【Linux系统编程】Ext2文件系统

【Linux系统编程】Ext2文件系统

用户11719958
发布于 2025-12-30 14:45:57
发布于 2025-12-30 14:45:57
一,理解一切皆文件
首先,在windows中是文件的东西,它们在linux中也是文件;其次一些在windows中不是文件的东西,比如进程、磁盘、显示器、键盘这样硬件设备也被抽象成了文件,你可以使用访问文件的方法访问它们获得信息;甚至管道,也是文件;网络编程中的socket(套接字)这样的东西,使用的接口跟文件接口也是⼀致的。
这样做最明显的好处是,开发者仅需要使用一套 API 和开发⼯具,即可调取 Linux 系统中绝大部分的资源。举个简单的例子,Linux 中几乎所有读(读文件,读系统状态,读PIPE)的操作都可以用read 函数来进行;几乎所有更改(更改文件,更改系统参数,写 PIPE)的操作都可以用write函数来进行。
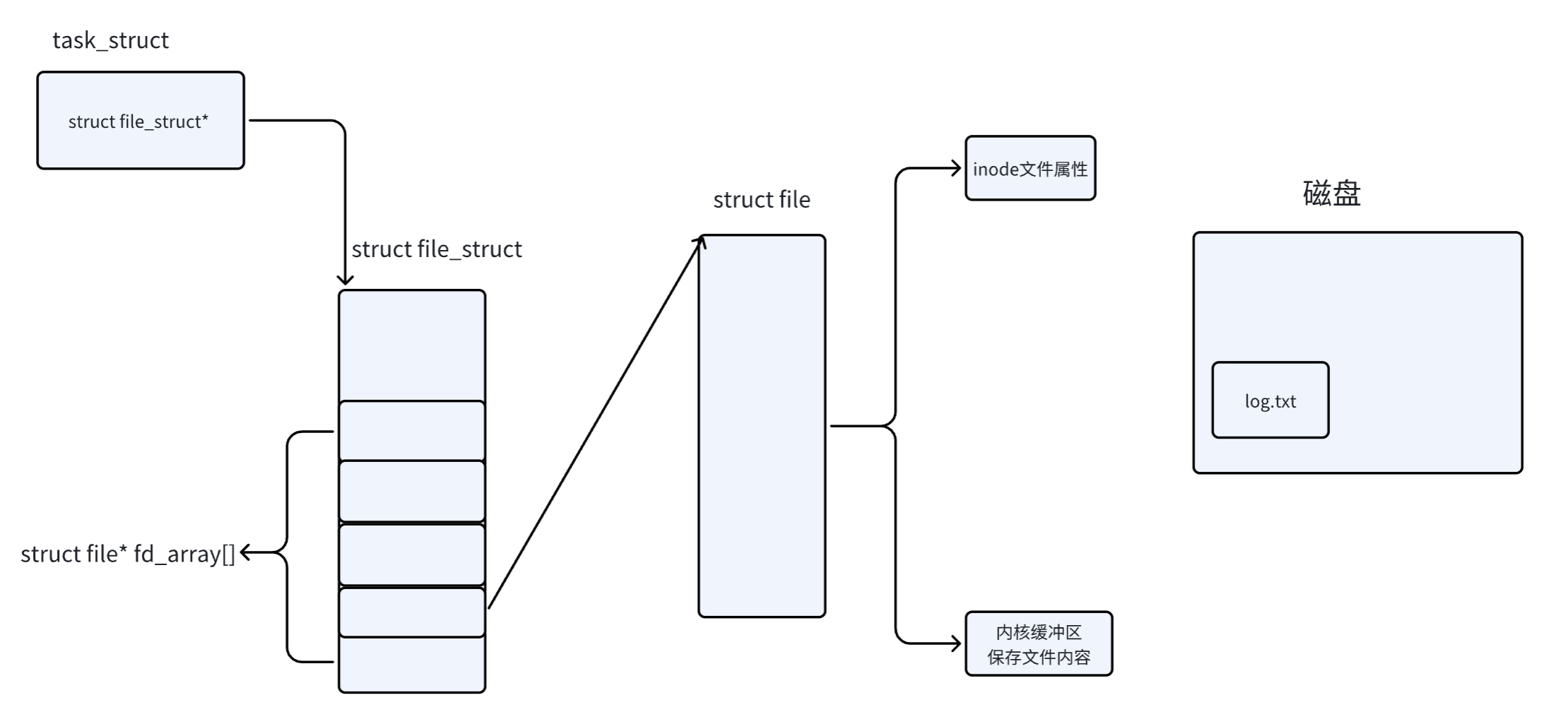
当打开一个文件时,操作系统为了管理所打开的文件,都会为这个文件创建一个file结构体。
struct file 中的 f_op 指针指向了一个 file_operations 结构体,这个结构体中的成员除了struct module* owner 其余都是函数指针。
file_operation 就是把系统调用和驱动程序关联起来的关键数据结构,这个结构的每⼀个成员都对应着⼀个系统调用。读取 file_operation 中相应的函数指针,接着把控制权转交给函数,从而完成了Linux设备驱动程序的工作。
