Nature系列|免疫浸润分析使用ssGSEA、GSVA都可以吗
原创
Nature系列|免疫浸润分析使用ssGSEA、GSVA都可以吗
原创
生信小博士
发布于 2025-11-01 16:47:18
发布于 2025-11-01 16:47:18
- 富集分析四兄弟:谁才是你的最佳选择?
- 一文厘清富集分析:GroupGO、enrichGO、gseGO、enrichKEGG、gseKEGG、enrichMKEGG
- enrich_degs_by_celltypes:对单细胞数据中按照不同细胞类型进行两组间的差异分析进行富集分析GO、KEGG
- GO富集分析结果太多,如何筛选?
- 获取KEGG通路的基因列表 做单细胞GSEA、GSVA分析(代码版)
- 获取msigdb所有通路或者特定通路、基因代码(代码版)
- Msigdb如何查找特定基因集合(网页版)
- 富集分析必看:GSVA 的思路与用法(完整代码)
结论先行
- 两者都适合做免疫浸润分析(bulk RNA-seq、单细胞伪合并/pseudobulk、空间转录组数据都可),前提是用高质量的免疫细胞特异基因集(如 LM22、xCell/MCP-counter 的细胞签名、自己从 scRNA 提炼出来的细胞签名),并处理好批次与归一化。
- ssGSEA:逐样本、基于秩的“单样本 GSEA”。对极值/尺度更稳,样本内排名为主,适合样本很少、或你只关心每个样本内部免疫谱的相对强弱。
- GSVA(默认核密度法):在样本集合上对基因表达分布做非参数变换,再对基因集做“随机游走”累积差分,更擅长在多样本之间对比、对中低表达的稳定性更好,但需要一批样本一起跑才能体现优势。
原理与差异
维度 | ssGSEA | GSVA(method="gsva") |
|---|---|---|
核心思想 | 对每个样本把所有基因做排名;对每个基因集做“随机游走”得到 enrichment score(ES) | 先把所有样本的基因表达做非参数分布估计(核密度),把原表达映射到“连续等级”;再对基因集做累积差值得到分数 |
输入依赖 | 单个样本即可;跨样本比较通常要再做行/列归一化 | 需要一个样本集合(≥5 更稳) |
对极值/测序深度 | 基于秩,不依赖绝对表达,对测序深度与极值较稳 | 做了分布变换,对中低表达更友好,能放大真实变动、压制技术噪声 |
分数可比性 | 样本内相对强弱可靠;跨样本需标准化(如行 z-score) | 设计上更利于样本间比较 |
小样本/单样本 | 友好(“单样本”本意) | 不适合严格的单样本场景 |
基因集大小与重叠 | 大小偏差与基因集重叠会带来得分偏 | 也会;两者都建议控制大小、减少重叠、做基因集修剪 |
为什么它们能用于“免疫浸润”? “免疫浸润”本质是细胞组成与活性在转录层面的影子。若有“某免疫细胞特异高表达的一组基因”(签名),那这组基因在一个样本里整体越靠前/越高,通常说明:
- 该细胞占比更高(组成效应),或
- 该细胞更活跃(状态效应),或二者兼有。 ssGSEA/GSVA 正是把“这一组基因是否整体靠前/更活跃”转成一个分数,因此可以作为免疫浸润的相对指标。
关键提醒:它们给的是相对活性/丰度分而非绝对“比例”。要想获得“细胞比例”,优先用去卷积方法(如 CIBERSORTx、EPIC、MCP-counter、quanTIseq),或用流式/病理定量来验证。
什么时候选谁?
- 选 ssGSEA:
- 极少样本(甚至单个样本、单个病人报告)
- 异构平台或批次差很大、只能做样本内排名来规避尺度问题
- 想把签名直接应用到单细胞的 pseudobulk或空间 spot且样本量偏小
- 选 GSVA(默认 method="gsva"):
- 队列型研究,需比较组间差异、做下游统计建模
- 你关心中等表达的稳定趋势,希望分数对跨样本比较更平滑
- 折中:用
GSVA::gsva()同一接口里跑method="ssgsea"或"gsva",两者都算一遍,选择更稳定/更符合生物学的。
实战要点(避免“伪浸润”)
- 归一化/批次
- bulk:建议
TPM/CPM + log1p,或 DESeq2 VST;跨批次用 ComBat/limma removeBatchEffect。 - scRNA-seq 的 pseudobulk:先每样本/每亚群求和再
