【MySQL基础篇】四、数据类型


Ⅰ. 数据类型分类
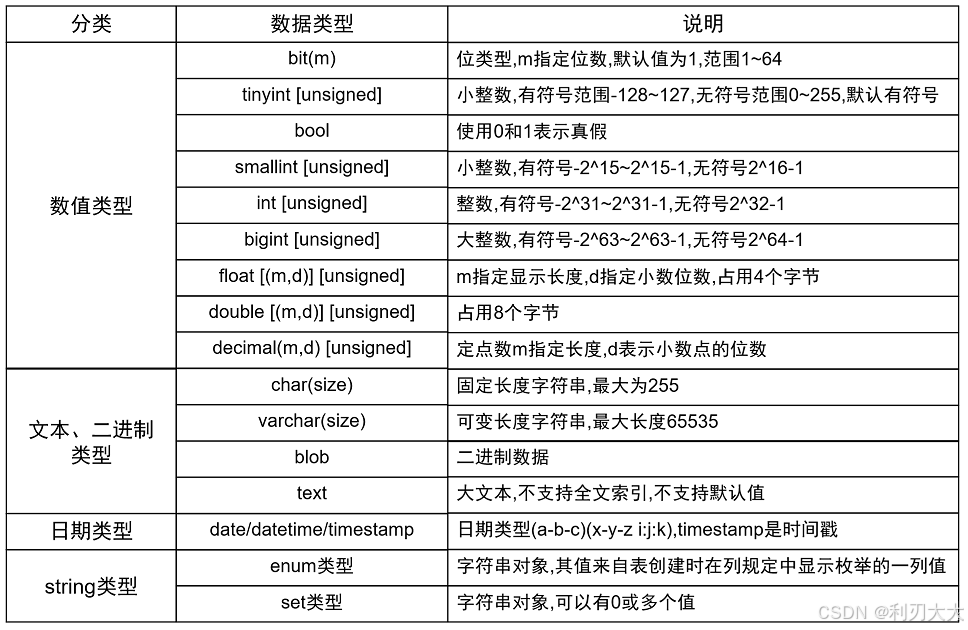
上图列举了 mysql 中的数据类型,其实我们主要分为四种类型来讲解,数据类型比较接近的比如说 tinyint、smallint、int 等几个类型,我们只会挑其中一个来讲,因为其它都是类似的!
Ⅱ. 数值类型
1、整数类型
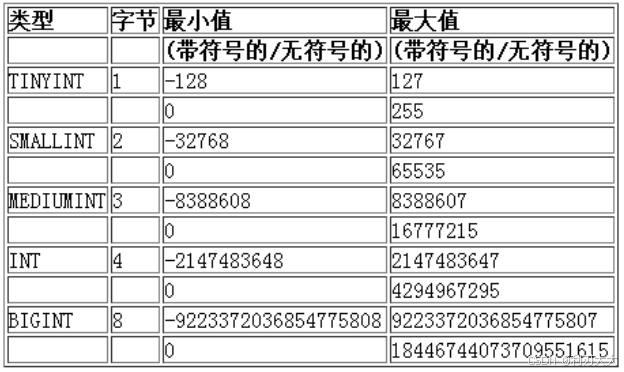
这里以 tinyint 类型为例,我们结合例子来看现象,主要测试一下数据的越界情况!
下面先创建一个数据库 test_db,然后创建一个表 t1,其中存放的类型就是 tinyint:
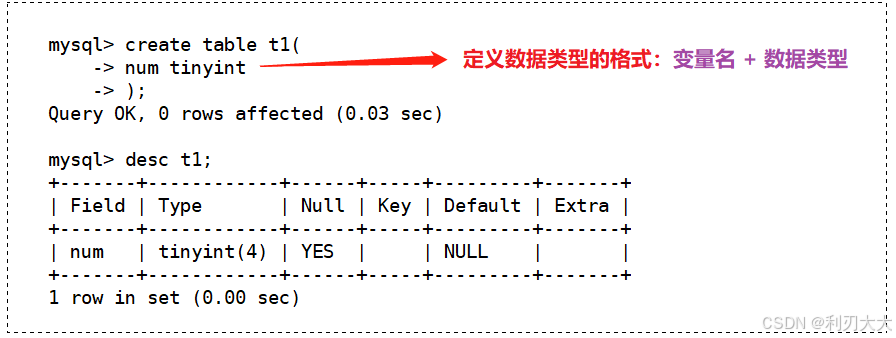
接着我们向 t1 中插入一些不超出 tinyint 范围的数据:

下面我们向里面插入几个超过 tinyint 范围的数据:

至此,我们可以得出一些结论:
- 如果我们向
mysql特定类型中插入不合法(类型不同或者超出数据范围)的数据,mysql是直接报错拦截的,不让我们进行对应的操作! - 反过来,如果我们已经有成功地插入数据到
mysql中的话,那么这个数据一定是合法的! - 所以一般而言,数据类型本身也是一种 约束(这个我们以后会经常碰到)
- 所谓的约束就是限制使用者的一些不合法操作!
