大模型应用:大模型训练数据治理:噪声过滤与高质量中文语料构建实践.40
原创
大模型应用:大模型训练数据治理:噪声过滤与高质量中文语料构建实践.40
原创
未闻花名
发布于 2026-03-09 07:55:52
发布于 2026-03-09 07:55:52
一、引言
大模型的性能上限,一半取决于模型架构与训练策略,另一半则由训练数据的质量决定。尤其对于中文大模型而言,中文语料存在来源繁杂、噪声冗余、格式不统一、语义歧义等问题,直接影响模型的理解能力、生成准确性与泛化能力。
今天我们将从基础概念入手,拆解大模型训练数据治理的核心流程,结合实践案例探讨噪声过滤的关键方法,并延伸现有语料治理维度,深入分析数据质量对模型性能的影响,为高质量中文语料构建提供可落地的参考方案。

二、基础概念
1. 训练数据治理
训练数据治理是贯穿数据采集、清洗、标注、质检、存储全生命周期的一系列技术与流程规范,目标是降低数据中的噪声占比、提升数据的有效性与一致性,让模型在训练过程中学习到准确、可靠的知识与模式。
对于中文大模型,数据治理还需要兼顾中文语言特性:如多音字、一词多义、句法结构灵活性、传统文化与现代网络用语的融合等。
2. 训练数据中的噪声
噪声数据是指对模型训练无正向贡献,甚至会干扰模型学习的无效数据,中文语料中的噪声主要分为以下几类:
- 内容噪声:包含错别字、病句、语义矛盾、重复内容、低质灌水文本(如网络水军评论、无意义拼接内容)。
- 格式噪声:文本格式混乱(如乱码、特殊符号滥用、无标点断句)、不同来源数据格式不统一(如部分语料带 HTML 标签,部分为纯文本)。
- 标注噪声:针对有监督训练数据,标注结果错误、标注标准不一致(如情感分类中 “中性” 与 “积极” 边界模糊)。
- 偏见噪声:包含歧视性内容、极端观点、地域或群体偏见的文本,会导致模型生成偏见性输出。
3. 高质量中文语料的核心标准
高质量中文语料需满足 “准确性、全面性、纯净性、新” 四大核心标准:
3.1 准确性
准确性是语言规范与知识可靠性的基石,是高质量语料的首要标准。这要求文本在多个层面均达到精确无误,语言层面的准确性意味着:
- 1. 文本需严格遵循现代汉语语法规范,杜绝错别字、拼音误用及乱码字符。
- 2. 标点符号的使用应当恰当,句子结构需完整清晰,避免出现主谓宾搭配不当或语序混乱等问题。
- 3. 更深一层的是语义明确性,即文本表达应无歧义。例如,代词需有清晰的指代对象,逻辑关系(因果、转折、并列等)应表述明白,避免产生多重解读。
在知识可靠性上:
- 1. 语料承载的事实、数据、日期、名称等信息必须真实准确,且最好有可验证的来源。
- 2. 这意味着需要严格过滤主观臆断、未经证实的谣言以及包含事实性错误的内容。
- 3. 只有基于真实可靠的知识,模型才能建立起对世界的正确认知。
3.2 全面性
全面性是构建多维度的语言与知识谱系,高质量的中文语料库应像一幅广阔的地图,覆盖语言使用的各个维度。
- 领域覆盖需要广泛而均衡:
- 它应涵盖科学技术(如人工智能、生物医学)、人文社科(如历史、哲学、法律)、生活服务(如医疗健康、金融服务)以及众多专业领域(如学术论文、技术文档)。这种广度确保模型能够应对跨领域的复杂问题。
- 场景多样性要求语料包含丰富的语言使用环境:
- 这既包括日常对话、客服问答等互动场景,也包括新闻报道、百科条目、合同协议等文档场景,还应涵盖文学创作、诗歌剧本等创造性表达。
- 此外,包含双语对照的语料对提升模型的翻译与跨语言理解能力至关重要。
- 文体完整性则关注语言的不同表达风格:
- 语料库中应同时容纳严谨规范的书面语体(如官方文件)、灵活生动的口语语体(包括方言与网络用语),以及介乎两者之间的混合语体,如演讲、访谈。
- 专业领域的特殊语体和术语表达也需得到充分体现。
3.3 纯净性
纯净性是确保语料清洁与安全的关键,纯净性关注的是语料的"清洁度"与安全性,直接关系到模型输出的质量和伦理边界。
- 噪声控制涉及清除文本中的各类干扰:
- 这包括去除乱码、无关字符(如网页广告、导航栏文本)、残留的HTML标签以及排版混乱的内容。
- 同时,也需过滤机器生成的无意义文本或低质量重复内容。
- 重复率控制旨在提升语料的信息密度:
- 通过技术手段(如MD5哈希、文本相似度计算)去除完全重复或高度近似的文本,避免模型过度拟合某些模式;
