Hermes Agent 技术架构深度解析:110K+ Star,自进化 AI Agent 架构设计
原创
Hermes Agent 技术架构深度解析:110K+ Star,自进化 AI Agent 架构设计
原创
术哥
发布于 2026-05-07 23:05:06
发布于 2026-05-07 23:05:06
Hermes Agent 技术架构深度解析:110K+ Star,自进化 AI Agent 架构设计
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 91 篇,Hermes 最佳实战第 1 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
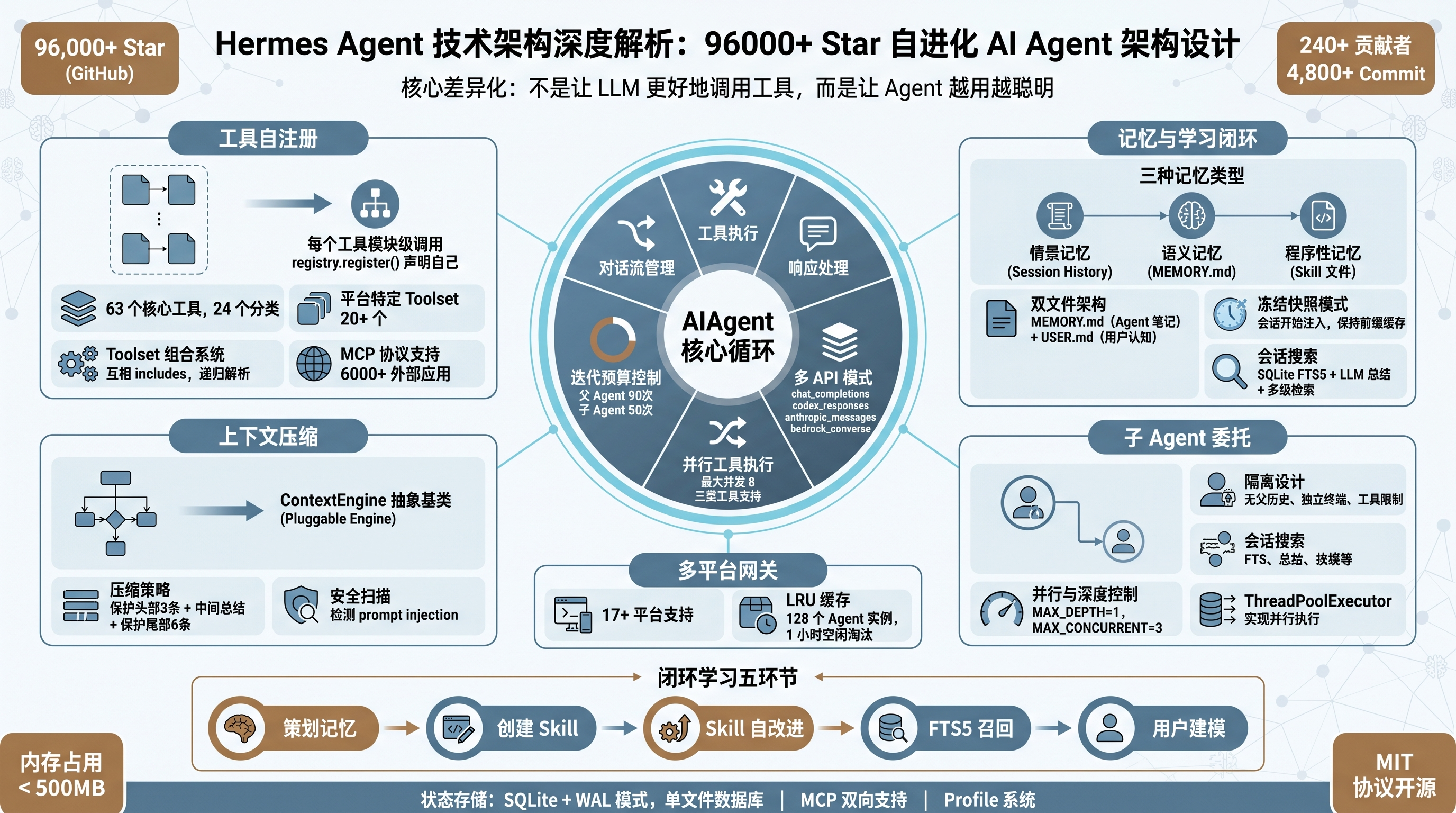
封面图:Hermes Agent 架构全景图
2026 年 2 月,Nous Research 发布了一个叫 Hermes Agent 的开源项目。两个月后,GitHub Star 数冲到 96,000+(截止发稿已经 110K),贡献者超过 240 人,Commit 数超过 4,800 次。
数据很猛,但说实话,开源项目 Star 涨得快不一定代表技术强。翻了代码库和官方文档之后,我的判断是:这个项目在架构设计上确实有东西 - 尤其是它把闭环学习(Closed Learning Loop)做成了原生能力,不是事后打补丁,而是从 Day 1 就融入了核心架构。
当前市面上大部分 Agent 框架的思路是:让 LLM 更好地调用工具。Hermes Agent 的思路不一样:让 Agent 越用越聪明。这个方向差异决定了整个架构的设计取舍。
这篇文章从源码出发,把 Hermes Agent 的架构拆开来看。重点不是介绍它有什么功能(README 写得够详细了),而是分析它为什么这样设计,以及这些设计决策背后的取舍。
1. 项目定位与核心差异化
Hermes Agent 的官方定位是 self-improving AI agent - 自进化 AI Agent。这个定位和市面上绝大多数 Agent 框架拉开了距离。
大多数 Agent 框架解决的问题是:怎么让 LLM 更好地调用工具。Hermes Agent 解决的是:怎么让 Agent 越用越聪明。
具体来说,它的闭环学习包含五个环节:
- 策划记忆:任务完成后,Agent 自主判断什么值得记住
- 创建 Skill:识别重复模式,自动生成 Markdown 格式的 Skill 文件
- Skill 自改进:现有 Skill 失败时自动优化
- FTS5 召回:按需检索历史对话(SQLite 全文索引)
- 用户建模:从行为推断偏好(Honcho 方言式建模)
完成任务 → 策划记忆 → 创建 Skill → Skill 自改进 → FTS5 召回 → 用户建模 → (循环)这套机制对应认知科学的三种记忆类型:情景记忆(会话历史)、语义记忆(MEMORY.md 持久事实)、程序性记忆(Skill 文件)。