- 这样子才能保证数据库中的数据是可预期的、完整的!
下面我们再演示一下如何创建无符号类型的数据,其实就是在数据类型后面加一个 unsigned 即可:
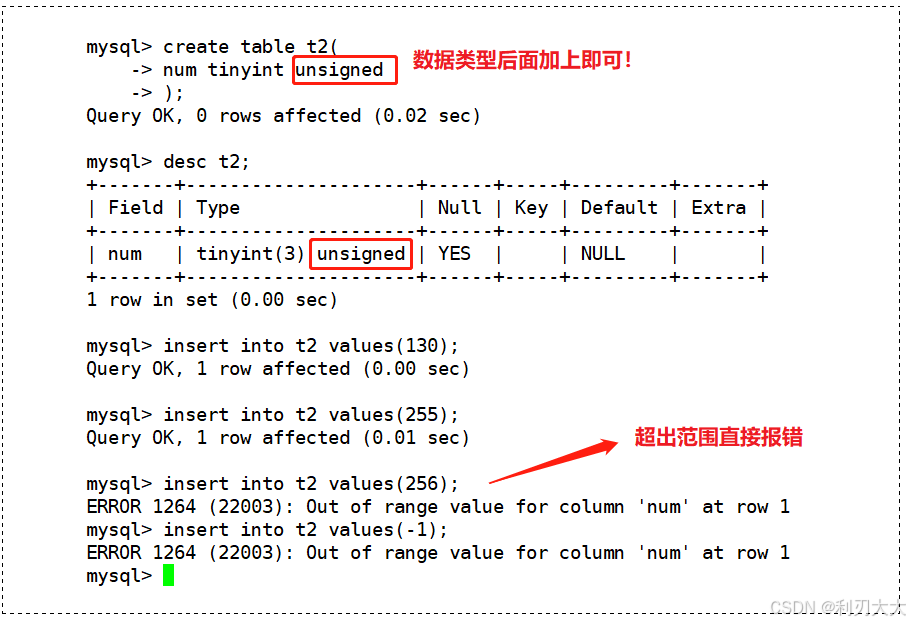
注意:尽量不使用 unsigned,对于 int 类型可能存放不下的数据,int unsigned 同样可能存放不下,与其如此,还不如设计时,将 int 类型提升为 bigint 类型。
2、位类型 – bit
bit[(m)] : 位字段类型。m表示每个值的位数,范围从1到64。如果m被忽略,默认为1。 下面我们创建一个表,在表中存放 bit 类型的数据:
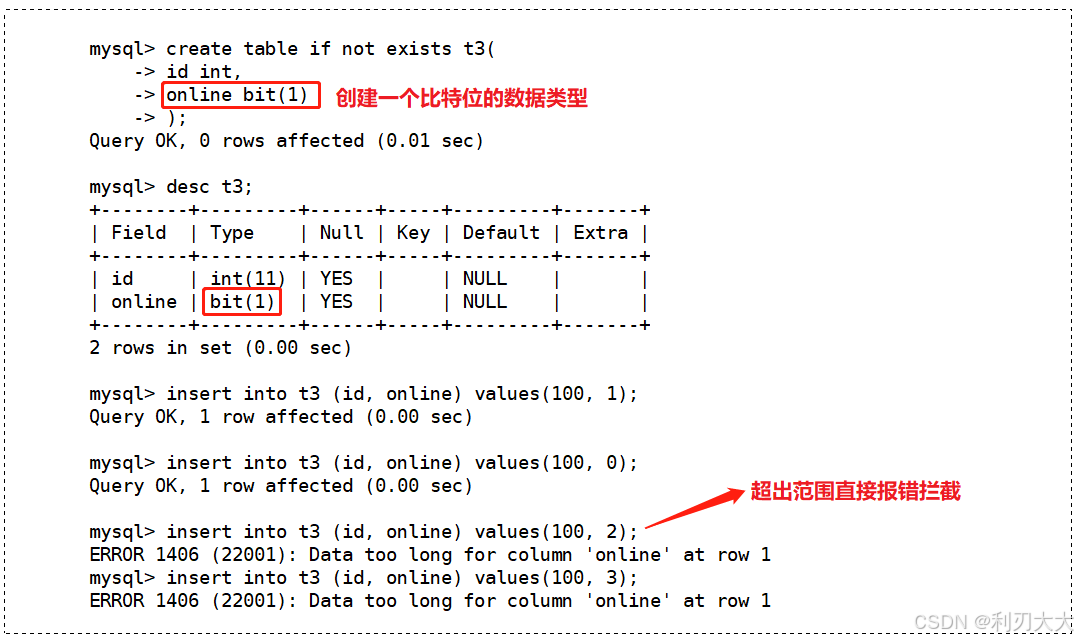
注意事项:
-
bit字段在显示时,是按照ASCII码对应的值显示。所以如果想通过select语句查看的话,需要使用hex()函数将其转化为十六进制格式才能看得到!
