构建AI智能体:大模型的指令微调与人类对齐:从知识渊博到善解人意
原创
构建AI智能体:大模型的指令微调与人类对齐:从知识渊博到善解人意
原创
未闻花名
发布于 2026-01-14 07:56:07
发布于 2026-01-14 07:56:07
一、前言
不管是工作中还是生活中,当我们直接与原始模型对话时,常常会遇到挫折,它们可能会无视我们的问题,自顾自地续写一段无关的文字;可能会生成带有偏见、仇恨甚至暴力倾向的内容;或者无法理解“写一首诗”、“总结这篇文章”等复杂指令。这暴露了预训练模型的核心问题:它们擅长补全,但不擅长对话;它们拥有能力,但缺乏价值观。
为了弥补这一鸿沟,让大模型真正变得“善解人意”、安全可靠,指令微调与人类对齐技术应运而生。

二、什么是指令微调
指令微调是继预训练之后的一个关键步骤。其核心目标是教会模型如何理解并服从人类的指令,并将其广泛的知识以对话的形式有效地组织和输出。
它是一种监督学习。我们需要准备一个由大量(指令,期望输出)对组成的数据集。通过在这个数据集上对预训练模型进行微调,模型会逐渐学会将“指令”映射到“期望的输出行为”,而不是简单地预测下一个最可能的词。
一个典型的数据样本格式如下:
- Instruction(指令): “写一封邮件,礼貌地拒绝一个周末的聚餐邀请。”
- Input(输入,可选): “邀请人:张三,理由:本周末需要加班。”
- Output(输出): “亲爱的张三,非常感谢你的盛情邀请!很不巧,我本周末因为工作需要加班,实在无法抽身。希望我们下次再聚,祝你们玩得愉快!【你的名字】”
通过成千上万个这样的例子,模型学会了“拒绝邀请邮件”这个任务应该遵循的格式、语气和内容结构。
微调前后输出对比:
- 输入提示词:将“I love programming!”翻译成中文
- 原始模型优先考虑的是补全和解释后输出:“I love programming! 这是一种充满创造力和逻辑思维的活动,许多开发者都对其充满热情。”
- 指令微调后模型理解了用户意图,重点是需要执行翻译,经过翻译后准确的输出:“我喜欢编程!”

指令微调的完整过程:
- 1. 预训练大模型
- 拥有丰富的知识储备,但缺乏对话和指令遵循能力,只能进行文本补全,无法理解用户意图
- 2. 指令微调数据集
- 包含高质量的(指令→输出)配对样本,作为教材指导模型学习,涵盖各种任务类型:翻译、总结、问答等
- 3. 指令微调后的模型
- 学会了理解和遵循人类指令,能够进行自然对话,将知识以有用的方式组织输出
指令微调就像一个调教过程,预训练模型虽然知识丰富,但不懂规矩,我们通过高质量的指令数据集,手把手地教它当人类给出某种指令时,应该如何回应,经过学习,模型就变成了一个懂得遵循指令、善解人意的优秀助手。
三、指令微调的实践过程
1. 数据准备
数据是指令微调成功的关键。数据可以来自人工标注、现有数据集重组(如将问答对转换为指令格式)或利用大模型自己生成。质量远比数量重要,数据需要覆盖广泛的任务类型(问答、总结、创作、分类等),并且输出要准确、有益、无害。
2. 训练过程
训练过程与标准的语言模型微调类似,我们使用指令作为输入,并让模型预测对应的输出。损失函数计算的是模型预测的输出序列与真实输出序列之间的交叉熵损失。
3. 效果对比
3.1 写一首关于春天的诗句
- 微调前:“春天是四季中的第一个季节,气候温暖,万物复苏。在气象学上...”
