【C/C++】初识C++(二):深入详解缺省参数(默认参数)函数重载、引用(重头戏)

【C/C++】初识C++(二):深入详解缺省参数(默认参数)函数重载、引用(重头戏)

艾莉丝努力练剑
发布于 2025-11-13 10:19:41
发布于 2025-11-13 10:19:41
🔥个人主页:艾莉丝努力练剑 ❄专栏传送门:《C语言》、《数据结构与算法》、C语言刷题12天IO强训、LeetCode代码强化刷题、C/C++干货分享&学习过程记录 🍉学习方向:C/C++方向 ⭐️人生格言:为天地立心,为生民立命,为往圣继绝学,为万世开太平
前言:本专栏记录了博主C++从初阶到高阶完整的学习历程,会发布一些博主学习的感悟、碰到的问题、重要的知识点,和大家一起探索C++这门程序语言的奥秘。本文作为本专栏的第二篇文章,起到了奠定基调的作用。这个专栏将记录博主C++语法、高阶数据结构、STL的学习过程,正所谓“万丈高楼平地起”,我们话不多说,继续进行C++阶段的学习。
C++的两个参考文档:
老朋友(非官方文档):cplusplus 官方文档(同步更新):cppreference
补充说明部分
1、补充1——提高效率
我们在IO要求比较高的地方,如部分大量输入的竞赛题中,会输入以下三行代码来提高效率——
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
实际上就是关闭了C语言的同步,这个时候就不要混着写了,只能用C++一种语言写。 当然这三行代码还有很多内容我们现在还没有办法用现有的知识很好地解释。 等我们后面学习了IO流,会更细节地进行介绍,一个是ostream另一个是istream嘛。
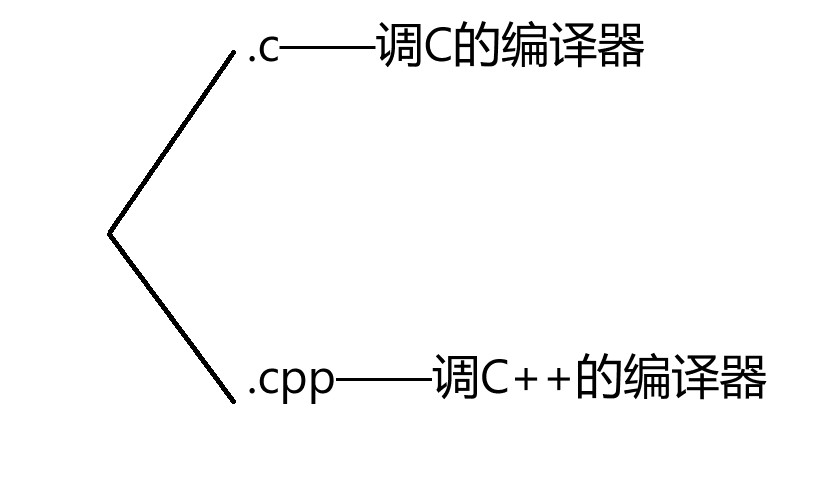
2、补充2——文件后缀
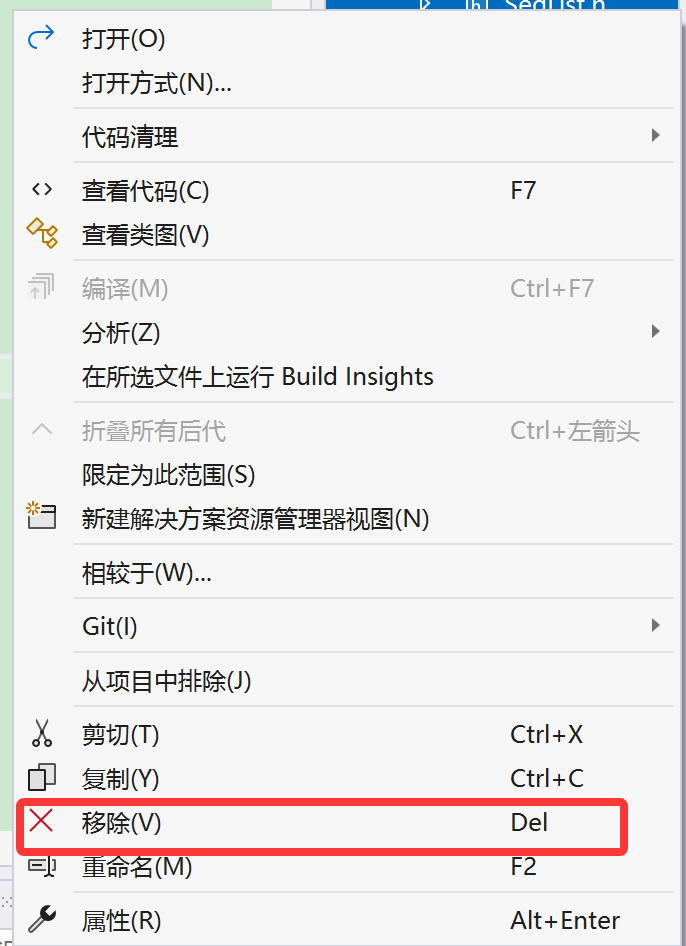
3、补充3——文件移除
注意:文件移除不等于文件删除(只是在编译的时候不编译进去)。
我们先右击鼠标移除一个文件——
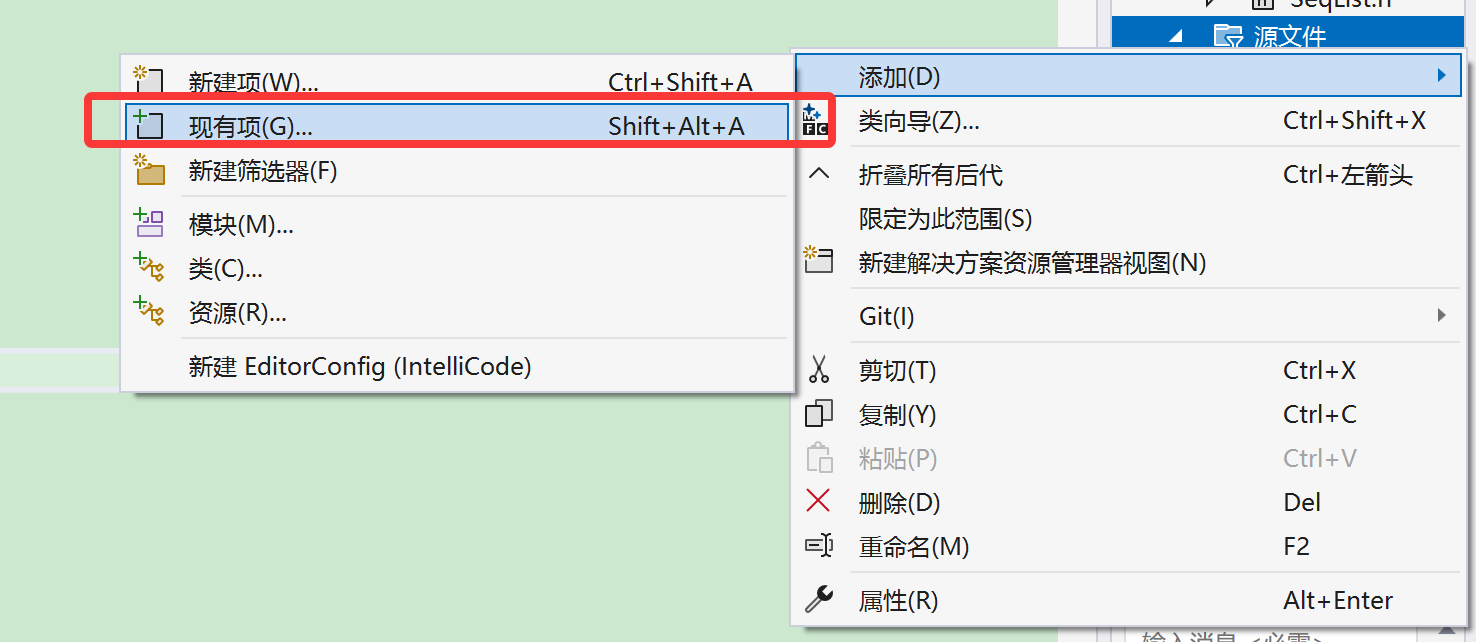
我们移除之后可以通过右击添加现有项——
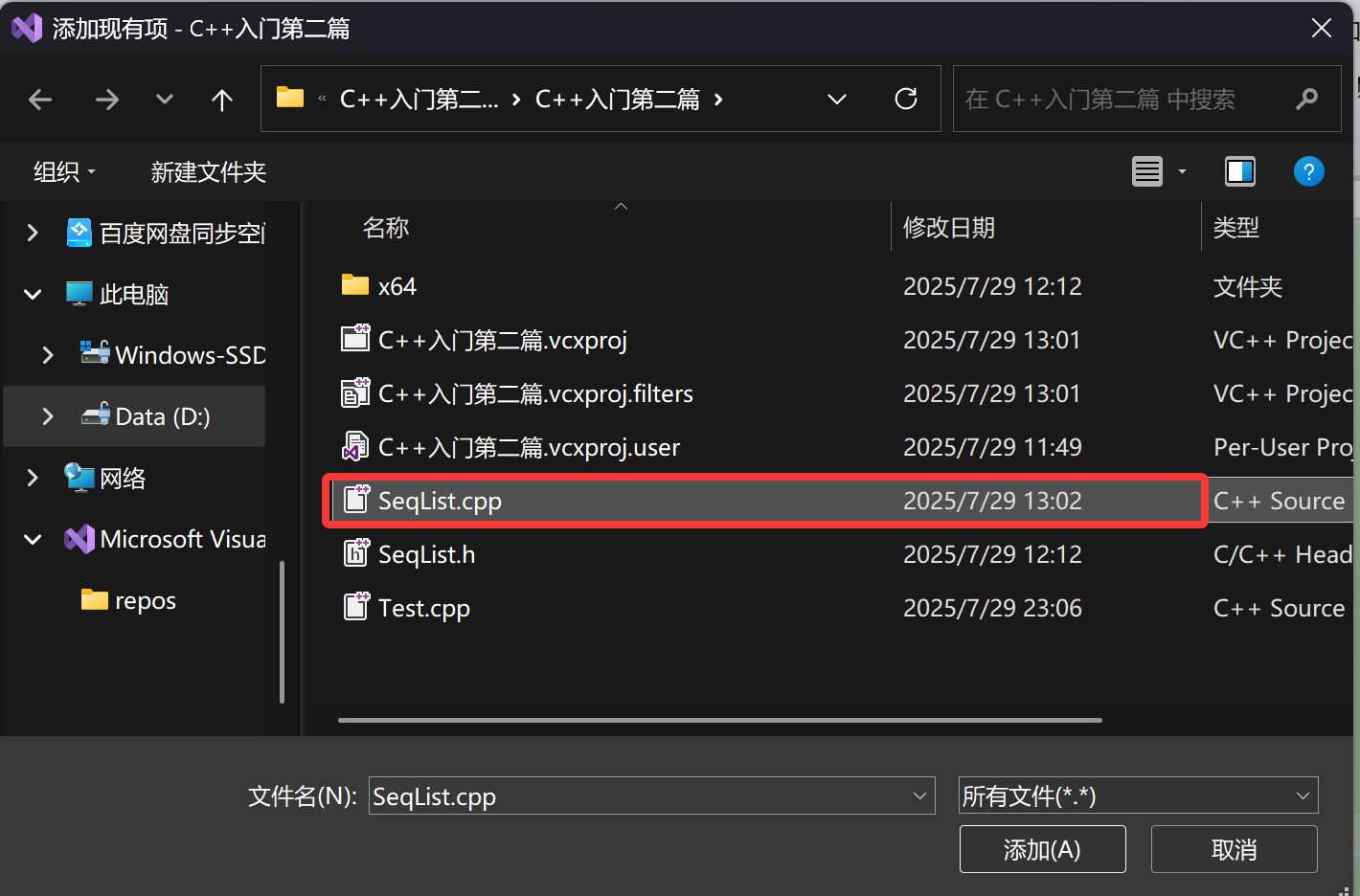
在文本资源管理器当前路径下找到我们移除的文件——
4、补充4——扩容会降低效率
#include<iostream>
#include"SeqList.h"
using namespace std;
int main()
{
int n;
cin >> n;
SL s1;
//没有扩容——扩容会降低效率
SLInit(&s1, n);
//n很大,比如100000,不断扩容
for (int i = 0; i < n; i++)
{
SLPushBack(&s1, i);
}
SL s2;
SLInit(&s2);
// 5 4 6 3 4 7 4
//查找出所有的4
int i = SLFind(&s2, 4);
while (i != -1)
{
i = SLFind(&s2, 4, i + 1);
}
return 0;
}这里没有用扩容——因为扩容会降低效率,假如这个n很大,比如100000,就需要不断扩容,效率会受影响。扩容要开空间、拷贝数据、释放旧空间,都是极大地代价。
如果我们上来malloc也不行,我们比如说直接malloc1000个空间,这样就定死了,万一只需要5个空间呢?那995个空间不是就浪费了吗?
我们初始化增加一个参数,来控制初始化的大小——
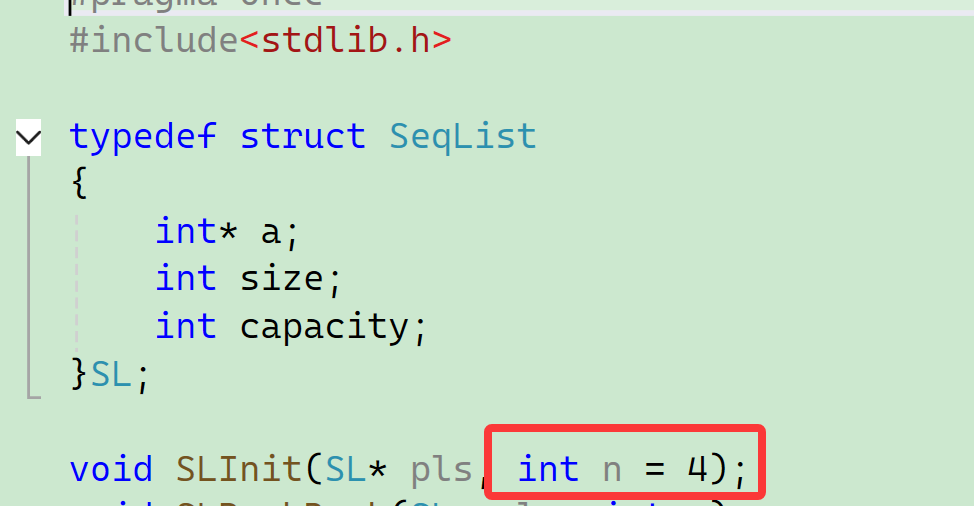
这样就没有扩容,我们初始化直接就开好这个空间了。 但是这样做的前提就是我们知道需要多大的空间,才可以这样整。

