大模型应用:概率驱动:大模型文字预测的核心机制与理论基础.5
原创
大模型应用:概率驱动:大模型文字预测的核心机制与理论基础.5
原创
未闻花名
发布于 2026-02-02 07:51:01
发布于 2026-02-02 07:51:01
一. 大模型文字预测
1. 基本原理
文字预测,就是让模型根据已经出现的文字,预测下一个最可能出现的字(或词)。比如,输入“今天天气很”,模型可能预测出“好”、“热”、“冷”等。
2. 模型的文字表示
计算机不能直接理解文字,所以需要将文字转换成数字。这个过程叫做编码。
- 步骤1:构建词汇表
- 模型会有一个很大的词汇表,包含成千上万个常见的字、词或子词(比如“天气”是一个词,“很”是一个词)。
- 步骤2:将文字转换成数字ID
- 每个词在词汇表中都有一个唯一的数字ID。例如:
- “今天” -> 1001
- “天气” -> 2002
- “很” -> 3003
- 步骤3:将数字ID转换成向量
- 模型会有一个嵌入层,将每个数字ID转换成一个固定长度的向量(一串数字)。这个向量可以理解为这个词的“含义”的数学表示。

3. 预测下一个字
模型接收到输入文字的向量序列后,通过复杂的计算(主要是Transformer结构),最终输出一个对于下一个字的概率分布。
- 例子:输入“今天天气很”,模型会计算词汇表中每个词作为下一个词的概率。
- “好” -> 0.8
- “热” -> 0.15
- “冷” -> 0.05
- ...其他词的概率很小。
然后,模型可以选择概率最大的“好”作为预测结果。
核心比喻:超级词语接龙
- 游戏规则:你说出一个开头,比如 “今天天气”,你的朋友需要接下一个最可能的词。
- 普通人的做法:可能会接“真好”、“不错”、“晴朗”。
- 大模型的做法:它的大脑里有一个“概率字典”。当它看到“今天天气”时,它会瞬间计算出成千上万个词跟在后面的可能性:
- “真好” -> 35% 的概率
- “不错” -> 25% 的概率
- “晴朗” -> 15% 的概率
- “像” -> 5% 的概率
- “苹果” -> 0.0001% 的概率 (几乎不可能)
- 模型的输出:模型会选择概率最高的那个词,比如“真好”。于是,句子变成了“今天天气真好”。
这就是文字预测最最基本的核心:根据已有的文字,计算下一个最可能出现的文字是什么。大模型不是一个真正的大脑,而是一个极其复杂的数学网络。我们可以把它想象成一个巨大的、经过特殊训练的自动补全机器。
- 模型的输入:你给它的所有文字(我们称之为 “上下文” 或 “提示”)。
- 模型的处理:通过网络中数百亿个参数,可以理解为神经元的连接强度和知识储存点,来理解你输入文字的含义、语法和常识。
- 模型的输出:一个包含了所有可能的下一个词的概率分布列表。
4. 核心Transformer架构
Transformer是大模型的核心,它使用了一种叫做自注意力机制的技术,可以让模型在处理一个词的时候,同时考虑到上下文中的所有词,从而更好地理解语境,就像我们读一句话时,不会只看前一个词,而是会联系整句话来理解每个词的含义。
二、文字预测的学习过程
一个模型不是生来就会预测的。它需要经历一个“上学”的过程,这个过程叫做 “训练”。
1. 学习资料:海量的文本数据
模型的课本就是互联网上无数的网页、书籍、文章、代码等等。它通过阅读这些资料,学习人类语言是如何组织的。
2. 学习目标:猜猜下一个词
模型的学习过程就是通过大量文本数据,不断练习“预测下一个词”的任务。
- 训练数据:从互联网、书籍等来源收集的海量文本。
- 训练方法:随机从文本中截取一段,让模型根据前面的词预测下一个词,然后根据模型的预测是否正确来调整模型参数。
3. 学习方式:填空题海战术
训练过程就像一个做不完的“填空题”考试。具体步骤如下:
