有什么比绕开网络更快?第0层存储!


在科技领域,你要么开辟新的道路,要么被困在拥堵中。第0层存储(Tier 0)不仅清理了道路上的障碍,还建造了高速公路。它消除了低效率,粉碎了瓶颈,释放了GPU的真正力量。MLPerf1.0基准结果(详见:Hammerspace使用服务器本地NVMe磁盘打造全局共享存储,在MLPerf1.0基准中创造新纪录)明确了一件事:Tier 0不是增量改造,而是一场技术创新。
1.几乎没有CPU负载
英伟达CEO黄仁勋有一句名言:“让GPU闲置是一种罪过”。Tier 0仅使用标准Linux内核,即可将服务器处理器利用率降至几乎为零。想象一下,在不对计算资源产生巨大负荷的情况下运行大量工作负载,那是纯粹的效率提升。
这不是理论上的数据,而是可以在客户生产中看到的,也是我们在验室中得到证实的。使用Tier 0,服务器可以完成它们应该做的事情:计算和运行人工智能模型,而不是浪费存储时间。
2.单个Tier 0客户端的性能优于整个Lustre集群配置
这是令人瞠目结舌的结果:单个第0层客户端:只有1个标准Linux服务器客户端节点就比4个OSS节点、8个OST节点和18个客户端的Lustre集群多支持10%的H100 GPU数量。
当我们扩大Tier 0的客户端数量后,使其与Lustre集群客户端数量一样,均为18个,此时您将可支持比Lustre多20倍的H100 GPU数量,这不是渐进式的提升,而是无与伦比的加速。
而且不需要额外的硬件,Tier 0只是利用您已经在GPU服务器上的存储空间(本地NVMe磁盘)。通过解锁你已经拥有的磁盘而已,因为客户在购买GPU服务器时就已经选配了这些NVMe磁盘,但这些磁盘严重利用不足,Tier 0技术改变了这一切,唤醒了一只在沉睡的猛兽。
这不仅仅是小聪明,而是改变了游戏规则。