当然这样我们写的还不够好,如果我不知道要插入多少个数据,怎么办?

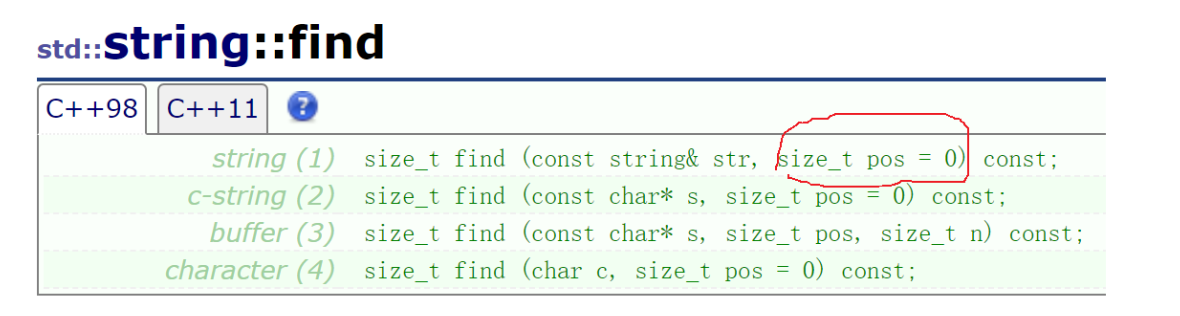
那就要用到接下来我们要介绍的缺省函数的知识了! 我们不知道改传多少的时候,默认传4个。 假如有这几个数字,要求我们查找出所有的4——

以前我们都是默认从0开始查找的,现在我们直接从i下标位置开始查找—— 如果没找到,就让它返回-1。如果想让它从0位置开始查找,那我们就可以不传这个参数。

这个程序就变成了这样一个逻辑。 因此这个地方也一样,也是加一个参数,以便更好地控制功能,给上缺省值就更好了——

三、C++入门基础
(三)缺省参数
1、理解缺省函数的概念
缺省博主记得应该在介绍C语言时就有提过一嘴,这里再说明一下:
缺省参数可以在传参时不传或者少传参数的函数,缺省参数又叫默认参数。
缺省参数是C++区别于C语言的一点,指的是在函数声明时可以给函数的形参设置一个初值,这个初值必须要是一个常量或者全局变量,但是我们一般不用全局变量,因为会存在线程安全的问题,因此一般来说就是用常量来设这个初值。
缺省参数的概念:
1、缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参,缺省参数分为全缺省和半缺省参数(有些地方把缺省参数也叫默认参数); 2、全缺省就是全部形参给缺省值,半缺省就是部分形参给缺省值。C++规定半缺省参数必须从右往左依次连续缺省,不能间隔跳跃给缺省值; 3、带缺省参数的函数调用,C++规定必须从左到右依次给实参,不能跳跃给实参; 4、函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省值,其实就是编译器为了防止程序员两次定义缺省给的不一样。
2、两种缺省函数
缺省函数分全缺省和半缺省。全缺省和半缺省的概念我们已经了解了,下面我们会举几个例子:
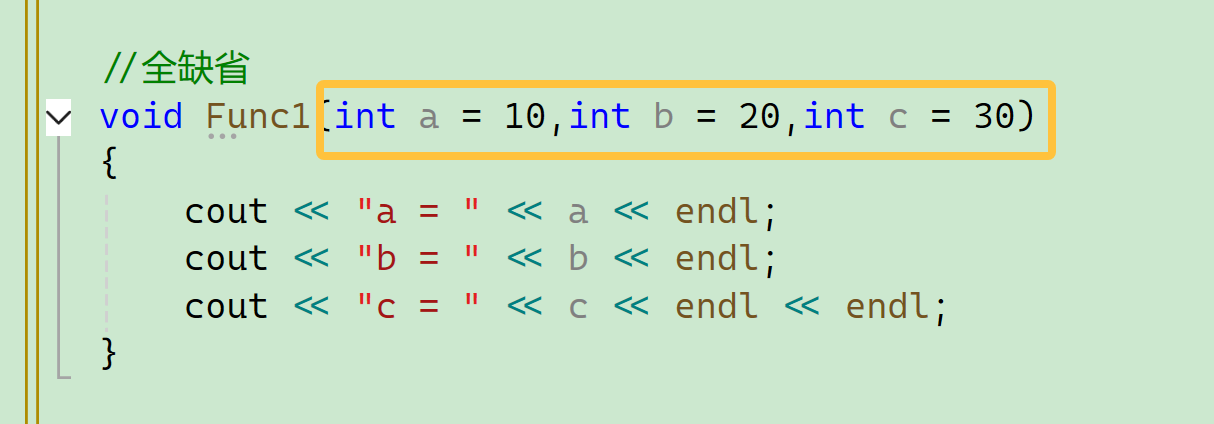
(1)全缺省(完全缺省)
顾名思义,全缺省就是可以不传任何参数,当然也可以传参数,这样会覆盖原来的值。
比如我们看下面的代码:
#include<iostream>
using namespace std;
void Func(int a = 0)
{
cout << a << endl;
}
//全缺省
void Func1(int a = 10,int b = 20,int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
Func(1);//实参
Func();//缺省值
Func1(1, 2, 3);
Func1(1, 2);
Func1(1);
Func1();
return 0;
}
三个都给了缺省值, 全缺省比较灵活,不用考虑跳不跳过的问题,我们可以灵活调配,a、b、c的位置可以随便放,因为这是你定义的函数嘛。这个方法在半缺省很适用。

