《Linux系统编程之进程基础》【进程切换 + 进程调度】

《Linux系统编程之进程基础》【进程切换 + 进程调度】

序属秋秋秋
发布于 2025-12-18 14:46:49
发布于 2025-12-18 14:46:49
往期《Linux系统编程》回顾:/------------ 入门基础 ------------/ 【Linux的前世今生】 【Linux的环境搭建】 【Linux基础 理论+命令】(上) 【Linux基础 理论+命令】(下) 【权限管理】 /------------ 开发工具 ------------/ 【软件包管理器 + 代码编辑器】 【编译器 + 自动化构建器】 【版本控制器 + 调试器】 【实战:倒计时 + 进度条】 /------------ 系统导论 ------------/ 【冯诺依曼体系结构 + 操作系统基本概述】 /------------ 进程基础 ------------/ 【进程入门】 【进程状态】 【进程优先级】
前言:
hi ~,小伙伴们大家好啊!(✪ω✪) 今天我们终于迎来了关于进程基础内容的最后一节了,啊对没错咱们花了 4 节课铺垫的这些内容,其实都还只是进程的 “入门基础知识”∑(O_O;),关于进程的深度学习还远没结束哦~ 但不管怎样,先让我们把基础篇的最后一节稳稳拿下!💪🎯
----- 2025 年 11 月 24 日(十月初五)周一,小雪后的第二天 |
|---|
正式开讲前,鼠鼠先揭晓今天的核心知识点:【进程切换 + 进程调度】🚀! 这俩内容可是理解操作系统 “高效干活” 的关键,咱们用通俗的方式剧透核心: ฅ^ •ﻌ• ^ฅ
进程切换:本质是 CPU 从一个进程的执行,切换到另一个进程执行的过程,使用有趣的小故事通俗易懂的讲进程切换 ( = ̄ω ̄= 猫)进程调度:就是操作系统决定 “该让哪个进程先上 CPU” 的 “裁判逻辑”,看Linux内核🐧是怎么设计进程调度的 ٩(◕︿◕。)۶`
搞懂这两个知识点,就能彻底打通进程基础的 “任督二脉”,为后续进程通信、线程学习埋下关键伏笔~ 咱们赶紧进入正题,搞定这最后一节基础内容吧! (´• ω •)ノ(ᗒᗨᗕ)`
