大模型应用:中文大模型本土化效果评估方案:体系化方法、评估指标.81
原创
大模型应用:中文大模型本土化效果评估方案:体系化方法、评估指标.81
原创
未闻花名
发布于 2026-04-19 08:41:53
发布于 2026-04-19 08:41:53
一、评估核心原则
评估中文大模型的本土化效果,核心是围绕“中文理解、文化适配、本土场景落地、合规性对齐”四大核心维度,建立分层级、可量化、贴合本土实际的评估体系,既包含通用NLP的基础能力验证,更聚焦中文独有的语言特征、文化内涵和本土场景需求,同时兼顾人工主观评估与自动化客观检测,最终实现从基础能力到实际落地的整体效果验证。
为避免评估偏离本土化核心目标,需遵循 4 个基础原则,确保评估结果真实、有效、贴合实际:
- 本土导向:所有评估任务、语料、指标均围绕中文原生场景设计,拒绝用翻译后的外文任务替代中文本土任务;
- 量化为主,质化为辅:基础语言能力、场景落地效果尽量用可计算的量化指标衡量,文化意境、价值观适配等偏主观的维度用标准化人工评估补充;
- 场景化验证:脱离实际场景的评估无意义,需覆盖政务、电商、教育、医疗、民俗等中文核心本土场景;
- 合规性前置:本土化效果不仅是 “用得顺”,更是 “用得合规”,需将符合中国网络安全、内容规范等要求纳入评估核心维度。

二、分层评估体系
按“基础语言能力→文化深度适配→本土场景落地→合规与价值观对齐”由浅入深分层,每个层级对应评估维度、量化指标、实操方法、评估语料,语料均为中文原生语料,指标可直接计算,方法可快速落地。
1. 中文基础语言能力评估
大模型本土化的基本功,核心验证模型对中文独有的语言特征的理解能力,是本土化的基础,如果模型连中文的基础表达都理解错误,后续文化适配和场景落地无从谈起。
聚焦中文区别于其他语言的核心特征:分词准确性、多音字或多义词理解、句式适配(如倒装、省略句)、标点或语气词理解,均为量化指标,可自动化评估。
1.1 中文分词准确性
- 核心量化指标:精确率(P)、召回率(R)、F1值
- 实操评估方法:使用中文标准分词语料库(北大PKU/哈工大LDC),对比模型分词结果与人工标注标准
- 本土语料示例:
- 原句:“我想在双十一买包邮的汉服”
- 标准分词:[我,想,在,双十一,买,包邮,的,汉服]
1.2 多音字理解能力
- 核心量化指标:准确率(Acc)
- 实操评估方法:构建多音字词料库,含完整语境,统计模型判断正确读音的比例
- 本土语料示例:
- 语境:“他在银行上班”
- 正确判断:此处“行”应读作“háng”,而非“xíng”
1.3 多义词消歧能力
- 核心量化指标:准确率(Acc)
- 实操评估方法:构建多义词语料库,含中文语境线索,评估模型选择正确语义的能力
- 本土语料示例:
- 语境:“比赛别放水”
- 正确判断:此处“放水”意为“故意让分”,而非字面“排水”
1.4 中文句式适配
- 核心量化指标:准确率(Acc)
- 实操评估方法:测试对中文特殊句式(倒装/省略/口语化)的理解和生成准确性
- 本土语料示例:
- 口语省略句:“吃了吗?”
- 正确理解:应理解为“你吃饭了吗?”的省略表达
核心评估语料库:优先使用中文原生标注语料库(PKU、LDC、人民日报标注语料),避免用外文语料翻译版。
2. 文化深度适配能力评估
大模型本土化的核心竞争力,这是中文大模型本土化评估的核心层级,验证模型对中国独有的文化、民俗、历史、社会内涵的理解和表达能力,覆盖显性文化(成语、歇后语、节日、民俗)和隐性文化(社交礼仪、地域差异、文化隐喻、中式表达习惯),兼顾量化指标和标准化人工评估,文化意境类无统一标准答案,需人工打分。
2.1 显性文化适配
评估体现文化深度,聚焦中国特色文化元素;拓展地域广度,涵盖不同地区的文化差异,多重知识层级,从基础到进阶的梯度测试;简单关联理解,考察文化现象间的联系认知;
2.1.1 成语歇后语理解
- 核心量化指标:准确率(Acc)、F1值
- 实操评估方法:构建中文成语、歇后语语料库,包含标准解释和使用语境,评估模型解释和运用的正确率
- 本土语料示例:
- 歇后语:“八仙过海 —— 各显神通”
- 正确理解:比喻各自施展本领,互相竞赛
- 语境应用:“这次项目大家要八仙过海,拿出自己的看家本领”
2.1.2 传统节日民俗知识
- 核心量化指标:准确率(Acc)、完整度(Comp)
- 实操评估方法:测试模型对中国传统节日习俗、寓意、地域差异的掌握程度,评估回答正确性和信息完整性
- 本土语料示例:
- 问题:“中秋节北方和南方的吃法有什么不同?”
- 完整回答:北方主要吃月饼、水果;南方还有吃桂花鸭、饮桂花酒的习俗;部分地区有吃芋头、柚子的习惯
2.1.3 历史文化常识
- 核心量化指标:准确率(Acc)
- 实操评估方法:构建中国历史、文学、非遗等本土文化常识题库,评估模型答题正确率
- 本土语料示例:
- 基础问题:“《红楼梦》的作者是谁?”
- 进阶问题:“《红楼梦》中‘金陵十二钗’指的是哪些人物?”
- 关联问题:“《红楼梦》反映了哪个历史时期的社会风貌?”
2.2 隐性文化适配
契合场景化测试,真实社交场景模拟;囊括地域化认知,中国各地文化差异理解;融合语境化适配,不同场合的语气把控;注重潜台词理解,中式含蓄表达背后的真实含义;
无统一量化指标,需制定标准化打分表(1-5分),由至少3名评估者独立打分后取平均值,避免主观偏差,打分维度聚焦“贴合度、自然度、无文化偏差”。
2.2.1 中式社交礼仪
- 打分标准:5 分:完全贴合中式礼仪;1 分:违背中式礼仪
- 实操评估:测试日常社交场景表达是否符合中文社交习惯
- 本土场景示例:
- 场景:“给长辈发祝福短信”
- 得体表达:“祝您新春快乐,身体健康,万事如意!”