传值是连续传的,不能跳过传下一个,以传三个为例:要么传第一个、要么传前两个,要么不传。
比如我们main函数就传3个值,也就是说,不能这样传——

可以看到,编译器也是冒出了红色波浪线的警告。
不能传空(这个不会用缺省值补,如果非要用某个默认值要么你就把参数位置调换一下)。
缺省值是从左往右给的,实参传参是从右往左传的。
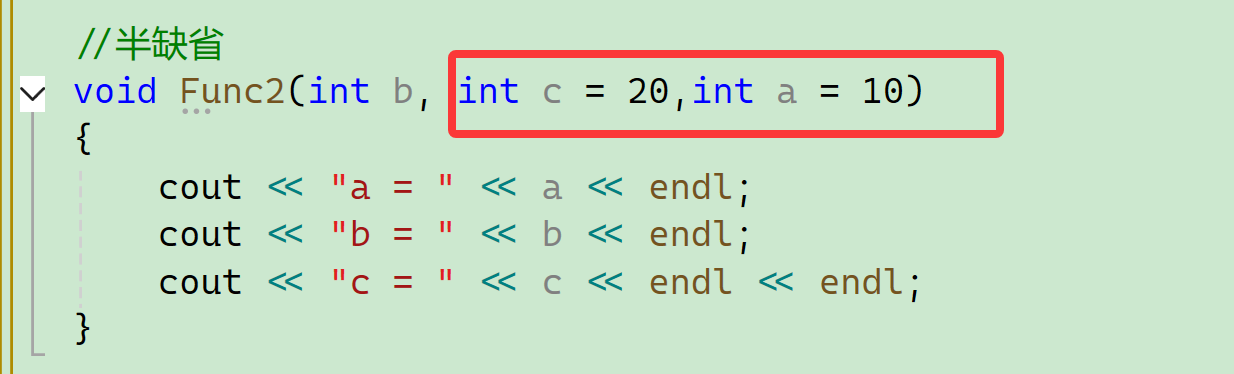
(2)半缺省(部分缺省)
半缺省不一定是一半,其实确切地说应该叫“部分缺省”是给部分形参设置默认值,而部分形参没有,因此在函数调用时未设置默认值的形参就必须传入对应的实参。
我们看下面的代码:
//半缺省
void Func2(int b, int c = 20,int a = 10)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
Func(1);//实参
Func();//缺省值
Func2(1);
Func2(1, 2);
Func2(1, 2, 3);
return 0;
}因为是从右往左依次连续缺省,不能跳跃给缺省值。函数是我们定义的,如果你要缺省某个值,可以把它放在右边,如下图,假如我们要缺省a,就把a放在了最右边,给了个缺省值,因为函数是我们定义的,哪些值要缺省,我们把它往后放就可以了。
3、注意事项
(1)(实参)从左往右传,(形参)从右往左(给缺省值)连续缺省; (2)从右往左依次连续缺省,不能跳跃给缺省值:

不能这样像上面写,而下面这样——
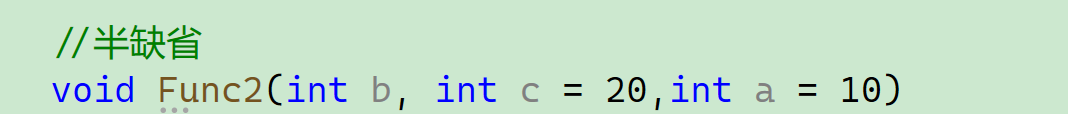
这样写是可以的; (3)比如说有.h声明文件、,c定义文件、test.c测试文件这样三个文件,我们就在声明文件里面给缺省值,在定义里面就不给缺省值了,这是为了防止缺省给的不一样。
补充:缺省参数的一些内容可以看一下博主在正文之前的【补充】。
(四)函数重载
1、函数重载的概念理解
C++支持在同一作用域中出现同名函数,但是要求这些同名函数的形参不同,可以是参数个数不同或者 类型不同。这样C++函数调用就表现出了多态行为,使用更灵活。C语言是不支持同一作用域中出现同名函数的。
2、函数重载
我们这里就展示几种不同——
以下就是三种不同的函数重载——
(1)参数类型不同
//函数重载
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}(2)参数个数不同
//2、参数个数不同
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}(3)参数类型顺序不同
//3、参数类型顺序不同
void f(int a,char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b,int a)" << endl;
}(4)返回值不同不能作为重载条件
返回值不同不能作为重载条件,因为调用时也无法区分。
//返回值不同不能作为重载条件,因为调用时也无法区分
void fxx()
{}
int fxx()
{
return 0;
}3、函数重载完整代码演示
代码演示如下——
//函数重载
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}
//2、参数个数不同
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}
//3、参数类型顺序不同
void f(int a,char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b,int a)" << endl;
}
#include<iostream>
using namespace std;
//下⾯两个函数构成函数重载
//不传参调用时,存在调用歧义
void f1()
{
cout << "f1()" << endl;
}
void f1(int a = 10)
{
cout << "f1(int a)" << endl;
}
int main()
{
cout << Add(1, 2) << endl;
cout << Add(1.1, 2.2) << endl;
//f();
//f(1);
//调用时无法确定要调用哪个
//fxx();
f1(1);
//f1();
return 0;
}4、多态行为
我们以后介绍【面向对象】的时候会详细介绍多态——面向对象的多态,博主现在先提一嘴,让大家先有个印象。
(五)C++的引用
前面我们讲的都是C++的一些小语法,感觉是Bjarne博士为了解决C语言的不足对其做的一些修改,接下来要介绍的是我们C++入门阶段学习的重头戏——引用(别名),其实也是为了解决C语言的一些缺陷,至于要解决的问题是什么呢?我们也不要废话,就是指针问题。
1、引用的概念理解
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间, 它和它引用的变量共用同一块内存空间。
总结:类型&引用别名 = 引用对象。
比如说绰号(或者像江湖上的呼号),就都是别名。比如以前古人的字,季汉的蜀相诸葛亮,复姓诸葛,名亮,字孔明,诸葛丞相是诸葛亮,诸葛孔明也是诸葛亮,“武侯”也是诸葛亮……大家明白了吗?取了别名,其实就是同一个东西。 再比如大家应该都读过《水浒传》,及时雨、呼保义都是宋江的江湖绰号,他又字公明,又是郓城县的押司,人又称“宋押司”,这些就是别名。
引用就等于取别名。
我们给已存在的变量取了别名,变量和别名共用同一块内存空间,不会新开辟空间。我们可以这样理解:江湖上多了个及时雨、呼保义,但是宋江没有多。
——这里我们留意一下,一会儿我们还会提到。
先说明:这里的不会开辟新空间其实是基于引用是语法层的概念。
2、&
C++中为了避免引入太多的运算符,会复用C语言的一些符号,比如前面的<<和>>,这里引用也和取地址使用了同一个符号&,大家注意使用方法角度区分就可以。
但是,不是说C++的&就没有取地址的功能,不是的,只是得看具体情境。
正因如此,因为C++复用C语言的一些符号才导致使用的时候容易混淆。
代码演示:
//引用
#include<iostream>
using namespace std;
int main()
{
int i = 0;
int& j = i;
cout << &i << endl;
cout << &j << endl;
++j;
//一个变量可以有多个引用
int& k = j;
k = 10;
//引用在定义时必须初始化
//int& x;
//x = i;
//引用一旦引用一个实体,再不能引用其他实体
int m = 20;
k = m;
return 0;
}(1)引用
这里符合引用的格式的就是作为引用的功能——

类型是int,引用别名是j,引用对象是i,引用别名即被引用对象:
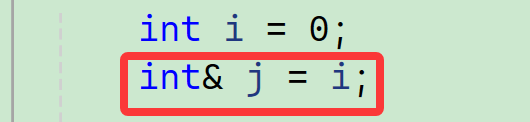
(2)取地址
这里前面什么都没有的、后面光一个变量,就是取地址——

为什么不改呢?既然复用了与C语言相同的符号,为什么不改呢?可以改,但是编程语言有一个“向前兼容”的问题,而且这么多年很多公司用现在的C++已经写了几千万行代码,如果轻易改了肯定会被程序员们、公司给骂死,甚至会放弃这门语言,不好随便就改了。
并且,语言很难统一。
3、引用的特性

