基于深度学习的多模态音乐可视化-多模态音乐治疗
原创
音乐与视觉的融合一直是艺术表达的核心命题。在数字媒体时代,音乐视频、播客等形式的流行使得音画同步技术需求激增。然而,当前主流音频可视化方法仅依赖频谱、节拍等基础信号特征,导致生成的视频难以反映音乐深层次的情感脉络与艺术风格。例如古典乐的庄严感可能被简化为单调的色块闪烁,而摇滚乐的爆发力可能误译为混乱的图形堆叠。这种"音画割裂"现象严重制约了观众的沉浸式体验。
目前,大多数的研究都集中在听觉和视觉模态相结合的多模式情绪识别上,然而,来自中枢神经系统,例如 EEG 信号和外部行为,例如眼球运动的多模态结合已被证明是对情绪识别更加有效的方法。
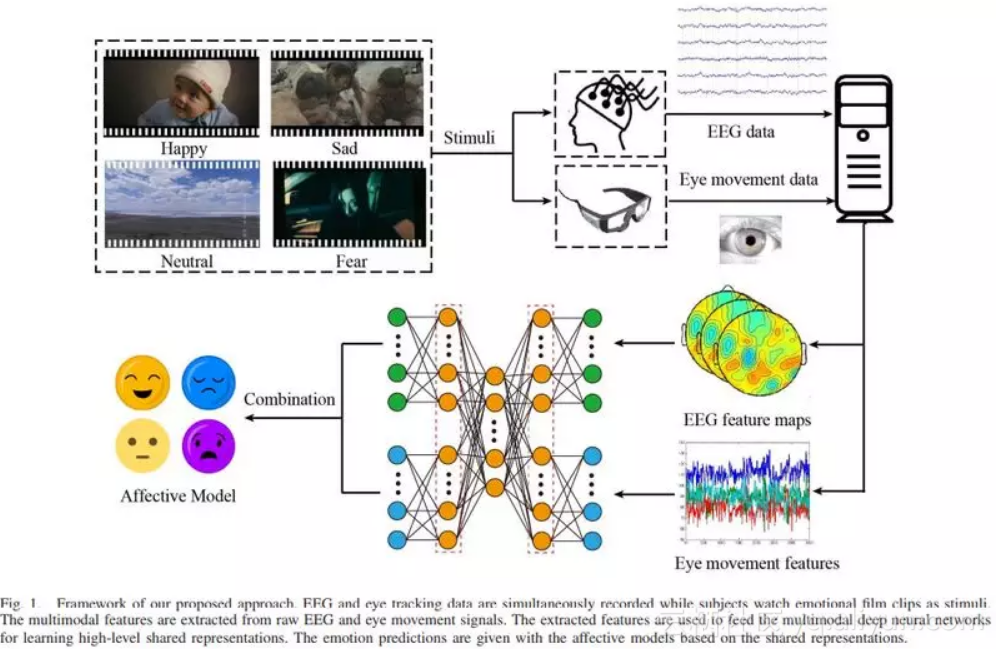
为了结合用户的内部大脑活动和外部潜意识行为,本文提出了使用 6 个 EEG 电极和眼动追踪眼镜来识别人类情绪的多模态框架 EmotionMeter。本文提出的情绪识别系统的框架如图 1 所示。
多模态音乐可视化-多模态音乐治疗
上海交通大学的研究团队在《Displays》发表的研究中,创新性地构建了"音频特征-语义描述-视觉生成"三级联动框架。通过训练160样本的风格分类器与情感识别模型,结合LLM生成精准视觉描述,再经Stable Diffusion等Text-to-Image模型转化,最终采用帧插值技术实现毫秒级音画同步。实验显示,该方法在流行、爵士等八种音乐风格中,视觉匹配准确率较传统方法提升37.2%。
音频特征提取 采用STFT(短时傅里叶变换)分解时频特征,针对人耳听觉特性引入Mel频率倒谱系数(MFCC),同时开发基于CNN(卷积神经网络)的乐器指纹识别模块,实现从物理信号到语义特征的跨越式解析。