TMM/VST。
- bulk:建议
- 细胞签名质量(也就是免疫基因集的质量)
- 物种匹配、去掉非特异或普遍上调(如核糖体、热休克、IFN 即时早基因)
- 签名大小 20–200 基因较稳,过小/过大都不理想;减少不同细胞签名间的重叠
- 可比性与统计
- ssGSEA 结果常对每个基因集跨样本 z-score后再做组间比较;GSVA 直接进入线性模型/差异分析。
- 多基因集比较要做多重校正(BH/FDR)。
- 正交验证
- 与去卷积(CIBERSORTx/MCP-counter/xCell)做相关性
- 与 IHC/IF 计数、流式、病理评估对照
- 单细胞/空间
- 单细胞层面更推荐模块打分(Seurat AddModuleScore、AUCell),或先 pseudobulk 再 GSVA/ssGSEA,减少稀疏度影响。
- 空间转录组:对 spot 做 ssGSEA/GSVA 后,用组织学区域或细胞解卷积结果交叉验证。
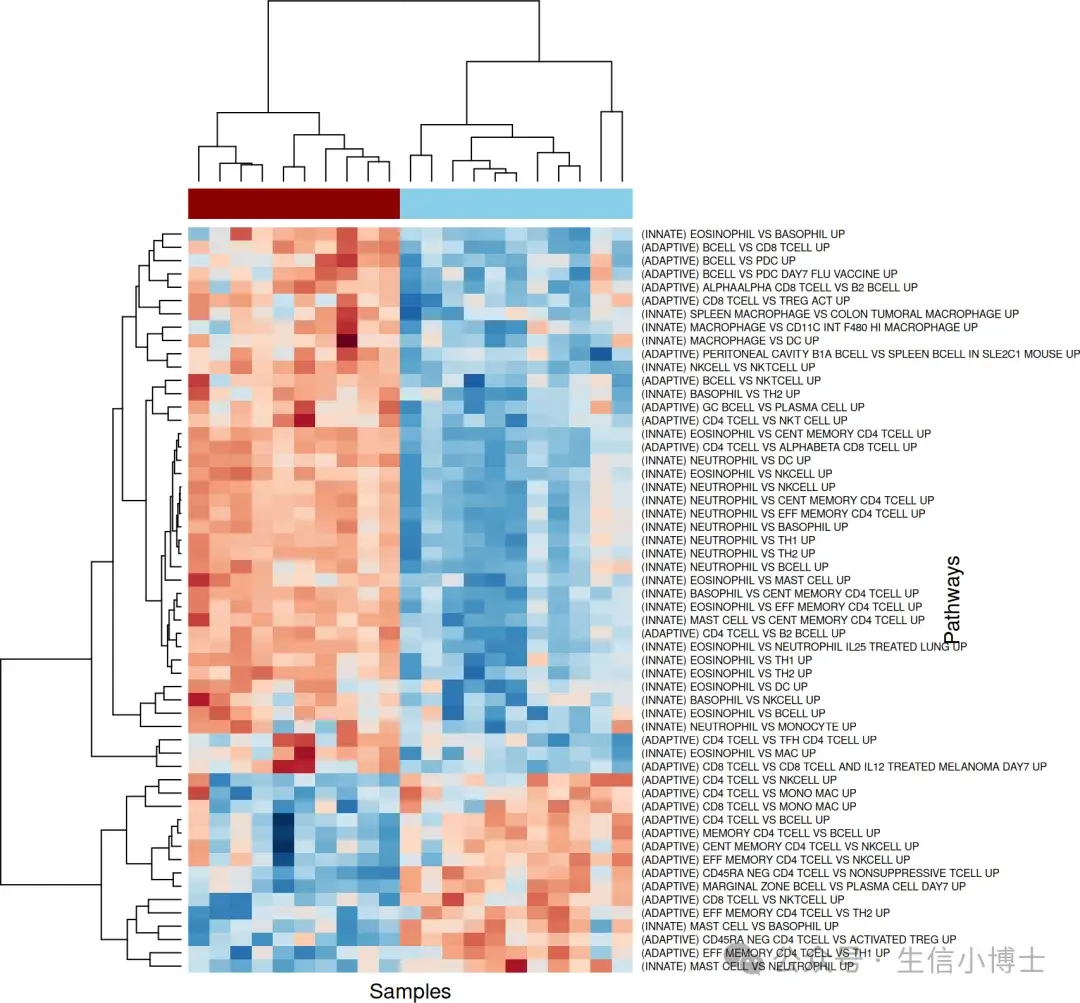
文献中使用ssgsea做免疫浸润的案例
- (A) Correlation between MCTS1 expression and relative abundance of 24 types of immune cell. The size of dot corresponds to the absolute Spearman’s correlation coefficient values.
mehods Immune Infiltration Analysis A total of 24 immune cells were used to calculate the level of immune infiltration, and the relative enrichment score of these immune cells in breast cancer was assessed by single-sample GSEA, which was accomplished using the R package GSVA (Bindea et al, 2013). The correlation between the expression of MCTS1 and these immune cells was investigated using the Spearman’s correlation analysis, and the differences in the level of immune infiltration between the high and low MCTS1 expression groups were evaluated using the Wilcoxon ranksum test. 结果描述 Correlation Between MCTS1 Expression and Immune Infiltration The expression of MCTS1 was significantly negatively correlated with the levels of immune cell infiltration of natural killer (NK) cells (r = –0.240, p < 0.001), CD8+ T cells (r = –0.220, p < 0.001), effector memory T (TEM) cells (r = –0.210, p < 0.001), and plasmacytoid dendritic cells (pDCs) (r = –0.210, p < 0.001) (Figure 7A).
https://www.bioconductor.org/packages/devel/bioc/vignettes/GSVA/inst/doc/GSVA.html#:~:text=Gene%20set%20variation%20analysis%20,wise原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号