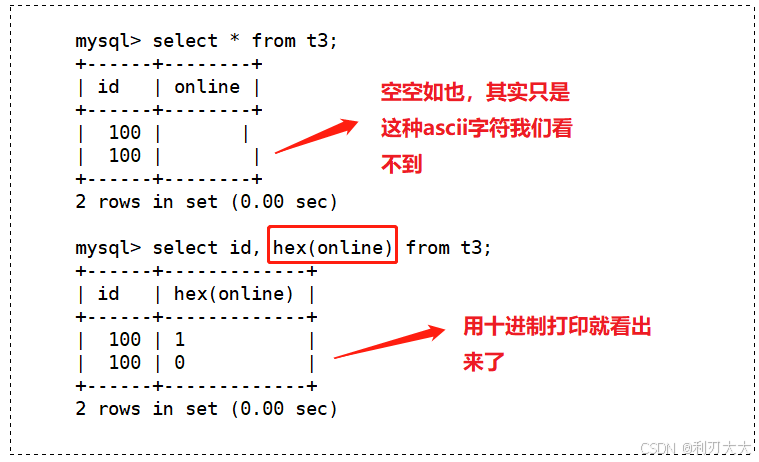
- 申请超过
bit的数据类型范围也会报错!
3、小数类型
① 浮点数类型
浮点数类型有 float、double,这里我们以 float 类型为例!
其语法如下所示:
float[(m, d)] [unsigned] : m指定显示总长度,d指定小数位数,占用空间4个字节注意实现:
mysql在保存小数时会进行四舍五入- 一般来说浮点数的范围是根据
m和d来进行把控的。如果我们在定义数据类型的时候,不带上m和d的话,那么该浮点数会默认按照我们插入的数据大小做存储,但是会有一些精度损失! - 此外,浮点数类型在
mysql中也是有无符号类型的,其作用只是砍掉了负数那部分,而正数部分的取值范围依然还是那样子!
