突破语音智能体前沿,腾讯AI Lab与港科大两项研究入选国际学术顶会

突破语音智能体前沿,腾讯AI Lab与港科大两项研究入选国际学术顶会

小腾资讯君
发布于 2025-09-02 08:48:55
发布于 2025-09-02 08:48:55
智能体与语音研究的结合,可以碰撞出怎么样的火花。最近,腾讯AI Lab与港科大(广州)共同推出的两项研究给出了答案。
【研究1】AudioGenie: 一个多样化多模态到多音频生成的无需训练的多智能体框架
Paper: https://arxiv.org/abs/2505.22053
Project page: https://audiogenie.github.io/
腾讯AI Lab联合香港科技大学(广州)共同发表论文《AudioGenie: A Training-Free Multi-Agent Framework for Diverse Multimodality-to-Multiaudio Generation》。该研究在多模态到多音频生成(MultiModality-to-MultiAudio, MM2MA)领域取得了重要突破,旨在解决从视频、图像、文本等多种输入形式,生成包含音效、语音、音乐、歌曲等多种类型组合的、与情境高度匹配的音频这一核心难题。该论文已被ACM MM2025接收。
研究背景与挑战
图片
多模态到多音频生成(MM2MA)是人机交互、游戏开发、影视制作及VR/AR等前沿应用的关键技术。然而,该领域长期面临三大挑战:
• 精细化理解挑战:现有模型难以对复杂的多模态输入(尤其是视频)进行深入、细致的理解,无法精准捕捉时空维度上的关键信息。
• 任务多样性挑战:单一模型难以胜任音效、语音、音乐、歌曲等不同类型音频的生成任务,而不同模型各有所长,缺乏一个统一、高效的协作框架。
• 输出可靠性挑战:传统生成流程多为单次通过,缺乏有效的自我修正和迭代优化机制,导致输出质量不稳定、错误难以纠正。
核心框架
