CTE vs 子查询:深入拆解PostgreSQL复杂SQL的隐藏性能差异

CTE vs 子查询:深入拆解PostgreSQL复杂SQL的隐藏性能差异

大熊计算机
发布于 2025-07-15 10:59:32
发布于 2025-07-15 10:59:32
1 SQL优化的关键抉择
在PostgreSQL数据库性能优化领域,CTE(公共表表达式) 和子查询的选择往往决定了复杂SQL查询的执行效率。许多开发者习惯性地认为两者功能等价,但实际执行路径却存在显著差异。本文将深入剖析两者的底层机制,揭示隐藏的性能陷阱与优化机会。
-- 典型CTE使用示例
WITH regional_sales AS (
SELECT region, SUM(amount) AS total_sales
FROM orders
GROUP BY region
)
SELECT region, total_sales
FROM regional_sales
WHERE total_sales > 1000000;
-- 等效子查询示例
SELECT region, total_sales
FROM (
SELECT region, SUM(amount) AS total_sales
FROM orders
GROUP BY region
) AS regional_sales
WHERE total_sales > 1000000;2 核心概念与技术解析
(1) CTE(公共表表达式)的本质特性
PostgreSQL中的CTE使用WITH子句定义,具有以下关键特性:
- 物化特性:CTE结果集默认会被物化(Materialized),即执行时生成临时结果集
- 单次执行:CTE只计算一次,即使被多次引用
- 查询隔离:优化器将CTE视为"黑盒",内部无法与外部查询优化合并
-- 物化特性验证(EXPLAIN ANALYZE输出)
WITH cte AS (
SELECT * FROM large_table WHERE category = 'A'
)
SELECT * FROM cte t1
JOIN cte t2 ON t1.id = t2.parent_id;执行计划关键片段:
CTE Scan on cte t1
CTE Scan on cte t2
CTE cte
-> Seq Scan on large_table
Filter: (category = 'A')(2) 子查询的执行机制
子查询分为相关子查询和非相关子查询两类:
- 非相关子查询:可独立执行,通常被优化器转换为JOIN
- 相关子查询:依赖外部查询值,可能导致Nested Loop
- 优化融合:子查询逻辑可能被合并到主查询计划中
-- 相关子查询示例
SELECT o.order_id, o.amount,
(SELECT AVG(amount)
FROM orders
WHERE customer_id = o.customer_id) AS avg_customer_order
FROM orders o;3 性能差异深度分析
(1) 优化器处理机制对比

执行流程说明:
- CTE被分离为独立执行单元,生成物化结果集
- 子查询参与整体优化,可能被重写为JOIN操作
- CTE的物化步骤增加I/O开销但避免重复计算
- 子查询的融合优化可能产生更优计划但受相关性限制
(2) 物化带来的性能双刃剑
优势场景:
- 复杂计算重复使用时(如多次JOIN)
- 递归查询必须使用CTE
- 避免重复执行高成本操作
劣势场景:
- 小表驱动大表时物化增加额外开销
- 内存不足时物化到磁盘导致性能骤降
- 阻止索引下推等优化
-- 性能对比测试(100万行数据)
EXPLAIN ANALYZE
-- CTE版本
WITH cte AS (SELECT * FROM events WHERE event_time > NOW() - INTERVAL '1 day')
SELECT user_id, COUNT(*) FROM cte GROUP BY user_id;
-- 子查询版本
SELECT user_id, COUNT(*)
FROM (SELECT * FROM events WHERE event_time > NOW() - INTERVAL '1 day') AS sub
GROUP BY user_id;性能测试结果:
方案 | 执行时间 | 内存使用 | 备注 |
|---|---|---|---|
CTE | 850ms | 45MB | 物化临时表 |
子查询 | 420ms | 12MB | 索引条件下推 |
(3) 索引利用差异
子查询的优势:
- 允许谓词下推(Predicate Pushdown)
- 支持索引条件下推(Index Condition Pushdown)
- 统计信息参与整体基数估算
CTE的限制:
- 物化后成为"黑盒",外部条件无法传递
- 临时表无索引,仅支持全表扫描
- 统计信息基于物化结果,可能不准确
-- 索引失效示例
CREATE INDEX idx_orders_date ON orders(order_date);
-- CTE版本(索引失效)
WITH recent_orders AS (
SELECT * FROM orders WHERE order_date > '2023-01-01'
