大模型应用:多模态图文精准识别:基于本地化OCR模型应用实践.78
原创
大模型应用:多模态图文精准识别:基于本地化OCR模型应用实践.78
原创
未闻花名
发布于 2026-04-16 08:03:18
发布于 2026-04-16 08:03:18
一、引言
在OCR技术从传统字符匹配向大模型多模态融合演进的当下,图片理解作为多模态技术的核心支柱,其重要性愈发凸显。传统计算机视觉技术往往局限于单一的图像分类、目标检测任务,只能捕捉图片表层的视觉信息,却无法真正理解图像背后的语义关联与逻辑脉络。单纯的 OCR 模型已难以满足复杂场景的识别需求,而融合视觉 - 语言能力的多模态大模型,凭借对图片内容的理解能力,能轻松应对倾斜文字、复杂排版、多语言混合等传统 OCR 的痛点。
Qwen2-VL-OCR-2B 多模态智能体的出现,彻底打破了这一技术桎梏。它创新性地将视觉感知、光学字符识别与大语言模型的语义理解能力深度融合,实现了从 "看得到" 到 "看得懂" 的跨越。面对一张包含文字、图像、图表的复杂图文内容,该模型不仅可以精准识别出图片中的每一个文字信息,更能理解文字与图像之间的内在联系,梳理出内容的逻辑框架与核心主旨。2B 超轻量参数量,本地 CPU/GPU 均可流畅运行,基于多模态大模型的理解能力实现高精度图文识别,今天我们结合详细的应用示例一探究竟。

二、模型介绍
Qwen2-VL系列的轻量OCR专用模型,其相比传统OCR模型(如PaddleOCR 基础版)和其他大模型OCR(如 GLM-OCR),在轻量性、兼容性、识别能力上有显著优势,尤其适合本地部署场景:
- 1. 超轻量易部署:仅2B参数量,模型文件体积小,CPU可流畅运行,低配显卡、无显卡环境无压力,本地部署无网络依赖,数据更安全;
- 2. 多模态融合识别:并非单纯的字符匹配,而是通过视觉编码 + 语言理解双模块工作,能理解图片上下文,对倾斜文字、复杂排版、小字体、多语言混合的识别精度远高于传统OCR;
- 3. 生态无缝衔接:基于ModelScope实现模型一键下载、缓存,通过 Transformers 库的多模态专用接口加载,无需新的框架;
- 4. 指令式灵活调用:支持自然语言指令驱动,可通过修改指令实现精准识别、指定区域识别、多语言翻译识别等个性化需求,扩展性极强;
- 5. 全格式兼容:支持 jpg/png/bmp/webp 等主流图片格式,内置图片预处理逻辑,无需手动转换图片通道和尺寸;
- 6. 设备自动适配:通过device_map="auto"自动检测 CPU/GPU,有显卡则自动 GPU 加速,无显卡则CPU兜底,无需手动配置设备。
适配场景:个人本地图文提取、小型工具开发、批量图片识别、多语言混合图文处理、复杂排版图片识别(如文档、小票、海报)等,兼顾精度、速度、易用性。
三、环境准备
1. 核心依赖
# 核心依赖:transformers(多模态核心)、modelscope(模型下载)
pip install transformers modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
# 基础框架:torch(模型运行,CPU版本自动适配,GPU需装对应CUDA版本)
pip install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
# 图片处理/可视化:Pillow(图片读取)、matplotlib(图片展示)
pip install pillow matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
# 可选依赖:opencv-python(图片预处理,拓展功能用)
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple2. 版本兼容建议
- transformers >= 4.39.0,需支持 Qwen2-VL 的多模态处理器
- modelscope >= 1.9.0,保证模型下载缓存稳定
- torch >= 2.0.0,保证模型加载和设备适配
四、多模态 OCR 核心工作原理
Qwen2-VL-OCR-2B-Instruct作为视觉 - 语言多模态大模型,其OCR识别逻辑与传统 OCR、单纯的大模型OCR有本质区别,核心是“视觉感知 + 语言生成”的融合流程,整体工作步骤可分为 5 步:

步骤详细说明:
- 1. 模型下载与缓存:通过 ModelScope 的snapshot_download从官方仓库下载模型权重到本地,自动校验缓存,重复运行不重复下载;
- 2. 多模态预处理:通过AutoProcessor(多模态专用处理器)完成图片编码(将像素转为模型可识别的视觉特征)、文本指令分词(将自然语言指令转为模型可识别的 token)、对话模板适配(按模型要求拼接图片特征 + 文本指令,生成标准输入格式);
- 3. 设备自动分配:通过device_map="auto"将模型和预处理后的输入数据自动分配到 CPU/GPU,无需手动指定;
- 4. 多模态推理:模型先通过视觉模块提取图片中的文字区域和特征,再通过语言模块结合输入指令,生成符合要求的识别文字;
- 5. 结果解码与可视化:将模型生成的 token 序列解码为人类可读的文字,同时通过 Matplotlib 展示待识别图片,实现 “图文对照” 的直观效果。
核心差异:
- 传统OCR是“检测→识别”的纯视觉流程,对复杂场景鲁棒性差;
- 而Qwen2-VL-OCR-2B是“视觉感知→语言理解→生成输出”的融合流程,借助大模型的语言理解能力,能更好地处理模糊、倾斜、排版混乱的文字,甚至能理解文字的语义上下文。
五、案例实践
1. 多模态OCR文字识别示例
