[数据分析]用户分群与画像:聚类算法的实战应用
原创
[数据分析]用户分群与画像:聚类算法的实战应用
原创
I. 引言
用户分群是指将庞大的用户群体按照特定标准划分为具有相似特征的子群体的过程。通过分群,企业可以识别出高价值用户、潜在流失用户、新用户等不同群体,从而实施精准的市场策略。而用户画像则是基于用户的社会属性、行为特征、偏好习惯等多维度信息,构建出的标签化用户模型。
聚类算法作为无监督学习的重要分支,在用户分群与画像构建中发挥着不可替代的作用。与需要标注数据的监督学习方法不同,聚类算法能够自主发现数据中的内在结构和模式,特别适合处理海量、未标注的用户数据。
II. 聚类算法基础理论
2.1 聚类算法的数学原理
聚类分析的核心目标是将数据集中的对象分组,使得同一组(簇)内的对象相似度较高,而不同组之间的对象相似度较低。从数学角度,这可以形式化为一个优化问题。
给定数据集 X = \{x_1, x_2, ..., x_n\} ,其中每个数据点 x_i \in \mathbb{R}^d ,聚类算法旨在找到划分 C = \{C_1, C_2, ..., C_k\} ,使得目标函数最优化。对于K-means算法,其目标函数为:
J = \sum_{j=1}^{k} \sum_{x_i \in C_j} \|x_i - \mu_j\|^2
其中\mu_j 是簇 C_j 的质心,计算为:
\mu_j = \frac{1}{|C_j|} \sum_{x_i \in C_j} x_i
K-means算法通过迭代优化过程最小化目标函数J,具体步骤如下:
- 随机选择k个初始质心
- 将每个数据点分配到最近的质心所在的簇
- 重新计算每个簇的质心
- 重复步骤2-3直到质心不再显著变化或达到最大迭代次数
2.2 距离度量与相似性计算
在聚类算法中,距离度量是决定聚类效果的关键因素。常见的距离度量包括:
- 欧氏距离:最常用的距离度量,适用于连续型特征 $d(x,y) = \sqrt{\sum_{i=1}^{d}(x_i - y_i)^2}$
- 曼哈顿距离:对异常值更不敏感 d(x,y) = \sum_{i=1}^{d}|x_i - y_i|
- 余弦相似度:适用于文本和高维稀疏数据 \text{cosine}(x,y) = \frac{x \cdot y}{\|x\|\|y\|}
对于混合类型数据(包含数值型和分类型特征),需要采用特殊的距离度量方法,如Gower距离。
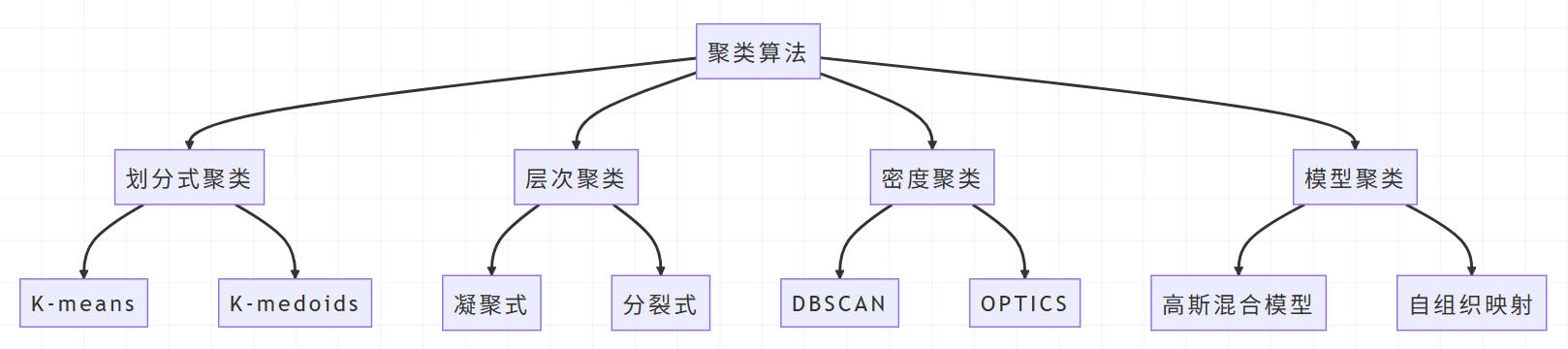
2.3 主要聚类算法分类
根据聚类原理的不同,聚类算法可以分为以下几类:
算法类型 | 代表算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
划分式聚类 | K-means, K-medoids | 计算效率高,适合大规模数据 | 需要预设簇数量,对初始值敏感 | 球形簇,均匀簇大小 |
层次聚类 | AGNES, DIANA | 不需要预设簇数,可视性好 | 计算复杂度高,难以处理大规模数据 | 小规模数据,需要层次结构 |
密度聚类 | DBSCAN, OPTICS | 能发现任意形状簇,抗噪声 | 对参数敏感,高维数据效果差 | 非球形簇,噪声数据 |
模型聚类 | GMM, SOM | 概率归属,理论基础强 | 计算复杂,可能过拟合 | 数据符合特定分布 |
2.4 聚类算法评估指标
评估聚类结果的质量是聚类分析中的重要环节。常用的评估指标包括:
- 内部指标:基于数据本身的特征评估
- 轮廓系数(Silhouette Coefficient)
- Calinski-Harabasz指数
- Davies-Bouldin指数
- 外部指标:与真实标签比较
- 调整兰德指数(Adjusted Rand Index)
- 标准化互信息(Normalized Mutual Information)
- 同质性(Homogeneity)和完整性(Completeness)
- 相对指标:用于确定最佳簇数
- 肘部法则(Elbow Method)
- 间隙统计量(Gap Statistic)
III. 数据准备与预处理
3.1 数据收集与理解
在实际的用户分群项目中,数据质量直接决定了分析效果。我们首先需要收集多源用户数据,并进行深入的理解和探索。
用户数据通常来源于多个渠道:
- 用户基本属性数据(年龄、性别、地域等)
- 用户行为数据(浏览、点击、购买等)
- 用户交易数据(订单金额、购买频次等)
- 用户社交数据(关注、分享、评论等)
在本实战案例中,我们使用一个模拟的电商用户数据集,包含以下关键字段:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.impute import SimpleImputer
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 生成模拟用户数据
np.random.seed(42)
n_users = 5000
# 用户基本属性
age = np.random.normal(35, 10, n_users).astype(int)
age = np.clip(age, 18, 70) # 年龄限制在18-70岁
gender = np.random.choice(['男', '女'], n_users, p=[0.48, 0.52])
city_tier = np.random.choice([1, 2, 3], n_users, p=[0.3, 0.4, 0.3])
# 用户行为数据
sessions_count = np.random.poisson(25, n_users) # 会话次数
avg_session_duration = np.random.normal(300, 120, n_users) # 平均会话时长(秒)
page_views_per_session = np.random.normal(8, 3, n_users)
# 用户交易数据
total_spent = np.random.gamma(5, 100, n_users) # 总消费金额
purchase_frequency = np.random.poisson(6, n_users) # 购买频次
last_purchase_days = np.random.exponential(30, n_users).astype(int) # 距上次购买天数
# 创建数据框
user_data = pd.DataFrame({
'user_id': range(1, n_users + 1),
'age': age,
'gender': gender,
'city_tier': city_tier,
'sessions_count': sessions_count,
'avg_session_duration': avg_session_duration,
'page_views_per_session': page_views_per_session,
'total_spent': total_spent,
'purchase_frequency': purchase_frequency,
'last_purchase_days': last_purchase_days
})
print("数据概览:")
print(user_data.head())
print(f"\n数据集形状: {user_data.shape}")
print("\n数据基本信息:")
print(user_data.info())
print("\n描述性统计:")
print(user_data.describe())3.2 数据清洗与缺失值处理
真实世界的数据往往存在各种质量问题,需要进行系统的数据清洗。
# 数据质量检查
def check_data_quality(df):
"""检查数据质量"""
quality_report = pd.DataFrame({
'数据类型': df.dtypes,
'缺失值数量': df.isnull().sum(),