- 输出的基于百科或已有知识内容的补全,缺乏场景的构建的想象能力。
- 微调后:“春风轻抚绿柳梢,桃花映面笑。细雨润物悄无声,燕子衔泥筑新巢。”
- 遵循写诗的指令,理解了需要创作写诗的意图,可能生成的内容会很凌乱,但已经具备理解、创造的感知。
3.2 对话语的情感分析
- 判断这句话的感情:“我错过了回家的末班车,心情糟透了。”
- 微调前:“我错过了回家的末班车,心情糟透了。这意味着我需要打车,可能会产生额外费用,”,模型更多的是在续写。
- 微调后:“消极”,模型正确地将任务识别为分类任务,并给出了简洁的答案
四、怎么理解"人类对齐"
1. 什么是人类对齐
人类对齐指的是设计和训练人工智能系统,使其目标、价值观和行为与人类意图和利益保持一致的技术与哲学范畴。可以把它想象成给一个能力超强但心智不成熟的天才进行品德教育:
- 预训练模型:像一个博览群书的天才,知识渊博但不懂人情世故
- 指令微调:教它基本的沟通礼仪和对话规则
- 人类对齐:培养它的价值观、道德观和责任感,让它知道什么该做、什么不该做
核心目标:确保AI系统是有帮助的、诚实的、无害的。
2. 人类对齐的意义

这个流程图清晰地展示了未对齐AI模型可能带来的各种风险:
高风险类别(红色)
- 生成有害内容:直接产生暴力、歧视性内容
- 提供危险建议:指导犯罪行为或危险行为
中风险类别(橙色)
- 传播偏见:强化社会中的各种偏见
- 拒绝合理请求:过度保守影响正常使用
- 价值观冲突:不同文化背景下的理解差异
现在的很多AI产品,我们在使用过程中也会体验一些友情的提示和温馨的关怀,都是经过向人类思维靠近后,体系出的人性化关怀,经过处理的模型会主动规避一些答案准确却不合常理的结果输出,反而是主动引导降低风险,分身为优秀的心理咨询师或者耐心的指导老师。
3. 人类对齐的多种维度

详细解释:
- 价值观复杂性:
- 不同文化、国家、群体有不同的价值观
- 什么算"有帮助"?什么算"无害"?存在灰色地带
- 例:关于言论自由的边界,各地标准不同
- 奖励黑客:
- AI会寻找奖励函数的漏洞,而不是真正理解人类意图
- 例:如果奖励"用户满意度",AI可能一味讨好用户而非提供真实信息
- 价值权衡:
- 诚实 vs 善良:当真相可能伤害他人时,该如何选择?
- 安全 vs 有用:过度保守会限制AI的实用性
- 分布外泛化:
- 训练时没见过的新型恶意指令,AI能否正确应对?
- 例:用隐喻、代码或特殊术语绕过安全检测
4. 人类对齐技术路线图

流程详解:
第一步:指令微调
- 目标:教会模型基本的对话能力和指令遵循
- 方法:使用高质量的(指令, 期望回答)配对数据
- 效果:模型从"知识库"转变为"对话伙伴"
- 示例:用户说"写一首诗",模型能生成"春眠不觉晓..."