---------------进程切换---------------
1. 什么是进程的切换?
进程切换:(也称“进程上下文切换”)是指 CPU 从当前正在执行的进程,切换到另一个需要执行的进程的过程。
- 它是操作系统实现
“多任务并发”的核心机制 —— 即便在单核 CPU 上,通过频繁的进程切换,也能让多个进程 “看似同时运行”
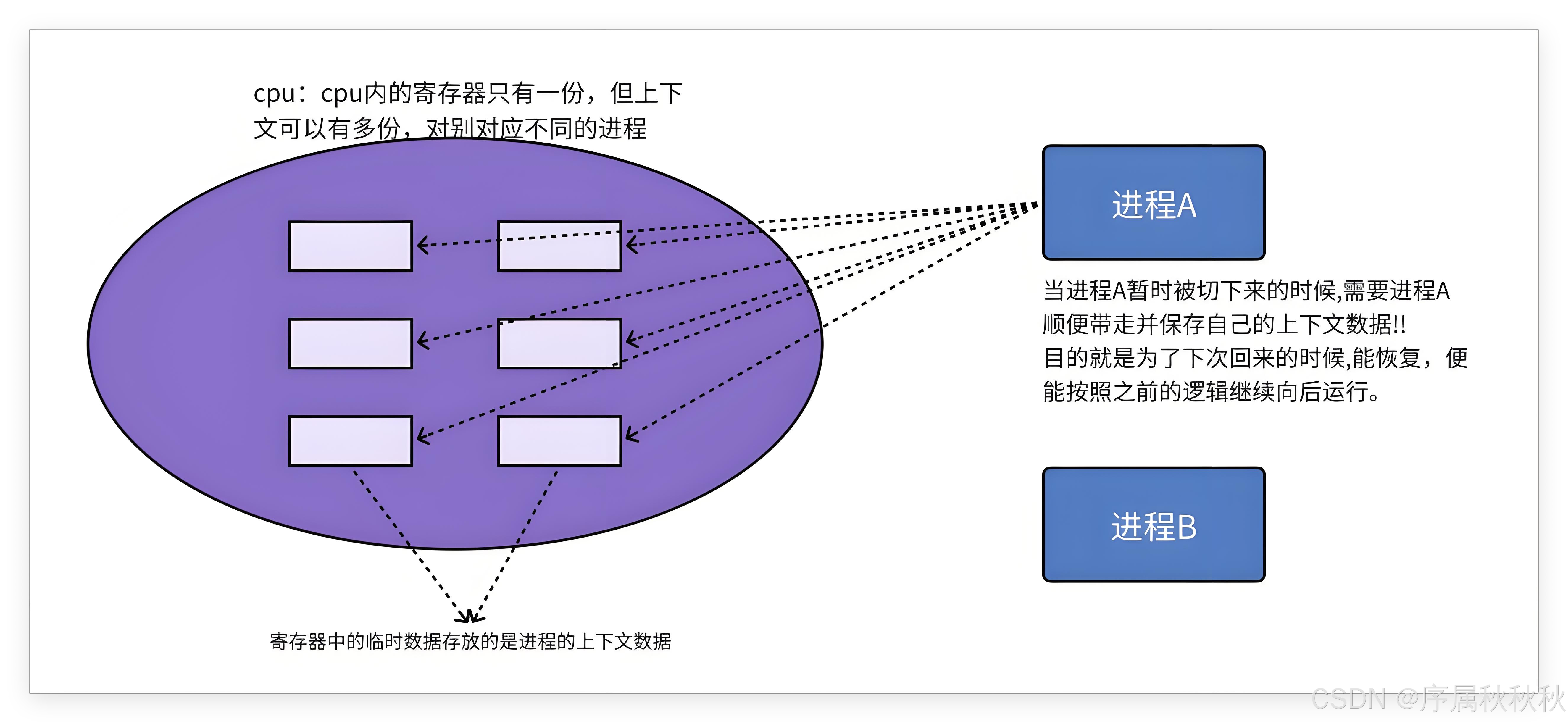
要理解进程切换,首先需要明确一个关键概念:进程上下文
“进程上下文” 是进程运行所需的全部信息集合,包括两类核心内容:
- 硬件上下文:CPU 寄存器中存储的临时数据。
- 程序计数器 PC—— 记录下一条要执行的指令地址
- 通用寄存器 —— 存储进程运行中的临时变量
- 程序状态字 PSW—— 记录 CPU 状态如中断屏蔽位
- 软件上下文:
- 进程的地址空间(代码、数据、堆、栈)
- 进程控制块 PCB(记录进程 ID、优先级、状态等核心属性)
- 打开的文件描述符
2. 死循环进程会卡死系统吗?
平时我们在集成开发环境(IDE)里写过死循环代码,当这个死循环运行起来时,系统确实会变得卡顿一些,但绝对不会完全卡死。
要理解为什么是这样的,需先明白这个问题:一个进程获得 CPU 使用权后,会一直把自己的代码执行完毕吗? 答案是否定的,除非代码非常简短,能在操作系统分配的一个 “时间片” 内执行完。 操作系统会为每个进程分配时间片,时间片就是 CPU 给进程的一段有限执行时长。
- 比如,一个进程要在 CPU 上运行,操作系统会告知它:“只能运行 1 毫秒哦,1 毫秒内跑完了就结束,要是没跑完,我就会把你从 CPU 上‘请’下来,你得回到运行队列里重新排队,等下次调度时再执行。” 这里单次分配给进程的执行时间,就被称为时间片
- 所以,进程并不是永久性地占用 CPU 资源,而是临时拥有,运行一段指定时间后,就会被从 CPU 上剥离
正因为每个进程都基于时间片来运行,所以不会出现一个进程长期独占 CPU 的情况。
有些小伙伴可能会疑惑:要是在单核机器上运行死循环,会不会卡死?