- 同时确保存储和计算资源的高效利用。
- 内容安全与合规是必须坚守的底线:
- 语料应彻底清除暴力、色情、极端主义等有害信息,并尽力减少在性别、种族、地域、职业等方面的偏见与歧视内容。
- 隐私保护也至关重要,个人敏感信息(如身份证号、电话号码)需进行脱敏处理。
- 此外,整个语料库的构建必须符合知识产权等相关法律法规。
3.4 新颖性
新颖性是保持语料生命力与时代相关性,语言是活的,知识在更新,语料库也必须与时俱进。时效性要求语料包含足够比例的新近内容。
- 对于新闻资讯、政策法规、市场数据等,应力求获取一年内的信息;
- 对于科技进展、学术研究,通常涵盖近三年的成果;
- 而基础理论知识或经典文学作品,则可具有更长的时效性。
- 这种搭配使模型既能把握时代脉搏,又拥有稳固的知识根基。
与之配套的是系统的知识更新与维护机制:
- 语料库应有清晰的版本管理和更新时间戳,对于已过时的信息可进行标记或提供更新版本。
- 更重要的是,需要建立动态的补充流程,定期纳入新兴领域和热点话题的语料,确保语料库的持续生长和活力。
三、核心流程
大模型训练数据治理是一个闭环迭代的过程,核心流程分为 5 个阶段,每个阶段都需要结合中文语言特性设计针对性方案。
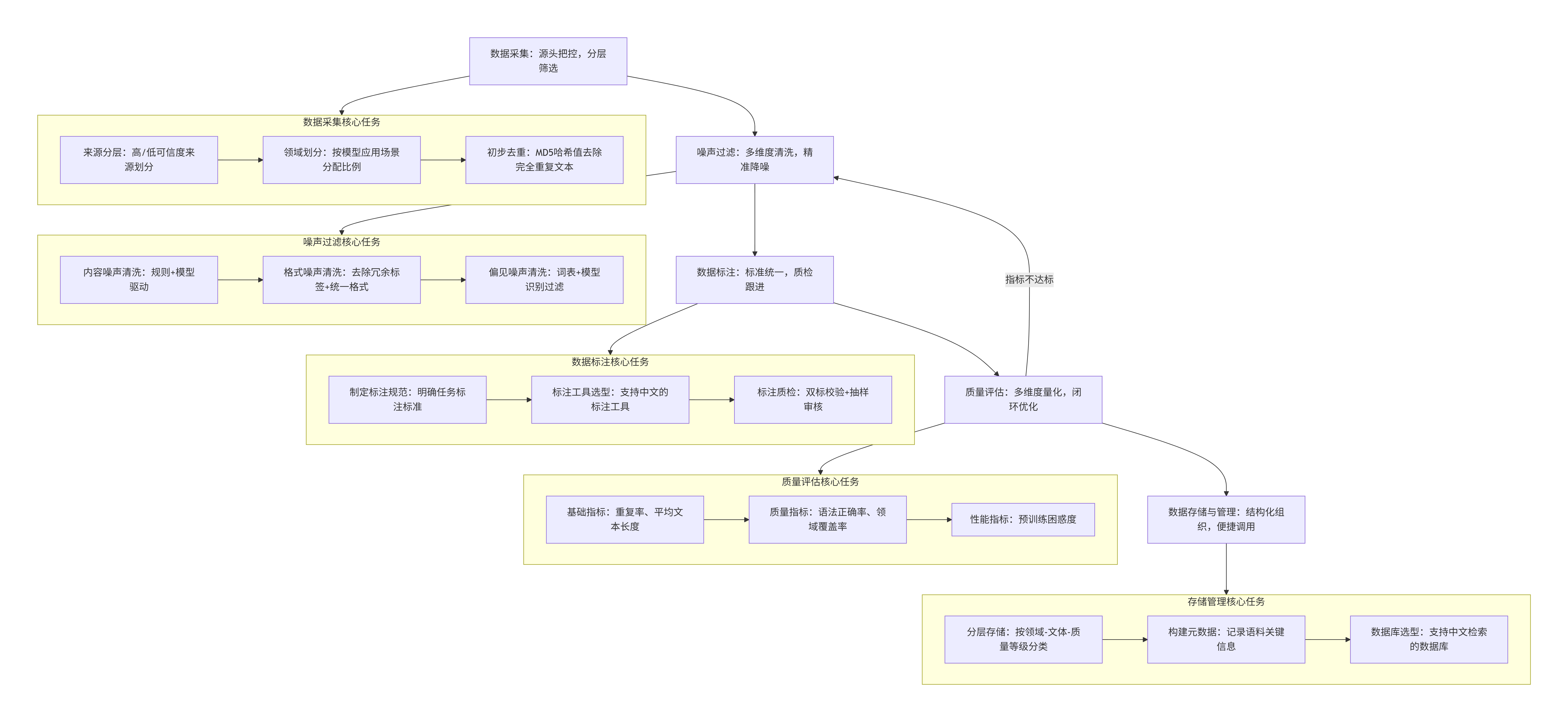
1. 数据采集:源头把控,分层筛选
数据采集是治理的第一步,直接决定了后续治理的难度。中文语料的来源主要包括公开数据集(如 Wiki 中文、CC-100 中文子集)、互联网公开文本(新闻、论文、书籍、社交媒体)、行业私有数据等。
核心操作:
1.1 来源分层:将数据源分为 “高可信度来源”(如权威新闻网站、学术论文库、正规出版物)和 “低可信度来源”(如论坛评论、社交媒体),优先采用高可信度数据。
1.2 领域划分:根据模型的应用场景(如通用大模型、金融大模型),确定语料的领域分布比例,避免单一领域数据占比过高。
1.3 初步去重:对采集到的原始数据进行粗粒度去重(如基于 MD5 哈希值去除完全重复的文本),减少后续清洗压力。
2. 噪声过滤:多维度清洗,精准降噪
噪声过滤是数据治理的核心环节,需要结合规则引擎、统计方法、机器学习模型进行多维度处理,针对中文语料的噪声类型设计专项清洗策略。
核心操作(按噪声类型分类):
2.1 内容噪声清洗
- 规则驱动清洗:
- 基于中文分词工具(如 jieba、THULAC)识别错别字、病句,例如通过词频统计筛选 “生僻词”“无意义词”(如 “的的的”“啊啊啊”);
- 设定文本长度阈值,过滤过短(如少于 5 个字符)或过长(如数万字无分段)的文本。
- 模型驱动清洗:
- 训练文本质量评分模型:基于人工标注的 “高质量 / 低质量” 语料,训练分类模型(如 TextCNN、BERT-base-chinese),对语料进行质量打分,筛选高分文本;
- 利用语义相似度模型(如 Sentence-BERT 中文版本)去除近重复文本(如内容相似但表述略有差异的新闻稿)。
2.2 格式噪声清洗
- 去除文本中的 HTML 标签、特殊符号(如 、\t、\n冗余换行);
- 统一标点符号格式(如将英文标点 “.” 替换为中文标点 “。”);
- 针对口语化文本(如对话语料),补充缺失的标点,修正口语化缩写(如 “酱紫” 改为 “这样子”),提升文本规范性。
2.3 偏见噪声清洗
- 构建中文偏见词表:包含性别歧视、地域歧视、种族歧视等相关词汇;
- 结合文本分类模型识别包含偏见内容的文本,进行过滤或人工修正;
- 对筛选后的语料进行偏见检测评估,确保语料的中立性。
3. 数据标注:标准统一,质检跟进
对于有监督训练任务(如指令微调、分类任务),需要对清洗后的语料进行标注。中文语料标注的核心难点在于语义边界的界定(如情感极性、意图分类)。
核心操作:
3.1 制定标注规范:针对具体任务明确标注标准,例如指令微调中 “指令 - 回复” 对的标注要求(回复需准确匹配指令意图、符合中文表达习惯)。
3.2 标注工具选型:选用支持中文分词、批量标注的工具。
3.3 标注质检:采用"双标校验"(同一文本由两名标注员标注)和"抽样审核"(随机抽取 10%-20% 标注数据人工审核),降低标注噪声。
4. 质量评估:多维度量化,闭环优化
数据治理完成后,需要通过量化指标评估语料质量,并根据评估结果迭代优化治理流程。
