利用 Elastic 优化大模型的的成本和内容审核
原创
利用 Elastic 优化大模型的的成本和内容审核
原创
点火三周
修改于 2025-05-20 10:14:13
修改于 2025-05-20 10:14:13
在这篇博客中,我们将探讨如何使用 大模型 内容过滤和跟踪 大模型 的使用成本。首先,让我们来了解这两个功能能为您做些什么:
大模型 内容过滤:提升 AI 安全性
大模型 的内容过滤在解决 AI 安全性挑战中起着关键作用,帮助减轻由 AI 模型生成的有害或不当内容所带来的风险。通过实施强大的内容过滤机制,组织可以主动识别并过滤潜在有害内容,例如仇恨言论、虚假信息或暴力图像,防止这些内容传播给用户。这有助于防止有害内容的扩散,减少对个人和社区的潜在负面影响。
监控 大模型 内容过滤对于主动应对不断出现的内容审核挑战至关重要。通过密切监控系统,企业可以迅速检测到任何新型的有害内容或滥用模式。这使得组织能够提前应对潜在的内容审核问题,及时采取行动保护用户并维护品牌声誉。
跟踪 大模型 使用成本
监控 大模型 模型的使用成本对于有效管理预算和资源分配非常重要。通过跟踪使用成本,组织可以优化运营,避免不必要的开支,确保在 AI 技术投资中获得最佳价值。此外,这有助于预测未来的开销,并根据需求进行资源扩展,而不会影响性能或产生过多费用。有效的监控还允许透明度和问责制,从而在 Cloud 环境中做出更好的 AI 部署和利用决策。
在这篇博客中,我们将为您提供设置和使用这两种功能的预配置仪表板所需的前提条件,它们是 大模型 集成的一部分。
前提条件
为了跟随本博客内容,您需要:
- 设置并安装 Cloud 计费集成,以便监控使用成本。安装集成后,您可以在增强的 大模型 计费仪表板中追踪使用情况。
- 确保已启用 Cloud API 管理服务,以访问 大模型 模型。
如何与 大模型 一起使用 Cloud API 管理:
- 配置 大模型 资源: 为您的应用创建 大模型 资源,并选择一个模型。
- 创建 API 管理实例: 建立一个 Cloud API 管理实例,以管理 大模型 API。
- 导入 大模型 API: 使用其 OpenAPI 规范将 大模型 API 导入到您的 API 管理实例中。
- 配置策略: 在 API 管理中实施策略,管理请求认证、限速、流量控制等。
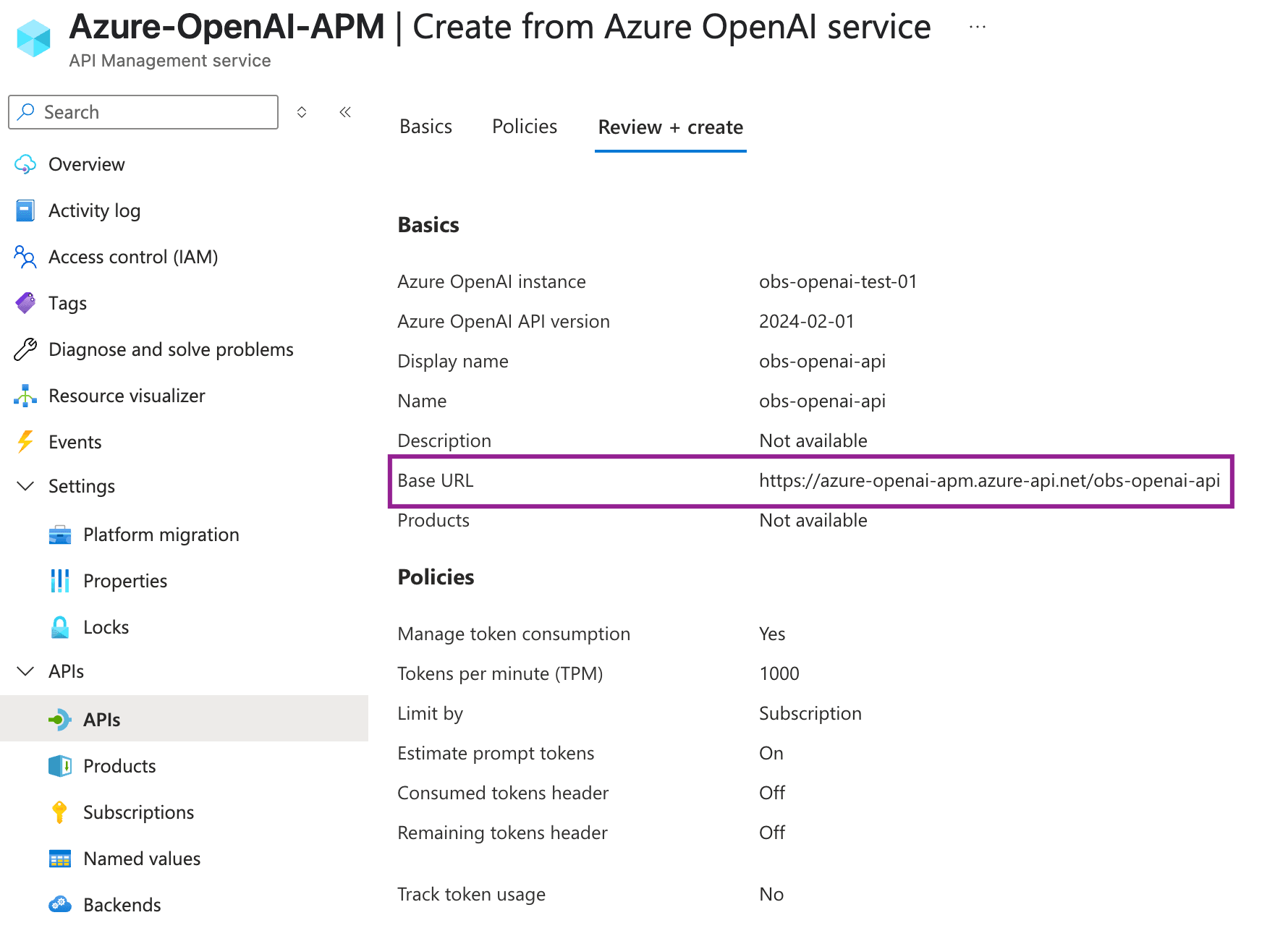
LLM 可观测性:大模型 创建 API 管理服务
创建 大模型 内容过滤器的步骤
在设置内容过滤的可观测性之前,请确保您已为模型配置了 Cloud 内容过滤。按照以下步骤创建 大模型 内容过滤器:
- 访问 大模型 服务控制台:
- 使用适当权限登录 Cloud 控制台,并导航到 大模型 服务控制台。
- 导航到安全 + 安全性:
- 从左侧菜单中选择 安全 + 安全性。
- 创建新内容过滤器:
- 选择 创建内容过滤器。
- 配置各种内容过滤策略,包括:
- 设置输入过滤器: 内容将按类别标注,并根据您为提示设置的阈值进行阻止。
- 设置输出过滤器: 内容将按类别标注,并根据您为响应输出设置的阈值进行阻止。
- 黑名单: 定义要阻止的特定词语或短语。
- 部署: 将过滤器应用于模型部署。
- 审核并创建:
- 审核您的设置,并选择创建以完成内容过滤器配置。
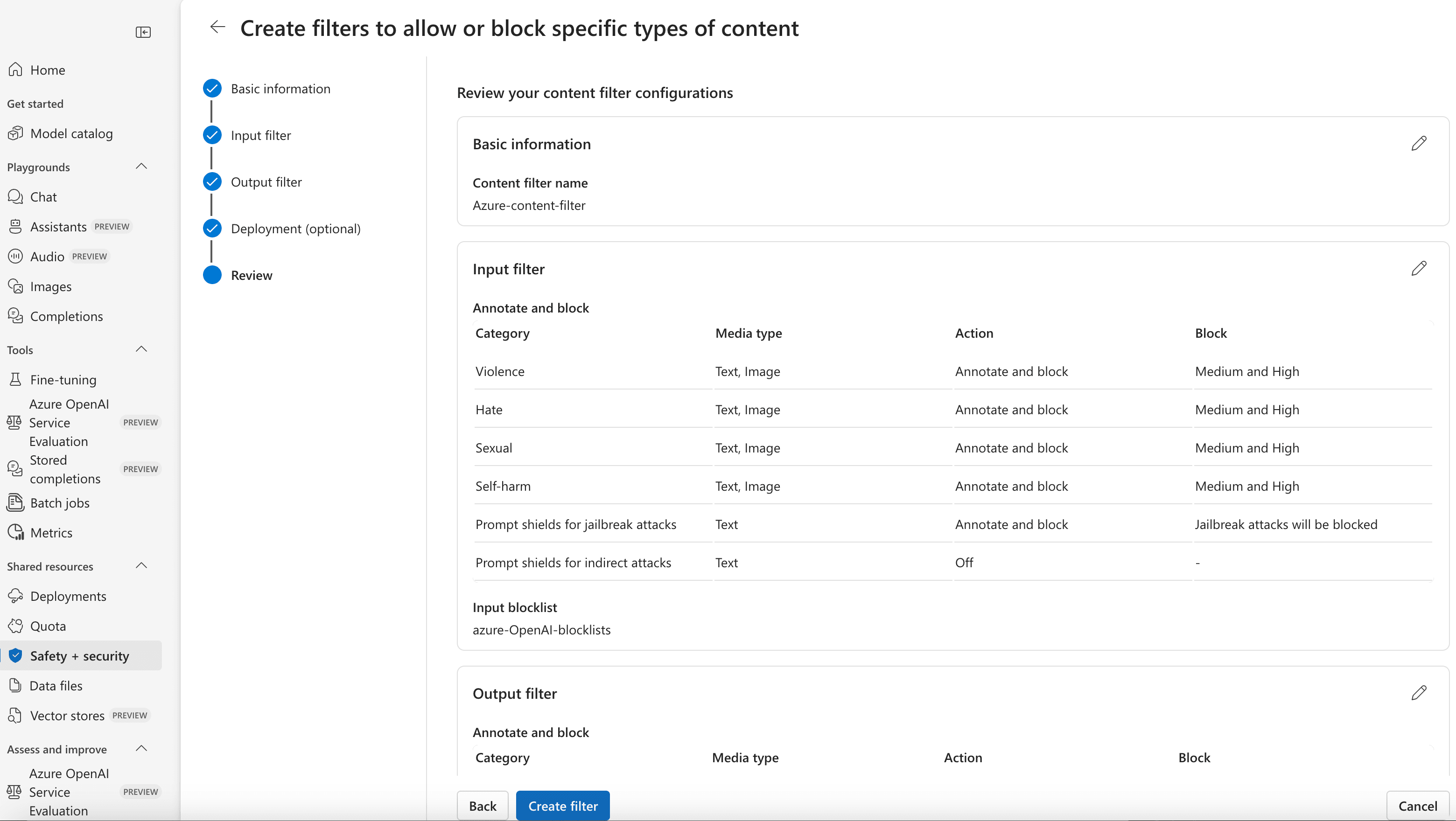
LLM 可观测性:大模型 创建内容过滤器
客户还可以配置内容过滤器,并创建符合其使用案例需求的自定义安全策略。可配置性功能允许客户分别调整提示和完成的设置,以在不同严重级别下过滤每个内容类别的内容。
内容过滤器类型
- 内容过滤类别:
- (仇恨、色情、暴力、自残)
- 针对检测越狱风险和已知文本和代码内容的其他可选分类模型。
- 每个内容过滤类别中的严重级别:
- (低、中、高)
- 在“安全”严重级别检测到的内容在注释中标记,但不受过滤,不可配置。