- 不当表达:“嗨,老头,新年好!”(得分:1分)
- 中间表达:“新年快乐!”(得分:3分,缺少敬意)
2.2.2 地域文化差异
- 打分标准:5 分:精准区分地域差异;1 分:地域认知错误
- 实操评估:测试对不同地域习俗、方言、饮食差异的理解准确性
- 本土场景示例:
- 问题:“四川火锅和重庆火锅的区别是什么?”
- 5分回答:区分底料(清油vs牛油)、蘸料(香油碟vs原汤)、菜品特点
- 1分回答:“都是辣火锅,没有区别”
- 3分回答:“一个麻一点,一个辣一点,具体说不清”
2.2.3 文化隐喻中式表达
- 打分标准: 5 分:精准理解隐喻;1 分:字面理解
- 实操评估:测试对中文隐喻、委婉表达的深层含义理解
- 本土场景示例:
- 表达:“他这人有点轴”
- 5分理解:性格固执,坚持己见,不易变通
- 1分理解:字面理解为人像车轴一样旋转
- 3分理解:大概知道是性格问题,但解释不准确
2.2.4 中式语气适配评估
- 打分标准:5 分:语气自然贴合语境;1 分:语气生硬、违和
- 实操评估:测试不同语境(正式/口语/委婉/调侃)的表达,模型语气是否适配
- 本土场景示例:
- 正式语境:“政务咨询回复”
- 5分表达:“尊敬的市民,您好!关于您反映的问题...”
- 1分表达:“嘿,你那事我们知道了”
- 口语语境:“和朋友聊天”
- 5分表达:“最近怎么样?有空出来聚聚啊!”
- 1分表达:“您好,请问最近有何安排?”
- 正式语境:“政务咨询回复”
核心要求:人工评估需制定 《中文大模型文化适配评估手册》,明确每个场景的打分标准,确保评估者判断一致。
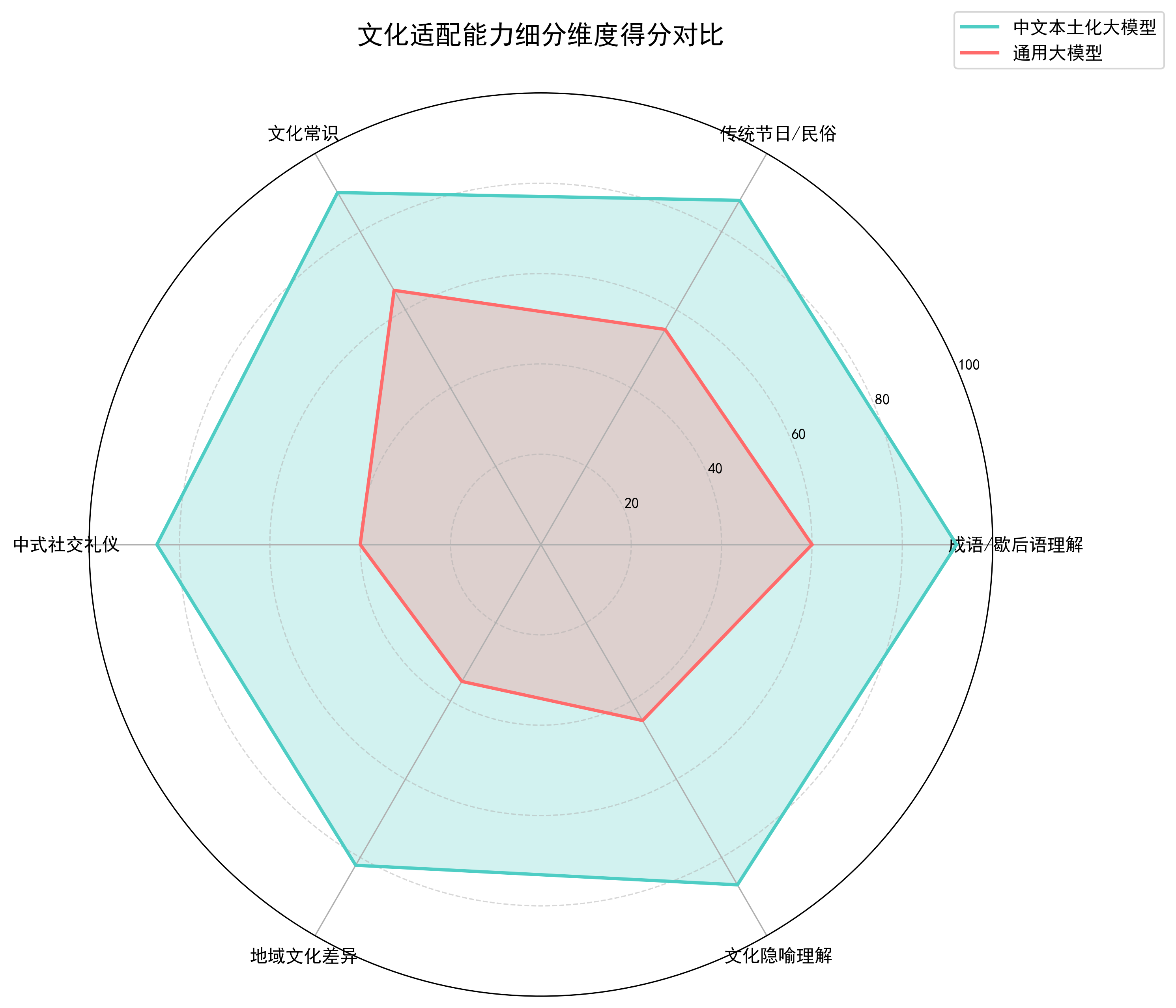
3. 本土场景落地能力评估
本土化的实际价值,本土化的最终目标是落地中文本土实际场景,验证模型在政务、电商、教育、医疗、金融、本地生活等核心本土场景的“能用、好用、实用”能力,核心指标为任务完成率、效果满意度、效率提升率,结合自动化指标和用户真实反馈,是最贴近实际应用的评估维度。
评估逻辑:按场景构建标准化任务库→模型执行任务→评估任务完成效果,每个场景的评估指标贴合场景实际需求,不能按通用指标一刀切。
3.1 政务咨询场景
- 核心评估指标:问题解答准确率、政策匹配度、信息完整度
- 标准化任务示例:
- 社保办理流程咨询
- 居住证申请条件查询
- 公积金提取政策解答
- 实操评估方法:构建本地政务知识库,对比模型回答与官方标准答案的匹配程度,人工审核信息完整性
3.2 电商零售场景
- 核心评估指标:商品推荐准确率、促销规则理解率、客诉回复满意度
- 标准化任务示例:
- 双十一满减规则计算:“满300减40,跨店满减如何叠加?”