核心评估指标:
- 基础指标:重复率,即重复文本数量/总文本数量
- 基础指标:平均文本长度,即所有文本字符数的平均值
- 质量指标:语法正确率,即语法正确文本数量/总文本数量
- 质量指标:领域覆盖率,即覆盖目标领域的数量/预设领域总数
- 性能指标:模型预训练困惑度,用治理后语料预训练小模型,困惑度越低表示语料质量越高
闭环优化:若某一指标不达标,如困惑度过高,则回溯到噪声过滤阶段,调整清洗策略,如优化文本质量评分模型的阈值。
5. 数据存储与管理:结构化组织,便捷调用
高质量语料需要进行结构化存储,方便后续模型训练的快速调用。
核心操作:
5.1 采用分层存储结构:按"领域 - 文体 - 质量等级"对语料进行分类存储;
5.2 构建语料元数据:记录每条语料的来源、质量评分、标注信息等;
5.3 选用支持中文检索的数据库,如Elasticsearch,便于快速筛选目标语料。
6. 流程简化与总结

- 1 数据采集:源头把控
- 目的:从各类来源获取原始数据
- 核心方法:分层筛选、领域划分、初步去重
- 关键产出:初步清洗的原始数据集合
- 2 噪声过滤:质量净化
- 目的:去除数据中的低质和干扰内容
- 核心方法:内容、格式、偏见三维度清洗
- 关键产出:高纯净度的预处理数据
- 3. 数据标注:标准统一
- 目的:为数据添加准确的标签和注释
- 核心方法:规范制定、工具选型、质检机制
- 关键产出:标准化标注的模型训练数据
- 4. 质量评估:量化验证
- 目的:客观评估数据质量并指导优化
- 核心方法:基础、质量、性能多维度评估
- 关键产出:量化质量报告与改进建议
- 5. 存储管理:高效组织
- 目的:结构化存储数据以便后续使用
- 核心方法:分层存储、元数据管理、数据库选型
- 关键产出:组织有序、易于检索的数据仓库
四、存量语料库治理实践
现有存量的语料治理往往聚焦于"去重、去噪、格式统一",但忽略了一些对模型性能影响显著的维度。结合中文语料特性,以下 3 个延伸维度值得重点关注:
1. 语义一致性治理
中文存在大量一词多义现象(如"苹果"既指水果,也指科技公司),若语料中同一词汇的语义混乱,会导致模型学习到错误的关联知识。
治理方法:
- 基于词义消歧模型(如 LSTM + 注意力机制)对语料中的多义词进行语义标注;
- 按语义类别对语料进行细分,确保同一训练批次内的语料语义一致;
- 构建中文词义知识库,如基于《现代汉语词典》,对语料中的语义错误进行修正。
2. 文化适配性治理
中文语料包含大量传统文化、地域文化、网络文化内容,若模型无法理解这些文化内涵,会导致生成内容水土不服。
治理方法:
- 补充传统文化语料,如四大名著、唐诗宋词,并标注文化背景信息;
- 对网络流行语(如"内卷"、"躺平")进行标准化解释,避免模型误解;
- 针对不同地域的方言文本(如粤语、四川话),进行普通话转化或标注,确保语料的通用性。
3. 时效性治理
大模型容易出现"知识老化"问题,即无法掌握最新的知识,如 2025 年的新政策、新技术。
治理方法:
- 建立语料时效性分级机制:将语料分为永久有效知识(如数学公式、历史事实)和时效性知识(如新闻、政策);
- 定期更新时效性语料库,删除过时内容(如旧政策文件);
- 在语料中添加时间戳,训练模型时引入时间注意力机制,让模型区分新旧知识。
五、对模型性能的影响
数据质量与模型性能并非简单的线性关系,而是"量变到质变"的过程,当数据质量低于某一阈值时,模型性能会急剧下降;当数据质量达到一定水平后,模型性能的提升会趋于平缓。
- 噪声数据会误导模型学习:低质量语料中的错误语法、矛盾语义会让模型学习到错误的语言模式,导致生成文本不通顺、逻辑混乱。
- 数据分布不均会导致模型偏科:若训练语料中某一领域占比过高,模型在该领域的性能会较强,但在其他领域的性能会显著下降,如金融语料过多的模型,无法很好地理解医疗文本。
- 高质量语料提升模型泛化能力:准确、多样的高质量语料能让模型学习到中文语言的本质规律,从而在未见过的新任务、新场景中表现出更强的泛化能力。
六、案例实践
1. 基于规则的中文语料噪声过滤
实现基础的文本清洗,包括去特殊符号、统一标点、过滤短文本、简单去重,初次接触简单理解数据治理的底层规则逻辑。
import re
import hashlib