项目采用 MIT 协议开源,技术栈以 Python 3.11+ 为主,支持 OpenAI、Anthropic、Bedrock、OpenRouter 等多种模型后端。官方列出的支持列表包括 Nous Portal、OpenRouter(200+ 模型)、NVIDIA NIM、OpenAI GPT-5.x、Anthropic Claude Opus 4.6、Google Gemini 3.1 Pro、DeepSeek、Hugging Face(20+ 开放模型)、Ollama(本地模型)等。切换模型只需一条 hermes model 命令,不需要改代码。
2. 核心架构概览
先看目录结构,能快速理解系统的职责划分:
目录/文件 | 职责 |
|---|---|
| AIAgent 主类,Agent 循环核心 |
| 40+ 工具实现(终端、浏览器、文件、搜索、MCP) |
| Toolset 定义和组合系统 |
| System Prompt 组装器 |
| 记忆管理(双 Provider 架构) |
| 上下文引擎(可插拔) |
| 轨迹压缩器 |
| SQLite 状态存储(FTS5 全文搜索) |
| 多平台消息网关 |
| 内置 Skill 库(24 个分类) |
| 插件系统 |
| CLI 接口(51 个模块) |
| 执行环境后端(local/Docker/SSH/Daytona/Singularity/Modal) |
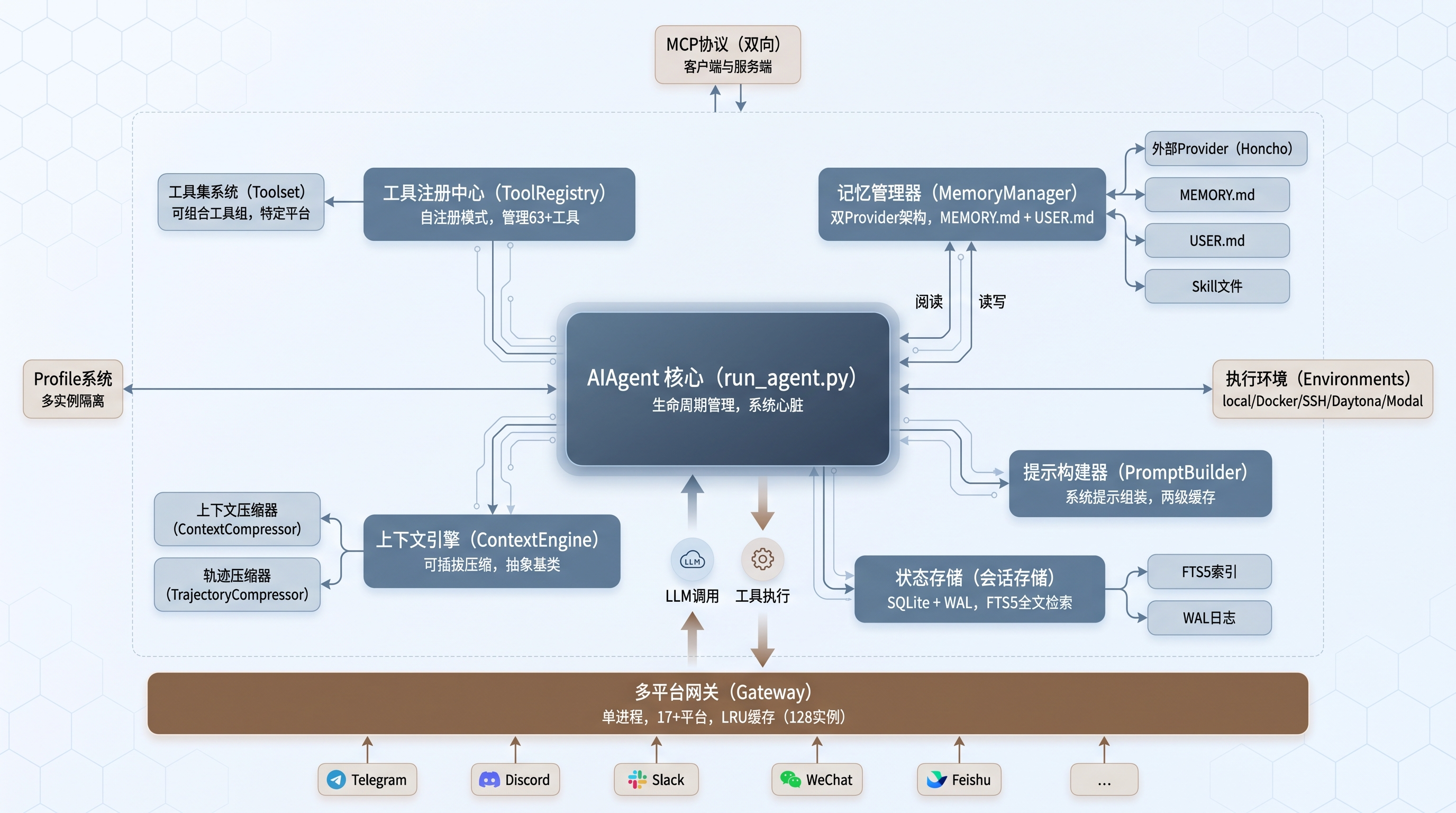
系统架构总览图
图 1:Hermes Agent 系统架构总览
架构上的几个关键设计决策:
- Agent 循环和工具执行在同一进程:通过
run_agent.py中的AIAgent类管理整个生命周期,没有用微服务那套东西 - 工具自注册模式:每个工具文件在模块级别调用
registry.register()声明自己,不需要中心化的注册表 - 上下文压缩可插拔:
ContextEngine是抽象基类,默认实现是ContextCompressor,可以替换 - 状态存储用 SQLite + WAL:单文件数据库,支持多读者 + 单写者,适合网关的多平台并发场景
- MCP 双向支持:既能作为 MCP 客户端连接外部工具服务器,也能作为 MCP 服务端被 Cursor、VS Code 等接入
还有一个值得注意的设计:Profile 系统。v0.6.0 引入了多实例 Profile,每个 Profile 拥有独立的配置、记忆库、会话历史、Skill 集合和工具权限。这意味着你可以在同一台机器上跑多个独立的 Agent 实例,互不干扰 - 比如一个用于工作项目,一个用于个人自动化。
内存占用方面,不跑本地 LLM 的情况下,Agent 进程本身占用不到 500MB。官方宣称可以在 $5/月的 VPS 上运行,这个数据从架构上看是合理的 - SQLite 很轻,Agent 实例的主要开销在对话历史的内存占用上。
3. Agent 循环深度拆解
run_agent.py 中的 AIAgent 类是整个系统的心脏。它管理对话流、工具执行、响应处理的全流程。
