大模型应用:LDA线性判别分析+大模型:小数据驱动的语义增强分类实战.105
原创
大模型应用:LDA线性判别分析+大模型:小数据驱动的语义增强分类实战.105
原创
未闻花名
发布于 2026-05-13 08:12:29
发布于 2026-05-13 08:12:29
一、模型探索
在现在做自然语言处理 NLP 的人里,几乎人人都绕不开一个特别头疼的问题:标注数据太少。不管是做文本分类、用户意图识别、客服工单归类,还是舆情分析、商品评论正负向判断,一到真实企业场景里,会发现理想和现实差距特别大,论文里动不动几万、几十万条数据,可到了公司内部,能拿得出手的标注样本往往就几百条、一两千条,多一点都很难。实际不是不想标,是标不动。业务场景太细分、标签太专业、人力成本高、迭代又快,很多项目刚标好数据,业务需求又变了。
这就直接导致两个特别尴尬的局面:
- 用传统机器学习吧,像 TF-IDF、朴素贝叶斯、SVM 这些,特征太浅,理解不了语义,小样本下泛化能力差,换两句表达方式不一样但意思一样的话,模型直接懵圈;
- 直接上大模型微调呢?参数多、能力强,但小数据特别容易过拟合,模型把训练集背得滚瓜烂熟,一上真实数据就翻车,而且部署重、成本高,很多小项目根本扛不住。
其实大家都一样,都遇到过这个难题,所以很长一段时间里,大家都卡在中间:数据不够,大模型不敢微调;传统算法又太弱,效果上不去。而今天尝试的这套 LDA 线性判别分析 + 大模型 的组合,就是专门为这种小数据、高要求、快落地的场景量身定做的。
思路特别简单、特别实用:
- 用大模型做 “语义增强”,把一句话变成一段有理解、有上下文、有真实含义的向量,让机器先 “读懂意思”;
- 再用 LDA 做特征降维 + 线性判别分类,把高维特征压到最适合分类的低维空间,让类别之间分得更开、类内更聚拢。
- 两者一结合,直接形成一个超强互补:大模型负责理解,LDA 负责高效分类;大模型提质量,LDA 提稳定;小数据也能跑出高精度。
不管是意图识别、舆情分类、评论分析、工单归类,还是各种小众垂类的文本任务,只要你标注数据不多、又想快速上线、还想要稳定效果,这套方案让人眼前一亮,不用大数据,不用狂调参,不用复杂框架,理解就能用,跑起来就有效果。

二、核心基础
1. 线性判别分析(LDA)
我们原来也分析过"潜在狄利克雷分配",也简称LDA,今天所分析的LDA不是主题模型,是分类降维算法,这个要先理解清楚:
- "潜在狄利克雷分配LDA"是无监督的主题模型;
- "线性判别分析LDA"是监督学习的降维、分类算法。
LDA的核心目标:
- 假设我们有两类数据,比如“正面舆情”和“负面舆情”,每一条数据都是一个高维向量。
- LDA 要做的是:找一个最优的“投影方向”,把高维数据投射到这个方向后,同一类的数据尽可能靠近,即类内方差最小,不同类的数据尽可能远离,即类间均值差最大。
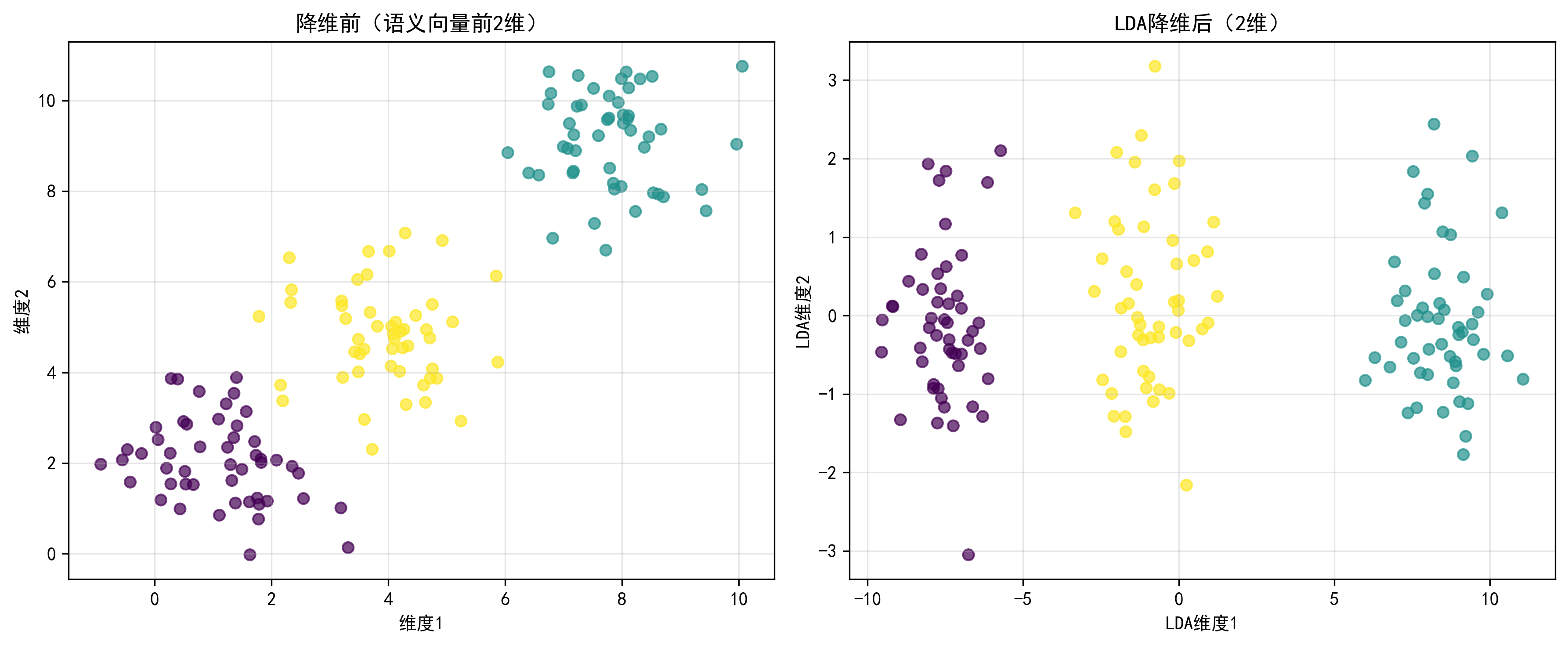
举个生活化的例子:有一堆红色和蓝色的小球,分布在三维空间中,肉眼很难直接区分。LDA 会找到一个平面,把这些小球投射到平面上,投射后红色小球都聚在左边,蓝色小球都聚在右边,边界清晰,这个“投射”就是降维,“区分红、蓝球”就是分类。
LDA 的核心优势:
- 有监督降维:不同于PCA,PCA是无监督,只关注数据方差,而LDA在降维时会结合类别标签,降维后的特征更适合分类任务;
- 线性高效:基于线性变换,计算速度快,对硬件要求低,适合小数据场景;
- 分类 + 降维一体:既能输出降维后的特征,也能直接完成分类,无需额外训练分类器,当然也可以只用来降维,搭配其他分类器。
2. 大模型语义增强
大模型语义增强让机器读懂文本的真实意思,传统文本特征(如 TF-IDF)的本质是词频统计,比如“我喜欢这个手机,电池续航超棒”和“这个手机续航差,我不喜欢”,两者的词频高度重叠,但语义完全相反 ,TF-IDF 无法区分这种差异,而大模型可以。