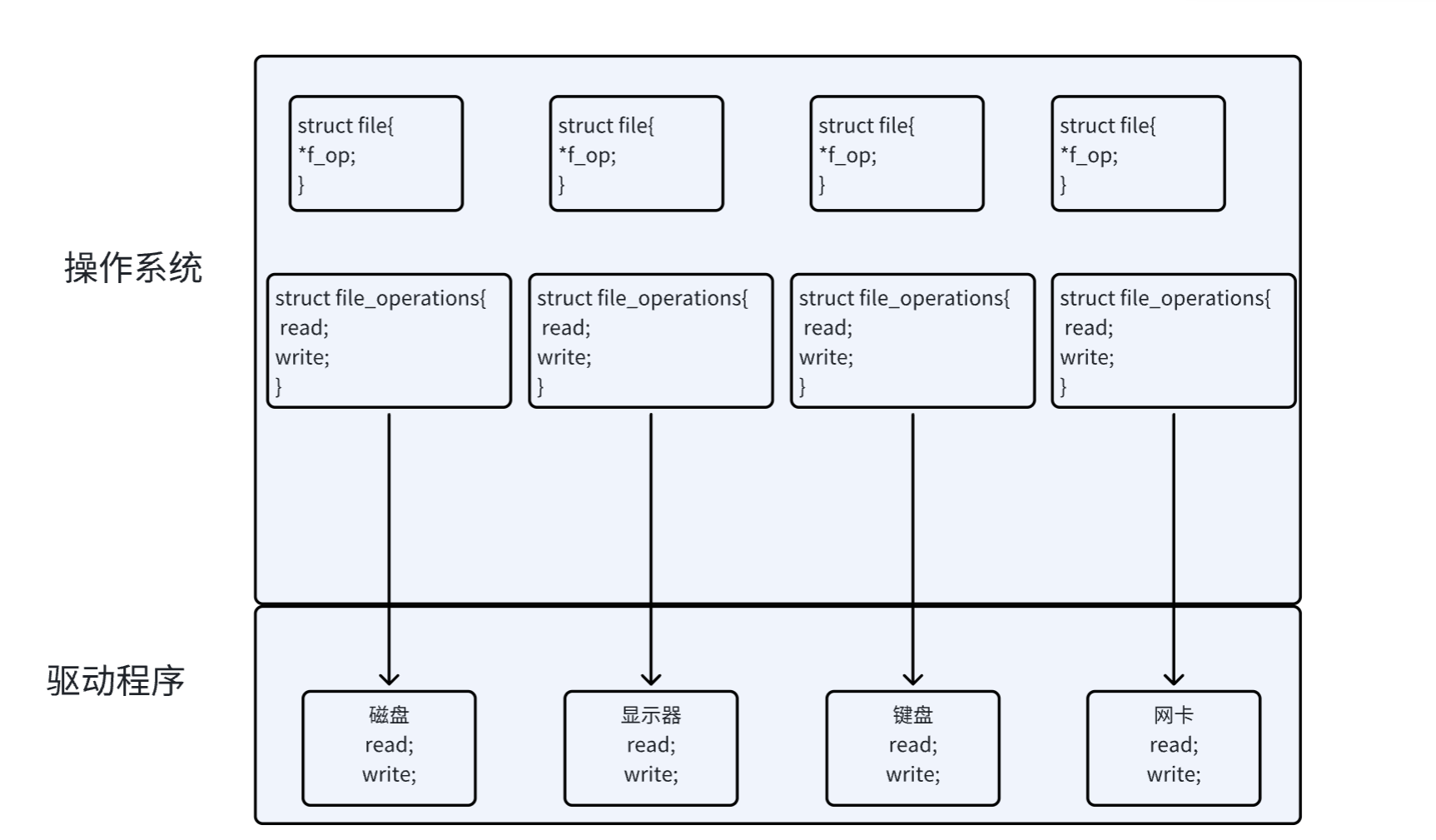
上图中的外设,每个设备都可以有自己的read、write,但一定是对应着不同的操作方法!!但通过struct file 下 file_operation 中的各种函数回调,让我们开发者只用file便可调取 Linux 系统中绝⼤部分的资源!!这便是“linux下一切皆文件”的核心理解。
二,缓冲区
1,什么是缓冲区
缓冲区是内存空间的⼀部分。也就是说,在内存空间中预留了⼀定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
2,为什么要引入缓冲区机制
- 读写文件时,如果不开辟对文件操作的缓冲区,直接通过系统第哦啊用对磁盘进行操作(读、写等),那么每次对文件进行一次读写操作时,都需要使用读写系统调用来处理此操作,即需要执行一次系统调用,执行一次系统调用将涉及到CPU状态的切换,即从用户空间切换到内核空间,实现进程上下文的切换,这将损耗一定的CPU时间,频繁的磁盘访问对程序的执行效率造成很大的影响。
- 为了减少使用系统调用的次数,提高效率,我们就可以采用缓冲机制。比如我们从磁盘里读取信息,可以在磁盘文件进行操作时,可以一次从文件中读出大量的数据到缓冲区中,以后对这部分的访问就不需要再使用系统调用了,等缓冲区的数据读取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作大大快于对磁盘的操作,故应用缓冲区可大大提⾼计算机运行速度。