'缺失值比例': df.isnull().sum() / len(df) * 100,
'唯一值数量': df.nunique(),
'重复行': [df.duplicated().sum()] * len(df.columns)
})
return quality_report
quality_report = check_data_quality(user_data)
print("数据质量报告:")
print(quality_report)
# 处理异常值
def handle_outliers(df, columns):
"""使用IQR方法处理异常值"""
df_clean = df.copy()
for col in columns:
if df[col].dtype in ['int64', 'float64']:
Q1 = df[col].quantile(0.25)
Q3 = df[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 缩尾处理
df_clean[col] = np.clip(df_clean[col], lower_bound, upper_bound)
return df_clean
# 数值型列
numeric_columns = ['age', 'sessions_count', 'avg_session_duration',
'page_views_per_session', 'total_spent',
'purchase_frequency', 'last_purchase_duration']
user_data_clean = handle_outliers(user_data, numeric_columns)
print("异常值处理后的描述性统计:")
print(user_data_clean.describe())3.3 特征工程
特征工程是聚类分析成功的关键,好的特征能够显著提升聚类效果。
# 创建新特征
def create_features(df):
"""创建衍生特征"""
df_eng = df.copy()
# 用户价值相关特征
df_eng['avg_order_value'] = df_eng['total_spent'] / df_eng['purchase_frequency']
df_eng['avg_order_value'] = df_eng['avg_order_value'].replace([np.inf, -np.inf], 0)
# 用户活跃度特征
df_eng['total_session_duration'] = df_eng['sessions_count'] * df_eng['avg_session_duration']
df_eng['total_page_views'] = df_eng['sessions_count'] * df_eng['page_views_per_session']
# 用户忠诚度特征
df_eng['recency_score'] = 1 / (df_eng['last_purchase_days'] + 1) # 避免除零
# 用户参与度特征
df_eng['engagement_score'] = (df_eng['sessions_count'] / df_eng['sessions_count'].max() +
df_eng['avg_session_duration'] / df_eng['avg_session_duration'].max() +
df_eng['page_views_per_session'] / df_eng['page_views_per_session'].max()) / 3
return df_eng
user_data_eng = create_features(user_data_clean)
# 选择用于聚类的特征
clustering_features = [
'age', 'sessions_count', 'avg_session_duration',
'page_views_per_session', 'total_spent', 'purchase_frequency',
'last_purchase_days', 'avg_order_value', 'total_session_duration',
'total_page_views', 'recency_score', 'engagement_score'
]
# 准备聚类数据
X = user_data_eng[clustering_features]
print("特征相关性矩阵:")
plt.figure(figsize=(12, 10))
correlation_matrix = X.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0)
plt.title('特征相关性热图')
plt.tight_layout()
plt.show()3.4 数据标准化
由于聚类算法对特征的尺度敏感,我们需要对数据进行标准化处理。
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print("标准化后的数据统计:")
print(f"均值: {X_scaled.mean(axis=0)}")
print(f"标准差: {X_scaled.std(axis=0)}")
# 可视化标准化效果
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
# 标准化前
axes[0].boxplot([X[col] for col in X.columns], labels=X.columns)
axes[0].set_title('标准化前的特征分布')
axes[0].tick_params(axis='x', rotation=45)
# 标准化后
X_scaled_df = pd.DataFrame(X_scaled, columns=X.columns)
axes[1].boxplot([X_scaled_df[col] for col in X_scaled_df.columns], labels=X_scaled_df.columns)
axes[1].set_title('标准化后的特征分布')
axes[1].tick_params(axis='x', rotation=45)
plt.tight_layout()
plt.show()
# 使用PCA进行降维可视化(用于后续分析)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
print(f"PCA解释方差比: {pca.explained_variance_ratio_}")
print(f"累计解释方差: {pca.explained_variance_ratio_.sum()}")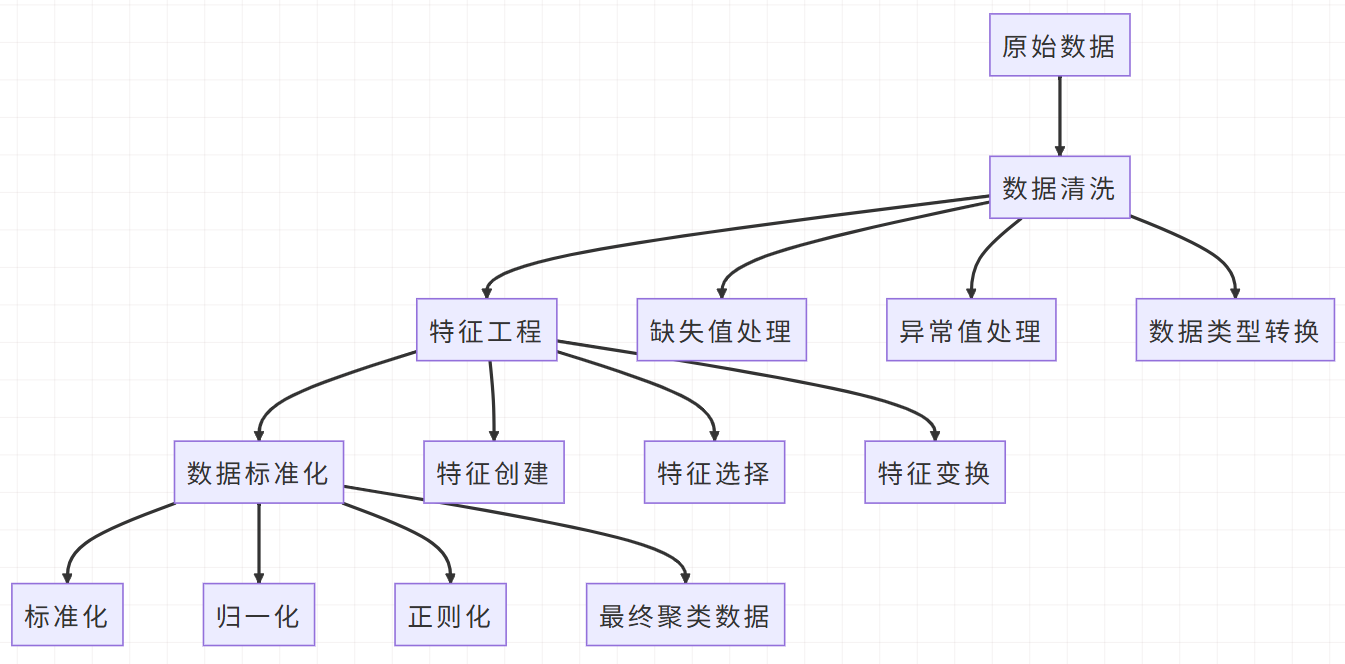
IV. 聚类算法实现与优化
4.1 K-means聚类实现
K-means是最常用的聚类算法,我们首先实现基础版本,然后进行优化。
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# 寻找最优K值
def find_optimal_k(X, max_k=15):
"""使用肘部法则和轮廓系数确定最优K值"""
inertias = []
silhouette_scores = []
k_range = range(2, max_k + 1)
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
kmeans.fit(X)
inertias.append(kmeans.inertia_)
if k > 1: # 轮廓系数需要至少2个簇
