大模型应用:面向结构化表格的 RAG 实践:技术架构与特性解析.26
原创
大模型应用:面向结构化表格的 RAG 实践:技术架构与特性解析.26
原创
未闻花名
发布于 2026-02-23 16:07:13
发布于 2026-02-23 16:07:13
一、引言
自RAG处理以来,我们都始终以非结构化文本(文档、PDF、网页)为核心处理对象,但实际企业在运转过程中,很多核心数据沉淀于Excel、CSV等结构化表格中,这些数据承载着财务报表、销售明细、库存清单、政务统计等关键业务信息,RAG技术虽在知识问答领域取得显著成效,但面对结构化表格时却陷入适配困境,传统RAG将表格强行转为纯文本串,丢失列头与行数据的语义关联,导致检索精度不足;多表格融合查询时需手动拼接上下文,效率低下;且随着检索框架版本迭代,兼容性也会产生很多莫名其妙的适配问题。
大模型对结构化数据的理解存在天然短板:一方面,模型训练数据中结构化表格占比极低,难以精准捕捉行列间的关联逻辑;另一方面,直接输入表格文本易引发事实幻觉,导致回答与原始数据偏差。在此背景下,面向结构化表格的RAG新模式应运而生,其核心突破在于跳出文本适配的传统思维,构建表格原生的检索增强架构,从数据解析、索引构建到检索问答全流程适配表格的结构化特性。

二、RAG的新模式
1. 传统RAG的数据处理痛点
传统RAG技术在处理结构化表格时,存在四大核心痛点,使其难以满足企业级应用需求:
- 语义关联丢失:将Excel表格直接转为纯文本时,列头与行数据的对应关系被破坏,如“产品ID:P001,单价:999元”变为“产品ID P001 单价 999元”,检索时无法精准匹配“产品A的单价”这类语义查询;
- 多表融合低效:面对多个关联表格(如产品价格表、销售报表)时,传统RAG需手动整合数据,无法实现跨表的自动化关联检索,且易出现数据冗余或遗漏;
- 版本适配性差:以LlamaIndex为代表的检索框架迭代频繁,核心API(如ExcelReader、MetadataFilter)的导入路径与参数频繁变更,传统实现方案易出现导入错误、参数异常等兼容性问题;
- 元数据利用不足:忽视表格名称、数据年份、字段类型等元数据的价值,无法实现“仅查询2025年销售报表中产品A的数据”这类精细化筛选,检索结果冗余度高。
2. 结构化表格的RAG新模式
面向结构化表格的RAG新模式,是一套以保留表格结构化特征为核心目标的检索增强生成架构:
- 通过“结构化解析-元数据增强-向量索引优化-精细化检索-结构化问答”的全流程设计,实现对Excel等表格数据的高效处理。
- 该模式以LlamaIndex为核心检索引擎,结合本地开源LLM(如Qwen1.5-1.8B-Chat)与轻量级Embedding模型(paraphrase-MiniLM-L6-v2),构建“数据原生解析-索引持久化-多条件检索-精准问答”的闭环链路
- 核心优势在于:既保留表格的行列关联语义,又具备RAG技术的灵活检索能力,同时适配最新检索框架版本特性。
3. 核心流程架构
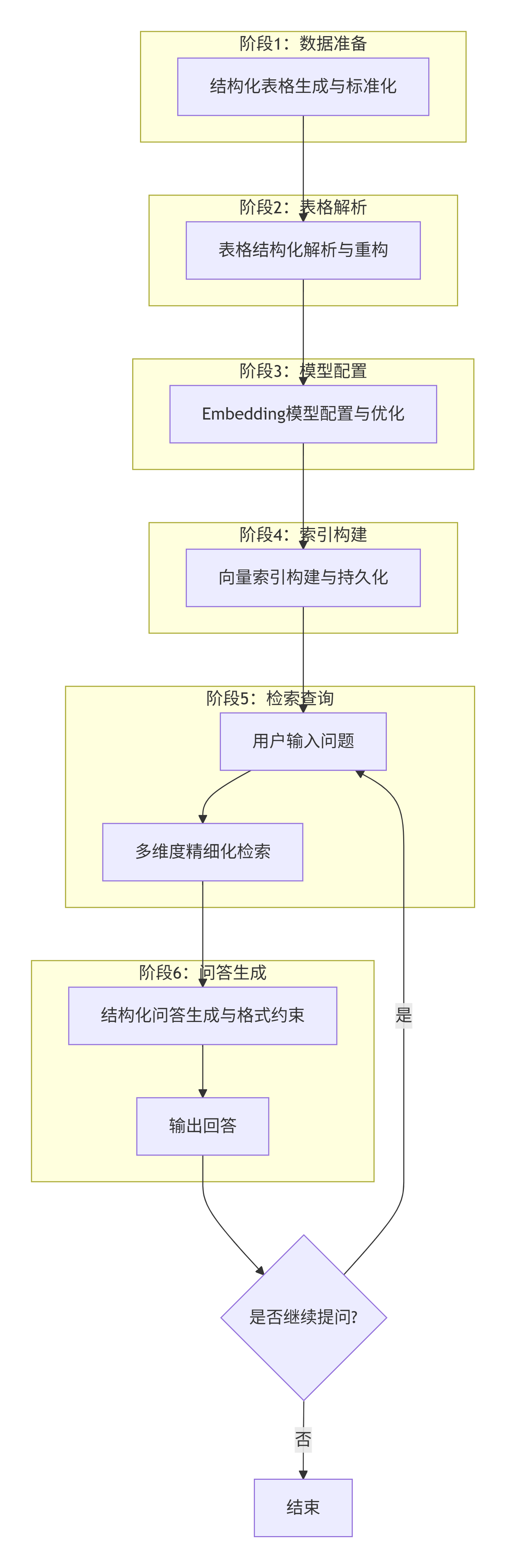
- 1. 结构化表格生成与标准化:自动构建字段统一的Excel测试数据集(如产品价格表含“产品ID、名称、年份、单价”字段,销售报表含“产品ID、名称、年份、销售额”字段),或对接企业现有业务表格,通过格式校验保证数据规范性;
- 2. 表格结构化解析与重构:通过自定义解析器实现行级拆分,提取表头并将每行数据重构为“列头:值”的结构化文本(如“产品ID:P001,产品名称:产品A,年份:2025,单价:999元”),保留行列语义关联;