问题: (1)可不可以给别名取别名?可以。 (2)可不可以取多个别名?可以。
都可以,在语法上是允许的。 因为地址都一样。
既然这样,我们来看一下引用有哪些特性——
(1)引用必须初始化,定义是就要确定是谁的别名,不能先定义再看是谁的别名; (2)语法上允许取多个别名; (3)引用一旦引用一个实体之后,就不能再引用其他实体了(那样其实只是赋值)。
这里的k = m只是赋值,不能是引用——

因为i、j、k的地址是相同的,而m和i、j、k的地址不同。
像这里 j 是 i 的别名,k 是 j 的别名,也就是说 k 也是 i 的别名——

说个不恰当的例子,赋值这个就像是你的老婆,不能一会儿是你的老婆,一会儿又变成别人的。哈哈哈,开个玩笑。
4、引用的使用
引用难不是难在语法,引用难就难在使用。
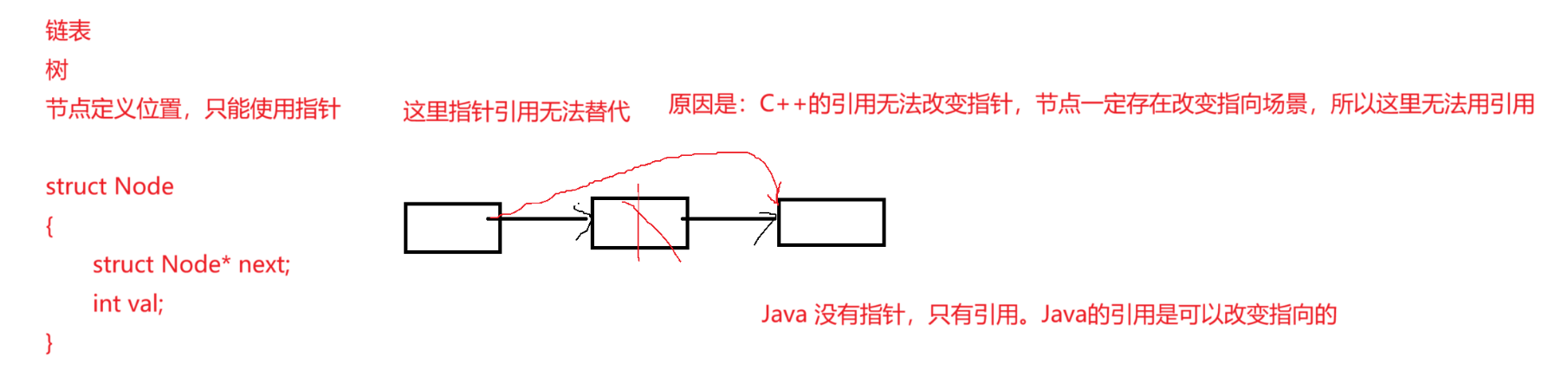
前面我们提到发明引用就是为了解决C语言中指针的问题。
大部分场景用引用去代替指针,部分场景还是得用指针—— 虽然引用确实用起来逻辑比指针通顺,但是像带节点的比如链表、二叉树依然还是得用指针来解决,节点定义位置,只能用指针,因为链表、链式结构二叉树不是连续的物理空间,这里指针引用了无法转向(无法改变转向),所以我们说:引用和指针是相辅相成的。
原因:C++的引用无法改变指针,节点一定存在改变指向的场景,所以这里无法使用引用。

5、引用的好处
1、引用可以减少拷贝,形参是实参的引用我们就不用拷贝了,从而提高了传参的效率; 2、改变引用对象的同时也改变了被引用对象。
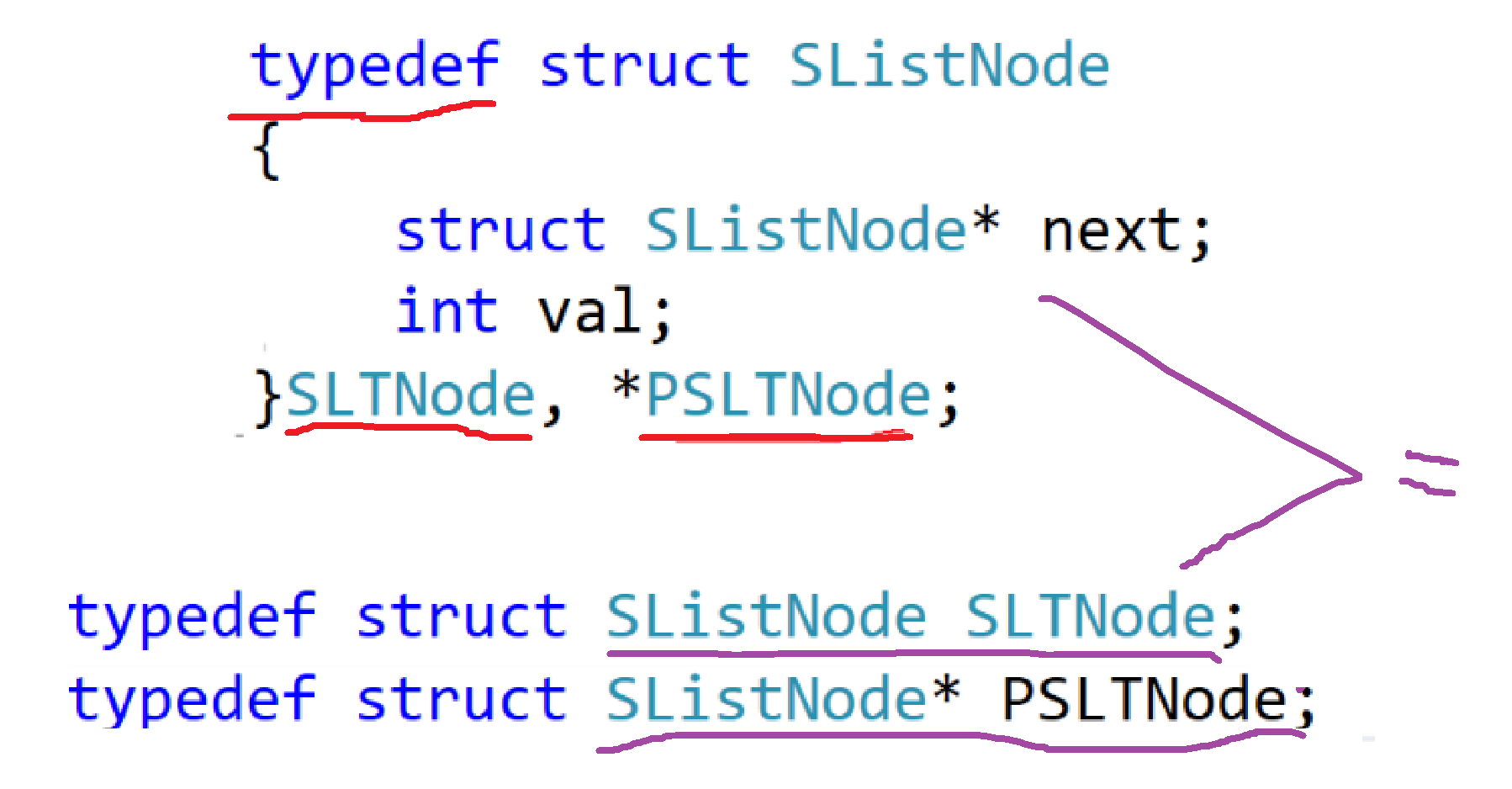
6、PSLTNode的幽灵
这个完全是学校教材的遗毒,让很多人看得一头雾水——这是什么玩意儿?
其实这是结构体指针。这两个就等价于这个——
大家看明白了吗?可能博主表达得还不是很清楚,看这个——

即:

我们这里typedef了一下,就是说我们重命名了一下,struct SListNode*就是PSLTNode,所以我们说,PSLTNode是结构体指针。
这里phead(形参)就是plist(实参)的别名,phead改变了就是plist改变了——