class BasicChineseTextCleaner:
def __init__(self):
# 特殊符号正则(匹配HTML标签、特殊转义符、冗余空格)
self.special_char_pattern = re.compile(r'<.*?>|&[a-z]+;|\s+')
# 中英文标点映射(统一为中文标点)
self.punct_map = {
'.': '。', ',': ',', '?': '?', '!': '!',
':': ':', ';': ';', '(': '(', ')': ')'
}
def clean_special_chars(self, text):
"""去除特殊符号和冗余空格"""
cleaned = self.special_char_pattern.sub(' ', text)
return cleaned.strip()
def unify_punctuation(self, text):
"""统一中英文标点"""
for en_punc, cn_punc in self.punct_map.items():
text = text.replace(en_punc, cn_punc)
return text
def filter_short_text(self, text, min_len=10):
"""过滤过短文本(默认至少10个字符)"""
return text if len(text) >= min_len else None
def get_text_hash(self, text):
"""生成文本哈希值(用于完全去重)"""
return hashlib.md5(text.encode('utf-8')).hexdigest()
def deduplicate_texts(self, texts):
"""基于哈希去重"""
hash_set = set()
unique_texts = []
for text in texts:
if text is None:
continue
text_hash = self.get_text_hash(text)
if text_hash not in hash_set:
hash_set.add(text_hash)
unique_texts.append(text)
return unique_texts
def clean(self, raw_texts):
"""全流程基础清洗"""
cleaned_texts = []
for text in raw_texts:
# 步骤1:去特殊符号
text = self.clean_special_chars(text)
if not text:
continue
# 步骤2:统一标点
text = self.unify_punctuation(text)
# 步骤3:过滤短文本
text = self.filter_short_text(text)
if text:
cleaned_texts.append(text)
# 步骤4:去重
cleaned_texts = self.deduplicate_texts(cleaned_texts)
return cleaned_texts
# 测试示例
if __name__ == "__main__":
# 原始噪声语料
raw_texts = [
" <p>今天吃了苹果,味道超棒!</p> ", # 含HTML标签+转义符
"今天吃了苹果.味道超棒!", # 英文标点
"好吃", # 过短文本
" <p>今天吃了苹果,味道超棒!</p> ", # 重复文本
"我今天买了华为手机,性能很好~"
]
cleaner = BasicChineseTextCleaner()
result = cleaner.clean(raw_texts)
print("清洗后结果:")
for i, text in enumerate(result):
print(f"{i+1}. {text}")输出结果:
清洗后结果: 1. 今天吃了苹果,味道超棒! 2. 今天吃了苹果。味道超棒! 3. 我今天买了华为手机,性能很好~
2. 模型驱动的中文语料质量评分
基于预训练中文 BERT 模型训练文本质量分类器,实现"高质量/低质量"语料的智能筛选,更贴近实际应用的数据治理逻辑。