- 1. 出题:从训练文本中随机截取一句话,比如:“机器学习是人工智能的一个重要分支。”
- 2. 遮盖:把这句话的最后一个词(或随机一个词)遮住,变成:“机器学习是人工智能的一个重要____。”
- 3. 答题:让模型根据前面的文字,去预测这个空白处应该填什么。模型会给出它的答案,比如“领域”、“方向”、“部分”等,每个都有一个概率。
- 4. 批改:系统会拿出被遮盖的真实答案“分支”,与模型的预测进行对比。
- 5. 纠错与调整:
- 如果模型预测“分支”的概率很高,系统就会表扬它,并微调内部参数,强化这个连接。
- 如果模型预测错了(比如它认为“苹果”的概率很高),系统就会告诉它错了,并微调内部参数,削弱这个错误的连接。
4. 量变引起质变
这个“出题-答题-批改-调整”的过程,会以惊人的速度重复数万亿次。模型处理的文本量相当于把整个图书馆的书读上成千上万遍。
通过这个过程,模型逐渐学会了:
- 语法:什么词性后面该接什么词性。
- 语义:词与词之间的含义关联(比如“苹果”更可能和“吃”、“手机”联系在一起,而不是和“天气”)。
- 常识:“水在0摄氏度会结冰”、“先有鸡还是先有蛋”是一个哲学问题。
- 逻辑:一定的上下文会导向一定的结论。
最终,它从一个文盲变成了一个博学的语言大师。
5. 损失函数:衡量预测的差距
模型会用一个叫做损失函数的指标来衡量预测值与真实值的差距。比如,如果真实的下一个词是“好”,而模型给“好”的概率是0.8,那么损失就较小;如果概率是0.1,损失就较大。
6. 反向传播与梯度下降:调整模型参数
模型通过反向传播算法计算损失函数对每个参数的梯度,即参数需要调整的方向和大小,然后用梯度下降法更新参数,使得下次预测更准确。
比喻:就像学生做练习题,对答案后发现自己错了,然后分析错在哪里,调整自己的解题思路,下次争取做对。
7. 预训练与微调
- 预训练:模型首先在大量通用文本上学习,获得通用的语言能力(比如语法、常识等)。这个过程非常耗时,需要巨大的计算资源。
- 微调:在预训练的基础上,用特定领域的数据(如医学、法律)或针对特定任务(如问答、对话)对模型进行进一步训练,使其更擅长特定任务。
三、文字预测的应用
如果大模型只是一个词一个词地预测,能有什么大用处,事实上,这正是所有强大AI应用的基础,应用的范围涵盖广泛,以智能对话、内容创作以及信息检索总结等这些和我们息息相关的业务领域为起点正蓬勃发展。
1. 智能对话(如deepseek)
你问:“中国的首都是哪里?”,模型内部是这样预测的:
- 上下文:“中国的首都是哪里?” -> 最可能的下一个词是 [北京]
- “北京” -> 后面最可能接的词是 [是]
- “是” -> 后面最可能接的词是 [中国]
- “中国” -> 后面最可能接的词是 [的]
- ...如此循环,直到模型预测到一个表示句子结束的特殊符号。
- 最终输出:“中国的首都是北京。”
模型并不是从数据库里调取了答案,而是根据它学到的知识,一个字一个字地写出了这个最可能的回答。
2. 内容创作(写文章或代码)
你给一个开头:“假如我有一双翅膀,”,模型开始预测:
- “我将” -> (概率高)
- “飞向” -> (概率高)
- “蓝天” -> (概率高)
- ... 它利用学到的关于“翅膀”、“飞翔”、“自由”的文本模式,创作出一篇完整的散文或诗歌。
写代码也是同理,它根据前面的代码结构,预测下一行最可能出现的代码是什么。
3. 信息检索与总结
你让它总结一篇长文,模型会先阅读全文作为上下文,然后开始生成预测。第一个最可能生成的词往往就是全文的核心主题词,然后围绕这个主题,生成概括性的句子,它不是在提取句子,而是在重述知识。
4. 逻辑推理与解决问题
即使是复杂的数学题或逻辑推理,也可以被转化为一个文本预测任务。
- 题目:“小明有5个苹果,吃了2个,又买了3个,现在有几个?”