silhouette_scores.append(silhouette_score(X, kmeans.labels_))
return inertias, silhouette_scores, k_range
inertias, silhouette_scores, k_range = find_optimal_k(X_scaled)
# 绘制肘部法则和轮廓系数图
fig, axes = plt.subplots(1, 2, figsize=(15, 5))
# 肘部法则
axes[0].plot(range(2, 16), inertias, 'bo-')
axes[0].set_xlabel('簇数量 (K)')
axes[0].set_ylabel('簇内平方和 (Inertia)')
axes[0].set_title('肘部法则 - 寻找最优K值')
axes[0].grid(True)
# 轮廓系数
axes[1].plot(range(2, 16), silhouette_scores, 'ro-')
axes[1].set_xlabel('簇数量 (K)')
axes[1].set_ylabel('轮廓系数')
axes[1].set_title('轮廓系数 - 寻找最优K值')
axes[1].grid(True)
plt.tight_layout()
plt.show()
# 选择最优K值并训练模型
optimal_k = 5 # 根据图表选择
kmeans = KMeans(n_clusters=optimal_k, random_state=42, n_init=10)
kmeans_labels = kmeans.fit_predict(X_scaled)
# 评估聚类结果
silhouette_avg = silhouette_score(X_scaled, kmeans_labels)
calinski_harabasz = calinski_harabasz_score(X_scaled, kmeans_labels)
davies_bouldin = davies_bouldin_score(X_scaled, kmeans_labels)
print("K-means聚类评估指标:")
print(f"轮廓系数: {silhouette_avg:.4f}")
print(f"Calinski-Harabasz指数: {calinski_harabasz:.4f}")
print(f"Davies-Bouldin指数: {davies_bouldin:.4f}")
# 可视化聚类结果(使用PCA降维)
plt.figure(figsize=(10, 8))
scatter = plt.scatter(X_pca[:, 0], X_pca[:, 1], c=kmeans_labels, cmap='viridis', alpha=0.6)
plt.colorbar(scatter)
plt.xlabel('第一主成分')
plt.ylabel('第二主成分')
plt.title('K-means聚类结果可视化 (PCA降维)')
# 标记簇中心
centers_pca = pca.transform(kmeans.cluster_centers_)
plt.scatter(centers_pca[:, 0], centers_pca[:, 1], c='red', marker='X', s=200, label='簇中心')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()4.2 聚类结果分析
深入分析每个簇的特征,为后续用户画像构建奠定基础。
# 将聚类结果添加到原始数据
user_data_eng['cluster'] = kmeans_labels
# 分析每个簇的特征
cluster_profiles = user_data_eng.groupby('cluster')[clustering_features].mean()
cluster_sizes = user_data_eng['cluster'].value_counts().sort_index()
print("各簇大小:")
print(cluster_sizes)
# 可视化簇特征对比
fig, axes = plt.subplots(3, 2, figsize=(15, 12))
axes = axes.ravel()
features_to_plot = ['total_spent', 'purchase_frequency', 'age',
'engagement_score', 'recency_score', 'sessions_count']
for i, feature in enumerate(features_to_plot):
cluster_profiles[feature].plot(kind='bar', ax=axes[i], color='skyblue')
axes[i].set_title(f'各簇的{feature}对比')
axes[i].set_xlabel('簇')
axes[i].set_ylabel(feature)
axes[i].tick_params(axis='x', rotation=45)
plt.tight_layout()
plt.show()
# 生成详细的簇分析报告
def generate_cluster_report(df, cluster_col, features):
"""生成详细的簇分析报告"""
report = {}
for cluster in sorted(df[cluster_col].unique()):
cluster_data = df[df[cluster_col] == cluster]
cluster_report = {
'簇大小': len(cluster_data),
'占比': len(cluster_data) / len(df) * 100
}
# 数值型特征统计
for feature in features:
if df[feature].dtype in ['int64', 'float64']:
cluster_report[f'{feature}_均值'] = cluster_data[feature].mean()
cluster_report[f'{feature}_标准差'] = cluster_data[feature].std()
report[f'簇_{cluster}'] = cluster_report
return pd.DataFrame(report).T
cluster_report = generate_cluster_report(user_data_eng, 'cluster', clustering_features)
print("详细簇分析报告:")
print(cluster_report)4.3 高级聚类算法比较
除了K-means,我们还尝试其他聚类算法,比较它们的效果。
from sklearn.cluster import DBSCAN, AgglomerativeClustering
from sklearn.mixture import GaussianMixture
import time
# 定义比较的算法
algorithms = {
'K-means': KMeans(n_clusters=optimal_k, random_state=42, n_init=10),
'DBSCAN': DBSCAN(eps=0.5, min_samples=5),
'层次聚类': AgglomerativeClustering(n_clusters=optimal_k),
'高斯混合模型': GaussianMixture(n_components=optimal_k, random_state=42)
}
# 比较不同算法
results = {}
for name, algorithm in algorithms.items():
print(f"训练 {name}...")