bert-base-chinese 模型简单介绍:
Google BERT-Base-Chinese 是谷歌官方发布的首个中文预训练BERT模型,基于原始BERT架构专门针对中文语料进行训练。
模型特点:
- 影响力广泛:为后续所有中文BERT变体模型(如RoBERTa、ALBERT中文版)奠定了基础
- 标准参考:常被用作中文NLP任务的基准对比模型
- 训练数据:中文维基百科 + 大量中文网页文本
- 中文词表优化:使用21,128个汉字级别的token构建词汇表
- 大规模中文语料:在维基百科中文版和大量中文网页内容上训练
使用场景:
- 文本分类:判断评论的情感倾向(正面/负面/中性)、主题分类、垃圾邮件检测
- 命名实体识别:将预测标签映射回实体类型
- 问答系统:抽取式问答、阅读理解、FAQ匹配
- 文本相似度计算:计算两个文本或段落的余弦相似度
import torch
import torch.nn as nn
from transformers import BertTokenizer, BertModel
from torch.utils.data import Dataset, DataLoader
from modelscope.hub.snapshot_download import snapshot_download
# 1. 定义数据集(模拟人工标注的质量语料)
class TextQualityDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_len=128):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
# 中文BERT分词
encoding = self.tokenizer(
text,
truncation=True,
padding='max_length',
max_length=self.max_len,
return_tensors='pt'
)
return {
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'labels': torch.tensor(label, dtype=torch.long)
}
# 2. 定义质量评分模型(基于BERT微调)
class TextQualityClassifier(nn.Module):
def __init__(self, bert_model_name='bert-base-chinese', num_classes=2):
super().__init__()
cache_dir = "D:\\modelscope\\hub"
model_name = "google-bert/bert-base-chinese"
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
self.bert = BertModel.from_pretrained(local_model_path)
self.dropout = nn.Dropout(0.3)
self.fc = nn.Linear(self.bert.config.hidden_size, num_classes)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs.pooler_output # [CLS] token输出
x = self.dropout(pooled_output)
logits = self.fc(x)
return logits
# 3. 训练+预测流程
def train_and_predict():
# 初始化工具
cache_dir = "D:\\modelscope\\hub"
model_name = "google-bert/bert-base-chinese"
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = BertTokenizer.from_pretrained(local_model_path)