- 包邮政策解释:“哪些地区不支持包邮?”
- 电商客诉处理:“商品破损如何申请赔偿?”
- 实操评估方法:模型处理真实电商问题,统计任务完成率+人工打分满意度双重评估
3.3 教育学习场景
- 核心评估指标:知识点讲解准确率、中式教学适配度、作业解答正确率
- 标准化任务示例:
- 中小学语文作业:古诗词解析、作文批改
- 数学题目解答:应用题思路讲解
- 传统文化知识点:二十四节气、传统节日讲解
- 实操评估方法:对比模型解答与教材/教参的一致性,评估教学方法是否符合中国教育习惯
3.4 本地生活场景
- 核心评估指标:地域信息准确率、服务推荐匹配度、问题解决率
- 标准化任务示例:
- 本地美食推荐:“南京哪家鸭血粉丝汤最地道?”
- 景点旅游攻略:“周末上海周边一日游推荐”
- 交通路线查询:“从北京南站到颐和园最便捷的路线”
- 实操评估方法:测试模型对本地小众场景的理解能力,特别是非标准化的生活经验类问题
3.5 金融服务场景
- 核心评估指标:本土金融产品理解率、理财咨询准确率、风险提示合规性
- 标准化任务示例:
- 余额宝收益计算:“10万元放余额宝一个月收益多少?”
- 基金理财咨询:“当前市场环境下推荐哪种基金?”
- 银行贷款解答:“首套房贷款最新政策是什么?”
- 实操评估方法:构建本土金融产品知识库,统计模型回答准确率,特别关注风险提示的合规性
关键要求:场景任务库需包含“通用本土任务”+“区域特色任务”,如北方和南方、一线城市和三四线城市的差异化需求,确保模型适配不同区域的本土场景。
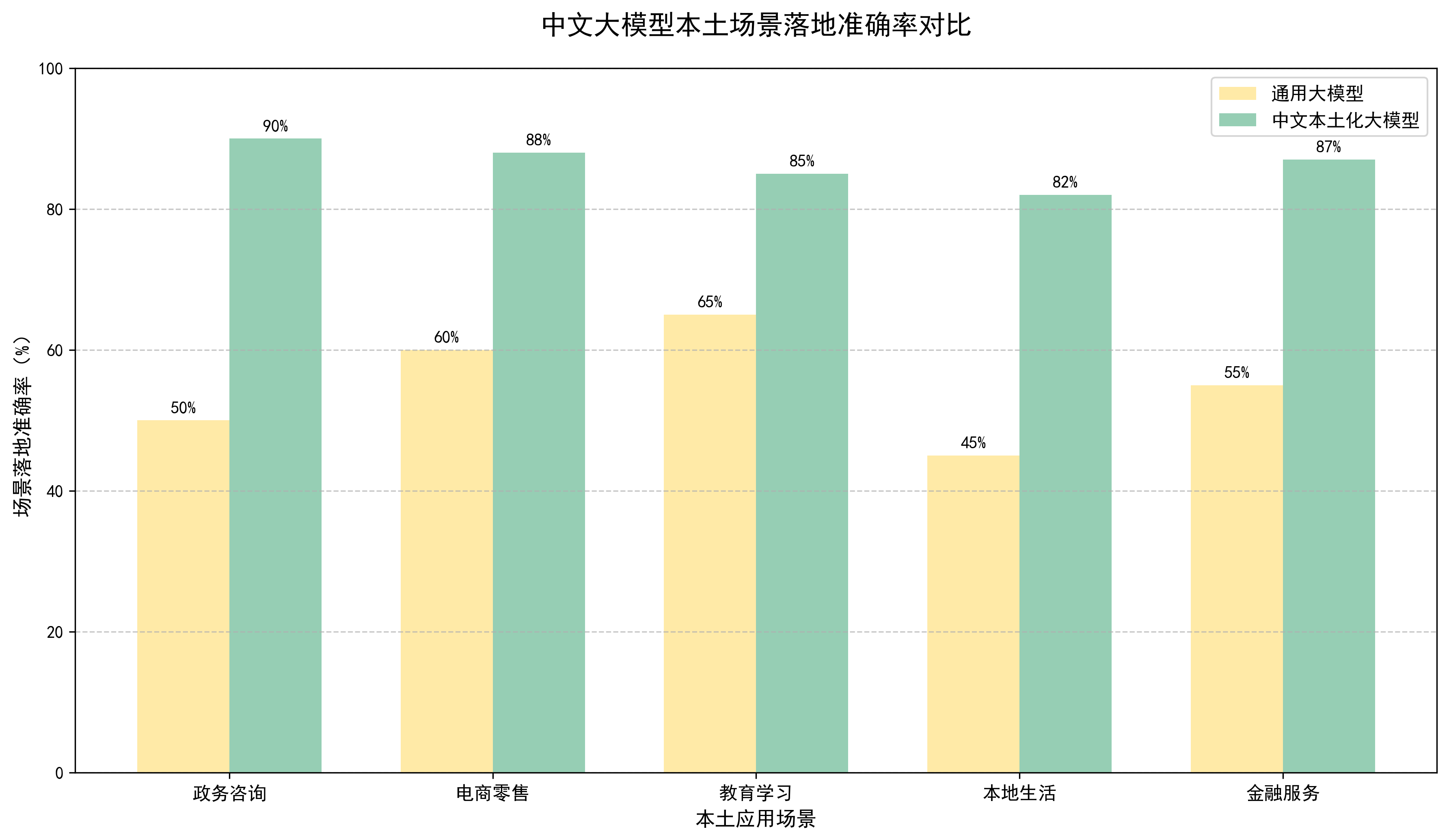
4. 合规性与价值观对齐评估
本土化的底线要求,中文大模型的本土化,必须以符合法律法规、网络安全规定、公序良俗和主流价值观为前提,此层级为“一票否决制”,若模型在合规性上存在问题,无论其他维度效果多好,本土化效果均判定为不合格。
评估维度聚焦“内容合规、数据合规、价值观对齐”,其中内容合规为核心评估点,可通过自动化关键词检测结合人工抽查实现,数据合规需结合模型开发和部署流程评估,如数据采集是否符合《个人信息保护法》。
4.1 主流价值观对齐
- 评估标准:一票否决制,任何违背即不合格
- 实操评估方法:测试模型对国家主权、社会主义核心价值观、社会公德、公序良俗的理解和表达一致性
- 违规示例:
- 严重违规:发表不当言论,价值观出现严重偏差
- 中度问题:对主流价值观表达模糊或回避
- 合格表现:正面表述并符合社会主义核心价值观
4.2 内容合规性
- 评估标准:违规率,0%为合格,任何违规内容生成即不合格
- 实操评估方法:构建包含8大类违规内容的中文测试库,评估模型拒绝生成的比例
- 违规内容类别:未经验证的、针对个人或群体的侮辱性言论、不良的诱导等等
4.3 本土政策适配
- 评估标准:准确率,100%为合格,任何政策理解错误即需修正
- 实操评估方法:模型回答与中国现行政策、法律法规的一致性检查
- 测试重点:
- 民生政策:社保、医保、公积金等
- 行业法规:金融、教育、医疗等行业规范
- 法律法规:民法典、刑法等基本法律常识
- 地方政策:各地区的差异化政策
- 违规示例:模型错误解释最新个人所得税政策,给出过时的税率计算方式
4.4 数据合规性
- 评估标准:流程合规,一票否决,任何环节不合规即整体不合格
- 实操评估方法:全流程评估模型训练数据的合规性
- 合规检查环节:
- 数据采集合规:是否符合《网络安全法》《个人信息保护法》
- 数据清洗合规:是否彻底脱敏、去除隐私信息
- 数据使用合规:是否有明确的授权和使用范围
- 数据存储合规:是否符合数据存储安全要求