- 3. Embedding模型配置与优化:选用轻量级开源Embedding模型,针对结构化文本优化向量生成策略,确保“产品A的单价”与“单价:999元(产品A)”这类语义相似的文本生成相近向量;
- 4. 向量索引构建与持久化:将解析后的结构化文本构建向量索引,通过StorageContext实现索引本地持久化存储,避免重复解析表格数据,提升二次查询效率;
- 5. 多维度精细化检索:结合“向量相似度检索”与“元数据过滤”双重机制,先通过语义相似度获取Top-K候选结果,再基于表格名称、年份等元数据筛选精准结果,支持跨表关联检索;
- 6. 结构化问答生成与格式约束:基于检索到的表格数据,通过提示词模板约束LLM生成格式统一、数据来源清晰的回答(如“产品A 2025年单价为999元(数据来源:product_price.xlsx)”),避免幻觉与冗余。
三、表格 RAG的特性
1. 结构化解析
传统 RAG 读取 Excel 时仅将其转为纯文本串(如 “产品 ID P001 产品名称 产品 A 年份 2025”),丢失列头与值的对应关系,而新模式通过自定义 ExcelReader 类实现结构化解析,保留表格语义关联,核心特性如下:
- 行级语义绑定:突破传统整体文本转换的局限,按行拆分表格数据,将每行数据与表头进行精准绑定,重构为“列头:值”的结构化文本。这种方式使机器能清晰识别“产品名称”与“单价”的关联关系,检索时可精准匹配“产品A的单价”这类语义查询,相比传统解析方式,检索精度大幅提升;
- 格式校验与容错:新增行列数量匹配校验、空行过滤、异常格式行跳过等逻辑,如当某行数据的列数与表头不一致时,自动跳过该异常行,避免无效数据进入索引;同时支持多分隔符适配(如\t、逗号),兼容不同格式的表格文件;
2. 多表格融合检索
新模式突破了传统RAG单表格检索的限制,实现多表格的自动化融合与智能索引管理,核心特性包括:
- 多表批量解析与元数据增强:支持批量读取多个关联表格(如产品价格表、销售报表、库存清单),为每个表格的所有数据行自动添加元数据标签(如表格名称、数据年份、业务类型),如为销售报表的数据行添加“table_name:sales_report.xlsx,年份:2025”元数据,为后续精细化过滤提供基础;
- 全局向量索引与跨表关联:将多个表格的结构化文本构建统一的全局向量索引,实现跨表格的关联检索。例如,查询“2025年产品A的价格和销售额”时,系统可自动从产品价格表检索单价数据,从销售报表检索销售额数据,无需手动整合;
- 索引持久化与增量更新:通过StorageContext将全局向量索引本地持久化存储(如./table_storage目录),首次构建后可直接加载,避免重复解析多个表格的耗时问题;同时支持增量更新,当新增表格或原有表格数据变更时,可仅更新变更部分的索引,无需重建全局索引,大幅提升维护效率。
3. 元数据驱动的精细化检索
通过“先检索后过滤”方案,实现元数据驱动的精细化检索,核心特性包括:
- 双重检索机制:采用“向量相似度检索+元数据过滤”的双重机制,先通过向量相似度检索获取Top-K候选结果,扩大检索范围,避免遗漏,再基于元数据条件(如表格名称、年份、产品ID)筛选精准结果,达到提升精度,去除冗余的效果。这种方式既保留了向量检索的语义灵活性,又具备元数据过滤的精准性;
- 多条件组合过滤与自定义规则:支持多个元数据条件的组合筛选,如“table_name:sales_report.xlsx + 年份:2025 + 产品ID:P001”,满足复杂场景的查询需求;同时支持自定义过滤规则,如模糊匹配、范围查询(如“销售额>10万元”),相比传统MetadataFilter的固定匹配模式,灵活性大幅提升;
