为什么 InnoDB 中的反向索引扫描更慢?


作者:马金友, 一名给 MySQL 找 bug 的初级 DBA。
爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
本文约 1500 字,预计阅读需要 5 分钟。

如果你注意到在 MySQL 中 ORDER BY DESC 查询比 ORDER BY ASC 稍微慢一些,不用担心 —— 这是已知且符合预期的行为。
这是因为 InnoDB 的设计和优化是为了进行正向扫描,它使用单向链表结构来组织页面上的记录。
因此,向前移动(ASC)的时间复杂度是 O(1),而向后移动(DESC)的时间复杂度是 O(n)。
这篇博客将从存储层面的角度演示这两种算法。
1. InnoDB 页面结构
1.1 单向链表
InnoDB 使用单向链表来组织 record。 每个页面有两个虚拟 record:infimum 和 supremum,它们分别作为链表的头部和尾部。 一旦数据页面包含用户记录,链表就会按逻辑顺序显示。
infimum -> rec1 -> rec2 -> rec3 -> rec4 -> ... -> supremum
1.2 REC_NEXT
每条记录在记录头中额外占用 2 个字节(byte)来存储指向下一条记录的偏移量。
constexpr uint32_t REC_NEXT = 2;
constexpr uint32_t REC_NEXT_MASK = 0xFFFFUL;
例如,infimum 记录的 REC_NEXT 值是 0x00, 0x0d。
/** The page infimum and supremum of an empty page in ROW_FORMAT=COMPACT */
static const byte infimum_supremum_compact[] = {
/* the infimum record */
0x01 /*n_owned=1*/, 0x00, 0x02 /* heap_no=0, REC_STATUS_INFIMUM */, 0x00,
0x0d /* pointer to supremum */, 'i', 'n', 'f', 'i', 'm', 'u', 'm', 0,
/* the supremum record */
0x01 /*n_owned=1*/, 0x00, 0x0b /* heap_no=1, REC_STATUS_SUPREMUM */, 0x00,
0x00 /* end of record list */, 's', 'u', 'p', 'r', 'e', 'm', 'u', 'm'};
通过 infimum 记录偏移 0x000d,可以得到 supremum 记录。
In [1]: infimum_supremum_compact = [
...: 0x01 , 0x00, 0x02 , 0x00,
...: 0x0d , 'i', 'n', 'f', 'i', 'm', 'u', 'm', 0,
...: 0x01 , 0x00, 0x0b, 0x00,
...: 0x00, 's', 'u', 'p', 'r', 'e', 'm', 'u', 'm'
...: ]
...:
In [2]: infimum_supremum_compact[5]
Out[2]: 'i'
In [3]: infimum_supremum_compact[5+0x000d]
Out[3]: 's'
1.3 页面目录 (Page Directory)