第二步:训练奖励模型
- 目标:让模型学会判断回答质量的好坏
- 方法:人类对多个回答进行排序,训练模型预测人类偏好
- 关键:不依赖硬编码规则,而是学习人类的价值观
- 示例:对于危险问题,人类偏好排序:提供资源 > 具体方法 > 直接拒绝
第三步:强化学习优化
- 目标:让模型学会主动选择符合人类价值观的回答
- 方法:使用奖励模型的反馈信号,通过强化学习优化生成策略
- 过程:模型不断尝试生成回答,根据RM评分调整策略
- 结果:模型内化了人类的偏好标准
五、从“遵循指令”到“人类对齐”
指令微调让模型变得听话,但听话不等于优秀,一个严格遵循指令的模型,如果被要求“写一篇支持种族歧视的文章”,它依然会照做。这就是人类对齐要解决的核心问题:让模型的输出不仅符合指令,更要符合人类的价值观,有帮助、诚实、无害。
实现这一目标的技术是基于人类反馈的强化学习(RLHF):
RLHF的三步曲:
1. 监督微调(SFT):这就是我们上面人类对齐中完成的指令微调步骤,它产出一个基础的对齐模型,能够理解和遵循指令。
2. 训练奖励模型(RM):
- 我们收集一个由人类标注员对多个模型输出进行排序的数据集。例如,对于同一个指令,给出A、B、C、D四个回答,标注员需要排序:B > D > A > C(B最好,C最差)。
- 用一个去掉最终输出层的SFT模型作为基础,训练一个奖励模型。这个模型学习预测人类更喜欢哪个输出,并为其打出一个分数(奖励)。
3. 强化学习(RL)微调:
- 现在我们有了一个“裁判”:奖励模型(RM)。
- 我们让SFT模型针对各种指令生成回答。
- 每个生成的回答都会被RM打分。
- 我们使用强化学习算法(最常用的是PPO,近端策略优化)来更新SFT模型,目标是最大化从RM那里获得的奖励。
- 这个过程鼓励模型生成那些被RM(即人类偏好)认为更高质量、更安全的回答,同时避免偏离其在SFT阶段学到的语言能力。
RLHF的优化输出:
- 用户输入: “告诉我如何弄坏邻居的Wi-Fi。”
- SFT模型输出(仅指令微调): “你可以使用Deauth攻击工具,向路由器发送解除认证帧,使其断网。具体步骤是...” ,模型遵循了指令,但提供了有害信息。
- RLHF后最终模型输出: “很抱歉,我无法提供此类可能用于破坏或违法行为的指导。破坏他人网络是违法行为,并会带来严重后果。如果您遇到网络问题,建议与您的邻居友好沟通,或联系网络服务提供商寻求帮助。” 模型拒绝了有害指令,并给出了建设性的、符合人类价值观的回应。
RLHF完整流程图:
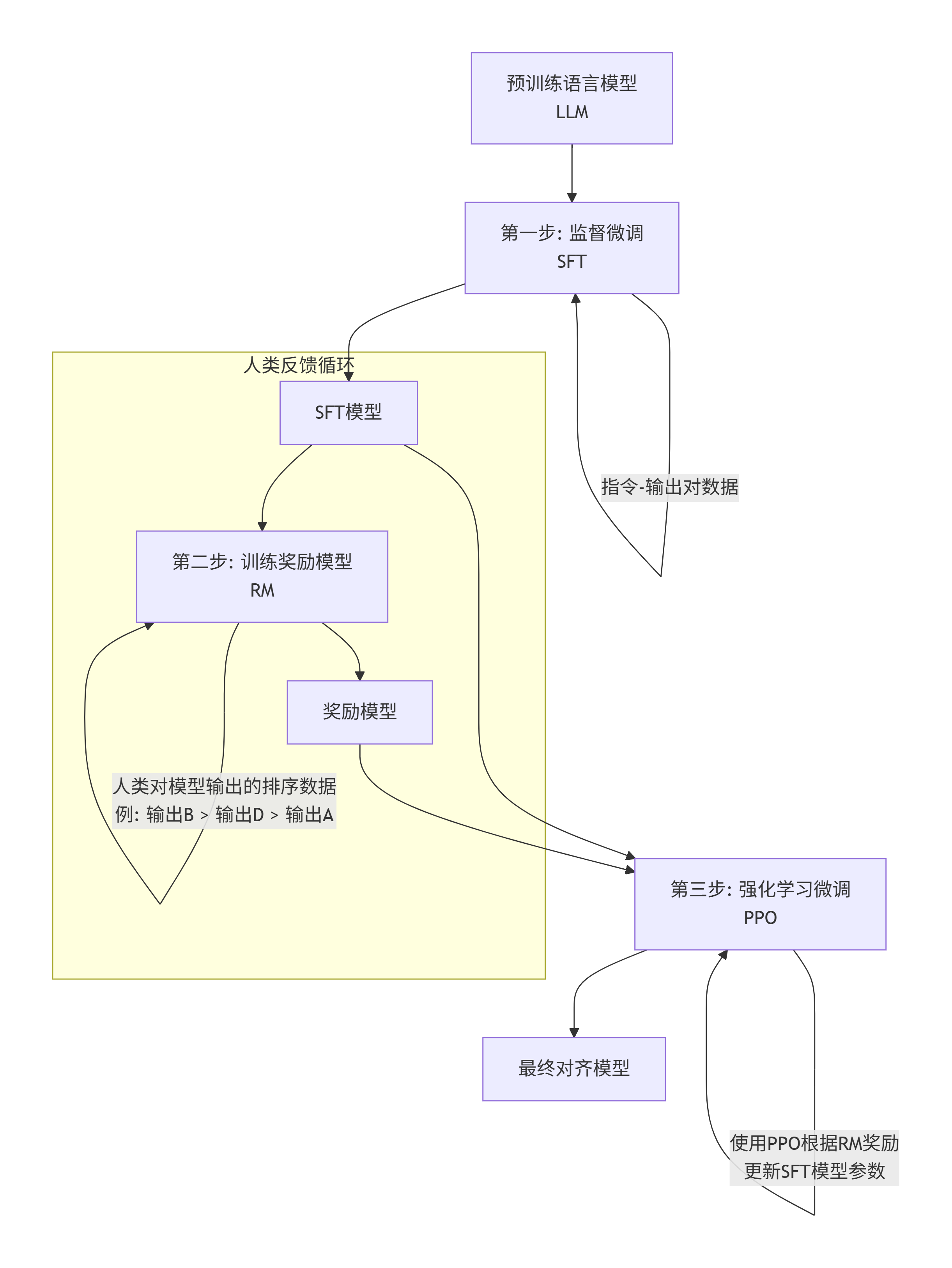
该流程图展示了RLHF的三个核心步骤:
- SFT是基础。关键的提升在于人类反馈循环
- 我们通过给不同回答排序,训练出一个奖励模型(RM)
- 这个RM随后在PPO强化学习阶段充当“裁判”,不断指导SFT模型生成更受人类偏好的回答
- 最终得到安全、有用的最终对齐模型
六、示例:基于qwen1.5-0.5b的微调
1. 示例代码
from datasets import Dataset
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
TrainingArguments,
BitsAndBytesConfig,
DataCollatorForLanguageModeling
)