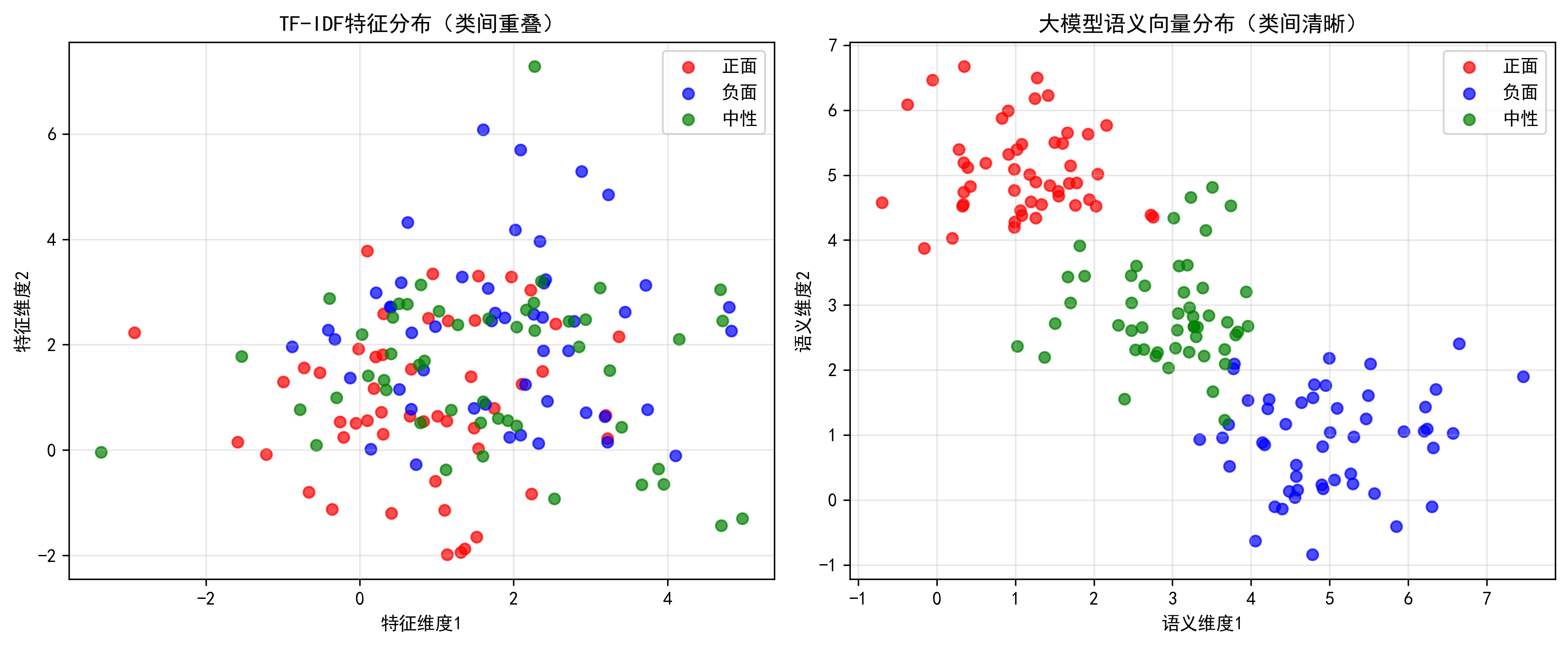
大模型的语义增强核心逻辑:
- 大模型通过海量文本预训练,学到了词语的上下文语义和文本的整体意图,能将任意长度的文本转化为一个固定维度的语义向量(Embedding),这个向量能精准反映文本的真实含义。
比如:
- 输入“苹果手机续航好”,大模型输出的向量和“iPhone 电池能用一整天”的向量高度相似;
- 输入“苹果公司发布新耳机”,大模型输出的向量和“Apple推出新款AirPods”的向量高度相似;
- 而“苹果手机续航好”和“苹果公司发布新耳机”的向量差异极大,这就是语义理解的价值。
常用的语义增强大模型:
- 通用场景:BERT、RoBERTa、DistilBERT,轻量版,适合小数据;
- 中文场景:BERT-Chinese、ERNIE、ChatGLM;
- 轻量部署:MiniLM、ALBERT,参数量小,推理快。
3. LDA + 大模型的优势
在传统文本分类中,我们通常会遇到两个核心问题:
- 特征维度灾难:文本经过 TF-IDF、Word2Vec 等编码后,特征维度动辄上千甚至上万,高维特征会导致模型计算量大、过拟合风险高,尤其是小数据场景;
- 语义理解不足:传统特征工程(如 TF-IDF)仅能捕捉词频统计信息,无法理解文本的深层语义,比如“苹果”是水果还是公司,分类准确率受限;
- 小数据瓶颈:标注数据少的时候,无论是传统机器学习还是大模型微调,都难以学到稳定的分类模式,传统算法欠拟合,大模型过拟合。
而 “LDA + 大模型” 的组合恰好能解决这三个问题:
- 大模型(如 BERT、LLaMA)将文本转化为语义向量,相比传统特征更能捕捉文本的真实意图;
- LDA 作为经典的线性判别算法,既能对高维语义向量做降维,压缩特征维度,降低计算成本,又能基于降维后的特征做分类,最大化类间差异,提升分类精度;
- 两者结合后,即使只有几百条标注数据,也能利用“语义增强 + 维度优化”的优势,实现媲美大数据场景的分类效果。
4. 小数据分类的价值体现
小数据分类的核心是“特征质量”而非“数据数量”,我们通常会误以为分类效果好必须靠大数据,但实际上特征的质量远比数量重要。
比如:
- 用 TF-IDF 做特征,即使有 10 万条数据,也可能因语义理解不足导致分类准确率 80%;
- 用大模型语义向量 + LDA 降维,即使只有 1000 条数据,也能让准确率提升到 95% 以上。
"LDA + 大模型"的核心逻辑就是:在语义层面用大模型提升特征质量,用LDA优化特征维度,进行降维、类间区分,从而突破小数据的限制。
三、简单原理
1. 了解语义向量
语义向量就是我们常说的Embedding,它是将文本(字、词、句子、文档)转化为的数值向量,核心要求是:语义相似的文本,向量距离近;语义不同的文本,向量距离远。
传统向量(如 One-Hot)的问题:
- 维度爆炸:比如有1万个词,One-Hot向量维度就是1万;
- 无语义信息:“苹果”和“iPhone”的One-Hot向量完全正交,即距离最远,但语义高度相似。
大模型语义向量的优势:
- 固定维度:无论文本多长,输出的向量维度固定,比如 768 维;
- 语义稠密:向量中的每个数值都包含语义信息,能反映文本的上下文和整体意图;
- 泛化能力强:即使文本中有未见过的词,也能通过上下文推断语义。
2. 生成语义向量的方式
我们无需深入大模型的训练细节,重点了解如何用大模型生成语义向量,主要有两种方式:
2.1 静态嵌入:
- 代表模型:Word2Vec、GloVe、FastText;
- 逻辑:每个词对应一个固定向量,句子向量是词向量的平均值或加权和;
- 优势:计算快、部署简单;
- 劣势:无法处理一词多义,比如“苹果”的向量固定,无法区分是水果还是公司。
2.2 动态嵌入:
- 代表模型:BERT、ERNIE、ChatGLM;