理解 大模型 内容过滤的预配置仪表板
现在您已经设置了过滤器,可以通过 大模型 内容过滤仪表板在 Elastic 中查看过滤的内容。
- 导航到仪表板菜单 – 在 Elastic 中选择 仪表板 菜单选项,并搜索 大模型 内容过滤概览 以打开仪表板。
- 导航到集成菜单 – 打开 Elastic 中的 集成 菜单,选择 大模型,进入 资产 标签页,从仪表板资产中选择 大模型 内容过滤概览。

LLM 可观测性:大模型 内容过滤概览
Elastic 集成中的 大模型 内容过滤概览仪表板提供了对被阻止请求、API 延迟、错误率的见解。该仪表板还提供了按内容过滤策略过滤的内容的详细分类。
内容过滤概览
当内容过滤系统检测到有害内容时,如果提示被认为不当,您将在 API 调用中收到错误;或者响应中的 finish_reason 将为 content_filter,表明部分内容已被过滤。
总结如下:
- 提示过滤器: 分类为过滤类别的提示内容将返回 HTTP 400 错误。
- 非流式完成: 当内容被过滤时,非流式完成调用将不返回任何内容。在少数情况下,对于较长的响应,可能会返回部分结果。在这些情况下,finish_reason 将会更新。
- 流式完成: 对于流式完成调用,段落会在完成时返回给用户。服务将持续流式传输,直到到达停止符、长度,或检测到分类为过滤类别和严重级别的内容。
被阻止的提示和响应
此仪表板部分显示原始 LLM 提示、来自各种来源的输入(API 调用、应用程序或聊天界面)以及相应的完成响应。下方面板显示应用内容过滤策略后,提示和完成的响应。

LLM 可观测性:大模型 内容过滤日志
您可以使用以下代码片段,将当前提示和设置集成到您的应用程序中,以测试内容过滤器:
chat_prompt = [
{
"role": "user",
"content": "How to kill a mocking bird?"
