从0开始全面认识高质量数据集建设(7)
原创
从0开始全面认识高质量数据集建设(7)
原创
zhouzhou的奇妙编程
发布于 2026-02-23 21:14:07
发布于 2026-02-23 21:14:07
总结
建设工作一览表
整个项目走下来,我们最后回过头来复盘一下。
一个单位,想做这件事情,最开始肯定是得做好顶层设计,但是有的人可能想说,我们公司那么多年都没做过顶层设计啥的,不也过的好好的吗?但是这里我想说的是,在高质量数据集建设这个事情上不一样。
第一,数据的质量不是天然形成的,而是设计出来的。 过去企业做业务系统,数据是业务的副产品,有就用、没有就算了。但高质量数据集不同,它要求数据具备场景适配性、多模态融合能力与AI可训性,这些特性不可能靠自然积累获得,必须从源头规划数据采集标准、标注规范、质量评估体系。没有顶层设计,各部门各自为战,最后出来的数据格式不统一、标准不一致、质量参差不齐,根本没法用于大模型训练。到实际要训练的时候,又得把这个流程重新走一遍,得不偿失。
第二,合规成本越来越高,事后补救的代价太大。 2025年以来,国家数据局等多部门已构建起从顶层设计到行业细则的多层次政策法规体系。"数据二十条"、《"数据要素×"三年行动计划》等政策对数据来源合法性、隐私保护、跨境流通都有明确要求。如果前期没有做好合规架构设计,后期发现数据无法合规使用,前期投入的采集、清洗、标注成本全部打水漂。这个风险,没有单位能承受。
第三,高质量数据集建设是系统工程,不是单点突破。 根据2025全球数商大会的专家共识,高质量数据集的构建需要"全链路"治理能力,从数据采集、清洗、标注、存储到流通、应用,每个环节都要有统一的标准和流程。这涉及技术架构、组织架构、管理制度多个维度的协同。没有顶层设计,就像盖楼不打地基,建到一半发现承重墙位置不对,推倒重来的成本远高于前期规划。
第四,AI时代的数据治理已进入"深水区"。 2026年的数据治理,正从单点技术优化走向系统性生态构建。高质量数据集提供"燃料",AI提供"引擎",合规提供"轨道",三者缺一不可。企业唯有将三者深度融合,才能在守住安全底线的同时,真正释放数据作为新质生产力的巨大潜能。
所以,回到最开始的问题:以前没做顶层设计也能过日子,那是因为在传统业务模式下,数据只是辅助工具。但在"人工智能+"时代,数据是核心生产要素,高质量数据集是基础设施。基础设施能不能建好,决定了企业未来五到十年的竞争力。这笔账,值得好好算一算。
顶层设计不是纸上谈兵,而是用前期的思考成本,换取后期的执行效率和风险可控。在高质量数据集建设这件事上,想清楚再动手,比动手后再想清楚,要划算得多。