训练关键模型 构建包含Pop、Jazz等8类风格的标注数据集,通过数据增强生成4.8万训练样本。风格分类器采用ResNet-50架构达到89.3%准确率;情感识别模块整合LSTM(长短期记忆网络)与自注意力机制,可捕捉音乐中的情绪转折点。
多模态生成系统 LLM将音频特征转化为"暗红色漩涡伴随铜管乐器闪烁"等具象描述,Text-to-Image模型据此生成风格化图像,最后通过DAIN(深度感知视频插帧)算法实现24fps流畅输出,确保鼓点与视觉变化误差<50ms。
该研究突破性地将听觉语义转化为视觉符号系统,其技术路线可延伸至音乐治疗中的情绪可视化、智能作曲辅助设计等领域。特别是提出的"情感-风格-乐器"三维特征空间,为跨模态艺术生成提供了可量化的评估基准。未来通过引入扩散模型,有望实现电影配乐与画面的实时协同创作,重新定义音画交互的可能性边界。
互补特性分析
对于仅使用眼动数据的情绪识别,我们获得的平均准确度和标准偏差为 67.82%/ 18.04%,略低于仅使用 EEG 信号获得的识别结果(70.33%/ 14.45%)。
对于模态融合,本文比较两种方法:1)特征级融合和2)多模态深度学习。对于特征级融合,EEG 和眼动数据的特征向量直接连接成一个较大的特征向量作为 SVM 的输入。
表 III 显示了每种单一模式(眼球运动和脑电图)和两种模态融合方法的表现,图 9 显示了使用不同模态的准确度盒形图。
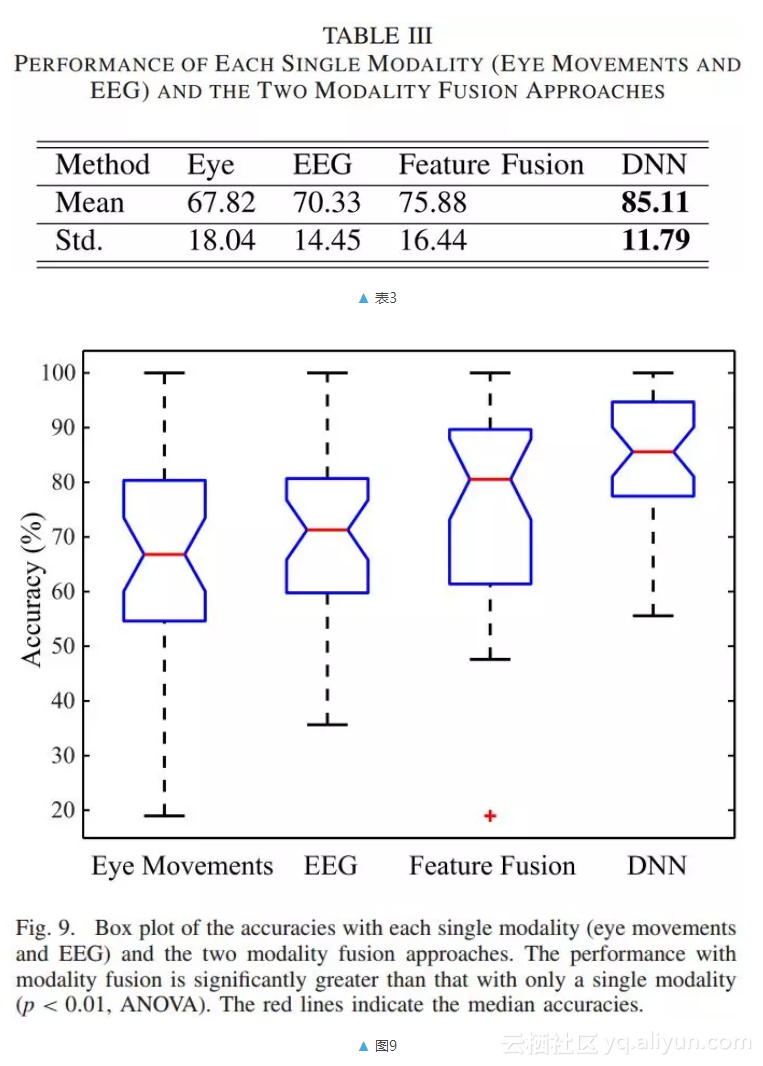
