3FS为什么没有完全遵守POSIX语义

3FS为什么没有完全遵守POSIX语义

早起的鸟儿有虫吃
发布于 2025-12-24 15:54:57
发布于 2025-12-24 15:54:57
提问:采用FoundationDB后 3FS牺牲了什么
有网友提问
为啥 DeepSeek-3FS元数据无状态,CephFS 的 元数据 要搞得这么复杂
看了你文章:
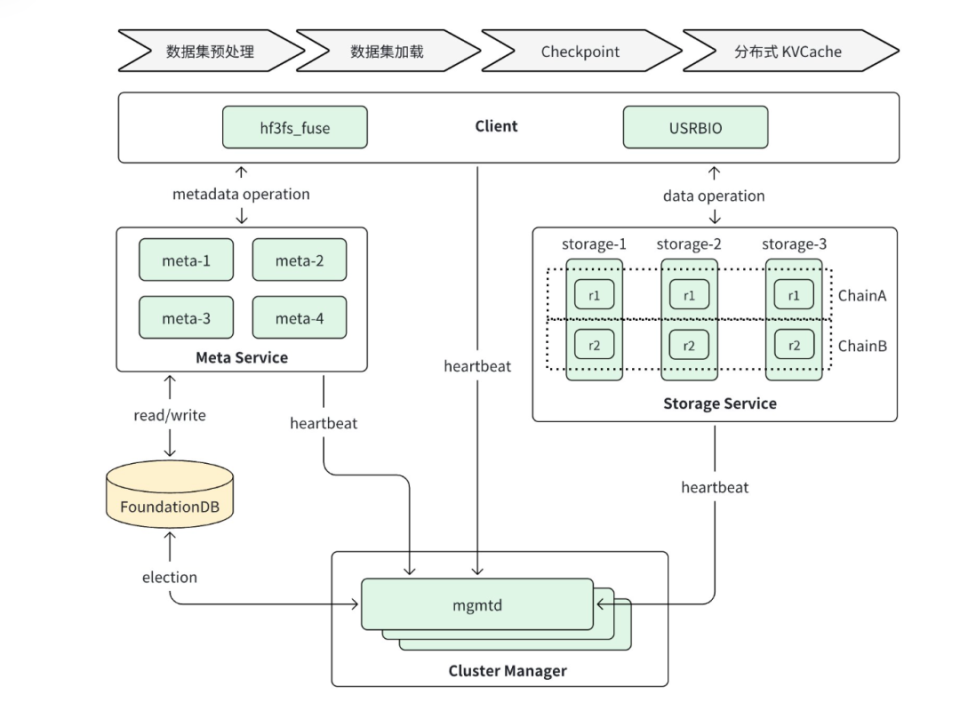
了解到3FS 系统有四个组件:
•
集群管理器
元数据服务:提供元数据服务
•
采用存算分离设计
•
Meta Service 的节点本身是无状态
Storage Service 提供数据存储服务,采用存算一体设计:
•
每个存储节点管理本地 SSD 存储资源,提供读写能力;
•
每份数据 3 副本存储,采用的链式复制协议 CRAQ(Chain Replication with Apportioned Queries)提供 write-all-read-any 语义,对读更友好;
•
系统将数据进行分块,尽可能打散到多个节点的 SSD 上进行数据和负载均摊
客户端。
3FS 提供了两种形态的客户端,
•
FUSE 客户端
•
hf3fs_fuse 和
•
原生客户端 USRBIO:
•
写入成功后,客户端会在本地内存中更新一个关键信息——该文件的“最大写入偏移量。
•
这个操作纯粹在客户端内存中进行,不涉及任何网络通信或事务,因此速度极快。
•
客户端会启动一个后台线程,默认每隔5秒,将本地记录的所有以写入模式打开文件的“最大写入偏移量”汇总,并批量上报给元数据服务(Meta Service)这是实现“异步传播”的核心环节
所有组件都通过 RDMA 网络(InfiniBand 或 RoCE)连接。
针对元数据服务组件 是无状态的设计,采用FoundationDB存储元数据
•
无主从区别,每个服务都对我提供功能
•
更不会缓存大量元数据
采用FoundationDB 有点如下
核心优势 | 对3FS的意义 |
|---|---|
1. 获得强一致性,简化开发 | FoundationDB提供严格可串行化(Serializable)的ACID事务FS借此将复杂的目录树操作(如创建、重命名)直接映射为KV事务,由底层保证原子性和一致性,极大简化了元数据服务的设计 |
2. 实现元数据服务的无状态与线性扩展 | 采用存算分离设计,元数据本身持久化在FoundationDB中,Meta Service节点无状态。这使得元数据服务能力可以随节点增加而线性扩展,避免了传统MDS(元数据服务器)的扩展瓶颈 |
3. 内置高可用与容错能力 | FoundationDB本身具备高可用性,其确定性模拟测试框架能确保系统在各类故障下的稳定性,这使得3FS元数据层可以复用这套成熟可靠的基石,无需重复造轮子 |
4. 架构解耦,专注上层优化 | FoundationDB是专注“数据库下半部分”的事务性KV存储。3FS团队可以专注于在其上构建高效的文件系统语义层(如元数据模型、客户端协议),而无需操心底层分布式存储的复杂问题 |
采用FoundationDB后 3FS存在什么缺点
3FS明确其设计目标是面向AI大文件、高吞吐场景, 而非通用的文件系统 3FS的设计哲学 不做通用的 万能钥匙,而做针对特定场景的高性能利器
在采用FoundationDB的同时,也做出了一些关键妥协。
牺牲部分POSIX语义以换取性能
根据之前的讨论,3FS为了保证性能,不提供完整的POSIX强一致性。
这在采用FoundationDB时体现为: 为了避免其高隔离级别事务(SSI)和**跨分片两阶段提交
场景:有两个进程操作同一个日志文件 train.log。
•
进程A(写入者):持续追加写入日志。
•
进程B(读取者):定期读取文件以监控进度。
•
初始状态:train.log 文件大小为 1000字节。
关键操作序列:
1
在 T1 时刻,进程A成功调用 write(fd, buf, 200),向文件尾部追加200字节新数据。
2
在 T2 时刻(紧接着T1之后),进程B立即调用 stat() 查询文件大小,并尝试读取文件的“最后500字节”。
问题:在 T2 时刻,进程B看到的文件大小是多少?它能读取到进程A在T1时刻写入的那200字节新数据吗?