- 可以看出,缓冲区就是一块内存区,它用在输入输出设备和CPU之间,用来缓存数据。它使得低速的输入输出设备和告诉的CPU能够协调工作,避免低速的输⼊输出设备占用CPU,解放出CPU,使其能够高效率工作。
缓冲类型
标准I/O提供了3种类型的缓冲区。
- 全缓冲区:这种缓冲方式要求填满整个缓冲区后才进行I/O系统调用操作。对于磁盘文件的操作通常使用全缓冲的方式访问。
- 行缓冲区:在行缓冲情况下,当在输入和输出中遇到换行符时,标准I/O库函数将会执行系统调用操作。当所操作的流涉及一个终端时(例如标准输⼊和标准输出),使用行缓冲方式。因为标准I/O库每行的缓冲区长度是固定的,所以只要填满了缓冲区,即使还没有遇到换行符,也会执行I/O系统调用操作,默认行缓冲区的大小为1024。
- 无缓冲区:无缓冲区是指标准I/O库不对字符进行缓存,直接调用系统调用。标准出错流stderr通常是不带缓冲区的,这使得出错信息能够尽快地显示出来。
除了上述列举的默认刷新方式,下列特殊情况也会引发缓冲区的刷新:
- 缓冲区满时;
- 执行flush语句;
- 进程结束;
三,理解磁盘
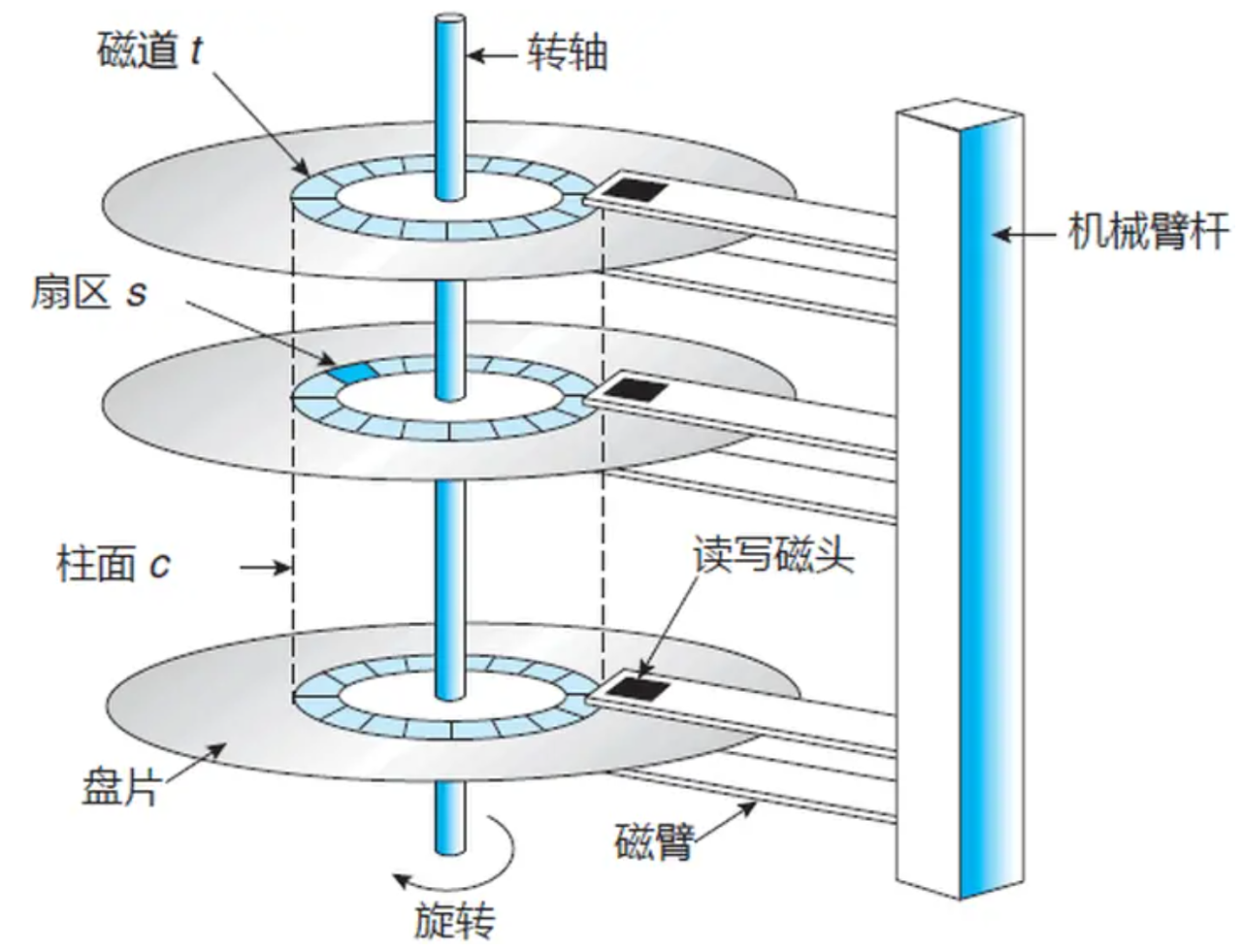
1,磁盘物理结构

核心机械组件 :
- 盘片:用于记录二进制数据。
- 磁头:每个盘片的正反两面各对应一个磁头,磁头通过微型悬臂固定在音圈电机(VCM)驱动的磁头臂上,可沿盘片半径方向精准移动。