举个例子,下面我们创建一个 m=4,d=2 的浮点数类型,其范围也就顺理成章的为 -99.99 ~ 99.99,如下所示:
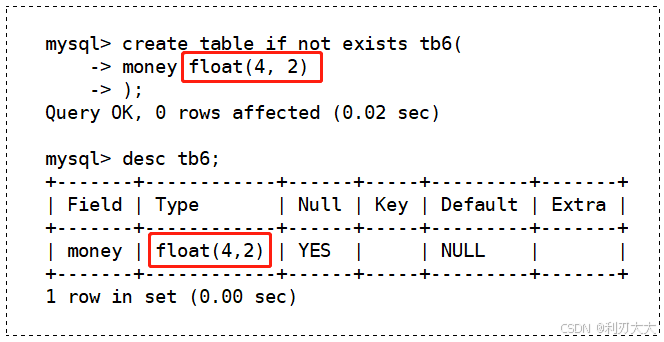
下面我们试着往里面插入多条数据:

② 固定精度的十进制数类型 – decimal
decimal(m, d) [unsigned] : 定点数m指定长度,d表示小数点的位数 在
mysql中,decimal类型用于存储精确的十进制数值。与float类型不同,decimal类型不会丢失精度,并且可以存储较大的数值范围。decimal类型的大小是可变的,可以指定精度和小数位数。它的存储需求取决于指定的精度和小数位数。 注意,虽然decimal类型可以存储小数值,但它 不是浮点数类型,它是一种固定精度的十进制数类型,它以字符串形式存储,并且不会丢失精度。与浮点数类型(如float和double)不同,decimal类型可以精确表示十进制数值,而不会引入舍入误差(但是计算过程也会有四舍五入)。 而浮点数类型(如float和double)使用二进制表示法来存储数值,因此在进行计算时可能会引入舍入误差。因此,如果需要进行精确计算或存储货币金额等需要确切数值的场景,建议使用decimal类型而不是浮点数类型。
下面我们的操作主要是用来区分一下浮点数类型和 decimal 类型的精度:
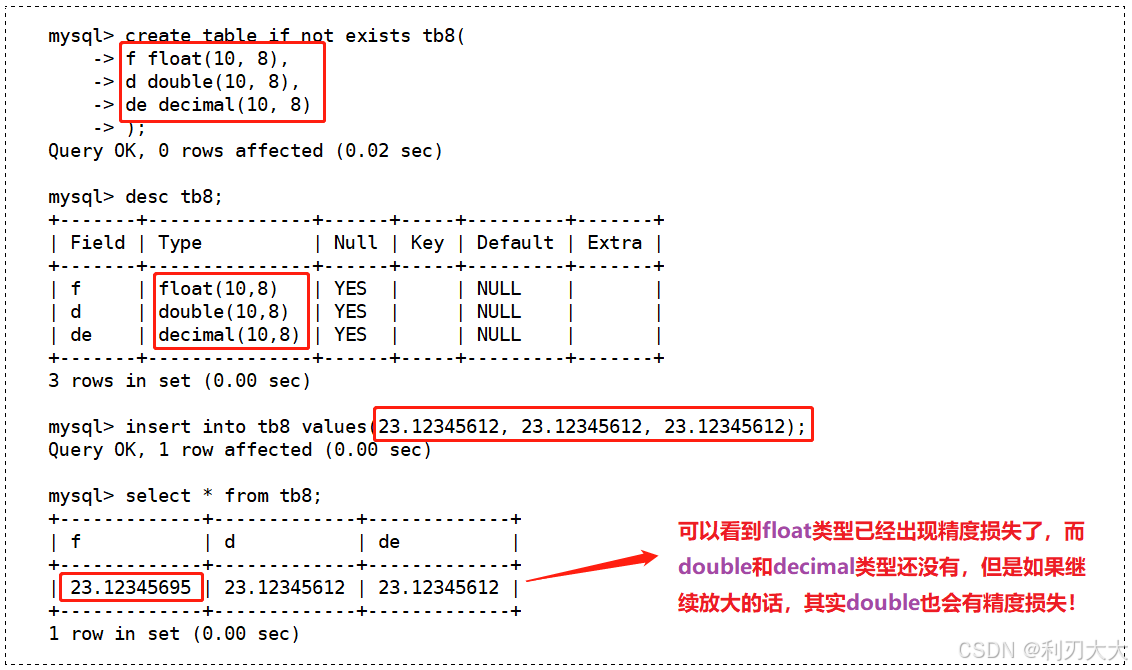
说明:
float表示的精度大约是7位。decimal整数最大位数m为65,其中支持小数最大位数d是30。- 如果
d被省略,默认为0 - 如果
m被省略,默认是10。
- 如果
Ⅲ. 字符串类型
1、char类型
char(L): 固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255注意事项:
- 这里说单位为字符,不只是指
ascii字符,也可以是gbk、utf8 等编码字符!