特性 | CephFS | 3FS | 传统POSIX |
|---|---|---|---|
写入后可见性 | close-to-open | 最终一致 | 立即可见 |
元数据缓存 | 可配置TTL | 异步刷新 | 同步更新 |
性能代价 | 中等(需fsync) | 低(无同步) | 高(全局锁) |
一致性保证 | 会话一致性 | 最终一致性 | 强一致性 |
在不同的文件系统中,进程B在T2时刻(紧接写入后立即查询)会得到完全不同的结果,具体如下: |
1
在POSIX系统(如本地Ext4)中:
•
结果:进程B查询到的文件大小是1200字节,并且读取到的“最后500字节”包含进程A新写入的200字节数据。
•
原因:内核在write()系统调用返回前,已经在内存中同步更新了所有进程共享的文件元数据(包括大小)。因此,进程B能立即看到一致的最新状态。
2
在CephFS中:
•
结果:这完全取决于进程A是否执行了同步操作。
•
如果进程A在写入后没有调用fsync()或关闭文件:进程B查询到的大小很可能是旧的1000字节,因此读取到的“最后500字节”不包含新数据,导致数据丢失。
•
如果进程A在写入后调用了fsync()或关闭了文件:进程B查询到的大小会是1200字节,并能正确读取到包含新数据在内的完整内容。
•
原因:CephFS为平衡性能与一致性,采用“close-to-open”语义。文件打开写入期间,元数据更新可能缓存在客户端;只有在同步或关闭时,才会提交到元数据服务器并使所有客户端可见。
3
在3FS中:
•
结果:无论进程A是否调用fsync(),进程B在T2时刻几乎肯定查询到的是旧的1000字节,因此读取会丢失新写入的200字节数据。
•
原因:3FS为了追求极高的写入吞吐量,采用了最终一致性模型。文件大小的更新由客户端异步、定期上报,因此在写入后极短的时间内,其他客户端无法感知到元数据变化。
•
POSIX:提供 内存级即时强一致,对应用最透明。
•
CephFS:提供 close-to-open会话强一致,需应用在关键点同步。
•
3FS:提供 最终一致,为极致吞吐牺牲一致性时效,应用需自处理完整性。
设计:为什么这样设计
1. 无全局同步锁
3FS放弃了传统文件系统的全局inode锁机制。
在本地Ext4中:
•
内核维护全局的inode锁和缓存一致性
•
write()系统调用在返回前会更新所有共享的元数据
•
这确保了写入的线性一致性
而3FS:
•
每个客户端维护自己的元数据缓存( 客户端写入日志(Client Write Log, CWL))
•
写入只更新本地缓存,异步传播到FoundationDB
•
读取时可能命中陈旧的缓存
一致性级别 | 3FS的选择 | 性能收益 | 一致性代价 |
|---|---|---|---|
线性一致性 | ❌ 放弃 | 无 | 完美POSIX |
顺序一致性 | ⚠️ 部分 | 中等 | 跨进程顺序 |
最终一致性 | ✅ 采用 | 最大 | 临时不一 |
整个异步传播流程可以分解为以下几个关键步骤:
1
写入路径与本地记录
•
当客户端执行写入操作时,数据会通过高性能的USRBIO接口直接写入存储服务写入成功后,
•
客户端会在本地内存中更新一个关键信息——该文件的 “最大写入偏移量”。
•
这个操作纯粹在客户端内存中进行,不涉及任何网络通信或事务,因此速度极快。
2
定期报告
•
客户端会启动一个后台线程,默认每隔5秒,将本地记录的所有以写入模式打开文件的“最大写入偏移量”汇总,并批量上报给元数据服务(Meta Service)。
•
这是实现“异步传播”的核心环节。
3
最终提交
•
元数据服务收到客户端的报告后,并不一定立即更新FoundationDB。 为了合并可能的多次更新并减少事务冲突,更新任务可能会被分发和排队
•
在文件关闭(close)或同步(fsync)时,会触发一个强制性的元数据提交流程:
https://deepwiki.com/deepseek-ai/3FS
fuse IO 过程
FUSE客户端写文件时,文件大小这个元数据不是实时更新到存储的,而是采用异步传播机制 参考:https://github.com/deepseek-ai/3FS/blob/main/docs/design_notes.md
The file length is stored in the inode.