start_time = time.time()
if name == '高斯混合模型':
labels = algorithm.fit_predict(X_scaled)
else:
labels = algorithm.fit_predict(X_scaled)
end_time = time.time()
# 评估指标(DBSCAN可能产生噪声点,需要特殊处理)
if len(set(labels)) > 1: # 确保有多个簇
silhouette = silhouette_score(X_scaled, labels)
calinski = calinski_harabasz_score(X_scaled, labels)
davies = davies_bouldin_score(X_scaled, labels)
else:
silhouette = calinski = davies = np.nan
results[name] = {
'labels': labels,
'silhouette_score': silhouette,
'calinski_harabasz_score': calinski,
'davies_bouldin_score': davies,
'n_clusters': len(set(labels)) - (1 if -1 in labels else 0), # 处理噪声点
'training_time': end_time - start_time
}
# 比较结果
comparison_df = pd.DataFrame({
'算法': list(results.keys()),
'轮廓系数': [results[alg]['silhouette_score'] for alg in results],
'Calinski-Harabasz': [results[alg]['calinski_harabasz_score'] for alg in results],
'Davies-Bouldin': [results[alg]['davies_bouldin_score'] for alg in results],
'簇数量': [results[alg]['n_clusters'] for alg in results],
'训练时间(秒)': [results[alg]['training_time'] for alg in results]
})
print("算法比较结果:")
print(comparison_df)
# 可视化不同算法的聚类结果
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
axes = axes.ravel()
for i, (name, result) in enumerate(results.items()):
if i < 4: # 确保不超过子图数量
scatter = axes[i].scatter(X_pca[:, 0], X_pca[:, 1], c=result['labels'],
cmap='viridis', alpha=0.6)
axes[i].set_title(f'{name}聚类结果\n轮廓系数: {result["silhouette_score"]:.4f}')
axes[i].set_xlabel('第一主成分')
axes[i].set_ylabel('第二主成分')
plt.colorbar(scatter, ax=axes[i])
plt.tight_layout()
plt.show()4.4 聚类稳定性评估
评估聚类结果的稳定性,确保模型的可重复性。
from sklearn.utils import resample
def evaluate_clustering_stability(X, algorithm, n_iterations=10, sample_ratio=0.8):
"""评估聚类稳定性"""
stability_scores = []
n_samples = int(len(X) * sample_ratio)
for i in range(n_iterations):
# 自助采样
sample_indices = resample(range(len(X)), n_samples=n_samples, random_state=i)
X_sample = X[sample_indices]
# 训练模型
if algorithm == 'K-means':
model = KMeans(n_clusters=optimal_k, random_state=42, n_init=10)
elif algorithm == 'GMM':
model = GaussianMixture(n_components=optimal_k, random_state=42)
else:
continue
labels_sample = model.fit_predict(X_sample)
# 计算轮廓系数作为稳定性指标
if len(set(labels_sample)) > 1:
score = silhouette_score(X_sample, labels_sample)
stability_scores.append(score)
return np.mean(stability_scores), np.std(stability_scores)
# 评估K-means稳定性
kmeans_stability_mean, kmeans_stability_std = evaluate_clustering_stability(
X_scaled, 'K-means'
)
# 评估GMM稳定性
gmm_stability_mean, gmm_stability_std = evaluate_clustering_stability(
X_scaled, 'GMM'
)
print("聚类稳定性评估:")
print(f"K-means平均轮廓系数: {kmeans_stability_mean:.4f} (±{kmeans_stability_std:.4f})")
print(f"GMM平均轮廓系数: {gmm_stability_mean:.4f} (±{gmm_stability_std:.4f})")
# 特征重要性分析(基于簇间方差)
def analyze_feature_importance(X, labels, feature_names):
"""分析各特征在聚类中的重要性"""
from sklearn.feature_selection import f_classif
# 使用ANOVA F-value评估特征重要性
f_values, p_values = f_classif(X, labels)
importance_df = pd.DataFrame({
'特征': feature_names,
'F值': f_values,
'p值': p_values,
'重要性排名': np.argsort(f_values)[::-1] + 1
}).sort_values('F值', ascending=False)
return importance_df
feature_importance = analyze_feature_importance(X_scaled, kmeans_labels, clustering_features)
print("特征重要性分析:")
print(feature_importance)
# 可视化特征重要性
plt.figure(figsize=(10, 6))
plt.barh(feature_importance['特征'], feature_importance['F值'], color='lightcoral')
plt.xlabel('F值 (特征重要性)')
plt.title('聚类特征重要性分析')
plt.gca().invert_yaxis()
plt.tight_layout()
plt.show()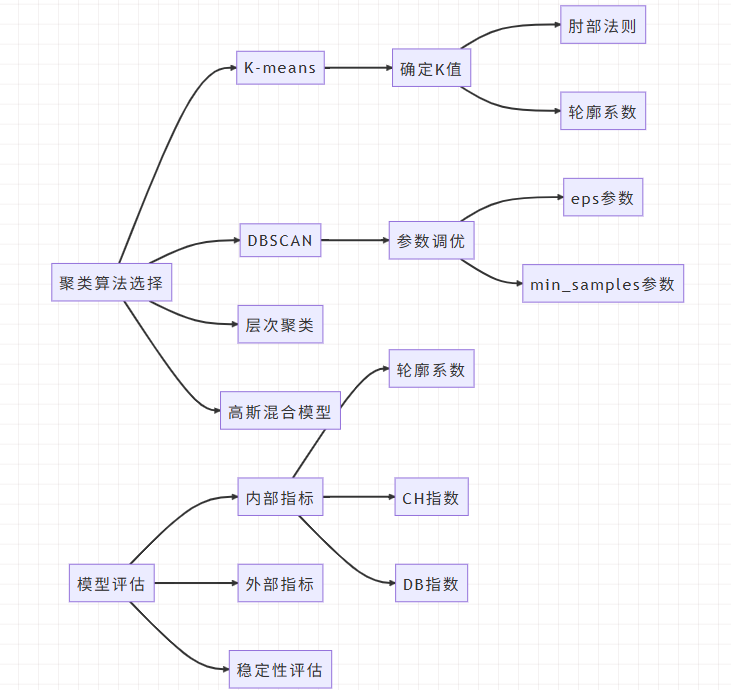
V. 用户画像构建与分析
5.1 用户画像标签体系构建
基于聚类结果,我们构建详细的用户画像标签体系,将每个簇转化为具有业务意义的用户群体。
# 基于聚类结果构建用户画像
def build_user_profiles(df, cluster_col, features):
"""构建详细的用户画像"""
profiles = {}
for cluster in sorted(df[cluster_col].unique()):
cluster_data = df[df[cluster_col] == cluster]
profile = {
'群体规模': len(cluster_data),
'占比': len(cluster_data) / len(df) * 100
}
# 基本特征分析
numeric_features = [f for f in features if df[f].dtype in ['int64', 'float64']]
for feature in numeric_features:
mean_val = cluster_data[feature].mean()
std_val = cluster_data[feature].std()
# 创建业务标签
if feature == 'total_spent':
if mean_val > df[feature].quantile(0.75):
profile['消费能力'] = '高价值用户'
elif mean_val > df[feature].quantile(0.25):
profile['消费能力'] = '中等价值用户'
else:
profile['消费能力'] = '低价值用户'
elif feature == 'purchase_frequency':
if mean_val > df[feature].quantile(0.75):
profile['购买频率'] = '高频用户'
elif mean_val > df[feature].quantile(0.25):
profile['购买频率'] = '中频用户'
else:
profile['购买频率'] = '低频用户'
elif feature == 'recency_score':
if mean_val > df[feature].quantile(0.75):
profile['最近活跃度'] = '活跃用户'
elif mean_val > df[feature].quantile(0.25):
profile['最近活跃度'] = '一般用户'
else:
profile['最近活跃度'] = '沉默用户'
elif feature == 'engagement_score':
if mean_val > df[feature].quantile(0.75):
profile['参与度'] = '高参与度'
elif mean_val > df[feature].quantile(0.25):
profile['参与度'] = '中参与度'
else:
profile['参与度'] = '低参与度'
# 人口统计特征
if 'age' in df.columns:
age_mean = cluster_data['age'].mean()
if age_mean < 25:
profile['年龄群体'] = '年轻用户'
elif age_mean < 40:
profile['年龄群体'] = '中年用户'
else:
profile['年龄群体'] = '成熟用户'
if 'gender' in df.columns:
gender_ratio = (cluster_data['gender'] == '男').mean()
if gender_ratio > 0.6:
profile['性别分布'] = '男性为主'
elif gender_ratio < 0.4:
profile['性别分布'] = '女性为主'