既然顶层设计的重要性已经明确,那么接下来要回答的问题是:顶层设计到底要设计什么?具体怎么落地?
我们前面的几篇,都是在阐述这个事情,这里大家也别嫌啰嗦,我们再重新捋一遍哈~
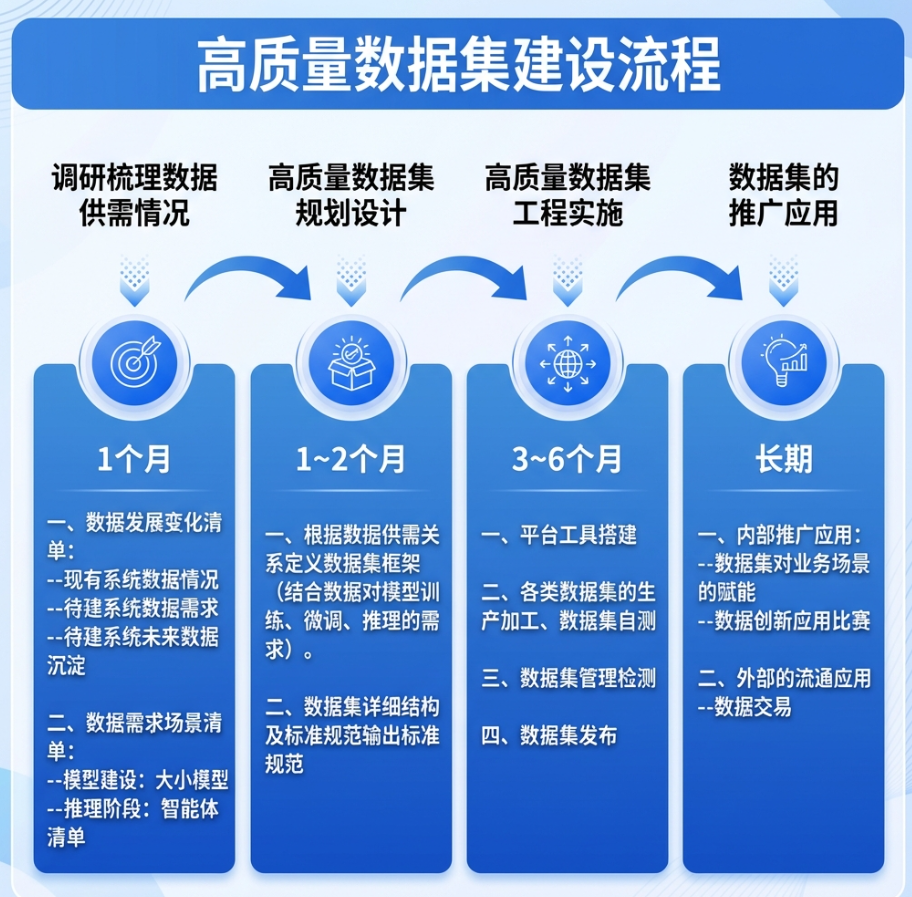
高质量数据集建设时间规划
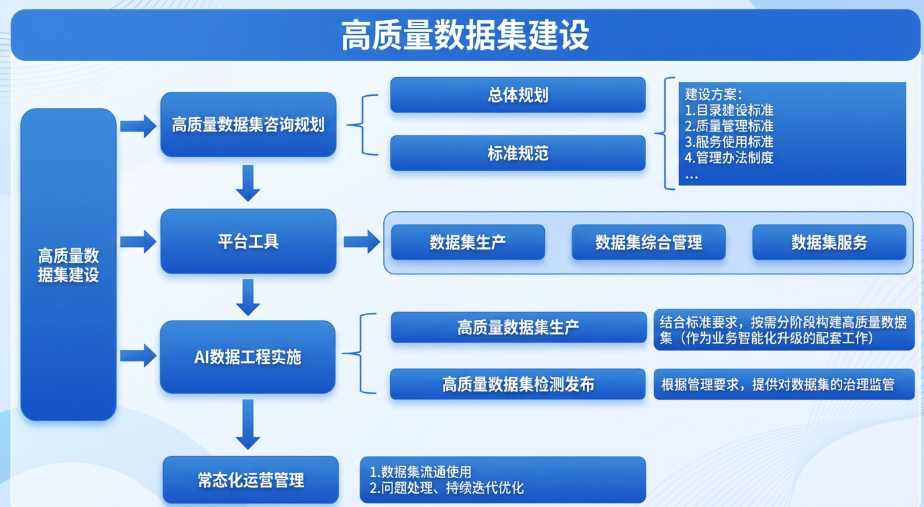
第一,把"做什么"和"怎么做"想清楚
很多人一上来就急着买工具、招人手、采数据,结果干到一半发现方向偏了。我们的做法是,先把咨询规划做扎实。
我们首先回答了三个核心问题:
问题 | 答案 |
|---|---|
为什么要建? | 支撑业务智能化升级,为大模型训练提供高质量"燃料" |
建成什么样? | 形成覆盖核心业务场景、符合国家和行业标准、可复用可流通的数据集资产 |
怎么分阶段? | 按"试点验证→规模扩展→生态开放"三步走,避免一次性投入过大 |
这个规划不是一拍脑袋定的,而是联合业务部门、技术团队、合规法务多方论证的结果。规划文档最后厚达一百多页,但每一页都是真金白银换来的经验。
第二,立好规矩再干活
前面也提到,我们按照国家的标准,依照自己的行业特征和内部要求,也是制定了很多内部规则,大致也就是四类:
- 目录建设标准:统一数据集的分类、命名、元数据描述
- 质量管理标准:定义完整性、准确性、一致性、时效性等质量维度及评估方法
- 服务使用标准:规范数据申请、审批、交付、使用追踪流程
- 管理办法制度:明确责任主体、考核机制、违规处理办法
但是很重要的一点是,标准不是挂在墙上的,是要嵌入到每个工作流程里的。我们把标准做成了检查清单和自动化校验规则,目前仍然还在不断优化改进,不符合标准的数据根本进不了系统。
第三,平台工具支撑,让标准"长"在系统里
标准定得再好,靠人盯人执行是不现实的。必须通过平台工具,把标准固化到系统流程中,让合规成为必选项。
在功能方面,基本需要覆盖以下三大能力:
- 数据集生产工具链
- 数据集综合管理
- 数据集服务接口
第四,从"有数据"到"有好数据"
平台建好了,标准也有了,接下来就是真刀真枪地生产高质量数据集。这一步我们坚持两个原则:
- 按需分阶段构建,不贪大求全
- 检测发布把关,确保"出得去、用得稳"
我们没有一开始就追求全覆盖,而是优先选择3个高价值业务场景作为试点:
试点场景 | 数据类型 | 建设周期 | 产出成果 |
|---|---|---|---|
智能客服 | 对话文本、政策文件 | 2个月 | 300余条标注对话数据 |
安全监管 | 视频流抽帧、风险样本 | 6个月 | 3000余张标注图像 |