2、varchar类型
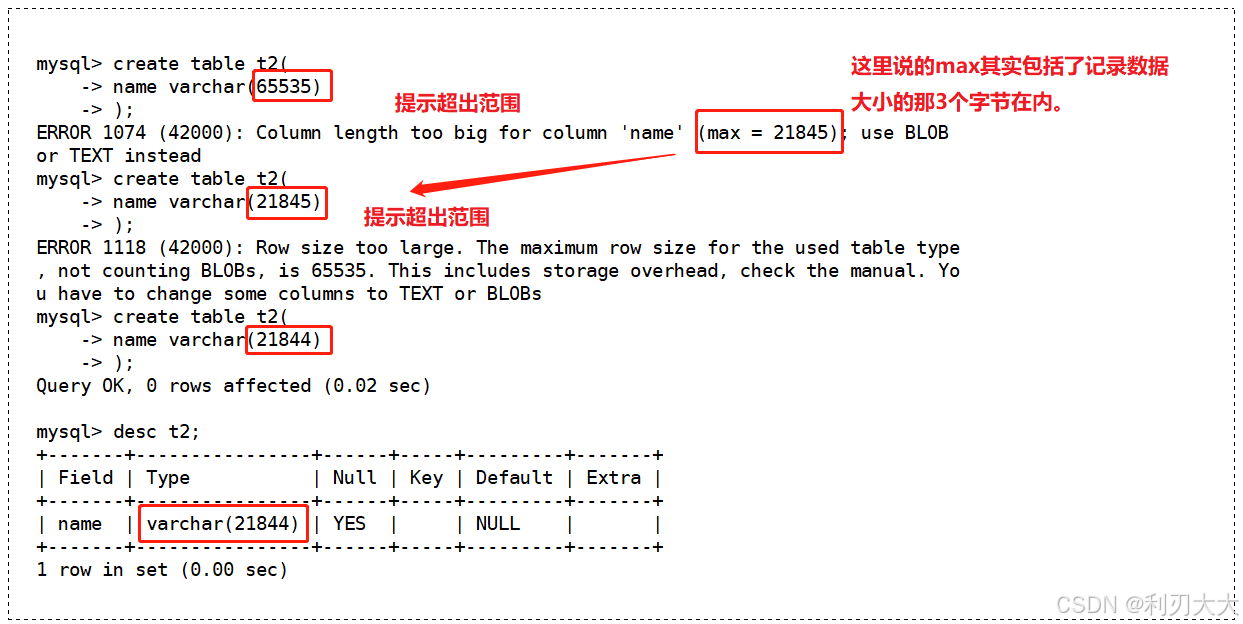
varchar(L): 可变长度字符串,L表示字符长度,单位也是字符,最大长度65535个字节!!! varchar 类型的使用和 char 基本是一样的,这里主要介绍其编码的注意事项以及区别!
注意事项:
- 虽然说
L表示长度,单位也是字符,但是可以看到varchar数据类型的最大长度是以字节为单位的,这是为了适应不同的编码格式而设定的,其最大的长度不超过65535个字节,也就是说,L是随不同编码格式而有不同的取值范围的! - 但是因为规定有
1~3个字节用于记录数据的大小(这是动态开辟的,也就是说当一个字节不够表示大小了才会使用两个、三个字节),所以实际 最大长度实际上是65532~65534个字节 !- 举个例子:
- 如果我们使用的是
utf8也就是每个字符占用三个字节的话,那么总共只能用65532/3 = 21844个字符。 - 如果我们使用的是
gbk也就是每个字符占用两个字节的话,那么总共只能用65532/2 = 32766个字符。
- 如果我们使用的是
- 举个例子:
- 此外,如果表中不止有一列字段的话,那么此时
varchar的最大字节可能要变得更小!