7、传返回值(引用)
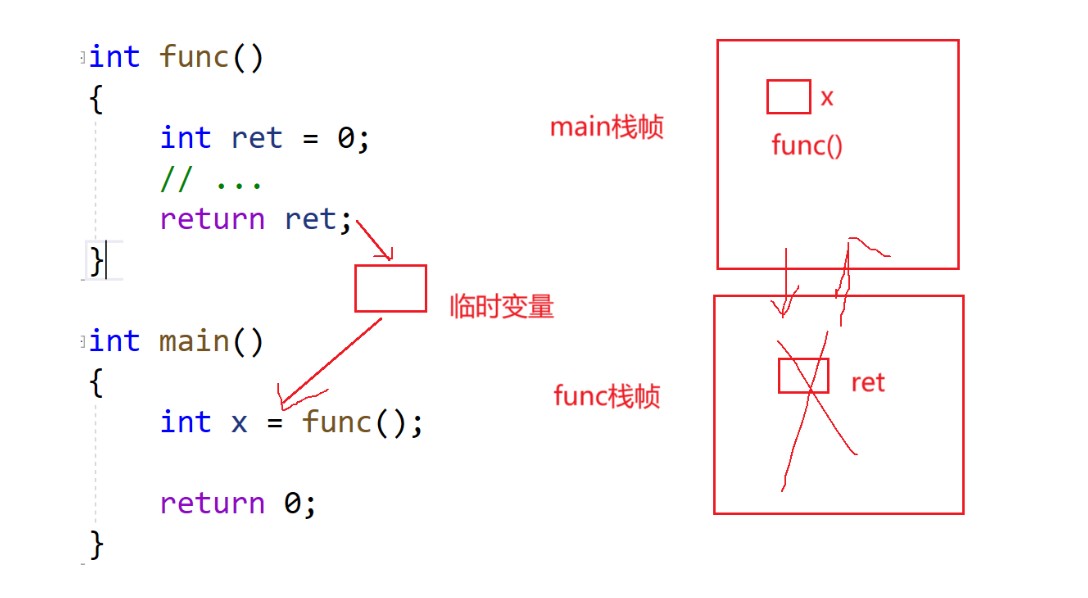
我们要结合【函数栈帧的创建与销毁】来看,这个博主也专门写了篇文章,链接如下:
【深入详解】函数栈帧的创建与销毁:寄存器、压栈、出栈、调用、回收空间
不会用ret作为返回值(func函数调用的返回值),ret——局部变量(出了作用域就销毁了)——栈帧销毁了。我们结合栈帧的内容加以理解。
传值返回的机制是我们介绍的第一个产生临时变量的场景,还有一个我们后面再介绍。
8、传引用返回(返回ret的别名)
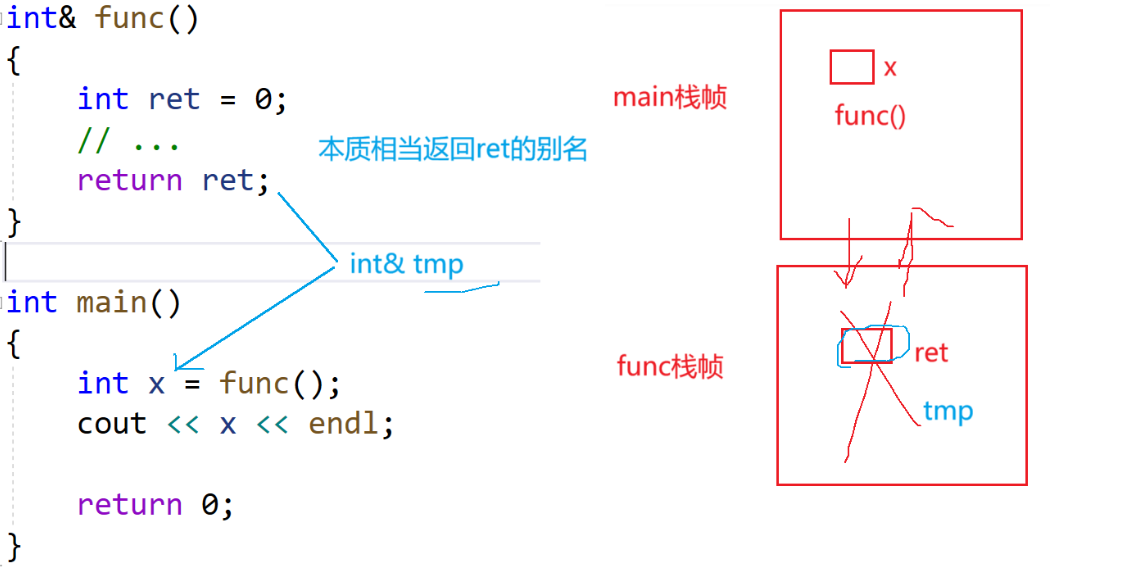
如图所示,本质上就相当于返回ret的别名。
ret已经销毁了,返回的其实是tmp的别名,x是tmp的别名,相当于x是tmp的别名。
这个程序其实有问题,本质相当于野指针的访问,两种可能的结果:0或者随机值。
9、内存空间的销毁 ≠ 空间没了
因为我们知道,内存可以反复使用,空间反复申请(操作系统分配)、归还操作系统。
打个比方,我们租房子住,房子退掉了,但是我们偷偷留下了一把“钥匙”,我们虽然把房子退了,但还是能通过这把“钥匙”进入房子——违法的访问,这是非法的,但是房子退了只是这个房子我不住了——这块内存空间还给操作系统了——但我依然能通过一些“钥匙”进入房子,即访问这块内存空间,也就是说,虽然内存空间free了,但这块空间还是存在的。
10、越界不一定会报错——越界抽查
注意,我们说的是不一定。
相当于访问野指针,但请注意:
越界读不会报错("r"),越界写才会报错("w")。
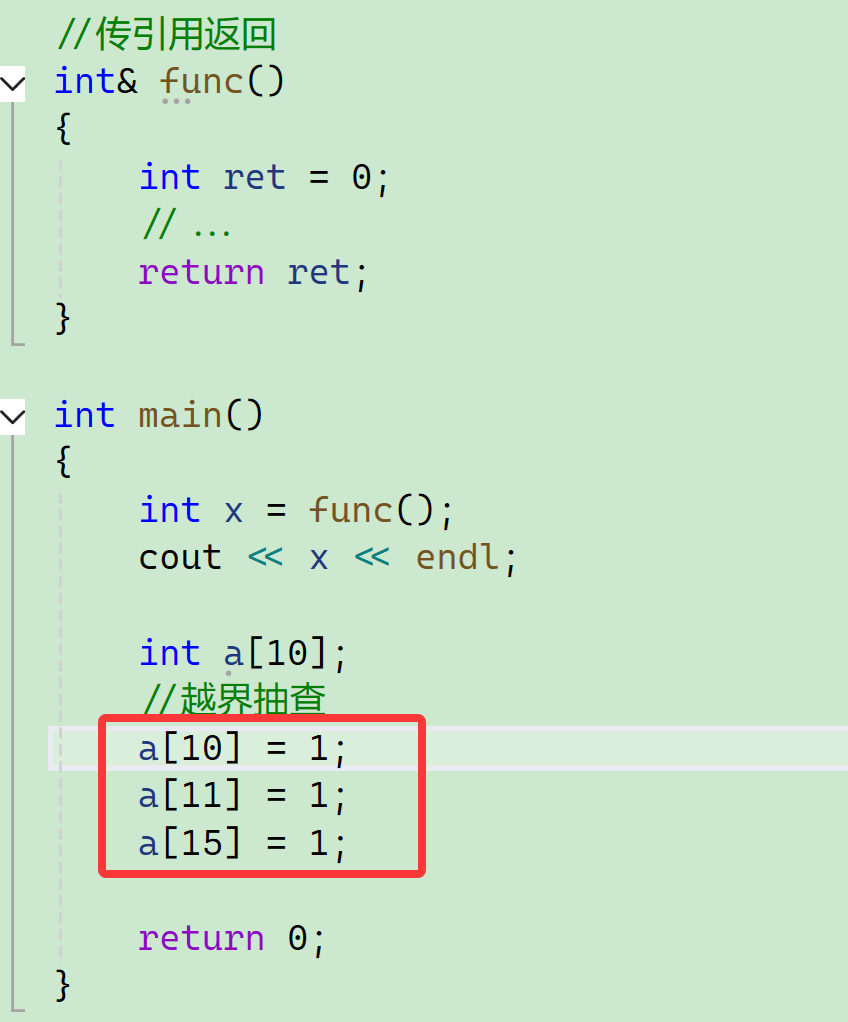
抽查:抽越界的头两个位置。 返回值0,说明通过了。
11、传引用ret
我们来看一个很神奇的程序结果——
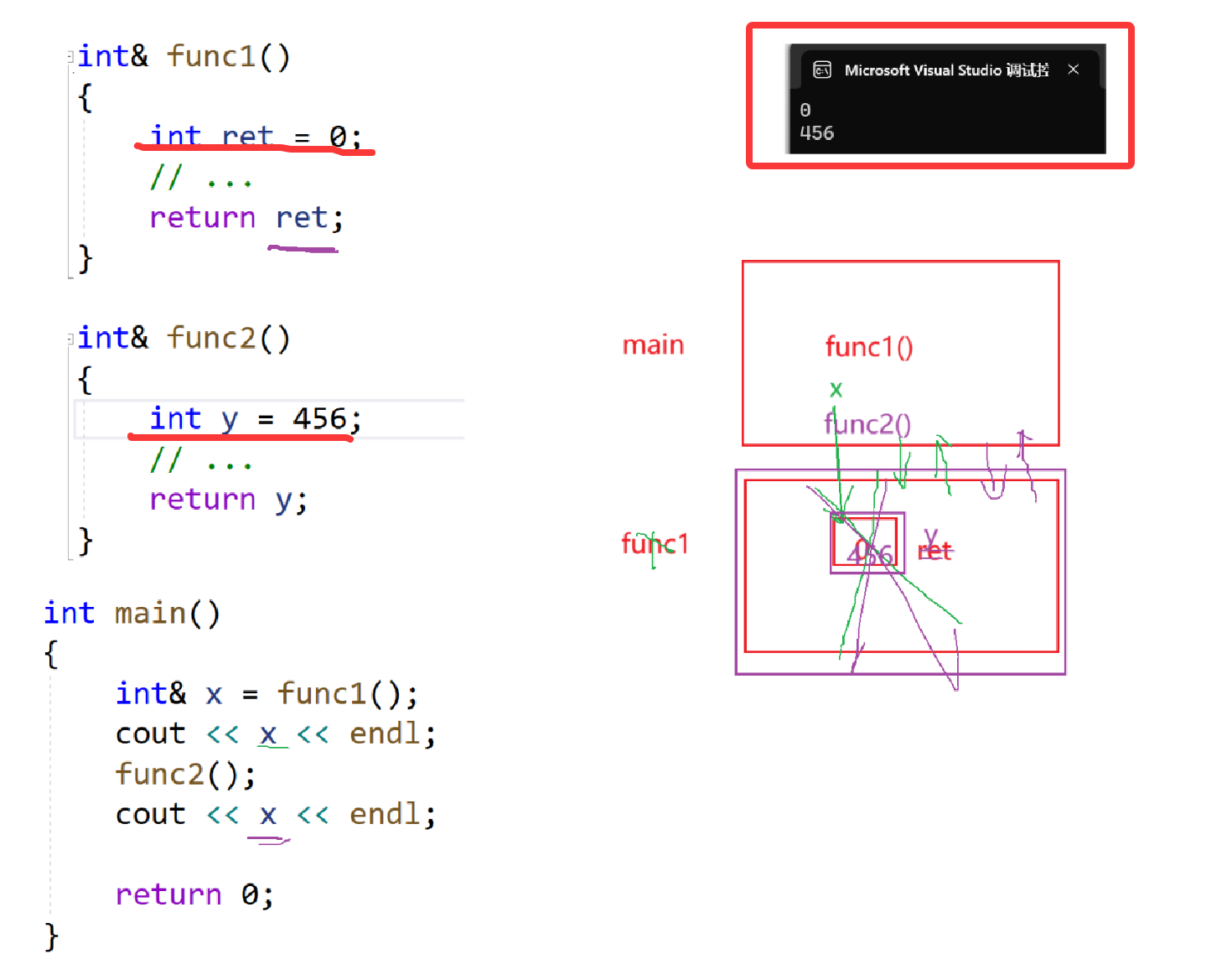
这里func1和func2重叠了。
为什么会这样呢?因为ret和y使用的其实是同一块空间,栈帧是向下使用的。
这个例子其实也是错的(返回的引用是野指针,不安全,可能会被别人修改)。
12、传引用返回应该怎么正确使用?
加上static,这个static我们之前也介绍过:

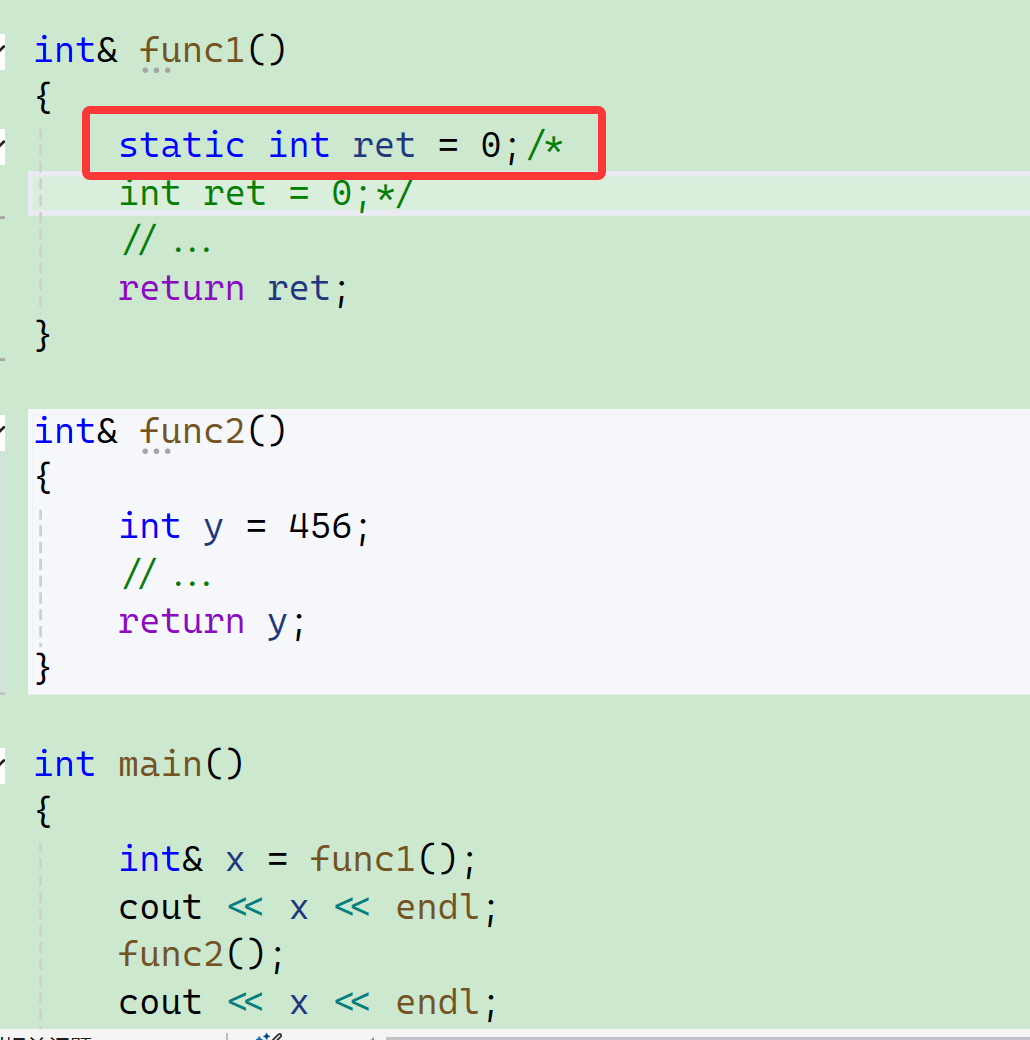
这样不受栈帧影响的才能用传引用返回。 传引用返回的本质是:返回返回对象的引用(别名),提高了效率,同时改变返回对象。
注意:如果返回值是个局部变量,存在风险。
13、下标位置访问
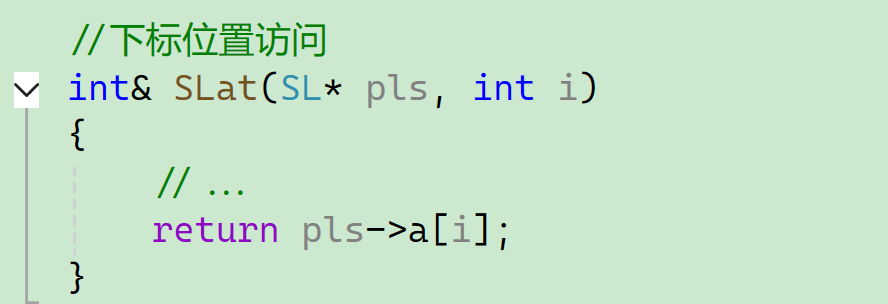
14、修改引用对象
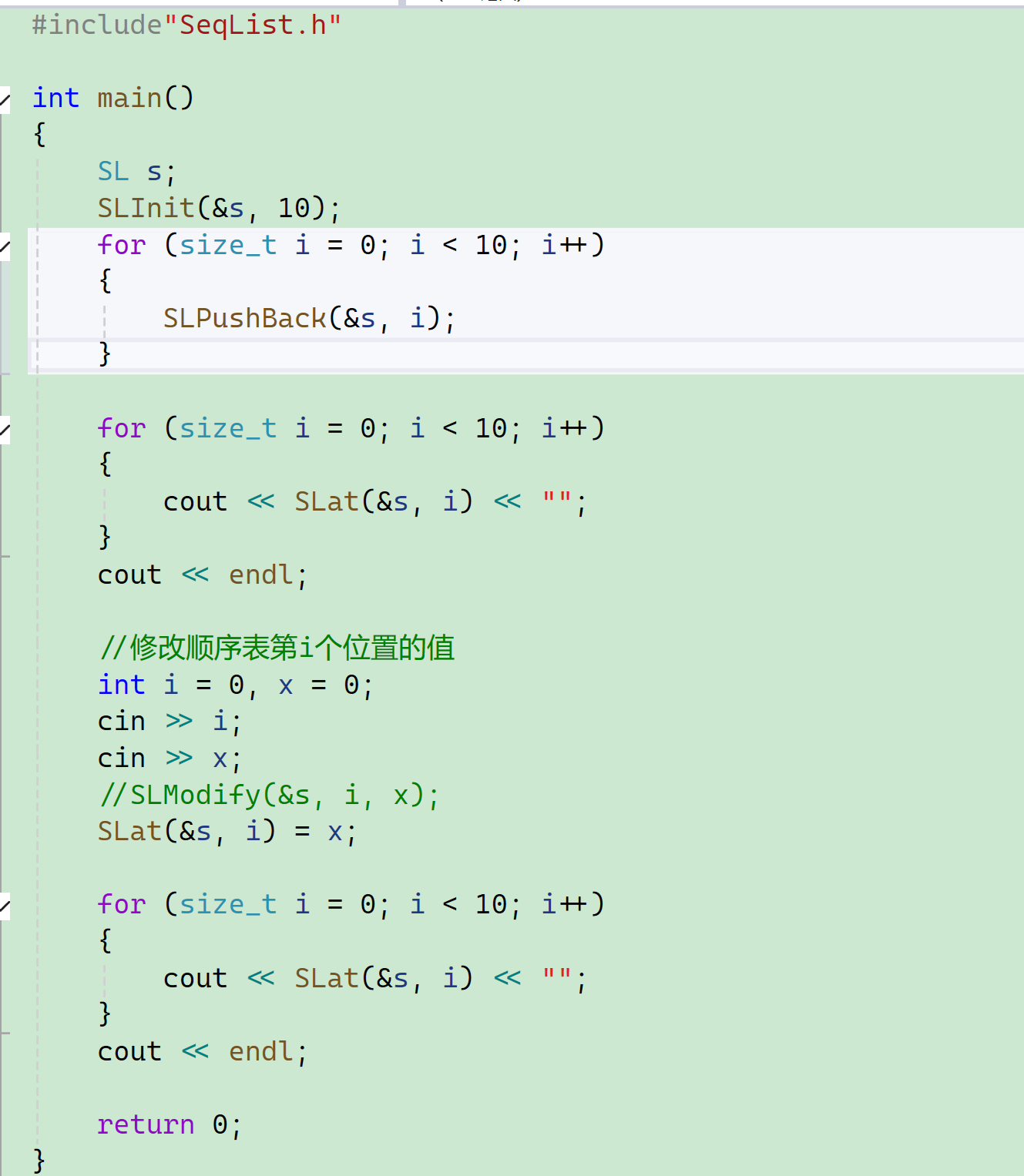
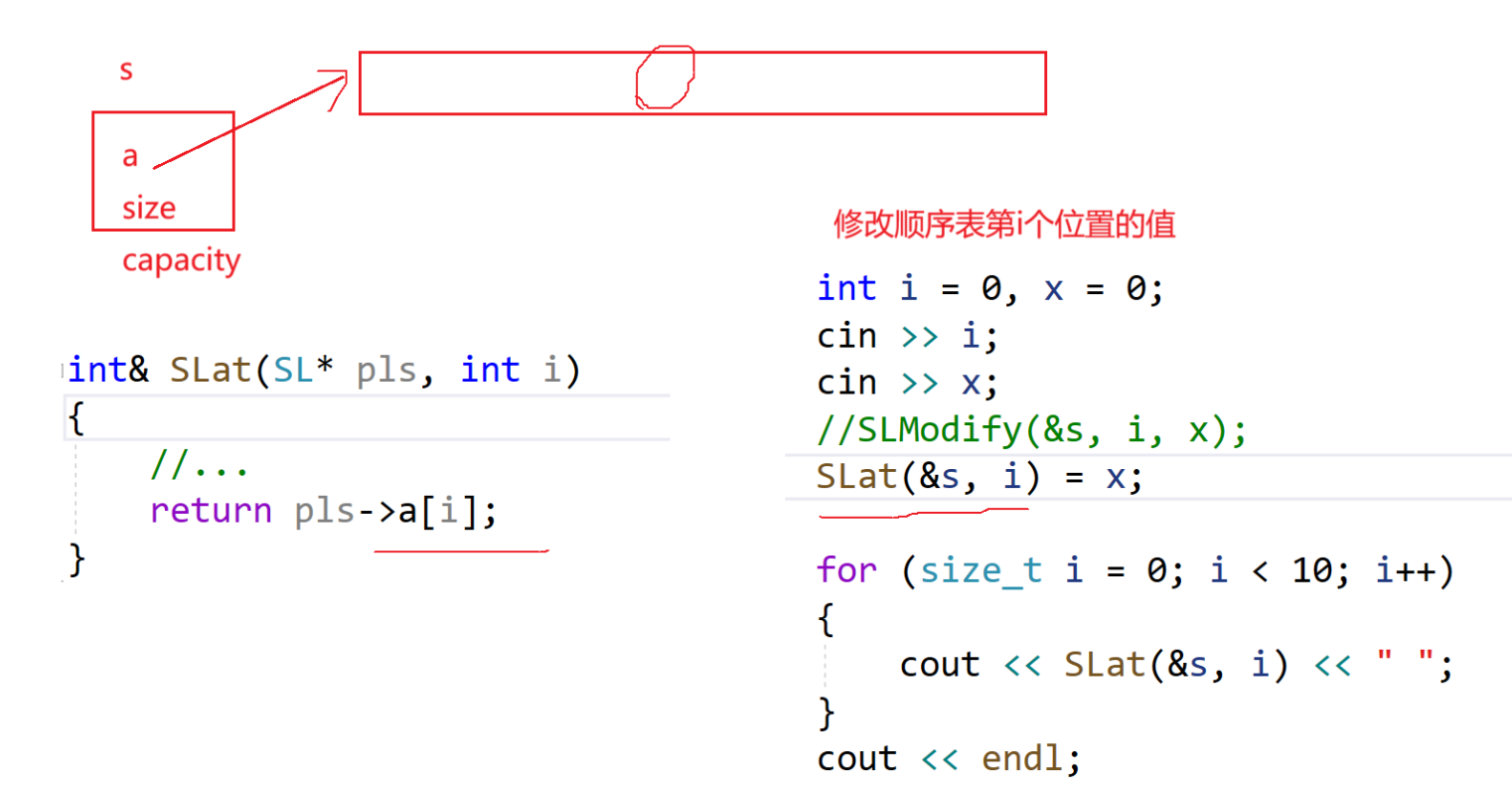
这样我们就不需要Modify这个方法了,直接一个SLat就解决了。