数据存储的物理结构:
- 磁道(Track)与扇区(Sector):盘片表面被划分为同心圆磁道,最外圈为 0 磁道。每个磁道进一步分割为扇区,早期为 512 字节,现代采用 4KB 高级格式化(Advanced Format)以提升纠错能力。
- 柱面(Cylinder):所有盘片上同一半径的磁道组成柱面。例如,第 100 号柱面包含所有盘片的第 100 号磁道。磁头切换柱面时需移动整个磁头臂,而切换同柱面内的不同磁道仅需选择对应磁头,因此数据存储时优先集中在同一柱面以减少寻道时间。
2,磁盘的存储结构
如何定位一个扇区:
- 先确定要访问哪一个柱面(cylinder)
- 接着定位磁头(header)
- 最后定位到一个扇区(sector)
- 扇区是从磁盘读出和写入信息的最小单位,通常大小是512字节。
- 磁头(header)数:每个盘片一般有上下两面,分别对应一个磁头,一共有两个磁头。
- 磁道数:磁道是从盘片外圈往内圈编号0磁道,1磁道...,靠近主轴的同心圆用于停靠磁头,不存储数据。
- 柱面(cylinder)数:磁道构成柱面,数量上等同于磁道个数。
- 扇区(sector)数:每个磁道都被切分成很多扇形区域,每道的扇区数量相同。
- 圆盘(platter)数:就是盘片的数量。
- 磁盘容量=磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数。