由于单向链表的数据结构,InnoDB 必须扫描整个链表才能找到一条 record,这效率很低。
InnoDB 在每个数据页的末尾维护一个动态数组(page directory),数组中的每个元素(槽/slot)存储一条record的位置。
/* We define a slot in the page directory as two bytes */
constexpr uint32_t PAGE_DIR_SLOT_SIZE = 2;
它不是存储每条记录的地址,而是每个槽指向该槽所管理记录中的最后一条记录。一个槽通常管理 4 到 8 条记录。
/* The maximum and minimum number of records owned by a directory slot. The
number may drop below the minimum in the first and the last slot in the
directory. */
constexpr uint32_t PAGE_DIR_SLOT_MAX_N_OWNED = 8;
constexpr uint32_t PAGE_DIR_SLOT_MIN_N_OWNED = 4;
第一个槽总是指向 infimum,最后一个槽总是指向 supremum。
1.4 N_OWNED
每条记录在记录头中占用 4 个位(bit)来存储 N_OWNED。
constexpr uint32_t REC_NEW_N_OWNED = 5; /* This is single byte bit-field */
constexpr uint32_t REC_N_OWNED_MASK = 0xFUL;
如果记录是槽中的最后一条记录,它的值就是该槽拥有的记录数。否则,值为 0。
2. 示例
下图展示了数据页面的布局
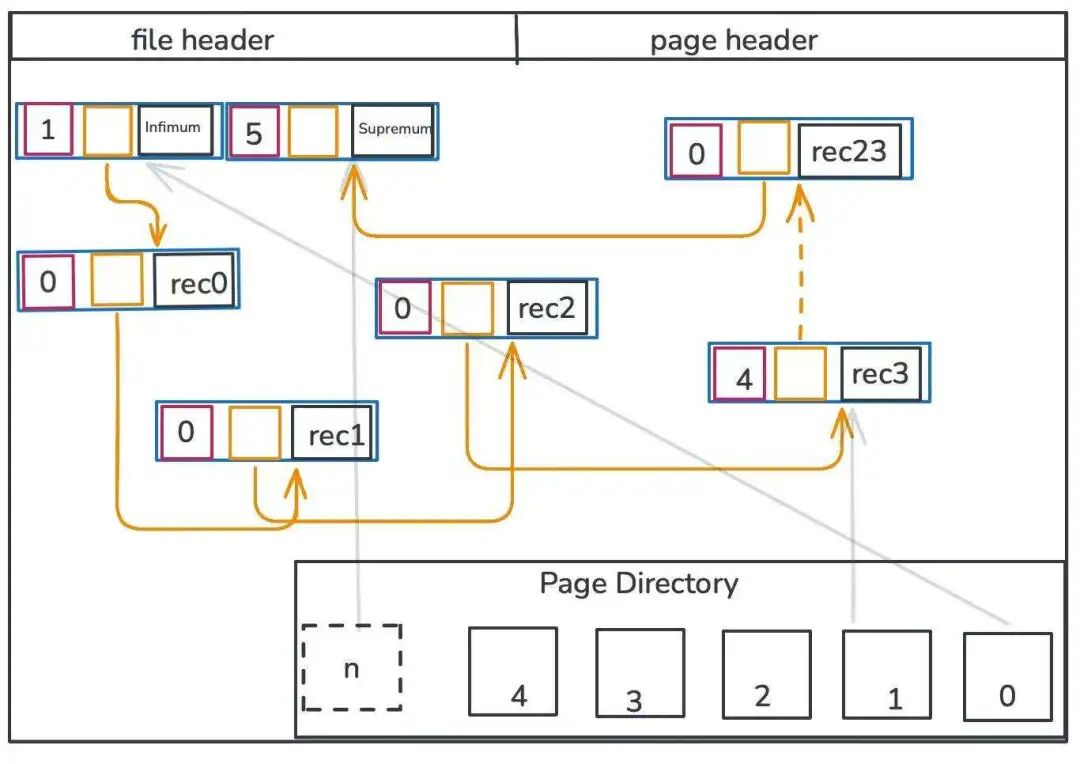
innodb_page_example
innodb_page_example
- 橙色箭头连接了从
rec0到rec23的 24 条用户记录。 - 灰色箭头指向槽所管理的最后一条记录。 槽
0指向infimum,它包含 1 条记录。 槽n指向supremum,它包含 5 条记录。 槽1指向rec3,它包含 4 条记录。
3. 算法
我们将使用以下逻辑 InnoDB 页面布局来理解这两种扫描算法。
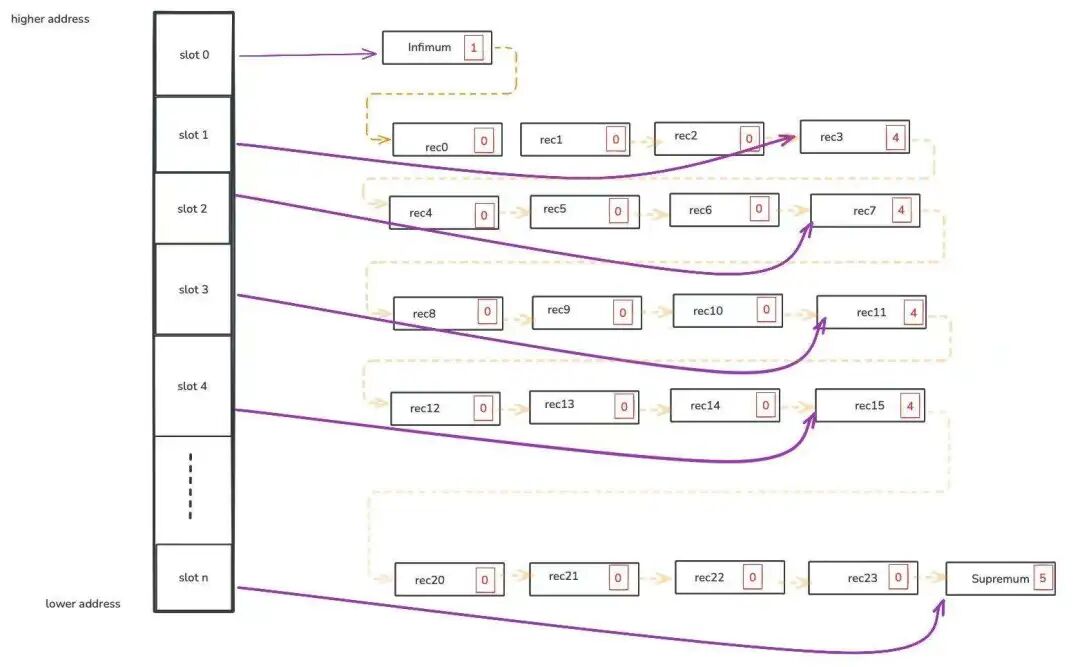
innodb_page_logic
innodb_page_logic
3.1 正向扫描 (Forward Scan)
从 rec10 找到页面上的下一条记录很容易。
- 读取
REC_NEXT偏移量
field_value = mach_read_from_2(rec - REC_NEXT);
- 获取下一条记录的位置
return (ut_align_offset(rec + field_value, UNIV_PAGE_SIZE));
3.2 反向扫描 (Backward Scan)
从rec10找到页面上的前一条记录会更困难。
3.2.1 查找哪个槽管理了当前记录 (page_dir_find_owner_slot)
① 扫描从当前记录开始的所有记录,直到 n_owned 不为 0。
while (rec_get_n_owned_new(r) == 0) {
r = rec_get_next_ptr_const(r, true);
...