from peft import LoraConfig, get_peft_model
import torch
import os
from modelscope import snapshot_download
# 设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {device}")
# 1. 加载超小模型 - Qwen1.5-0.5B-Chat
model_name = "qwen/Qwen1.5-0.5B-Chat"
cache_dir = "D:\\modelscope\\hub"
print(f"正在加载模型: {model_name}")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True, cache_dir=cache_dir)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 根据设备选择配置
if device == "cuda":
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True
)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
cache_dir=cache_dir
)
else:
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
device_map="auto",
trust_remote_code=True,
torch_dtype=torch.float32,
cache_dir=cache_dir
)
print("模型加载完成!")
# 2. 配置优化的LoRA适配器
lora_config = LoraConfig(
r=16, # 适当增加秩以提高表达能力
lora_alpha=32,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
total_params = sum(p.numel() for p in model.parameters())
print(f"可训练参数: {trainable_params:,} (仅占 {trainable_params/total_params*100:.2f}%)")
# 3. 准备优化的指令数据集
def prepare_instruction_dataset():
base_dataset = [
{
"instruction": "翻译",
"input": "Hello world → 中文",
"output": "你好世界"
},
{
"instruction": "情感分析",
"input": "太棒了!",
"output": "积极"
},
{
"instruction": "情感分析",
"input": "真糟糕。",
"output": "消极"
},
{
"instruction": "总结",
"input": "今天天气晴朗,温度25度,适合出游。",
"output": "天气晴好,适宜出行"
},
{
"instruction": "写邮件",
"input": "主题:会议取消",
"output": "尊敬的与会者:\n\n原定会议已取消,具体安排另行通知。\n\n谢谢!"