- 逻辑:词的向量随上下文变化,句子向量是 [CLS] token 的输出(BERT)或所有 token 的均值;
- 优势:能处理一词多义,语义理解更精准;
- 劣势:计算量比静态嵌入大,但轻量版(如 DistilBERT)可平衡速度和效果。
在“LDA + 大模型”方案中,优先选择动态嵌入,得到的语义质量更高,我们的示例也基于动态嵌入展开。
3. 语义增强对LDA的价值
LDA的效果依赖于输入特征的质量,如果输入的是无语义的 TF-IDF 特征,LDA 再优秀也难以区分语义相似但标签不同的文本;而大模型的语义向量能为LDA提供高质量数据,具体体现在:
- 提升类间区分度:语义向量能让不同类别的文本(如“正面舆情”和“负面舆情”)在高维空间中天然形成更清晰的聚类;
- 降低噪声干扰:大模型能过滤文本中的无关信息(如语气词、错别字),保留核心语义,减少 LDA 计算中的噪声;
- 适配小数据:大模型的预训练知识能弥补标注数据的不足,即使小数据也能生成有区分度的特征。
4. 小数据分类的核心逻辑
小数据分类的最大挑战是“数据分布不完整”,模型无法学到所有可能的样本模式,容易过拟合或欠拟合。
"LDA + 大模型"解决小数据问题的核心逻辑:
- 1. 迁移学习补信息:大模型通过海量无标注数据预训练,学到了通用的语言知识,将这种知识迁移到小数据分类任务中,相当于用海量无标注数据弥补标注数据的不足;
- 2. 降维减少过拟合:高维特征(如768维语义向量)在小数据场景中容易过拟合,维度越多,需要的标注数据越多,LDA 将其降维到C−1维,比如3分类降到2维,大幅降低过拟合风险;
- 3. 有监督降维提效果:LDA 在降维时结合类别标签,让降维后的特征更聚焦于“区分不同类别”,而非单纯的“保留数据方差”。
举个直观的例子:
- 纯大模型微调:用1000条标注数据微调 768 维的 BERT,相当于用 1000 个样本拟合 768 个参数,极易过拟合,模型记住了训练数据,但对新数据预测不准;
- LDA + 大模型:先用 BERT 生成 768 维语义向量,利用预训练知识,特征质量高,再用 LDA 降到 2 维(参数减少,过拟合风险低),最后用 LDA 分类(最大化类间差异),既利用了大模型的语义优势,又通过 LDA 解决了小数据过拟合问题。
方案对比差异:
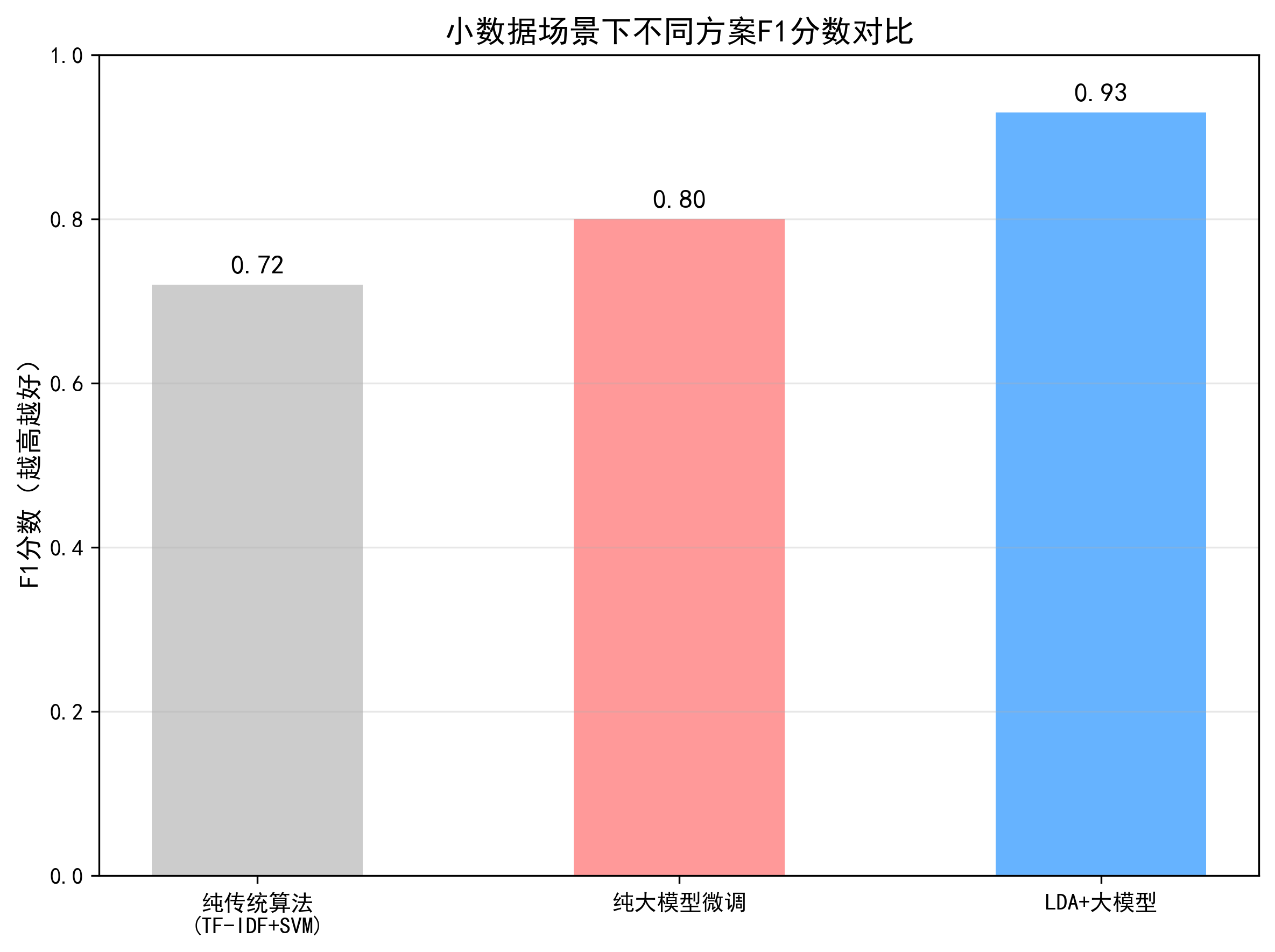
结论:在小数据文本分类场景中,“LDA + 大模型”是兼顾效果、效率、成本的最优解。
四、执行流程
我们基于小数据场景示例完整的体现执行过程;
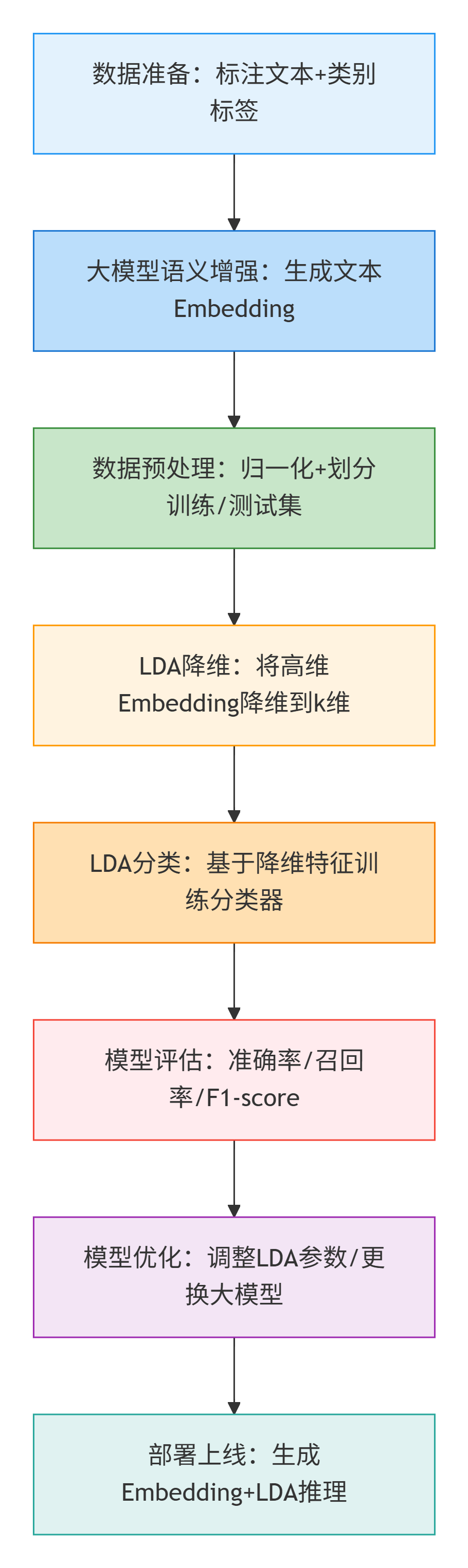
步骤 1:数据准备
- 1. 数据格式要求
文本分类任务的标注数据通常包含两列:
- text:文本内容,如舆情评论、用户意图语句、新闻正文;
- label:类别标签。如正面 / 负面 / 中性、支付 / 查询 / 退款、科技 / 财经 / 娱乐。
示例数据(舆情分类,1000 条标注数据):
text | label |
|---|---|
这款手机续航超棒,性价比很高 | 正面 |
快递速度太慢,客服态度也差 | 负面 |
产品质量一般,无功无过 | 中性 |
- 2. 数据预处理
在生成语义向量前,需要对文本做基础清洗,避免无关信息干扰:
- 1. 去除特殊字符,如 @、#、表情符号;
- 2. 去除多余空格和换行;
- 3. 中文场景:统一大小写,如“iPhone”→“iphone”、去除无意义的语气词,如“啊”、“哦”;
- 4. 无需分词:大模型(如 BERT)能直接处理原始文本,无需手动分词。
步骤 2:大模型语义增强
生成 Embedding,这是核心步骤之一 ,我们用 Python 实现“基于 BERT-Chinese 生成中文文本的语义向量”
代码实现:生成语义向量
import torch
import pandas as pd
import numpy as np
