Sparse FlashAttention 算子架构分析与调优技巧
原创
Sparse FlashAttention 算子架构分析与调优技巧
原创
fanstuck
发布于 2026-01-13 10:21:56
发布于 2026-01-13 10:21:56
背景简介
大规模Transformer模型的注意力机制在长序列情况下面临严重的计算和内存瓶颈:传统自注意力需执行级别的矩阵运算,并存储同规模的中间结果,频繁读写高带宽内存(HBM)造成IO开销巨大。FlashAttention的出现旨在从算法和系统层面解决这一瓶颈。
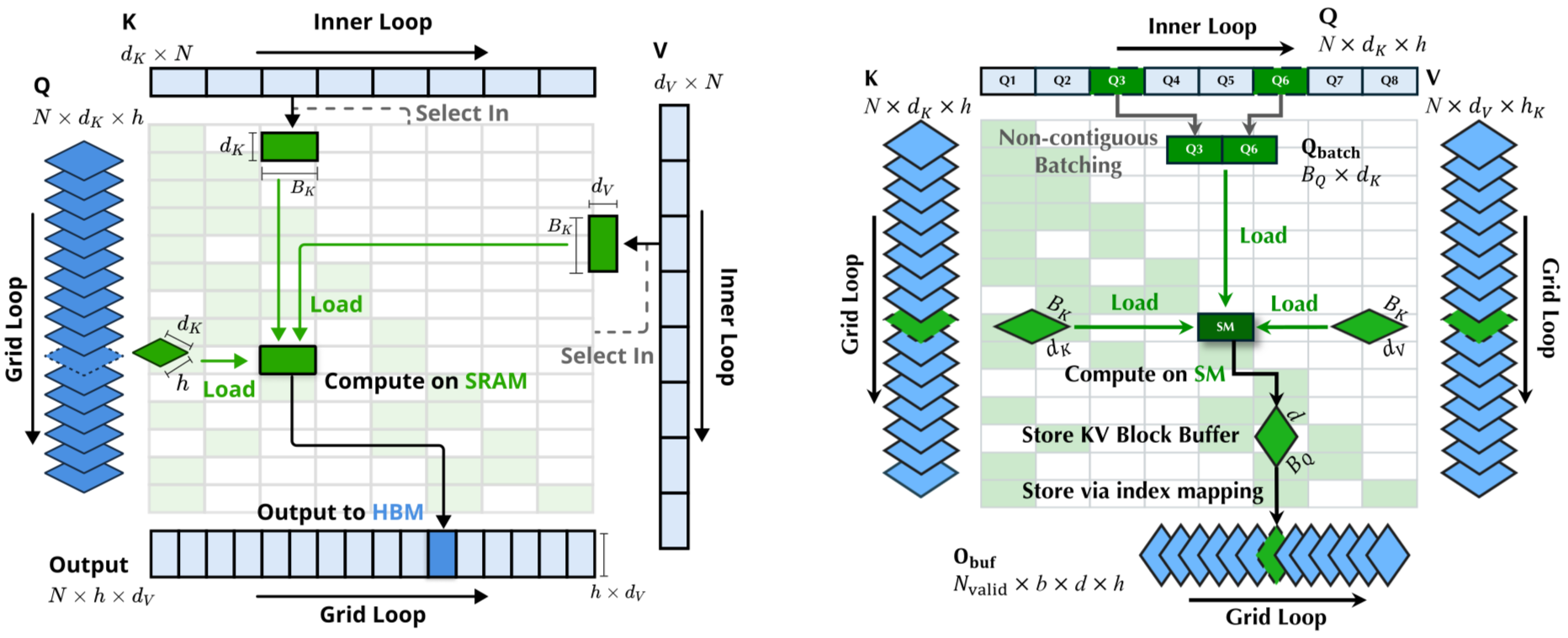
fig:
Stanford DAWN实验室提出的FlashAttention通过分块计算、内存层次优化和在线Softmax等技术,在数学上与标准注意力等价的前提下,将注意力计算的IO复杂度从优化为线性级别,大幅降低90%以上的内存占用。
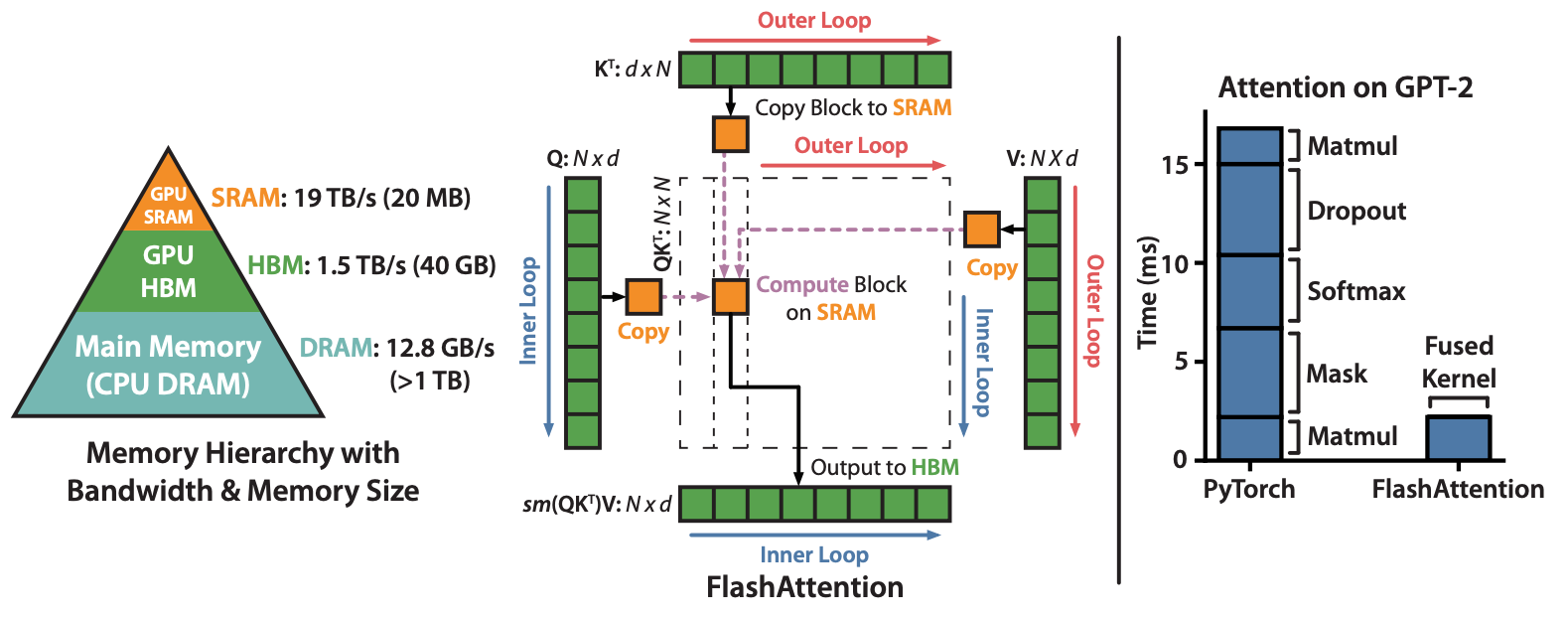
fig:
基于Ascend CANN架构实现的FlashAttention融合算子充分利用片上SRAM缓存(如L0/UB),将完整注意力的多个步骤融合在单一Kernel中近似流式执行,减少对HBM的访问次数,实现了统一架构设计(支持多头、交叉、甚至稀疏注意力等变体)并兼容主流深度学习框架。
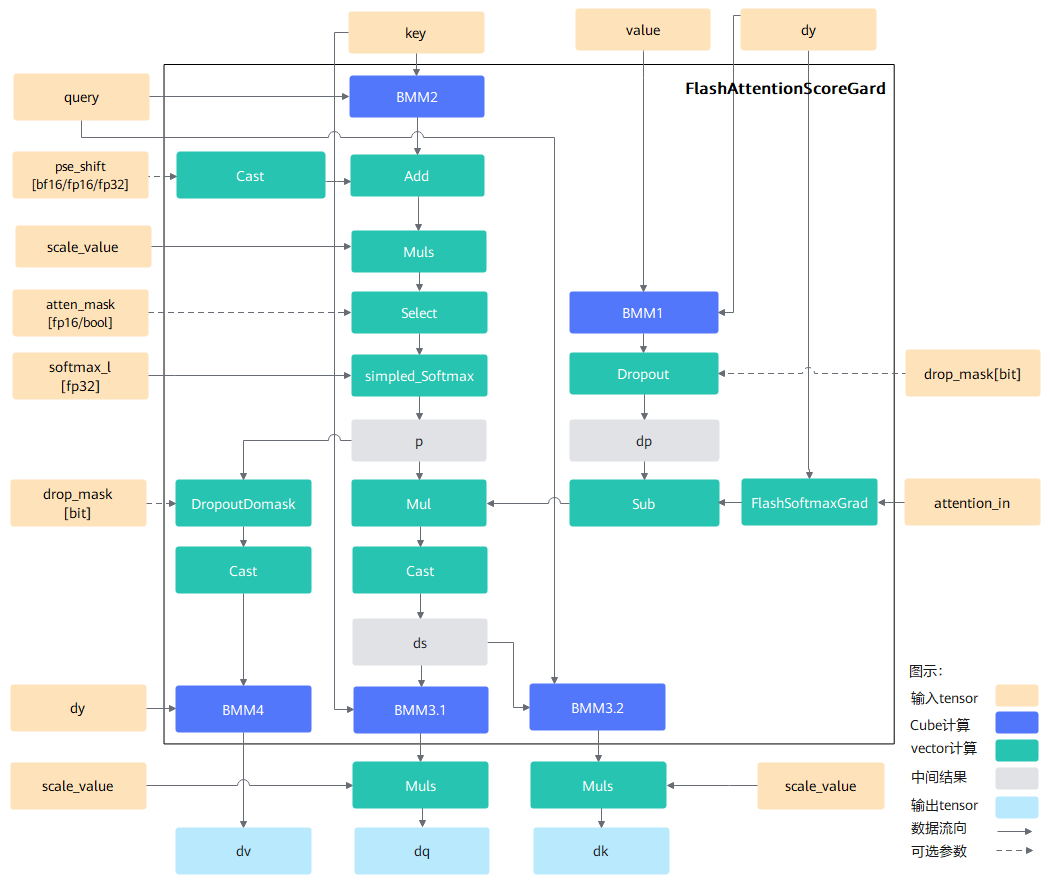
fig:
在Ascend硬件协同优化下,定制的分块策略使FlashAttention算子性能获得显著提升,在一些长序列场景下相对于传统小算子实现加速效果。
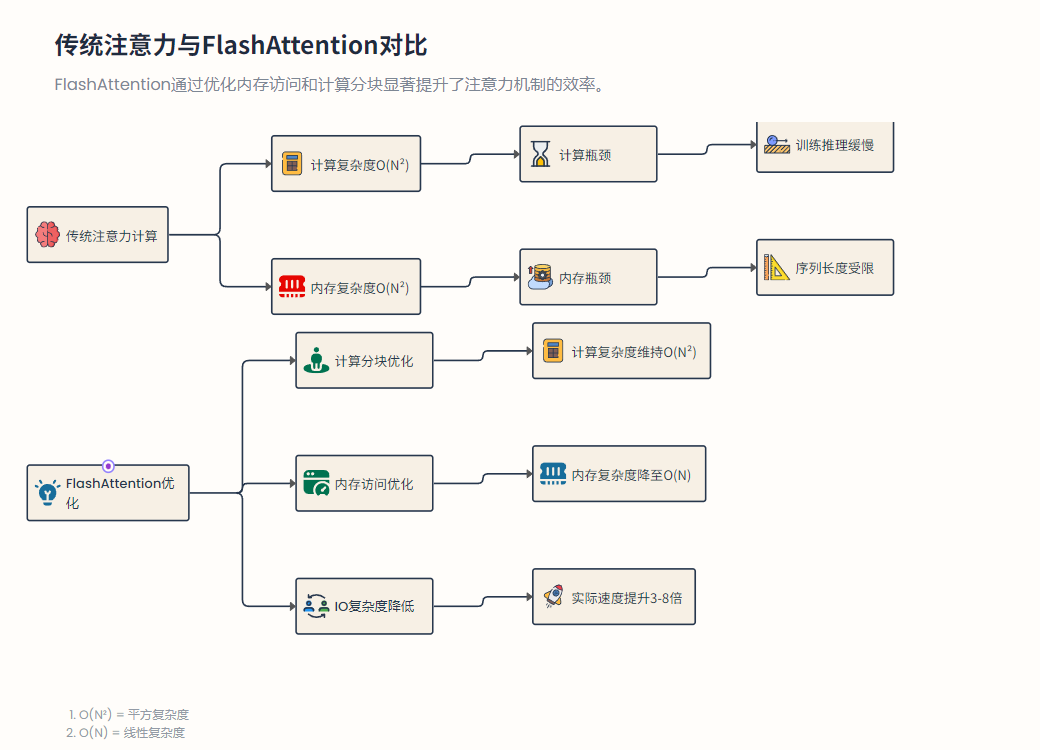
fig:
传统Attention需要两次完整的矩阵乘积并存储整个得分矩阵,计算和内存开销均为。FlashAttention将和、加权求和等步骤融合同步,在片上缓存中以小块为单位完成乘积和归一化,避免生成全尺寸中间结果,将HBM访存量降为线性级别(每元素仅一次读取/写回),从而显著降低了内存带宽瓶颈,提高了算力利用效率。
算子设计
Sparse FlashAttention算子的设计充分结合了FlashAttention的融合思想和稀疏计算特点。在实现上,SFA将多步注意力计算融合进单个自定义Kernel,使数据尽可能留在片上缓存完成完整处理流程。
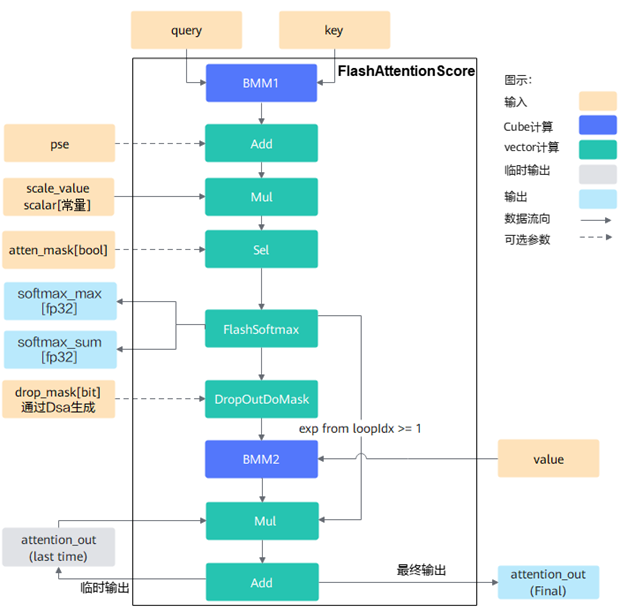
fig:
一方面,SFA继承了FlashAttention在Ascend上的核心架构——采用片上分块计算策略,在一个Kernel内按块依次完成Q*K^T乘积、Softmax归一化和Softmax(QK^T)*V加权求和等子步骤。与传统将这些步骤拆分为多个算子不同,融合算子通过在UB缓冲区反复利用小块数据,实现了计算与数据搬运的高度重叠,并避免了中间大矩阵的物理落地,大幅提升了算子算力和带宽利用率。