但事实上,系统确实会变卡,却不会彻底卡死。
不然我们怎么能用Ctrl + C这样的快捷键去结束掉死循环进程呢?这就说明,其实死循环进程并没有一直在独占 CPU资源。
3. CPU中的寄存器是什么?
寄存器:是CPU内部极小、极快的内存单元,用于临时存放当前正在执行的指令、数据以及指令的地址
- 它们是CPU直接工作和计算的
“临时工作台” - 当 CPU 执行当前进程时,进程的 PCB(进程控制块)的作用就相对弱化了,此时 CPU 的主要关注点是进程的
代码和数据 - CPU 访问进程的代码和数据时,并非一次性将所有内容都加载进来,而是按照指令顺序逐条处理,为此,CPU 内部设计了多种寄存器来配合工作
这些寄存器各有其特定功能比如我们常见的:
- PC(程序计数器,也称 EIP):用来记录
下一条要执行的指令地址,确保 CPU 能按顺序执行代码 - ebp/esp(栈基址寄存器和栈指针寄存器):用于管理
进程的栈空间 - eax/ebx/ecx/edx(通用寄存器):用于临时存储
运算数据或地址 - cs/ds/es/fs/gs(段寄存器):用于指定
代码段、数据段等内存区域 - eflags(状态寄存器):用于记录
CPU的运行状态,比如:运算是否溢出、是否产生进位、中断是否允许等 - cr0~cr4(控制寄存器):用于控制
CPU的工作模式和系统功能,比如:内存分页管理、保护模式切换等
当一个进程运行时,CPU 的这些寄存器会被填充上与该进程相关的临时数据:
- 有的寄存器(如:eflags)用于标记数据运算是否出现溢出、浮点数计算是否有误
- 有的(如:PC)指明代码的执行起点
- 还有的可能指向 PCB 或其他关键数据结构,协助 CPU 与操作系统配合完成进程管理
这些寄存器就像 CPU 的 “临时工作台”,实时保存着进程运行中的关键信息,确保指令能连续、正确地执行。
小故事:厨师做饭
想象一个顶尖
厨师(CPU)在厨房(计算机)里做一道菜(执行一个程序)
- 菜谱:放在书架上的
一本烹饪书(内存),里面记录了做菜的所有步骤和原料清单(程序指令和数据) - 工作台:厨师面前的
一张很小的操作台(寄存器) - 冰箱/仓库:厨房里的
大型储物区(硬盘),存放着所有食材
4. 进程如何进行切换?
4.1:小故事:学生当兵
你是一名大学生,某天偶然看到学校附近在招募大学生士兵,政策是服役一年后可以返校继续完成学业。你平时身材高高壮壮,外形也还算周正,抱着试试看的心态报了名,没想到顺利通过了选拔。 这时候你要是头脑一热,直接一脚踹开宿舍门对舍友喊:“兄弟们拜拜了,我现在就去当兵,明年见!”,就这么不管不顾地走了, 那可就麻烦了。 等一年后退伍返校,大概率会收到学校的退学通知 —— 毕竟服役的这一年里,上课点名每次都没到,也没参加期末考试,一学年下来挂科累积了二十多门,学校按规定只能作退学处理。 所以,你正确的做法是:通过选拔后,第一时间找到辅导员申请 “保留学籍”,这一步才是重中之重。辅导员核实情况后,第二天会给你一个厚实的牛皮档案袋,里面装着你的成绩单、课程进度表、学籍信息表等所有和学习相关的材料,并且他会特意叮嘱你:“这个档案你自己收好,退伍回来时再交给我,我帮你恢复学籍。” 做好这些准备,你才能安心去服役。 一年后服役期满返校,你还不能直接走进教室坐下来听课,而是要先拿着档案袋找到辅导员办理学籍恢复手续。因为你入伍前读的是大二上学期,辅导员核对完材料后,会把你安排到该年级的某一个班级里,你要跟着他们继续完成大二后续的课程。
这个生活案例,其实和操作系统里的 “进程切换” 逻辑高度相似,我们可以一一对应来看:
- 学校 → CPU:是 “执行任务” 的核心载体(学校承载学习任务,CPU 承载进程执行)
- 辅导员 → 进程调度器:负责 “
资源协调与状态管理”(辅导员管理学籍,调度器管理进程) - 你(学生) → 进程:是 “被调度的任务主体”(学生完成学习任务,进程完成计算任务)