柱面(cylinder),磁头(head),扇区(sector),显然可以定位数据了,这就是数据定位(寻址)方式之一,CHS寻址方式。
3,磁盘的逻辑结构

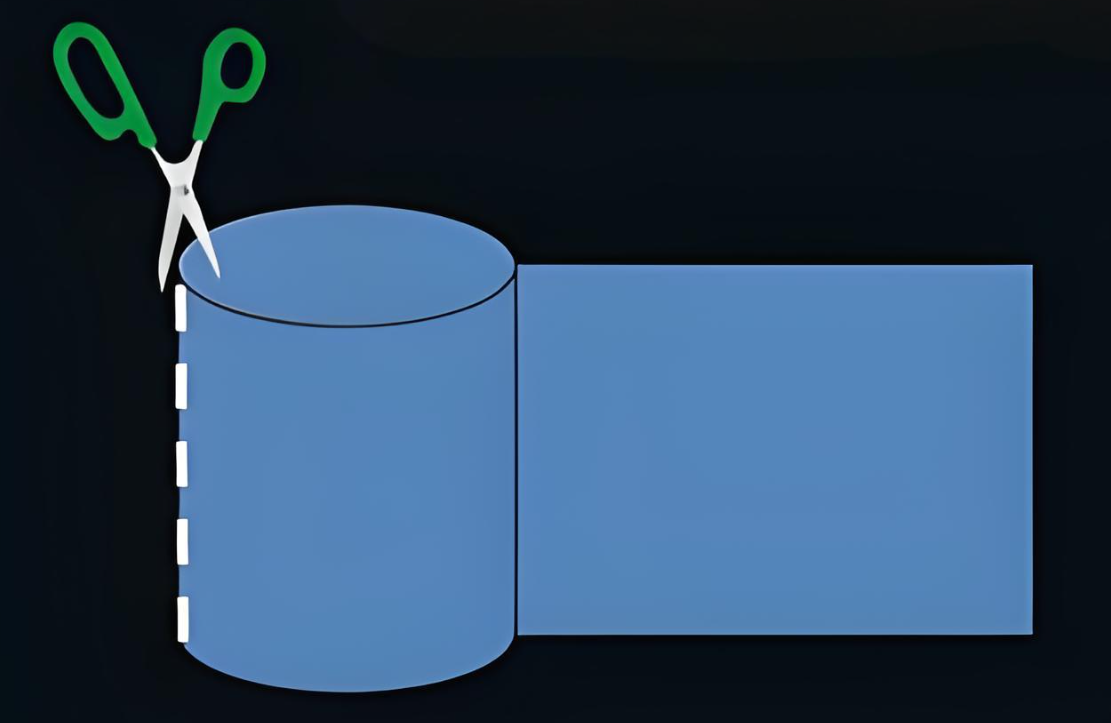
磁带上面可以存储数据,我们可以把磁带“拉直”,形成线性结构。

那么磁盘本质上虽然是硬质的,但是逻辑上我们可以把磁盘想象成为卷在一起的磁带,那么磁盘的逻辑存储结构我们也可以类似于:

这样每一个扇区,就有了一个线性地址(其实就是数组下标),这种地址叫做 LBA。
所以,磁盘的真实情况是:
磁道:
某一盘面的某一个磁道展开,即:一维数组

柱面:
整个磁盘所有盘面的同一个磁道,即柱面展开,一个二维数组。
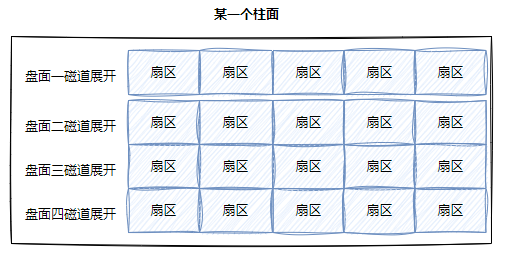
柱面展开类似于下面的过程:
整盘展开:即一个三维数组
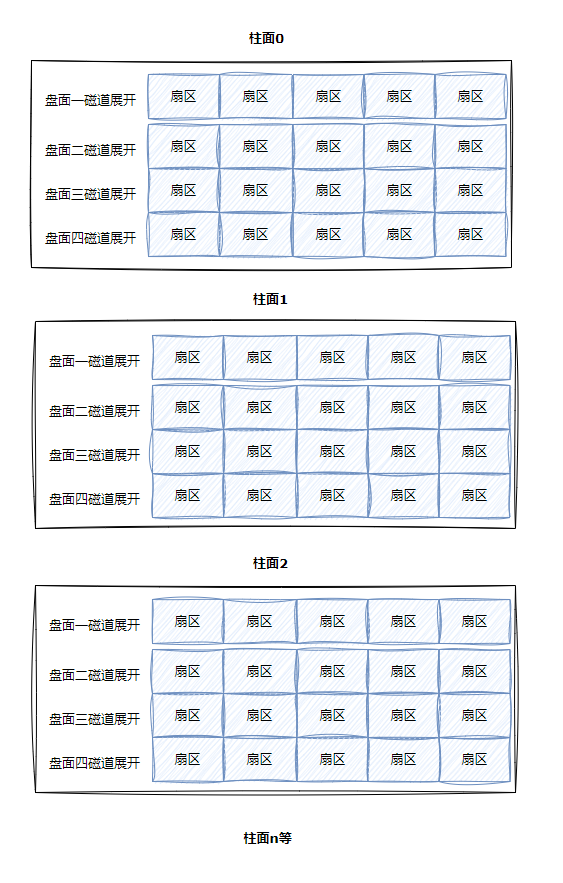
所以,寻址一个扇区:先找到哪⼀个柱面(Cylinder) ,在确定柱⾯内哪一个磁道(其实就是磁头位置,Head),在确定扇区(Sector),所以就有了CHS 。
其实这个三位数组,我们可以看成是一个一维数组。

所以,每一个扇区都有一个下标,我们叫做 LBA(Logical Block Address) 地址,其实就是线性地址。所以怎么计算得到这个LBA地址呢?

OS只需要使用LBA就可以了!!LBA地址转成CHS地址,CHS如何转换成为LBA地址。谁做啊??磁盘自己来做!