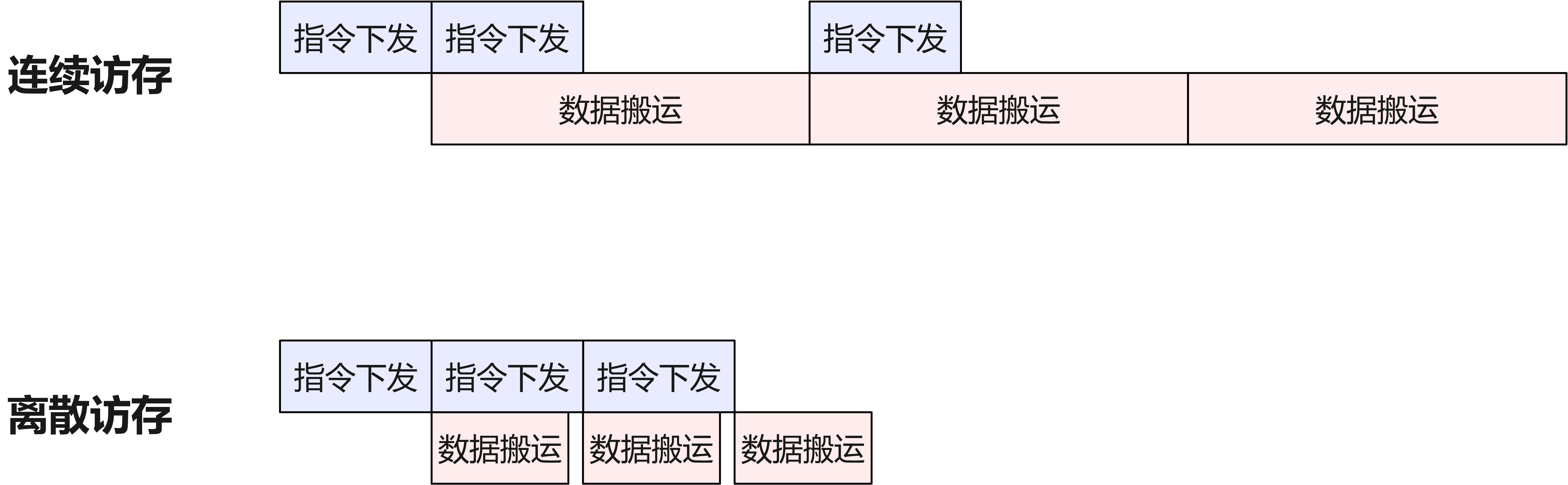
fig:
另一方面,SFA在上述融合流程中增加了稀疏模式下的Query-Key筛选逻辑。具体实现是:在计算主注意力过程之前,Kernel中集成一个轻量的Lightning Indexer阶段,用于根据稀疏模式选取需要重点计算的Key/Value条目。
Lightning Indexer会根据当前Query和全部Key的近似匹配度生成一个稀疏掩码/索引列表:例如在DeepSeek稀疏注意力中,它通过FP8量化的点积快速筛出Top-相关的Token索引。这些索引随后用于裁剪输入,即从原始K、V大矩阵中提取对应的候选Token子集。
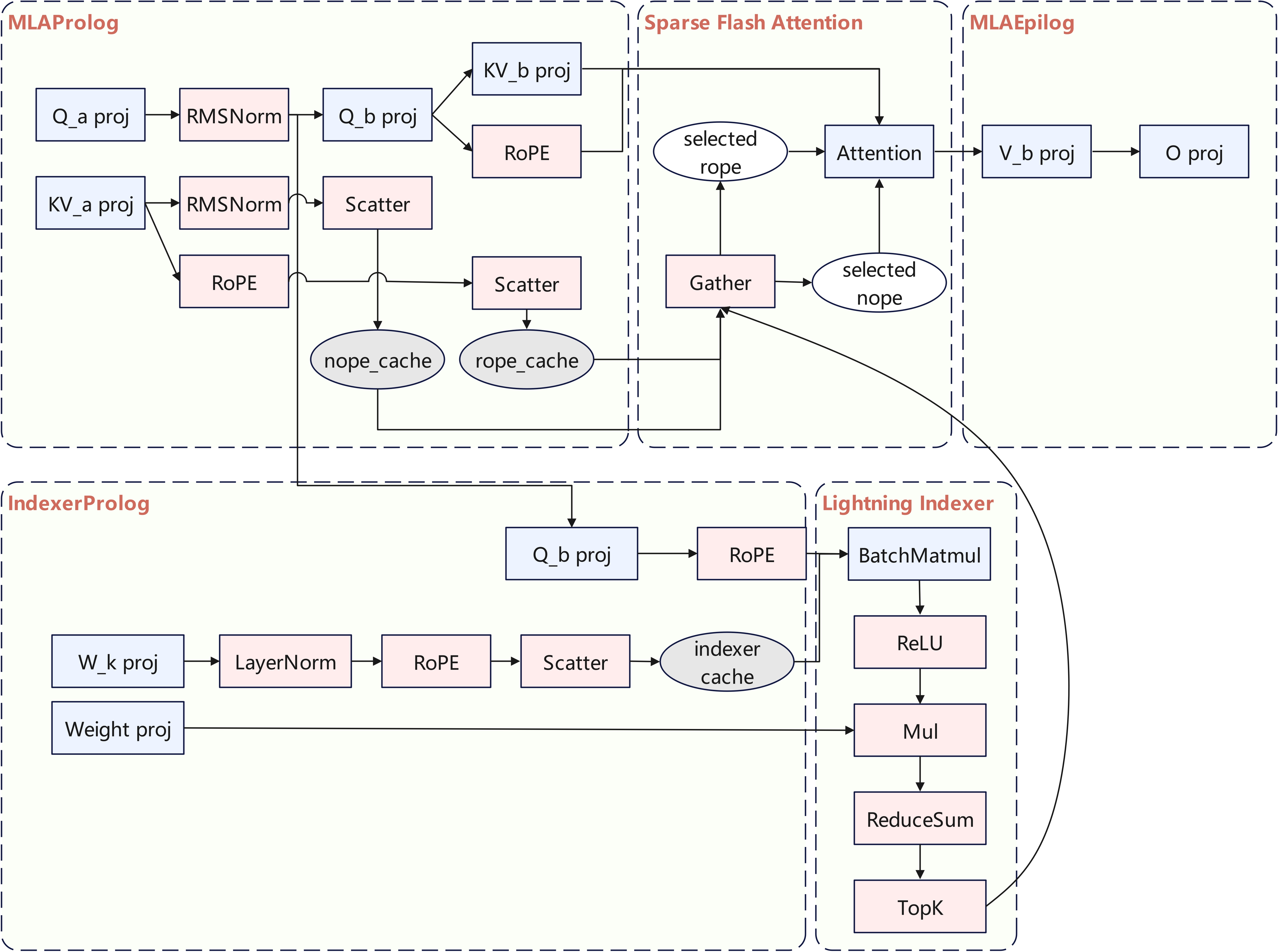
fig:
在PyPTO提供的算子开发框架下,这种稀疏模式通常表示为在计算图中增加一个由Lightning Indexer生成的布尔Mask或索引张量,再据此对K、V进行Gather操作,将稀疏选择后的子K、子V送入后续Attention计算。
Ascend CANN针对这种模式提供了良好的支持:Lightning Indexer和稀疏Attention可作为自定义算子融合注册,使框架在执行时能够识别并高效调度稀疏计算图。例如,DeepSeek-V3.2-Exp在其算子实现中定义了LightningIndexerProlog算子负责上述稀疏索引的生成,相关代码见ops/pypto/src/lightning_indexer_prolog_pto/op_kernel/quant_lightning_indexer_prolog.cpp(基于PyPTO的Ascend算子实现)文件。紧随其后的稀疏注意力算子则接收Top-索引及对应的K、V子集,在一个Kernel内完成注意力矩阵的乘法和Softmax等操作。
值得一提的是,SFA的算子架构在Ascend上做了针对性优化以适配硬件特性。例如,在PyPTO框架下,Ascend算子开发者可以利用统一接口来适配多种注意力变体而无需重复开发:FlashAttention融合算子通过模板化设计支持多头、自注意力和交叉注意力等不同模式,在此基础上扩展支持稀疏注意力只需增加相应的掩码生成和处理逻辑即可。
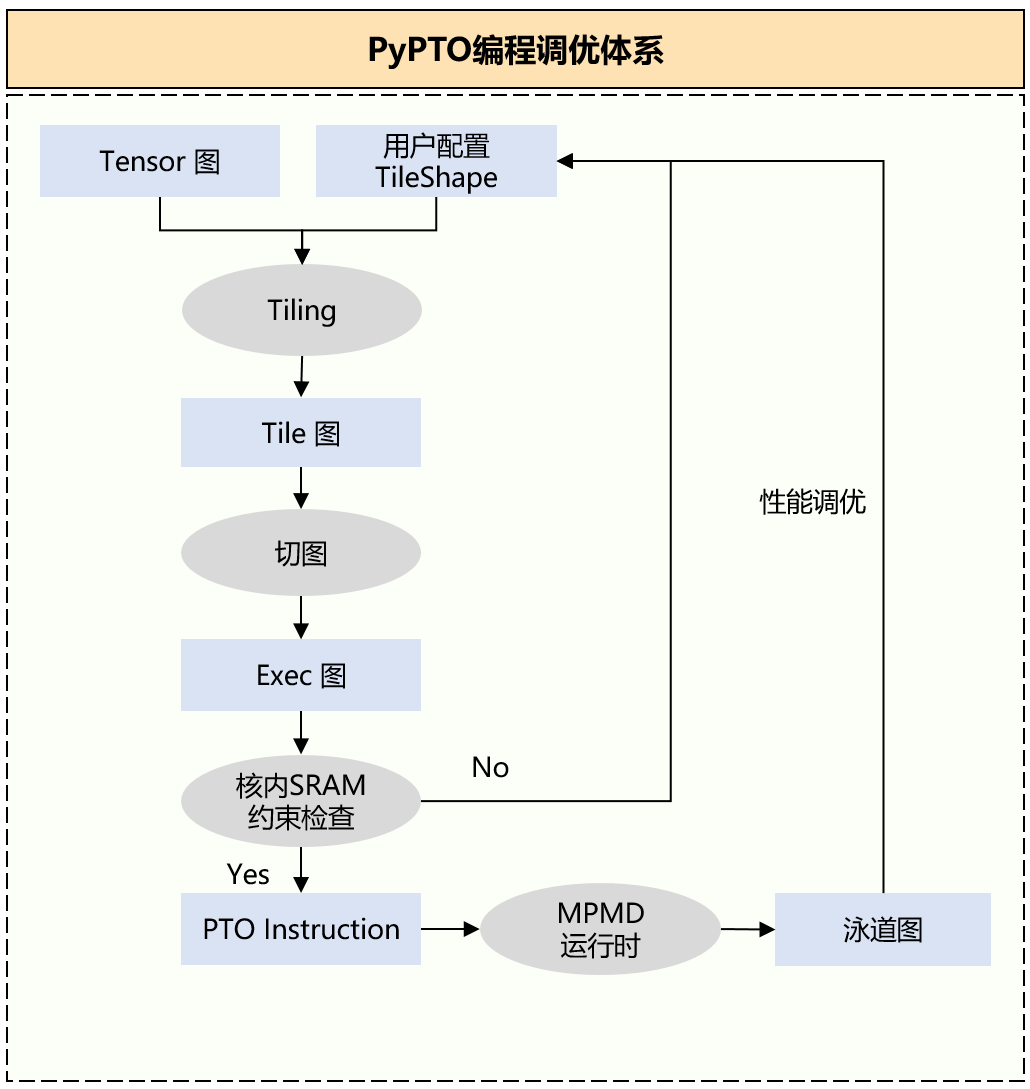
fig:
硬件层面,Ascend的Matrix Cube和Vector引擎具有固定的向量宽度和片上缓存容量,SFA内核据此定制了分块策略:例如将序列分为若干大小合适的子块,使每块的数据正好填满L0/UB缓存并对齐向量计算宽度,从而最大化利用每次内存搬运的数据。这样,在一个Kernel中Lightning Indexer先按块遍历Key集合计算评分,产生Top-掩码后,稀疏注意力阶段再按块计算所选Token的注意力得分和输出,始终保证数据访问和计算粒度与硬件缓存/向量单元匹配。这种设计结合Ascend架构的片上多级缓冲(如L0、L1、LLC)和高并发DMA通道,有效降低了稀疏计算下可能出现的缓存抖动和不规则访存开销,确保算子在处理稀疏模式时依然保持高效的内存带宽利用率和计算吞吐。