Agent 循环的基本流程是:接收用户消息 → 构建请求(含 system prompt + 记忆 + 上下文) → 调用 LLM → 解析响应 → 如果包含工具调用则执行工具 → 把工具结果加入上下文 → 再次调用 LLM → 直到 LLM 不再请求工具调用 → 返回最终响应。
这个循环有几个关键的控制机制值得展开说说。
迭代预算控制
Agent 循环不是无限运行的。IterationBudget 类实现了一个线程安全的迭代计数器,用来看住 Agent 的执行预算:
- 父 Agent 默认 90 次迭代
- 子 Agent 默认 50 次迭代
这个设计解决的是一个很实际的问题:Agent 有时候会陷入死循环,反复调用同一个工具。迭代预算到了就强制停止,防止 token 烧穿。
并行工具执行
Agent 循环中的一个关键判断逻辑在 _should_parallelize_tool_batch() 方法中。它把工具分成三类:
分类 | 策略 | 典型工具 |
|---|---|---|
| 永远不并行 |
|
| 只读安全,可并行 |
|
| 路径隔离,条件并行 |
|
最大并发工作线程数硬编码为 8(_MAX_TOOL_WORKERS)。
这个设计说明团队对 Agent 的实际使用场景做过深入思考。比如 web_search 和 read_file 都是纯读操作,并行执行完全安全。但 write_file 和 patch 操作同一文件时就有冲突风险,所以需要路径隔离检查。
中断与转向机制
Agent 在执行过程中可能会收到用户的新指令。Hermes Agent 的处理方式是 _interrupt_requested + _pending_steer 双标志位设计:
- 不打断当前正在执行的工具:等工具批次完成后再处理
- 注入转向指令:把用户的新需求作为
_pending_steer注入下一轮对话
这个选择很务实。如果强行中断正在执行的 write_file,可能导致文件写了一半。等工具批次完成再转向,保证了操作的原子性。
多 API 模式
AIAgent 支持四种 API 模式:chat_completions、codex_responses、anthropic_messages、bedrock_converse。模型提供商路由是自动检测的,支持 OpenAI、Anthropic、Bedrock、OpenRouter、Copilot ACP 等。
这意味着同一套 Agent 逻辑可以无缝切换底层模型,不需要改业务代码。从代码结构看,模型提供商的检测逻辑在 AIAgent 的初始化阶段完成,之后整个会话期间保持不变。如果需要切换模型,需要创建新的 Agent 实例。
PromptBuilder 也是这个环节的关键组件。agent/prompt_builder.py 负责组装完整的 system prompt,包含多个层次:DEFAULT_AGENT_IDENTITY(核心身份定义)、平台特定提示、技能索引、上下文文件、记忆快照等。其中 MEMORY_GUIDANCE 区分了声明式事实和命令式指令,告诉模型记忆内容应该怎么用。TOOL_USE_ENFORCEMENT_GUIDANCE 则指导模型如何正确使用工具。