4,CHS和LBA
CHS转成LBA:
- 磁头数*每磁道扇区数 = 单个柱面的扇区总数
- LBA = 柱面号C*单个柱面的扇区总数 + 磁头号H*每磁道扇区数 + 扇区号S - 1
- 即:LBA = 柱面号C*(磁头数*每磁道扇区数) + 磁头号H*每磁道扇区数 + 扇区号S - 1
- 扇区号通常是从1开始的,而在LBA中,地址是从0开始的
- 柱面和磁道都是从0开始编号的
- 总柱面,磁道个数,扇区总数等信息,在磁盘内部会自动维护,上层开机的时候,会获取到这些参数。
LBA转成CHS:
- 柱面号C = LBA // (磁头数*每磁道扇区数)【就是单个柱面的扇区总数】
- 磁头号H = (LBA % (磁头数*每磁道扇区数)) // 每磁道扇区数
- 扇区号S = (LBA % 每磁道扇区数) + 1
- "//": 表示除取整
所以:从此往后,在磁盘使用者看来,根本就不关心CHS地址,而是直接使用LBA地址,磁盘内部自己转换。所以:从现在开始,磁盘就是一个元素为扇区 的一维数组,数组的下标就是每一个扇区的LBA地址。OS使用磁盘,就可以用一个数字访问磁盘扇区了。
四,引入文件系统
1,引入"块"的概念
其实硬盘是典型的“块”设备,操作系统读取硬盘数据的时候,其实是不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个”块”(block)。
硬盘的每个分区是被划分为一个个的”块”。一个”块”的大小是由格式化的时候确定的,并且不可以更改,最常见的是4KB,即连续八个扇区组成⼀个 ”块”。”块”是文件存取的最小单位。
注意:
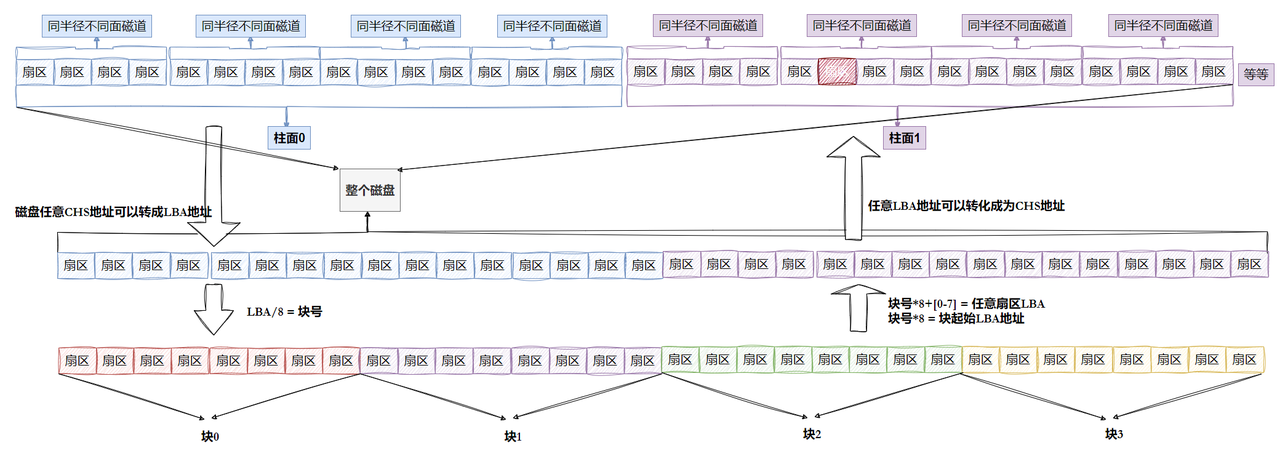
- 磁盘就是一个三维数组,我们把它看待成为一个"一维数组",数组下标就是LBA,每个元素都是扇区
- 每个扇区都有LBA,那么8个扇区一个块,每一个块的地址我们也能算出来。
- 知道LBA:块号 = LBA/8
- 知道块号:LAB=块号*8 + n. (n是块内第几个扇区)
2,引入"分区"的概念
其实磁盘是可以被分成多个分区(partition)的,以Windows观点来看,你可能会有⼀块磁盘并且将它分区成C,D,E盘。那个C,D,E就是分区。分区从实质上说就是对硬盘的一种格式化。

3,引入"inode"概念
文件=数据+属性。
我们使用ls -l 的时候看到的除了看到文件名,还能看到文件元数据(属性)。
所以,文件在磁盘上存储的狮虎,不仅要存储文件的内容数据,还要存储属性,这个属性就是文件的inode信息。
本质上这是一个结构体,包含文件的各种属性,比如文件类型,文件所有者,大小,最后修改时间......等。
还有一个inode_number整型数字,inode_number和文件是一一对应的。
这个结构体的大小一般是128字节。(这个结构题不包含文件名,因为文件名长度是变化的,如果保存在该结构中,那么结构体的长度也就大小不一了)。