model = TextQualityClassifier(bert_model_name=local_model_path)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
# 模拟标注数据(1=高质量,0=低质量)
train_texts = [
"人工智能技术的发展推动了智能制造的升级,相关算法在工业场景中落地效果显著。", # 高质量
"啊啊啊这啥呀不知道说啥随便写写", # 低质量
"2025年中国数字经济规模预计突破80万亿元,同比增长9.5%。", # 高质量
"凑字数凑字数凑字数,没啥内容的垃圾文本", # 低质量
"唐诗宋词是中国传统文化的瑰宝,其中蕴含的美学价值至今仍被广泛研究。" # 高质量
]
train_labels = [1, 0, 1, 0, 1]
# 构建数据集
dataset = TextQualityDataset(train_texts, train_labels, tokenizer)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
# 训练配置
optimizer = torch.optim.Adam(model.parameters(), lr=2e-5)
loss_fn = nn.CrossEntropyLoss()
model.train()
# 简易训练(5轮)
for epoch in range(5):
total_loss = 0
for batch in dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask)
loss = loss_fn(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {total_loss/len(dataloader):.4f}")
# 测试新语料质量评分
test_texts = [
"大模型训练数据治理需要兼顾噪声过滤和语义一致性。",
"随便打几个字,这是低质量文本"
]
model.eval()
with torch.no_grad():
for text in test_texts:
encoding = tokenizer(
text, truncation=True, padding='max_length',
max_length=128, return_tensors='pt'
)
input_ids = encoding['input_ids'].to(device)
attention_mask = encoding['attention_mask'].to(device)
outputs = model(input_ids, attention_mask)
prob = torch.softmax(outputs, dim=1)
quality_score = prob[0][1].item() # 高质量概率
print(f"文本:{text}\n质量评分(0-1):{quality_score:.4f}\n")
if __name__ == "__main__":
train_and_predict()输出结果:
Downloading Model from https://www.modelscope.cn to directory: D:\modelscope\hub\google-bert\bert-base-chinese Epoch 1, Loss: 0.6334 Epoch 2, Loss: 0.3851 Epoch 3, Loss: 0.2471 Epoch 4, Loss: 0.2325 Epoch 5, Loss: 0.1880 文本:大模型训练数据治理需要兼顾噪声过滤和语义一致性。 质量评分(0-1):0.7932 文本:随便打几个字,这是低质量文本 质量评分(0-1):0.3300
3. 语义一致性 + 时效性治理
结合中文词义消歧(解决一词多义)和时间戳筛选(解决知识老化),实现更贴合中文特性的高阶数据治理。
text2vec-base-chinese 模型简单介绍:
Jerry0/text2vec-base-chinese模型,这是一个基于中文文本的文本表示(text-to-vector)模型,主要用于将中文句子映射到固定维度的向量空间,以便进行后续的文本相似度计算、聚类、分类等任务。