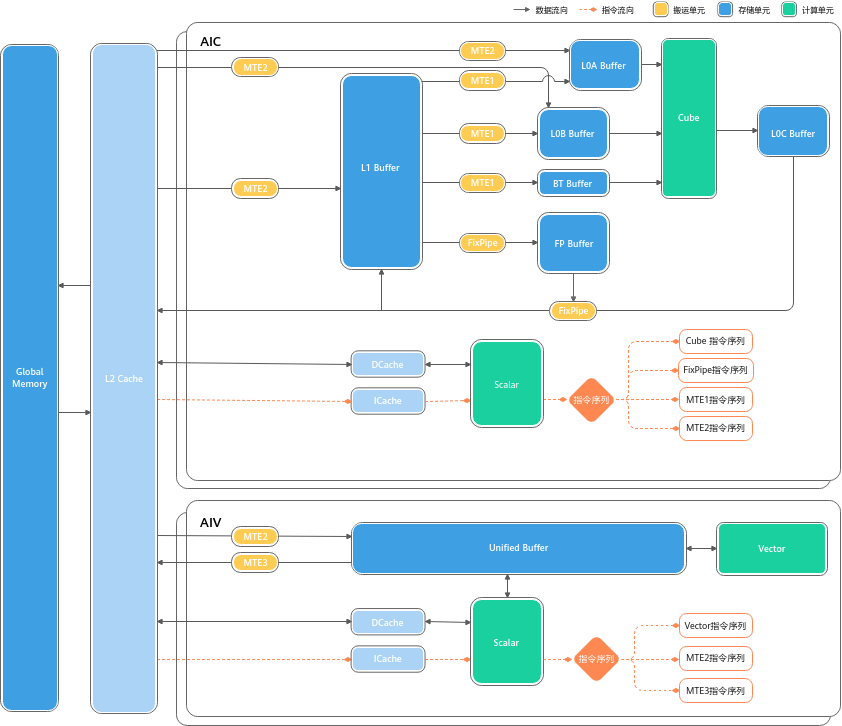
fig:
关键路径解读
Sparse FlashAttention的执行流程可以拆解为稀疏索引选择和稀疏注意力计算两个阶段,每个阶段内部又各自采用了高效的分块并行处理。以下对其关键路径和数据流进行解析:
阶段1
Lightning Indexer 筛选候选Token。当新的Query需要与长序列历史Token计算注意力时,Lightning Indexer会率先运行,对所有个候选Key进行相关性打分。通常这个过程按块进行:例如将长度序列按每块64个token划分(DeepSeek实现中索引缓存页大小为64),利用Ascend向量核并行计算每块中的Query-Key点积分数。
struct ConstInfo { // CUBE与VEC核间同步的模式 static constexpr uint32_t FIA_SYNC_MODE2 = 2; // BUFFER的字节数 static constexpr uint32_t BUFFER_SIZE_BYTE_32B = 32; static constexpr uint32_t BUFFER_SIZE_BYTE_64B = 64; static constexpr uint32_t BUFFER_SIZE_BYTE_256B = 256; static constexpr uint32_t BUFFER_SIZE_BYTE_512B = 512; static constexpr uint32_t BUFFER_SIZE_BYTE_1K = 1024; static constexpr uint32_t BUFFER_SIZE_BYTE_2K = 2048; static constexpr uint32_t BUFFER_SIZE_BYTE_4K = 4096; static constexpr uint32_t BUFFER_SIZE_BYTE_8K = 8192; static constexpr uint32_t BUFFER_SIZE_BYTE_16K = 16384; static constexpr uint32_t BUFFER_SIZE_BYTE_32K = 32768; // 无效索引 static constexpr int INVALID_IDX = -1; // CUBE和VEC的核间同步EventID uint32_t syncC1V1 = 0U; uint32_t syncV1C1 = 0U; // 基本块大小 uint32_t mBaseSize = 1ULL; uint32_t s1BaseSize = 1ULL; uint32_t s2BaseSize = 1ULL; uint64_t batchSize = 0ULL; uint64_t gSize = 0ULL; uint64_t qHeadNum = 0ULL; uint64_t kHeadNum; uint64_t headDim; uint64_t sparseCount; // topK选取大小 uint64_t kSeqSize = 0ULL; // kv最大S长度 uint64_t qSeqSize = 1ULL; // q最大S长度 uint32_t kCacheBlockSize = 0; // PA场景的block size uint32_t maxBlockNumPerBatch = 0; // PA场景的最大单batch block number LI_LAYOUT outputLayout; // 输出的格式 bool attenMaskFlag = false; uint32_t actualLenQDims = 0U; // query的actualSeqLength 的维度 uint32_t actualLenDims = 0U; // KV 的actualSeqLength 的维度 bool isAccumSeqS1 = false; // 是否累加模式 bool isAccumSeqS2 = false; // 是否累加模式 }; struct SplitCoreInfo { uint32_t s2Start = 0U; // S2的起始位置 uint32_t s2End = 0U; // S2循环index上限 uint32_t bN2Start = 0U; uint32_t bN2End = 0U; uint32_t gS1Start = 0U; uint32_t gS1End = 0U; bool isLD = false; // 当前核是否需要进行Decode归约任务 };
Lightning Indexer内部通过FP8量化降低计算和存储精度,以极低的开销完成对大部分Token的评估。在每处理完一块后,Indexer会更新当前发现的Top-高分Token列表——这通常通过维护一个小型\最大堆/阈值来逐渐筛选出全局分数最高的若干Token。
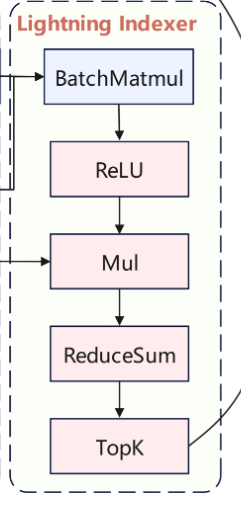
fig:
待所有块遍历完成,Lightning Indexer即可输出最终选中的稀疏索引集合。这些索引通常对应若干相关性最高的片段或token(例如DeepSeek中每个Query选取相关度最高的若干段落,再细化到固定数量的token)。通过这一粗筛过程,海量的不相关Token被有效排除在后续计算之外——Lightning Indexer本身的复杂度为(为隐藏维度),远小于原始注意力计算,当极大时这一阶段的开销相对于整体是可接受的。
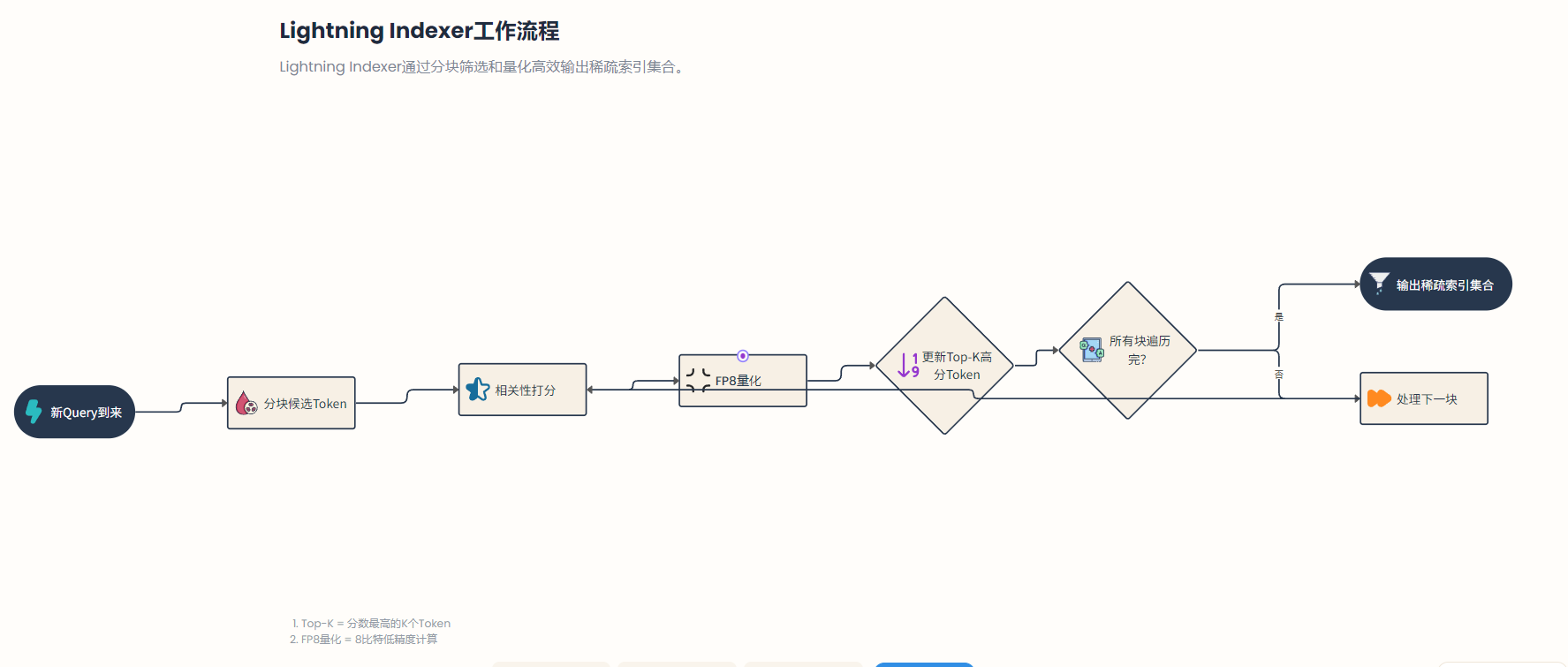
fig:
阶段2
Sparse Attention细粒度计算。Lightning Indexer确定Top-候选索引后,Sparse FlashAttention算子会将对应的Key和Value向量从大矩阵提取出来,组成大小为的紧凑子矩阵。随后,算子仅针对这些筛选后的条目执行标准的注意力计算流程。