else:
profile['性别分布'] = '性别均衡'
profiles[f'用户群体_{cluster}'] = profile
return pd.DataFrame(profiles).T
# 构建用户画像
user_profiles = build_user_profiles(user_data_eng, 'cluster', clustering_features)
print("用户画像分析:")
print(user_profiles)
# 可视化用户群体分布
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 群体规模分布
axes[0, 0].pie(user_profiles['群体规模'], labels=user_profiles.index, autopct='%1.1f%%')
axes[0, 0].set_title('用户群体分布')
# 消费能力分布
consumption_profile = user_profiles['消费能力'].value_counts()
axes[0, 1].bar(consumption_profile.index, consumption_profile.values, color=['gold', 'lightcoral', 'lightblue'])
axes[0, 1].set_title('消费能力分布')
axes[0, 1].tick_params(axis='x', rotation=45)
# 参与度分布
engagement_profile = user_profiles['参与度'].value_counts()
axes[1, 0].bar(engagement_profile.index, engagement_profile.values, color=['lightgreen', 'orange', 'purple'])
axes[1, 0].set_title('用户参与度分布')
axes[1, 0].tick_params(axis='x', rotation=45)
# 最近活跃度分布
recency_profile = user_profiles['最近活跃度'].value_counts()
axes[1, 1].bar(recency_profile.index, recency_profile.values, color=['red', 'yellow', 'green'])
axes[1, 1].set_title('用户活跃度分布')
axes[1, 1].tick_params(axis='x', rotation=45)
plt.tight_layout()
plt.show()5.2 用户群体深度分析
对每个用户群体进行深度分析,揭示其独特特征和行为模式。
# 深度分析每个用户群体
def deep_dive_cluster_analysis(df, cluster_col, cluster_id):
"""对特定群体进行深度分析"""
cluster_data = df[df[cluster_col] == cluster_id]
overall_data = df
analysis = {}
# 关键指标对比
key_metrics = ['total_spent', 'purchase_frequency', 'engagement_score',
'recency_score', 'sessions_count', 'avg_order_value']
for metric in key_metrics:
cluster_mean = cluster_data[metric].mean()
overall_mean = overall_data[metric].mean()
ratio = cluster_mean / overall_mean if overall_mean != 0 else 0
analysis[metric] = {
'群体均值': cluster_mean,
'总体均值': overall_mean,
'相对比例': ratio,
'表现': '高于平均' if ratio > 1 else '低于平均'
}
# 行为模式分析
if 'gender' in cluster_data.columns:
gender_dist = cluster_data['gender'].value_counts(normalize=True)
analysis['性别分布'] = gender_dist.to_dict()
if 'city_tier' in cluster_data.columns:
city_dist = cluster_data['city_tier'].value_counts(normalize=True)
analysis['城市等级分布'] = city_dist.to_dict()
return analysis
# 为每个群体生成深度分析报告
cluster_analyses = {}
for cluster_id in sorted(user_data_eng['cluster'].unique()):
cluster_analyses[f'群体_{cluster_id}'] = deep_dive_cluster_analysis(
user_data_eng, 'cluster', cluster_id
)
# 可视化关键指标对比
def plot_cluster_comparison(cluster_analyses, metrics_to_plot):
"""绘制群体关键指标对比图"""
n_metrics = len(metrics_to_plot)
n_clusters = len(cluster_analyses)
fig, axes = plt.subplots(2, 3, figsize=(18, 10))
axes = axes.ravel()
for i, metric in enumerate(metrics_to_plot):
if i < len(axes):
cluster_names = []
ratios = []
for cluster_name, analysis in cluster_analyses.items():
if metric in analysis:
cluster_names.append(cluster_name)
ratios.append(analysis[metric]['相对比例'])
colors = ['green' if r > 1 else 'red' for r in ratios]
bars = axes[i].bar(cluster_names, ratios, color=colors, alpha=0.7)
axes[i].axhline(y=1, color='black', linestyle='--', alpha=0.5)
axes[i].set_title(f'{metric}相对比例')
axes[i].set_ylabel('相对比例 (群体均值/总体均值)')
axes[i].tick_params(axis='x', rotation=45)
# 在柱子上添加数值
for bar, ratio in zip(bars, ratios):
axes[i].text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.02,
f'{ratio:.2f}', ha='center', va='bottom')
plt.tight_layout()
plt.show()
metrics_to_visualize = ['total_spent', 'purchase_frequency', 'engagement_score',
'recency_score', 'sessions_count', 'avg_order_value']
plot_cluster_comparison(cluster_analyses, metrics_to_visualize)
# 生成群体特征雷达图
def create_radar_chart(cluster_analyses, cluster_id, metrics, figsize=(8, 8)):
"""创建群体特征雷达图"""
from math import pi
# 准备数据
values = []
for metric in metrics:
if metric in cluster_analyses[f'群体_{cluster_id}']:
values.append(cluster_analyses[f'群体_{cluster_id}'][metric]['相对比例'])
else:
values.append(0)
# 完成环形
values += values[:1]
metrics_radar = metrics + [metrics[0]]
# 角度计算
angles = [n / float(len(metrics)) * 2 * pi for n in range(len(metrics))]
angles += angles[:1]
# 绘图
fig, ax = plt.subplots(figsize=figsize, subplot_kw=dict(projection='polar'))
ax.plot(angles, values, 'o-', linewidth=2, label=f'群体 {cluster_id}')
ax.fill(angles, values, alpha=0.25)
ax.set_thetagrids([a * 180/pi for a in angles[:-1]], metrics)
ax.set_ylim(0, max(values) * 1.1)
ax.set_title(f'用户群体 {cluster_id} 特征雷达图', size=14, y=1.05)
ax.grid(True)
plt.show()
# 为每个群体创建雷达图
for cluster_id in range(optimal_k):
create_radar_chart(cluster_analyses, cluster_id,
['total_spent', 'purchase_frequency', 'engagement_score',
'recency_score', 'sessions_count'])5.3 用户画像业务应用
将技术分析转化为业务洞察,为不同用户群体制定精准的运营策略。
# 基于用户画像制定业务策略
def generate_business_strategies(user_profiles, cluster_analyses):
"""为每个用户群体制定业务策略"""
strategies = {}
for cluster_id in range(len(user_profiles)):
profile = user_profiles.iloc[cluster_id]
analysis = cluster_analyses[f'群体_{cluster_id}']
strategy = {
'群体特征': [],
'核心洞察': [],
'推荐策略': [],
'预期目标': []
}
# 基于消费能力制定策略
consumption_level = profile['消费能力']
if consumption_level == '高价值用户':
strategy['群体特征'].append('高消费能力、高客单价')
strategy['核心洞察'].append('对价格不敏感,重视品质和服务')
strategy['推荐策略'].extend([
'提供VIP专属服务',
'推送高端产品和限量款',
'个性化定制推荐'
])
strategy['预期目标'].append('提升客户忠诚度和生命周期价值')
elif consumption_level == '中等价值用户':
strategy['群体特征'].append('中等消费水平,有升级潜力')