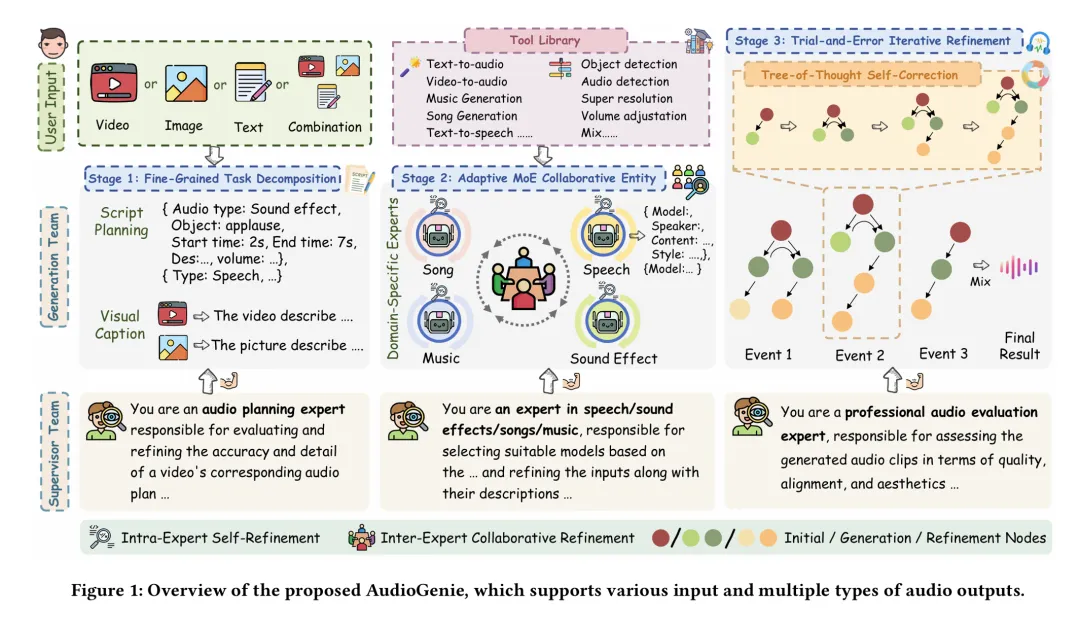
为应对上述挑战,研究团队创新性地提出了 AudioGenie,一个无需训练的多智能体系统。其核心思想是构建一个由“生成团队”和“监督团队”组成的双层协作架构,通过严谨的流程化设计,确保音频生成的高质量与高保真度。
图片
AudioGenie的核心创新组件包括:
1. 精细化任务分解模块 (Fine-Grained Task Decomposition):
在第一阶段,框架首先对输入的多模态信息进行系统性分析,将其分解为一系列具体的、可管理的音频子事件。每个子事件都被精确标注了音频类型、起止时间、内容描述等信息,形成结构化的生成蓝图,为后续的精准生成奠定基础。
2. 自适应混合专家协作实体 (Adaptive MoE Collaborative Entity):
在第二阶段,系统将分解后的子任务分配给相应的领域专家(如音效专家、语音专家等)。每个专家基于其专业知识,从工具库中自适应地选择最适合的SOTA模型。该模块引入了“专家内自我修正”与“专家间协作修正”机制,通过多方位的审视与协同,优化并确定最终的生成方案。
3. 试错与迭代优化模块 (Trial-and-Error Iterative Refinement):
在最终生成阶段,框架采用基于“思维树(Tree-of-Thought)”的迭代优化流程。系统会生成候选音频,并由监督团队从质量、对齐度、美学等维度进行评估。若存在瑕疵,系统将自动触发修正或重试流程,通过不断的评估、纠错和迭代,直至输出满足要求,从而显著提升最终生成结果的可靠性与质量。
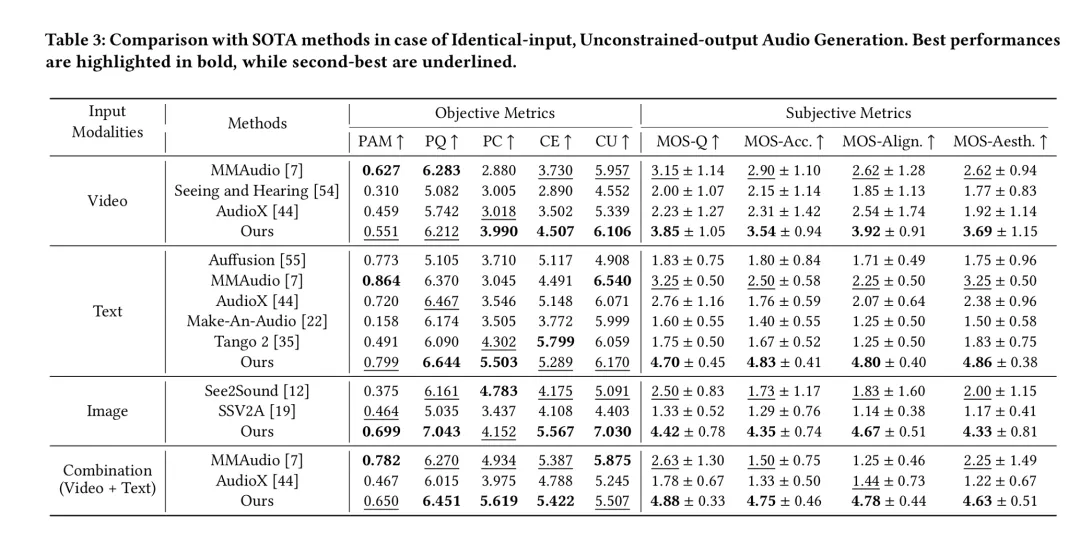
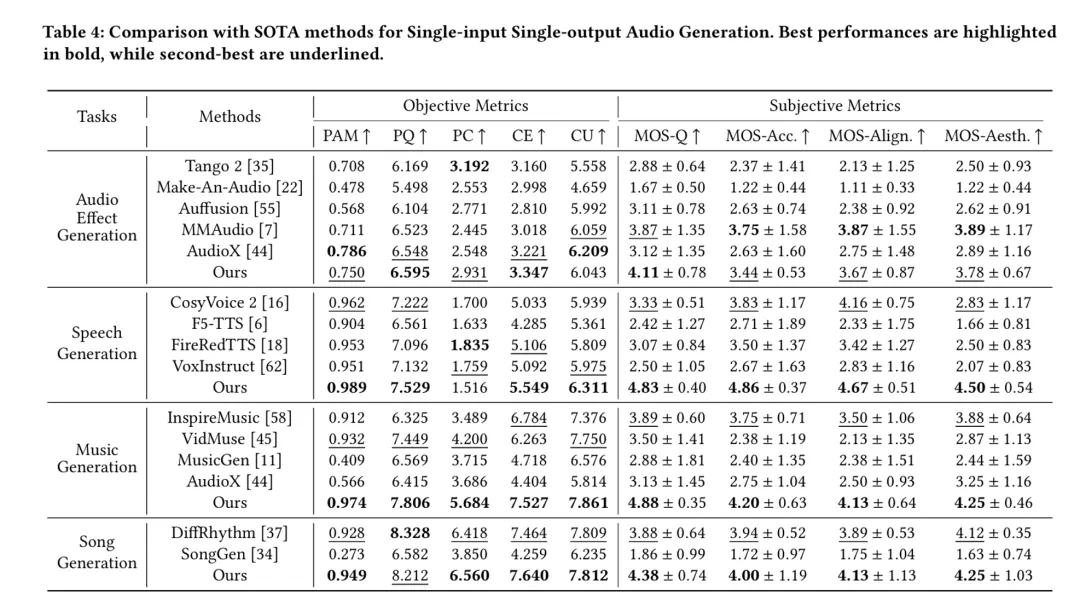
实验结果
为了对AudioGenie进行全面评估,研究团队构建了该领域的首个评测基准 MA-Bench,其中包含198个经过专业标注、涵盖多种音频类型的视频。