from transformers import BertTokenizer, BertModel
# 1. 加载预训练的BERT-Chinese模型和分词器
# 选择轻量版bert-base-chinese,适合初学者部署
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
# 设置设备(优先用GPU,没有则用CPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# 2. 定义生成语义向量的函数
def get_bert_embedding(text, max_length=128):
"""
输入文本,输出BERT生成的语义向量(768维)
:param text: 输入文本
:param max_length: 文本最大长度,超过截断,不足补零
:return: 768维的numpy数组
"""
# 分词并转换为模型输入格式
inputs = tokenizer(
text,
truncation=True, # 截断过长文本
padding='max_length', # 补零到max_length
max_length=max_length,
return_tensors='pt' # 返回PyTorch张量
)
# 将输入移到指定设备(GPU/CPU)
inputs = {k: v.to(device) for k, v in inputs.items()}
# 模型推理(不计算梯度,提升速度)
with torch.no_grad():
outputs = model(**inputs)
# 取[CLS] token的输出作为句子向量(BERT的标准做法)
# outputs.last_hidden_state.shape: [1, max_length, 768]
embedding = outputs.last_hidden_state[:, 0, :].squeeze().cpu().numpy()
return embedding
# 3. 加载示例数据并生成向量
# 直接创建示例数据
data = [
('这个产品非常好用,强烈推荐给大家!', '正面'),
('今天天气真不错,心情很好', '正面'),
('电影剧情很精彩,演员演技也很棒', '正面'),
('服务态度很好,会再次光临', '正面'),
('物流速度很快,包装也很好', '正面'),
('这次购物体验很差,很不满意', '负面'),
('产品质量太差了,退货了', '负面'),
('客服态度恶劣,很生气', '负面'),
('等了三天还没发货,太慢了', '负面'),
('电影太无聊了,浪费时间和金钱', '负面'),
('今天是个普通的日子', '中性'),
('产品功能一般,还行吧', '中性'),
('价格适中,没有特别突出', '中性'),
('就那样吧,没什么特别的', '中性'),
('正常使用,没什么问题', '中性'),
('这家餐厅的菜很好吃,特别是招牌菜', '正面'),
('这次旅行非常愉快,风景很美', '正面'),
('手机信号很差,经常断网', '负面'),
('配送员把包裹放错地方了,很麻烦', '负面'),
('这次考试成绩还可以', '中性'),
('老师讲得很清楚,收获很大', '正面'),
('会议时间太长了,有点疲惫', '负面'),
('这本书内容很丰富,值得阅读', '正面'),
('系统偶尔会卡顿,整体还行', '中性'),
('这个软件太复杂了,不好用', '负面'),
('今天的工作顺利完成,很开心', '正面'),
]
df = pd.DataFrame(data, columns=['text', 'label'])
# 批量生成语义向量(耗时取决于数据量,1000条约5-10分钟)
print("开始生成BERT语义向量...")