strategy['核心洞察'].append('对性价比敏感,需要引导消费')
strategy['推荐策略'].extend([
'提供组合优惠套餐',
'推送性价比高的产品',
'会员等级提升激励'
])
strategy['预期目标'].append('促进消费升级,提高客单价')
else: # 低价值用户
strategy['群体特征'].append('低消费频率和金额')
strategy['核心洞察'].append('价格敏感,需要培养消费习惯')
strategy['推荐策略'].extend([
'推送促销和折扣信息',
'低门槛入门产品推荐',
'社交分享激励活动'
])
strategy['预期目标'].append('提高活跃度和转化率')
# 基于参与度制定策略
engagement_level = profile['参与度']
if engagement_level == '高参与度':
strategy['群体特征'].append('高频互动,积极参与')
strategy['核心洞察'].append('品牌忠实粉丝,愿意参与互动')
strategy['推荐策略'].append('邀请参与产品评测和社区建设')
strategy['预期目标'].append('培养品牌大使,提升口碑传播')
elif engagement_level == '低参与度':
strategy['群体特征'].append('互动较少, passively参与')
strategy['核心洞察'].append('需要刺激和引导参与')
strategy['推荐策略'].append('推送互动性强的内容和活动')
strategy['预期目标'].append('提高用户粘性和参与度')
# 基于活跃度制定策略
recency_level = profile['最近活跃度']
if recency_level == '沉默用户':
strategy['群体特征'].append('长期未活跃,有流失风险')
strategy['核心洞察'].append('需要重新激活和召回')
strategy['推荐策略'].extend([
'推送专属回归优惠',
'个性化召回邮件',
'调查流失原因'
])
strategy['预期目标'].append('防止流失,重新建立连接')
strategies[f'群体_{cluster_id}'] = strategy
return strategies
# 生成业务策略
business_strategies = generate_business_strategies(user_profiles, cluster_analyses)
# 输出策略报告
for cluster_id, strategy in business_strategies.items():
print(f"\n{'-'*50}")
print(f"{cluster_id} 业务策略报告")
print(f"{'-'*50}")
for category, items in strategy.items():
print(f"\n{category}:")
for item in items:
print(f" • {item}")
# 可视化策略优先级矩阵
def plot_strategy_priority_matrix(user_profiles):
"""绘制用户群体策略优先级矩阵"""
fig, ax = plt.subplots(figsize=(10, 8))
# 定义坐标:价值度 vs 活跃度
for cluster_id in range(len(user_profiles)):
profile = user_profiles.iloc[cluster_id]
# 确定价值度坐标
if profile['消费能力'] == '高价值用户':
value_score = 3
elif profile['消费能力'] == '中等价值用户':
value_score = 2
else:
value_score = 1
# 确定活跃度坐标
if profile['最近活跃度'] == '活跃用户':
activity_score = 3
elif profile['最近活跃度'] == '一般用户':
activity_score = 2
else:
activity_score = 1
# 绘制气泡图
bubble_size = profile['群体规模'] * 10 # 用气泡大小表示群体规模
ax.scatter(value_score, activity_score, s=bubble_size, alpha=0.6,
label=f'群体 {cluster_id}')
ax.annotate(f'群体{cluster_id}', (value_score, activity_score),
xytext=(5, 5), textcoords='offset points')
ax.set_xlabel('用户价值度')
ax.set_ylabel('用户活跃度')
ax.set_title('用户群体策略优先级矩阵')
ax.set_xticks([1, 2, 3])
ax.set_yticks([1, 2, 3])
ax.set_xticklabels(['低价值', '中价值', '高价值'])
ax.set_yticklabels(['低活跃', '中活跃', '高活跃'])
ax.grid(True, alpha=0.3)
ax.legend()
# 添加策略区域注释
ax.text(2.5, 2.5, '重点维护', fontsize=12, ha='center',
bbox=dict(boxstyle="round,pad=0.3", facecolor="lightgreen", alpha=0.5))
ax.text(2.5, 1, '价值提升', fontsize=12, ha='center',
bbox=dict(boxstyle="round,pad=0.3", facecolor="lightyellow", alpha=0.5))
ax.text(1, 2.5, '活跃提升', fontsize=12, ha='center',
bbox=dict(boxstyle="round,pad=0.3", facecolor="lightblue", alpha=0.5))
ax.text(1, 1, '观察培养', fontsize=12, ha='center',
bbox=dict(boxstyle="round,pad=0.3", facecolor="lightcoral", alpha=0.5))
plt.tight_layout()
plt.show()
plot_strategy_priority_matrix(user_profiles)
VI. 部署与生产环境应用
6.1 模型部署与API开发
将训练好的聚类模型部署到生产环境,提供实时用户分群服务。
import pickle
import json
from flask import Flask, request, jsonify
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
class UserClusteringService:
"""用户聚类服务类"""
def __init__(self, model_path, scaler_path, feature_names):
self.model = self.load_model(model_path)
self.scaler = self.load_model(scaler_path)
self.feature_names = feature_names
def load_model(self, path):
"""加载模型"""
with open(path, 'rb') as f:
return pickle.load(f)
def preprocess_features(self, user_data):
"""预处理用户特征"""
# 确保特征顺序一致
input_features = pd.DataFrame([user_data])[self.feature_names]
# 数据清洗和转换
for feature in self.feature_names:
if feature in ['age', 'sessions_count', 'purchase_frequency']:
input_features[feature] = pd.to_numeric(input_features[feature], errors='coerce')
# 处理缺失值
input_features = input_features.fillna(input_features.median())
return input_features
def predict_cluster(self, user_data):
"""预测用户所属群体"""
try:
# 预处理
processed_features = self.preprocess_features(user_data)
# 标准化
scaled_features = self.scaler.transform(processed_features)
# 预测
cluster = self.model.predict(scaled_features)[0]
probabilities = self.model.predict_proba(scaled_features)[0] if hasattr(self.model, 'predict_proba') else None
return {
'cluster': int(cluster),
'probabilities': probabilities.tolist() if probabilities is not None else None,
'status': 'success'
}
except Exception as e:
return {
'cluster': -1,
'error': str(e),
'status': 'error'
}
# 保存训练好的模型和标准化器
def save_models(kmeans_model, scaler, feature_names, model_path='kmeans_model.pkl',
scaler_path='scaler.pkl', features_path='features.json'):
"""保存模型和配置"""
with open(model_path, 'wb') as f:
pickle.dump(kmeans_model, f)
with open(scaler_path, 'wb') as f:
pickle.dump(scaler, f)
with open(features_path, 'w') as f:
json.dump(feature_names, f)
print("模型保存完成!")
# 保存当前训练的模型
save_models(kmeans, scaler, clustering_features)
# 创建Flask应用
app = Flask(__name__)
clustering_service = None
@app.before_first_request
def load_models():
"""在第一个请求前加载模型"""
global clustering_service
try:
with open('features.json', 'r') as f:
feature_names = json.load(f)
clustering_service = UserClusteringService(
model_path='kmeans_model.pkl',
scaler_path='scaler.pkl',
feature_names=feature_names
)
print("模型加载成功!")