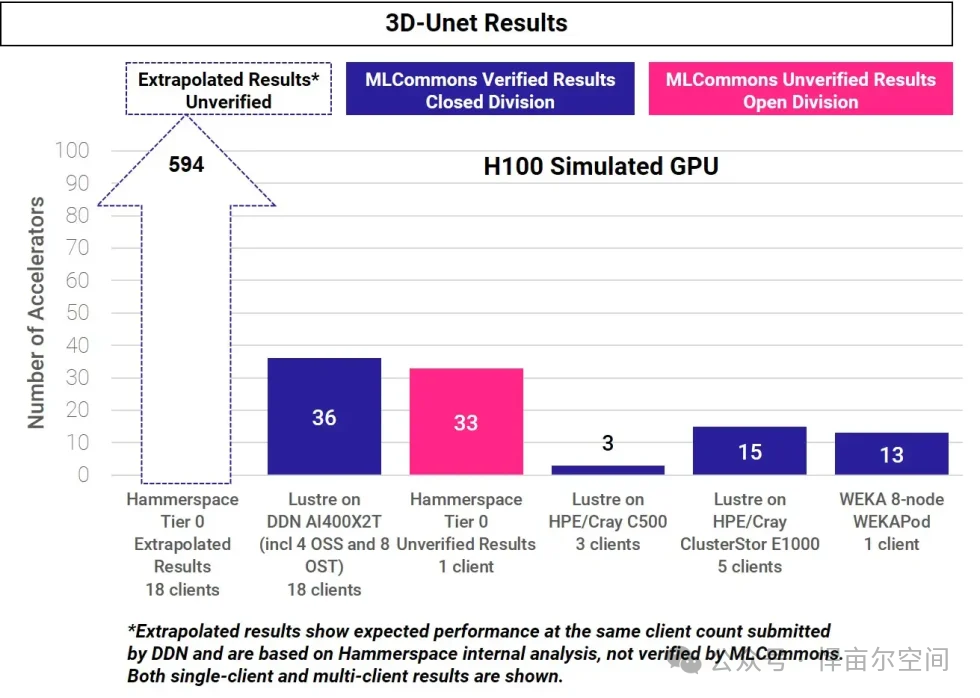
《与Lustre同为18个客户端情况下,支持GPU数量是其约20倍》
3.再见!网络限制
网络是带宽密集型工作负载中GPU计算的关卡,Tier 0通过完全消除网络依赖性来打破关卡。传统场景下均在2x100GbE接口上受阻,但Tier 0不需要它们。本地NVMe磁盘允许GPU全速运行,而无需等待数据通过网络管道。
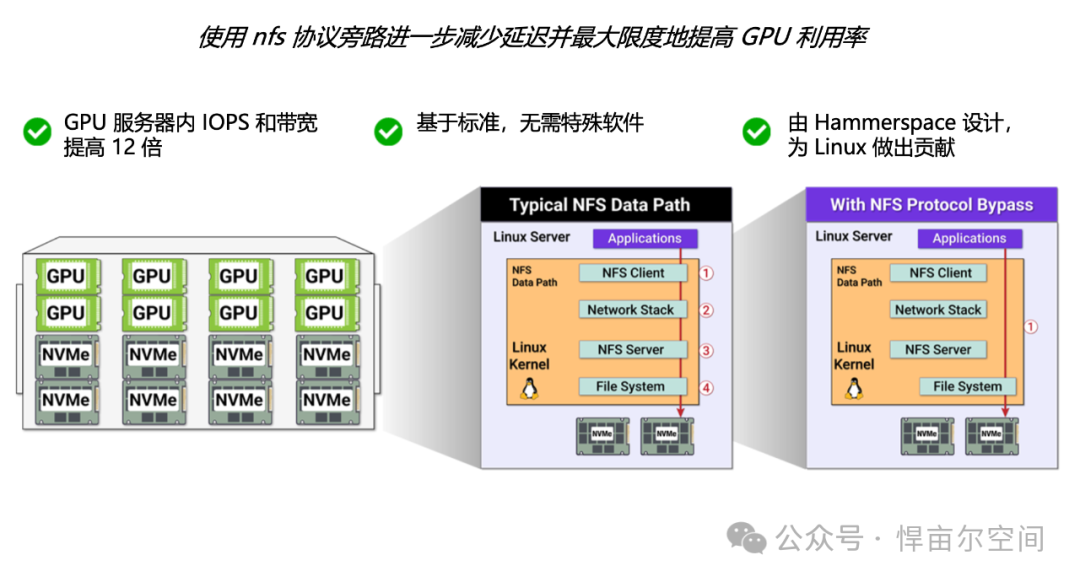
4.线性可扩展性,人工智能和HPC的最佳选择
什么比缩放更好?可预测地缩放!Tier 0为您提供线性性能缩放,把你的GPU翻倍?将您的吞吐量翻倍,简单的数学,由下一代NAS架构开始。
实际上,Tier 0将检查点持续时间从分钟缩短到几秒钟,这是巨大的进步。在检查点上节省的每一秒都是GPU可以花在训练模型或运行模拟上的另一秒钟。
5.更高的效率,更明智的投资
这不仅仅是关于效率,而是关于进行更明智的投资。Tier 0的架构通过以下方式节省了CapEx和OpEx:
使用您已经拥有的硬件,无需新的基础设施,没有大规模的网络升级,没有增加复杂性。如果您的GPU服务器已经配置了NVMe磁盘,Tier 0将充分发挥其潜力。
减少对高性能外部存储的需求,通过最大化GPU本地存储,组织可以节省昂贵的硬件、网络、电力和冷却。
加快任务处理速度,更快的性能意味着所需的GPU更少,可以把预算投入到其它需要的地方。
第0层存储(Tier 0)不但提供极高性能,它还可以无缝集成到第1层和归档层等外部存储中。Hammerspace将所有存储层统一为一个单一命名空间和全局文件系统(详细请查阅:标准Linux + Hammerspace: 开启基于标准的高性能存储新时代)。
腾讯云开发者