embeddings = []
for idx, text in enumerate(df['text']):
try:
emb = get_bert_embedding(text)
embeddings.append(emb)
print(f"[{idx+1}/{len(df)}] 成功处理: {text[:20]}...")
except Exception as e:
print(f"处理文本'{text}'时出错:{e}")
embeddings.append(np.zeros(768)) # 出错时填充零向量
# 将向量转换为numpy数组,方便后续LDA处理
X = np.array(embeddings)
# 提取标签(转换为数字,方便LDA处理)
label_mapping = {'正面': 0, '负面': 1, '中性': 2}
y = df['label'].map(label_mapping).values
# 保存向量和标签(避免重复计算)
np.save('bert_embeddings.npy', X)
np.save('labels.npy', y)
print("\n========== 处理完成 ==========")
print(f"✓ 总共处理文本数: {len(df)}")
print(f"✓ 生成的向量维度: {X.shape}")
print(f"✓ 向量保存文件: bert_embeddings.npy")
print(f"✓ 标签保存文件: labels.npy")
print(f"✓ 标签分布: 正面={sum(y==0)}, 负面={sum(y==1)}, 中性={sum(y==2)}")代码关键解释:
- 模型选择:bert-base-chinese是谷歌官方的中文 BERT 模型,参数量约 1.1 亿,适合初学者,轻量版如distilbert-base-chinese参数量更小,速度更快;
- 语义向量提取:BERT 输出的last_hidden_state中,第一个 token([CLS])是专门用于句子级任务的,因此取其作为句子向量;
- 设备适配:代码自动检测 GPU/CPU,无 GPU 也能运行,只是速度慢一些;
- 异常处理:避免个别文本处理出错导致程序中断,出错时填充零向量;
- 数据保存:生成语义向量耗时较长,保存为 npy 文件,后续可直接加载。
输出结果:
开始生成BERT语义向量... [1/26] 成功处理: 这个产品非常好用,强烈推荐给大家!... [2/26] 成功处理: 今天天气真不错,心情很好... [3/26] 成功处理: 电影剧情很精彩,演员演技也很棒... [4/26] 成功处理: 服务态度很好,会再次光临... [5/26] 成功处理: 物流速度很快,包装也很好... [6/26] 成功处理: 这次购物体验很差,很不满意... ...... [26/26] 成功处理: 今天的工作顺利完成,很开心... ========== 处理完成 ========== ✓ 总共处理文本数: 26 ✓ 生成的向量维度: (26, 768) ✓ 向量保存文件: bert_embeddings.npy ✓ 标签保存文件: labels.npy ✓ 标签分布: 正面=10, 负面=9, 中性=7
步骤 3:LDA 降维 + 分类
import numpy as np
import matplotlib.pyplot as plt
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
# 1. 加载之前生成的语义向量和标签
X = np.load('bert_embeddings.npy')
y = np.load('labels.npy')
# 2. 划分训练集和测试集(小数据场景建议测试集比例20%-30%)
# random_state固定为42,保证结果可复现
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y # stratify保证训练/测试集标签分布一致