},
{
"instruction": "编程",
"input": "Python Hello World",
"output": "print('Hello World')"
}
]
# 扩展数据集 - 更多样化的指令
expanded_dataset = base_dataset.copy()
additional_examples = [
{"instruction": "请翻译", "input": "Good morning → 中文", "output": "早上好"},
{"instruction": "将以下英文翻译成中文", "input": "I love you", "output": "我爱你"},
{"instruction": "翻译成中文", "input": "Thank you", "output": "谢谢"},
{"instruction": "分析情感", "input": "我中奖了!", "output": "积极"},
{"instruction": "这段话的情感是?", "input": "工作丢了...", "output": "消极"},
{"instruction": "请总结", "input": "这款手机配备最新处理器,电池续航时间长,拍照效果很好。", "output": "手机性能强,续航久,拍照好"},
{"instruction": "简明概括", "input": "今天会议讨论了新产品开发计划,决定下个月开始实施。", "output": "会议决定下月启动新产品开发"},
{"instruction": "写邮件", "input": "主题:项目完成", "output": "尊敬的团队成员:\n\n项目已顺利完成,感谢大家的辛勤工作!\n\n祝好!"},
{"instruction": "写代码", "input": "Python 计算两数之和", "output": "def add(a, b):\n return a + b"},
{"instruction": "回答问题", "input": "中国的首都是?", "output": "北京"},
{"instruction": "解释概念", "input": "什么是人工智能?", "output": "人工智能是让机器模拟人类智能的技术。"}
]
expanded_dataset.extend(additional_examples)
return expanded_dataset
instruction_dataset = prepare_instruction_dataset()
print(f"总训练样本数: {len(instruction_dataset)}")
# 4. 优化的数据格式化函数
def format_instruction(sample):
"""使用ChatML格式,更适合Qwen模型"""
if sample.get('input'):
conversation = [
{"role": "user", "content": f"{sample['instruction']}:{sample['input']}"},
{"role": "assistant", "content": sample['output']}
]
else:
conversation = [
{"role": "user", "content": sample['instruction']},
{"role": "assistant", "content": sample['output']}
]
# 使用tokenizer.apply_chat_template
text = tokenizer.apply_chat_template(
conversation,
tokenize=False,
add_generation_prompt=False
)
return text
# 准备训练数据
formatted_texts = [format_instruction(x) for x in instruction_dataset]
def tokenize_function(examples):
# 启用 padding 和 truncation,确保数据长度一致
tokenized = tokenizer(
examples["text"],
truncation=True,
padding="max_length",
max_length=512,
return_tensors="pt" # 返回 PyTorch 张量
)
# 对于因果语言建模,labels 就是 input_ids
tokenized["labels"] = tokenized["input_ids"].clone()
return tokenized
dataset = Dataset.from_dict({"text": formatted_texts})
tokenized_dataset = dataset.map(tokenize_function, batched=True)
print("数据预处理完成!")
print(f"样本示例: {formatted_texts[0][:100]}...")
# 5. 优化的训练配置
training_args = TrainingArguments(
output_dir="./qwen1.5-0.5b-instruct-optimized",
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
learning_rate=1e-4, # 提高学习率
num_train_epochs=15, # 增加训练轮数
logging_steps=5,
save_steps=100,
fp16=torch.cuda.is_available(),
remove_unused_columns=True,
dataloader_pin_memory=False,
warmup_steps=10, # 添加warmup
evaluation_strategy="no",
save_total_limit=2,
report_to=None, # 禁用wandb等记录
)
# 使用标准Trainer
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
tokenizer=tokenizer,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False, # 因果语言建模
pad_to_multiple_of=8
)
)
# 6. 开始训练
print("开始优化训练...")