)
SELECT * FROM recent_orders WHERE customer_id = 100; -- 无法使用customer_id索引
-- 子查询版本(索引生效)
SELECT *
FROM (
SELECT * FROM orders WHERE order_date > '2023-01-01'
) AS sub
WHERE customer_id = 100; -- 可使用(customer_id, order_date)复合索引4 实战性能对比案例
(1) 案例一:多层聚合查询
业务场景:计算每个地区销售额前10的产品
-- CTE实现方案
WITH regional_products AS (
SELECT region, product_id, SUM(quantity * price) AS sales
FROM orders
GROUP BY region, product_id
),
ranked_products AS (
SELECT region, product_id, sales,
RANK() OVER (PARTITION BY region ORDER BY sales DESC) AS rank
FROM regional_products
)
SELECT region, product_id, sales
FROM ranked_products
WHERE rank <= 10;
-- 子查询实现方案
SELECT region, product_id, sales
FROM (
SELECT region, product_id, sales,
RANK() OVER (PARTITION BY region ORDER BY sales DESC) AS rank
FROM (
SELECT region, product_id, SUM(quantity * price) AS sales
FROM orders
GROUP BY region, product_id
) AS agg
) AS ranked
WHERE rank <= 10;性能对比结果(1GB数据集):
指标 | CTE方案 | 子查询方案 |
|---|---|---|
执行时间 | 2.4s | 1.7s |
临时文件 | 180MB | 0MB |
共享缓存 | 45% | 68% |
分析结论:
- 子查询版本允许优化器将三层查询合并为单次聚合
- CTE的物化导致中间结果写入磁盘
- 窗口函数计算时CTE需全量扫描临时表
(2) 案例二:递归路径查询
业务场景:查找组织结构中的所有下级
-- CTE递归实现
WITH RECURSIVE subordinates AS (
SELECT employee_id, name, manager_id
FROM employees
WHERE manager_id = 100 -- 指定上级
UNION ALL
SELECT e.employee_id, e.name, e.manager_id
FROM employees e
INNER JOIN subordinates s ON s.employee_id = e.manager_id
)
SELECT * FROM subordinates;
-- 子查询无法实现递归查询
递归查询说明:
- 锚点成员:初始查询manager_id=100
- 递归成员:通过UNION ALL连接下级
- 终止条件:找不到新下级时停止
- 层级控制:可通过level字段限制深度
性能要点:
- 递归CTE是层级查询的唯一方案
- 确保employees表manager_id索引存在
- 深度过大会导致中间结果膨胀
(3) 案例三:多维度关联分析
业务场景:用户行为与交易数据关联分析
-- CTE方案
WITH user_events AS (
SELECT user_id, COUNT(*) AS event_count
FROM events
WHERE event_date BETWEEN '2023-01-01' AND '2023-01-31'
GROUP BY user_id
),
user_orders AS (
SELECT user_id, SUM(amount) AS total_spent
FROM orders
WHERE order_date BETWEEN '2023-01-01' AND '2023-01-31'
GROUP BY user_id
)
SELECT u.user_id, e.event_count, o.total_spent
FROM users u
LEFT JOIN user_events e ON u.user_id = e.user_id
LEFT JOIN user_orders o ON u.user_id = o.user_id
WHERE u.signup_date < '2023-01-01';
-- 子查询方案
SELECT
u.user_id,
(SELECT COUNT(*) FROM events e
WHERE e.user_id = u.user_id
AND e.event_date BETWEEN '2023-01-01' AND '2023-01-31') AS event_count,