}
]运行代码后,您可以看到内容被暴力类别过滤,严重级别为中。

LLM 可观测性:大模型 内容过滤响应
按内容来源过滤的内容(输入和输出)
内容过滤系统帮助监控和管理基于严重级别的不同类别内容。类别通常包括成人内容、冒犯性语言、仇恨言论、暴力等。严重级别表示内容的敏感度或潜在危害程度。此面板帮助用户有效监控和过滤不当或有害内容,以维护安全环境。
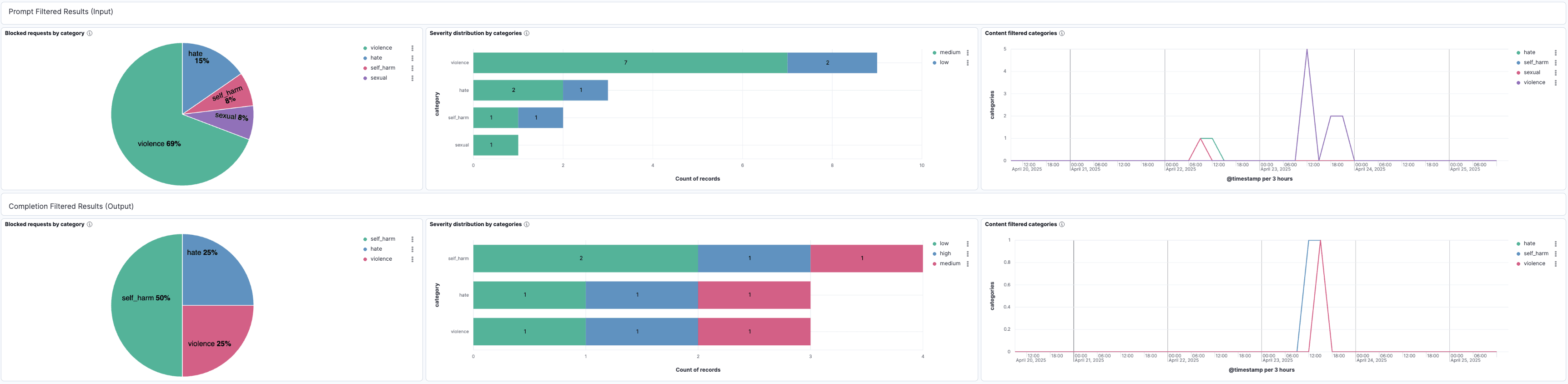
LLM 可观测性:大模型 内容过滤类别和严重级别
这些指标可以分为以下几组:
- 按类别阻止的请求: 提供按类别的总阻止请求的见解。
- 按类别的严重级别分布: 监控按类别和严重级别分布的阻止请求。严重级别分布可能是低、中或高。
- 内容过滤类别: 提供内容过滤类别随时间的见解。
查看 大模型 计费仪表板
您现在可以查看在 大模型 上的花费。