}
它会检查 rec10,然后是 rec11。
[rec10] --> [rec11]
^
[rec10] --> [rec11]
^
因为 rec11 的 n_owned 是 4,所以会跳转到步骤 1.2。
② 检查所有槽,直到找到指向步骤 1.1 中记录 r 的槽。
rec_offs_bytes = mach_encode_2(r - page);
while (UNIV_LIKELY(*(uint16 *)slot != rec_offs_bytes)) {
....
slot += PAGE_DIR_SLOT_SIZE;
}
return (((ulint)(first_slot - slot)) / PAGE_DIR_SLOT_SIZE);
它会从最后一个槽(slot n)开始扫描到 slot 0。
[n]...[4][3][2][1][0]
^
因为 slot n 指向 supremum(不是 rec11),所以会检查下一个槽(slot 4)。
[n]...[4][3][2][1][0]
^
因为 slot 4 指向 rec15(不是 rec11),所以会检查下一个槽(slot 3)。
[n]...[4][3][2][1][0]
^
因为 slot 3 指向 rec11,所以会返回 3。
3.2.2 扫描当前slot group 以查找前一条记录
① 跳转到前一个槽。 因为 slot 3 只持有slot group的最后一条记录,它无法扫描 slot 3 中的所有记录。
slot = page_dir_get_nth_slot(page, slot_no - 1);
rec2 = page_dir_slot_get_rec(slt);
幸运的是,它可以利用前一个槽组的最后一条记录来扫描当前槽组中的所有record。
通过检查 slot 2,它会找到 rec7。
② 扫描槽组中的所有记录所有 record 匹配当前 record。
while (rec != rec2) {
prev_rec = rec2;
rec2 = page_rec_get_next_low(rec2, true);
}
return (prev_rec);
它会检查 rec7、rec8、rec9,然后是 rec10,直到找到 rec10 的前一条 record,即 rec9。
[rec7] --> [rec8] --> [rec9] --> [rec10] --> [rec11]
^
[rec7] --> [rec8] --> [rec9] --> [rec10] --> [rec11]
^
[rec7] --> [rec8] --> [rec9] --> [rec10] --> [rec11]
^
[rec7] --> [rec8] --> [rec9] --> [rec10] --> [rec11]
^
4. 时间复杂度
正向扫描是 O(1),但反向扫描是 O(n),其中 n 是页面目录中的槽数。
5. 基准测试
5.1 正向扫描 (Forward scan)
mysql > select k from sbtest1 order by k asc limit 9999999, 1;
+---------+
| k |
+---------+
| 8670945 |
+---------+
1 row in set (1.41 sec)
mysql > desc select k from sbtest1 order by k asc limit 9999999, 1\G
*************************** 1.row ***************************
id: 1
select_type: SIMPLE
table: sbtest1
partitions: NULL
type: index
possible_keys: NULL
key: k_1
key_len: 4
ref: NULL
rows: 9864216
filtered: 100.00
Extra: Using index
1 row inset, 1 warning (0.00 sec)
5.2 反向扫描 (Backward scan)
mysql > select k from sbtest1 order by k desc limit 9999999, 1;
+---------+
| k |
+---------+
| 1184614 |
+---------+
1 row in set (2.01 sec)
mysql > desc select k from sbtest1 order by k desc limit 9999999, 1\G
*************************** 1.row ***************************
id: 1
select_type: SIMPLE
table: sbtest1
partitions: NULL
type: index
possible_keys: NULL
key: k_1
key_len: 4
ref: NULL
rows: 9864216
filtered: 100.00
Extra: Backward index scan; Using index
1 row in set, 1 warning (0.00 sec)
本文关键字:#MySQL #InnoDB #索引扫描
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号