由于,计算复杂度相当于对一个短序列执行全连接注意力(例如时仅1.6%原始token参与后续计算)。在实现上,SFA沿用了FlashAttention的两遍在线Softmax算法:第一遍按块计算得到注意力得分局部值,同时找出每个Query对应的score最大值并累加每块的和,以计算全局Softmax归一因子;第二遍再次按相同块划分计算并乘以对应的Value,累加得到最终输出。源码参考:https://gitcode.com/cann/cann-recipes-infer/blob/master/ops/tilelang/sparse_flash_attention.py。
with T.Scope("V"): T.fill(acc_o, 0.0) T.fill(sumexp, 0.0) T.fill(m_i, -2.0 ** 30) T.barrier_all() for loop_i in range(ni): T.copy(indices[b_i, s_i, g_i, loop_i * bi:loop_i * bi + bi], indices_ub_) T.barrier_all() for bi_i in range(bi // 2): T.copy(kv[b_i, indices_ub_[bi_i + vid * bi // 2], g_i, :d], kv_ub) T.copy(kv[b_i, indices_ub_[bi_i + vid * bi // 2], g_i, d:], kv_tail_ub) T.barrier_all() T.copy(kv_ub, workspace1[cid, bi_i + vid * bi // 2, :]) T.copy(kv_tail_ub, workspace2[cid, bi_i + vid * bi // 2, :]) T.barrier_all() T.set_cross_flag("MTE3", 0) T.fill(acc_s_ub, 0.0) T.barrier_all() T.copy(m_i, m_i_prev) T.barrier_all() T.wait_cross_flag(1) T.copy(workspace3[cid, vid * v_block:vid * v_block + v_block, :], acc_s_ub_) T.barrier_all() T.add(acc_s_ub, acc_s_ub, acc_s_ub_) T.barrier_all() T.mul(acc_s_ub, acc_s_ub, sm_scale) T.barrier_all() T.reduce_max(m_i, acc_s_ub, tmp_ub, dim=-1) T.barrier_all() T.max(m_i, m_i, m_i_prev) T.barrier_all() T.sub(m_i_prev, m_i_prev, m_i) T.barrier_all() T.exp(m_i_prev, m_i_prev) T.barrier_all() for