基于多模态大模型(Qwen2-VL)实现高质量 OCR 文字识别,支持中文、英文、混合排版,并保留原始格式。注意观察示例中的提示词部分,针对不同的场景做不同的描述;
# 导入核心库
# 多模态模型与专用处理器
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
# ModelScope模型下载工具
from modelscope import snapshot_download
# 图片处理库
from PIL import Image
# 图片可视化库
import matplotlib.pyplot as plt
# 文件路径与系统操作
import os
# 异常处理相关(可选,增强鲁棒性)
import traceback
# -------------------------- 1. 模型基础配置(仅需修改此处少量参数) --------------------------
# 模型名称(ModelScope官方仓库,无需手动找权重)
MODEL_NAME = "prithivMLmods/Qwen2-VL-OCR-2B-Instruct"
# 模型本地缓存路径(建议绝对路径,避免中文/空格/特殊字符)
CACHE_DIR = "D:\\modelscope\\hub"
# 测试图片路径(替换为你的图片路径,相对/绝对均可,建议绝对路径)
TEST_IMG_PATH = "test_ocr.png"
# 生成最大新token数(控制识别结果长度,按需调整,默认1024足够大部分场景)
MAX_NEW_TOKENS = 1024
# 确保缓存目录存在,避免模型下载时创建目录失败
os.makedirs(CACHE_DIR, exist_ok=True)
# -------------------------- 2. 模型本地下载/缓存校验 --------------------------
print("="*60)
print("📥 正在下载/校验Qwen2-VL-OCR-2B模型缓存...")
print("提示:首次运行需下载模型(约数GB),后续直接使用本地缓存,无需重复下载!")
try:
local_model_path = snapshot_download(
MODEL_NAME, # 模型名称
cache_dir=CACHE_DIR, # 本地缓存路径
)
print(f"✅ 模型下载/校验完成,本地缓存路径:\n{local_model_path}")
except Exception as e:
print(f"❌ 模型下载失败,错误信息:{e}")
print(f"📝 错误详情:{traceback.format_exc()}")
exit() # 模型下载失败,直接退出程序
# -------------------------- 3. 加载多模态处理器与模型 --------------------------
print("="*60)
print("⚙️ 正在加载多模态处理器与Qwen2-VL-OCR-2B模型...")
try:
# 加载多模态专用处理器:负责图片编码、文本分词、对话模板拼接
processor = AutoProcessor.from_pretrained(
local_model_path,
trust_remote_code=True # 适配Qwen2-VL的自定义代码,必须开启
)
# 加载Qwen2-VL多模态模型,用于OCR推理
model = Qwen2VLForConditionalGeneration.from_pretrained(
local_model_path,
trust_remote_code=True, # 适配自定义代码,必须开启
device_map="auto", # 自动分配设备(CPU/GPU/显存自动适配)
torch_dtype="auto" # 自动适配数据类型,节省显存/内存
).eval() # 模型设为评估模式,关闭训练相关层,提升推理速度和稳定性
print("✅ 多模态处理器与模型加载成功!")
print(f"🔧 模型运行设备:{model.device}") # 打印模型实际运行的设备(CPU/GPU)
except Exception as e:
print(f"❌ 处理器/模型加载失败,错误信息:{e}")
print(f"📝 错误详情:{traceback.format_exc()}")
exit()
# -------------------------- 4. 定义OCR识别+图片可视化核心函数 --------------------------
def qwen2_vl_ocr_detect(img_path, prompt="识别这张图片中的所有文字,保留原始排版"):
"""
Qwen2-VL-OCR-2B多模态OCR识别函数,支持自定义指令
:param img_path: 待识别图片的路径(相对/绝对)
:param prompt: 识别指令(自然语言,可自定义,如多语言识别、指定区域识别)
:return: 模型识别的文字结果
"""
# 第一步:校验图片路径是否存在
if not os.path.exists(img_path):
raise FileNotFoundError(f"图片路径不存在,请检查:{img_path}")
# 第二步:读取图片并转为RGB格式(解决PNG透明通道、BMP灰度图等格式兼容问题)
img = Image.open(img_path).convert("RGB")
# 第三步:图片可视化输出(图文对照,直观查看待识别内容)
print("="*60)
print("🖼️ 正在展示待识别图片...")