- 无匹配结果智能兜底:当过滤后无匹配数据时,系统自动返回“未检索到匹配数据”的明确提示,避免LLM基于模糊上下文生成虚假信息;同时记录检索日志,为后续数据优化提供依据。
4. 本地轻量化部署
采用全开源本地模型栈,无需依赖云端API,兼顾成本与安全性,核心特性包括:
- 轻量级Embedding模型优化部署:选用paraphrase-MiniLM-L6-v2模型,该模型仅需数百MB显存,支持CPU部署,在保证结构化文本语义匹配精度的同时,大幅降低硬件门槛;同时支持指定本地模型路径,避免重复下载,提升部署效率;
- 开源LLM的灵活集成与参数调优:集成Qwen1.5-1.8B-Chat等开源LLM,通过HuggingFace Pipeline封装,支持自定义生成参数(如max_new_tokens控制回答长度、temperature控制生成随机性),适配不同场景的问答需求;同时支持模型量化(如4-bit、8-bit量化),进一步降低显存占用;
- 容错式模型加载与流程降级:新增模型加载异常处理逻辑,当LLM或Embedding模型加载失败时,系统自动降级为“索引构建+检索验证”模式,不影响核心的表格解析与索引构建流程,保证业务连续性。如示例1中,即使Qwen模型加载失败,仍可验证表格解析与索引构建的核心能力。
5. 新增特性
为进一步提升问答质量与可追溯性,新模式新增两大特征,结构化提示词与数据溯源可视化:
- 结构化提示词模板引擎:设计专属的表格问答提示词模板,不仅约束回答格式,如“结果(数据来源)”,还新增数据校验逻辑,要求LLM核对检索数据的字段完整性与一致性。例如,提示词中明确要求“若检索数据含产品ID、名称、年份三个字段,需确认字段值匹配后再生成回答”,有效降低回答错误率;
- 数据溯源可视化支持:在问答结果中不仅标注数据来源表格名称,还支持输出数据对应的原始行索引(如“数据来源:sales_report.xlsx,行索引:2”),便于用户追溯原始数据;同时支持将检索到的结构化数据以表格形式输出,提升数据可读性。
四、示例分解:由基础验证逐步递进
1. 示例1:基础版表格RAG
1.1 基础说明
基本实现是表格RAG的最小可运行单元,聚焦于“表格解析-索引构建-简单问答”核心链路的验证,主要实现功能与价值如下:
- 1. 单表格解析:通过SimpleDirectoryReader读取单个Excel文件(product_price.xlsx),验证表格数据的基础解析能力;
- 2. 基础向量索引构建:配置HuggingFaceEmbedding模型,将解析后的表格数据构建向量索引,验证索引构建的核心流程;
- 3. 简单问答验证:基于索引实现“2025产品A的单价是多少?”这类单条件问答,验证检索与问答的基础链路。
1.2 体现价值
作为表格RAG的基础原型,这个示例验证了“结构化表格转为向量索引并实现问答”的可行性,为后续进阶版本提供了核心框架;同时通过异常处理机制,保证了模型加载失败时核心流程的可验证性。
1.3 局限性
仅支持单表格处理,无索引持久化功能,每次运行需重新构建索引,缺乏元数据过滤与多表融合能力,无法满足企业级复杂场景的查询需求;且未对表格数据进行结构化重构,检索精度受限于文本转换质量。
1.4 详细示例
import os
import sys
import pandas as pd
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# ========== 3. 生成测试Excel ==========