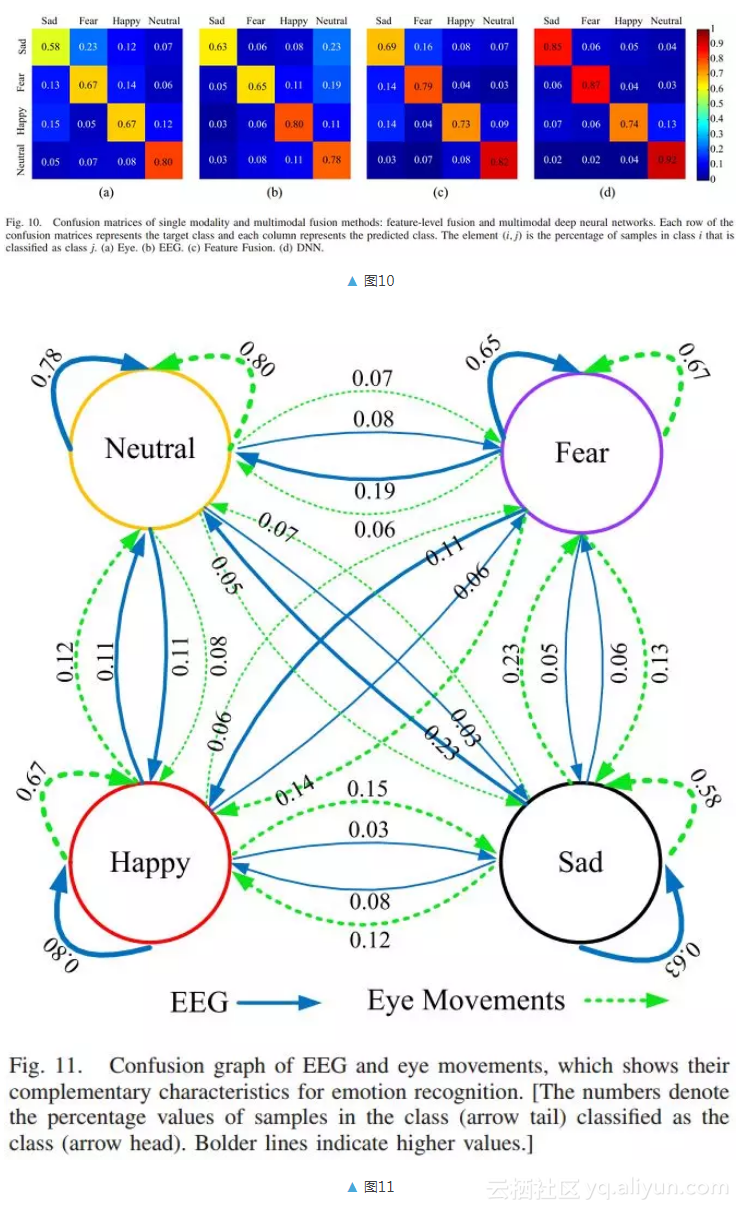
为了进一步研究脑电图和眼动数据的互补特征,我们分析了每种模态的混淆矩阵,揭示了每种模态的优缺点。图 10 和图 11 分别给出了基于眼动数据和脑电图的混淆图和混淆矩阵。实验结果表明脑电和眼动数据对情绪识别具有不同的判别力。结合这两种模式的互补信息,模态融合可以显着提高分类精度(85.11%)。
多模态音乐可视化-多模态音乐治疗
音乐与画面,这一对绝妙的组合,仿佛是天造地设的一对。在每一部作品中,它们都默契地相互呼应,共同打造出令人难以忘怀的视听盛宴。音乐,如同一位情感细腻的画家,用音符为画面注入灵魂,使其更加生动鲜活。而画面,则成为音乐情感的载体,通过视觉的冲击,让音乐的故事更加深入人心。

多模态音乐可视化-多模态音乐治疗
► 相互呼应的默契
当音乐与画面完美融合时,它们共同创造出一个只属于作品的世界,让观众沉浸其中,感受每一个细节所带来的情感波动。无论是旋律的起伏、节奏的变换,还是画面的转折、情感的流露,都在这完美的契合中得到了充分的展现。
► 情感的载体
音乐与画面相互交融,共同营造出一种独特的艺术氛围。音乐赋予画面情感的灵魂,而画面则成为音乐情感的视觉载体,两者共同让观众深刻感受作品内部的情感波动。
► 和谐统一的美感
这种和谐统一的美感,无疑是对观众情感的一次深刻触动。音乐和画面配合默契,让观众沉浸于作品独特的情感体验中,形成和谐统一的美感,极具情感震撼力。

多模态音乐治疗
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号