PromptBuilder 还有一个两级缓存机制来加速 Skill 索引的读取:LRU 缓存(内存中)+ 磁盘快照(持久化)。这在 Skill 数量很多的时候能明显减少启动时间。
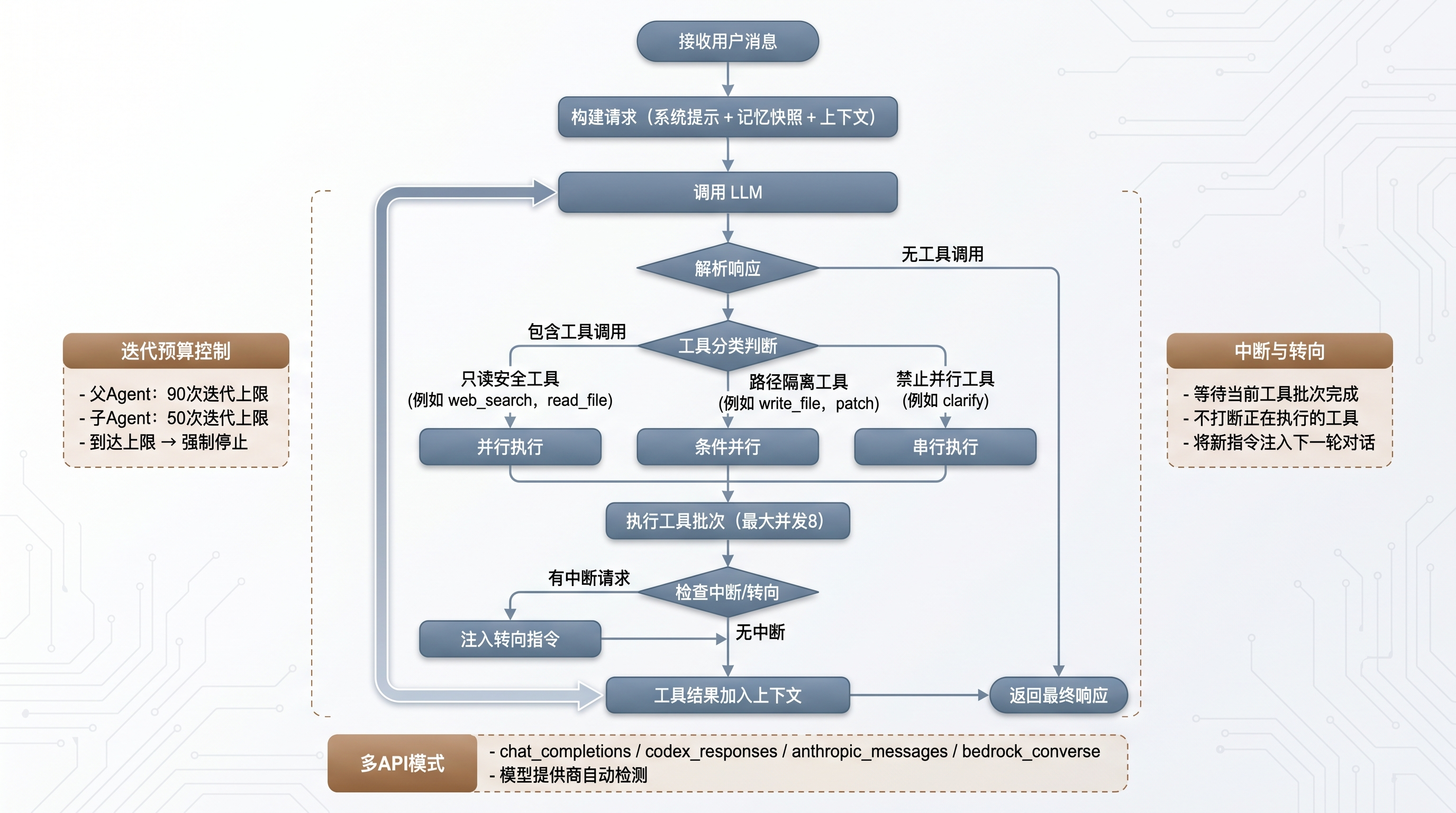
Agent 循环流程图
图 2:Agent 循环流程图 — 迭代预算控制、并行工具执行、中断与转向机制
4. 工具系统:自注册 + Toolset 组合
ToolRegistry 自注册模式
工具系统的核心在 tools/registry.py。它采用了一个很优雅的自注册模式:
每个工具文件在模块级别调用 registry.register(),声明自己的 schema、handler、toolset 归属。注册表用 threading.RLock() 保证线程安全,读取时做快照。
# tools/registry.py 中的 ToolEntry 结构(简化)
class ToolEntry:
name: str # 工具名
toolset: str # 所属工具集
schema: dict # JSON Schema
handler: callable # 处理函数
check_fn: callable # 检查函数
requires_env: bool # 是否需要执行环境
is_async: bool # 是否异步
description: str # 描述
emoji: str # 显示图标发现机制也很有意思:discover_builtin_tools() 通过 AST 分析检测哪些 .py 文件包含 registry.register() 调用,不需要手动维护工具列表。
动态注册/注销场景主要用于 MCP 服务器刷新:MCP 工具上线时调用 register(),下线时调用 deregister()。
Toolset 组合系统
toolsets.py 实现了一个组合式工具集系统。Toolset 之间可以互相 includes,支持递归解析。
核心工具列表 _HERMES_CORE_TOOLS 包含 63 个工具,所有平台共享:
类别 | 工具举例 |
|---|---|
Web |
|
终端 |
|
文件 |
|
视觉 |
|
技能 |
|
浏览器 |
|
规划 |
|
代码执行 |
|
定时任务 |
|
其他 |
|
平台特定 toolset 如 hermes-cli、hermes-telegram、hermes-discord 等有 20 多个。hermes-gateway 是所有平台工具的并集。
这种组合式设计的好处是:新接入一个平台时,只需要定义该平台特有的工具,然后 includes 核心工具集就行。比如新增一个飞书适配器,只需要定义飞书的消息发送、消息格式化等平台特有工具,然后引用 hermes-gateway 的基础工具集。
从代码组织上看,这种设计避免了工具的重复定义。一个 web_search 工具只存在一份实现,但可以通过不同的 toolset 暴露给不同的平台。同时,MCP 协议的支持(mcp_serve.py)让 Hermes Agent 可以接入 6,000+ 外部应用,这些 MCP 工具通过动态注册机制集成到 ToolRegistry 中。
