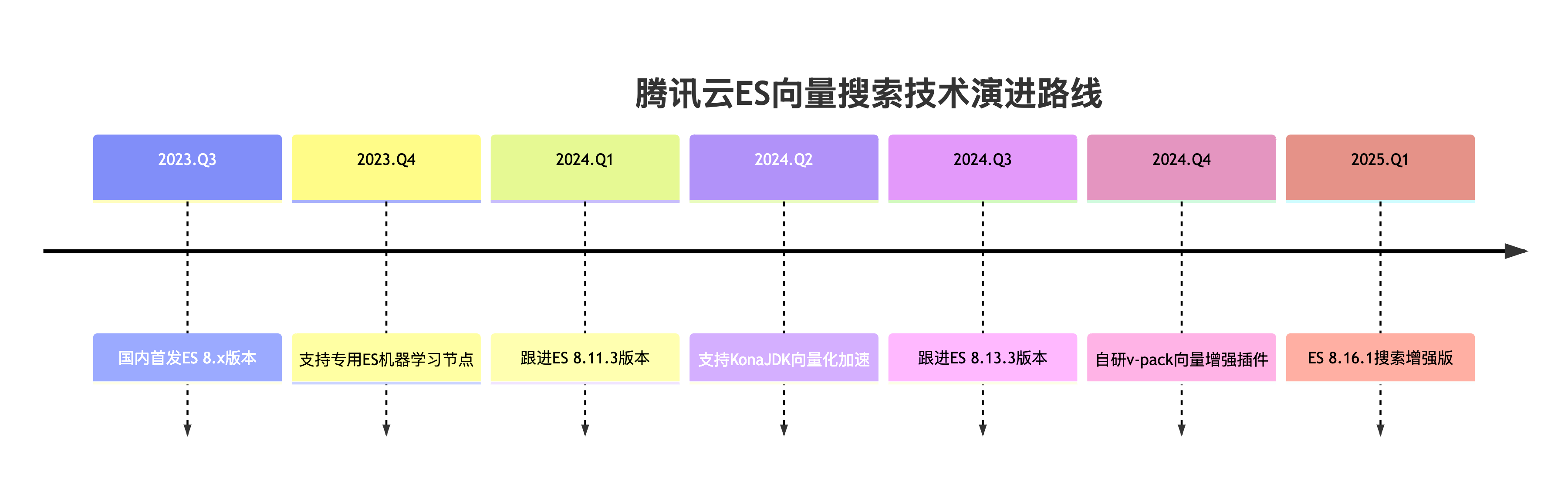
腾讯云 ES 团队持续投入开源生态建设,覆盖最新的向量场景:
- 核心贡献:累计提交 200+ 社区PR,向量相关 10+
让技术回归本质,用创新驱动价值
腾讯云 ES 将持续深耕 AI Search 基础设施,致力服务好当今日益增长的 RAG 与多模态搜索需求,与开发者共同探索搜索技术的无限可能。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