- 学籍档案袋 → 进程上下文:包含任务执行的全部关键信息(档案袋装学习记录,上下文装寄存器数据、PCB 信息等)
- 申请保留学籍 → 保存进程上下文:任务暂停前,先将关键状态信息(学习档案/寄存器数据)保存起来
- 去服兵役 → 进程被剥离 CPU:任务(学习/进程执行)暂时停止,让出核心载体(学校/CPU)
- 返校恢复学籍、续读课程 → 恢复进程上下文:重新加载保存的状态信息(档案袋/上下文),让任务从暂停点继续执行
通过这个类比就能清晰理解:
进程切换不是 “直接停、直接启”,而是先 “保存状态”,再 “让出资源”,最后 “恢复状态续跑”—— 就像学生入伍前要先保留学籍,回来后才能无缝衔接学业一样。
4.2:真实具体的切换流程
在这里插入图片描述
比如说现在进程 A 正在 CPU 上执行,已经运行到代码的第 100 行,它基于原始数据 4 和 6,计算得出了结果 10 此时,CPU 的各个寄存器里都保存着与进程 A 相关的各类数据:
- 程序计数器记录着下一条要执行的指令地址
- 通用寄存器存储着临时运算值
- ……
这些 CPU 寄存器内的全部数据,我们称之为当前进程的硬件上下文数据
当进程 A 的时间片耗尽时,不能直接就让它退出 CPU。
- 操作系统会先把 CPU 寄存器中进程 A 的硬件上下文数据,完整地保存到进程 A 的 PCB(进程控制块) 里
- 保存好后,再把进程 A 重新放入就绪队列的末尾,让它等待下一次被调度执行的机会
接着操作系统会选择进程 B,把它调度到 CPU 上运行。
- 此时进程 B 会用自身的硬件上下文数据,覆盖 CPU 寄存器中原有的进程 A 的数据,然后开始执行自己的代码
- 运行一段时间后,进程 B 的时间片也用完了,同样要进行上下文保存操作 —— 将 CPU 寄存器里进程 B 的硬件上下文数据保存到它的 PCB 中,之后进程 B 也被放回就绪队列
如果之后需要再次调度进程 A 执行,也不能直接把它放到 CPU 上。
- 而是要先从进程 A 的 PCB 中,把之前保存的硬件上下文数据,重新恢复到 CPU 的寄存器里
- 这样一来,进程 A 就能从之前被暂停的位置(代码第 100 行执行完、计算结果为 10 的状态),继续往后运行了
由此可见:进程切换最核心的操作,就是对当前进程硬件上下文数据(即 CPU 内寄存器的内容)的保存与恢复
4.3:进程的硬件上下文存放在……

在这里插入图片描述
在早期的操作系统设计中,任务状态段(TSS,Task State Segment) 承担的核心角色,其实就是存储进程的硬件上下文 —— 也就是说,进程运行时 CPU 寄存器里的所有临时数据(如:程序计数器、通用寄存器、状态寄存器等),都会被保存到对应的 TSS 对象中。
- 如果将所有硬件上下文数据都塞进进程控制块(
task_struct)里,会导致task_struct的体积变得异常庞大 task_struct作为描述进程的核心数据结构,每次创建新进程时都需要被分配和初始化,过大的体积会直接增加内存开销,同时拖慢进程创建的速度
因此:为了优化性能、让进程创建更高效,设计就
- 将 “硬件上下文” 这部分数据从task_struct中剥离出来
- 用 TSS 或其他专门的结构来单独存储
这样既精简了task_struct的结构,又能让硬件上下文的管理更聚焦、更高效。
---------------进程调度---------------
1. 什么是进程的调度?
进程调度:操作系统通过特定策略,决定 “哪个进程能获得 CPU”、“能占用 CPU 多久”、“什么时候把 CPU 让给其他进程” 的管理过程。
- 首先需要回到操作系统的核心矛盾:CPU 是计算机中最核心的硬件资源,但同一时间只能 “专注” 执行一个进程的指令
- 而系统中通常同时存在成百上千个进程(比如:你正在用的浏览器、音乐软件、后台的聊天工具等)