这两行代码是等价的——

这里一来我们既可以读,也可以修改顺序表对应位置的值,就完全不需要Modify了。
这是修改引用对象的例子。
15、引用的使用场景
问题:为什么ret销毁了还能变成引用? ——加深对引用的理解
语法上引用不开空间,指针要开空间。
我们转到【反汇编】,看一下反汇编——
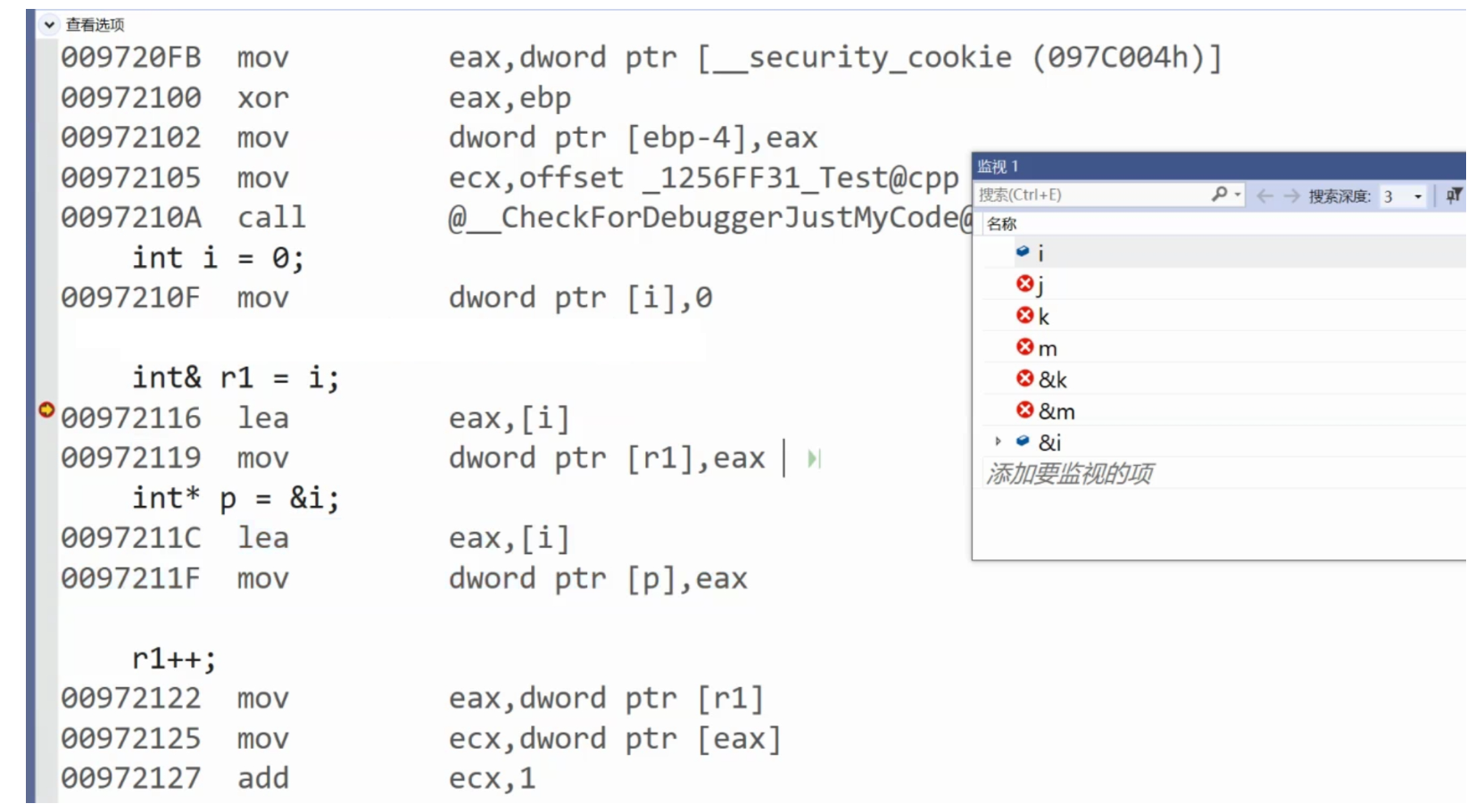
我们学习C++还是要懂一些汇编的知识。
通过观察汇编,我们发现:其实引用和指针是一样的。
引用(不开空间)是语法层的概念,到了汇编层面没有引用,实现还是底层去实现的,而底层本质还是指针来实现的,用指针来实现,那还是要开空间——