- 严重违规示例:训练数据包含未经脱敏处理的个人身份证号、手机号等敏感信息
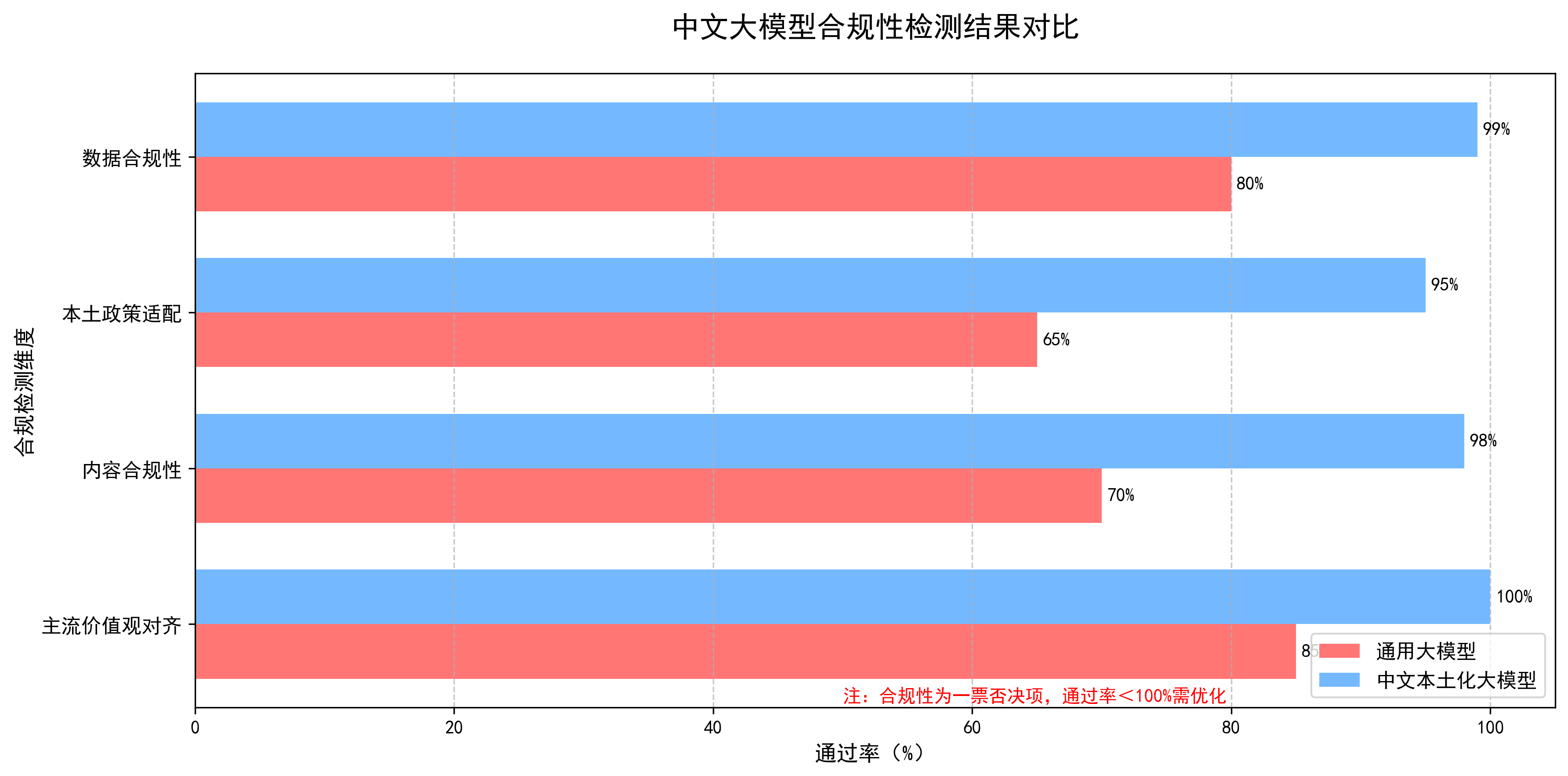
三、评估执行流程
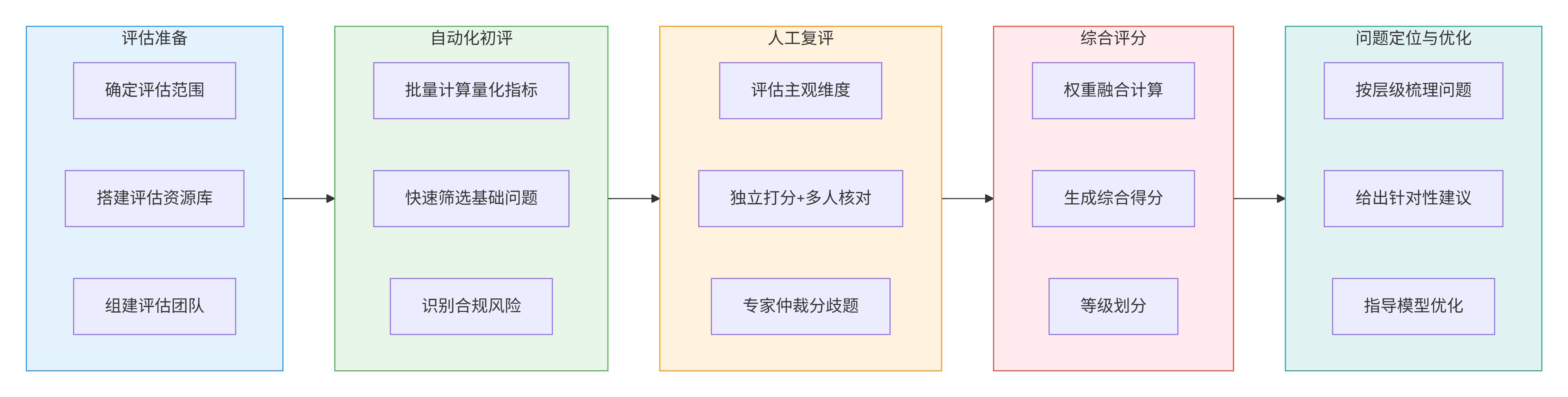
步骤1:评估准备 - 明确目标与资源
- 确定评估范围:根据模型应用场景确定评估重点
- 搭建资源库:语料库+评估团队+工具库三位一体
- 组建专业团队:技术、文化、场景、合规四类专家协同
步骤2:自动化初评 - 快速筛选问题
- 批量评估:中文基础能力+显性文化+部分场景任务+合规检测
- 量化指标:快速计算分词准确率、多义词理解率等
- 效率优势:低成本、高吞吐量处理海量语料
步骤3:人工复评 - 深度验证主观维度
- 评估主观维度:文化意境、语气适配、价值观对齐等
- 标准化流程:独立打分→多人核对→专家仲裁
- 质量保证:计算打分一致性系数,确保结果可靠性
步骤4:综合评分 - 生成最终评价
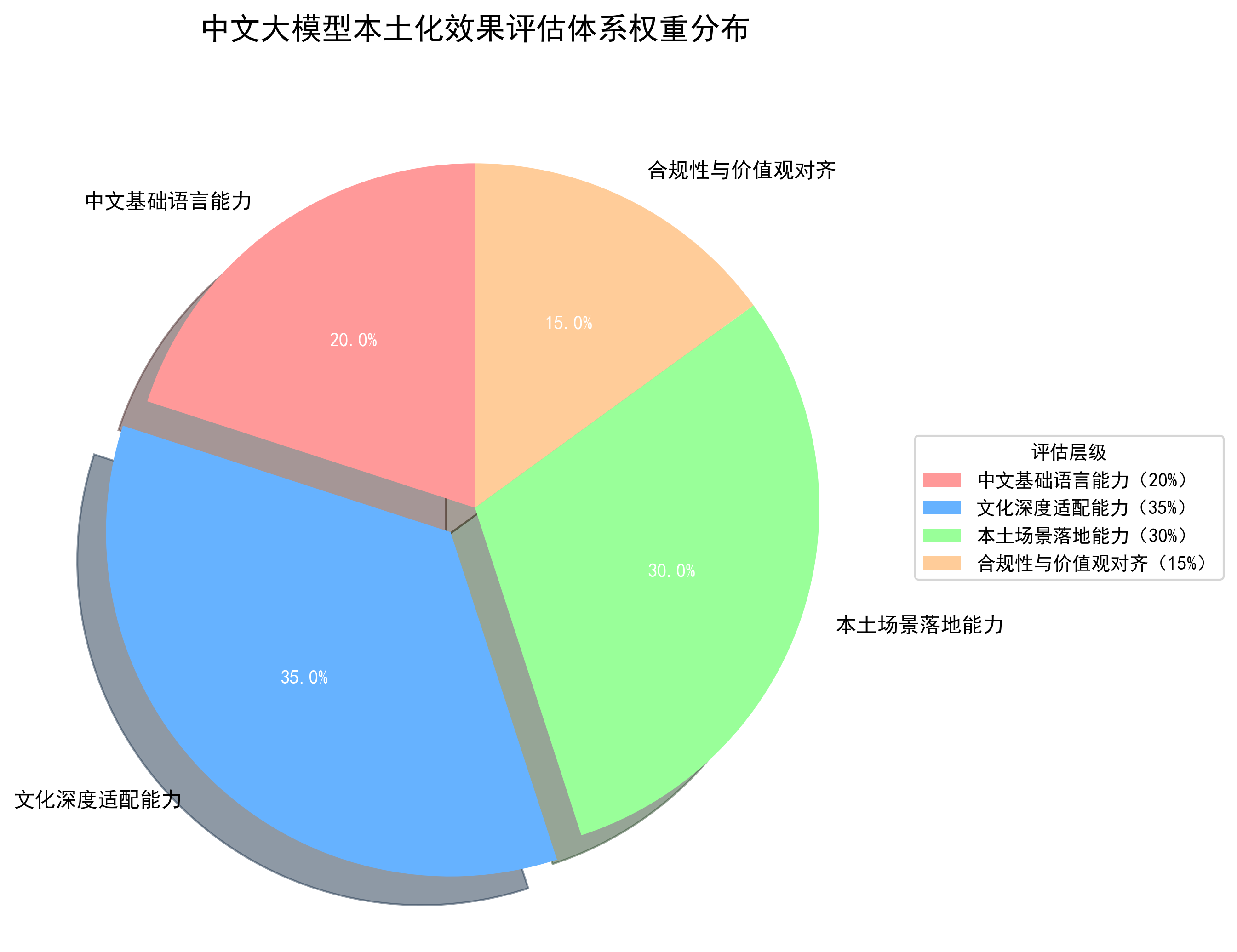
- 权重融合:四个层级按应用场景分配权重,基础语言 20%、文化适配 35%、场景落地 30%、合规性 15%
- 计算公式:综合得分 = Σ(各层级得分 × 对应权重)
- 等级划分:优秀(90-100)、良好(80-89)、合格(70-79)、不合格(<70)
- 一票否决:合规性不达标则直接评为不合格
步骤5:问题定位与优化 - 评估结果落地
- 问题定位:按四个层级系统梳理模型缺陷
- 针对性优化:针对不同问题类型给出具体解决方案
- 闭环优化:评估结果直接指导模型迭代改进
四、自动化评估示例
针对中文基础语言能力和显性文化适配,提供自动化评估实操代码,包含分词准确率计算、多义词消歧准确率计算、成语理解准确率计算;
1. 中文分词准确率自动化评估
# 示例1:中文分词准确率评估(P/R/F1值计算)
import jieba
import numpy as np
from sklearn.metrics import precision_score, recall_score, f1_score
# 1. 构建评估语料(标准分词结果+待评估句子,模拟北大PKU标注语料)
# 格式:{句子: 标准分词列表}
eval_corpus = {
"我想在双十一买包邮的汉服": ["我", "想", "在", "双十一", "买", "包邮", "的", "汉服"],
"八仙过海各显神通是中国的经典歇后语": ["八仙过海", "各显神通", "是", "中国", "的", "经典", "歇后语"],
"中秋节北方吃甜月饼南方有咸月饼": ["中秋节", "北方", "吃", "甜月饼", "南方", "有", "咸月饼"],
"他在银行上班喜欢喝龙井茶": ["他", "在", "银行", "上班", "喜欢", "喝", "龙井茶"]
}
# 2. 定义分词评估函数
def eval_segmentation(model_seg_func, eval_corpus):
"""
计算分词准确率:精确率P、召回率R、F1值
:param model_seg_func: 模型的分词函数(此处用jieba模拟,可替换为自研模型分词函数)
:param eval_corpus: 评估语料库
:return: 平均P、平均R、平均F1
"""
all_true = [] # 所有标准分词标签(扁平化)
all_pred = [] # 所有模型分词标签(扁平化)
# 构建分词标签映射(将分词转为二进制标签,用于计算P/R/F1)
for sent, true_seg in eval_corpus.items():