为了让这些进程 “看起来同时运行”、避免 CPU 资源浪费,并且保证系统响应及时,操作系统就需要一套“合理分配CPU使用权”的机制 —— 这就是进程调度
它是操作系统实现 “多任务并发” 的关键,也是连接 “进程管理” 与 “CPU 硬件” 的核心桥梁。
2. Linux中真实进程的调度是什么样的?
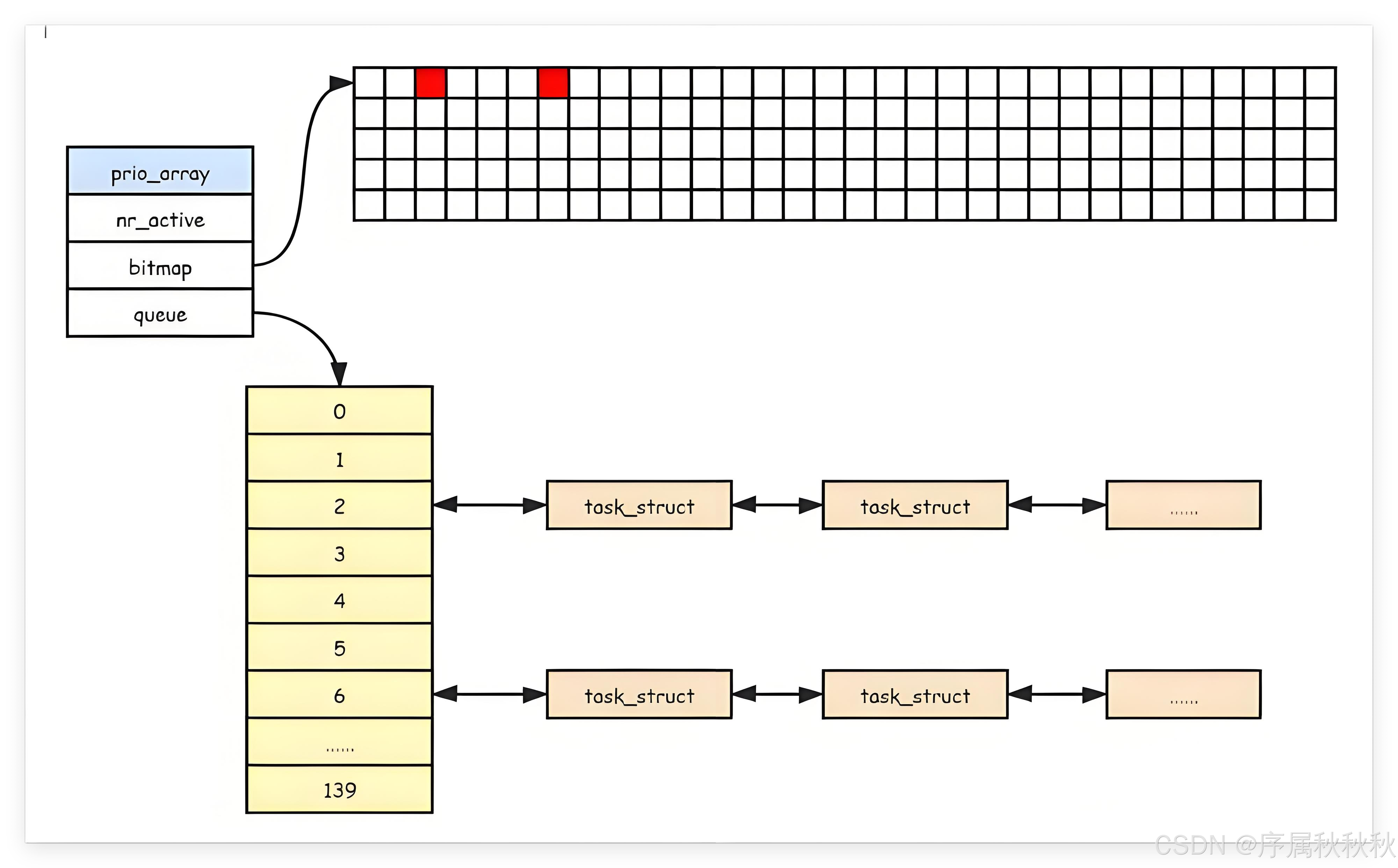
一、queue[140](优先级链表数组)

在这里插入图片描述
在 Linux 系统的进程调度设计中,通常一个 CPU 核心对应一个独立的 “运行队列”(Runqueue),用于管理该核心上等待调度的进程。 而运行队列中会包含一个关键的数据结构 ——
queue[140],它是理解 Linux 优先级调度的核心。
一、queue[140] 是什么?
queue[140]的完整定义是 struct task_struct *queue[140],本质是一个 “结构体指针数组”:
- 数组的每一个元素(
queue[i])都是一个指针,指向一个struct task_struct(即进程控制块 PCB,描述进程的核心数据,如:PID、状态、优先级等) - 更准确地说,
queue[140]中的每一项对应一个“优先级链表头”—— 相同优先级的进程会被串联成一个链表,而queue[i]就指向该优先级链表的第一个进程
queue(即queue[140])的本质:是 Linux 运行队列(runqueue)中 按 “进程优先级” 分类的 “链表头数组”
它的核心作用是 “归类收纳”—— 把相同优先级的进程,串联成一个双向链表,而queue[i]就指向 “优先级为i的进程链表” 的表头。
二、为什么是 140 项?