图片
大量客观与主观实验结果表明,与现有方法相比[1,2,3,4],AudioGenie在多项关键指标上均达到最佳(SOTA)或相当的性能。
图片
图片
AudioGenie不仅能够更完整、更准确地生成与多模态输入同步的音频事件,并且在生成的音频质量、时空对齐精度和艺术表现力上均展现出明显优势。
,时长03:20
价值与展望
AudioGenie作为一种无需训练、数据友好的MM2MA生成方案,极大地降低了高质量、多类型音频内容的创作门槛。这项研究成果在游戏场景制作、影视后期合成、虚拟人交互等领域拥有广阔的应用前景。
参考文献
[1] Cheng H K, Ishii M, Hayakawa A, et al. MMAudio: Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis[C]//Proceedings of the Computer Vision and Pattern Recognition Conference. 2025: 28901-28911.
[2] Tian Z, Jin Y, Liu Z, et al. Audiox: Diffusion transformer for anything-to-audio generation[J]. arXiv preprint arXiv:2503.10522, 2025.
[3] Tian Z, Liu Z, Yuan R, et al. Vidmuse: A simple video-to-music generation framework with long-short-term modeling[C]//Proceedings of the Computer Vision and Pattern Recognition Conference. 2025: 18782-18793.
[4] Ning Z, Chen H, Jiang Y, et al. DiffRhythm: Blazingly fast and embarrassingly simple end-to-end full-length song generation with latent diffusion[J]. arXiv preprint arXiv:2503.01183, 2025.

图片
【研究2】:Cued-Agent:用于自动线索语识别的协作多智能体系统
Paper: Cued-Agent: A Collaborative Multi-Agent System for Automatic Cued Speech Recognition
地址:https://arxiv.org/abs/2508.00391
本研究工作由腾讯 AI Lab 联合香港科技大学(广州)师生共同完成,被国际计算机学会主办的多媒体领域顶级会议ACM Multimedia 2025接收。

图片
图1 . Cued-Agent 整体架构
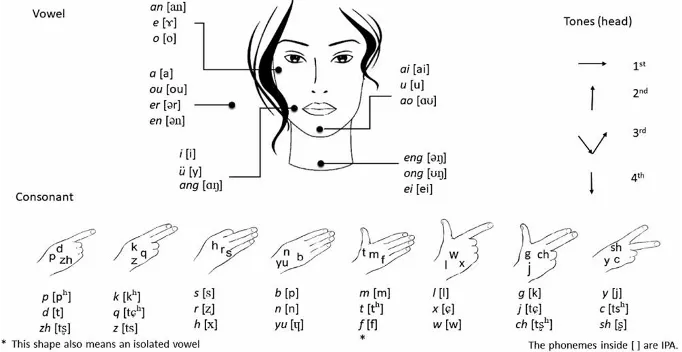
线索语(Cued Speech, CS)是一种视觉沟通系统,它结合手部编码和唇读,帮助听障人士进行交流[1]。与编码语义的手语系统相比,线索语系统直接对文本读音进行编码,通过特定手部动作对元音和辅音进行可视化表达,让人们在大脑当中建立与发音的联系,从而让听障人士理解文字,掌握和使用正常的语言。 因其准确性与易于学习的特性,自1967年起源于美国后,线索语被广泛拓展并应用于60多种语言。在中文线索语系统中,8种手部形状和5个手部位置分别编码了辅音与元音音素。
图片
图2. 中文线索语系统