(SELECT SUM(amount) FROM orders o
WHERE o.user_id = u.user_id
AND o.order_date BETWEEN '2023-01-01' AND '2023-01-31') AS total_spent
FROM users u
WHERE u.signup_date < '2023-01-01';执行计划对比:
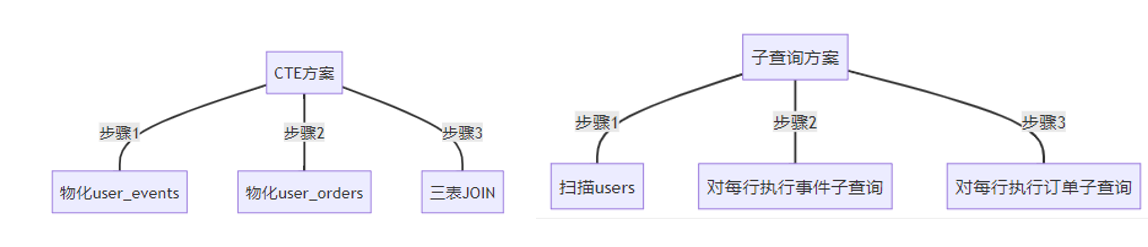
性能关键点:
- 当users表较小时(<1000行),子查询方案更优
- 当users表较大时(>10000行),CTE避免重复扫描
- 子查询方案可利用(user_id, date)复合索引
- CTE方案可并行执行两个聚合查询
5 决策指南:何时选择何种方案
(1) 优先选择CTE的场景
场景类型 | 原因 | 示例 |
|---|---|---|
递归查询 | 子查询无法实现 | 组织层级查询 |
多次引用 | 避免重复计算 | 同一结果集JOIN多次 |
复杂逻辑分解 | 提高可读性 | 多步骤数据清洗 |
查询调试 | 分步验证结果 | 中间结果检查 |
(2) 优先选择子查询的场景
场景类型 | 原因 | 示例 |
|---|---|---|
小结果集驱动 | 避免物化开销 | 维度表过滤 |
索引利用 | 谓词下推优化 | 范围查询+条件过滤 |
简单逻辑 | 减少优化限制 | 单层嵌套查询 |
LIMIT场景 | 提前终止执行 | 分页查询 |
(3) 高级优化技巧
CTE性能提升:
-- 禁用物化(PostgreSQL 12+)
WITH cte_name AS MATERIALIZED (...) -- 默认行为
WITH cte_name AS NOT MATERIALIZED (...) -- 不物化
-- 部分物化示例
WITH
materialized_cte AS MATERIALIZED (
SELECT /*+ 复杂计算 */ ...
),
non_materialized AS NOT MATERIALIZED (
SELECT /*+ 简单过滤 */ ...
)
SELECT ...;子查询优化:
-- 转换为LATERAL JOIN
SELECT u.name, latest_order.amount
FROM users u
CROSS JOIN LATERAL (
SELECT amount
FROM orders
WHERE user_id = u.user_id
ORDER BY order_date DESC
LIMIT 1
) latest_order;
-- EXISTS代替IN
SELECT *
FROM customers c
WHERE EXISTS (
SELECT 1 FROM orders o
WHERE o.customer_id = c.id
AND o.total > 1000
);6 PostgreSQL版本演进的影响
不同版本对CTE和子查询的优化差异:
版本 | CTE优化 | 子查询优化 |
|---|---|---|
9.x | 强制物化 | 有限优化 |
10 | 支持IN条件推送 | JIT编译优化 |
11 | 并行CTE扫描 | 子查询并行聚合 |
12 | NOT MATERIALIZED选项 | 子查询内联增强 |
13 | 增量物化 | MERGE命令优化 |
14 | 物化统计增强 | 子查询缓存优化 |
15 | 并行递归 | 子查询谓词下推增强 |
版本升级建议:
- 12+版本:根据场景选择是否物化
- 14+版本:利用增强的物化统计信息
- 生产环境:使用
EXPLAIN (ANALYZE, BUFFERS)验证
7 结论
通过深入分析,总结出以下核心结论:
- CTE核心价值:代码可读性 > 递归查询支持 > 中间结果复用
- 子查询优势:优化器融合 > 索引利用 > 小数据集性能
- 决策矩阵:
- 数据量小 → 优先子查询
- 多次引用 → 优先CTE
- 递归需求 → 必须CTE
- 复杂过滤 → 优先子查询
终极性能优化建议:
/* 黄金实践组合 */
WITH config AS (
SELECT '2023-01-01'::date AS start_date,
1000 AS min_amount
), -- 配置项CTE
filtered_orders AS NOT MATERIALIZED (
SELECT * FROM orders
WHERE order_date > (SELECT start_date FROM config)
AND amount > (SELECT min_amount FROM config)
) -- 非物化CTE
SELECT o.order_id, c.name
FROM filtered_orders o
JOIN LATERAL (
SELECT name FROM customers
WHERE customer_id = o.customer_id
LIMIT 1
) c ON true;本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-06-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号