5. 记忆与学习闭环
这是 Hermes Agent 和其他 Agent 框架拉开差距的地方。
双文件记忆架构
agent/memory_manager.py 中的 MemoryManager 采用双 Provider 架构:一个内置 Provider(管理 MEMORY.md 和 USER.md)+ 最多一个外部 Provider(如 Honcho)。
两个记忆文件的分工很明确:
- MEMORY.md:Agent 的个人笔记。记录环境事实、项目约定、工具的使用技巧
- USER.md:Agent 对用户的认知。记录偏好、沟通风格、期望
记忆注入时使用 <memory-context> 标签做上下文围栏,防止模型把记忆上下文误认为新的用户输入。tools/memory_tool.py 中还有一个安全扫描机制,检测注入/泄露模式 - 比如记忆内容中是否包含试图操控模型行为的恶意指令。
记忆条目之间用 §(section sign)分隔。这个选择挺有意思的,用一个不太常见的字符做分隔符,降低了和正文内容冲突的概率。
冻结快照模式
这个设计解决了一个很实际的问题:系统提示的稳定性。
会话开始时,MemoryManager 把当前的记忆内容作为快照注入系统提示。之后整个会话期间,系统提示保持不变 - 中途写入的记忆只更新磁盘文件,不刷新系统提示。
这样做的好处是保持前缀缓存有效。如果每次记忆更新都刷新系统提示,KV cache 就会失效,每次请求都要重新计算前面所有 token 的 KV 对。冻结快照让前缀缓存命中率大大提高。
这是一个典型的读写分离思路:读路径(会话开始时的快照注入)和写路径(中途更新磁盘文件)完全解耦。代价是 Agent 在一个会话内对记忆的修改,需要等到下一个会话才能被读取。对于大多数使用场景来说,这个延迟是可以接受的。
Skill 系统
tools/memory_tool.py 负责双存储的管理,Skill 文件存放在 ~/.hermes/skills/ 目录下,是标准的 Markdown 文件。
Skill 的创建和改进流程:
- Agent 完成一个复杂任务后,自动识别是否包含可复用的模式
- 如果有,生成 Markdown 格式的 Skill 文件,包含触发条件、执行步骤、注意事项
- 使用 Skill 时如果发现问题(过时、报错),立即 patch 更新
agent/prompt_builder.py 中的 SKILLS_GUIDANCE 提供了 Skill 创建和更新的指导规则。PromptBuilder 还实现了两级缓存(LRU + 磁盘快照)来加速 Skill 索引的读取。
会话搜索
hermes_state.py 中的 SessionDB 基于 SQLite FTS5 实现跨所有会话消息的全文搜索。搜索流程是:FTS5 召回相关片段 → LLM 总结 → 注入当前上下文。
prompt_builder.py 中的 SESSION_SEARCH_GUIDANCE 指导 Agent 何时以及如何使用会话搜索。