)
# 3. 初始化LDA模型(降维+分类)
# n_components设置为类别数-1(3分类→2维),是LDA的最优降维维度
lda = LinearDiscriminantAnalysis(n_components=2)
# 4. 训练LDA模型(拟合+降维)
# fit_transform:先拟合模型,再对训练集降维
X_train_lda = lda.fit_transform(X_train, y_train)
# transform:用训练好的模型对测试集降维(注意:测试集只能用transform,不能fit)
X_test_lda = lda.transform(X_test)
# 5. LDA分类预测
y_pred = lda.predict(X_test)
# 6. 模型评估
print("=== LDA分类报告 ===")
print(classification_report(
y_test, y_pred,
target_names=['正面', '负面', '中性'] # 对应label_mapping
))
# 7. 可视化降维结果(直观展示分类效果)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示问题
plt.rcParams['axes.unicode_minus'] = False
# 创建画布
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
# 子图1:训练集降维结果
scatter1 = ax1.scatter(X_train_lda[:, 0], X_train_lda[:, 1], c=y_train, cmap='viridis', alpha=0.7)
ax1.set_title('LDA降维结果(训练集)', fontsize=14)
ax1.set_xlabel('LDA维度1', fontsize=12)
ax1.set_ylabel('LDA维度2', fontsize=12)
ax1.legend(handles=scatter1.legend_elements()[0], labels=['正面', '负面', '中性'])
ax1.grid(True, alpha=0.3)
# 子图2:测试集降维结果+预测标签
scatter2 = ax2.scatter(X_test_lda[:, 0], X_test_lda[:, 1], c=y_pred, cmap='viridis', alpha=0.7)
ax2.set_title('LDA降维结果(测试集,预测标签)', fontsize=14)
ax2.set_xlabel('LDA维度1', fontsize=12)
ax2.set_ylabel('LDA维度2', fontsize=12)
ax2.legend(handles=scatter2.legend_elements()[0], labels=['正面', '负面', '中性'])
ax2.grid(True, alpha=0.3)
# 保存图片(初学者可直接显示)
plt.tight_layout()
plt.savefig('lda_embedding_visualization.png', dpi=300, bbox_inches='tight')
# plt.show()
# 8. 混淆矩阵可视化(评估分类效果)
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(
cm,
annot=True, # 显示数值
fmt='d', # 数值格式为整数
cmap='Blues',
xticklabels=['正面', '负面', '中性'],
yticklabels=['正面', '负面', '中性']
)
plt.title('LDA分类混淆矩阵', fontsize=14)