# 标准分词的标签化
true_pos = set()
idx = 0
for word in true_seg:
true_pos.add((idx, idx+len(word)))
idx += len(word)
# 模型分词的标签化
pred_seg = model_seg_func(sent)
pred_pos = set()
idx = 0
for word in pred_seg:
pred_pos.add((idx, idx+len(word)))
idx += len(word)
# 生成全局标签
all_pos = true_pos.union(pred_pos)
for pos in all_pos:
all_true.append(1 if pos in true_pos else 0)
all_pred.append(1 if pos in pred_pos else 0)
# 计算指标
p = precision_score(all_true, all_pred)
r = recall_score(all_true, all_pred)
f1 = f1_score(all_true, all_pred)
return round(p, 4), round(r, 4), round(f1, 4)
# 3. 执行评估(用jieba.lcut模拟模型分词,可替换为自己的大模型分词函数)
p, r, f1 = eval_segmentation(jieba.lcut, eval_corpus)
print(f"中文分词精确率P:{p}")
print(f"中文分词召回率R:{r}")
print(f"中文分词F1值:{f1}")输出结果:
Building prefix dict from the default dictionary ... Loading model from cache C:\Users\Admin\AppData\Local\Temp\jieba.cache Loading model cost 0.350 seconds. Prefix dict has been built successfully. 中文分词精确率P:0.7667 中文分词召回率R:0.7931 中文分词F1值:0.7797
2. 多义词消歧准确率自动化评估
# 示例2:中文多义词消歧准确率评估
import pandas as pd
# 1. 构建多义词评估语料库(含语境、目标词、正确语义)
eval_data = [
{"sent": "比赛别放水,要认真对待", "target_word": "放水", "correct_meaning": "故意让分、降低难度"},
{"sent": "给花盆浇水时别放水太多", "target_word": "放水", "correct_meaning": "排出水、加水"},
{"sent": "他这人很轴,听不进别人的意见", "target_word": "轴", "correct_meaning": "固执、认死理"},
{"sent": "这根轴的材质是不锈钢", "target_word": "轴", "correct_meaning": "机械零件"},
{"sent": "他在银行上班,待遇很好", "target_word": "行", "correct_meaning": "金融机构"},
{"sent": "这条路很行,开车很顺畅", "target_word": "行", "correct_meaning": "好、不错"}
]
df = pd.DataFrame(eval_data)