# 解决Matplotlib中文显示乱码问题(核心配置,必加)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 加载中文字体(黑体)
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示异常问题
# 设置图片展示尺寸,适配不同大小的图片
plt.figure(figsize=(10, 8))
plt.imshow(img) # 加载图片
plt.axis("off") # 关闭坐标轴,让图片展示更整洁
plt.title("待识别图片(Qwen2-VL-OCR-2B多模态识别)", fontsize=18, pad=20)
plt.show() # 弹出图片展示窗口(Jupyter中内嵌,本地脚本中弹出独立窗口)
# 第四步:多模态模型推理(核心步骤,按模型要求构造输入)
print("="*60)
print(f"🔍 正在执行多模态OCR识别,指令:{prompt}")
# 构造模型输入的对话格式(符合Qwen2-VL的指令式输入要求)
messages = [
{
"role": "user", # 角色为用户
"content": [
{"type": "image", "image": img}, # 输入图片
{"type": "text", "text": prompt} # 输入自然语言识别指令
]
}
]
# 应用模型的对话模板,生成标准输入文本(无需手动拼接,处理器自动完成)
text_prompt = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 将文本指令和图片转为模型可识别的张量,并分配到模型运行的设备(CPU/GPU)
inputs = processor(text=[text_prompt], images=[img], return_tensors="pt").to(model.device)
# 模型生成识别结果:基于输入的图片和指令,生成文字
generated_ids = model.generate(
**inputs,
max_new_tokens=MAX_NEW_TOKENS, # 最大生成token数,控制结果长度
do_sample=False, # 关闭采样,保证识别结果的确定性
temperature=0.0 # 温度值设为0,避免生成随机内容
)
# 将模型生成的token序列解码为人类可读的文字,跳过特殊符号
ocr_result = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
return ocr_result
# -------------------------- 5. 主程序运行入口 --------------------------
if __name__ == "__main__":
try:
# 调用OCR识别函数,可自定义识别指令(示例:默认中文识别/英文识别/多语言识别)
# 中文识别指令(默认):prompt="识别这张图片中的所有文字,保留原始排版"
# 英文识别指令:prompt="Recognize all text in this image and keep the original format"
# 中英混合识别:prompt="识别这张图片中的中英文文字,保留原始排版"
ocr_result = qwen2_vl_ocr_detect(
img_path=TEST_IMG_PATH,
prompt="识别这张图片中的所有文字,严格保留原始的排版和换行"
)
# 输出最终识别结果
print("="*60)
print("🎉 Qwen2-VL-OCR-2B多模态OCR识别完成!")