从数据流向看,完整的记忆召回链路是:用户提问 → Agent 判断是否需要历史信息 → 调用 session_search(FTS5 召回) → LLM 总结召回结果 → 结合 MEMORY.md/USER.md 的快照 → 形成完整的记忆上下文。这是一个多级检索的设计,不同类型的记忆走不同的通道。
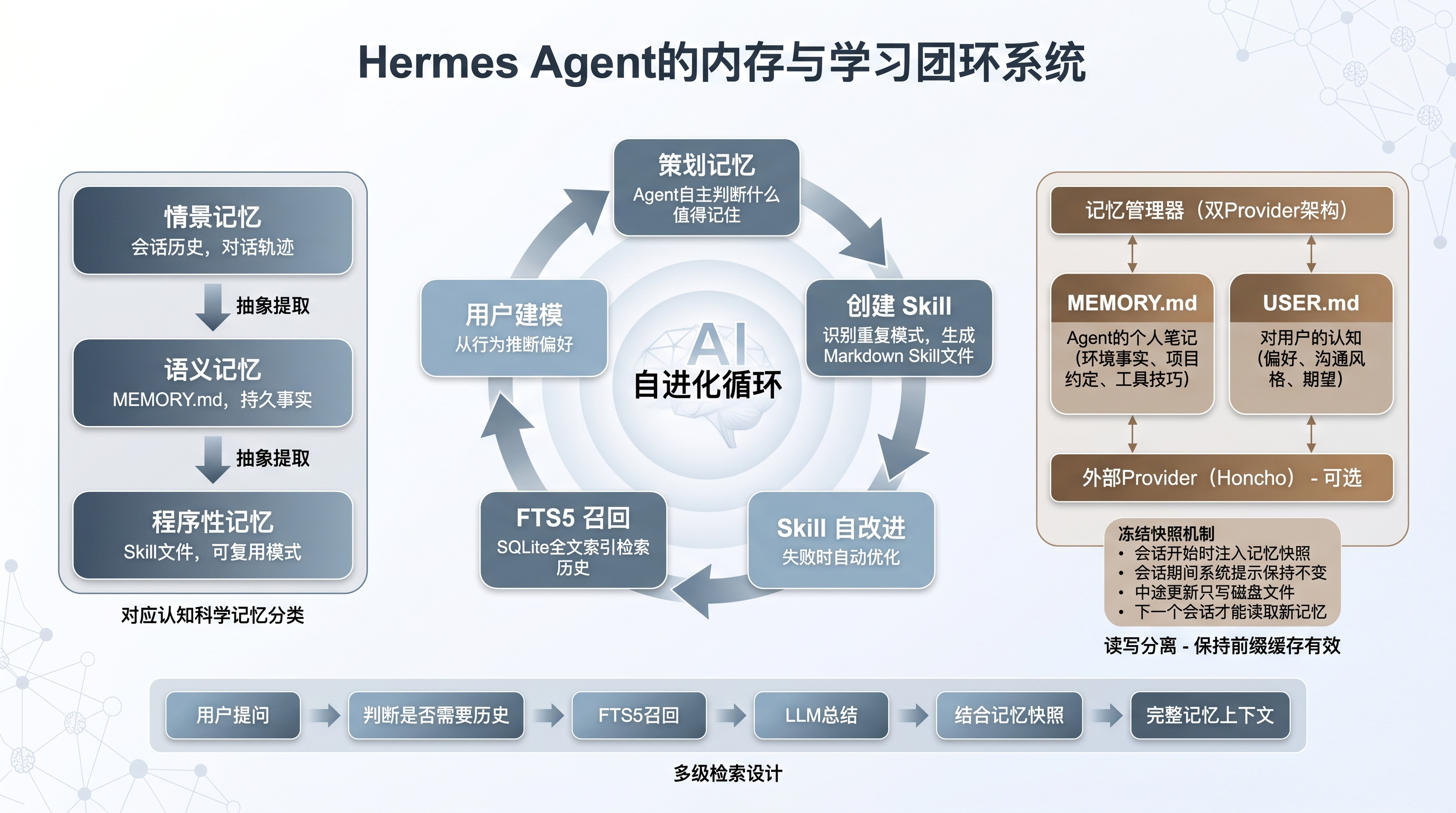
记忆与学习闭环图
图 3:记忆与学习闭环 — 五阶段循环 + 三层记忆架构 + 多级检索链路
你在项目中用过类似的记忆持久化方案吗?欢迎在评论区聊聊。
6. 上下文管理:可插拔压缩引擎
ContextEngine 抽象架构
agent/context_engine.py 定义了抽象基类 ContextEngine,agent/context_compressor.py 提供了默认实现 ContextCompressor。
可插拔设计意味着你可以实现自己的上下文管理策略,比如基于 RAG 的检索增强、基于重要性评分的选择性保留等。ContextEngine 的接口设计很简洁,核心就是接收当前对话历史和 token 预算,返回压缩后的上下文。
为什么要把上下文管理做成可插拔?因为不同使用场景对上下文的处理策略差异很大。编程场景需要保留完整的代码变更历史,对话场景需要保留情感上下文,数据分析场景需要保留中间结果。一个通用的压缩策略很难同时满足这些需求。
压缩策略详解
ContextCompressor 的压缩策略很讲究:
参数 | 默认值 | 作用 |
|---|---|---|
| 0.75 | 上下文使用率超过 75% 时触发压缩 |
| 3 | 保护前 3 条消息(通常是 system prompt + 用户初始请求) |
| 6 | 保护后 6 条消息(最近的对话上下文) |
压缩的具体流程:
- 保护头部和尾部:前 N 条和后 M 条消息不动
- 中间部分用辅助模型总结:不是简单截断,而是让另一个 LLM 生成结构化摘要
- 总结模板:包含已解决的问题、待处理的事项、活跃任务
- 工具输出裁剪:对工具返回的长文本做前置过滤,减少总结的 token 消耗
- 按比例分配 token 预算:中间部分的每段对话按比例分配总结的 token 预算
另外,trajectory_compressor.py 提供了轨迹压缩能力,主要用于科研场景的批量轨迹生成。
PromptBuilder 的安全扫描
agent/prompt_builder.py 还有一个容易被忽略的功能:_scan_context_content() 检测注入攻击。
上下文文件(.hermes.md、AGENTS.md、CLAUDE.md、.cursorrules)的优先级是 .hermes.md > AGENTS.md > CLAUDE.md > .cursorrules。安全扫描会检查这些文件中是否包含恶意指令,防止 prompt injection。
7. 子 Agent 委托机制
tools/delegate_tool.py 实现了子 Agent 委托机制,允许主 Agent 生成独立的子 Agent 实例来并行处理任务。
隔离设计
子 Agent 的隔离做得比较彻底:
- 无父历史:子 Agent 看不到父 Agent 的对话历史