queue[140]的长度之所以是 140,核心原因是 Linux 系统将进程优先级划分为 140 个等级(优先级数值越小,优先级越高)
这 140 个优先级又进一步分为两大类,对应不同的调度场景:
1. 实时优先级(0~99 级,共 100 个)
- 适用场景:实时进程(工业设备控制、自动驾驶的传感器数据处理、音频视频的实时编码等),这类进程 需要在严格时间内完成的任务
- 核心特点:优先级极高(0 级最高,99 级最低),调度器会优先满足实时进程的 CPU 需求 —— 只要有实时进程处于就绪态,非实时进程就无法获得 CPU,以此保证 “实时性”
- 对应队列:
queue[0]~queue[99],分别对应 0~99 级实时优先级的进程链表
2. 分时优先级(100~139 级,共 40 个)
- 适用场景:用户进程(我们日常使用的浏览器、微信、文档编辑器等),这类进程不需要 “严格实时”,但 需要公平分配 CPU 资源
- 核心特点:优先级相对较低(100 级高于 139 级),调度器通过 “时间片轮转” 等策略,让不同分时进程公平分享 CPU,避免某一进程长期独占资源
- 对应队列:
queue[100]~queue[139],分别对应 100~139 级分时优先级的进程链表
简单说:queue[140]就是 Linux 运行队列中 “按优先级分类的进程收纳架”:
- 140 个 “格子”(数组项)对应 140 个优先级
- 每个 “格子” 里挂着同优先级的进程链表
调度器调度时,会从优先级最高的非空队列开始,依次选取进程分配 CPU—— 这样既保证了实时进程的时效性,又兼顾了普通进程的公平性。
实时操作系统与分时操作系统的核心区别: 上面提到的“实时优先级”和“分时优先级”,本质对应了两种不同的操作系统设计理念 这里简单补充两者的核心差异,帮助理解优先级划分的逻辑:
维度 | 实时操作系统(RTOS) | 分时操作系统(Time-Sharing OS) |
|---|---|---|
核心目标 | 保证关键任务在规定时间内必须完成(时效性) | 让多个用户/进程公平共享 CPU 资源(公平性) |
调度特点 | 优先调度实时进程,可抢占非实时进程 | 按时间片轮转或优先级调度,兼顾公平与响应性 |
适用场景 | 工业控制、医疗设备、自动驾驶、航空航天 | 个人电脑(Windows/macOS)、服务器(Linux) |
失败后果 | 错过时间可能导致严重事故(如:设备失控) | 卡顿或延迟,但不会造成安全问题 |
Linux 系统是 “通用操作系统”,同时支持实时进程和普通分时进程 —— 通过
queue[140]的优先级划分,既能满足少量实时任务的需求,又能保证普通用户进程的公平与流畅,实现 “一机多用” 的灵活性。
二、bitmap[5](优先级位图)
一、遍历queue[140]找进程,时间复杂度太高? 如果只靠
queue[140],调度器每次选进程时,都要从最高优先级(0 级)开始,逐个检查queue[0]、queue[1]…… 直到找到第一个 “非空的链表”—— 这个过程本质是 “遍历数组”,最坏情况下要检查 140 次(比如:所有高优先级队列都空,只有queue[139]有进程),时间复杂度是
对于需要快速响应的调度器来说,
的效率虽然不算差,但仍有优化空间
疑问:能不能不用遍历,直接 “一眼找到” 有进程的最高优先级队列?
这就需要runqueue中的另一个关键成员:bitmap[5](优先级位图)
二、bitmap[5]如何让查找效率降到 O (1)?
bitmap[5]是专门为“快速定位非空队列”设计的“状态标记工具”1. bitmap[5]的基础属性:为什么是 5 个无符号整型?
- 类型大小:
bitmap是unsigned int(无符号整型)数组,每个unsigned int占 4 字节(32 个比特位) - 总比特位:5 个
unsigned int共占5 × 32 = 160个比特位 - 设计逻辑:我们需要标记
queue[140](140 个优先级队列)的 “空/非空” 状态 ——140 个状态需要 140 个比特位,而 160 个比特位刚好能覆盖(多余的 20 个比特位闲置不用,不影响功能)- 若用 4 个
unsigned int(仅 128 个比特位),128 <140,无法覆盖所有优先级 - 若用 6 个(192 个比特位),又会浪费过多内存 ——5 个是 “刚好够用且最省内存” 的选择
- 若用 4 个
2. bitmap[5]的核心作用:比特位与queue[140]一一对应
bitmap的每个比特位,都和 queue[140]的下标(即:优先级)一一绑定,比特位的 “0/1” 状态代表对应队列的 “空/非空”:
- 若
queue[i]对应的链表有进程(非空),则bitmap中第i个比特位设为 1 - 若
queue[i]对应的链表无进程(空),则bitmap中第i个比特位设为 0
比如:
queue[62]有进程 →bitmap的第 62 个比特位是 1queue[100]没进程 →bitmap的第 100 个比特位是 0
3. 调度器如何用bitmap快速找进程?