- 模型在大量文本中学过类似的算术模式,它会预测出最符合数学逻辑的答案序列:“5 - 2 = 3”, “3 + 3 = 6”,所以最终输出“6个”。
四、文字预测流程
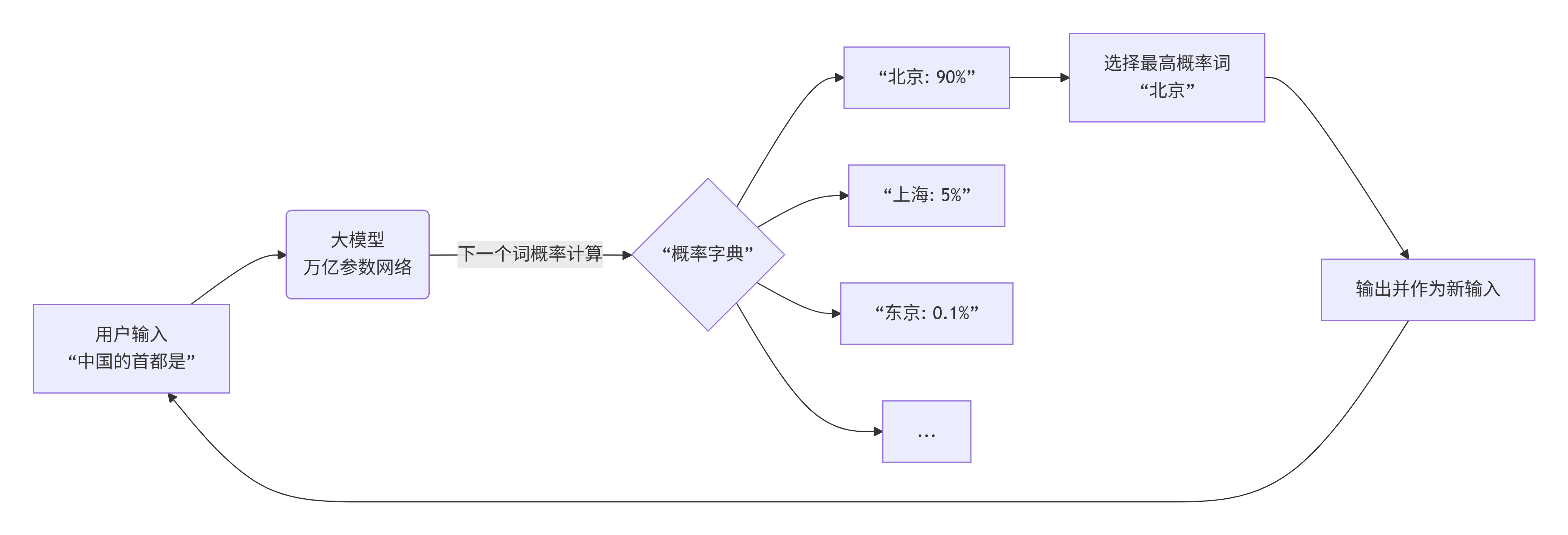
流程说明:
- 1. 接受外部输入的文字。
- 2. 模将其作为上下文,动用全部学识,即参数,计算下一个词的概率。
- 3. 从概率分布中选出最可能的词。
- 4. 将这个新词加到你原来的输入后面,形成新的、更长的上下文。
- 5. 重复步骤2-4,像一个循环的流水线,直到生成完整的回答。
五、简单的文本预测示例
示例以简化的方式展示文本预测的基本原理,我们将使用PyTorch框架展示一个非常简单的例子:基于字符级的中文文本预测,。
执行步骤:
- 1. 准备一个简单的中文文本数据集。
- 2. 构建一个简单的循环神经网络(RNN)模型。
- 3. 训练模型进行文本预测。
- 4. 使用模型进行文本生成。
注意:为了简化,我们使用字符级模型,即模型根据前面的字符预测下一个字符。
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 1. 准备一个简单的中文数据集
text = "深度学习是人工智能的一个重要分支,它让计算机能够从数据中学习。"
chars = list(set(text)) # 获取所有不重复的字符
print("语料库中的字符:", ''.join(chars))
# 创建字符到索引的映射
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for i, ch in enumerate(chars)}
vocab_size = len(chars)
print(f"词汇表大小: {vocab_size}")
# 2. 创建训练数据 - 构建(输入, 目标)对
seq_length = 5 # 输入序列长度
inputs = []
targets = []
for i in range(len(text) - seq_length):
input_seq = text[i:i + seq_length]
target_char = text[i + seq_length]
inputs.append([char_to_idx[ch] for ch in input_seq])
targets.append(char_to_idx[target_char])
# 转换为PyTorch张量
X = torch.tensor(inputs, dtype=torch.long)
y = torch.tensor(targets, dtype=torch.long)
print(f"\n输入序列示例: '{text[:seq_length]}' -> 目标: '{text[seq_length]}'")
print(f"X的形状: {X.shape}") # (样本数, 序列长度)
print(f"y的形状: {y.shape}") # (样本数,)
# 3. 定义一个简单的模型
class SimpleCharModel(nn.Module):
def __init__(self, vocab_size, embedding_dim=32, hidden_dim=64):
super(SimpleCharModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.rnn = nn.RNN(embedding_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
# x形状: (batch_size, seq_length)
embedded = self.embedding(x) # (batch_size, seq_length, embedding_dim)
_, hidden = self.rnn(embedded) # hidden: (1, batch_size, hidden_dim)