图片
图3.线索语交流样例
自动线索语识别(Automatic Cued Speech Recognition, ACSR)旨在利用人工智能驱动的方法,将线索语中的手势和唇部运动自动转换成文字[2]。传统方法受限于数据规模,无法充分训练复杂的融合机制,不足以解决线索语识别中手部和唇部动作之间天然存在的时序不同步问题。 并且,相关算法仅建立视频与音素序列的映射,导致了语义模糊,降低了沟通效率。
为应对上述挑战,本研究首次将多智能体系统引入ACSR领域,提出了名为Cued-Agent的框架。它通过集成四个相互协作的子智能体,有效将ACSR任务根据特性进行解耦,构建了低训练成本的识别框架。它们分别是:手部识别智能体,唇部识别智能体,手部提示解码智能体以及音素到词语自校正智能体.
图片
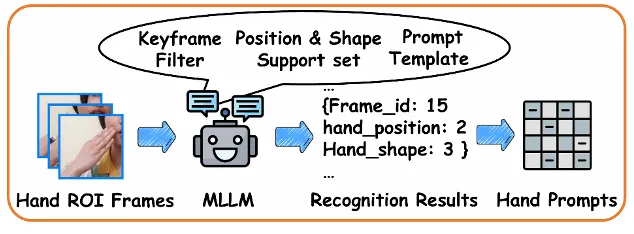
图4. 手部识别智能体
基于多模态大语言模型的手部识别智能体接收手部区域视频作为输入,利用关键帧筛选和专家提示策略将复杂的手部运动识别任务简化为手部形状和位置分类任务,以无需训练的方式解码手部动作,获取手部提示矩阵。
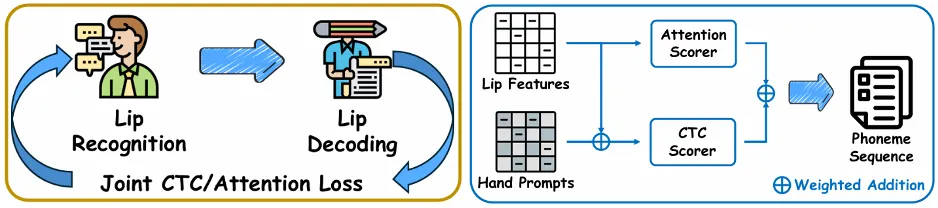
图片
图5. 唇部识别微调过程及手部提示解码代理中的无参数手唇联合解码
基于预训练Transformer的唇语识别智能体和解码器仅需使用唇部视频进行微调,在推理阶段即可进行精准的唇部特征提取。
手部提示解码智能体,接收唇部特征和手部提示,输出预测的音素序列。它创新的利用手部提示矩阵加权唇部特征解码过程,首次以无需额外训练和参数的方式实现了手部-唇部信息联合解码,避免了复杂且高成本的融合模块训练。
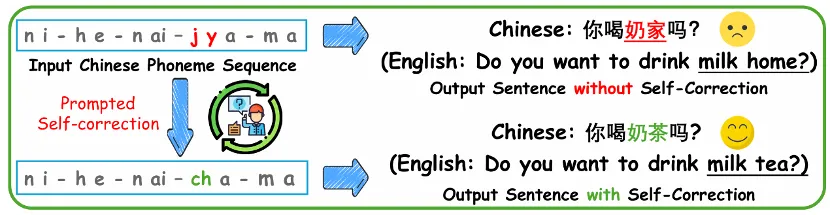
图片
图6. 音素到词语自校正智能体。结合语法和语义规范,智能体对音素序列进行细微修正,并输出语义连贯的自然语句。
基于大语言模型的音素到词语自校正智能体通过语义和语法规则对音素序列进行后处理,让Cued-Agent首次实现了从视频序列到自然语言句子的自校正转换。
实验证明,无论是在正常还是听障测试场景下,Cued-Agent均表现出色,验证了其在真实应用场景中的有效性和鲁棒性。
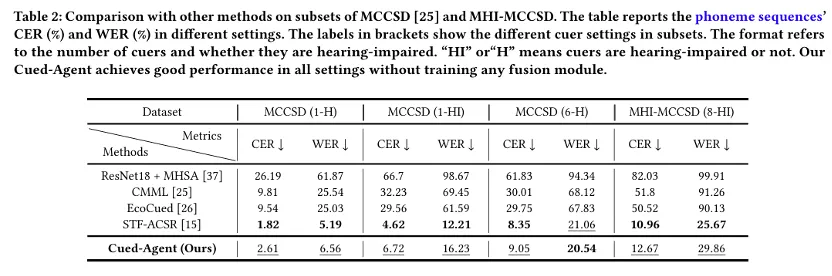
图片
此外,该研究还首次提出了两项新的自然语句评估指标:句子词错误率(S-WER)和语义分数(Semantic Score),用以更全面地评估生成句子的准确性和语义相似性。

图片
Cued-Agent的提出,不仅为自动线索语识别技术开辟了新的研究范式,也为开发更智能、更人性化的听障辅助沟通工具奠定了坚实基础。这项工作展示了多智能体系统在处理复杂、数据受限的多模态任务中的巨大潜力。未来,该方法有望被扩展至其他语言的自动唇语识别系统中,惠及全球更广泛的听障人群。
参考文献
[1] R. Orin Cornett. 1967. Cued Speech. American Annals of the Deaf 112, 1 (1967), 3–13.
[2] Li Liu, Gang Feng, Denis Beautemps, and Xiao-Ping Zhang. 2020. Re-synchronization using the hand preceding model for multi-modal fusion inautomatic continuous cued speech recognition. IEEE Transactions on Multimedia 23 (2020), 292–305.
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号