print("📜 识别结果如下:")
print("-"*60)
print(ocr_result)
print("-"*60)
except Exception as e:
print(f"❌ OCR识别过程失败,错误信息:{e}")
print(f"📝 错误详情:{traceback.format_exc()}")1.1 代码深度剖析
1.1.1 多模态专用处理器AutoProcessor的核心作用
与传统大模型的AutoTokenizer(仅处理文本)不同,AutoProcessor是多模态模型的专属预处理工具,同时负责图片和文本的预处理,核心功能有 3 个:
- 图片编码:将图片的像素值转换为 Qwen2-VL 模型可识别的视觉特征张量,自动完成图片尺寸调整、归一化等操作,无需手动处理;
- 文本分词:将自然语言指令(如“识别图片中的所有文字”)转换为模型可识别的 token 序列;
- 对话模板适配:通过apply_chat_template按 Qwen2-VL 模型的要求,将“图片特征 + 文本指令”拼接为标准的输入格式,避免因输入格式错误导致推理失败。
1.1.2 指令式输入的灵活性
代码中messages的构造方式是 Qwen2-VL-OCR-2B 的核心灵活点,通过修改prompt(自然语言指令),无需修改模型代码,即可实现个性化识别需求,示例:
- 中文精准识别:prompt="识别这张图片中的所有中文文字,保留原始排版和标点符号"
- 英文识别:prompt="Recognize all English text in this image, keep the original format"
- 中英混合识别:prompt="识别这张图片中的所有中英文文字,区分语言并保留排版"
- 指定内容识别:prompt="只识别这张图片中的标题文字,忽略正文"
- OCR + 翻译:prompt="识别这张图片中的英文文字,并将其翻译成中文"
1.1.3 model.generate生成参数调优
模型通过generate方法生成识别结果,关键参数直接影响识别效果和速度,核心参数解析(按需调整):
- max_new_tokens:最大生成新token数,识别长文本时需调大,如识别文档可设为 2048/4096,短文本设为512/1024即可,过大会增加推理时间;
- do_sample:是否开启采样,OCR 识别建议设为 False,关闭采样可保证识别结果的确定性,避免模型生成随机内容;
- temperature:温度值,控制生成内容的随机性,OCR 识别建议设为 0,值越大生成越随机,越小越确定;
- num_beams:束搜索数,可设为 2/4,提升识别结果的准确性,代价是少量推理时间增加。
1.1.4 设备适配的关键配置
- device_map="auto":自动检测电脑的硬件设备,若有 NVIDIA 显卡且安装了 CUDA,模型会自动加载到 GPU;若无显卡,自动加载到 CPU,无需手动指定device='cpu'或device='cuda';
- torch_dtype="auto":自动适配模型的数据类型(如 FP16/FP32),在 GPU 上会自动使用 FP16,节省显存;在 CPU 上自动使用 FP32,保证兼容性;
- model.eval():将模型设为评估模式,关闭 Dropout、BatchNorm 等训练相关的层,不仅能提升推理速度,还能避免模型在推理时产生不必要的随机误差。
1.1.5 模型缓存机制
通过 ModelScope 的snapshot_download下载的模型会缓存到CACHE_DIR指定的路径,首次运行下载后,后续运行会直接校验并使用本地缓存,无需重复下载。
测试的图片:test_ocr.png

1.2 输出结果
================================================== 正在下载/校验Qwen-OCR模型缓存... Downloading Model from to directory: D:\modelscope\hub\prithivMLmods\Qwen2-VL-OCR-2B-Instruct 模型本地路径:D:\modelscope\hub\prithivMLmods\Qwen2-VL-OCR-2B-Instruct ================================================== 正在加载Qwen-OCR... The image processor of type `Qwen2VLImageProcessor` is now loaded as a fast processor by default, even if the model checkpoint was saved with a slow processor. This is a breaking change and may produce slightly different outputs. To continue using the slow processor, instantiate this class with `use_fast=False`. Loading weights: 100%|███| 729/729 [00:00<00:00, 2773.44it/s, Materializing param=model.visual.patch_embed.proj.weight] Some parameters are on the meta device because they were offloaded to the cpu and disk. 模型加载成功! ================================================== 正在识别... ================================================== ✅ Qwen-OCR识别完成! 识别结果: <|im_start|>system You are a helpful assistant.<|im_end|> <|im_start|>user <|vision_start|><|image_pad|><|image_pad|>省略很多标签<|image_pad|><|image_pad|><|image_pad|><|image_pad|><|vision_end|>Recognize all text in this image.<|im_end|> <|im_start|>assistant 测试合同(软件服务合同) 甲方(委托方):北京 XX 科技有限公司 统一社会信用代码:9111010105XXXXXXX 地址:北京市朝阳区 XX 街道 XX 大厦 15 层 联系方式:138XXXX1234 乙方(服务方):上海 XX 软件技术有限公司 统一社会信用代码:91310104XXXXXXX 地址:上海市浦东新区 XX 路 XX 号 XX 园区 3 号楼 联系方式:139XXXX5678 依据《中华人民共和国民法典》及相关法律法规,甲乙双方本着平等自愿、协商一致的原则,就甲方委托乙方提供软件定制开发及运维服务事宜,订立本合同,以资共同信守。 一、服务内容与范围<|im_end|>
2. OCR文字识别并理解示例
基于 Qwen2-VL 多模态大模型的通用图像理解(Image Understanding)示例,核心作用是让 AI看懂任意图片内容,并用自然语言进行详细描述或回答特定问题。
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
from modelscope import snapshot_download
from PIL import Image
import matplotlib.pyplot as plt
import os
import traceback
# ====================== 配置不变 ======================
model_name = "prithivMLmods/Qwen2-VL-OCR-2B-Instruct"
cache_dir = "D:\\modelscope\\hub"
TEST_IMG_PATH = "image_understand.png" # 可以是任意图片:风景、截图、海报、人物、物品
MAX_NEW_TOKENS = 1024
os.makedirs(cache_dir, exist_ok=True)
# ====================== 下载模型(不变) ======================
print("="*60)
print("📥 下载/校验模型缓存...")