output = self.fc(hidden.squeeze(0)) # (batch_size, vocab_size)
return output
# 初始化模型
model = SimpleCharModel(vocab_size)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
print(f"\n模型结构:")
print(model)
# 4. 训练模型
print("\n开始训练...")
epochs = 200
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
# 前向传播
outputs = model(X)
loss = criterion(outputs, y)
# 反向传播
loss.backward()
optimizer.step()
if (epoch + 1) % 50 == 0:
print(f'轮次 [{epoch+1}/{epochs}], 损失: {loss.item():.4f}')
# 5. 使用模型进行预测
def predict_next_chars(model, start_string, num_chars=10):
model.eval()
chars = [ch for ch in start_string]
print(f"\n预测结果:")
print(start_string, end="")
for _ in range(num_chars):
# 准备输入
input_seq = [char_to_idx[ch] for ch in chars[-seq_length:]]
input_tensor = torch.tensor([input_seq], dtype=torch.long)
# 预测下一个字符
with torch.no_grad():
output = model(input_tensor)
probabilities = torch.softmax(output, dim=1)
predicted_idx = torch.argmax(probabilities, dim=1).item()
# 获取预测的字符
predicted_char = idx_to_char[predicted_idx]
print(predicted_char, end="")
chars.append(predicted_char)
print()
# 测试预测
predict_next_chars(model, "深度学", 10)
predict_next_chars(model, "人工智", 10)
def visualize_prediction(model, input_string):
model.eval()
# 准备输入
input_seq = [char_to_idx[ch] for ch in input_string]
input_tensor = torch.tensor([input_seq], dtype=torch.long)
# 获取预测概率
with torch.no_grad():
output = model(input_tensor)
probabilities = torch.softmax(output, dim=1).squeeze().numpy()
# 可视化
chars = list(char_to_idx.keys())
plt.figure(figsize=(12, 4))
bars = plt.bar(range(len(chars)), probabilities)
plt.xticks(range(len(chars)), chars, rotation=45)
plt.title(f'输入 "{input_string}" 后下一个字符的概率分布')
plt.ylabel('概率')
# 标出概率最高的几个字符
top_indices = probabilities.argsort()[-3:][::-1]
for i, idx in enumerate(top_indices):