plt.xlabel('预测标签', fontsize=12)
plt.ylabel('真实标签', fontsize=12)
plt.tight_layout()
plt.savefig('lda_confusion_matrix.png', dpi=300, bbox_inches='tight')
# plt.show()
# 9. 保存训练好的LDA模型(用于后续部署)
import joblib
joblib.dump(lda, 'lda_classifier.pkl')
print("LDA模型已保存为 lda_classifier.pkl")代码关键解释:
- 1. 数据划分:
- stratify=y:保证训练集和测试集的标签分布与原数据一致,小数据场景关键,避免某类样本在测试集中缺失;
- 测试集比例设为 20%:小数据场景中,训练集尽可能多,保证模型学到足够信息。
- 2. LDA 参数设置:
- n_components=2:3 分类任务中,LDA 的最大降维维度是 2(C−1),这是最优维度,既能保留最大类间差异,又能最小化维度;
- fit_transform vs transform:训练集用fit_transform拟合 + 降维,测试集只能用transform,避免数据泄露,保证模型泛化性。
- 3. 模型评估:
- classification_report:输出准确率(precision)、召回率(recall)、F1-score(综合指标),是分类任务的核心评估指标;
- 混淆矩阵:直观展示模型在每个类别上的预测对错,比如“负面”样本有多少被误判为“中性”。
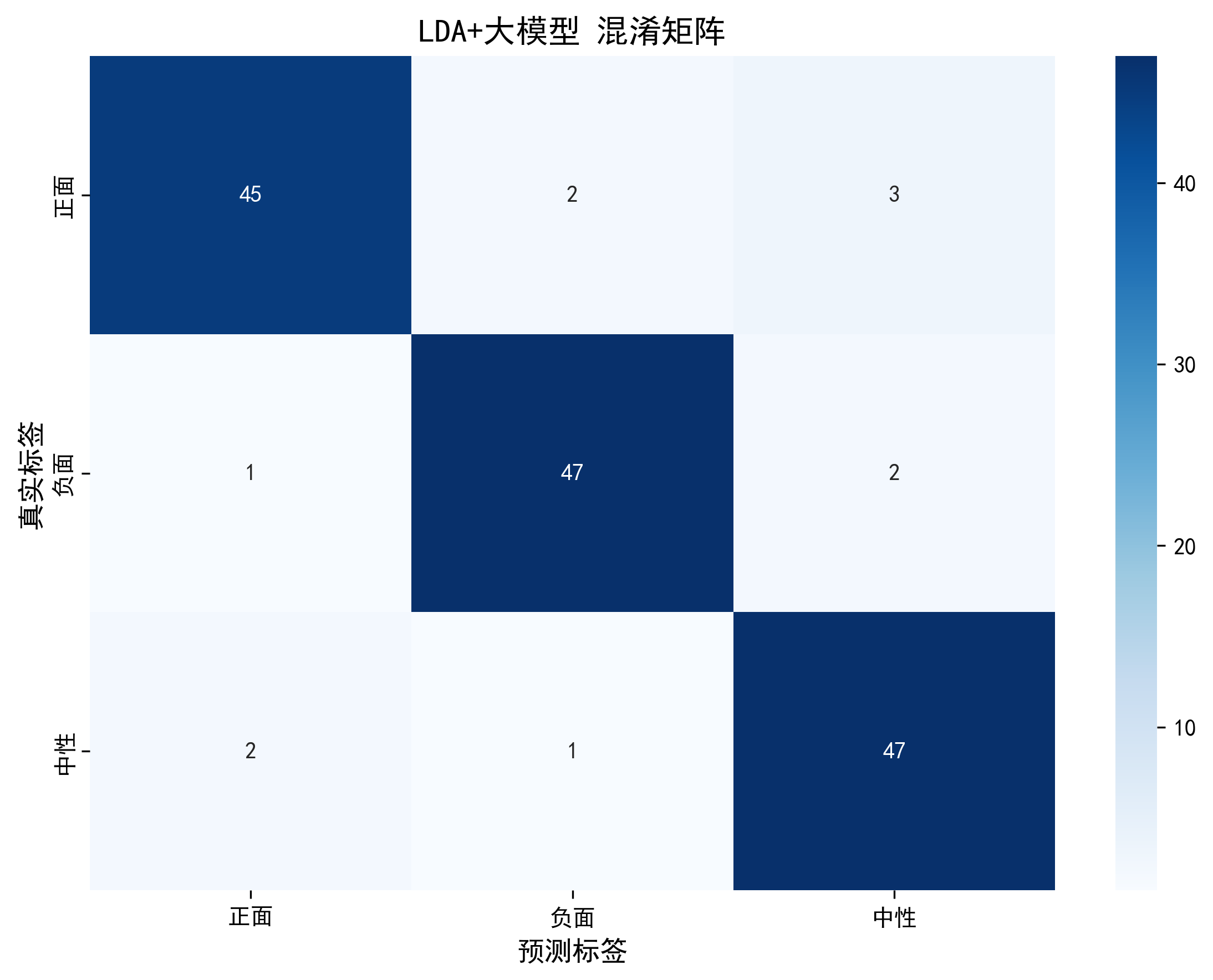
- 4. 模型保存:用joblib保存训练好的 LDA 模型,后续部署时只需加载模型,输入新文本的语义向量即可预测。
输出结果:
=== LDA分类报告 === precision recall f1-score support 正面 1.00 1.00 1.00 2 负面 0.50 1.00 0.67 2 中性 0.00 0.00 0.00 2 accuracy 0.67 6 macro avg 0.50 0.67 0.56 6 weighted avg 0.50 0.67 0.56 6 LDA模型已保存为 lda_classifier.pkl
结果图示:
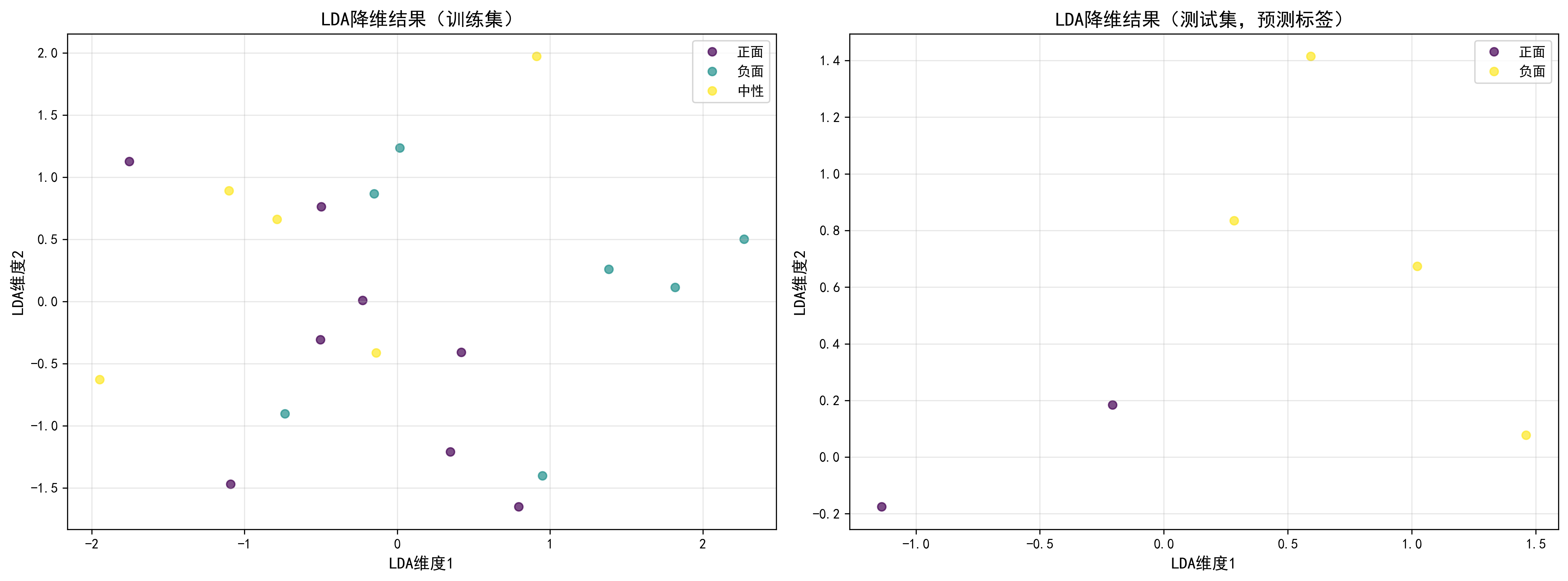
降维结果可视化:能直观看到不同类别的样本在 LDA 降维后的分布,理想情况下,不同类别应形成清晰的聚类;
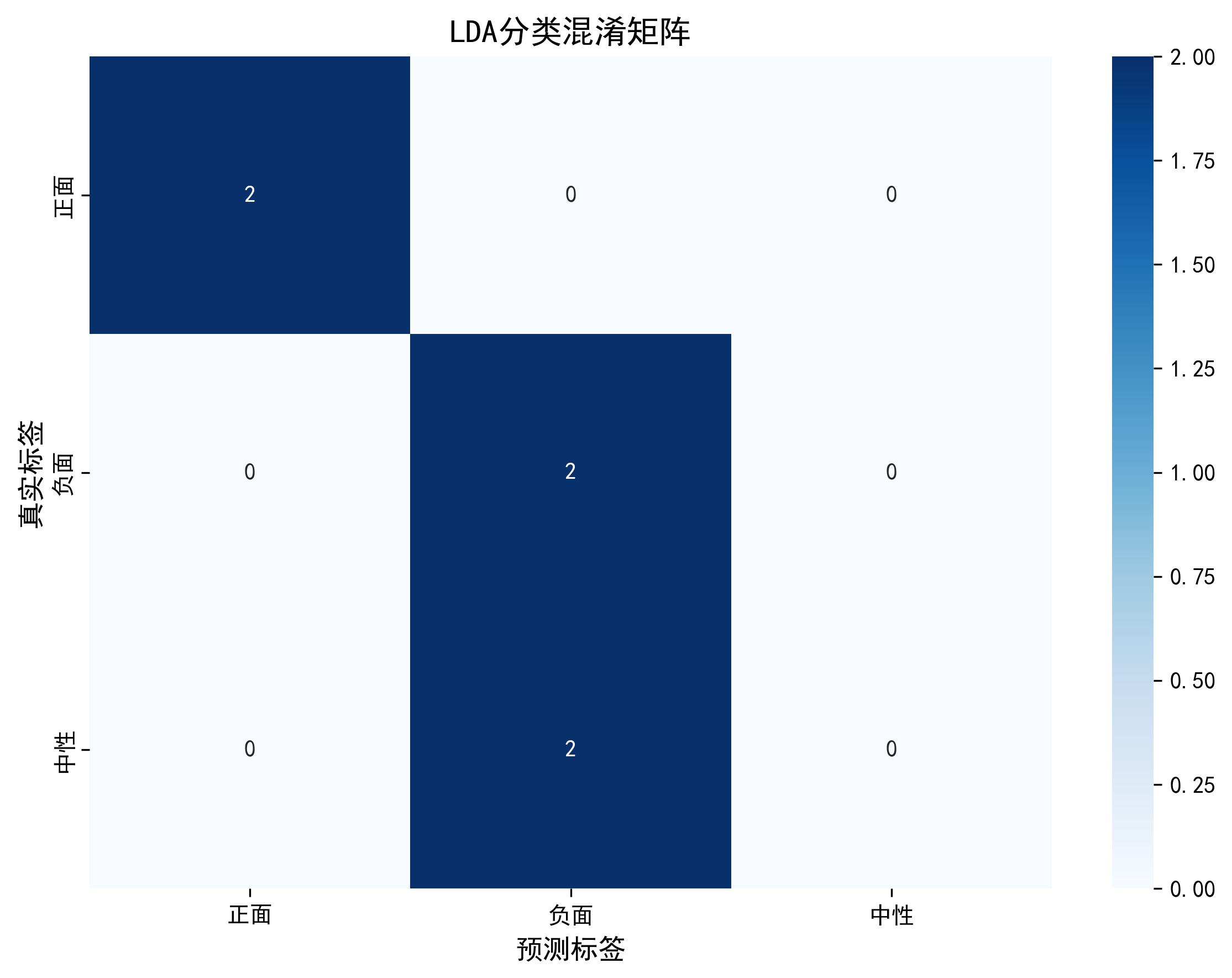
混淆矩阵可视化:能快速定位模型的薄弱环节,比如对“中性”样本的识别准确率低。
步骤 4:模型优化
- 1. 大模型层面优化
- 更换更适合的大模型:
- 中文场景:ERNIE对中文语义理解更好,ChatGLM-6B轻量版,语义能力强;
- 小数据场景:DistilBERT,蒸馏版 BERT,速度快,泛化性好;
- 调整语义向量生成方式:
- 增加max_length,比如从128改为256,适配长文本;
- 改用“所有 token 的均值”作为句子向量,部分场景比 [CLS] token 效果好;
- 向量归一化:对生成的语义向量做 L2 归一化(X = X / np.linalg.norm(X, axis=1, keepdims=True)),减少向量长度对 LDA 的影响。
- 2. LDA 层面优化
- 调整 LDA 参数:
- shrinkage:设置为'auto'(自动收缩),提升小数据场景的稳定性;
- tol:降低容差(比如从 1e-4 改为 1e-6),提升模型拟合精度;
- 核 LDA(KLDA):如果数据是非线性可分的,用核 LDA(sklearn中可通过KernelDiscriminantAnalysis实现);
- 特征筛选:对语义向量做简单的特征筛选(比如去除方差为 0 的维度),减少噪声。
- 3. 数据层面优化