try:
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
print(f"✅ 模型路径:{local_model_path}")
except Exception as e:
print(f"❌ 下载失败:{e}")
exit()
# ====================== 加载模型/处理器(不变) ======================
print("="*60)
print("⚙️ 加载多模态模型...")
try:
processor = AutoProcessor.from_pretrained(local_model_path, trust_remote_code=True)
model = Qwen2VLForConditionalGeneration.from_pretrained(
local_model_path, trust_remote_code=True, device_map="auto", torch_dtype="auto"
).eval()
print(f"✅ 加载成功,设备:{model.device}")
except Exception as e:
print(f"❌ 加载失败:{e}")
exit()
# ====================== 核心:识图函数(仅prompt不同) ======================
def image_understand(img_path, prompt="请详细描述这张图片的全部内容"):
if not os.path.exists(img_path):
raise FileNotFoundError(f"图片不存在:{img_path}")
img = Image.open(img_path).convert("RGB")
# 图片可视化输出(保留你要的图片展示)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10, 6))
plt.imshow(img)
plt.axis("off")
plt.title("待识图图片(Qwen2-VL 多模态理解)", fontsize=16)
plt.show()
# 识图推理(格式完全同OCR,只是prompt变了)
print("🔍 正在识图理解...")
messages = [
{"role": "user", "content": [{"type": "image", "image": img}, {"type": "text", "text": prompt}]}
]
text_prompt = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = processor(text=[text_prompt], images=[img], return_tensors="pt").to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=MAX_NEW_TOKENS, do_sample=False, temperature=0.0)
result = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
return result
# ====================== 主程序:识图 ======================
if __name__ == "__main__":
try:
# -------------- 这里切换不同识图指令 --------------
# 指令1:通用详细描述(最强通用识图)
prompt = "请详细描述这张图片:场景、主体、物体、颜色、布局、文字、氛围、用途"
# 指令2:问答式识图
# prompt = "这张图片是什么场景?主要表达什么?"
# 指令3:只识别主体物体
# prompt = "请识别图中的主要物体/人物,不要多余描述"
result = image_understand(TEST_IMG_PATH, prompt=prompt)
print("="*60)
print("🎉 识图完成!模型理解结果:")
print("-"*60)
print(result)
print("-"*60)
except Exception as e:
print(f"❌ 识图失败:{e}")测试的图片:image_understand.png