h_i in range(v_block): T.barrier_all() T.sub(acc_s_ub[h_i, :], acc_s_ub[h_i, :], m_i[h_i]) T.barrier_all() T.exp(acc_s_ub, acc_s_ub) T.barrier_all() T.reduce_sum(sumexp_i_ub, acc_s_ub, tmp_ub, dim=-1) T.barrier_all() T.mul(sumexp, sumexp, m_i_prev) T.barrier_all() T.add(sumexp, sumexp, sumexp_i_ub) T.barrier_all() for h_i in range(v_block): T.barrier_all() T.mul(acc_o[h_i, :], acc_o[h_i, :], m_i_prev[h_i]) T.barrier_all() T.copy(acc_s_ub, acc_s_half) T.barrier_all() T.copy(acc_s_half, workspace4[cid, vid * v_block:vid * v_block + v_block, :]) T.barrier_all() T.set_cross_flag("MTE3", 2) T.wait_cross_flag(3) T.barrier_all() T.copy(workspace5[cid, vid * v_block:vid * v_block + v_block, :], acc_o_ub) T.barrier_all() T.add(acc_o, acc_o, acc_o_ub) T.barrier_all() T.set_cross_flag("V", 4) T.barrier_all() for h_i in range(v_block): T.barrier_all() T.div(acc_o[h_i, :], acc_o[h_i, :], sumexp[h_i]) T.barrier_all()
这种“两步走”策略确保Softmax的精确性,同时避免一次性生成完整得分矩阵。需要强调的是,稀疏选择会影响块计算的次序和内存访问模式:选中的个Token往往分布在原始序列的不同位置,如果直接逐个读取可能导致无规律的小片段内存访问,降低硬件带宽利用率。
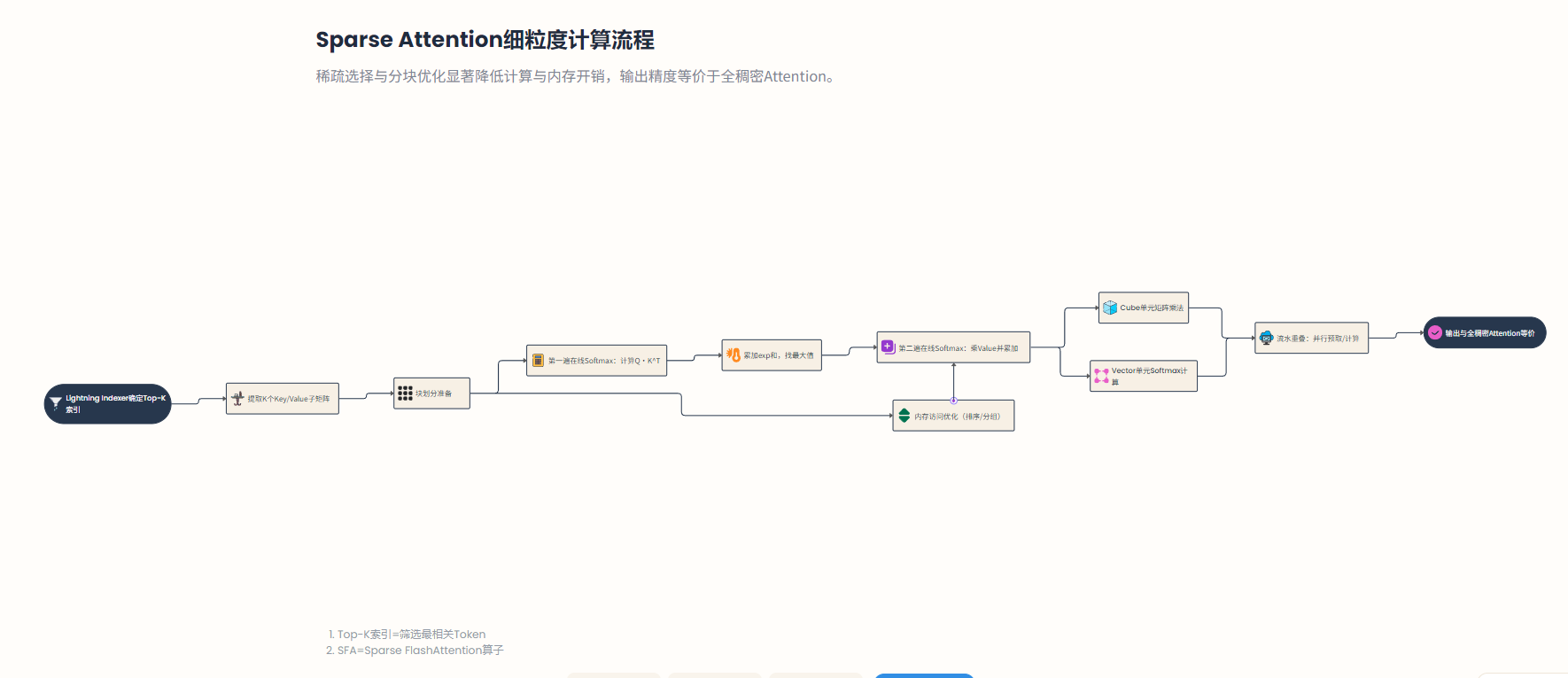
fig:
为此,SFA在Lightning Indexer阶段通常会对候选索引进行排序或分组(例如按照原始顺序排序),并尽量以顺序批量方式加载所需的K、V子块数据。这样一来,SFA第二阶段的内存访问模式接近于处理一个长度为的连续序列,充分利用了Ascend片上缓存的局部性优势。