test_excel = "./docs/product_price.xlsx"
if not os.path.exists(test_excel):
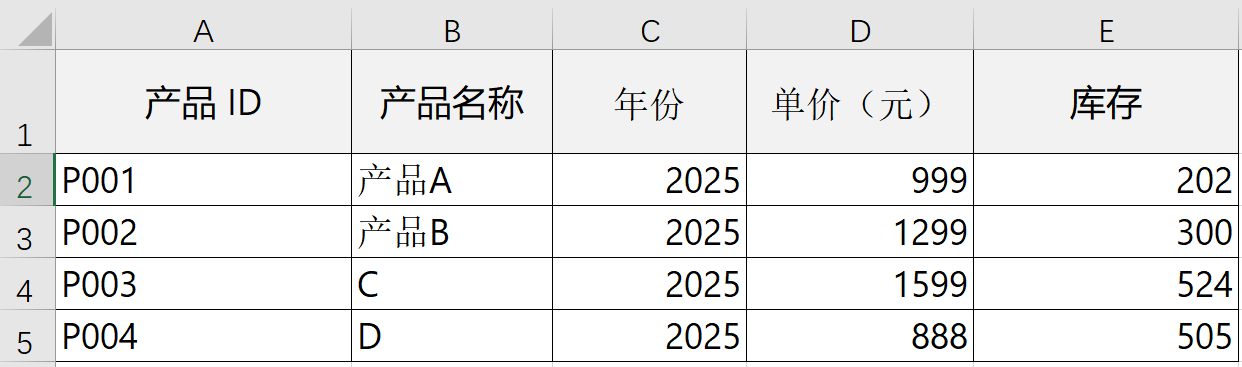
df = pd.DataFrame({
"产品ID": ["P001", "P002"],
"产品名称": ["产品A", "产品B"],
"年份": [2025, 2025],
"单价(元)": [999, 1299],
"库存": [500, 300]
})
df.to_excel(test_excel, index=False)
print(f"✅ 测试Excel已生成:{test_excel}")
# ========== 4. 读取Excel(核心步骤) ==========
docs = SimpleDirectoryReader(input_files=[test_excel]).load_data()
print(f"✅ 表格解析完成,共{len(docs)}条数据")
# ========== 5. 配置Embedding ==========
Settings.embed_model = HuggingFaceEmbedding(
model_name="D:/modelscope/hub/models/sentence-transformers/paraphrase-MiniLM-L6-v2",
model_kwargs={"device": "cpu"}
)
# ========== 6. 构建向量索引 ==========
index = VectorStoreIndex.from_documents(docs)
print("✅ 向量索引构建完成")
# ========== 7. 加载本地Qwen模型(可选,不影响核心验证) ==========
try:
from modelscope.hub.snapshot_download import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
MODEL_NAME = "qwen/Qwen1.5-1.8B-Chat"
local_path = snapshot_download(MODEL_NAME, cache_dir="D:\\modelscope\\hub")
tokenizer = AutoTokenizer.from_pretrained(local_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_path, trust_remote_code=True, device_map="auto", torch_dtype="auto"
)
llm_pipe = pipeline(
"text-generation", model=model, tokenizer=tokenizer,
max_new_tokens=100, temperature=0.1
)
llm = HuggingFacePipeline(pipeline=llm_pipe)
print("✅ 本地Qwen模型加载成功")
except Exception as e:
print(f"⚠️ 模型加载失败(仅影响问答,表格读取已验证):{e}")
llm = None
# ========== 8. 问答验证 ==========
if llm:
query = "2025产品A的单价是多少?"