有了bitmap,调度器找 “最高优先级非空队列” 时,再也不用遍历queue[140],而是通过 “位运算指令” 直接定位第一个为 1 的比特位:
- 操作系统内核会调用专门的位运算接口(比如:x86 架构的
bsf指令,即 “Bit Scan Forward”,从低位到高位扫描第一个为 1 的比特位) - 这个指令能在 “一个 CPU 周期” 内找到目标比特位,进而确定对应的优先级
i,再直接通过queue[i]拿到该优先级的进程链表 - 整个查找过程的时间复杂度,从原来的 O (140)(遍历数组),降为O(1)(单次位运算)
三、总结:queue与bitmap的配合逻辑
-
queue[140]是 “按优先级分类的收纳架”,负责归类进程 -
bitmap[5]是 “收纳架的状态指示灯”,负责标记哪个收纳架有进程
两者配合,让调度器实现了 “高效归类 + 快速查找”:
- 进程入队:按优先级
i,直接挂到queue[i]的链表,并将bitmap第i位设为 1 - 进程出队(调度):用位运算扫描
bitmap,找到第一个为 1 的比特位,直接定位到最高优先级的queue[i],取链表头的进程执行
通过bitmap,将查找最高优先级队列的时间复杂度从
降为
,保证调度器的快速响应。
在这里插入图片描述
三、nr_active(就绪进程计数)
在 Linux 运行队列(runqueue)的设计中:
- 除了
queue[140](优先级链表数组)和bitmap[5](优先级位图) - 还有一个关键的计数变量 ——
nr_active
它的核心作用是 统计当前运行队列中处于 “就绪态” 的进程总数(即:所有queue[i]链表中,可被调度执行的进程总和)
这个变量看似简单,却能在调度器工作的第一步起到 “快速预检” 的作用,大幅减少不必要的操作。
当调度器需要挑选进程分配 CPU 时,并不会直接去扫描bitmap或queue数组,而是先检查nr_active的值:
- 如果nr_active == 0:说明当前运行队列中没有任何就绪态进程,CPU 暂时没有可执行的任务(此时调度器可能会让 CPU 进入空闲状态,或调度内核的空闲进程
idle) - 如果nr_active > 0:才证明有进程在等待 CPU,此时调度器再通过
bitmap查找 “最高优先级的非空队列”—— 也就是我们之前说的,用位运算定位bitmap中第一个为 1 的比特位,进而找到对应的queue[i]链表,最终从链表中选取进程执行
简单来说:nr_active就像运行队列的 “总开关指示灯”:
- 先看灯亮不亮(
nr_active是否大于 0),亮了再去细找具体的 “待执行进程”(通过bitmap和queue) - 避免了 “队列本为空,却还要扫描位图” 的无效操作,进一步优化了调度器的工作效率
四、*active 和 *expired(调度队列池指针)
这时候可能有小伙伴会产生疑问:
- 如果按照之前的调度逻辑,假设有两个进程,优先级分别是 60(高优先级)和 99(低优先级)
- 其中 60 号进程是一个死循环 —— 当它的时间片耗尽,从 CPU 上剥离后,因为死循环需要持续执行,所以还得重新回到就绪队列等待调度 这时候问题就来了:60 号进程会被放回优先级 60 的链表末尾,而它的优先级又比 99 号高,那 99 号进程岂不是永远抢不到 CPU,一直处于 “饥饿” 状态?
为了解决 “低优先级进程饥饿” 的问题,Linux 的运行队列(runqueue)设计了一个关键优化 ——引入 “双队列机制”
- 在 runqueue 内部,不再是单份的
queue[140],而是有两份完全相同的 “优先级调度单元” - 每个单元都包含
nr_active(就绪进程计数)、bitmap[5](优先级位图)和queue[140](优先级链表数组)这三个核心成员
具体实现上:
- 内核先定义了一个专门的结构体
rqueue_elem(可理解为 “优先级队列单元”),结构体内部就封装了这三个成员 - 接着在 runqueue 里定义一个
rqueue_elem类型的数组prio_array[2]—— 这就相当于创建了两个独立的 “调度队列池”
同时,runqueue 里还会定义两个指针,用来管理这两个队列池:
struct rqueue_elem *active:指向当前 “正在调度的队列池”(简称 active 队列),调度器只会从这个队列池里挑选进程struct rqueue_elem *expired:指向 “已调度过、暂时待激活的队列池”(简称 expired 队列),用来存放 “时间片耗尽后重新入队的进程”
初始状态下:
active = &prio_array[0](active 队列指向第一个队列池,里面存放初始就绪进程)expired = &prio_array[1](expired 队列指向第二个队列池,初始为空)
双队列如何解决 “低优先级进程饥饿”? 回到之前 60 号和 99 号进程的例子,双队列机制会这样工作:
- 初始调度阶段:
- 60 号和 99 号进程都在 active 队列中 —— 因为 60 号优先级更高,调度器会优先调度它