模型特点:
- 基础架构:该模型基于预训练的Transformer架构(如BERT)进行微调,专门用于中文文本的向量表示。
- 训练数据:使用大规模中文语料进行训练,能够捕捉中文语言的语义信息。
- 输出:对于输入的中文句子,模型可以生成一个固定维度的向量(通常为768维),这个向量可以用于表示句子的语义。
使用场景:
- 文本相似度计算:计算两个句子之间的余弦相似度,用于语义搜索、重复问题检测等。
- 文本聚类:将句子向量进行聚类,发现主题或模式。
- 文本分类:作为特征输入到分类器中。
- 信息检索:将文档和查询转换为向量,进行语义检索。
import torch
from transformers import AutoModel, AutoTokenizer
import jieba
from datetime import datetime
from modelscope.hub.snapshot_download import snapshot_download
class AdvancedChineseTextGovernor:
def __init__(self):
# 加载中文词义消歧模型(基于SimBERT)
cache_dir = "D:\\modelscope\\hub"
model_name = "Jerry0/text2vec-base-chinese"
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
self.tokenizer = AutoTokenizer.from_pretrained(local_model_path)
self.semantic_model = AutoModel.from_pretrained(local_model_path)
# 中文多义词典(示例:苹果、银行)
self.polysemous_words = {
"苹果": ["水果", "科技公司"],
"银行": ["金融机构", "河边的堤岸"]
}
# 时效性关键词库(示例)
self.timely_keywords = ["2025政策", "2025技术", "2025经济"]
def get_text_embedding(self, text):
"""获取文本语义向量(用于词义消歧)"""
inputs = self.tokenizer(
text, return_tensors='pt', padding=True,
truncation=True, max_length=128
)
with torch.no_grad():
outputs = self.semantic_model(** inputs)
# 均值池化获取句向量
emb = outputs.last_hidden_state.mean(dim=1)
return emb
def disambiguate_polysemous_word(self, text, target_word):
"""多义词义消歧"""
if target_word not in self.polysemous_words:
return "未知语义"
# 生成目标词不同语义的参考向量
ref_embeddings = {}
for meaning in self.polysemous_words[target_word]:
ref_text = f"{target_word} {meaning}"
ref_embeddings[meaning] = self.get_text_embedding(ref_text)
# 计算文本与各语义的相似度
text_emb = self.get_text_embedding(text)
max_sim = 0
best_meaning = ""
for meaning, ref_emb in ref_embeddings.items():
sim = torch.cosine_similarity(text_emb, ref_emb).item()
if sim > max_sim:
max_sim = sim
best_meaning = meaning
return best_meaning