3、char和varchar的比较
如下表,举了个例子,很快就能看懂它们的区别:

如何选择定长或变长字符串❓❓❓
- 如果数据确定长度大致都一样,就使用 定长(char),比如:身份证、手机号、md5。
- 如果数据长度有变化,就使用 变长(
varchar)。比如:名字、地址,但是你要保证最长的能存的进去。 - 定长的磁盘空间比较浪费,但是效率高。
- 定长的意义是,直接开辟好对应的空间
- 变长的磁盘空间比较节省,但是效率低。
- 变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少。
Ⅳ. 日期类型
常用的日期有如下三个:
date- 格式为
'yyyy-mm-dd',占用 三字节 - 只有日期,并且只能手动更改
- 格式为
datetime- 格式为
'yyyy-mm-dd HH:ii:ss'表示范围从1000到9999,占用 八字节 - 有日期也有时分秒,但是只能手动更改
- 格式为
timestamp- 时间戳,从
1970年开始的'yyyy-mm-dd HH:ii:ss'格式,这和datetime完全一致,占用 四字节 - 与
datetime唯一不同的是,当我们 插入或者更新一条记录的时候,会自动设置为当前的日期和时间,这种自动更新的行为是由MySQL的内部机制控制的,不需要手动操作。
- 时间戳,从
我们先创建一个表,分别带有这三种日期类型:

下面我们插入数据,并做修改来看看区别:

Ⅴ. enum类型与set类型
1、语法
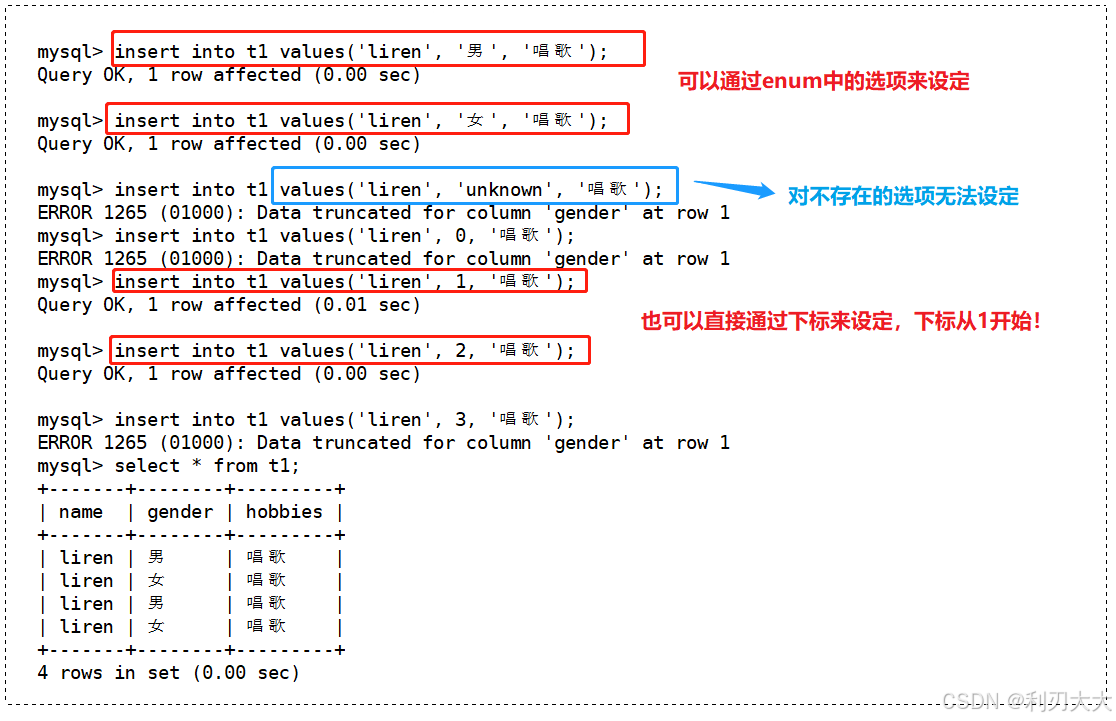
enum(枚举):允许在列中定义一个值列表,然后 只能从该列表中选择一个值。- 我们可以通过直接用列表中的值,或者通过其选项值,这些选项的每个选项值依次对应如下数字:
1,2,3,…最多65535个,所以当我们添加枚举值时,也可以添加对应的数字编号!- 例如,如果有一个名为