- 当 60 号的时间片耗尽后,不会再放回 active 队列,而是被链入 expired 队列中优先级 60 的链表
- 队列动态变化:
- 之后调度器继续从 active 队列挑选进程(此时 99 号进程还在 active 队列中)
- 当 active 队列中的 99 号进程被调度、时间片耗尽后,同样会被放入 expired 队列
- 避免插队:
- 整个过程中,所有 “时间片耗尽的进程” 都会被转移到 expired 队列,active 队列中的进程只会越来越少,不会有 “高优先级进程重新插队” 的情况
- 这就保证了 active 队列里的低优先级进程(比如:99 号)一定能等到被调度的机会,不会被高优先级进程长期压制
- 队列切换(swap):
- 当 active 队列中的所有进程都被调度过(即
active->nr_active == 0,active 队列空了),调度器会执行一次简单的 “指针交换” - 让
active指向原本的 expired 队列(此时 expired 队列里已经存满了之前转移过来的进程),让expired指向原本空掉的 active 队列
- 当 active 队列中的所有进程都被调度过(即
这样一来:
- 原本的 expired 队列就变成了新的 “活跃调度队列”,调度器继续从新的 active 队列中挑选进程
- 而空掉的队列则作为新的 expired 队列,等待接收后续 “时间片耗尽的进程”
通过这种 “双队列交替激活” 的机制,既能保证高优先级进程的优先执行,又能避免低优先级进程永远得不到调度的 “饥饿问题”,实现了调度的公平性。
-------补充-------
在 Linux 的运行队列(runqueue,常简称为 rq)中:
nr_running、cpu_load、nr_switches是三个核心的状态统计变量,分别用于记录 CPU 调度的关键信息,帮助操作系统感知负载、优化调度策略
(1)nr_runing
nr_running:当前 CPU 的 “就绪进程数”
- 含义:记录当前运行队列中,处于就绪态的进程总数(即:已经准备好、等待 CPU 执行的进程数量,不包含处于阻塞态的进程)
- 作用:是操作系统判断 “CPU 是否繁忙” 的最直接指标
- 若 nr_running = 0:说明当前 CPU 没有待执行的就绪进程,会调度 “空闲进程(idle)”,让 CPU 进入低功耗状态
- 若 nr_running > 1:说明有多个进程在抢 CPU,调度器需要按 优先级/时间片 策略分配资源,避免进程饥饿
- 举例:你同时开着浏览器(1 个进程)、微信(1 个进程)、音乐软件(1 个进程),且三者都处于就绪态,此时该 CPU 的
nr_running就是 3
(2)cpu_load
cpu_load:当前 CPU 的 “负载统计”
- 含义:记录一段时间内(通常是 1 分钟、5 分钟、15 分钟),CPU 上 “处于就绪态或运行态的进程总数的平均值”,反映 CPU 的 “长期繁忙程度”(区别于
nr_running的 “瞬时值”) - 作用:帮助操作系统做 “全局调度决策”
- 若 A CPU 的
cpu_load远高于 B CPU,调度器会把 A CPU 上的部分进程迁移到 B CPU,避免单 CPU 过载 - 对用户而言,通过
top或uptime命令看到的 “CPU 负载值”(如:load average: 1.2, 0.8, 0.6),核心数据就来自cpu_load
- 若 A CPU 的
- 特点:是 “平均值”,能反映 CPU 的负载趋势 —— 比如:1 分钟负载 1.2,说明最近 1 分钟内,CPU 平均有 1.2 个进程在 等待/执行(0.2 是进程等待的累积体现)
(3)nr_swithes
nr_switches:当前 CPU 的 “进程切换次数”
- 含义:记录从 CPU 启动至今(或某个统计周期内),发生 “进程上下文切换” 的总次数(包括 “主动切换” 和 “被动切换”)
- 作用:用于评估 “调度开销” 和 “系统响应性”
- 若
nr_switches过高:说明 CPU 大部分时间在 “保存/恢复 进程上下文”,而非执行进程任务,会导致系统效率下降(常见于进程数量过多的场景) - 若
nr_switches过低:可能说明 CPU 长期被单个进程占用(如:死循环高优先级进程),需检查调度策略是否合理
- 若
- 举例:CPU 先执行进程 A(时间片到后切换)→ 执行进程 B(B 阻塞后切换)→ 再执行进程 A,这一过程会触发 2 次切换,
nr_switches就会 + 2
一句话总结三者关系:
nr_running:看 “当下有多少进程等 CPU”(瞬时)cpu_load:看 “最近 CPU 平均有多忙”(趋势)nr_switches:看 “CPU 在进程间切换了多少次”(开销)
三者共同构成了 CPU 调度的 “状态仪表盘”,帮助操作系统平衡效率与公平性。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-11-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号