风险预测 | 交易记录、行为日志 | 10个月 | 近万条时序数据 |
每个试点完成后都进行复盘,总结经验后再推广到其他场景。这种"小步快跑"的方式,让我们少走了很多弯路。
而对于数据集的质量把关,我们同样极其重视,生产完成后,不是直接发布,而是要经过严格的检测流程的。
第五,常态化运营管理
很多单位的数据集项目,上线之日就是停滞之时,这样往往拖个几年,之前花大价钱建的项目就又烂尾了,所以,我们从现在开始就必须要认识到,高质量数据集是"活"的资产,需要持续运营才能保持价值。
而如何把数据资产盘活呢?我们自己内部做到了以下几点,不一定对哈,但至少现阶段表现还不错,拿出来跟大家交流交流。
1、主动推动数据集流通使用
正如上面提到的,我们几年前刚开始也踩过坑。数据集建好了,往平台上一放,想着业务部门自然会来用,结果半年过去,一查使用日志,80%的数据集调用次数是零。
问题出在哪?业务部门根本不知道有什么、在哪找、怎么用。
后来我们就做了两件事情,成功激发了他们的积极性,第一件事是定期给业务部门和领导群发数据资产简报,主要内容包括本月新增了什么数据集、哪些数据集被高频使用、有哪些单位使用数据做成了一些应用案例等等;第二件事是组织数据应用创新比赛,这个比赛不一定要规模大,但是得有新意,鼓励业务部门挖掘数据价值,获奖案例在全公司表彰,根据目前举办的这一次来看,我们发现很多需求是在比赛过程中碰撞出来的,比闭门造车靠谱多了。
数据集的价值不在于有,而在于用。我们统计发现,被调用次数越多的数据集,其迭代优化速度也越快,质量提升越明显。这就像流水不腐,用得越多,活得越好。
2、问题处理与持续迭代
数据集用起来,肯定会有问题。标注错了、格式不对、更新不及时……关键不是不出问题,而是出了问题能快速解决。
我们建了一个"数据问题工单流程",也是内置在工具平台内的:
用户提交问题 → 自动分派责任人 → 24小时内响应 → 解决后用户确认 → 归档复盘刚开始执行的时候,有人抱怨"太麻烦了,打个电话不行吗"。我们坚持了下来,因为电话里说清楚的事,不记录下来,下次还会再犯,通过平台里解决了一次以后,下一次在遇到类似问题他们也会依葫芦画瓢了。
现在回头看,这个机制其实也是有几个好处的,一是问题可追溯,每个数据集的历史问题都能查到,避免重复踩坑;二是责任可考核,谁负责的数据集问题多、解决慢,一目了然;三是改进有依据,定期分析问题类型,发现系统性缺陷就优化流程。
除此,每个月还需要做一次健康度评估,主要看下面这几个指标:
指标 | 评估内容 | 处理方式 |
|---|---|---|
使用率 | 近90天调用次数 | 连续两季度为零→考虑通报后下架或者调整归档 |