- 独立终端会话:子 Agent 有自己的终端环境
- 工具限制:
DELEGATE_BLOCKED_TOOLS列表禁止子 Agent 使用特定工具
被禁止的工具包括递归委托(防止子 Agent 再生孙 Agent)、用户交互类工具(子 Agent 不应该直接和用户对话)、记忆写入工具(防止子 Agent 污染主 Agent 的记忆)。
并行与深度控制
# 子 Agent 关键配置
MAX_DEPTH = 1 # 默认扁平,最多可配到 3
MAX_CONCURRENT = 3 # 最多 3 个并行子 Agent并行执行通过 ThreadPoolExecutor 实现。多个子任务可以同时运行。
深度控制有两层含义:
- 委托深度:
_delegate_depth跟踪委托链的长度,默认MAX_DEPTH=1意味着子 Agent 不能再委托 - 角色模式:
leaf(叶节点,只能执行)或orchestrator(编排者,可以再次委托)
run_agent.py 中的 _active_children 管理所有活跃的子 Agent 实例。

子 Agent 委托架构图
图 4:子 Agent 委托架构 — 父子隔离、并行执行、深度控制
说实话,子 Agent 并发最多 3 个这个限制,社区里有人吐槽过。对于复杂的并行场景,3 个子 Agent 确实不够用。但从架构安全的角度看,限制并发数可以避免资源爆炸 - 每个 Agent 都有自己的终端会话和上下文,3 个就已经意味着 3 倍的资源消耗。
8. 多平台网关架构
gateway/run.py 实现了一个统一的消息网关,单一进程处理所有平台消息。
支持的平台
网关支持 17+ 个平台:
Telegram、Discord、Slack、WhatsApp、Signal、Email、SMS、Home Assistant、Mattermost、Matrix、DingTalk(钉钉)、Feishu(飞书)、WeChat(微信)、WeCom(企业微信)、QQ、BlueBubbles、Webhook。
Agent 缓存策略
网关用 LRU 缓存 + 空闲 TTL 淘汰来管理 Agent 实例:
- 缓存容量:128 个 Agent 实例
- 空闲淘汰:1 小时无活动自动清理
这个设计是为了平衡内存使用和响应速度。Agent 实例占用内存不小(需要维护对话历史、工具状态等),但每次创建新实例开销也大。LRU + TTL 是一个合理的折中。
网关与 Agent 循环的协作
网关收到消息后,会从缓存中查找或创建对应的 Agent 实例,然后把消息交给 Agent 的主循环处理。Agent 的响应再通过网关发回给对应平台。
这意味着同一个 Agent 可以同时服务多个平台 - 你可以在 Telegram 上开始一个对话,然后在 Discord 上继续。不同平台的消息格式差异(比如 Telegram 的 Markdown V2、Discord 的 Embed、Slack 的 Block Kit)在网关层统一处理,Agent 核心不需要关心这些细节。