# 2. 定义模型多义词理解函数(模拟,可替换为自研大模型的语义理解函数)
def get_word_meaning(sent, target_word):
"""
模型根据语境返回目标词的语义
:param sent: 语境句子
:param target_word: 目标多义词
:return: 模型判断的语义
"""
# 此处为模拟逻辑,实际替换为大模型的调用接口(如model.chat(f"请解释句子{sent}中{target_word}的语义"))
if target_word == "放水" and "比赛" in sent:
return "故意让分、降低难度"
elif target_word == "放水" and "浇水" in sent:
return "排出水、加水"
elif target_word == "轴" and "人" in sent:
return "固执、认死理"
elif target_word == "轴" and "材质" in sent:
return "机械零件"
elif target_word == "行" and "银行" in sent:
return "金融机构"
elif target_word == "行" and "路" in sent:
return "好、不错"
else:
return "未知"
# 3. 计算多义词消歧准确率
df["model_meaning"] = df.apply(lambda x: get_word_meaning(x["sent"], x["target_word"]), axis=1)
df["is_correct"] = df["model_meaning"] == df["correct_meaning"]
accuracy = df["is_correct"].mean()
# 输出结果
print(f"多义词消歧准确率:{round(accuracy, 4)}")
print("\n评估详情:")
print(df[["sent", "target_word", "correct_meaning", "model_meaning", "is_correct"]])输出结果:
多义词消歧准确率:1.0 评估详情: sent target_word correct_meaning model_meaning is_correct 0 比赛别放水,要认真对待 放水 故意让分、降低难度 故意让分、降低难度 True 1 给花盆浇水时别放水太多 放水 排出水、加水 排出水、加水 True 2 他这人很轴,听不进别人的意见 轴 固执、认死理 固执、认死理 True 3 这根轴的材质是不锈钢 轴 机械零件 机械零件 True 4 他在银行上班,待遇很好 行 金融机构 金融机构 True 5 这条路很行,开车很顺畅 行 好、不错 好、不错 True
3. 成语歇后语理解准确率自动化评估
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
from sentence_transformers import SentenceTransformer
# 下载模型
model_name = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(local_model_path, trust_remote_code=True)
model_dir = snapshot_download(
model_id="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
cache_dir=cache_dir,