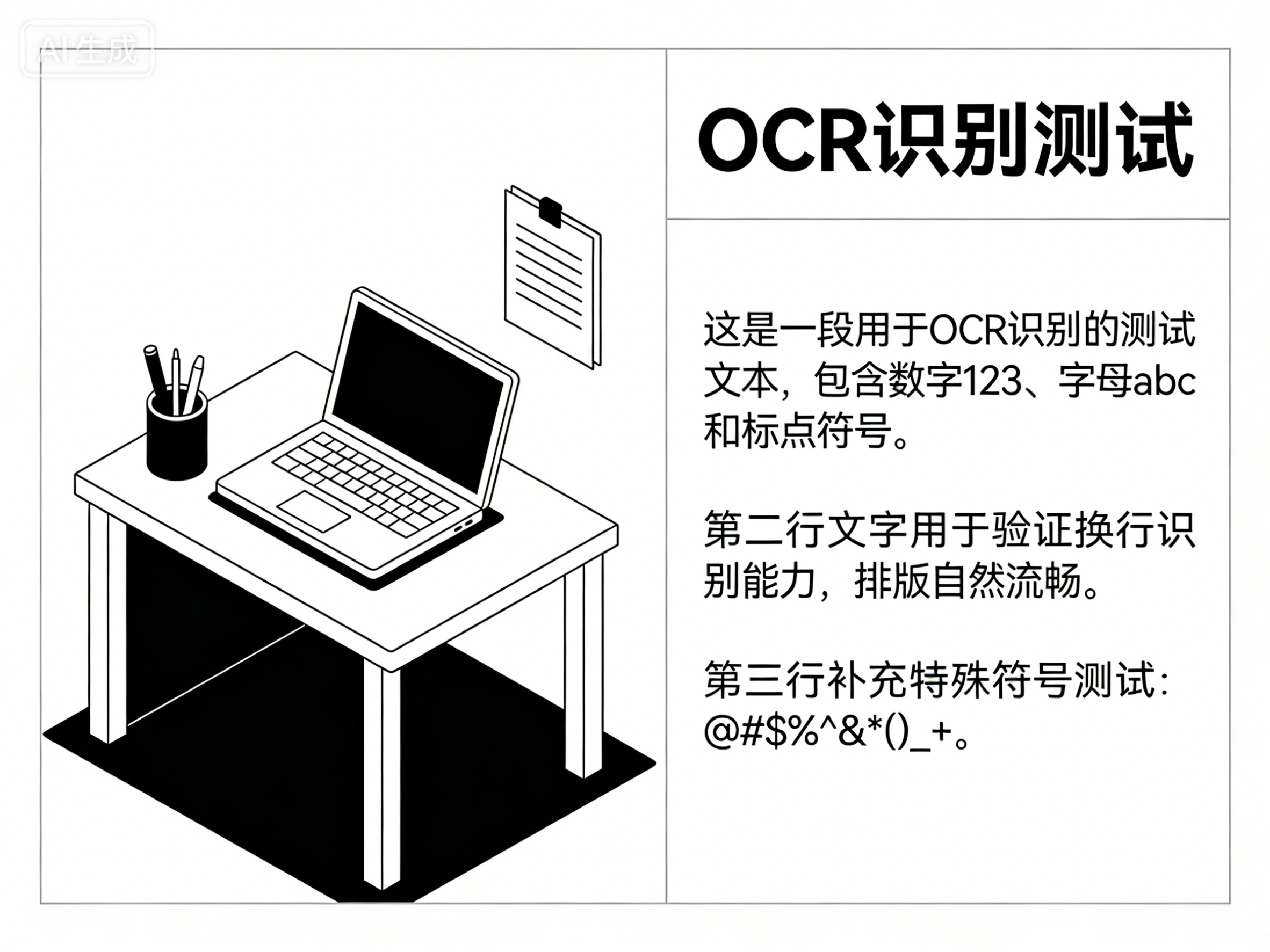
输出结果:
============================================================ 📥 下载/校验模型缓存... Downloading Model from to directory: D:\modelscope\hub\prithivMLmods\Qwen2-VL-OCR-2B-Instruct ✅ 模型路径:D:\modelscope\hub\prithivMLmods\Qwen2-VL-OCR-2B-Instruct ============================================================ ⚙️ 加载多模态模型... ✅ 加载成功,设备:cpu 🔍 正在识图理解... ============================================================ 🎉 识图完成!模型理解结果: ------------------------------------------------------------ <|im_start|>system You are a helpful assistant.<|im_end|> <|im_start|>user <|vision_start|><|image_pad|><|image_pad|>省略很多标签<|image_pad|><|image_pad|><|image_pad|><|image_pad|><|vision_end|>请详细描述这张图片:场景、主体、物体、颜色、布局、文字、氛围、用途<|im_end|> <|im_start|>assistant 这张图片展示了一个办公桌上的场景,桌面上有一台笔记本电脑、一支笔和一个文件夹。图片的左上角有一个AI生成的图标,表示这是AI生成的内容。图片的右上角有一个标题“OCR识别测试”,表示这是用于OCR(光学字符识别)测试的内容。 图片的主体是一台笔记本电脑,笔记本电脑上有一个打开的文件夹,文件夹里有一张纸。图片的左下角有一个黑色的桌子,桌子的边缘有阴影效果。图片的右下角有一个黑色的地板,地板的边缘有阴影效果。 