def filter_timely_text(self, texts_with_timestamp, cutoff_date="2024-01-01"):
"""过滤过时文本(保留2024年后的时效性内容)"""
cutoff = datetime.strptime(cutoff_date, "%Y-%m-%d")
timely_texts = []
for text, timestamp in texts_with_timestamp:
text_date = datetime.strptime(timestamp, "%Y-%m-%d")
# 同时筛选含时效性关键词的文本
if text_date >= cutoff and any(kw in text for kw in self.timely_keywords):
timely_texts.append(text)
return timely_texts
# 测试示例
if __name__ == "__main__":
governor = AdvancedChineseTextGovernor()
# 1. 词义消歧测试
test_texts = [
"苹果发布了新款iPhone 16",
"我买了一斤苹果,很甜"
]
print("=== 词义消歧结果 ===")
for text in test_texts:
meaning = governor.disambiguate_polysemous_word(text, "苹果")
print(f"文本:{text}\n'苹果'语义:{meaning}\n")
# 2. 时效性过滤测试
texts_with_ts = [
("2025政策:大模型数据治理新规发布", "2025-03-15"),
("2023年的旧政策:人工智能发展规划", "2023-05-20"),
("2025技术:中文大模型语义一致性治理突破", "2025-01-10")
]
timely_texts = governor.filter_timely_text(texts_with_ts)
print("=== 时效性过滤结果 ===")
for text in timely_texts:
print(text)输出结果:
=== 词义消歧结果 === 文本:苹果发布了新款iPhone 16 '苹果'语义:科技公司 文本:我买了一斤苹果,很甜 '苹果'语义:水果 === 时效性过滤结果 === 2025政策:大模型数据治理新规发布 2025技术:中文大模型语义一致性治理突破
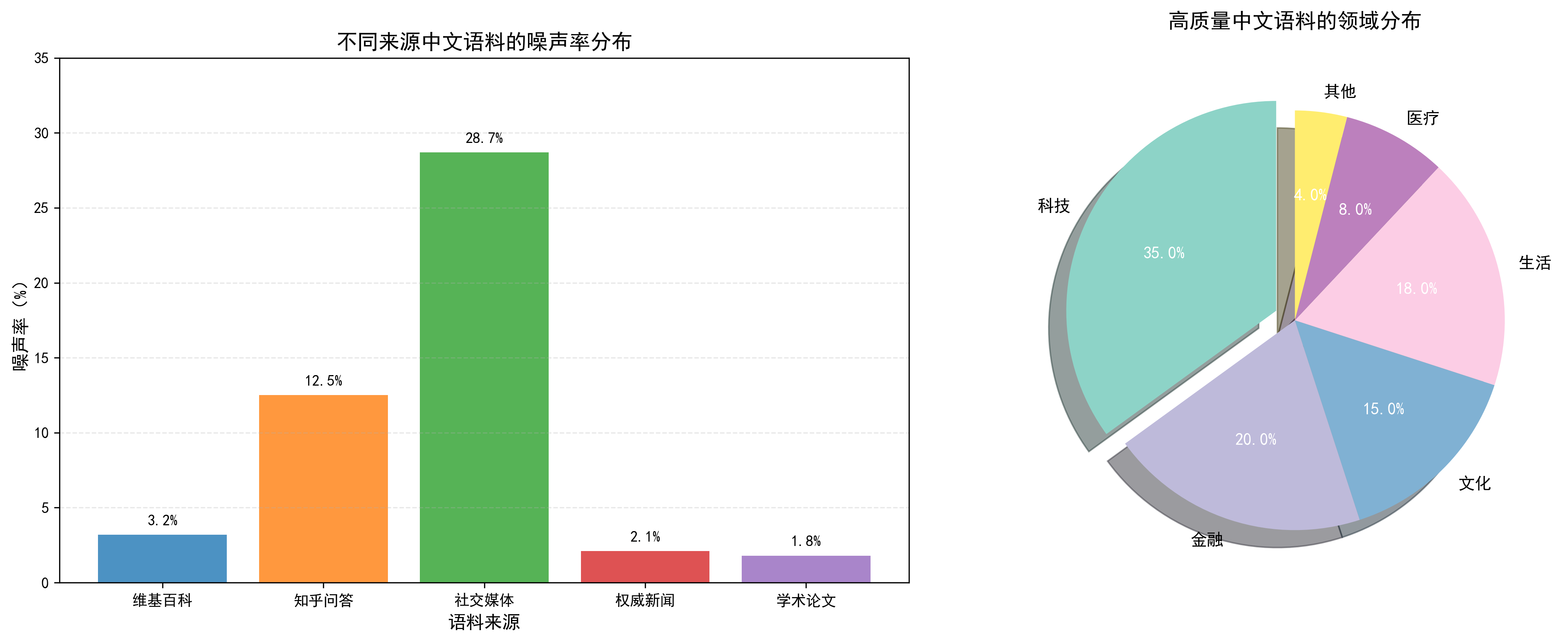
4. 不同噪声率对中文大模型核心性能指标的影响

4.1 原始实验数据
噪声率(%) 中文分词准确率(%) 文本生成流畅度(1-10) 常识问答准确率(%) 0 3 92.5 8.6 82.3 1 10 88.7 7.8 78.5 2 15 85.1 7.1 74.2 3 20 79.8 6.0 68.9 4 25 72.3 4.8 61.2 5 30 65.2 4.2 52.1
4.2 相关性分析结果(皮尔逊相关系数)
噪声率 vs 分词准确率:-0.9790(强负相关) 噪声率 vs 生成流畅度:-0.9912(强负相关) 噪声率 vs 问答准确率:-0.9750(强负相关)
4.3 数据治理前后性能提升量化
治理前(噪声率30%)→ 治理后(噪声率3%): 中文分词准确率:65.2% → 92.5%,提升41.9% 文本生成流畅度:4.2分 → 8.6分,提升104.8% 常识问答准确率:52.1% → 82.3%,提升58.0%
七、总结
大模型训练数据治理是一项技术与经验并重的系统工程,对于中文大模型而言,更需要兼顾语言特性与文化内涵。从基础的噪声过滤到进阶的语义、文化、时效性治理,每一个环节都直接影响模型的最终性能。
随着大模型技术的发展,数据治理将成为一种大的趋势,我们可以利用大模型自身进行数据清洗与质检,实现以模型治理数据,以数据优化模型的闭环;同时可以针对不同行业、不同场景的需求,构建专属的高质量中文语料库。结合我们的实际业务场景考量,从而达到符合预期的效果。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号