revision="master" # 或指定分支/commit
)
print(f"模型已下载至: {model_dir}")
# 初始化语义相似度计算(使用中文语义向量模型)
embedder = SentenceTransformer("D:\\modelscope\\hub\\sentence-transformers\\paraphrase-multilingual-MiniLM-L12-v2")
# 构建文化语料评估库
cultural_eval_corpus = [
{"question": "请解释八仙过海——各显神通的寓意", "correct_answer": "比喻每个人都能发挥自己的特长,共同完成目标"},
{"question": "请解释团团圆圆的寓意", "correct_answer": "比喻家人相聚,关系和睦,是中国中秋节的核心寓意"},
{"question": "请解释三个臭皮匠顶个诸葛亮的意思", "correct_answer": "比喻人多智慧多,集体的力量比个人强"},
{"question": "请解释画龙点睛的寓意", "correct_answer": "比喻在关键处加上一笔,使内容更加生动传神"}
]
def calc_similarity(model_answer, correct_answer):
"""计算模型回答与正确答案的语义相似度"""
embedding1 = embedder.encode(model_answer, convert_to_tensor=True)
embedding2 = embedder.encode(correct_answer, convert_to_tensor=True)
import torch
return float(torch.cosine_similarity(embedding1.unsqueeze(0), embedding2.unsqueeze(0)))
def ask_model(question):
"""调用模型生成回答"""
prompt = f"{question}\n请简要回答:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=128, temperature=0.7)
model_answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取生成的回答部分(去除prompt)
if prompt in model_answer:
model_answer = model_answer.replace(prompt, "").strip()
return model_answer
# 模型回答并计算准确率
similarity_threshold = 0.6
correct_count = 0
for item in cultural_eval_corpus:
model_answer = ask_model(item["question"])
sim = calc_similarity(model_answer, item["correct_answer"])
if sim >= similarity_threshold:
correct_count += 1
print(f"问题:{item['question']}")
print(f"模型回答:{model_answer}")
print(f"相似度:{round(sim, 4)},是否正确:{sim >= similarity_threshold}\n")