博主再举个例子,就比如“老婆饼”,我们经常调侃的“老婆饼里面没老婆”,这个老婆饼就是表达层,老婆饼一定是老婆做的吗?只是表达上的一种比喻呀!就像老婆做的一样。老婆饼这个就是表达层,而底层是谁来实现的呢?也就是说这个老婆饼是谁做的呢?可能是个老太太,甚至可能不是个女的做的,这就相当于实现层。
空间还在,地址也知道。
——这就是为什么ret销毁了还能变成引用。
结尾
本文的完整代码
1、SeqList.h
#pragma once
#include<stdlib.h>
typedef struct SeqList
{
int* a;
int size;
int capacity;
}SL;
void SLInit(SL* pls, int n = 4);
void SLPushBack(SL* pls, int x);
int SLFind(SL* pls, int x, int i = 0);
int& SLat(SL* pls, int i);
void SLModify(SL* pls, int i, int x);2、SeqList.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"SeqList.h"
void SLInit(SL* pls, int n)
{
pls->a = (int*)malloc(n * sizeof(int));
pls->size = 0;
pls->capacity = n;
}
void SLPushBack(SL* pls, int x)
{
//...
pls->a[pls->size++] = x;
}
//查找
int SLFind(SL* pls, int x,int i)
{
while (i < pls->size)
{
//...
}
return -1;
}
//下标位置访问
int& SLat(SL* pls, int i)
{
//...
return pls->a[i];
}
void SLModify(SL* pls, int i, int x)
{
//...
pls->a[i] = x;
}3、Test.c
#define _CRT_SECURE_NO_WARNINGS 1
//#include<iostream>
//using namespace std;
//
//int main()
//{
// int i = 0;
// cout << "XXX" << i << '\n' << endl;
// printf("%d\n", i);
//
// return 0;
//}
//#include<iostream>
//using namespace std;
//
//int main()
//{
// //在IO要求比较高的地方,如部分大量输入的竞赛题中,输入以下三行代码
// //可以提高C++IO效率
// ios_base::sync_with_stdio(false);
// cin.tie(nullptr);
// cout.tie(nullptr);
// //关闭了C语言的编译同步,这个时候就不要混着写了,只能用C++写
//
// return 0;
//}
//#include<iostream>
//using namespace std;
//
//void Func(int a = 0)
//{
// cout << a << endl;
//}
//
////全缺省
//void Func1(int a = 10,int b = 20,int c = 30)
//{
// cout << "a = " << a << endl;
// cout << "b = " << b << endl;
// cout << "c = " << c << endl << endl;
//}
//
////半缺省
//void Func2(int b, int c = 20,int a = 10)
//void Func2(int a = 10, int b,int c = 30)
//{
// cout << "a = " << a << endl;
// cout << "b = " << b << endl;
// cout << "c = " << c << endl << endl;
//}
//
//int main()
//{
// Func(1);//实参
// Func();//缺省值
//
// Func1(1, 2, 3);
// Func1(1, 2);
// Func1(1);
// Func1();
//
// Func2(1);
// Func2(1, 2);
// Func2(1, 2, 3);
//
// return 0;
//}
//#include<iostream>
//#include"SeqList.h"
//using namespace std;
//
//int main()
//{
// int n;
// cin >> n;
//
// SL s1;
// //没有扩容——扩容会降低效率
// SLInit(&s1, n);
//
// //n很大,比如100000,不断扩容
// for (int i = 0; i < n; i++)
// {
// SLPushBack(&s1, i);
// }
//
// SL s2;
// SLInit(&s2);
//
// // 5 4 6 3 4 7 4
// //查找出所有的4
// int i = SLFind(&s2, 4);
// while (i != -1)
// {
// i = SLFind(&s2, 4, i + 1);
// }
//
// return 0;
//}
/////////////////////////////////////////////////////////////////////////////////////////////////
////函数重载
////C不支持同名函数存在
//int Add(int left, int right)
//{
// //cout << "int Add(int left, int right)" << endl;
// return left + right;
//}
//
//double Add(double left, double right)
//{
// //cout << "double Add(double left, double right)" << endl;
// return left + right;
//}
//
//int main()
//{
// return 0;
//}
//#include<iostream>
//using namespace std;
//
////函数重载
//int Add(int left, int right)
//{
// cout << "int Add(int left, int right)" << endl;
// return left + right;
//}
//
//double Add(double left, double right)
//{
// cout << "double Add(double left, double right)" << endl;
// return left + right;
//}
//
////2、参数个数不同
//void f()
//{
// cout << "f()" << endl;
//}
//
//void f(int a)
//{
// cout << "f(int a)" << endl;
//}
//
////3、参数类型顺序不同
//void f(int a,char b)
//{
// cout << "f(int a,char b)" << endl;
//}
//
//void f(char b, int a)
//{
// cout << "f(char b,int a)" << endl;
//}
//
//////返回值不同不能作为重载条件,因为调用时也无法区分
////void fxx()
////{}
////
////int fxx()
////{
//// return 0;
////}
//
//#include<iostream>
//using namespace std;
////下⾯两个函数构成函数重载
////不传参调用时,存在调用歧义
//void f1()
//{
// cout << "f1()" << endl;
//}
//
//void f1(int a = 10)
//{
// cout << "f1(int a)" << endl;
//}
//
//int main()
//{
// cout << Add(1, 2) << endl;
// cout << Add(1.1, 2.2) << endl;
//
// //f();
// //f(1);
//
// //调用时无法确定要调用哪个
// //fxx();
//
// f1(1);
// //f1();
//
// return 0;
//}
////////////////////////////////////////////////////////////////////////////////////////////////
//引用
#include<iostream>
using namespace std;
int main()
{
int i = 0;
int& j = i;
cout << &i << endl;
cout << &j << endl;
++j;
//一个变量可以有多个引用
int& k = j;
k = 10;
//引用在定义时必须初始化
//int& x;
//x = i;
//引用一旦引用一个实体,再不能引用其他实体
int m = 20;
k = m;
return 0;
}
#include<iostream>
using namespace std;
//指针
//引用
//大部分场景去替代指针,部分场景还是离不开指针
//void Swap(int* rx, int* ry)
//{
// int tmp = *rx;
// *rx = *ry;
// *ry = tmp;
//}
//
//void Swap(int& rx, int& ry)
//{
// int tmp = rx;
// rx = ry;
// ry = tmp;
//}
//
//typedef struct SeqList
//{
// //...
//}SL;
////void SLInit(SL*ps1,int n = 4)
//void SLInit(SL*ps1,int n = 4)
//{ }
//
//void Swap(int** pp1, int** pp2)
//{
// int* tmp = *pp1;
// *pp1 = *pp2;
// *pp2 = tmp;
//}
//
//void Swap(int*& rp1, int*& rp2)
//{
// int* tmp = rp1;
// rp1 = rp2;
// rp2 = tmp;
//}
//
//typedef struct SListNode
//{
// struct SListNode* next;
// int val;
//}SLTNode,*PSLTNode;
//typedef struct SListNode SLTNode;
//typedef struct SListNode* PSLTNode;
//void SLTPushBack(SLTNode** pphead, int x)
//{
// SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
//
// if (*pphead == NULL)
// {
// *pphead = newnode;
// }
// else
// {
// //找到尾节点,newnode链接到尾节点
// }
//}
////void SLTPushBack(SLTNode*& phead,int x)
//void SLTPushBack(PSLTNode& phead, int x)
//{
// SLTNode* newnode = NULL;// = malloc
//
// if (phead == NULL)
// {
// phead = newnode;
// }
// else
// {
// //找到尾节点,newnode链接到尾节点
// }
//}
//
//int main()
//{
// int x = 0, y = 1;
// cout << x << "" << y << endl;
//
// //Swap(&x, &y);
// cout << x << "" << y << endl;
//
// Swap(x, y);
// cout << x << "" << y << endl;
//
// SL s;
// SLInit(s);
//
// int* p1 = &x, * p2 = &y;
// Swap(&p1, &p2);
// Swap(p1, p2);
//
// //SLTNode* plist = NULL;
// //SLTPushBack(&plist, 1);
// //SLTPushBack(&plist, 2);
// //SLTPushBack(&plist, 3);
// //SLTPushBack(&plist, 4);
//
// //SLTNode* plist = NULL;
// PSLTNode plist = NULL;
// SLTPushBack(plist, 1);
// SLTPushBack(plist, 2);
// SLTPushBack(plist, 3);
// SLTPushBack(plist, 4);
//
// return 0;
//}
////传引用返回
//int func()
//{
// int ret = 0;
// //...
// return ret;
//}
//
//int main()
//{
///* int x = func();
// func() += 1;*///临时变量不能去修改
//
// return 0;
//}
////传引用返回
//int& func()
//{
// int ret = 0;
// //...
// return ret;
//}
//
//int main()
//{
// //int x = func();
// //cout << x << endl;
//
// //int a[10];
// ////越界抽查
// //a[10] = 1;
// //a[11] = 1;
// //a[15] = 1;
//
// return 0;
//}
//int& func1()
//{
// //static int ret = 0;
// int ret = 0;
// //...
// return ret;
//}
//
//int& func2()
//{
// int y = 456;
// //...
// return y;
//}
//
//int main()
//{
// int& x = func1();
// cout << x << endl;
// func2();
// cout << x << endl;
//
// return 0;
//}
#include"SeqList.h"
//int main()
//{
// SL s;
// SLInit(&s, 10);
// for (size_t i = 0; i < 10; i++)
// {
// SLPushBack(&s, i);
// }
//
// for (size_t i = 0; i < 10; i++)
// {
// cout << SLat(&s, i) << "";
// }
// cout << endl;
//
// //修改顺序表第i个位置的值
// int i = 0, x = 0;
// cin >> i;
// cin >> x;
// //SLModify(&s, i, x);
// SLat(&s, i) = x;
//
// for (size_t i = 0; i < 10; i++)
// {
// cout << SLat(&s, i) << "";
// }
// cout << endl;
//
// return 0;
//}
int main()
{
int i = 0;
//语法引用不开空间,指针要开空间
int& r1 = i;
int* p = &i;
r1++;
(*p)++;
return 0;
}本文介绍的也是C++的入门基础内容,大家学习不能马虎,要为接下来的【类和对象】打好基础。
往期回顾:
【C/C++】初始C++(一):C++历史的简单回顾+命名空间、流插入、命名空间的指定访问、展开问题等概念整理
结语:本文内容到这里就全部结束了, 本文我们在上一篇文章的基础上,继续学习了缺省参数(默认参数)、函数重载、引用等概念,从现在一直到学习到模版初阶学完之后,都是些晦涩的概念,还用不起来,到后面我们就能像之前那样,结合起来介绍。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-08-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号