For files being actively updated, the length stored in inode may diverge from the actual length.
Clients periodically (5 seconds by default) report to meta service maximum write position of each file opened in write mode.
If this position exceeds the length in inode and there is no concurrent truncate operation, this position is adopted as the new file length.
Due to the possibility of concurrent writes from multiple clients, the method described above ensures only eventual consistency for file lengths.
When processing close/fsync operations, the meta service obtains the precise file length by querying the ID and length of the last chunk from the storage service.
Since file data is striped across multiple chains, this operation incurs non-negligible overhead.
Concurrent updates to the same file’s length by multiple meta services may cause transaction conflicts and lead to repeated file length computation.
To mitigate this, meta service distributes file length update tasks across multiple meta services using inode IDs and the rendezvous hash algorithm.
文件长度存储在索引节点(inode)中。
对于正在被活跃更新的文件,索引节点中存储的长度可能与实际长度不一致。
客户端默认以5秒为周期,向元数据服务报告每个以写入模式打开的文件的最大写入位置。如果该位置超过了索引节点中记录的长度,且没有并发的截断操作,则元服务会采纳此位置作为新的文件长度。
由于可能存在多个客户端的并发写入,上述方法只能保证文件长度的最终一致性。
在处理 `close` 或 `fsync` 操作时,元数据服务会通过向存储服务查询最后一个数据块的ID和长度来获取精确的文件长度。由于文件数据被分条存储在多个存储链上,此项操作会产生不可忽略的开销。
由多个元服务并发更新同一文件的长度可能会导致事务冲突,并引发重复的文件长度计算。为了缓解此问题,元服务使用索引节点ID和一致性哈希算法,将文件长度更新任务分布到多个元服务上执行
对于正在被活跃更新的文件,索引节点中存储的长度可能与实际长度不一致。客户端默认以5秒为周期,向元数据服务报告每个以写入模式打开的文件的最大写入位置。如果该位置超过了索引节点中记录的长度,且没有并发的截断操作,则元服务会采纳此位置作为新的文件长度。
由于可能存在多个客户端的并发写入,上述方法只能保证文件长度的最终一致性。在处理 `close` 或 `fsync` 操作时,元数据服务会通过向存储服务查询最后一个数据块的ID和长度来获取精确的文件长度。由于文件数据被分条存储在多个存储链上,此项操作会产生不可忽略的开销。
由多个元服务并发更新同一文件的长度可能会导致事务冲突,并引发重复的文件长度计算。
为了缓解此问题,元服务使用索引节点ID和一致性哈希算法,将文件长度更新任务分布到多个元服务上执行。
1. 写入路径与本地记录
•
写入操作通过USRBIO接口直接写入存储服务
•
客户端在RcInode::DynamicAttr结构中维护本地写入状态
DynamicAttr 结构维护了三个关键版本号来跟踪同步状态:
•
written: 写入版本
•
synced: 定期同步版本
•
fsynced: 强制同步版本(fsync/close触发) FuseClients.h
struct RcInode { struct DynamicAttr { uint64_t written = 0; uint64_t synced = 0; // period sync 定期同步版本 uint64_t fsynced = 0; // fsync, close, truncate, etc... 强制同步版本}•
写入完成后,
客户端调用finishWrite更新本地状态 IoRing.cc:209-220 ,
此操作纯内存操作,无网络通信。
2. 定期报告机制
•
客户端启动后台线程,默认每5秒执行周期性同步
•
检查SyncType::PeriodSync类型
•
刷新写缓冲区
•
调用元数据服务同步接口
3. 最终提交触发
文件关闭或fsync时触发强制同步:
•
close操作通过flushAndSync处理SyncType::Fsync FuseOps.cc:612-613
•
fsync直接调用元数据服务同步接口 MetaClient.cc:933-939
•
同步时更新fsynced字段确保强一致性 FuseClients.h:91-93
元数据服务收到报告后,可能排队更新以减少FoundationDB事务冲突,最终通过sync接口提交到持久化存储
从零开发分布式文件系统(一) :100G读写带宽,百万IO请求文件系统怎么实现的
从零实现分布式文件系统(二) 如何在不升级硬件的前提下,小文件并发读写性能提升十倍
从零开发分布式文件系统(三) :JuiceFS|沧海|3FS 能相互替代吗?百万 OPS如何满足(1)(ceph 默认5 千)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号