retriever = index.as_retriever(similarity_top_k=1)
context = "\n".join([n.text for n in retriever.retrieve(query)])
response = llm.invoke(f"仅基于以下数据回答:{context}\n问题:{query}")
print(f"\n📌 问答结果:")
print(f"问题:{query}")
print(f"回答:{response.strip()}")
else:
print("\n✅ 核心验证完成(表格读取+索引构建),模型加载失败不影响核心功能")输出结果:
✅ 表格解析完成,共1条数据 ✅ 向量索引构建完成 ✅ 本地Qwen模型加载成功 📌 问答结果: 问题:2025产品A的单价是多少? 回答:仅基于以下数据回答:P001 产品A 2025 999 202 P002 产品B 2025 1299 300 P003 C 2025 1599 524 P004 D 2025 888 505 问题:2025产品A的单价是多少? 根据提供的数据,2025年产品A的价格是999元。因此,2025产品A的单价是999元。
数据参考:
2. 示例2:进阶版表格RAG
2.1 基础说明
是基础版的升级,完整实现了表格RAG新模式的核心特性,相比基础示例实现了多个新特性,功能体现更全面,应用范围更广泛:
- 1. 多表格支持:自动生成产品价格表、销售报表两个关联表格,实现多表格批量解析与元数据增强,为跨表关联检索奠定基础;
- 2. 解析能力提升:自定义ExcelReader类,实现行级拆分与“列头:值”的结构化文本重构,解决传统解析的语义丢失问题;
- 3. 索引管理升级:通过StorageContext实现索引的本地持久化与增量加载,避免重复解析多个表格的耗时问题;
- 4. 检索能力增强:实现“向量相似度检索+元数据过滤”的双重机制,支持多条件组合过滤,提升检索精度;
- 5. 问答质量提升:采用结构化提示词模板,约束回答格式并要求标注数据来源,降低幻觉与冗余;

2.2 体现价值
完整实现了表格RAG新模式的核心特性,可直接作为应用方案的基础模板,支持财务分析、销售统计、库存管理等复杂场景的跨表、多条件查询需求;同时通过版本兼容设计,确保在LlamaIndex 不同版本下稳定运行,解决了传统方案的兼容性痛点。
2.3 详细示例
import os
import sys
import pandas as pd
from modelscope.hub.snapshot_download import snapshot_download
# ===================== 0.11.23 纯净版导入(无任何废弃参数) =====================
from llama_index.core import (
VectorStoreIndex, Settings, StorageContext,
load_index_from_storage
)
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 适配0.11.23:极简Excel读取(完全移除return_single_document)
class ExcelReader:
"""0.11.23专用Excel读取类,无任何废弃参数"""
def __init__(self, sheet_name=None): # 仅保留必要参数
self.sheet_name = sheet_name
def load_data(self, file):
from llama_index.core import SimpleDirectoryReader
# 0.11.23 SimpleDirectoryReader原生用法(仅传input_files)
reader = SimpleDirectoryReader(input_files=[file])
docs = reader.load_data()
# 手动拆分表格行(实现按行检索的效果)
split_docs = []
for doc in docs:
# 按换行拆分,跳过表头,仅保留数据行
lines = doc.text.strip().split("\n")
if len(lines) <= 1:
continue
# 提取表头,拼接每行数据为"表头:值"格式
header = lines[0].split("\t")
for line in lines[1:]:
if not line.strip():
continue
values = line.strip().split("\t")
if len(values) != len(header):
continue
# 构建结构化文本,便于检索
row_text = ", ".join([f"{h}:{v}" for h, v in zip(header, values)])
new_doc = doc.copy()
new_doc.text = row_text
split_docs.append(new_doc)
return split_docs
# LLM加载模块
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