except Exception as e:
print(f"模型加载失败: {e}")
@app.route('/health', methods=['GET'])
def health_check():
"""健康检查端点"""
return jsonify({'status': 'healthy', 'message': 'User Clustering Service is running'})
@app.route('/predict', methods=['POST'])
def predict_cluster():
"""预测用户所属群体"""
try:
user_data = request.get_json()
if not user_data:
return jsonify({'error': 'No input data provided'}), 400
result = clustering_service.predict_cluster(user_data)
return jsonify(result)
except Exception as e:
return jsonify({'error': str(e), 'status': 'error'}), 500
@app.route('/batch_predict', methods=['POST'])
def batch_predict():
"""批量预测用户群体"""
try:
users_data = request.get_json()
if not users_data or 'users' not in users_data:
return jsonify({'error': 'No users data provided'}), 400
results = []
for user_data in users_data['users']:
result = clustering_service.predict_cluster(user_data)
results.append(result)
return jsonify({'results': results, 'status': 'success'})
except Exception as e:
return jsonify({'error': str(e), 'status': 'error'}), 500
# 启动服务(在生产环境中使用WSGI服务器)
if __name__ == '__main__':
load_models()
app.run(host='0.0.0.0', port=5000, debug=False)6.2 实时用户分群流水线
构建完整的实时用户分群数据处理流水线。
import datetime
from typing import Dict, List, Any
import logging
class RealTimeUserClustering:
"""实时用户分群流水线"""
def __init__(self, model_service: UserClusteringService):
self.model_service = model_service
self.logger = logging.getLogger(__name__)
# 用户特征缓存(生产环境中使用Redis)
self.user_features_cache = {}
# 群体统计信息
self.cluster_stats = {
'total_processed': 0,
'cluster_distribution': {},
'last_updated': datetime.datetime.now()
}
def update_user_features(self, user_id: str, event_type: str, event_data: Dict):
"""根据用户事件更新特征"""
try:
if user_id not in self.user_features_cache:
self.user_features_cache[user_id] = self._initialize_user_features()
user_features = self.user_features_cache[user_id]
# 根据事件类型更新特征
if event_type == 'page_view':
self._handle_page_view(user_features, event_data)
elif event_type == 'purchase':
self._handle_purchase(user_features, event_data)
elif event_type == 'session_start':
self._handle_session_start(user_features, event_data)
elif event_type == 'session_end':
self._handle_session_end(user_features, event_data)
# 更新最后活跃时间
user_features['last_activity_time'] = datetime.datetime.now()
self.logger.info(f"Updated features for user {user_id}")
except Exception as e:
self.logger.error(f"Error updating features for user {user_id}: {e}")
def _initialize_user_features(self) -> Dict[str, Any]:
"""初始化用户特征"""
return {
'sessions_count': 0,
'total_page_views': 0,
'total_session_duration': 0,
'total_spent': 0.0,
'purchase_count': 0,
'last_purchase_time': None,
'last_activity_time': datetime.datetime.now(),
'current_session_start': None,
'current_session_views': 0
}
def _handle_page_view(self, features: Dict, event_data: Dict):
"""处理页面浏览事件"""
features['total_page_views'] += 1
features['current_session_views'] += 1
def _handle_purchase(self, features: Dict, event_data: Dict):
"""处理购买事件"""
purchase_amount = event_data.get('amount', 0)
features['total_spent'] += purchase_amount
features['purchase_count'] += 1
features['last_purchase_time'] = datetime.datetime.now()
def _handle_session_start(self, features: Dict, event_data: Dict):
"""处理会话开始事件"""
features['sessions_count'] += 1
features['current_session_start'] = datetime.datetime.now()
features['current_session_views'] = 0
def _handle_session_end(self, features: Dict, event_data: Dict):
"""处理会话结束事件"""
if features['current_session_start']:
session_duration = (datetime.datetime.now() - features['current_session_start']).total_seconds()
features['total_session_duration'] += session_duration
features['current_session_start'] = None
def get_user_cluster(self, user_id: str) -> Dict[str, Any]:
"""获取用户当前所属群体"""
try:
if user_id not in self.user_features_cache:
return {'cluster': -1, 'error': 'User not found'}
user_features = self.user_features_cache[user_id]
# 准备模型输入特征
model_input = self._prepare_model_input(user_features)
# 预测群体
result = self.model_service.predict_cluster(model_input)
# 更新统计信息
self._update_cluster_stats(result['cluster'])
# 添加业务标签
result['business_segment'] = self._get_business_segment(result['cluster'])
return result
except Exception as e:
self.logger.error(f"Error getting cluster for user {user_id}: {e}")
return {'cluster': -1, 'error': str(e)}
def _prepare_model_input(self, user_features: Dict) -> Dict[str, Any]:
"""准备模型输入特征"""
# 计算衍生特征
current_time = datetime.datetime.now()
# 购买频率(每天)
days_since_first_activity = 1 # 简化处理,实际中需要记录首次活跃时间
purchase_frequency = user_features['purchase_count'] / days_since_first_activity
# 距上次购买天数
if user_features['last_purchase_time']:
last_purchase_days = (current_time - user_features['last_purchase_time']).days
else:
last_purchase_days = 999 # 很大的数表示从未购买
# 平均会话时长
if user_features['sessions_count'] > 0:
avg_session_duration = user_features['total_session_duration'] / user_features['sessions_count']
else:
avg_session_duration = 0
# 平均每次会话页面浏览数
if user_features['sessions_count'] > 0:
page_views_per_session = user_features['total_page_views'] / user_features['sessions_count']
else:
page_views_per_session = 0
# 平均订单价值
if user_features['purchase_count'] > 0:
avg_order_value = user_features['total_spent'] / user_features['purchase_count']
else:
avg_order_value = 0
# 参与度评分
engagement_score = self._calculate_engagement_score(user_features)
# 近期活跃度评分
recency_score = self._calculate_recency_score(user_features, current_time)
return {
'sessions_count': user_features['sessions_count'],
'avg_session_duration': avg_session_duration,
'page_views_per_session': page_views_per_session,
'total_spent': user_features['total_spent'],
'purchase_frequency': purchase_frequency,
'last_purchase_days': last_purchase_days,
'avg_order_value': avg_order_value,
'total_session_duration': user_features['total_session_duration'],
'total_page_views': user_features['total_page_views'],
'recency_score': recency_score,
'engagement_score': engagement_score
}
def _calculate_engagement_score(self, user_features: Dict) -> float:
"""计算用户参与度评分"""
# 简化版的参与度计算
max_sessions = 100 # 假设的最大会话数
max_duration = 3600 # 假设的最大会话时长(秒)
max_views = 50 # 假设的最大页面浏览数
session_score = min(user_features['sessions_count'] / max_sessions, 1.0)
duration_score = min(user_features['total_session_duration'] / max_duration, 1.0)
views_score = min(user_features['total_page_views'] / max_views, 1.0)
return (session_score + duration_score + views_score) / 3.0
def _calculate_recency_score(self, user_features: Dict, current_time: datetime.datetime) -> float:
"""计算近期活跃度评分"""
if not user_features['last_activity_time']:
return 0.0
hours_since_activity = (current_time - user_features['last_activity_time']).total_seconds() / 3600
# 使用指数衰减函数
decay_rate = 0.1 # 衰减率
recency_score = np.exp(-decay_rate * hours_since_activity)
return recency_score
def _get_business_segment(self, cluster: int) -> str:
"""根据群体ID获取业务标签"""
segments = {
0: '高价值活跃用户',
1: '中等价值一般用户',
2: '潜在价值新用户',
3: '沉默流失风险用户',
4: '高频低价值用户'
}
return segments.get(cluster, '未知群体')
def _update_cluster_stats(self, cluster: int):
"""更新群体统计信息"""
self.cluster_stats['total_processed'] += 1
self.cluster_stats['cluster_distribution'][cluster] = \