plt.annotate(f'{probabilities[idx]:.3f}',
xy=(idx, probabilities[idx]),
xytext=(idx, probabilities[idx] + 0.02),
ha='center', fontsize=10,
arrowprops=dict(arrowstyle='->', color='red'))
print(f'候选 {i+1}: "{chars[idx]}" - 概率: {probabilities[idx]:.3f}')
plt.tight_layout()
plt.show()
# 可视化一些预测
visualize_prediction(model, "深度学")
visualize_prediction(model, "人工智")
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(0), :]
class SimpleTransformerModel(nn.Module):
def __init__(self, vocab_size, d_model=64, nhead=4, num_layers=2):
super(SimpleTransformerModel, self).__init__()
self.d_model = d_model
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoder = PositionalEncoding(d_model)
encoder_layers = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward=128)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers)
self.fc = nn.Linear(d_model, vocab_size)
def forward(self, x):
# x形状: (seq_length, batch_size)
embedded = self.embedding(x) * math.sqrt(self.d_model)
embedded = self.pos_encoder(embedded)
output = self.transformer_encoder(embedded)
output = self.fc(output[-1, :, :]) # 只取最后一个时间步
return output
# 使用Transformer模型重新训练
print("\n=== 使用Transformer模型 ===")
transformer_model = SimpleTransformerModel(vocab_size)
optimizer = optim.Adam(transformer_model.parameters(), lr=0.005)
# 调整数据格式以适应Transformer
X_transformer = X.transpose(0, 1) # Transformer需要(seq_len, batch_size)
# 简单训练几轮
for epoch in range(100):
transformer_model.train()
optimizer.zero_grad()
outputs = transformer_model(X_transformer)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
if (epoch + 1) % 25 == 0:
print(f'轮次 [{epoch+1}/100], 损失: {loss.item():.4f}')
# 测试Transformer模型
def transformer_predict(model, start_string, num_chars=10):
model.eval()
chars = [ch for ch in start_string]