五,Ext2文件系统
1,宏观认识
我们想要在硬盘上储文件,必须先把硬盘格式化为某种格式的文件系统,才能存储文件。文件系统的目的就是组织和管理硬盘中的文件。
ext2文件系统将整个分区划分成若干个同样大小的块组 (Block Group),如下图所示。只要能管理⼀个分区就能管理所有分区,也就能管理所有磁盘文件。
ext2文件系统会根据分区的大小划分为数个Block Group。
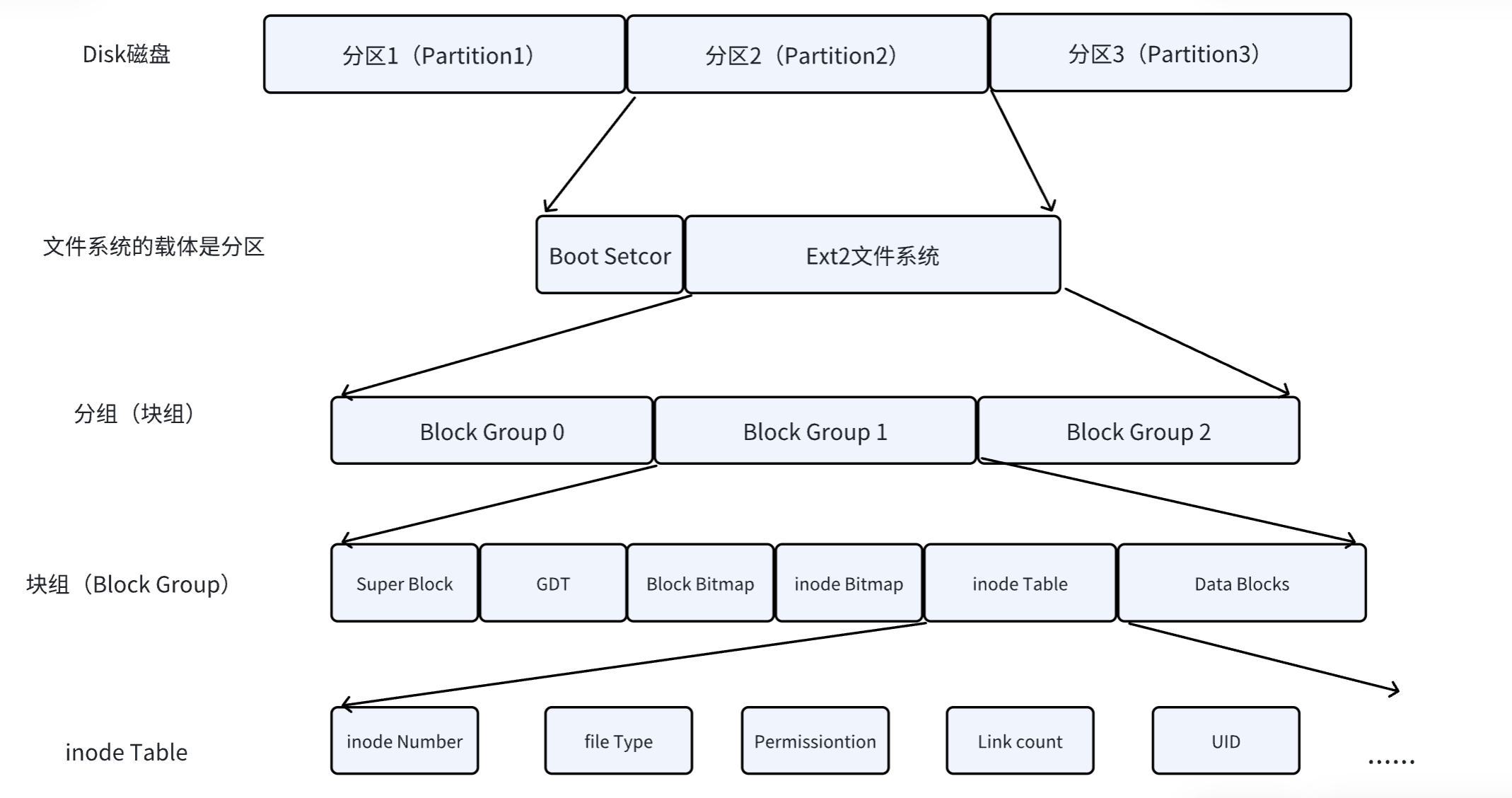
上图中启动块(Boot Block/Sector)的大小是确定的,为1KB,由PC标准规定,用来存储磁盘分区信息和启动信息,任何文件系统都不能修改启动块。启动块之后才是ext2文件系统的开始。
2,块组内部构成
1,inode节点表(Inode Table)
存放文件属性 如文件大小,所有者,最近修改时间等
- 当前分组所有Inode属性的集合
- inode编号以分区为单位,整体划分,不可跨分区
2,数据区(Data Block)
数据区:存放文件内容,也就是一个一个的Block。根据不同的⽂件类型有以下几种情况:
- 对于普通文件,文件的数据存储在数据块中。
- 对于目录,该目录下的所有文件名和目录名存储在所在目录的数据块中,除了文件名外,ls -l命令看到的其它信息保存在该文件的inode中。
- Block 号按照分区划分,不可跨分区
3,块位图(Block Bitmap)
Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用。
4,inode位图(Inode Bitmap)
每个bit表示一个inode是否空闲可用。
5,块组描述表(GDT)
块组描述符表,描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。每个块组描述符存储一个块组的描述信息,如在这个块组中从哪里开始是inode Table,从哪里开始是DataBlocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有一份拷贝。
6,超级块(Super Block)
存放文件系统本身的结构信息,描述整个分区的文件系统信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。
超级块在每个块组的开头都有⼀份拷贝(第⼀个块组必须有,后面的块组可以没有)。 为了保证文件系统在磁盘部分扇区出现物理问题的情况下还能正常工作,就必须保证文件系统的super block信息在这种情况下也能正常访问。所以⼀个文件系统的super block会在多个block group中进行备份,这些super block区域的数据保持一致。
知道inode号的情况下,在指定分区,请解释:对文件进行增、删、查、改是在做什么?