self.cluster_stats['cluster_distribution'].get(cluster, 0) + 1
self.cluster_stats['last_updated'] = datetime.datetime.now()
def get_cluster_statistics(self) -> Dict[str, Any]:
"""获取群体统计信息"""
total = self.cluster_stats['total_processed']
distribution = {}
for cluster, count in self.cluster_stats['cluster_distribution'].items():
distribution[cluster] = {
'count': count,
'percentage': (count / total * 100) if total > 0 else 0
}
return {
'total_processed': total,
'cluster_distribution': distribution,
'last_updated': self.cluster_stats['last_updated'].isoformat()
}
# 使用示例
if __name__ == '__main__':
# 初始化服务
with open('features.json', 'r') as f:
feature_names = json.load(f)
model_service = UserClusteringService(
model_path='kmeans_model.pkl',
scaler_path='scaler.pkl',
feature_names=feature_names
)
real_time_clustering = RealTimeUserClustering(model_service)
# 模拟用户事件
user_id = "user_12345"
# 用户开始会话
real_time_clustering.update_user_features(user_id, 'session_start', {})
# 用户浏览页面
for i in range(5):
real_time_clustering.update_user_features(user_id, 'page_view', {})
# 用户完成购买
real_time_clustering.update_user_features(user_id, 'purchase', {'amount': 199.99})
# 用户结束会话
real_time_clustering.update_user_features(user_id, 'session_end', {})
# 获取用户群体
result = real_time_clustering.get_user_cluster(user_id)
print(f"用户群体预测结果: {result}")
# 获取统计信息
stats = real_time_clustering.get_cluster_statistics()
print(f"实时统计信息: {stats}")6.3 监控与维护
建立完整的模型监控和维护体系,确保生产环境的稳定性。
import time
from datetime import datetime, timedelta
import smtplib
from email.mime.text import MIMEText
from typing import Dict, List
class ClusteringMonitor:
"""聚类模型监控系统"""
def __init__(self, model_service: UserClusteringService, alert_emails: List[str]):
self.model_service = model_service
self.alert_emails = alert_emails
# 监控指标
self.metrics = {
'prediction_count': 0,
'error_count': 0,
'cluster_distribution': {},
'response_times': [],
'last_health_check': datetime.now()
}
# 性能阈值
self.thresholds = {
'max_error_rate': 0.05, # 5%
'max_avg_response_time': 1.0, # 1秒
'min_cluster_diversity': 0.1 # 最小群体多样性
}
def record_prediction(self, cluster: int, response_time: float, error: bool = False):
"""记录预测结果"""
self.metrics['prediction_count'] += 1
self.metrics['response_times'].append(response_time)
if error:
self.metrics['error_count'] += 1
else:
self.metrics['cluster_distribution'][cluster] = \
self.metrics['cluster_distribution'].get(cluster, 0) + 1
def calculate_metrics(self) -> Dict[str, Any]:
"""计算监控指标"""
total_predictions = self.metrics['prediction_count']
error_rate = self.metrics['error_count'] / total_predictions if total_predictions > 0 else 0
avg_response_time = np.mean(self.metrics['response_times']) if self.metrics['response_times'] else 0
# 计算群体分布均匀度(使用基尼系数的补数)
cluster_counts = list(self.metrics['cluster_distribution'].values())
if cluster_counts:
total = sum(cluster_counts)
proportions = [count / total for count in cluster_counts]
gini = 1 - sum(p ** 2 for p in proportions) # 赫芬达尔指数
cluster_diversity = gini
else:
cluster_diversity = 0
return {
'total_predictions': total_predictions,
'error_rate': error_rate,
'avg_response_time': avg_response_time,
'cluster_diversity': cluster_diversity,
'cluster_distribution': self.metrics['cluster_distribution'],
'health_status': self._check_health_status(error_rate, avg_response_time, cluster_diversity)
}
def _check_health_status(self, error_rate: float, response_time: float, diversity: float) -> str:
"""检查系统健康状态"""
issues = []
if error_rate > self.thresholds['max_error_rate']:
issues.append(f"错误率过高: {error_rate:.3f}")
if response_time > self.thresholds['max_avg_response_time']:
issues.append(f"响应时间过长: {response_time:.3f}s")
if diversity < self.thresholds['min_cluster_diversity']:
issues.append(f"群体多样性不足: {diversity:.3f}")
if issues:
status = f"警告 - {', '.join(issues)}"
self._send_alert(issues)
else:
status = "健康"
return status
def _send_alert(self, issues: List[str]):
"""发送告警邮件"""
subject = "用户聚类系统告警"
body = "检测到以下问题:\n\n" + "\n".join(f"• {issue}" for issue in issues)
body += f"\n\n时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}"
# 简化版邮件发送(生产环境需要完整配置)
try:
# 这里应该是真实的邮件发送逻辑
print(f"ALERT: {subject}")
print(body)
except Exception as e:
print(f"发送告警邮件失败: {e}")
def perform_health_check(self) -> Dict[str, Any]:
"""执行健康检查"""
start_time = time.time()
try:
# 测试预测功能
test_user = {
'sessions_count': 10,
'avg_session_duration': 300,
'page_views_per_session': 8,
'total_spent': 1500,
'purchase_frequency': 0.5,
'last_purchase_days': 7,
'avg_order_value': 300,
'total_session_duration': 3000,
'total_page_views': 80,
'recency_score': 0.8,
'engagement_score': 0.7
}
result = self.model_service.predict_cluster(test_user)
response_time = time.time() - start_time
self.record_prediction(
cluster=result.get('cluster', -1),
response_time=response_time,
error=result.get('status') == 'error'
)
health_metrics = self.calculate_metrics()
self.metrics['last_health_check'] = datetime.now()
return {
'status': 'success',
'response_time': response_time,
'test_prediction': result,
'metrics': health_metrics
}
except Exception as e:
return {
'status': 'error',
'error': str(e),
'response_time': time.time() - start_time
}
def generate_daily_report(self) -> Dict[str, Any]:
"""生成日报"""
metrics = self.calculate_metrics()
report = {
'report_date': datetime.now().strftime('%Y-%m-%d'),
'summary': {
'total_predictions': metrics['total_predictions'],
'system_health': metrics['health_status'],
'performance_rating': self._calculate_performance_rating(metrics)
},
'detailed_metrics': metrics,
'recommendations': self._generate_recommendations(metrics)
}
return report
def _calculate_performance_rating(self, metrics: Dict) -> str:
"""计算性能评级"""
score = 0
if metrics['error_rate'] < 0.01:
score += 2
elif metrics['error_rate'] < 0.05:
score += 1
if metrics['avg_response_time'] < 0.5:
score += 2
elif metrics['avg_response_time'] < 1.0:
score += 1
if metrics['cluster_diversity'] > 0.3:
score += 1
ratings = {5: '优秀', 4: '良好', 3: '一般', 2: '需改进', 1: '差', 0: '极差'}
return ratings.get(score, '未知')
def _generate_recommendations(self, metrics: Dict) -> List[str]:
"""生成改进建议"""
recommendations = []
if metrics['error_rate'] > 0.03:
recommendations.append("检查模型输入数据质量,优化异常处理")
if metrics['avg_response_time'] > 0.8:
recommendations.append("优化特征计算逻辑,考虑缓存机制")
if metrics['cluster_diversity'] < 0.2:
recommendations.append("考虑重新训练模型或调整聚类参数")
if len(metrics['cluster_distribution']) < 3:
recommendations.append("用户群体区分度不足,建议特征工程优化")
if not recommendations:
recommendations.append("系统运行良好,继续保持监控")
return recommendations
# 监控系统使用示例
if __name__ == '__main__':
# 初始化模型服务
with open('features.json', 'r') as f:
feature_names = json.load(f)
model_service = UserClusteringService(
model_path='kmeans_model.pkl',
scaler_path='scaler.pkl',
feature_names=feature_names
)
# 初始化监控系统
monitor = ClusteringMonitor(
model_service=model_service,
alert_emails=['admin@company.com']
)
# 执行健康检查
health_result = monitor.perform_health_check()
print("健康检查结果:", json.dumps(health_result, indent=2, ensure_ascii=False))
# 生成日报
daily_report = monitor.generate_daily_report()
print("\n每日报告:", json.dumps(daily_report, indent=2, ensure_ascii=False))
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