print(f"\nTransformer预测结果:")
print(start_string, end="")
for _ in range(num_chars):
input_seq = [char_to_idx[ch] for ch in chars[-seq_length:]]
input_tensor = torch.tensor([input_seq], dtype=torch.long).transpose(0, 1)
with torch.no_grad():
output = model(input_tensor)
probabilities = torch.softmax(output, dim=1)
predicted_idx = torch.argmax(probabilities, dim=1).item()
predicted_char = idx_to_char[predicted_idx]
print(predicted_char, end="")
chars.append(predicted_char)
print()
transformer_predict(transformer_model, "深度学", 10)代码说明:
- 1. 数据准备: 我们将中文文本分解成字符,并为每个字符创建数字索引。
- 2. 构建训练对: 对于文本"深度学习...",我们会创建如:
- 输入:"深度学" → 目标:"习"
- 输入:"度学习" → 目标:"是"
- 3. 模型结构: 使用嵌入层 + RNN + 全连接层,输出每个字符的概率。
- 4. 训练: 通过最小化损失函数来调整模型参数。
- 5. 预测: 给定起始字符串,让模型逐个预测后面的字符。
输出结果:
语料库中的字符: 工度是计它分能个据够习支,人。要中让学机深的一算重从智数 词汇表大小: 28 输入序列示例: '深度学习是' -> 目标: '人' X的形状: torch.Size([26, 5]) y的形状: torch.Size([26]) 模型结构: SimpleCharModel( (embedding): Embedding(28, 32) (rnn): RNN(32, 64, batch_first=True) (fc): Linear(in_features=64, out_features=28, bias=True) ) 开始训练... 轮次 [50/200], 损失: 0.0007 轮次 [100/200], 损失: 0.0005 轮次 [150/200], 损失: 0.0004 轮次 [200/200], 损失: 0.0003 预测结果: 深度学习。人工智能的一个重 预测结果: 人工智能的一个重要分支,它 候选 1: "习" - 概率: 0.890 候选 2: "能" - 概率: 0.037 候选 3: "支" - 概率: 0.023 候选 1: "能" - 概率: 1.000 候选 2: "要" - 概率: 0.000 候选 3: "重" - 概率: 0.000 === 使用Transformer模型 === 轮次 [25/100], 损失: 0.0255 轮次 [50/100], 损失: 0.0054 轮次 [75/100], 损失: 0.0029 轮次 [100/100], 损失: 0.0025 Transformer预测结果: 深度学习。够从数据中学习。
图示结果:
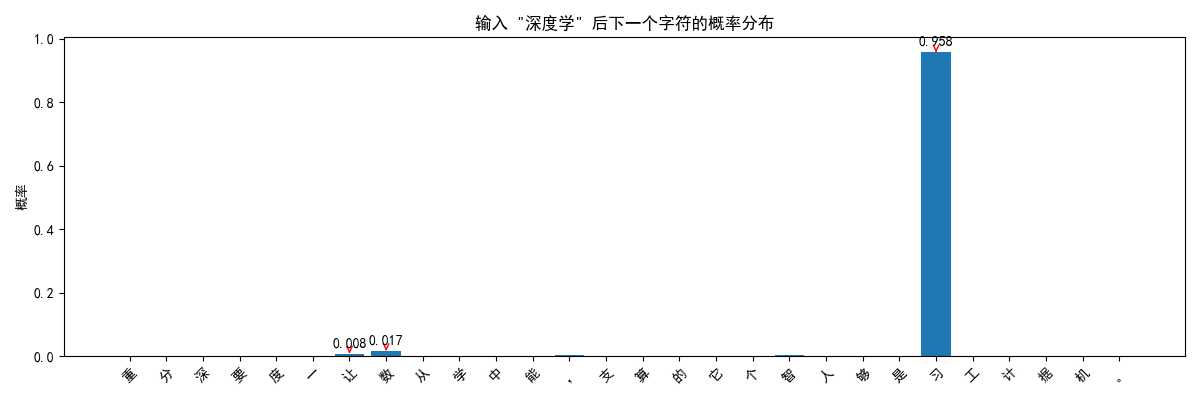
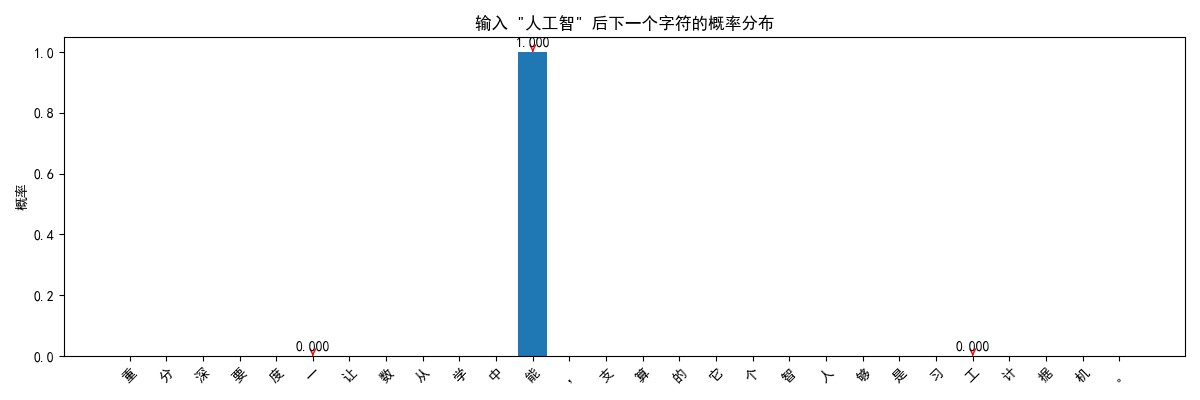
- 模型看到"深度学"后,认为下一个字符是"习"的概率最高
- 但也可能给出其他候选,体现了概率预测的本质
六、总结
大模型并不是在思考,而是在做基于经验的模式匹配,它就像一个吸收了人类所有公开文本精华的概率精灵,我们给它一个开头,它就能帮我们把这个开头之后最可能出现的内容给写出来。它的神奇之处,不在于它有多像人,而在于它通过纯粹的数字计算,捕捉并再现了人类语言和知识中蕴含的深邃规律。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号