质量分 | 抽样检测的准确率及人员使用反馈 | 人员反馈异常较多的或者抽样率不达标的考虑复检 |
更新时效 | 距离上次更新时间 | 超过6个月→提醒负责人 |
用户满意度 | 使用反馈评分 | 低于3分→通报负责人改进 |
对使用率低、质量下降、场景过时的数据集,我们果断进行归档或淘汰,保持资产库的新陈代谢。刚开始有人觉得太狠了,但后来大家发现,这其实是一种保护,早发现早处理了,就可以避免问题积累到不可收拾。
一点反思
目前我们其实也还是存在一些不足,拿出来跟大家坦诚交流一下,毕竟复盘不是为了吹牛,是为了下次做得更好。
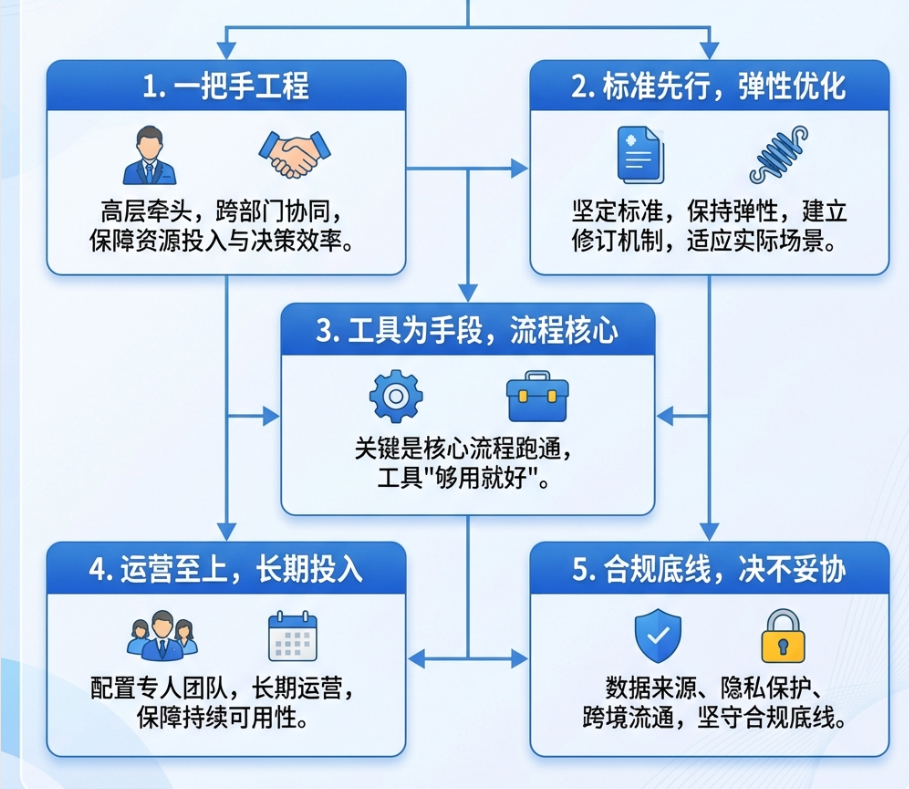
一个是跨部门协同还是不够顺畅,说白了还是人的因素占比太多导致的。 有时候业务部门提了需求,技术团队排期跟不上;有时候技术团队优化了工具,业务部门不知道。这个问题我们还在摸索更好的协作机制,目前打算建立一个长期的数据运营专班,每月固定时间把各方拉到一起对齐需求和进度。
二是自动化程度还有提升空间,目前质量检测、问题分派等环节还有不少步骤是人工操作的,效率有瓶颈,下一步打算引入更多自动化能力,让系统能自动预警、自动分派,把人从重复劳动里解放出来。
三是外部生态还没打通,目前数据集主要在内循环,跟行业伙伴、科研机构的数据互通还比较少。这块受合规限制较多,但长期看必须还是要突破的。现在已经在跟几家同行单位探讨数据互换的可能性,但进展比较慢,主要是机制还没建立起来。
第四是,运营团队人手紧张。 说实话,我们目前专职做数据运营的就3个人,要管几百个数据集的日常维护、问题响应、质量监控,确实有点力不从心。后续打算在重点业务部门培养数据运营联络员,形成分布式运营网络,减轻中心团队压力。
结语
最后想说几句心里话。
高质量数据集建设这事儿,真不是一蹴而就的项目,而是一项需要长期投入的基础工程。它不像业务系统那样能快速看到收益,但它的价值会随着时间推移不断放大。
我们单位从启动到现在,差不多花了一年半时间,才勉强把这套体系跑顺。中间踩过坑、走过弯路、也推倒重来过,但好在方向是对的。
用一句话总结我们的经验:顶层设计定方向,标准规范立规矩,平台工具提效率,工程实施保质量,常态运营促持续。
这条路不容易,但值得走。因为在这个人工智能+的时代,谁掌握了高质量数据,谁就掌握了未来的主动权。
至于具体做法对不对,欢迎大家批评指正。毕竟高质量数据集建设这事儿,全行业都还在探索,没有标准答案,只有不断试错、不断迭代。
共勉。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号