同时,在每个块内部,Ascend的Cube矩阵乘法单元负责主要的乘法累加计算,Vector标量单元则执行Softmax中的指数、除法等操作。通过合理设置分块大小和计算排布,SFA实现了Cube计算与Vector计算的流水重叠:当处理当前块的矩阵乘法时,上一块的Softmax归一和下一块的数据预取可以在后台并行进行,从而摊平了各子模块的等待时间。整个Sparse Attention细粒度计算阶段结束后,得到的输出与全稠密Attention计算结果在数值上等价(仅存在极小的近似误差),但总共涉及的算力和数据传输量已经大幅降低。
性能瓶颈定位
通过以上架构分析,可以看出Sparse FlashAttention极大缓解了长序列注意力的计算和内存压力,但在实现和优化过程中仍可能面临一些性能瓶颈。
片上缓存利用率瓶颈
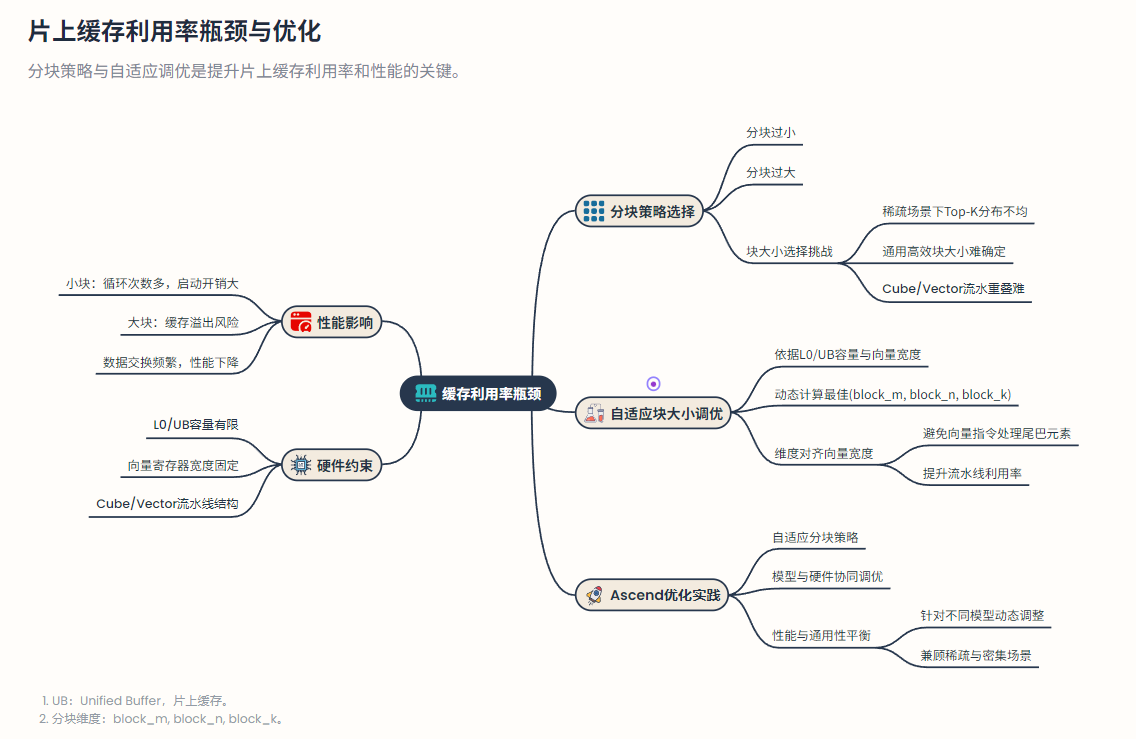
fig:
块策略的选择直接影响片上Unified Buffer (UB)等缓存的利用效率。如果分块过小,Kernel需要循环处理过多次,小块计算间的启动开销和片上数据交换频繁,导致性能下降;但若分块过大,可能超出片上缓存容量引发溢出,或导致Cube/Vector流水无法有效重叠。
尤其在稀疏场景下,不同查询可能对应不同分布的Top-索引,如何选择一个通用且高效的块大小是一大挑战。Ascend优化实践中通常采用\自适应块大小调优:根据硬件的L0/UB大小和向量寄存器宽度,计算出适合当前模型和硬件的最佳(block_m, block_n, block_k)分块维度,并确保这些维度对齐硬件向量宽度以避免向量指令处理“尾巴元素”。
稀疏模式下的分支和数据对齐开销
稀疏Attention引入的条件判断和不规则数据访问也可能影响硬件流水线效率。例如,在逐块判断某个块是否需要计算时(基于掩码或索引),频繁的if分支会破坏向量指令的批处理优势。同样地,选中的Top- token往往不是64的倍数,
fig:
这意味着最后一个向量寄存器可能装不满数据,造成计算单元部分闲置。为解决这些问题,Ascend编译器和算子开发者会采用填充和向量化对齐等手段:例如对Top-列表长度做上限Padding到硬件友好的倍数,或在生成稀疏掩码时直接按块对齐边界。这些措施减少了稀疏计算中由于数据不齐整带来的分支跳转和向量闲置,从而提高了实际有效算力利用率。
残余IO瓶颈:
尽管FlashAttention将Attention主要计算过程的HBM访存量降至线性,SFA仍然不可避免地需对全序列的Key进行一次扫描(Lightning Indexer阶段)。当序列长度极大时(如数十万级token),这一次的遍历本身可能成为新的瓶颈——尤其是生成每个新Query都要重复扫描。在
Ascend上,如果Key全部存放在HBM中,Lightning Indexer读遍所有Key向量的过程可能耗尽内存带宽,限制整体吞吐。
调优策略与结果
Ascend平台的Sparse FlashAttention实现中采用了一系列调优策略,并取得了显著的性能收益。