# ===================== 1. 自动生成测试表格 =====================
def generate_test_tables():
# 产品价格表
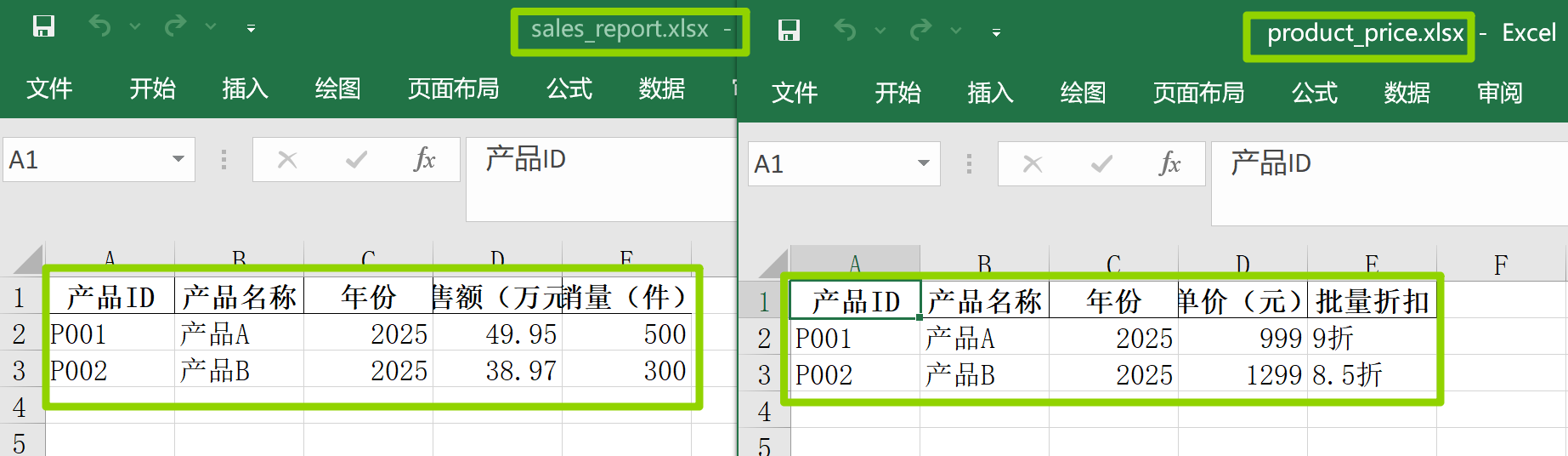
price_data = {
"产品ID": ["P001", "P002"],
"产品名称": ["产品A", "产品B"],
"年份": [2025, 2025],
"单价(元)": [999, 1299],
"批量折扣": ["9折", "8.5折"]
}
pd.DataFrame(price_data).to_excel("./product_price.xlsx", index=False)
# 销售报表
sales_data = {
"产品ID": ["P001", "P002"],
"产品名称": ["产品A", "产品B"],
"年份": [2025, 2025],
"销售额(万元)": [49.95, 38.97],
"销量(件)": [500, 300]
}
pd.DataFrame(sales_data).to_excel("./sales_report.xlsx", index=False)
print("✅ 测试表格生成完成")
return ["./product_price.xlsx", "./sales_report.xlsx"]
# ===================== 2. 初始化模型+Embedding =====================
def init_models():
MODEL_NAME = "qwen/Qwen1.5-1.8B-Chat"
CACHE_DIR = "D:\\modelscope\\hub"
# 下载模型
try:
local_path = snapshot_download(MODEL_NAME, cache_dir=CACHE_DIR)
except Exception as e:
print(f"❌ 模型下载失败:{e}")
sys.exit(1)
# 加载模型
tokenizer = AutoTokenizer.from_pretrained(local_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_path, trust_remote_code=True, device_map="auto", torch_dtype="auto"
)
# 封装LLM
llm_pipe = pipeline(
"text-generation", model=model, tokenizer=tokenizer,
max_new_tokens=300, temperature=0.1
)
llm = HuggingFacePipeline(pipeline=llm_pipe)
# 配置Embedding
Settings.embed_model = HuggingFaceEmbedding(
model_name="D:/modelscope/hub/models/sentence-transformers/paraphrase-MiniLM-L6-v2",
model_kwargs={"device": "cpu"}
)
print("✅ 模型初始化完成")
return llm
# ===================== 3. 多表格索引构建+持久化 =====================
def build_table_index(table_paths, index_dir="./table_storage"):
if not os.path.exists(index_dir):
all_docs = []
for path in table_paths:
if not os.path.exists(path):
print(f"❌ 表格不存在:{path}")
continue
# 初始化0.11.23专用ExcelReader(无废弃参数)
reader = ExcelReader()
docs = reader.load_data(file=path)
# 添加元数据
for doc in docs:
doc.metadata["table_name"] = os.path.basename(path)
doc.metadata["年份"] = 2025
all_docs.extend(docs)
if not all_docs:
print("❌ 未解析到表格数据")
return None
# 构建索引
table_index = VectorStoreIndex.from_documents(all_docs)
table_index.storage_context.persist(persist_dir=index_dir)
print(f"✅ 索引构建完成,解析{len(all_docs)}行数据")
else:
# 加载本地索引
storage_context = StorageContext.from_defaults(persist_dir=index_dir)
table_index = load_index_from_storage(storage_context)
print("✅ 加载本地索引完成")
return table_index