gender的列,并且只允许选择 “男” 或 “女” 作为值,可以将该列定义为enum("男", "女")。在这种情况下,列只能包含这两个值中的一个,或者可以选择为空。
- 例如,如果有一个名为
- 我们可以通过直接用列表中的值,或者通过其选项值,这些选项的每个选项值依次对应如下数字:
set(集合):类似于enum,但允许 从一个值列表中选择多个值。- 我们可以通过直接用列表中的值,或者通过其选项值,这些选项的每个选项值依次对应如下数字:
1,2,4,8,16,…最多64个,这是有原因的,这个结合下面的例子来讲会更清晰!- 例如,如果有一个名为
hobbies的列,并且允许选择多个爱好,您可以将该列定义为set('读书', '篮球', '跳舞', 'Rap')。在这种情况下,列可以包含这些值中的任意组合,或者可以选择为空。
- 例如,如果有一个名为
- 我们可以通过直接用列表中的值,或者通过其选项值,这些选项的每个选项值依次对应如下数字:
- 此外,
enum是从下标 1 开始获取元素的,而set则是从下标0开始获取元素的(虽然元素是空集)。
此外,使用
enum和set数据类型时,可以在创建表时指定默认值,例如gender enum('男', '女') default '女'。 需要注意的是,enum和set数据类型在某些情况下可能会有一些限制。例如,当值列表很长时,enum可能会占用更多的存储空间,而set可能会有一些查询和索引方面的限制。因此,在使用这些数据类型时,需要根据具体情况进行权衡和选择。
下面来举个例子,创建一张表,这个表中有 enum 和 set 两个类型的数据,前者用于选择性别,后者用于选择爱好:

然后向表中插入数据,先来测试一下 enum 的特性(图中已经说明细节):
下面再来测试一下 set 的特性:
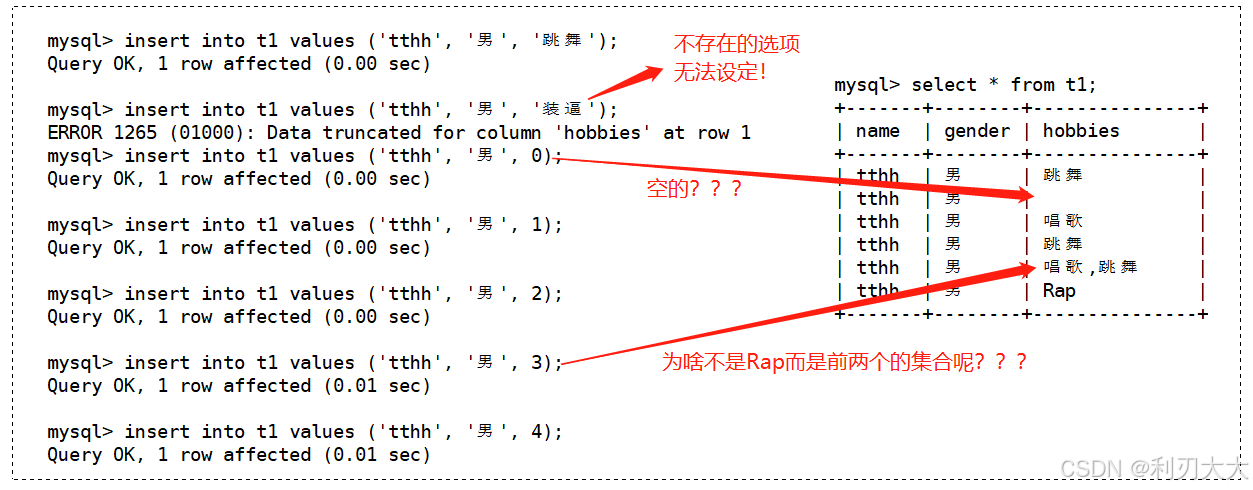
可以看到,与 enum 不同的是,set 是支持多选的!
除此之外,上面查询出来的结果中居然有一个是空的结果,其实这只是 代表一个空集,它是存在的,只不过没有内容,并不代表是 NULL,注意区分开!