图片的左上角有一行文字,表示这是用于OCR识别的测试文本,包含数字123、字母abc和标点符号。第二行文字表示这是用于验证换行识别能力的测试,排版自然流畅。第三行文字表示这是用于补充特殊符号测试的,包括@#$%^&*()_+。 图片的布局是将办公桌、笔记本电脑、文件夹和文字等元素放置在一个矩形框内,形成一个清晰的图像。文字的布局是按照从左到右、从上到下的顺序排列的,使得信息易于阅读和理解。 图片的右上角的标题“OCR识别测试”是主要的视觉焦点,吸引了观众的注意力。图片的左上角的AI生成图标和右上角的标题文字都是为了增强视觉效果和信息传达的准确性。<|im_end|> ------------------------------------------------------------
3. 识图与理解的融合实践
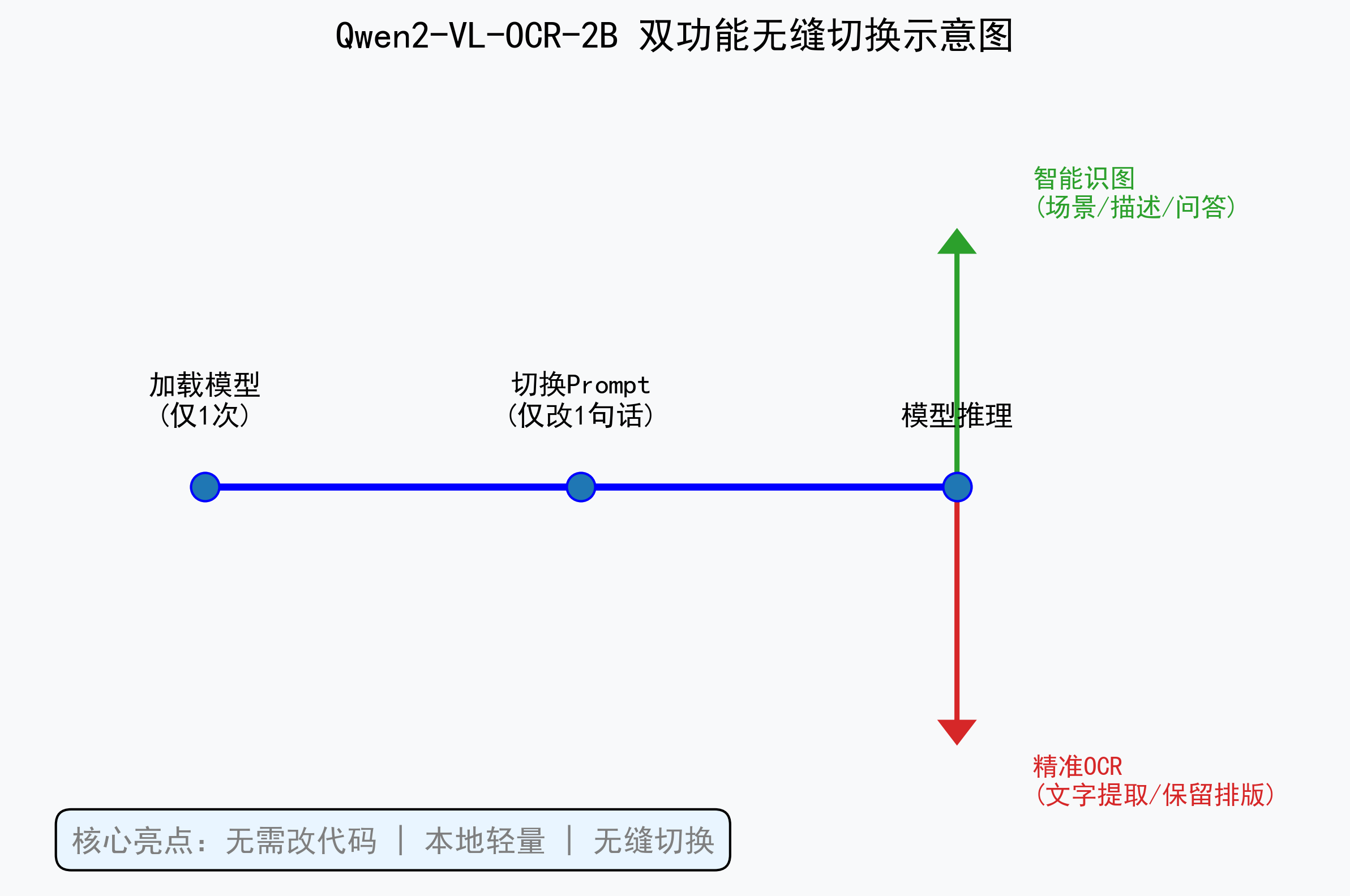
可以结合两个示例,融合两者体现,只需切换 prompt,就能在文字识别与智能识图之间无缝切换;
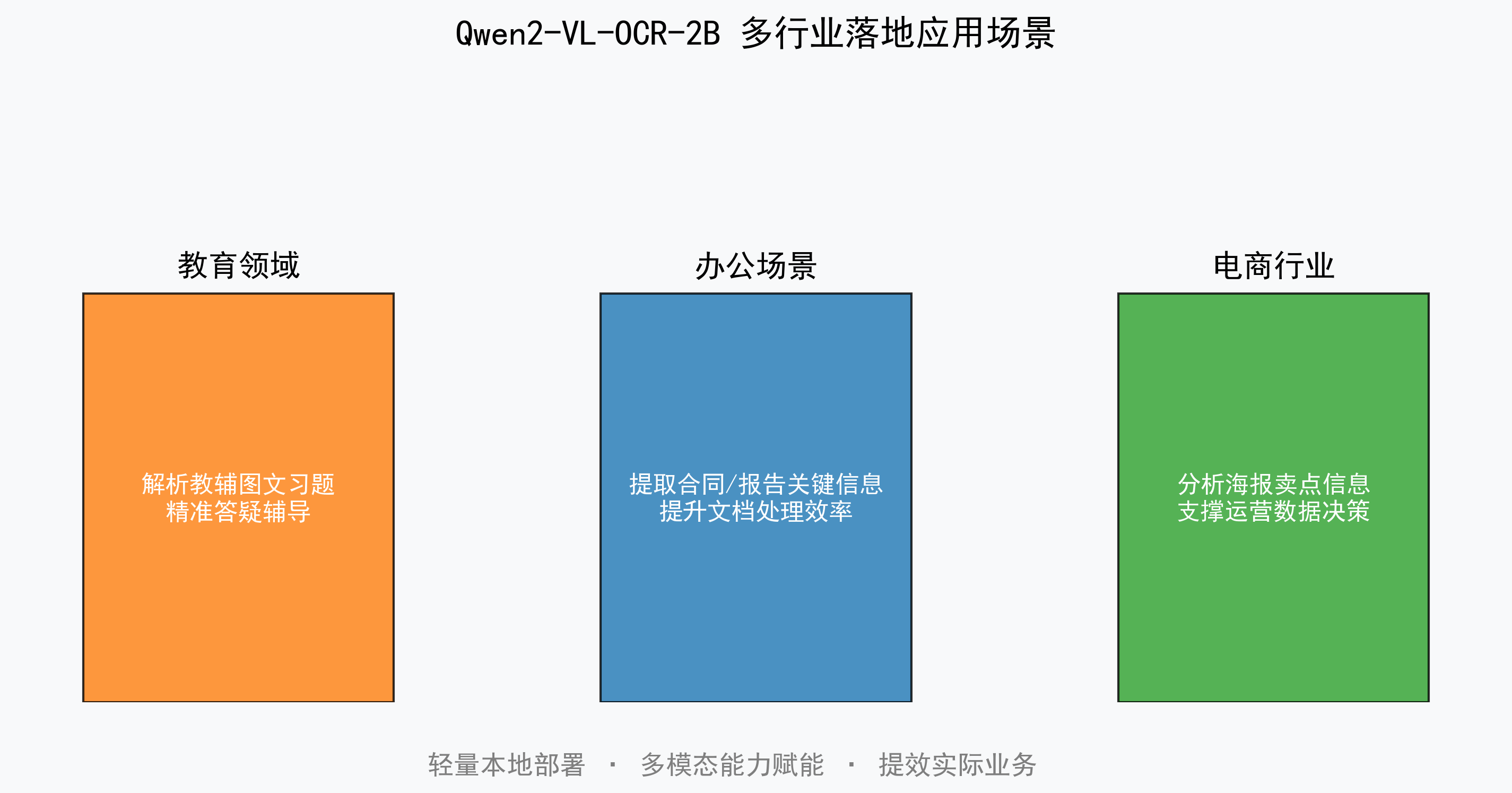
为各行各业带来了全新的应用可能
- 在教育领域,它可以自动解析教辅材料中的图文习题,为学生提供精准的答疑辅导;
- 在办公场景中,它能够快速提取合同、报告中的关键信息,大幅提升文档处理效率;
- 在电商行业,它可以智能分析商品宣传海报中的卖点信息,为商品运营提供数据支撑。
六、总结
今天我们基于本地OCR模型构建了一个可直接落地的轻量多模态 OCR 智能体,这款模型的核心价值在于将多模态大模型的语言理解能力与 OCR 的视觉识别能力深度融合,既解决了传统 OCR 在复杂场景下识别精度低的问题,又通过 2B 超轻量参数量实现了本地低成本部署,兼顾了精度、速度、易用性。
接触下来最大的感受是,它不是单纯的视觉信息读取工具,而是实打实的轻量多模态视觉语言模型,图片理解、场景识别、内容描述、看图问答这些能力都是原生自带的。而且操作起来特别友好,不用改任何代码,只需要切换一句 prompt,就能在文字识别和智能识图之间无缝切换,相当来说还是特别友好的,用来搭建本地轻量图文智能体再合适不过,实用性拉满!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号