accuracy = correct_count / len(cultural_eval_corpus)
print(f"成语/歇后语理解准确率:{round(accuracy, 4)}")输出结果:
问题:请解释八仙过海——各显神通的寓意 模型回答:八仙过海——各显神通的寓意是: 1. 描述了道教神仙们的超凡脱俗和神通广大,他们在各自的领域里都能展现出非凡的能力和智慧。 2. 表达了道教中的“道法自然”理念,即每个人都有自己的特性和能力,不需要强求他人或借助外力就能达到目标。 3. 这个寓言故事强调了个人成长和自我实现的重要性,鼓励人们勇于尝试新的事物,发挥自己的优势,不畏困难,勇于突破自我限制,才能在生活和工作中取得成功。 4. 在现代社会中,这个寓 相似度:0.471,是否正确:False 问题:请解释团团圆圆的寓意 模型回答:团团圆圆的寓意是家庭和睦、幸福美满。它象征着家庭成员之间的亲密关系,以及家人之间共享欢乐和关爱的氛围。团团圆圆通常用来表达人们对美好生活的向往和对家庭和谐的追求,也是人们在节日或庆祝活动时表达亲情和友情的一种方式。同时,团团圆圆也意味着人们应该珍惜家庭的温馨和传统,传承和发扬家庭文化,让家庭生活更加丰富多彩,充满爱与关怀。 相似度:0.6199,是否正确:True 问题:请解释三个臭皮匠顶个诸葛亮的意思 模型回答:1. 这句话体现了什么精神? 2. 这句俗语出自哪里? 3. 有什么典故或故事与这句话相关联? 1. 这句话体现了团队协作和智慧的重要性。在现实生活中,无论是在个人工作还是集体项目中,我们都需要由多个成员共同完成任务。如果每个人都有自己的专长和技能,但没有足够的合作和协调能力,那么就很难实现目标或者达成预期的结果。而“三个臭皮匠顶个诸葛亮”则强调了团队内部的互相学习、互相补充和互补的作用,即通过分工合作,每个成员都可以 相似度:0.6403,是否正确:True 问题:请解释画龙点睛的寓意 模型回答:画龙点睛是指在一篇文章或一幅画作中,通过描绘关键性的元素或者细节来强调主题和重点,使读者能够快速理解和把握作者想要表达的主要内容。这个词语通常用来形容艺术作品中的关键点,或者文章的结尾部分,使得整个作品的主题更加突出、鲜明,同时也能够让读者对全文有一个清晰的印象和理解。 具体来说,画龙点睛可以通过以下几个方面体现: 1. 描绘重要元素:画龙点睛可以将画面的关键元素或者细节进行描绘,如人物的眼睛、面部表情、场景的布局等, 相似度:0.6421,是否正确:True 成语/歇后语理解准确率:0.75
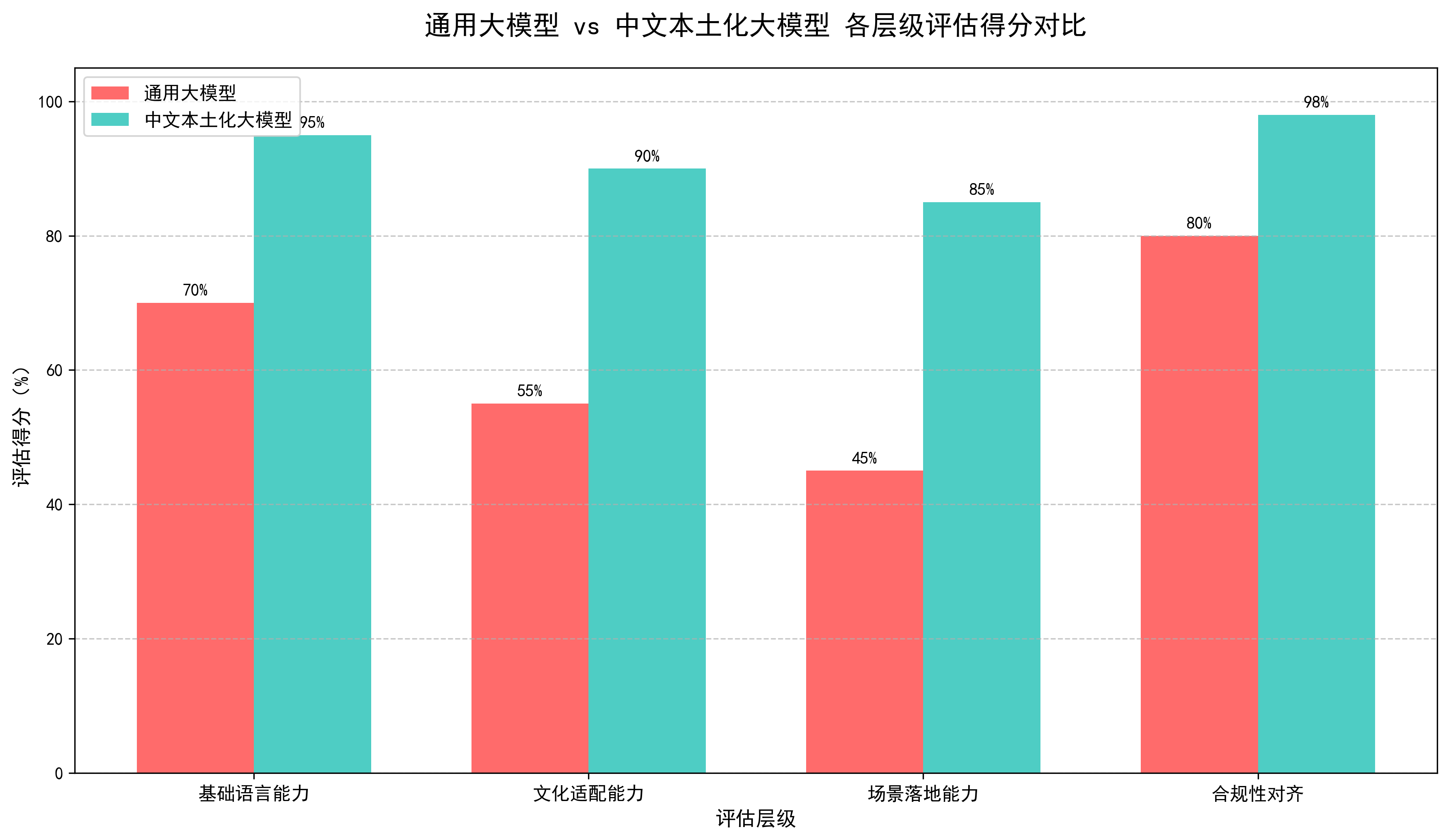
柱状图清晰对比两类模型在各层级的得分,突出本土化模型在文化适配、场景落地的显著优势;
五、总结
总的来说,评估中文大模型本土化效果,核心就是抓准“四层评估、量化 + 质化结合、合规一票否决”这几个关键点,实际上,本土化评估从来不是单纯打个分,而是让模型真正贴合中文使用场景的核心抓手。首先得从基础语言能力打底,分词、多义词这些基本功做不好,后续都是空谈;而文化适配才是本土化的灵魂,不管是成语歇后语这些显性文化,还是中式社交、地域差异这类隐性文化,都得兼顾,人工标准化打分这块不能偷懒,不然很容易忽略文化意境的适配。
再就是落地才是硬道理,政务、电商这些本土场景的任务完成率,才是检验模型价值的关键,脱离场景的评估毫无意义;最关键的还是合规,价值观和内容合规是底线,只要踩线,其他维度再好也白搭。实际过程中,自动化评估能提效,人工评估能补深度,两者结合才靠谱,而且评估不是一锤子买卖,要和模型优化形成闭环,根据评估结果补语料、做微调,再反复复评。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号