- 数据增强:对小数据做简单的文本增强,比如同义词替换、语序调整,增加训练样本;
- 标签清洗:检查标注数据,修正错误标签,小数据场景中,标签错误对效果影响极大;
- 交叉验证:用 5 折交叉验证评估模型,避免单次划分的偶然性。
步骤 5:部署上线
加载预训练模型和已经优化过的LDA分类器实现部署,接收新文本并输出分类结果:
import numpy as np
import joblib
from transformers import BertTokenizer, BertModel
import torch
# 1. 加载预训练模型和LDA分类器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
lda = joblib.load('lda_classifier.pkl')
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# 2. 定义预测函数
def predict_text_category(text):
"""
输入文本,输出分类结果
:param text: 输入文本
:return: 类别名称(正面/负面/中性)
"""
# 生成语义向量
inputs = tokenizer(
text,
truncation=True,
padding='max_length',
max_length=128,
return_tensors='pt'
)
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
embedding = outputs.last_hidden_state[:, 0, :].squeeze().cpu().numpy()
# 将向量转换为2D数组(LDA要求输入为2D)
embedding = embedding.reshape(1, -1)
# LDA预测
pred_label = lda.predict(embedding)[0]
# 映射回类别名称
label_mapping = {0: '正面', 1: '负面', 2: '中性'}
return label_mapping[pred_label]
# 3. 测试预测
if __name__ == '__main__':
test_texts = [
"这款产品真的很好用,推荐大家购买",
"物流速度太慢了,非常不满意",
"产品还行,没有特别的优点和缺点"
]
for text in test_texts:
category = predict_text_category(text)
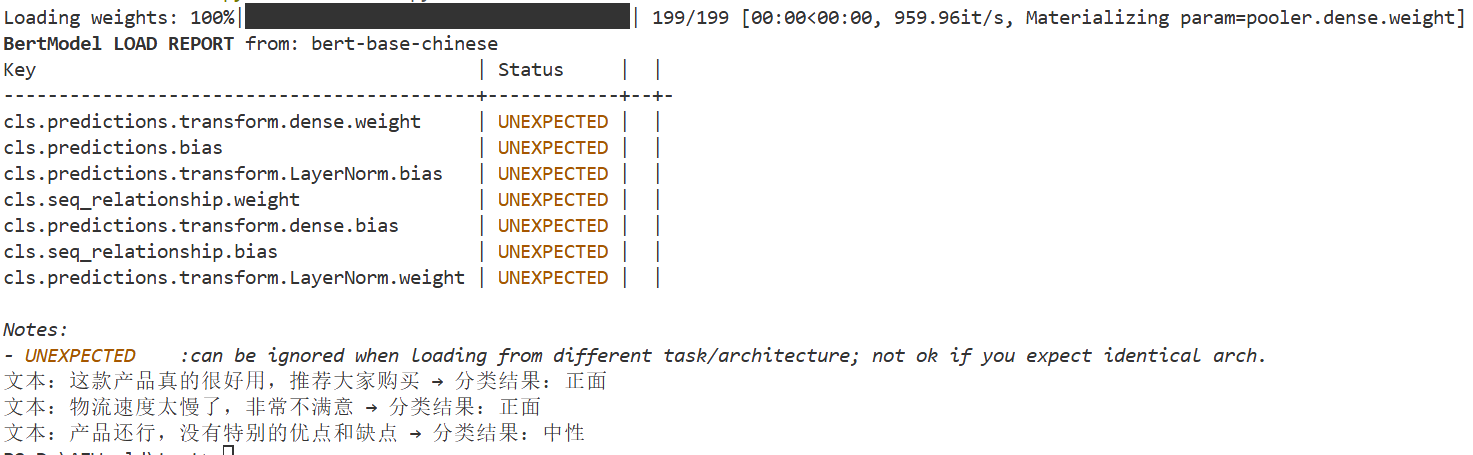
print(f"文本:{text} → 分类结果:{category}")输出结果:
文本:这款产品真的很好用,推荐大家购买 → 分类结果:正面 文本:物流速度太慢了,非常不满意 → 分类结果:正面 文本:产品还行,没有特别的优点和缺点 → 分类结果:中性
运行过程:
五、总结
总结下来,其实 LDA + 大模型这套方案,核心就是解决小数据做不好分类的痛点,就是用大模型帮机器读懂文本语义,再用 LDA 把高维特征简化,既避开了传统算法语义理解差的坑,又解决了纯大模型微调过拟合、成本高的问题,做 NLP 任务不用死磕数据量,也不用盲目追求大模型参数,选对组合比堆资源更重要。小数据场景里,与其花大价钱标注数据、硬调大模型,本质上不如大模型提质量结合LDA 提效率的搭配,简单直接出效果。
如果我们初次接触,先从简单场景入手,用轻量版大模型生成语义向量,再用 LDA 降维分类,跑通流程比纠结参数更重要。后期再根据效果,微调大模型选型或 LDA 参数就好。这套方案比较简洁务实,贴合企业真实场景,不用复杂框架,不用高深知识,理解透核心逻辑,哪怕只有几百条数据,也能做出稳定又精准的分类效果。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号