内存层次优化
充分利用Ascend芯片的多级内存结构(L0/UB、L1、LLC等)来提升数据局部性。一方面,调整UB分配策略,尽可能为注意力计算分配足够大的片上缓冲空间。例如通过增大单次处理的block尺寸,使UB几乎装满当前块所需的Q、K、V子矩阵和中间变量。
引入分层缓存机制:对Lightning Indexer阶段频繁访问的Key数据,可在LLC或HBM高速缓存中保留一份,从而减少每次扫描对HBM的重复访问。综合这些措施,SFA算子在长序列场景下的HBM带宽瓶颈大大缓解,内存访问效率明显提高。
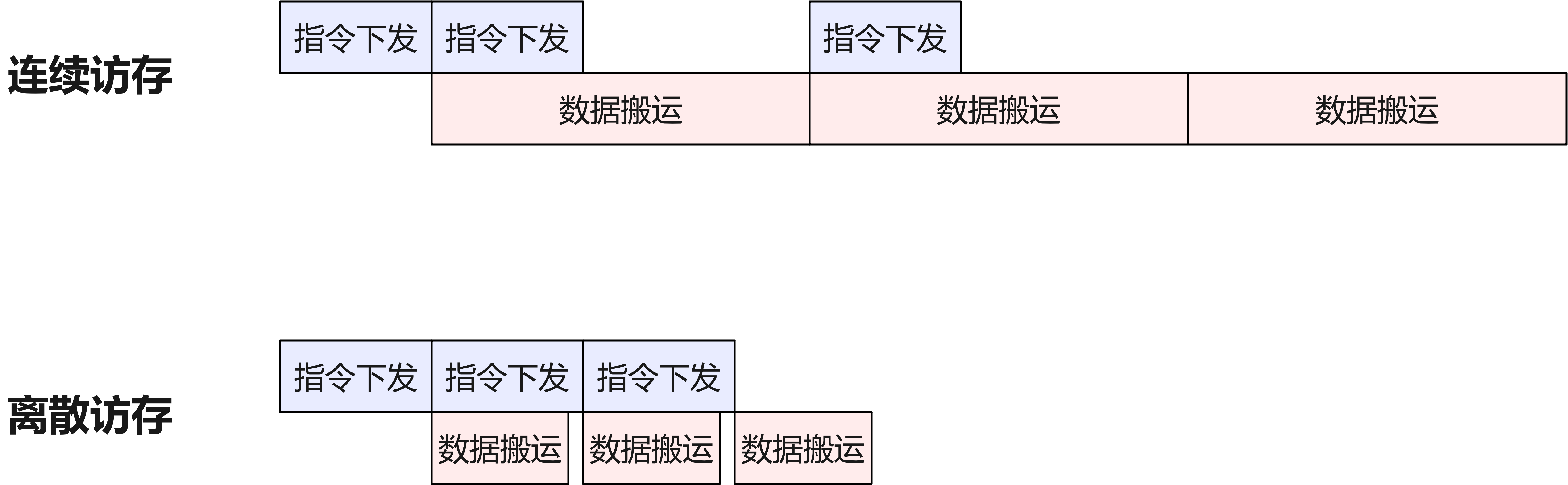
fig:
计算重计算trade-off
借鉴FlashAttention的做法,SFA通过牺牲少量算力重复计算来换取内存占用和访存量的下降。例如在Softmax归一过程中不保存中间级别的完整注意力矩阵,而是采用两遍扫描算法,第二遍需要重新计算一次局部值。
又如Lightning Indexer在FP8筛选后,Sparse Attention阶段重新对Top-候选执行高精度的计算,以确保数值精度——相当于对这些关键token重复计算了一次相关性分数。这些“重计算”策略略微增加了算术操作量,但极大减少了需要存储和传输的数据量(尤其是避免了大量稀疏无效元素的搬运),在实际权衡中是非常划算的。当时,重计算开销可以忽略不计,却换来了总体性能成倍提升。
流水并行调度
针对Ascend架构的Cube和Vector算子以及多通道DMA,精心调度各子任务的执行顺序,实现深度流水并行。调优过程中,通过分析算子时间线发现Cube(矩阵乘法)和Vector(激活函数等)之间存在空闲等待,于是采用**CV流水优化:让Cube一次性计算多个块的部分结果并暂存,然后Vector端分次取出处理。这样Cube可以连续工作,而Vector也有源源不断的数据可用,显著减少了两者之间的等待空隙。
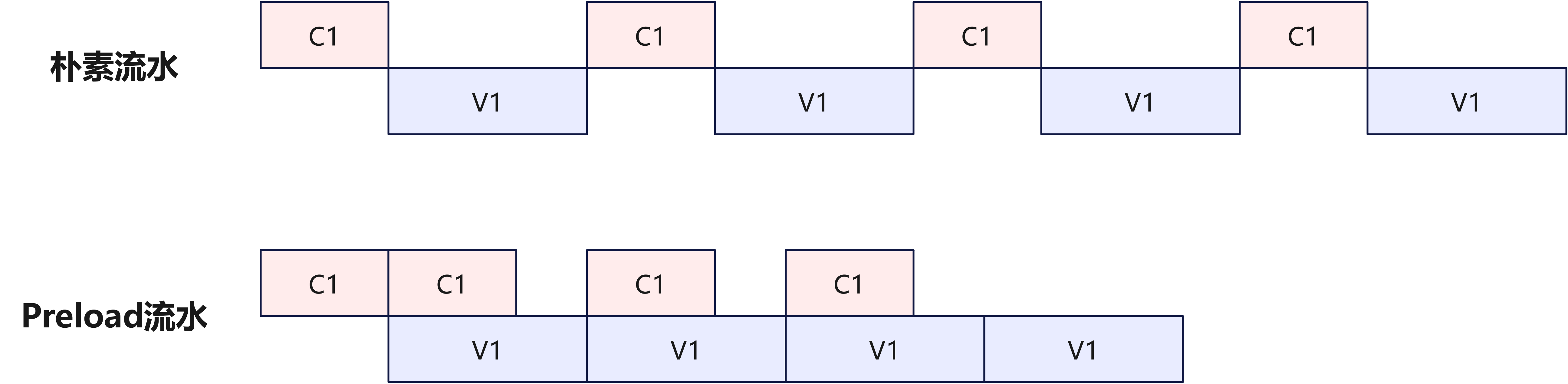
fig:
此外,充分利用Ascend的MTE(内存传输引擎)流水能力,在计算同期预取下一块数据、回写上一块结果,实现计算与数据搬运并行。通过这些调度优化,Sparse FlashAttention算子的各硬件单元(矩阵乘法引擎、向量处理器、DMA等)都能接近满负荷工作,整体效率接近理论峰值。
综合来看,Ascend平台下SFA融合算子的端到端优化效果非常显著——相比传统注意力计算,在长序列(例如128K tokens)场景下可实现数量级的性能跃升。得益于这样的优化成果,像DeepSeek-V3.2-Exp这样的长文本大模型才能将超长上下文应用于实际推理,并保持与稠密注意力相当的准确性。可以预见,随着硬件和算法的协同演进,未来Sparse FlashAttention将在更大模型和更长序列的场景中发挥关键作用,成为长序列高效推理的利器。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号