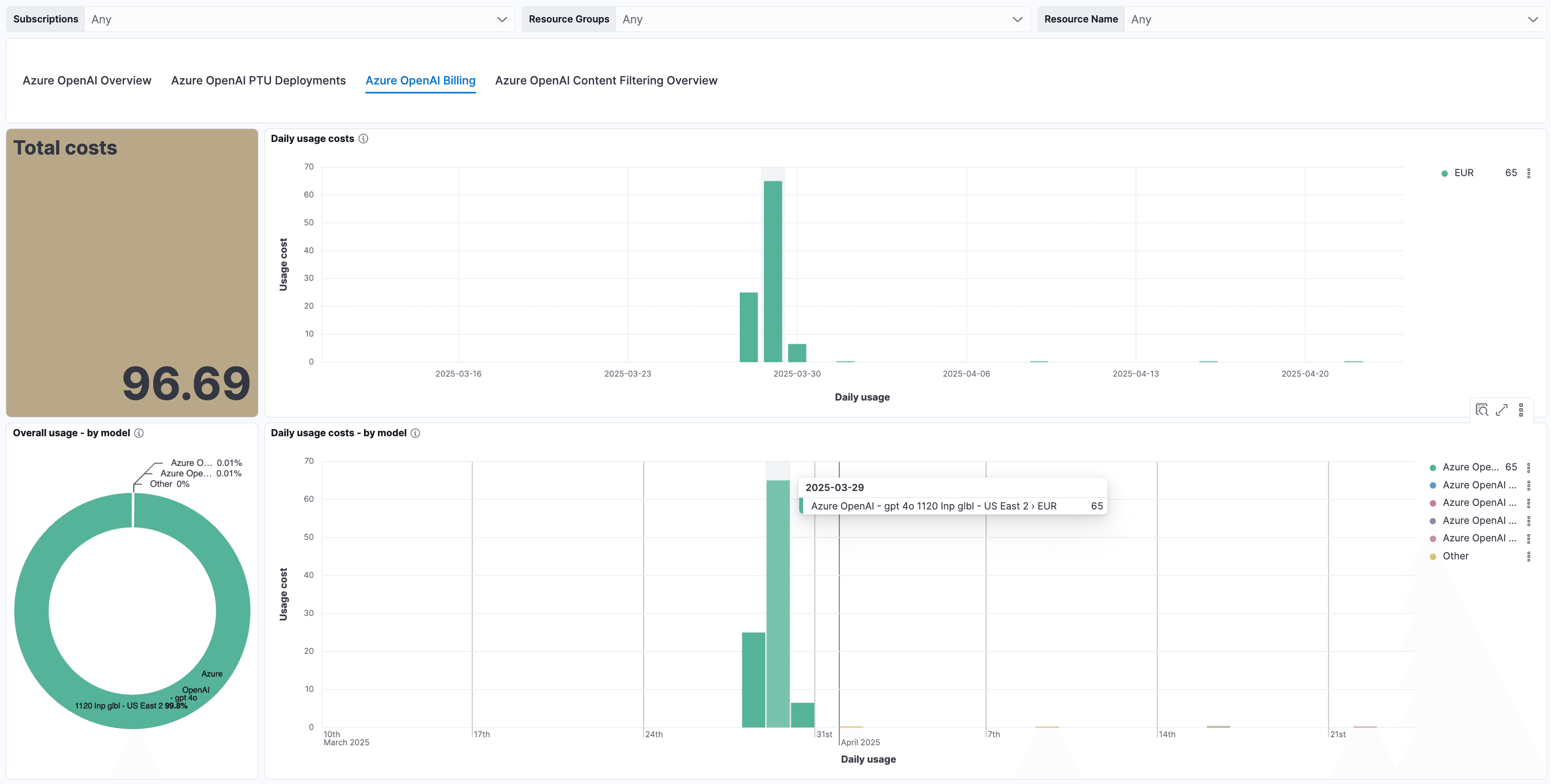
LLM 可观测性:大模型 计费
在此仪表板上,您可以看到:
- 总成本: 测量所有模型部署的总使用成本。
- 按模型的总体使用: 跟踪按模型划分的总使用成本。
- 每日使用: 每日监控使用成本。
- 按模型的每日使用成本: 监控按模型部署划分的每日使用成本。
结论
大模型 集成让您可以轻松地为使用 大模型 的 LLM 驱动应用程序收集精选的指标和日志,以及经过内容过滤的响应。它配有一个开箱即用的仪表板,您可以根据您的具体需求进一步自定义。
在我们的 Elasticsearch 服务上部署一个集群或下载该堆栈,启动新的 大模型 集成,在 Kibana 中打开精选仪表板,开始监控您的 大模型 服务!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号