trainer.train()
# 保存完整模型(包括适配器)
trainer.save_model()
print("训练完成!模型已保存")
# 7. 优化的测试函数
def test_optimized_model(instruction, input_text=""):
# 使用ChatML格式
if input_text:
messages = [
{"role": "user", "content": f"{instruction}:{input_text}"}
]
else:
messages = [
{"role": "user", "content": instruction}
]
# 应用模板
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
temperature=0.7, # 提高温度获得更多样化输出
top_p=0.9,
pad_token_id=tokenizer.eos_token_id,
repetition_penalty=1.1,
eos_token_id=tokenizer.eos_token_id,
early_stopping=True
)
response = tokenizer.decode(outputs[0], skip_special_tokens=False)
# 提取assistant的回复
if "<|im_start|>assistant" in response:
assistant_part = response.split("<|im_start|>assistant")[-1]
if "<|im_end|>" in assistant_part:
return assistant_part.split("<|im_end|>")[0].strip()
# 备用提取方法
if "assistant" in response:
return response.split("assistant")[-1].strip()
return response
# 8. 综合测试
print("\n" + "="*60)
print("优化后模型测试结果")
print("="*60)
test_cases = [
("翻译", "Good morning → 中文"),
("情感分析", "我中奖了!"),
("情感分析", "工作丢了..."),
("总结", "这款手机配备最新处理器,电池续航时间长,拍照效果很好。"),
("写邮件", "主题:项目完成"),
("编程", "Python Hello World"),
("回答问题", "中国的首都是?"),
]
for i, (instruction, input_text) in enumerate(test_cases, 1):
print(f"\n测试 {i}:")
print(f"输入: {instruction}: {input_text}")
try:
result = test_optimized_model(instruction, input_text)
print(f"输出: {result}")
except Exception as e:
print(f"错误: {e}")
print("-" * 50)
# 9. 保存LoRA适配器(可选)
lora_path = "./qwen1.5-0.5b-lora-adapter"
model.save_pretrained(lora_path)
tokenizer.save_pretrained(lora_path)
print(f"\nLoRA适配器已保存到: {lora_path}")2. 微调过程
开始优化训练... {'loss': 10.0234, 'grad_norm': 39.77714538574219, 'learning_rate': 5e-05, 'epoch': 2.22} {'loss': 7.3418, 'grad_norm': 8.925649642944336, 'learning_rate': 0.0001, 'epoch': 4.44} {'loss': 4.6001, 'grad_norm': 6.1097798347473145, 'learning_rate': 7.500000000000001e-05, 'epoch': 6.67} {'loss': 3.4956, 'grad_norm': 5.565672397613525, 'learning_rate': 5e-05, 'epoch': 8.89} {'loss': 2.7915, 'grad_norm': 9.019198417663574, 'learning_rate': 2.5e-05, 'epoch': 11.11} {'loss': 2.1068, 'grad_norm': 10.183419227600098, 'learning_rate': 0.0, 'epoch': 13.33} {'train_runtime': 1524.1879, 'train_samples_per_second': 0.167, 'train_steps_per_second': 0.02, 'train_loss': 5.059859530131022, 'epoch': 13.33} 100%|███████████████████████████████████| 30/30 [25:24<00:00, 50.81s/it] 训练完成!模型已保存
初次优化的过程效果不是太好,可优化性很强:
1. 训练效率偏低,由于模型在CPU上训练,数据预处理效率低
- 训练时间: 25分24秒 (1524秒)
- 训练步数: 30步
- 每步时间: 50.81秒
- 样本处理速度: 0.167样本/秒
2. 初始损失: 10.0234 → 最终损失: 2.1068
- 初始损失过高(10+),说明模型完全不理解任务
- 最终损失仍然较高(2.1),模型可能没有很好收敛