但是不是很奇怪,set 的测试中有这么奇怪的现象❓❓❓
其实一点都不奇怪,你说为什么 set 叫做 set,其实就是集合的意思,当我们通过 0 下标进行访问到的是一个空集;通过 1 下标访问到的是第一个元素;通过 2 下标访问到的是第二个元素;通过 3 下标访问到的是前两个元素的集合;而通过 4 下标访问到的是第三个元素……
是不是找到规律了,其实我们 用下标访问的时候,就相当于是一个位图,比特位为 1 的那个选项就会被选上,如下所示:

既然是这样子,那么我们想一下,我们要同时列举出五个选项的集合,那就是 11111,就是 31,我们试试看用下标 31 是不是得到该集合:
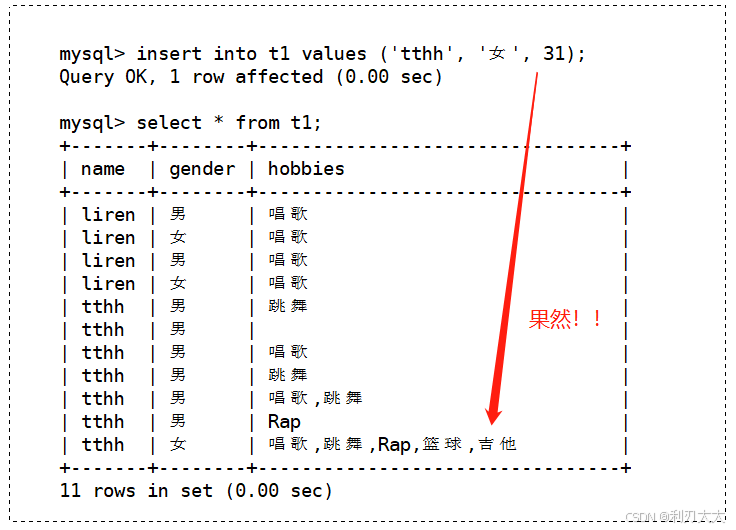
2、set的查询:find_in_set()
现在我们有一个要求,就是查询当前结果集中含有 ‘跳舞’ 的结果,如下所示:
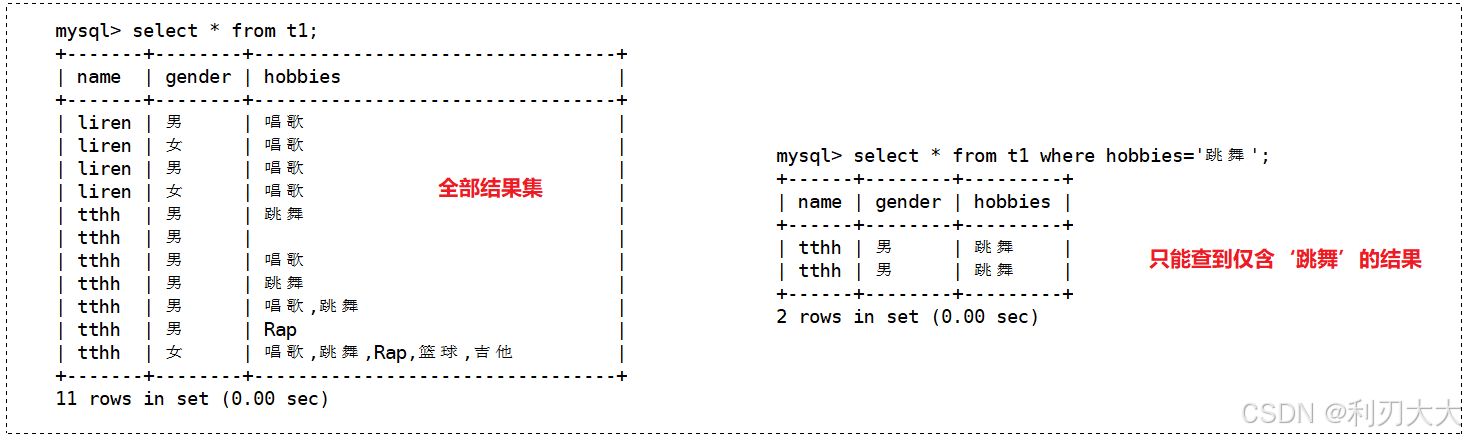
可以看到,where 语句(这个后面会讲!)已经没办法很好的帮我们查询出来了。
此时我们就要借用一个函数 find_in_set(),其 用于在逗号分隔的字符串列表中查找指定值的 MySQL 函数。它的功能是返回指定值在字符串列表中的位置。
函数语法如下所示:
find_in_set(value, string_list) 其中,value 是要查找的值,string_list 是逗号分隔的字符串列表。
函数返回一个整数值,表示 value 在 string_list 中的位置。如果找到了匹配的值,则返回其下标;如果未找到匹配的值,则返回 0。
比如说这样子用:

所以我们就可以 用该函数配合 where 语句和 and 语句来查找对应的集合选项:

本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-01-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