- 分区之后的格式化操作,就是对分区进行分组,在每个分组中写入Super Block,GDT,Block Bitmap,Inode Bitmap等管理信息,这些管理信息统称: 文件系统。
- 只要知道文件的inode号,就能在指定分区中确定是哪一个分组,进而在哪一个分组确定是哪一个inode
- 拿到inode文件属性和内容就全部都有了。
3,目录与文件名
目录也是文件,但是磁盘上没有目录的概念,只有文件属性+文件内容的概念。
目录的属性不⽤多说,内容保存的是:文件名和Inode号的映射关系。
- 所以,访问文件,必须打开当前墓库,根据文件名,获得对应的inode号,然后进行文件访问。
- 访问文件必须要知道当前工作目录,本质是必须能打开当前工作目录文件,查看目录文件的内容。
4,路径解析
问题:打开当前工作目录文件 ,查看当前工作目录文件的内容?当前工作目录不也是文件吗?我们访问当前工作目录不也是只知道当前工作目录的文件名吗?要访问它,不也得知道当前工作目录的inode吗?
答案1:所以也要打开:当前工作目录的上级目录,额....,上级目录不也有目录吗??不还是上面的问题吗?
答案2:所以类似"递归",需要把路径中所有的目录全部解析,出口是"/"根目录。
最终答案3:实际上,任何文件,都有路径,访问目标,比如:/home/xg/code/test/test/test.c
都要从根目录开始,依次打开每一个目录,根据目录名,依次访问每个目录下指定的目录,直到访问到test.c。这个过程叫做Linux路径解析。
可是路径谁提供?
- 你访问文件,都是指令/工具访问,本质是进程访问,进程有CWD!进程提供路径。
- 你open文件,提供了路径可是最开始的路径从哪⾥来?
- 所以Linux为什么要有根目录, 根目录下为什么要有那么多缺省目录?
- 你为什么要有家⽬录,你自己可以新建目录?
- 上面所有行为:本质就是在磁盘文件系统中,新建目录文件。而你新建的任何⽂件,都在你或者系统指定的目录下新建,这不就是天然就有路径了嘛!
- 系统+用户共同构建Linux路径结构。
5,路径缓存
问题1:Linux磁盘中,存在真正的目录吗?
答案:不存在,只有文件。只保存文件属性+文件内容
问题2:访问任何⽂件,都要从/目录开始进⾏路径解析?
答案:原则上是,但是这样太慢,所以Linux会缓存历史路径结构
问题2:Linux目录的概念,怎么产生 的?
答案:打开的文件是目录的话,由OS自己在内存中进行路径维护。
Linux中,在内核中维护树状路径结构的内核结构体叫做: struct dentry,这个结构体中就包含了文件的inode信息。
- 每个文件其实都要有对应的dentry结构,包括普通文件。这样所有被打开的文件,就可以在内存中形成整个树形结构。
- 整个树形节点也同时会隶属于LRU(Least Recently Used,最近最少使用)结构中,进行节点淘汰。
- 整个树形节点也同时会隶属于Hash,方便快速查找。
- 更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何文件,都在先在这棵树下根据路径进行查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry结构,缓存新路径。
六,软硬链接
1,硬链接
真正找到磁盘上文件的并不是文件名,而是inode。其实在linux中可以让多个文件名对应于同一个inode。
[root@localhost linux]# touch abc
[root@localhost linux]# ln abc def
[root@localhost linux]# ls -li abc def
263466 abc
263466 defabc和def的链接状态完全相同,他们被称为指向⽂件的硬链接。内核记录了这个连接数,inode 263466 的硬连接数为2。
我们在删除文件时干了两件事情:1.在目录中将对应的记录删除,2.将硬连接数-1,如果为0,则将对应的磁盘释放。
用途:
- .和..就是硬链接。
- 文件备份。
2,软链接
硬链接是通过inode引用另外一个文件,软链接是通过名字引用另外⼀个文件,但实际上,新的文件和被引用的文件的inode不同,应用常见上可以想象成一个快捷方式。
[root@localhost linux]# ln -s abc.s abc
1
[root@localhost linux]# ls -li
263563 -rw-r--r--. 2 root root 0 9⽉ 15 17:45 abc
261678 lrwxrwxrwx. 1 root root 3 9⽉ 15 17:53 abc.s -> abc
263563 -rw-r--r--. 2 root root 0 9⽉ 15 17:45 def用途:类似快捷方式。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-07-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号