v0.9.0(代号 "the everywhere release")还加入了 Termux(Android)和 iMessage 支持,进一步扩展了平台覆盖。
9. 状态持久化:SQLite + FTS5
hermes_state.py 中的 SessionDB 是整个系统的状态层。
技术选型
- SQLite + WAL 模式:支持多读者 + 单写者,适合网关多平台并发场景
- FTS5 全文搜索:跨所有会话消息的快速文本搜索
- Schema 版本控制:当前 v8,自动迁移
写竞争处理
SQLite 在高并发写入时容易出现锁竞争。SessionDB 的处理方式是随机抖动重试:15 次重试,每次等待 20-150ms 的随机时间。这个随机抖动可以避免多个写请求同时重试导致的护航效应(convoy effect)。
会话管理
get_compression_tip() 方法沿压缩-续链前进,追踪会话的完整历史。会话标题管理支持自动生成和唯一性约束,族系命名如 "title #2"、"title #3"。
所有数据存储在本地 ~/.hermes/ 目录,没有云端同步。搬家的时候拷贝目录就行。这种本地优先的设计在隐私敏感场景下是个加分项 - 你的对话历史和 Agent 记忆不会上传到任何云服务。
从选型上看,SQLite 在这里是一个恰到好处的选择。PostgreSQL 太重了,需要单独的数据库服务;纯文件存储又缺乏查询能力。SQLite + FTS5 提供了全文搜索、事务支持、WAL 并发,同时保持单文件部署的简洁性。对于 Agent 的状态管理场景来说,这是一个平衡得很好的方案。
总结
翻完 Hermes Agent 的代码库,几个架构层面的判断:
做得好的地方:
- 闭环学习是原生能力,不是事后加的补丁。从
PromptBuilder的MEMORY_GUIDANCE到MemoryManager的双文件架构,再到SessionDB的 FTS5 搜索,整套学习闭环在架构层面是贯通的 - 工具自注册 + Toolset 组合的设计很灵活,新接入平台只需定义差异部分
- 上下文压缩的可插拔架构给未来的优化留下了空间
- 迭代预算 + 中断机制体现了对 Agent 实际运行问题的深入理解
需要关注的局限:
- 子 Agent 并发上限 3 个,复杂并行场景受限
- 项目迭代节奏很快 - 不到 3 周发布了 4 个大版本,稳定性需要观察
- Windows 原生不支持,必须通过 WSL2
- 关于抄袭的争议(中国团队指控架构级抄袭)目前还没有最终结论
从架构设计上看,Hermes Agent 最大的贡献是把 Mitchell Hashimoto 提出的 Harness Engineering 五大组件(指令层、约束层、反馈层、记忆层、编排层)做成了产品级的内建能力。这在 Agent 框架领域是比较少见的。
如果你在做 Agent 相关的架构设计,Hermes Agent 的闭环学习和上下文管理部分值得细看。开源生态里能做到这个完成度的 Agent 框架,目前确实不多。
你觉得 Hermes Agent 的闭环学习路线是正确的方向吗?评论区见。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号