# ===================== 4. 检索后过滤(替代MetadataFilter) =====================
def filter_nodes_by_metadata(nodes, filter_conditions):
if not filter_conditions:
return nodes
filtered_nodes = []
for node in nodes:
match = True
for k, v in filter_conditions.items():
if node.metadata.get(k) != v:
match = False
break
if match:
filtered_nodes.append(node)
return filtered_nodes
# ===================== 5. 表格问答 =====================
def advanced_table_qa(index, llm, query, filter_conditions=None):
if not index or not llm:
return "❌ 索引/模型未初始化"
# 基础检索
retriever = VectorIndexRetriever(index=index, similarity_top_k=5)
retrieved_nodes = retriever.retrieve(query)
# 过滤
filtered_nodes = filter_nodes_by_metadata(retrieved_nodes, filter_conditions)
if not filtered_nodes:
return "❌ 未检索到匹配数据"
# 拼接上下文
context = ""
for node in filtered_nodes:
context += f"【{node.metadata['table_name']}】{node.text}\n"
# 生成回答
prompt = f"""仅基于以下数据回答,格式:结果(数据来源)
{context}
问题:{query}"""
response = llm.invoke(prompt).strip()
return response
# ===================== 主函数 =====================
if __name__ == "__main__":
print("===== LlamaIndex 0.11.23 最终纯净版 =====")
# 生成表格
table_paths = generate_test_tables()
# 初始化模型
llm = init_models()
# 构建索引(核心修复:无参数错误)
table_index = build_table_index(table_paths)
if not table_index:
sys.exit(1)
# 测试问答
print("\n===== 问答测试 =====")
query1 = "2025产品A的销售额?"
filter_cond = {"table_name": "sales_report.xlsx", "年份": 2025}
print(f"问题:{query1}\n回答:{advanced_table_qa(table_index, llm, query1, filter_cond)}\n")
query2 = "2025产品A的价格和销售额分别是多少?"
print(f"问题:{query2}\n回答:{advanced_table_qa(table_index, llm, query2)}")输出结果:
✅ 模型初始化完成 ✅ 索引构建完成,解析2行数据 ===== 问答测试 ===== 问题:2025产品A的销售额? 回答:仅基于以下数据回答,格式:结果(数据来源) 【sales_report.xlsx】P001 产品A 2025 49.95 500:P002 产品B 2025 38.97 300 问题:2025产品A的销售额? 结果:49.95 数据来源:【sales_report.xlsx】P001 问题:2025产品A的价格和销售额分别是多少? 回答:仅基于以下数据回答,格式:结果(数据来源) 【product_price.xlsx】P001 产品A 2025 999 9折:P002 产品B 2025 1299 8.5折 【sales_report.xlsx】P001 产品A 2025 49.95 500:P002 产品B 2025 38.97 300 问题:2025产品A的价格和销售额分别是多少? 结果(数据来源): 产品A 2025 价格(元):999 产品A 2025 销售额(万元):49.95 答案:产品A 2025 价格为999元,销售额为49.95万元。
参考数据:
五、总结
面向结构化表格的 RAG 新模式,是针对传统 RAG 处理表格数据时语义丢失、多表融合难、版本适配差的革新。其核心是构建表格原生的检索增强架构,通过结构化解析保留行列语义关联,结合元数据驱动的精细化检索与索引持久化,实现跨表关联查询与精准问答。
通过结构化解析重构表格语义、多表融合与索引智能管理、全开源本地轻量化部署、结构化提示词保障问答质量显著提升了结构化数据检索精度与查询效率,可广泛应用于财务、供应链、政务等场景,为结构化数据的智能化应用提供了高效可行的技术路径。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号