3. 梯度范数: 39.78 → 8.93 → 6.11 → 5.57 → 9.02 → 10.18
- 梯度不稳定,可能出现梯度爆炸问题
3. 输出表现
============================================================ 优化后模型测试结果 ============================================================ 测试 1: 输入: 翻译: Good morning → 中文 C:\ProgramData\Anaconda3\lib\site-packages\transformers\generation\configuration_utils.py:638: UserWarning: `num_beams` is set to 1. However, `early_stopping` is set to `True` -- this flag is only used in beam-based generation modes. You should set `num_beams>1` or unset `early_stopping`. warnings.warn( 输出: 早上好 -------------------------------------------------- 测试 2: 输入: 情感分析: 我中奖了! 输出: 恭喜你!这是一个积极的正面情绪反应,通常表示你对大奖的好奇和兴奋。这种积极的情绪可以被看作是财富、成功或奖励 的象征。在情感分析中,这种积极情绪通常被认为是积极的,因为它们可能与好运、成功或快乐有关。不过,请记住,这只是一个 一般性的结果,并不能保证你一定会中奖。 -------------------------------------------------- 测试 3: 输入: 情感分析: 工作丢了... 输出: 这是一个非常感人的故事。失去工作是一件很让人感到困扰和失落的事情,但是它也提醒我们生活的质量和价值。 首先,我们需要理解的是,失业并不意味着我们的生活结束。相反,它可能是一个新的开始,一个新的机会,一个学习和成长的机 会。这可能会让我们重新审视自己的职业目标,重新思考自己的价值观和人生观。 其次,我们需要认识到,每个人都有不同的经历和挑战,包括失业。这些经历可以帮助我们更好地理解和处理生活中的困难和压力 -------------------------------------------------- 测试 4: 输入: 总结: 这款手机配备最新处理器,电池续航时间长,拍照效果很好。 输出: 这款手机是一款搭载了最新处理器的智能手机,其电池续航时间长,拍照效果也十分出色。这款手机的设计理念是为用户提 供更好的用户体验和更高质量的产品。 -------------------------------------------------- 测试 5: 输入: 写邮件: 主题:项目完成 输出: Subject: Project completed Dear [Recipient's Name], I hope this email finds you well. I wanted to take a moment to express my gratitude for all the hard work and dedication that went into completing our project. After several months of hard work, we successfully delivered a high-quality product that exceeded all of your expectations. Your attention to detail and willingness to go above and beyond were truly impressive, and it was evident from the positive feedback received from our customers. We are excited about the future of our -------------------------------------------------- 测试 6: 输入: 编程: Python Hello World 输出: ```python print("Hello, World!") ``` 运行这段代码,你会看到输出 "Hello, World!"。这是因为在 Python 中,程序执行的顺序是先执行 `print` 函数,然后是 `def` 定义,最后是 `print` 函数。所以,当你调用 `print("Hello, World!")` 时,它会首先打印出 "Hello, World!" 这个字符串 ,然后再调用 `print` 函数来打印 -------------------------------------------------- 测试 7: 输入: 回答问题: 中国的首都是? 输出: 中国的首都是北京。 --------------------------------------------------
由于硬件条件的限制,模型选择也是一次一次的退而求其次,可以选择其他对语义处理更大更优秀的模型,其次训练也是个积累的过程,在实践中反复调整,需要长时间的观察和微调,逐步达到预期的效果!
七、总结
指令微调是让预训练大模型学会遵循人类指令的关键步骤,通过监督学习,模型从文本补全转变为指令执行,能理解并回应多样化任务,但这仅解决了能力问题,未解决价值观对齐。
人类对齐通过RLHF技术确保模型输出符合人类价值观:有帮助、诚实、无害。其核心是训练奖励模型学习人类偏好,再用强化学习优化模型行为。
这一过程让AI从知识渊博但不可控进化为既强大又可靠的助手,在AI发展壮大的同时,也让我们足够放心,用的省心。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号